引言
在当今快速发展的人工智能领域,语言模型已成为处理自然语言任务的核心技术。上下文窗口作为语言模型工作记忆的关键组成部分,直接影响着模型理解和生成文本的能力。本文将深入探讨上下文窗口的概念、工作机制、不同类型及其在语言模型中的应用,帮助读者全面理解这一核心技术概念及其对AI交互体验的影响。
正文内容
上下文窗口的基本概念
上下文窗口是指语言模型在生成新文本时可以回顾和引用的全部文本量以及它生成的新文本。这与语言模型训练时使用的大量数据语料库不同,代表了模型的"工作记忆"。
较大的上下文窗口允许模型理解和响应更复杂和冗长的提示,而较小的上下文窗口可能会限制模型处理较长提示或在扩展对话中保持连贯性的能力。这就好比人类的短期记忆容量,容量越大,能同时处理的信息就越复杂和全面。
标准上下文窗口的工作机制
在标准API请求中,上下文窗口遵循特定的行为模式:
- 渐进式令牌积累:随着对话轮次的推进,每个用户消息和助手响应都会在上下文窗口中累积,且完全保留之前的对话轮次。
- 线性增长模式:上下文使用量随着每个回合而线性增长,前一个回合的内容被完全保留。
- 固定容量限制 :例如Claude模型的上下文窗口有200,000个令牌的总容量,这是存储对话历史记录和生成新输出的最大容量。^^[The diagram below illustrates the standard context window behavior for API requests1 下图说明了 API 请求 1 的标准上下文窗口行为
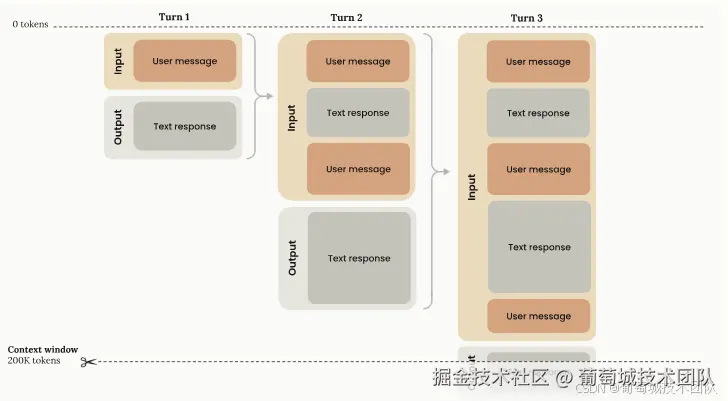
上下文窗口的输入输出流程可分为两个阶段:
- 输入阶段:包含所有以前的对话历史记录以及当前用户消息
- 输出阶段 :生成文本响应,该响应将成为未来输入的一部分
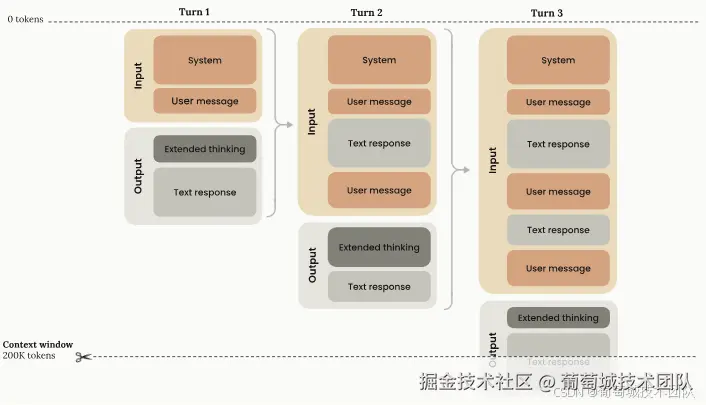
扩展思维模式下的上下文窗口
当启用扩展思维功能时,上下文窗口的管理变得更加复杂:
- 令牌计算规则:所有输入和输出令牌(包括用于思考的令牌)都计入上下文窗口限制,但在多轮情况下存在细微差别。
- 思维预算令牌:这是max_tokens参数的子集,作为输出令牌计费,并计入速率限制。
- 自动剥离机制:Anthropic API会自动从上下文窗口计算中剥离之前的思维块,这些思维块
技术实现细节包括:
- API自动排除之前轮次的思维块
- 扩展思维令牌仅在生成时作为输出令牌计费一次
- 有效上下文窗口计算公式:context_window = (input_tokens - previous_thinking_tokens) + current_turn_tokens
- 思维令牌包括思维块和redacted_thinking块
结合工具使用的上下文窗口
当扩展思维与工具使用结合时,上下文窗口管理遵循特定规则:
第一轮架构:
- 输入组件:工具配置和用户消息
- 输出组件:扩展思维+文字回复+工具使用请求
- 所有输入和输出组件都计入上下文窗口,并作为输出令牌计费
工具结果处理(第二轮):
- 输入组件:第一轮的所有块以及tool_result,必须包含对应的未修改思维块
- 输出组件:仅文本响应(在下一条用户消息前无额外扩展思维)
- 所有组件仍计入上下文窗口和输出令牌
第三步:
- 输入组件:结转所有输入和上一轮输出(思维块除外)
- 输出组件:生成新的扩展思维块
- 令牌计算:自动剥离之前思维令牌,其他块仍计入上下文窗口
关键注意事项:
- 必须包含未修改的思维块(含签名/编辑部分)
- 有效窗口计算公式变为:context_window = input_tokens + current_turn_tokens
- 使用加密签名验证思维块真实性
- Claude 4支持工具调用间的交错思维,而Claude Sonnet 3.7不支持
新版Claude模型的上下文窗口管理
较新的Claude模型(从Claude Sonnet 3.7开始)改进了上下文窗口管理:
- 显式错误提示:当提示令牌和输出令牌总和超过上下文窗口时,系统返回验证错误而非静默截断,提供更可预测的行为。
- 精确令牌管理:需要更仔细地规划令牌使用,可使用令牌计数API预估消息将消耗的令牌数后再发送给Claude。
结论
上下文窗口作为语言模型的核心工作机制,直接影响着AI系统的交互能力和复杂度处理水平。从基本概念到结合扩展思维和工具使用的高级应用,上下文窗口的管理策略不断演进,为开发者提供更强大的工具同时也提出了更精细的资源管理要求。理解上下文窗口的工作原理对于优化AI应用性能、设计高效对话流程以及合理规划系统资源都具有重要意义。随着模型技术的进步,上下文窗口的管理将变得更加智能和高效,为自然语言处理应用开辟更广阔的可能性。