金金金上线!
话不多,只讲你能听懂的前端知识

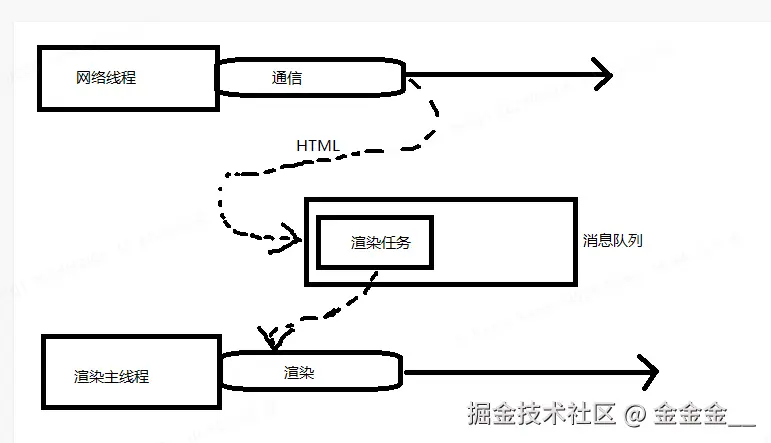
渲染时间点
浏览器里面有一个网络进程,进程里面会有一个网络线程:去通信一顿操作之后拿到
HTML之后会把这个东西生成 成 一个渲染任务 放到消息队列去排队,渲染主线程拿到渲染任务之后启动渲染流程
渲染流水线
浏览器是如何渲染页面的?
当浏览器的网络线程收到HTML文档后,会产生一个渲染任务,并将其传递给渲染主线程的消息队列。
在事件循环机制的作用下,渲染主线程取出消息队列中的渲染任务,开启渲染流程。
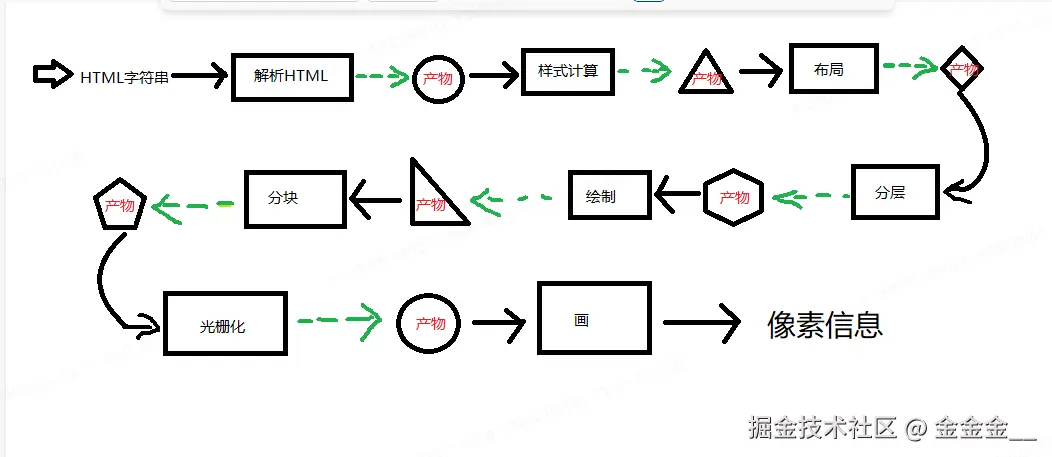
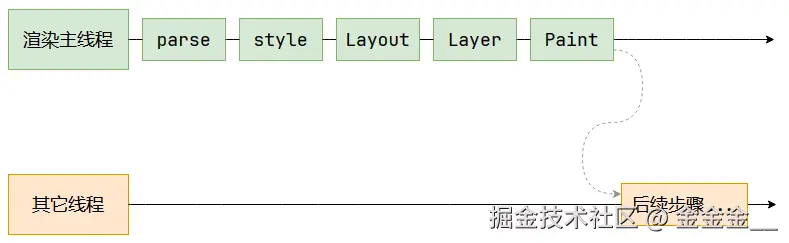
整个渲染流程分为多个阶段,分别是:
HTML解析、样式计算、布局、分层、绘制、分块、光栅化、画每个阶段都有明确的输入输出,上一个阶段的输出会成为下一个阶段的输入。
这样整个渲染流程就形成了一套组织严密的生产流水线。
渲染的第一步是解析
HTML。解析过程中遇到
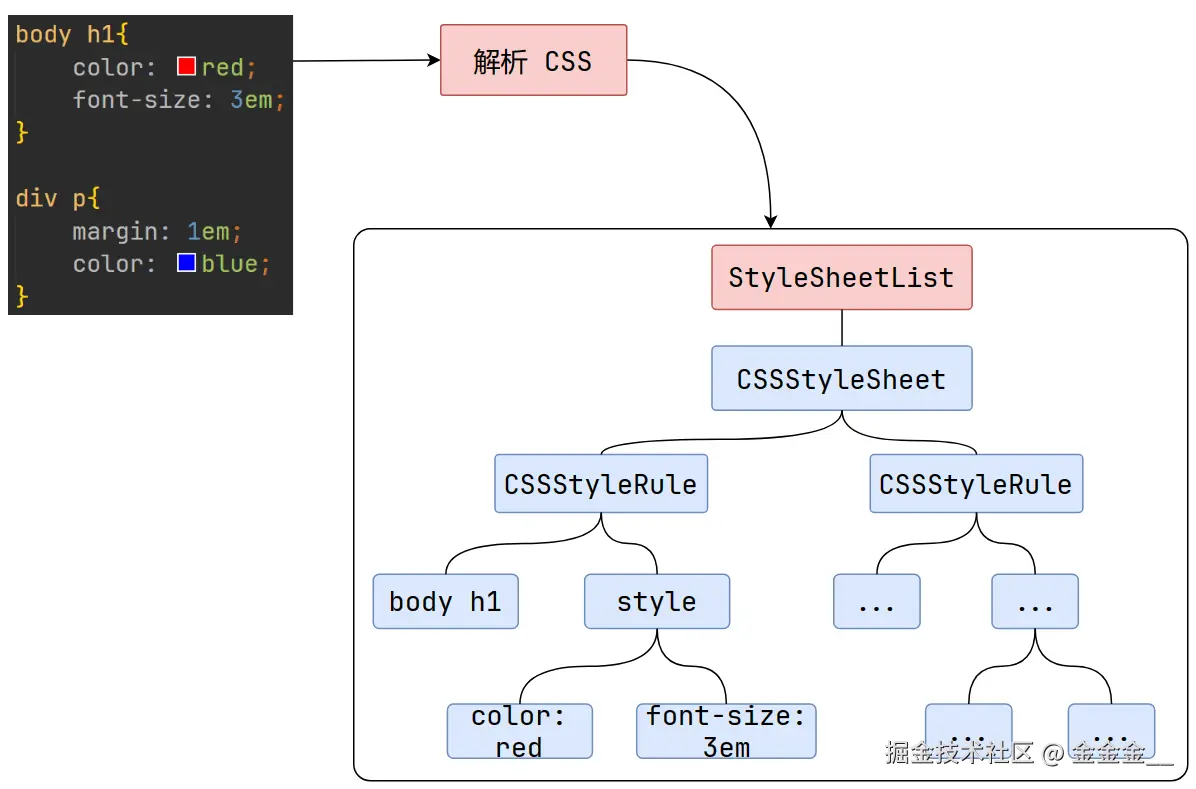
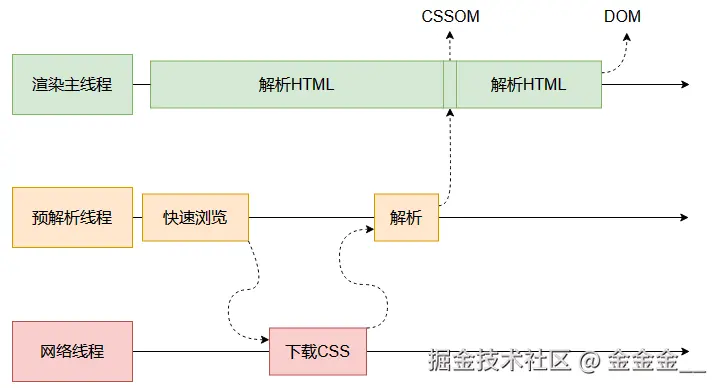
CSS解析CSS,遇到JS执行JS。为了提高效率,浏览器在开启解析前会启动一个预解析的线程,率先下载HTML中的外部CSS文件和外部的JS文件。如果主线程解析到
link位置,此时外部的CSS文件还没有下载好,主线程不会等待,继续解析后续的HTML。这是因为下载和解析CSS的工作是在预解析线程中进行的。这就是CSS不会阻塞HTML解析的根本原因。如果主线程解析到
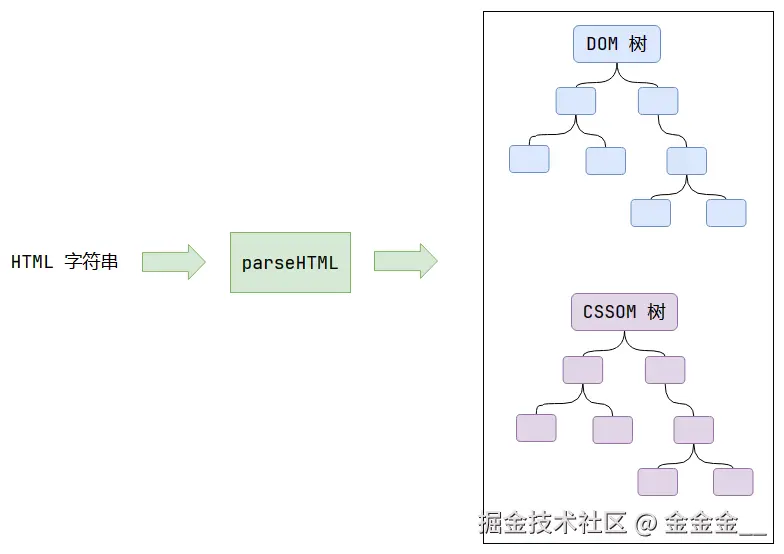
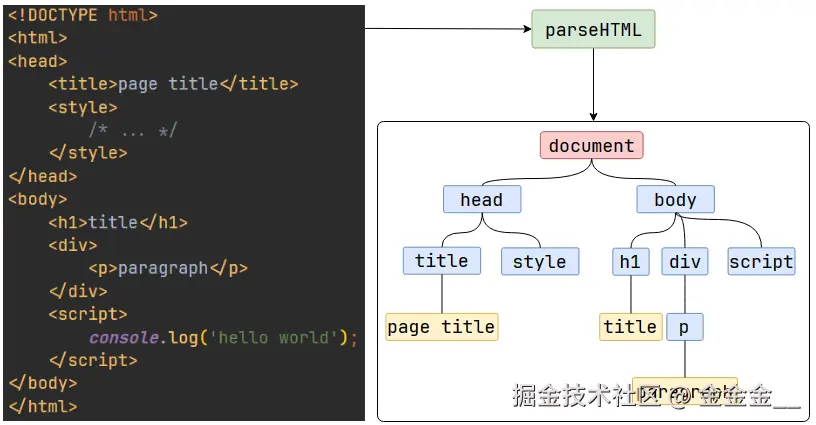
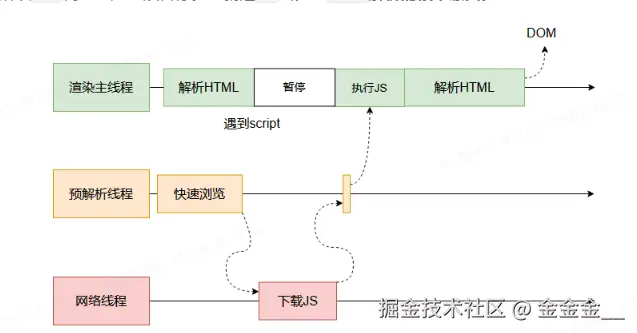
script位置,会停止解析HTML,转而等待JS文件下载好,并将全局代码解析执行完成后,才能继续解析HTML。这是因为JS代码的执行过程可能会修改当前的DOM树,所以DOM树的生产必须暂停。这就是JS会阻塞HTML解析的根本原因。第一步完成后,会得到
DOM树和CSSOM树,浏览器的默认样式、内部样式、外部样式、行内样式均会包含在CSSOM树中。
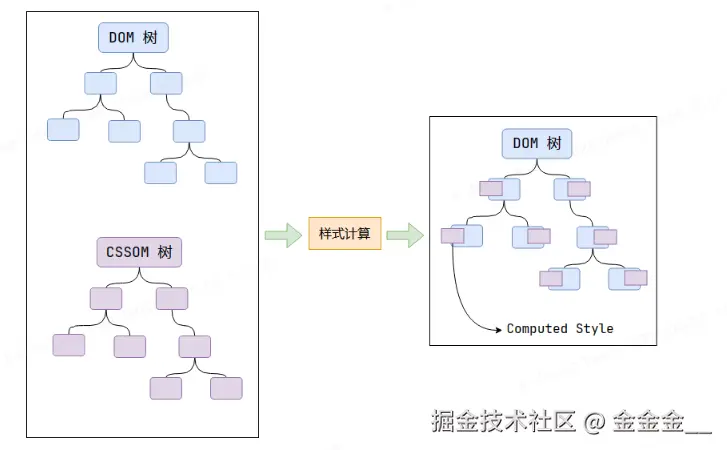
渲染的第二步是样式计算。
主线程会遍历得到的
DOM树,依次为树中的每个节点计算出它最终的样式,称之为Computed Style。在一过程中,很多预设值会变成绝对值,比如
red会变成rgb(255,0,0);相对单位会变成绝对单位,比如em会变成px。这一步完成后,会得到一颗带有样式的
DOM树。
渲染的第三步是布局。
布局完成后会得到布局树。
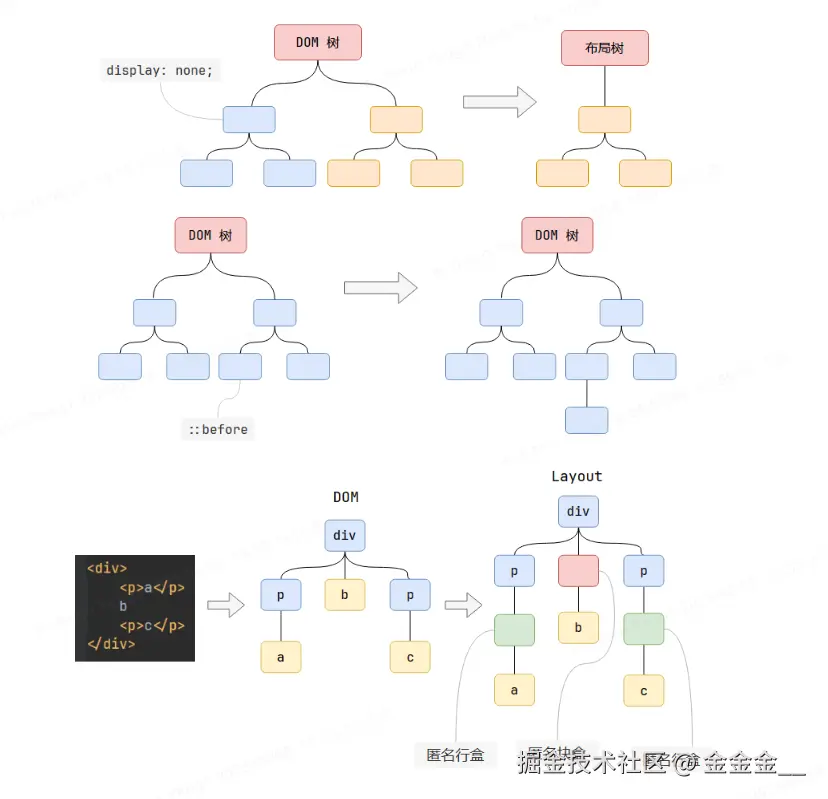
布局阶段会依次遍历
DOM树的每一个节点,计算每个阶段的几何信息。例如节点的宽高、相对包含快的位置。大部分时候,
DOM树和布局树并非一一对应。原因:
布局树是记录节点的几何信息(尺寸和位置)的,如果设置了
display: none;,则节点失去几何信息,不会被添加到布局树中。伪元素节点不存在于
DOM树中,但是有几何信息,因此会被生成到布局树中。布局过程存在两个规则(
w3c规定):
- 内容必须在行盒中
- 行盒和块盒不能相邻
如果在块盒中直接写入内容,则会在中间生成一个匿名行盒 ;如果块盒和行盒相邻,则为行盒外部生成一个匿名块盒。(参考上图)
📌插播小知识:
html标签只表明语义,不区分行盒或块盒,css决定元素是行盒还是块盒。通常理解的
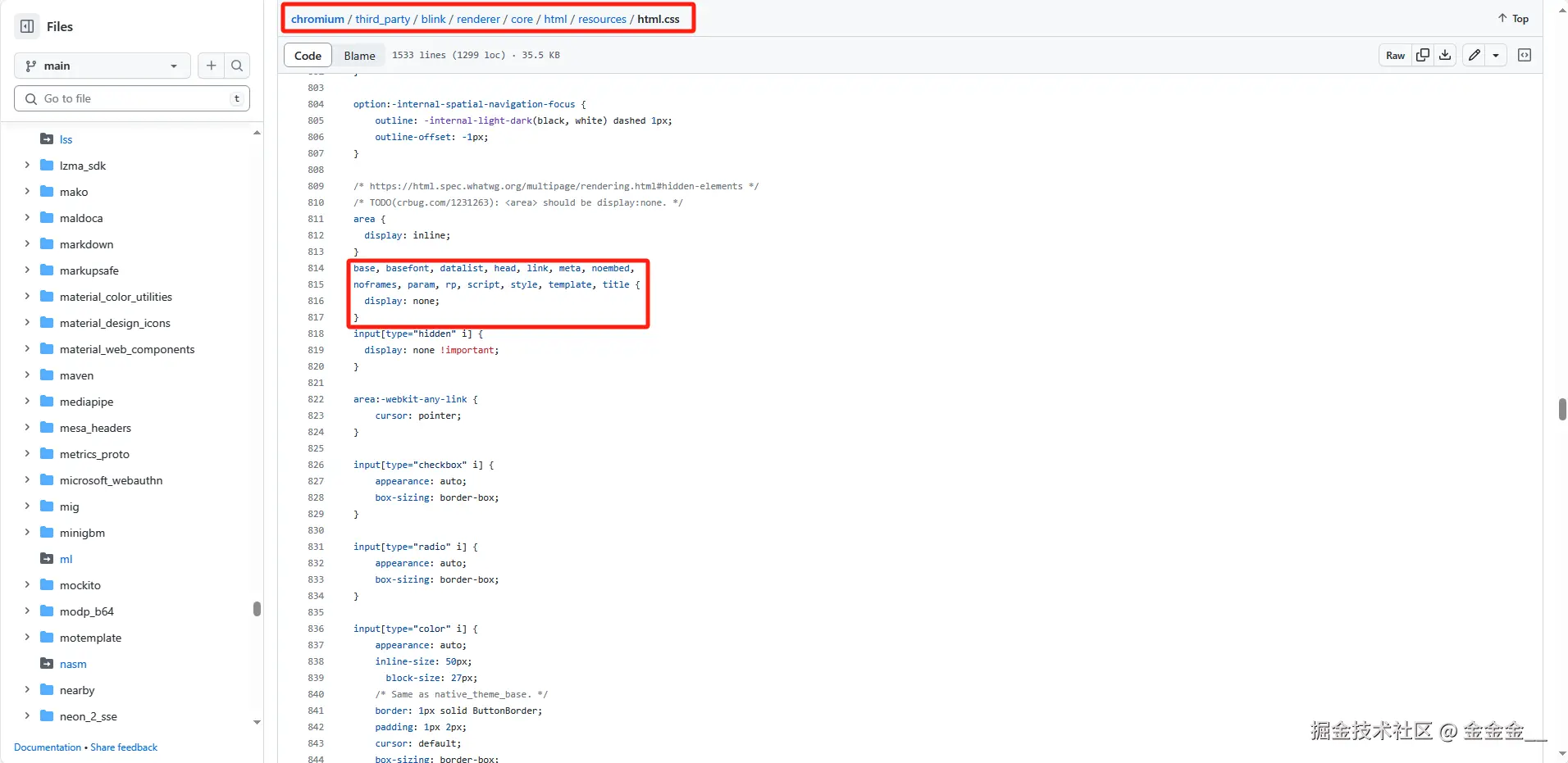
<p>, <div>是块盒,是因为浏览器默认样式给它们设置了display: block;。
<head>,<meta>等标签都是隐藏的,是因为浏览器默认样式表给它们设置了display: none;。可以在github上chromium的源代码中找到这些默认样式。
上述的
DOM树和布局树都是指浏览器底层的C++对象,它们以不同程度暴露到JS中。对于
DOM树,JS提供了document对象可以访问;而布局树,只暴露出了很少的内容,例如:clientWidth,offsetWidth等属性。
渲染的第四步是分层。
主线程会使用一套复杂的策略对整个布局树中进行分层。
分层的好处在于,将来某一个层改变后,仅会对该层进行后续处理,从而提示效率。
滚动条、堆叠上下文(与堆叠上下文有关的属性:
z-index,opacity,transform......)等样式都会或多或少的影响分层结果,也可以通过will-change属性更大程序的影响分层。注意:
will-change不要滥用,不要一开始写代码就用这个属性,一定要是效率出了问题、渲染变得卡了,最后定位就是分层造成的,某块区域经常变动 不希望重绘的过多,所以让这块区域单独形成一个层,这个时候才考虑使用will-change,不要滥用,因为分层过多不是好事~多了也会容易造成卡顿等引用自MDN
绘制可以将布局树中的元素分解为多个层。将内容提升到
GPU上的层(而不是CPU上的主线程)可以提高绘制和重新绘制性能。有一些特定的属性和元素可以实例化一个层,包括video和canvas,任何CSS属性为opacity、3D transform、will-change的元素,还有一些其他元素。这些节点将与子节点一起绘制到它们自己的层上,除非子节点由于上述一个(或多个)原因需要自己的层。分层确实可以提高性能,但是它以内存管理为代价,因此不应作为
web性能优化策略的一部分过度使用。
📌插播小知识will-change :通常大多数元素例如
<div>不会单独分为一层,但是如果它的内容经常需要更新、需要重新渲染,可以添加一个属性:will-change。如果这个元素的
transform属性需要经常发生变化,那么可以声明will-change: transform;,告知浏览器其需要经常更新,但是最后是否决定分层依然是浏览器的具体实现决定的。
渲染的第五步是绘制。
主线程会为每个层单独产生绘制指令集,用于描述这一层的内容该如何画出来。
绘制指令类似于
canvas的操作方法:
- 移动画笔到
xxx- 绘制宽为x,高为y的矩形
- ......
事实上,
canvas是浏览器将绘制过程封装后提供给开发者的工具。
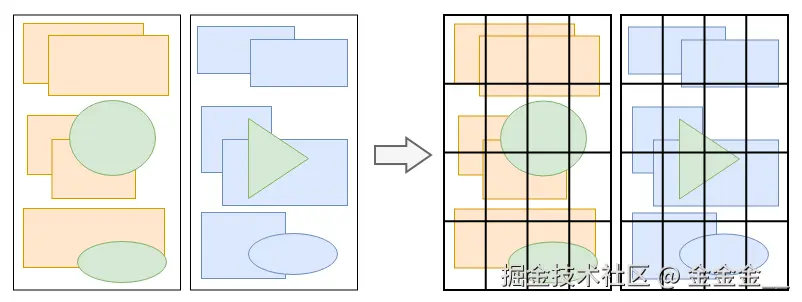
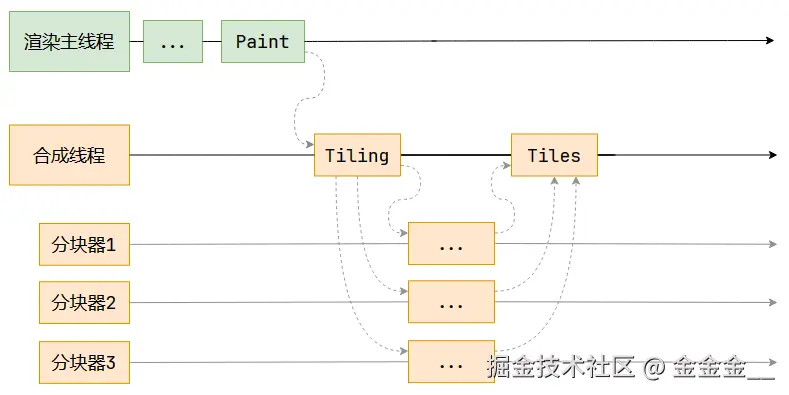
渲染的第六步是分块。
完成绘制后,主线程将每个图层的绘制信息提交给合成线程,剩余工作将由合成线程完成。
合成线程首先对每个图层进行分块,将其划分为更多的小区域。
它会从线程池中拿取多个线程来完成分块工作。
其中的合成线程和渲染主线程都位于渲染进程里。
目前大多数浏览器的策略是每个标签页都对应一个渲染进程,渲染进程里面包含多个线程。
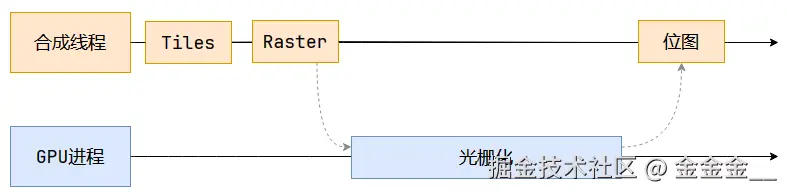
渲染的第七步是光栅化。
合成线程会将块信息交给
GPU进程,以极高的速度完成光栅化。
GPU进程会开启多个线程来完成光栅化,并且优先处理靠近视口区域的块。光栅化的结果就是一块一块的位图。
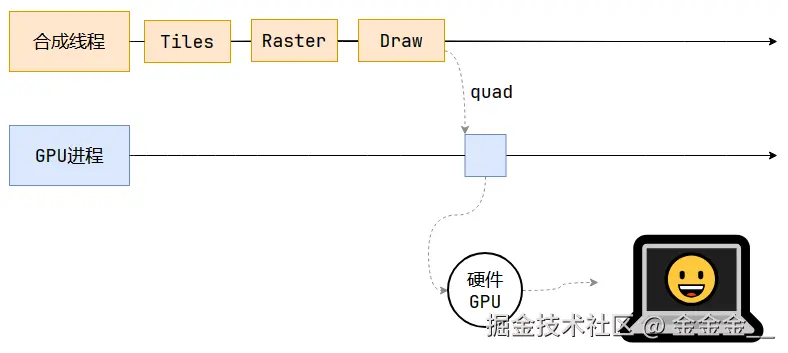
渲染的最后一步 也就是第八步 是 画。
合成线程拿到每个层、每个块的位图后,生成一个个【指引 `quad` 】信息。
指引会标识出每个位图应该画到屏幕的哪个位置,以及会考虑到旋转、缩放等变形。
变形发生在合成线程,与渲染主线程无关,这就是
transform效果高的本质原因。合成线程会把
quad提交给GPU进程,由GPU进程产生系统调用,提交给GPU硬件,完成最终的屏幕成像。为什么合成线程不直接将结果交给硬件,而要先转交给
GPU?答:
合成线程和渲染主线程都是隶属于渲染进程 的,渲染进程处于沙盒 中,无法进行系统调度,即无法直接与硬件
GPU通信。沙盒是一种浏览器安全策略,使得渲染进程无法直接与操作系统、硬件通信,可以避免一些网络病毒的攻击。
综上,合成线程将计算结果先转交给浏览器的
GPU进程,再由其发送给硬件GPU,最终将内容显示到屏幕上。
👉CSS中的transform是在这一步确定的,只需要对位图进行矩阵变换。这也是transform效率高的主要原因,因为它与渲染主线程无关,这个过程发生在合成线程中。
什么是reflow?
reflow的本质就是重新计算layout树。当进行了会影响布局树的操作后,需要重新计算布局树,会引发
layout。为了避免连续的多次操作导致布局树反复计算,浏览器会合并这些操作,当
JS代码全部完成后再进行统一计算。所以,改动属性造成的reflow是异步完成的。也同样因为如此,当
JS获取布局属性时,就可能造成无法获取到最新的布局信息。浏览器再反复权衡下,最终决定获取属性立即
reflow。
什么是repaint?
repaint的本质就是重新根据分层信息计算了绘制指令。当改动了可见样式后,就需要重新计算,会引发
repaint。由于元素的布局信息也属于可见样式,所以
reflow一定会引起repaint。
为什么transform的效率高?
因为
transform既不会影响布局也不会影响绘制指令,它影响的只是渲染流程的最后一个draw阶段。由于
draw阶段在合成线程中,所以transform的变化几乎不会影响到渲染主线程。反之,渲染主线程无论如何忙碌,也不会影响
transform的变化。
编写有误还请各位指正,万分感谢。