就在今天凌晨,GPT-5 经过了那么多天的铺垫,终于在千呼万唤中发布了,社交媒体和技术社区几乎被刷屏。

新版本在复杂推理、多模态输入、长对话保持等方面都有了明显进步。同时,GPT-5 在多轮逻辑推导中出现的错误率也有所下降,在编写代码、分析数据、跨模态生成等任务中展现出更强的稳定性和可控性。
OpenAl 的早期测试者反馈中,Cursor 创始人 Michael Truel 表示 GPT-5"具有显著的智能,易于操控,甚至拥有其他模型中不具备的人格特质",在多个实际编码任务中表现优异。

总体而言,GPT-5 在原有能力的基础上,实现了综合性提升。
但与此同时,不少用户和业内人士对这次更新并不买账。
有分析者认为 GPT-5 与前代相比提升有限,不足以带来明显"跃迁感"。
部分创作者调侃,这更像是一次 4.5 到 4.6 的平滑升级,而不是跃迁式的版本迭代。
甚至在发布会上还出现了图表错误:
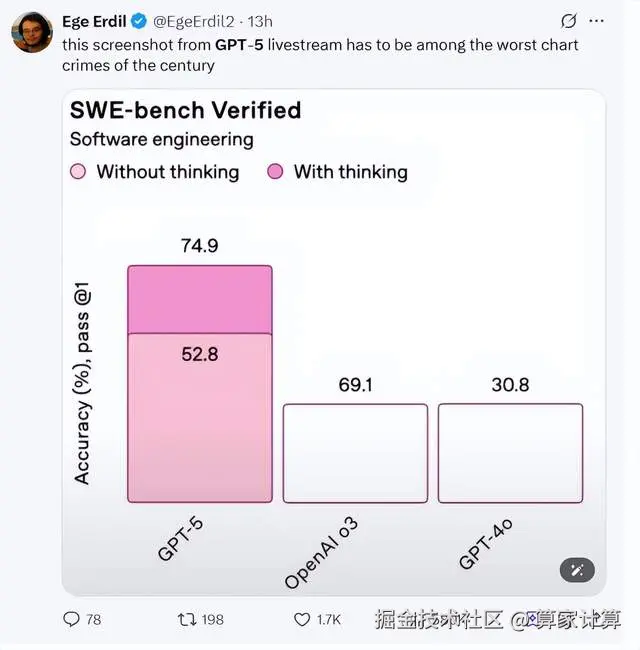
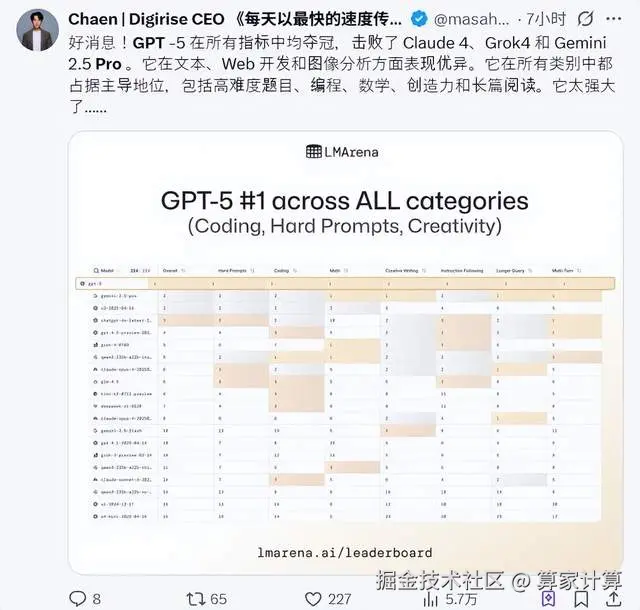
即便 GPT-5 在最新的大模型盲测竞技场榜单中已经是全方位第一。
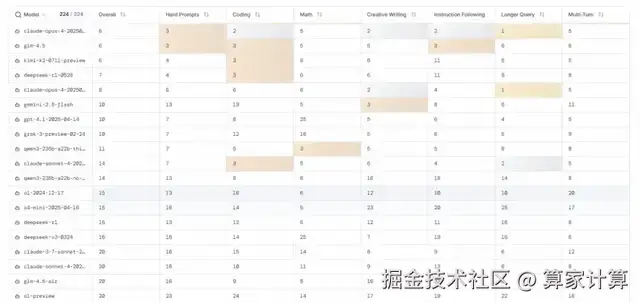
比起 GPT-4,GPT-5 的发布,为什么没有想象中惊艳?
首先,GPT-5 的评价分化背后,是大语言模型发展进入边际效应减弱的阶段。过去几年,OpenAI 和其他厂商依靠扩大参数规模、扩充训练数据,实现了从 GPT-2 到 GPT-4 的快速跃升。然而,随着模型规模接近可用算力和数据的极限,性能提升的感知度正在下降。
例如,在 GPT-3 到 GPT-4 的升级中,数学推理正确率、代码生成精度都有肉眼可见的跃升,但到了 GPT-5,这类指标的提升幅度在多数通用场景下只剩个位数百分比。这种微幅提升对专业用户依然有价值,但对普通用户来说,感受可能不如一次UI改版来得明显。
此外,用户心理预期的变化也是原因之一。Gartner 提出的技术成熟度曲线(Hype Cycle)表明:任何新技术在诞生后,都会经历"技术触发""期望膨胀的峰值""幻灭低谷""稳步爬升"和"成熟期"几个阶段。
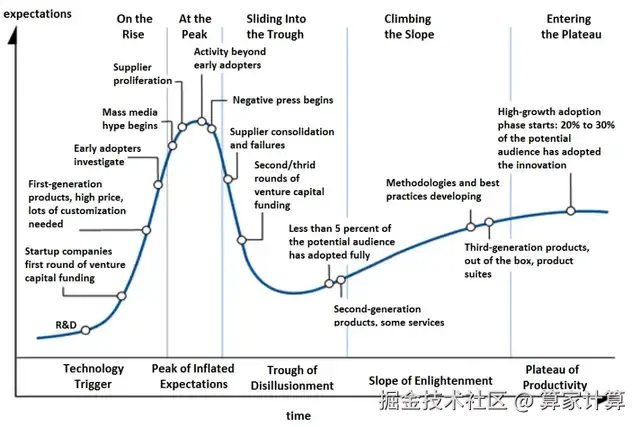
在 GPT-3 到 GPT-4 的跨越中,大语言模型正处于"期望膨胀的峰值",公众和行业几乎认为它可以在多数场景中替代人类工作,因此每一次升级都被寄予极高期望。
当时,甚至有人预测 GPT-5 的发布,将实现真正的 AGI。然而,随着模型性能接近架构和数据的瓶颈,单次迭代带来的体验提升变得有限,用户很容易感到落差。
GPT-5 的发布正好出现在从峰值走向"幻灭低谷"的阶段。而且 OpenAI 过高的宣传也让新版本更容易遭到质疑,反而掩盖了其中真正的进步点。
最后,AI 大模型的知识更新滞后、幻觉等问题依然没有消失。
以往,算力往往是 AI 大模型面临的主要困境。然而,发展到现在,尽管算力充足,当前大模型依旧容易出现幻觉,在知识链条推理中漏掉关键环节。
而且,GPT-5 的知识库更新到 2024 年底,但在许多实时性强的领域,如 AI 芯片新品规格、最新学术论文引用、行业政策变化,模型依然需要依赖外部检索或插件,这意味着核心能力还未与实时世界充分对齐。
行业发展的现实压力
这背后其实也是整个 AI 行业的缩影。技术迭代的节奏越来越快,但研发成本和风险也同步上升。据公开信息,GPT-5 的训练可能消耗了数百万美元级别的算力资源,还包括大量人工标注和数据清洗工作。这样的投入意味着,每一次迭代都需要在性能提升、市场反响和商业回报之间找到平衡。
与此同时,开源模型的崛起正在改变竞争格局。像 LLaMA 3、Mistral、Qwen 系列等开源大模型,在部分任务上的性能已经逼近甚至超过闭源模型,而且可在私有环境部署、成本更低。
很多企业在权衡后,开始将开源模型与闭源 API 混合使用,这进一步压缩了闭源产品在单纯性能竞争上的优势空间。GPT-5 的表现,并没有彻底扭转这种趋势。
从今天起,GPT-5 面向所有用户开放使用,无需排队。对于免费用户而言,每天提供一定额度,用完即自动切换到 GPT-5-mini。Pro 会员则可体验GPT-5 Pro高级推理功能。
面向开发者,GPT-5 的 API 价格,也比 GPT-4 最便宜的 Preview 版本还低。
相比于技术,OpenAI 这次发布,更多聚焦于价格优势和产品整合,加速商业落地。
在 AI 发展的下半场,单一产品的升级可能难以带来全民共振的惊喜。GPT-5 虽然未能成为划时代的符号,但它确实处在一个重要的转折点。大模型的未来不仅需要更大的规模,更需要更深层次的智能演化。