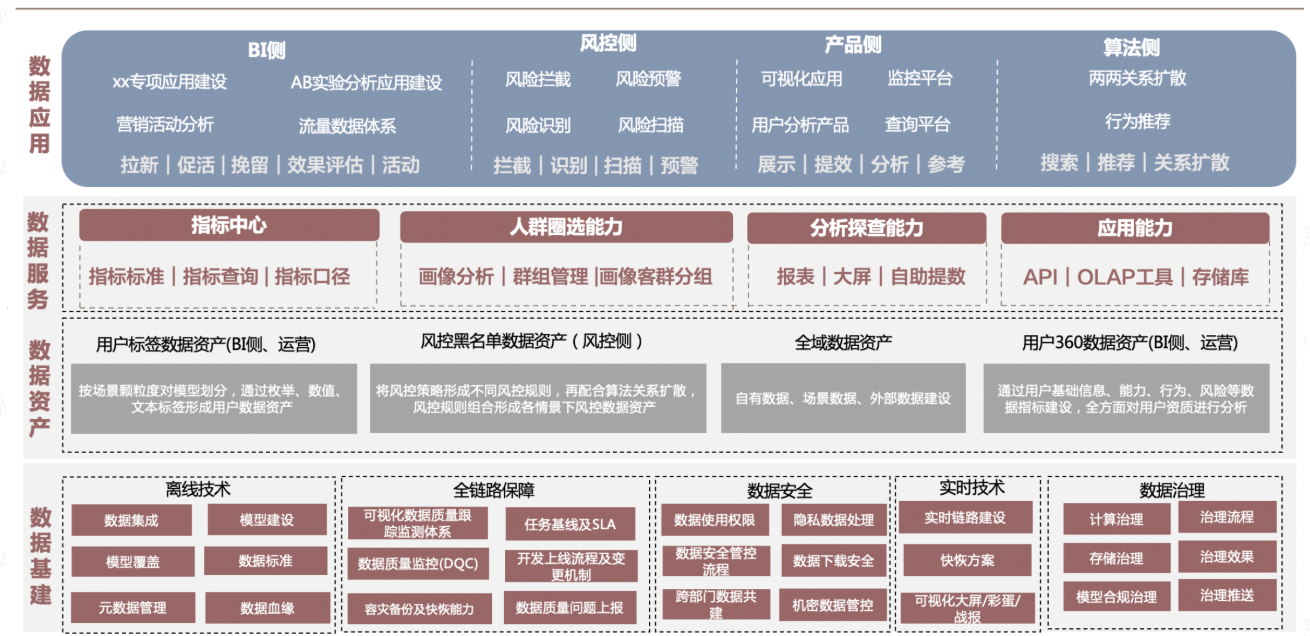
一、数据流转
数据从接入到应用的过程
1、用户在客户端的行为数据会通过日志收集、操作记录到数据库中。这一步也涉及到埋点
2、数仓对不同的数据源数据进行接入(mysql、kafka、业务系统等)
3、数据仓库对数据进行清洗、转换、关联、指标开发等完成数据宽表、标签宽表的开发
4、数分/算法使用数仓开发宽表进行实验、各类分析方法、可视化、算法模型开发,进行整体数据应用;
5、业务侧使用分析好的数据进行投放、拉新、促活等操作
二、数据仓库的概念
数据基建:承接各种数据源,通过对数据源数据采集,将不同源数据接入到数据仓库中统一处理
数据资产:数据宽表、数据明细表的建设
数据服务:通过指标体系、用户标签、数据门户、接口等方式统一管理数据
数据应用:为运营、风控等业务提供数据支撑,包括看板大屏、a/b实验、专题分析报告等
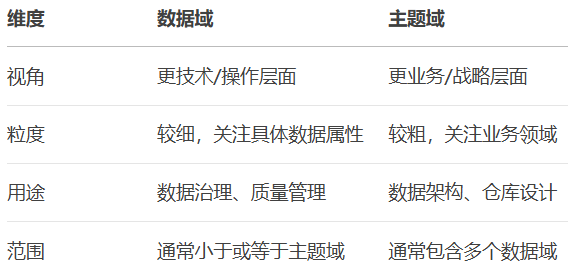
三、数据域及主题域
数据域是基于业务含义或技术特性进行分类,同一数据域中的数据共享相同的业务定义和规则,例如:客户数据域、产品数据域等
主题域是从业务战略角度对信息的划分,代表企业关注的主要业务领域,比数据域更宏观,一个主题域可能包含多个数据域。例如:销售主题域、供应链主题域等
四、数仓分层
4.1 为什么要数仓分层
(1)清洗数据结构:每一层有对应的作用,在使用时更好定位与了解
(2)数据血缘追踪:清晰知道上下游,便于排查问题,知道下游哪个模块在使用,提高开发效率及后期维护,尤其是在找报错和指标地来源时
(3)减少重复开发:完善好中间层,减少后期不必要的开发,从而减少资源消耗,保障口径一致
(4)复杂问题简单化:将复杂的问题拆解成多个步骤来完成,每一层处理单一步骤,当数据出现问题,只需要从单个问题去解决
4.2 如何分层及每层的作用
ODS(接入层):从各数据源将数据同步到数仓,不做任何数据处理,保留原始数据
DIM(维度层):用于维度管理
DWD(明细层):对ODS层数据进行关联,清洗,维度退化(维度表中维度数据放入明细表),转换,主题域建设
DWM(轻度汇总层):DWD层的生产数据进行整体关联,形成一张大的明细宽表
DMS(汇总层) :按照主题域、颗粒度(例如买家、卖家)划分,按照周期粒度、维度聚合形成指标较多的宽表。在DWS层完成指标口径统一及沉淀
ADS(数据应用层):按照应用域,颗粒度划分(例如买家、卖家)划分,按照应用主题将对应数据标签补充至应用层,最终形成用户画像及专项应用
五、数仓模型介绍
维度建模:按照事实表、维度表来构建数据仓库模型的方法,根据维度表与事实表之间的链接方式完成数据表开发。
模型建设五要素:
- 数据域/主题域:数据域对当前业务场景或业务sop进行拆分完成建设,主题域则是通过业务使用场景去做
- 事实表设计:围绕着业务过程来设计,通过获取描述业务过程的度量来表达业务过程,包含了引用的维度和与业务过程有关的度量;
- 维度:对当前场景分析角度描述及补充
- 颗粒度:数据域下场景用户再细分(买家和卖家),基于MECE法则,拆到不可拆分状态
- 度量值:对场景下数值类型的数据记录
六、增量与全量
数据分区:记录了当天的数据,可以通过分区快速定位自己数据,基本是日期
全量数据(对源数据全部覆盖)
增量数据(对源数据进行分区式覆盖)
df为日全量数据,di为日增量数据
七、数据模型规范
7.1 表命名规范
ODS层(接入层):全量:ods__{业务数据库名}_{业务数据表名}_df/di(df为日全量数据,di为日增量数据)
DWD层(明细层):dwd_{数据域}{二级数据域}{业务过程(不清楚或没有写detail)}_df/di(df为日全量数据,di为日增量数据)
DIM层(维度层):dim_业务域(没有业务相关可不写)__{维度定义}(例如日期写date)
DWM层(明细宽表层):dwd_{数据域}{二级数据域}{业务过程(不清楚或没有写detail)}_df/di(df为日全量数据,di为日增量数据)
DWS层(汇总层):dws_{数据域}{二级数据域}{颗粒度}(例如买家/卖家){业务过程}(如果没过程写target){周期粒度}(例如近30天写30d、一个月写1m、90天写90d等)
ADS层(应用层):ads_{一级主题域}(例如风控叫risk、营销叫mkt){二级主题域}{颗粒度}(例如买家/卖家){业务过程}{调度周期}(例如1天调度一次写1d)
7.2 字段命名
是否xxxxx用户,类型字段命名规范:is_{内容}
枚举值类型字段命名规范:xxxx_type
时间戳类型字段命名规范:xxx_date(日期),xxx_time(时间)
周期指标命名:{内容}_{时间描述}(如最近一次last1,最近两次last2,历史his,最近第二次last2nd)_date、最近180天 180d
百分比命名:{内容}_rate
数值类型(整型)命名:{内容}cnt{周期}(周期看情况加)
数值类型(小数)金额命名:{内容}amt{周期}(周期看情况加)