🥇个人主页:500佰
#Hive常见故障 #大数据 #生产环境真实案例 #Hive #离线数据库 #整理 #经验总结
说明:此篇总结hive常见故障案例处理方案 结合自身经历 总结不易 +关注(劳烦各位) +收藏 欢迎留言
专栏:Hive常见故障多案例FAQ宝典
【1】参数及配置类常见故障****本章
【2】任务运行类常见故障 本章
【3】SQL使用类常见故障 详见(点击跳转):
友情链接: Hive性能调优指导 --项目优化(指导书)
目录
[【1】参数及配置类常见故障 案例如下:](#【1】参数及配置类常见故障 案例如下:)
[执行set命令的时候报cannot modify xxx at runtime.](#执行set命令的时候报cannot modify xxx at runtime.)
[如何设置hive on spark 模式及提交任务到指定队列](#如何设置hive on spark 模式及提交任务到指定队列)
[hive on spark应用如何设置spark应用的参数?](#hive on spark应用如何设置spark应用的参数?)
[【2】任务运行类常见故障 案例如下:](#【2】任务运行类常见故障 案例如下:)
[drop partition操作有大量分区时操作失败](#drop partition操作有大量分区时操作失败)
Metastore连接数过高导致hive任务执行慢或任务失败
[return code 1:unable to close file](#return code 1:unable to close file)
Tez和MapReduce引擎下,Hive进行join的结果不一致
[【3】SQL使用类常见故障 如下(点击跳转):Hive常见故障多案例FAQ宝典 --项目总结(宝典二)](#【3】SQL使用类常见故障 如下(点击跳转):Hive常见故障多案例FAQ宝典 --项目总结(宝典二))
架构概述
Hive是建立在Hadoop上的数据仓库框架,提供类似SQL的Hive QL语言操作结构化数据,其基本原理是将HQL语言自动转换成MapReduce任务,从而完成对Hadoop集群中存储的海量数据进行查询和分析。
Hive主要特点如下:
-
海量结构化数据分析汇总。
-
将复杂的MapReduce编写任务简化为SQL语句。
-
灵活的数据存储格式,支持JSON,CSV,TEXTFILE,RCFILE,SEQUENCEFILE这几种存储格式。
Hive各组件说明:
| 名称 | 说明 |
|---|---|
| HiveServer | 一个集群内可部署多个HiveServer,负荷分担。对外提供Hive数据库服务,将用户提交的HQL语句进行编译,解析成对应的Yarn任务或者HDFS操作,从而完成数据的提取、转换、分析。 |
| MetaStore | 一个集群内可部署多个MetaStore,负荷分担。提供Hive的元数据服务,负责Hive表的结构和属性信息读、写、维护和修改。提供Thrift接口,供HiveServer、Impala、WebHCat等MetaStore客户端来访问,操作元数据。 |
| WebHCat | 一个集群内可部署多个WebHCat,负荷分担。提供Rest接口,通过Rest执行Hive命令,提交MapReduce任务。 |
| Hive客户端 | 包括人机交互命令行Beeline、提供给JDBC应用的JDBC驱动、提供给Python应用的Python驱动、提供给Mapreduce的HCatalog相关JAR包。 |
【1】参数及配置类常见故障 案例如下:
执行set命令的时候报cannot modify xxx at runtime.
症状
执行set命令时报以下错误:
Go
0: jdbc:hive2://xxx.xxx.xxx.xxx:21066/> set mapred.job.queue.name=QueueA;
Error: Error while processing statement: Cannot modify mapred.job.queue.name at list of params that are allowed to be modified at runtime (state=42000,code=1)解决方法
- 方案1:
-
登录集群 Manager页面,选择"集群 > 服务 > Hive > 配置 > 全部配置 > Hive > 安全"。
-
将要添加的参数添加到配置项hive.security.authorization.sqlstd.confwhitelist中。
-
点击保存并重启HiveServer后即可。如下图所示:
- 方案2:
-
登录集群 Manager页面,单击"集群 > 服务 > Hive > 配置 > 全部配置 > Hive > 安全"。
-
找到选项hive.security.whitelist.switch,选择OFF,点击保存并重启即可。
怎样在Hive提交任务的时候指定队列?
解决方法
如下,在执行语句前通过下述参数设置:
bash
set mapred.job.queue.name=QueueA;
select count(*) from rc;提交任务后,可在Yarn页面看到,任务已经提交到队列QueueA了。(说明:队列的名称区分大小写,如写成queueA,Queuea均无效。)
如何在导入表时指定输出的文件压缩格式
解决方法
-
当前Hive支持以下几种压缩格式:
bashorg.apache.hadoop.io.compress.BZip2Codec org.apache.hadoop.io.compress.Lz4Codec org.apache.hadoop.io.compress.DeflateCodec org.apache.hadoop.io.compress.SnappyCodec org.apache.hadoop.io.compress.GzipCodec -
如需要全局设置,既对所有表都进行压缩;可以在 Manager页面上进行全局配置,如下:
hive.exec.compress.output=true; 这个一定要选择true,否则下面选项不会生效。
-
如需在session级设置,只需要在执行命令前做如下设置即可:
bashset hive.exec.compress.output=true; set mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
desc描述表过长时,无法显示完整
解决方法
-
启动时,设置参数maxWidth=20000即可,如下:
bash[root@xxx.xxx.xxx.xxx logs]# beeline --maxWidth=2000 scan complete in 3ms Connecting to ...... Beeline version 1.1.0 by Apache Hive -
**扩展:**可通过beeline -help看到很多关于客户端显示的设置。如下:
bash-u <database url> the JDBC URL to connect to -n <username> the username to connect as -p <password> the password to connect as -d <driver class> the driver class to use -i <init file> script file for initialization -e <query> query that should be executed -f <exec file> script file that should be executed --hiveconf property=value Use value for given property --color=[true/false] control whether color is used for display --showHeader=[true/false] show column names in query results --headerInterval=ROWS; the interval between which heades are displayed --fastConnect=[true/false] skip building table/column list for tab-completion --autoCommit=[true/false] enable/disable automatic transaction commit --verbose=[true/false] show verbose error messages and debug info --showWarnings=[true/false] display connection warnings --showNestedErrs=[true/false] display nested errors --numberFormat=[pattern] format numbers using DecimalFormat pattern --force=[true/false] continue running script even after errors --maxWidth=MAXWIDTH the maximum width of the terminal --maxColumnWidth=MAXCOLWIDTH the maximum width to use when displaying columns --silent=[true/false] be more silent --autosave=[true/false] automatically save preferences --outputformat=[table/vertical/csv2/tsv2/dsv/csv/tsv] format mode for result display Note that csv, and tsv are deprecated - use csv2, tsv2 instead --truncateTable=[true/false] truncate table column when it exceeds length --delimiterForDSV=DELIMITER specify the delimiter for delimiter-separated values output format (default: |) --isolation=LEVEL set the transaction isolation level --nullemptystring=[true/false] set to true to get historic behavior of printing null as empty string --socketTimeOut=n socket connection timeout interval, in second. The default value is 300.
增加分区列后再insert数据显示为NULL
症状
执行如下命令:
sql
create table test_table(
col1 string,
col2 string
)
PARTITIONED BY(p1 string)
STORED AS orc tblproperties('orc.compress'='SNAPPY');
alter table test_table add partition(p1='a');
insert into test_table partition(p1='a') select col1,col2 from temp_table;
alter table test_table add columns(col3 string);
insert into test_table partition(p1='a') select col1,col2,col3 from temp_table;
这个时候select * from test_table where p1='a' 看见的列col3全为NULL
alter table test_table add partition(p1='b');
insert into test_table partition(p1='b') select col1,col2,col3 from temp_table;
select * from test_table where p1='b' 能看见col3有不为NULL的值解决方法
add column的时候加入cascade关键字即可,如下:
sql
alter table test_table add columns(col3 string) cascade;如何设置hive on spark 模式及提交任务到指定队列
解决方法
如下,在执行语句前通过下述参数设置:
sql
set hive.execution.engine = spark;
set spark.yarn.queue = testQueue;提交任务后,可在Yarn页面看到,如下任务已经提交到队列testQueue了。(说明:队列的名称区分大小写,如写成testqueue,TestQueue均无效。)
hive on spark应用如何设置spark应用的参数?
解决方法
-
Hive通过spark引擎在执行SQL语句前,可以通过set命令来设置Spark应用相关参数。
-
以下为与Spark相关的内存参数。
-
对于memoryOverhead参数,默认的单位是M,set命令中不能带有单位,否则会报错。
-
其他参数可通过同样的方式进行set。
-
参数设置只对当前session有效。
bashset spark.executor.memory = 1g; // executor内存大小 set spark.driver.memory = 1g; // driver内存大小 set spark.yarn.executor.memoryOverhead = 2048; // executor overhead 内存大小 set spark.yarn.driver.memoryOverhead = 1024; // driver overhead memory 大小 -
如何设置map和reduce个数
解决方法
-
map个数控制。
map数无法直接控制,需通过设置每个map加载数据量来控制map数(以下命令中的为默认值256M):
bashset mapreduce.input.fileinputformat.split.maxsize=*256000000*; -
reduce个数控制(以下命令中的值为默认值,默认不设置个数)
bashset mapred.reduce.tasks=-1;设置每个reduce处理的数据量(默认值为256M):
bashset hive.exec.reducers.bytes.per.reducer=*256000000*;
说明:参数建议只对单个session设置,示例中参数设置只对当前session有效。
MapReduce任务内存溢出问题处理
症状
MapReduce任务运行中出现各种内存溢出问题,例如:java heap space、out of memory以及AM日志中的Full GC等。
解决方法
-
确定内存溢出的是map阶段还是reduce阶段还是AM,报错信息中"m "为map,"r "为reduce,如下图所示为map阶段内存溢出:

-
AM则是查看AM日志中的GC打印,有Full GC则存在AM内存溢出:

-
以下为与map/reduce/AM内存相关的参数(以下值都为默认值,需根据实际情况翻倍调整):(说明:参数设置只对当前session有效。)
实例都为session级别生效,如需设置全局参数,需要把JVM最大使用内存写全。例如:AM JVM最大使用内存(可在beeline 命令行中执行**set yarn.app.mapreduce.am.command-opts;**命令获取):
bashyarn.app.mapreduce.am.command-opts=-Xmx1024m -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -verbose:gc-
map内存:
每个Map Task需要的内存量:
bashset mapreduce.map.memory.mb=*4096*;每个Map Task的JVM最大使用内存:
bashset mapreduce.map.java.opts=-Xmx*3276*M; -
reduce内存:
每个Reduce Task需要的内存量:
bashset mapreduce.reduce.memory.mb=*4096*;每个Reduce Task的JVM最大使用内存:
bashset mapreduce.reduce.java.opts=-Xmx*3276*M; -
AM内存:
AM需要的内存量:
bashset yarn.app.mapreduce.am.resource.mb=*1536*;AM的JVM最大使用内存:
bashset yarn.app.mapreduce.am.command-opts=-Xmx*1024*m;
-
动态分区方式插入数据,创建过多文件/分区
症状
动态分区插入数据,由于数据过多,创建出来的分区或文件过多,超出限制。
- 文件过多报错:total number of created files now is XXX.which exceeds 10000,Killing the job

- 创建分区过多报错:error occurred when node tried to create too many dynamic partitions

解决方法
-
创建文件过多需调整参数(以下示例为默认值,需按照实际情况进行调整,可直接在最后加几个0):参数建议只对单个session设置,示例中参数设置只对当前session有效。
bashset hive.exec.max.created.files=*100000*; -
创建分区过多需调整参数:
bashset hive.exec.max.dynamic.partitions=*1000*; set hive.exec.max.dynamic.partitions.pernode=*100*;
mapjoin相关参数
解决方法
以下参数都为默认参数,需根据现场实际情况进行修改:
-
开启mapjoin,mapjoin即在大表join小表的场景下,将小表加载到内存中,MapReduce任务只启动map读大表数据,读取时一条一条与内存中的小表对比join,比commonjoin效率高。
bashset hive.auto.convert.join=true; -
小表判定标准(默认值为25M)
调整场景:优化join执行时间,小表刚超25M一点,可调大该参数进入mapjoin:
bashset hive.mapjoin.smalltable.filesize=*25000000*; -
localtask加载小表时内存参数:
调整场景:任务报错"return code 3" ,localtask日志报错"map local work exhausted memory"。
localtask日志根据queryid在"../hive/hiveserver/localtask/$queryid.log"查看:

bash
set hive.mapred.local.mem=*1024*; (默认值1G,一般调为4096)Tez引擎和MapReduce引擎执行结果不同
症状
-
Hive on MapReduce数据比Hive on Tez数据少。
-
Hive on Tez数据比Hive on MapReduce数据少。
解决方法
-
Hive on MapReduce数据少。
由于Tez使用union all进行数据插入时会在分区目录下再建一个目录,Hive on MapReduce默认无法读取数据目录下再有目录下的数据,需要加入参数。
如只需本次查询生效则在客户端执行**set mapreduce.input.fileinputformat.input.dir.recursive=true;**开启MapReduce的递归查询模式,会递归遍历目录下的数据。
如需全局生效则在HiveServer自定义配置文件"hive-site.xml"中加入自定义参数"mapreduce.input.fileinputformat.input.dir.recursive",值为"true"。

- Hive on Tez数据少。
【2】任务运行类常见故障 案例如下:
Hive任务运行过程中失败,重试成功
症状
当hive任务在正常运行时失败,在客户端报出错误,类似的错误打印是:
bash
Error:Invalid OperationHandler:OperationHander [opType=EXECUTE_STATEMENT,getHandleIdentifier()=XXX](state=,code=0)而此任务提交到yarn上的mapreduce任务运行成功。

原因
出错的集群有两个HiveServer实例,首先查看其中一个hiveserver日志发现里面的报错与客户端中的错误一样均是Error:Invalid OperationHandler,查看另一个HiveServer发现在出错的时间段此实例有如下类似START_UP的打印,说明那段时间进程被干掉过,后来又启动成功,提交的任务本来连接的是这个hiveserver实例,这个实例被干掉后,任务进程连接到另一个健康的HiveServer上导致报错。
bash
2017-02-15 14:40:11,309 | INFO | main | STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting HiveServer2
STARTUP_MSG: host = XXX-xxx-xxx-xxx/XXX.xxx.xxx.xxx
STARTUP_MSG: args = []
STARTUP_MSG: version = 1.3.0解决方法
重新提交一次任务即可,保证HiveServer进程不会被重启。
执行select语句报错
问题
执行语句select count(*) from XXX**;**时客户端报错,Error:Error while processing statement :FAILED:Execution Error,return code 2 from ...这个报错return code2说明是在执行mapreduce任务期间报错导致任务失败。
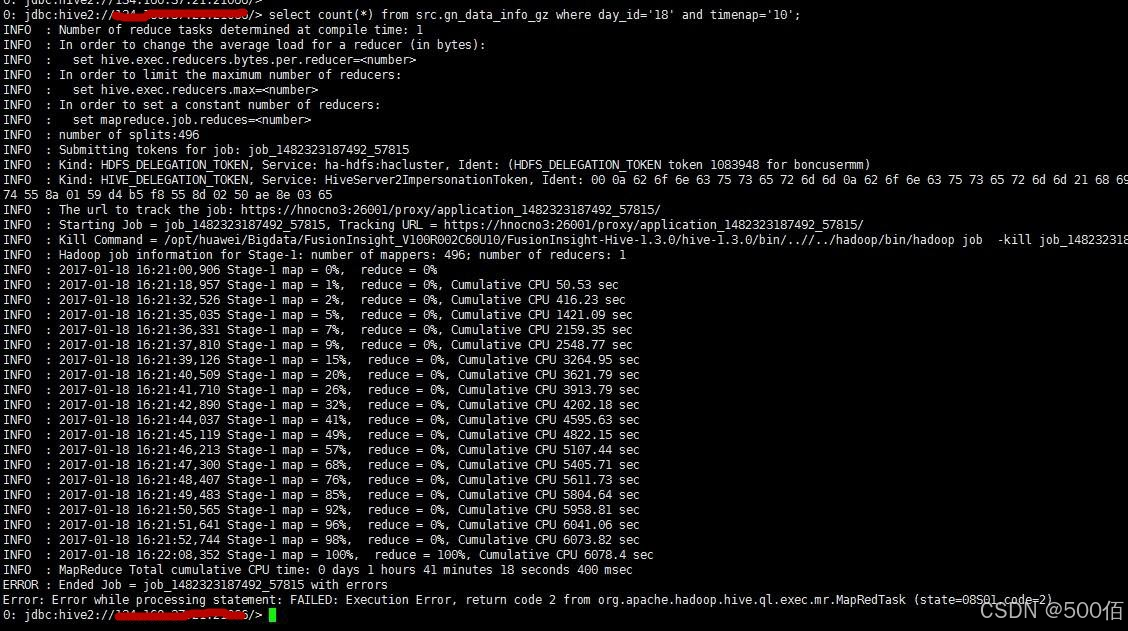
原因
- 进入Yarn原生页面查看Mapreduce任务的日志看到报错是无法识别到压缩方式导致错误,看文件后缀是gzip压缩,堆栈却报出是zlib方式。
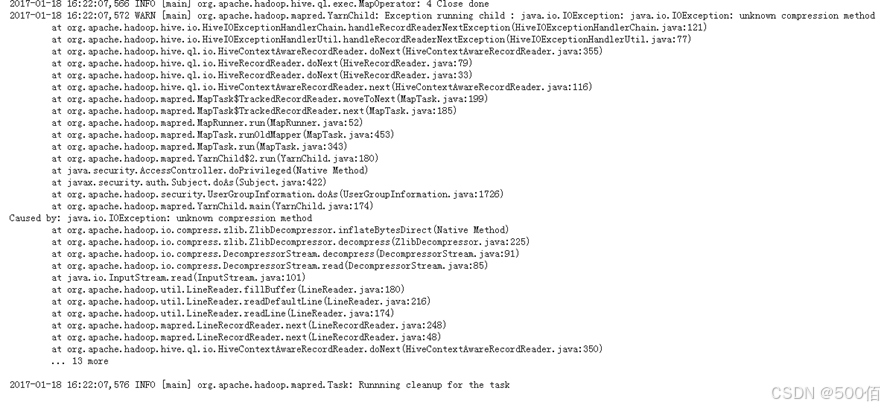
因此怀疑此语句查询的表对应的HDFS上的文件有问题,Map日志中打印出了解析的对应的文件名,将其从HDFS上下载到本地,看到是gz结尾的文件,使用tar命令解压报错,无法解压,格式不正确。使用file命令查看文件属性发现此文件来自于FAT系统的压缩而非Unix。

解决方法
将格式不正确的文件移除HDFS目录或者替换为正确的格式的文件。
drop partition操作有大量分区时操作失败
症状
执行drop partitions操作,执行异常:
bash
MetaStoreClient lost connection. Attempting to reconnect. | org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.invoke(RetryingMetaStoreClient.java:187)
org.apache.thrift.transport.TTransportException
at org.apache.thrift.transport.TIOStreamTransport.read(TIOStreamTransport.java:132)
at org.apache.thrift.transport.TTransport.readAll(TTransport.java:86)
at org.apache.thrift.transport.TSaslTransport.readLength(TSaslTransport.java:376)
at org.apache.thrift.transport.TSaslTransport.readFrame(TSaslTransport.java:453)
at org.apache.thrift.transport.TSaslTransport.read(TSaslTransport.java:435)
...查看对应MetaStore日志,有StackOverFlow异常:
bash
2017-04-22 01:00:58,834 | ERROR | pool-6-thread-208 | java.lang.StackOverflowError
at org.datanucleus.store.rdbms.sql.SQLText.toSQL(SQLText.java:330)
at org.datanucleus.store.rdbms.sql.SQLText.toSQL(SQLText.java:339)
at org.datanucleus.store.rdbms.sql.SQLText.toSQL(SQLText.java:339)
at org.datanucleus.store.rdbms.sql.SQLText.toSQL(SQLText.java:339)
at org.datanucleus.store.rdbms.sql.SQLText.toSQL(SQLText.java:339)原因
drop partition的处理逻辑是将找到所有满足条件的分区,将其拼接起来,最后统一删除。由于分区数过多,拼删元数据堆栈较深,抛出Stackoverflow。
解决方法
分批次删除分区。
localtask启动失败
症状
执行join等操作,数据量较小的时候,会启动localtask执行,执行过程会报错:
bash
jdbc:hive2://10.*.*.*:21066/> select a.name ,b.sex from student a join student1 b on (a.name = b.name);
ERROR : Execution failed with exit status: 1
ERROR : Obtaining error information
ERROR :
Task failed!
Task ID:
Stage-4
...
Error: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapredLocalTask (state=08S01,code=1)
...查看对应HiveServer日志,发现是启动localtask失败。
bash
2018-04-25 16:37:19,296 | ERROR | HiveServer2-Background-Pool: Thread-79 | Execution failed with exit status: 1 | org.apache.hadoop.hive.ql.session.SessionState$LogHelper.printError(SessionState.java:1016)
2018-04-25 16:37:19,296 | ERROR | HiveServer2-Background-Pool: Thread-79 | Obtaining error information | org.apache.hadoop.hive.ql.session.SessionState$LogHelper.printError(SessionState.java:1016)
2018-04-25 16:37:19,297 | ERROR | HiveServer2-Background-Pool: Thread-79 |
Task failed!
Task ID:
Stage-4
Logs:
| org.apache.hadoop.hive.ql.session.SessionState$LogHelper.printError(SessionState.java:1016)
2018-04-25 16:37:19,297 | ERROR | HiveServer2-Background-Pool: Thread-79 | /xx/hive/hiveserver/hive.log | org.apache.hadoop.hive.ql.session.SessionState$LogHelper.printError(SessionState.java:1016)
2018-04-25 16:37:19,297 | ERROR | HiveServer2-Background-Pool: Thread-79 | Execution failed with exit status: 1 | org.apache.hadoop.hive.ql.exec.mr.MapredLocalTask.executeInChildVM(MapredLocalTask.java:342)
2018-04-25 16:37:19,309 | ERROR | HiveServer2-Background-Pool: Thread-79 | FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapredLocalTask | org.apache.hadoop.hive.ql.session.SessionState$LogHelper.printError(SessionState.java:1016)
...
2018-04-25 16:37:36,438 | ERROR | HiveServer2-Background-Pool: Thread-88 | Error running hive query: | org.apache.hive.service.cli.operation.SQLOperation$1$1.run(SQLOperation.java:248)
org.apache.hive.service.cli.HiveSQLException: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapredLocalTask
at org.apache.hive.service.cli.operation.Operation.toSQLException(Operation.java:339)
at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:169)
at org.apache.hive.service.cli.operation.SQLOperation.access$200(SQLOperation.java:75)
at org.apache.hive.service.cli.operation.SQLOperation$1$1.run(SQLOperation.java:245)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1710)
at org.apache.hive.service.cli.operation.SQLOperation$1.run(SQLOperation.java:258)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)查看对应HiveServerr日志目录(/var/log/xx/hive/hiveserver)下,hs_err_pid_*.log,发现有内存不够的错误。
bash
# There is insufficient memory for the Java Runtime Environment to continue.
# Native memory allocation (mmap) failed to map 20776943616 bytes for committing reserved memory.
...原因
Hive在执行join的时候,数据量小时会生成MapJoin,执行MapJoin时会生成localtask任务,localtask启动的jvm内存继承了父进程的内存。
当有多个join执行的时候,启动多个localtask,如果机器内存不够,就会导致启动localtask失败。
解决方法
-
修改hive的配置"hive.auto.convert.join"为"false",保存配置并重启服务。
-
按照上述步骤执行后会对业务性能有一定的影响。如果不影响业务性能可以执行步骤 3。
-
修改Hive的"HIVE_GC_OPTS",把Xms调小,具体要根据业务评估,最小设置为"Xmx"的一半,修改完后保存配置并重启服务。
切域后Hive二次开发样例代码报错
症状
Hive的二次开发代码样例运行报No rules applied to 的错误: 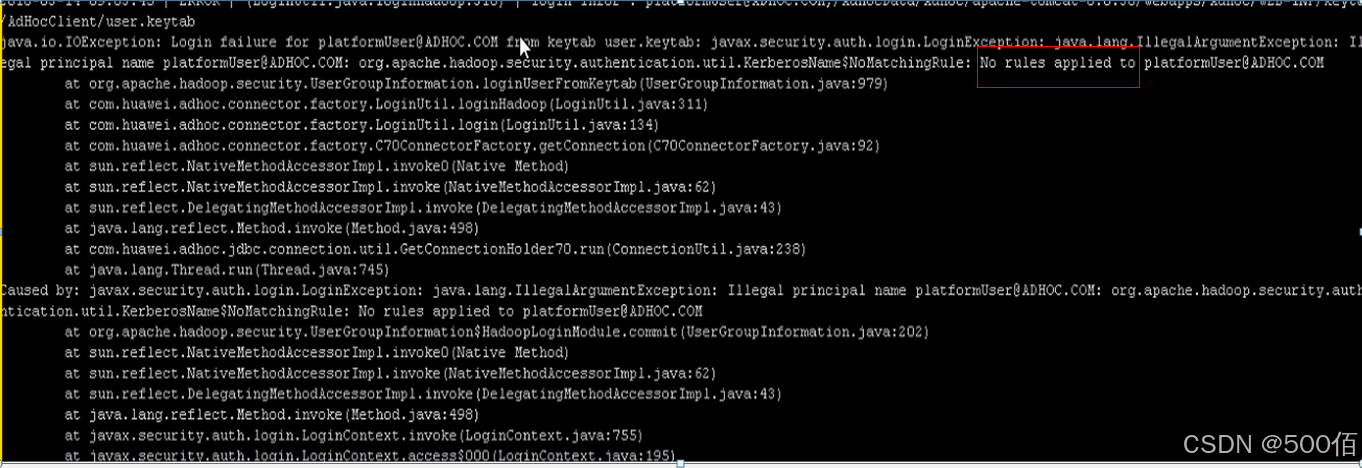
原因
-
Hive的二次开发样例代码会加载"core-site.xml",此文件默认是通过classload加载,所以使用的时候要把此配置文件放到启动程序的classpath路径下面。
-
如果修改了集群的域名,那么"core-site.xml"将发生变化,需要下载最新的"core-site.xml"并放入到打包hive二次开发样例代码进程的classpath路径下面。
解决方法
-
下载集群Hive最新的客户端,获取最新的"core-site.xml"。
-
将"core-site.xml"放入到打包hive二次开发样例代码进程的classpath路径下面。
输入文件数超出设置限制导致任务执行失败
问题
Hive执行查询操作时报Job Submission failed with exception 'java.lang.RuntimeException(input file number exceeded the limits in the conf;input file num is: 2380435,max heap memory is: 16892035072,the limit conf is: 500000/4)',此报错中具体数值根据实际情况会发生变化,具体报错信息如下:
bash
ERROR : Job Submission failed with exception 'java.lang.RuntimeException(input file numbers exceeded the limits in the conf;
input file num is: 2380435 ,
max heap memory is: 16892035072 ,
the limit conf is: 500000/4)'
java.lang.RuntimeException: input file numbers exceeded the limits in the conf;
input file num is: 2380435 ,
max heap memory is: 16892035072 ,
the limit conf is: 500000/4
at org.apache.hadoop.hive.ql.exec.mr.ExecDriver.checkFileNum(ExecDriver.java:545)
at org.apache.hadoop.hive.ql.exec.mr.ExecDriver.execute(ExecDriver.java:430)
at org.apache.hadoop.hive.ql.exec.mr.MapRedTask.execute(MapRedTask.java:137)
at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:158)
at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:101)
at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:1965)
at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:1723)
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1475)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1283)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1278)
at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:167)
at org.apache.hive.service.cli.operation.SQLOperation.access$200(SQLOperation.java:75)
at org.apache.hive.service.cli.operation.SQLOperation$1$1.run(SQLOperation.java:245)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1710)
at org.apache.hive.service.cli.operation.SQLOperation$1.run(SQLOperation.java:258)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Error: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask (state=08S01,code=1)原因
MapReduce 任务提交前对输入文件数的检查策略:在提交的MapReduce 任务中,允许的最大输入文件数和HiveServer最大堆内存的比值,例如500000/4(默认值),表示每4GB堆内存最大允许500000个输入文件。在输入的文件数超出此限制时则会发生此错误。
解决方法
-
登录集群管理页面,访问"集群 > 服务 > Hive > 配置",搜索"hive.mapreduce.input.files2memory"配置项。
-
修改"hive.mapreduce.input.files2memory"配置的值到合适值,根据实际内存和任务情况对此值进行调整。
-
保存配置并重启受影响的服务或者实例。
-
如调整后问题仍未解决,请根据业务情况调整HiveServer的GC参数至合理的值。
任务执行中报栈内存溢出导致执行任务失败
症状
Hive执行查询操作时报错Error running child : java.lang.StackOverflowError,具体报错信息如下:
bash
FATAL [main] org.apache.hadoop.mapred.YarnChild: Error running child : java.lang.StackOverflowError
at org.apache.hive.come.esotericsoftware.kryo.io.Input.readVarInt(Input.java:355)
at org.apache.hive.come.esotericsoftware.kryo.util.DefautClassResolver.readName(DefautClassResolver.java:127)
at org.apache.hive.come.esotericsoftware.kryo.util.DefautClassResolver.readClass(DefautClassResolver.java:115)
at org.apache.hive.come.esotericsoftware.kryo.Kryo.readClass(Kryo.java.656)
at org.apache.hive.come.esotericsoftware.kryo.kryo.readClassAnd0bject(Kryo.java:767)
at org.apache.hive.come.esotericsoftware.kryo.serializers.collectionSerializer.read(CollectionSerializer.java:112)
原因
java.lang.StackOverflowError这是内存溢出错误的一种,即线程栈的溢出,方法调用层次过多(比如存在无限递归调用)或线程栈太小都会导致此报错。
解决方法
通过调整MapReduce阶段的Map和Reduce子进程JVM参数中的栈内存解决此问题,主要涉及参数为"mapreduce.map.java.opts"和"mapreduce.reduce.java.opts",调整方法如下(以"mapreduce.map.java.opts"参数为例,此参数为调整map的栈内存,若需要调整reduce的栈内存,调整参数为"mapreduce.reduce.java.opts")。
-
临时增加Map内存(只针对此次beeline生效):
在beeline中执行如下命令set mapreduce.map.java.opts=-Xss8G;(具体数值请结合实际业务情况进行调整)
-
永久增加Map内存
"mapreduce.map.memory.mb"和"mapreduce.map.java.opts"的值:
-
登录 Manager页面,访问"集群 > 服务 > Hive > 配置 > 全部配置"。
-
在HiveServer自定义参数界面添加自定义参数"mapreduce.map.java.opts"及相应的值。
-
保存配置并重启受影响的服务或者实例。
修改配置后需要保存,请注意参数在HiveServer自定义参数处修改,保存重启后生效(重启期间Hive服务不可用),请注意执行时间窗口。
-
对同一张表或分区并发写数据导致任务失败
症状
Hive执行插入语句时,报错HDFS上文件或目录已存在或被清除,具体报错如下:

原因
-
根据HiveServer的审计日志,确认该任务的开始时间和结束时间。
-
在上述时间区间内,查找是否有对同一张表或分区进行插入数据的操作。
-
Hive不支持多同一张表或分区进行并发数据插入,这样会导致多个任务操作同一个数据临时目录,一个任务将另一个任务的数据移走,导致任务失败。
解决方法
修改业务逻辑,单线程插入数据到同一张表或分区。
Hive任务失败,报没有HDFS目录的权限
症状
Hive任务报错,提示执行用户没有HDFS目录权限。
bash
2019-04-09 17:49:19,845 | ERROR | HiveServer2-Background-Pool: Thread-3160445 | Job Submission failed with exception 'org.apache.hadoop.security.AccessControlException(Permission denied: user=hive_quanxian, access=READ_EXECUTE, inode="/user/hive/warehouse/bigdata.db/gd_ga_wa_swryswjl":zhongao:hive:drwx------
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkAccessAcl(FSPermissionChecker.java:426)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:329)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkSubAccess(FSPermissionChecker.java:300)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:241)
at com.hadoop.adapter.hdfs.plugin.HWAccessControlEnforce.checkPermission(HWAccessControlEnforce.java:69)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:190)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1910)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1894)
at org.apache.hadoop.hdfs.server.namenode.FSDirStatAndListingOp.getContentSummary(FSDirStatAndListingOp.java:135)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getContentSummary(FSNamesystem.java:3983)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getContentSummary(NameNodeRpcServer.java:1342)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.getContentSummary(ClientNamenodeProtocolServerSideTranslatorPB.java:925)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:616)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:973)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2260)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2256)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1781)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2254)原因
-
根据堆栈信息,可以看出在检查
"/user/hive/warehouse/bigdata.db/gd_ga_wa_swryswjl"
子目录的权限的时候失败。
bashorg.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkSubAccess(FSPermissionChecker.java:300) -
使用如下命令检查HDFS上表目录下所有文件目录的权限,发现有一个目录权限为700(只有文件属主能够访问),确认存在异常目录。
bashhadoop fs -ls /user/hive/warehouse/bigdata.db/gd_ga_wa_swryswjl/.hive-staging_hive**-*-*-******-***/tmp.-ext-10000
解决方法
-
确认该文件是否为手动异常导入,如不是数据文件或目录,删除该文件或目录。
bashhadoop fs -rm /user/hive/warehouse/bigdata.db/gd_ga_wa_swryswjl/.hive-staging_hive**-*-*-*****-***/tmp.-ext-10000 -
当无法删除时,建议修改文件或目录权限为770。
bashhadoop fs -chmod 770 /user/hive/warehouse/bigdata.db/gd_ga_wa_swryswjl/.hive-staging_hive**-*-*-******-***/tmp.-ext-10000
Metastore连接数过高导致hive任务执行慢或任务失败
症状
-
Hive执行查询操作时查询过慢或者查询失败。
-
查询管理界面连接数如下:并发连接数在1000以上。
-
查看metastore日志存在如下报错:
bashjava.sql.SQLException: Timed out waiting for a free available connection. at com.jolbox.bonecp.DefaultConnectionStrategy.getConnectionInternal(DefaultConnectionStrategy.java:88) at com.jolbox.bonecp.AbstractConnectionStrategy.getConnection(AbstractConnectionStrategy.java:90) at com.jolbox.bonecp.BoneCP.getConnection(BoneCP.java:553) at com.jolbox.bonecp.BoneCPDataSource.getConnection(BoneCPDataSource.java:131) at org.datanucleus.store.rdbms.ConnectionProviderPriorityList.getConnection(ConnectionProviderPriorityList.java:57) at org.datanucleus.store.rdbms.ConnectionFactoryImpl$ManagedConnectionImpl.getConnection(ConnectionFactoryImpl.java:418) at org.datanucleus.store.rdbms.ConnectionFactoryImpl$ManagedConnectionImpl.getXAResource(ConnectionFactoryImpl.java:378) at org.datanucleus.store.connection.ConnectionManagerImpl.allocateConnection(ConnectionManagerImpl.java:328) at org.datanucleus.store.connection.AbstractConnectionFactory.getConnection(AbstractConnectionFactory.java:94) at org.datanucleus.store.AbstractStoreManager.getConnection(AbstractStoreManager.java:430) at org.datanucleus.store.AbstractStoreManager.getConnection(AbstractStoreManager.java:396) at org.datanucleus.store.rdbms.query.SQLQuery.performExecute(SQLQuery.java:262) at org.datanucleus.store.query.Query.executeQuery(Query.java:1786) at org.datanucleus.store.query.AbstractSQLQuery.executeWithArray(AbstractSQLQuery.java:339) at org.datanucleus.store.query.Query.execute(Query.java:1654) at org.datanucleus.api.jdo.JDOQuery.execute(JDOQuery.java:221)
原因
-
metastore采用了线程池,若使用连接数达到上限,则会使新请求处于等待状态,待有空闲连接线程时才会进行连接。
-
metastore在当前版本未加入负载均衡机制,会默认连接配置文件中的第一个IP所在节点的metastore实例,在连接数到达一定数量后会导致metastore连接数负载过高。
-
当Hive分区数目>5000时,会导致Hive在获取元数据时过慢,无法快速完成任务执行释放连接。
解决方法
-
请确认是否有第三方程序直接连接metastore,例如使用vertica/kettle等第三方软件或应用侧编写的直连metastore的应用。
-
进行如下操作:
-
调整metastore的METASTORE_GC_OPTS参数值中-Xms -Xmx -Xmn为合适值。
推荐值如下(可根据以下三组推荐值进行调整):
bash-Xms4G -Xmx8G -Xmn1G -Xms8G -Xmx16G -Xmn2G -Xms16G -Xmx32G -Xmn4G -
在Hive服务参数中适当调整maxConnectionsPerPartition,默认为10,可适当调大,建议调整至25。不推荐调整至最大值。
在Hive服务参数中适当调整partitionCount的参数值,建议调整到3。
原则:partitionCount乘maxConnectionsPerPartition小于DBService最大连接数。
-
在DBService服务参数中调整dbservice.database.max.connections参数值,建议调整至800。
-
-
删除无用分区。
-
从业务侧降低metastore连接数至1000以下。
bonecp参数含义解析
参数解析
-
Hive的metastore实例与DBService连接是通过bonecp来进行管理的,有时会因为业务的原因导致连接数太多,获取连接失败,则需要调整一下。
-
partitionCount:设置分区个数。这个参数默认为1,建议5。
-
maxConnectionsPerPartition:设置每个分区含有connection最大个数。这个参数默认为10。建议调整为300。
-
-
metastore与DBservice之间可用的连接数为partitionCount与maxConnectionsPerPartition的乘积。
连接Metastore超时,导致任务失败
症状
Hive任务失败,查看日志报连接metastore超时退出。
bash
org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.invoke(RetryingMetaStoreClient.java:187)
org.apache.thrift.transport.TTransportException: java.net.SocketTimeoutException: Read timed out
at org.apache.thrift.transport.TIOStreamTransport.read(TIOStreamTransport.java:129)
at org.apache.thrift.transport.TTransport.readAll(TTransport.java:86)
at org.apache.thrift.protocol.TBinaryProtocol.readAll(TBinaryProtocol.java:429)
at org.apache.thrift.protocol.TBinaryProtocol.readI32(TBinaryProtocol.java:318)
at org.apache.thrift.protocol.TBinaryProtocol.readMessageBegin(TBinaryProtocol.java:219)
at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:77)
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.recv_get_partitions(ThriftHiveMetastore.java:2006)
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.get_partitions(ThriftHiveMetastore.java:1991)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.listPartitions(HiveMetaStoreClient.java:1172)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.invoke(RetryingMetaStoreClient.java:156)
at com.sun.proxy.$Proxy28.listPartitions(Unknown Source)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient$SynchronizedHandler.invoke(HiveMetaStoreClient.java:2107)
at com.sun.proxy.$Proxy28.listPartitions(Unknown Source)
at org.apache.hadoop.hive.ql.metadata.Hive.getAllPartitionsOf(Hive.java:2069)原因
该报错是因为HiveServer连接metastore获取元数据的时候超时,导致任务失败退出。
解决方法
-
在服务端调整hive.metastore.client.socket.timeout参数为36000。
-
在客户端的hive-site.xml文件中添加hive.metastore.client.socket.timeout参数,值为36000。
数据查询异常,部分字段为Null
症状
hive数据查询原表数据正常,从原表中查询出插入到text格式的表后,原本正常的字段内容变为了null。
原表查询结果:

插入后查询结果:
原因
-
针对textfile格式的表,单插一条数据到目标表,在hdfs上看文件内容发现,原表数据中存在换行符,导致在hdfs上存储时发生了换行,一条数据显示为多条数据。

-
textfile格式数据存储读数据是一行一行读文本,所以在hive中查询出现多行数据,字段出现乱序导致查询结果为null。
-
对比orc格式同样数据,orc将换行符以'\n'存储,查询出来时为1行数据
解决方法
调整目标表格式为不为textfile的格式,例如orc格式。
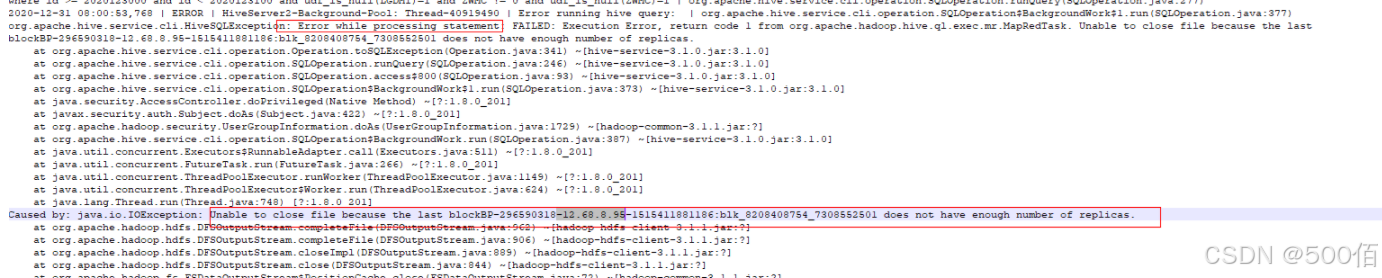
return code 1:unable to close file
症状
任务报错,unable to colse file because the lask block:blk.... does not have enough number of replicas。
原因
文件对象过多,namenode未能及时处理块上报信息。
解决方法
开启hdfs IBR特性,操作如下:
-
设置"dfs.blockreport.incremental.intervalMse"为"1000";
-
设置"dfs.namenode.file.close.num-committed-allowed"为"1";
-
设置Hiveserver重试参数"dfs.client.block.write.locateFollowingBlock.retries"为"10"。
Tez和MapReduce引擎下,Hive进行join的结果不一致
症状
执行hive-sql:SELECT * from (SELECT * from wzn) c, (SELECT * from wzn) b where c.a = b.a;
在MapReduce引擎下结果为90万,在Tez引擎下只有30万,经客户确认MapReduce引擎结果准确。
原因
通过对比两种引擎的执行计划,发现Tez使用的是是map join方式,MapReduce使用的是merge join方式。在使用Tez引擎下,将where条件中任意一张表的字段进行trim处理,结果与MapReduce引擎一致。
解决方法
-
设置表的属性:
alter table mirror_cms_epm_sc.wm_mp_day_elec_cal_20210104 set tblproperties ('bucketing_version'='2');
-
修改表:
msck repair table a;
analyze table my_table compute statistics;
-
优化参数:
set hive.compute.query.using.stats=false;
set hive.log.explain.output=false**;**
set hive.groupby.skewindata=true;
-
修改SQL语句为:
SELECT * from (SELECT * from wzn) c, (SELECT * from wzn) b where trim(c.a) = b.a.
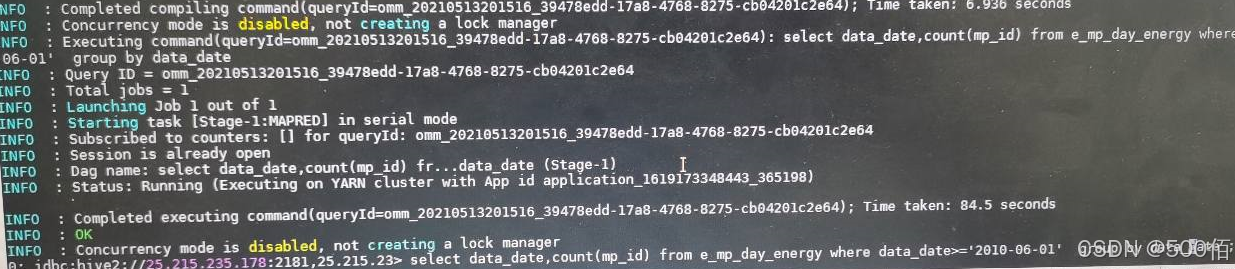
Hive表里有数据count无结果
症状
Hive表里有数据 count(*)无结果。
原因
数据量太大,客户端无法打印。
解决方法
设置"hive.log.explain.output"参数(启用后,将在log4j INFO级别和WebUI查询计划中记录EXPLAIN EXTENDED输出)。
set hive.log.explain.output=false。
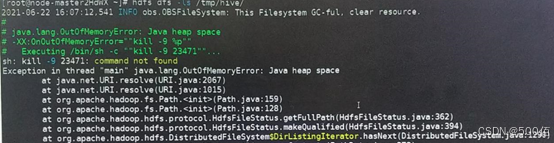
hive-sql报values太长
问题
执行hive-sql,报错code1。
原因
查看对应分区hdfs文件大小,报java heap space
修改HDFS客户端的内存大小:
进入/opt/client/HDFS/component_env,添加export HADOOP_HEAPSIZE=10240M、export GC_OPTS_HDFS =-Xmx10240M,然后执行source /opt/client/HDFS/component_env,再次执行时tmp临时目录已被清理。
以上可以确认,执行的sql返回的数据较大,导致临时文件撑满,导致执行失败。减少分区后继续执行,报错元数据表异常。
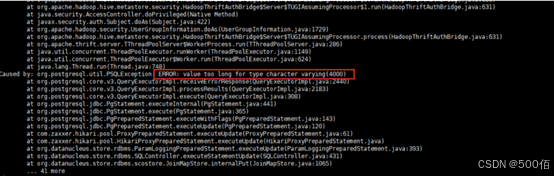
解决方法
以上日志可以明确,是由于客户执行的sql,在 Hive 在元数据库PARTITION_PARAMS中对每张表所有字段长度的累加总长度有限制,如图为 varchar(4000)。而客户加工的表实际存储字段总长大于定义。
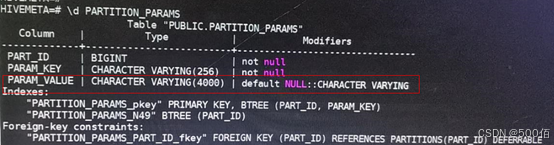
修改元数据库中的字段大小:
bash
alter table "PARTITION_PARAMS" alter column "PARAM_VALUE" type CHARACTER VARYING(8000);执行hive-sql插入数据重复
症状
使用insert overwrite后,数据偶发性出现重复,重复执行后数据恢复。
原因
-
查看hive-sql的来源sql,排查逻辑正确。
-
查看具体的hive-sql任务,在tez上找到当前任务,发现在执行map 1阶段一个task执行失败了一次。排查NN日志显示,hdfs在当前map阶段前后有两次写入hdfs文件记录,所以最终导入数据重复写入。
-
结论:tez抢占导致task被杀死,task在杀死前已成功的写结果文件到hdfs。task被杀死后导致重试,重复写相同的文件到hdfs。最终导致数据重复了。
解决方法
在mrs的hive服务中,配置tez参数tez.am.preemption.percentage =0 , 关闭抢占。
tez引擎写入的数据,切换mr引擎后查询不出来
症状
tez引擎插入数据后,mr引擎查询无数据。
原因
tez执行Union all语句时,生成的输出文件存在hive_union_subdir目录,mr读取时只读取表(分区)下文件不读取目录,所以查询不到。
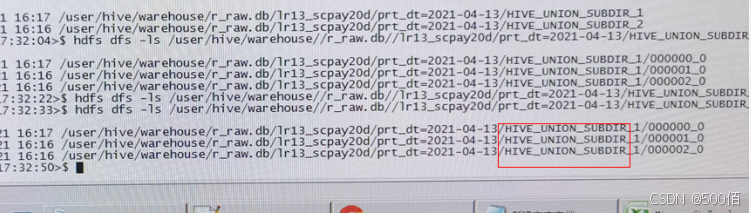
解决方法
可开启参数"set mapreduce.input.fileinputformat.input.dir.recursive=true",开启union优化,决定是否读取目录下数据。
【3】SQL使用类常见故障 如下(点击跳转):Hive常见故障多案例FAQ宝典 --项目总结(宝典二)
最后
此篇总结hive常见故障案例处理方案 结合自身经历 总结不易 +关注 +收藏 欢迎留言
SQL使用类常见故障 详见(点击跳转): Hive常见故障多案例FAQ宝典 --项目总结(宝典二)
谢谢大家
@500佰