#作者:邓伟
文章目录
一、问题简述
在实际部署过程中,存在Pod调度不均衡的问题:
- 某一业务场景下,集群共部署约40个服务,每个服务仅包含1个副本,理论上应均衡分布在7台节点上,但实际调度结果显示,Pod大量集中在其中3台节点上,其余4台节点未分配到任何相关Pod。
- 另一个业务场景中,部署约25个服务,单个服务副本数从个位数到上百不等,整体规模达到1000+Pod。按规划可调度至147台节点,但实际仅调度到114台,仍有33台节点未被覆盖,存在明显的节点资源利用不均现象。
二、问题分析
此问题属于正常现象
在Kubernetes调度器(Scheduler)的Pod调度流程中,节点评分阶段是决定Pod最终调度目标的核心决策环节。该阶段通过PreScore(预评分)、Score(评分)和NormalizeScore(分数归一化)三个子阶段完成对候选节点的系统化评估。哪个节点获取的分数较高(由多个一样高,则从里面随机选择一个节点),pod就绑定到这个节点。而默认的配置里打分阶段开启的插件为:NodeAffinity、NodeResourcesFit、VolumeBinding、PodTopologySpread、InterPodAffinity、NodeResourcesBalancedAllocation、ImageLocality、TaintToleration。
原理分析
打分原理
1、ImageLocality(镜像本地性)
打分依据:是否本地已有镜像
已存在目标镜像的节点在调度评分时可能获得更高得分,从而优先被选为目标节点。
如果镜像较大(>1GB),得分最高100,调度器会偏好这几台有镜像的节点。
推论
使用了相同镜像部署多个Deployment,这种场景下只要某些节点有缓存镜像,那ImageLocality打分就会把这些节点推向前排。
2、NodeResourcesBalancedAllocation(资源分配均衡)
打分依据:资源使用均衡性(如CPU和内存使用率标准差)
若某节点上CPU与内存的使用率较均衡(例如都为60%),其得分会高;
若某节点上CPU用了80%、内存用了20%,标准差较大,得分反而低。
推论
若已有镜像的节点同时资源使用率也更均衡,它会在这个策略中再次得分。
3、NodeResourcesFit(资源充足优先)
打分依据:剩余资源多则得分高
如果某些节点CPU使用率偏高但仍有较多资源未分配,它依然能得高分;
对于资源紧张的节点,该策略会压低其得分,避免继续调度。
推论
尽管最终在这7台节点上,Pod分布后整体资源占用趋于均衡,但在调度瞬时阶段,由于调度器是基于节点的实时资源使用情况进行评估,曾缓存目标镜像的节点可能表现出更高的资源可用性(如CPU/内存剩余量较大、镜像无需拉取等),从而在调度得分中占优。
源码流程参考
1、k8s资源分配
计算节点可用资源:
kubernetes-1.23.6\pkg\scheduler\framework\plugins\noderesources\resource_allocation.go: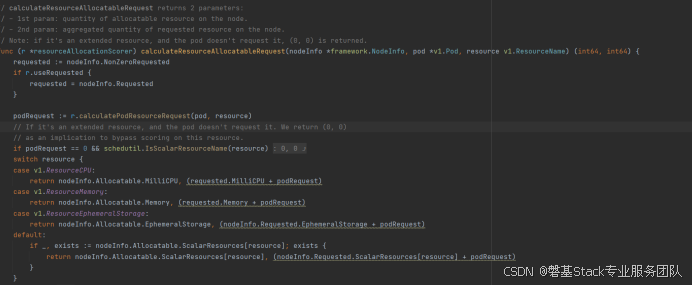
获取节点内存和已申请资源,之后进行排序:
kubernetes-1.23.6\pkg\scheduler\framework\plugins\noderesources\resource_allocation.go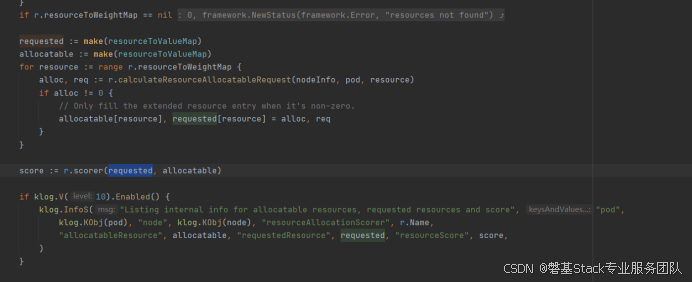
2、k8s调度(打分)
Scorer打分配置如下:
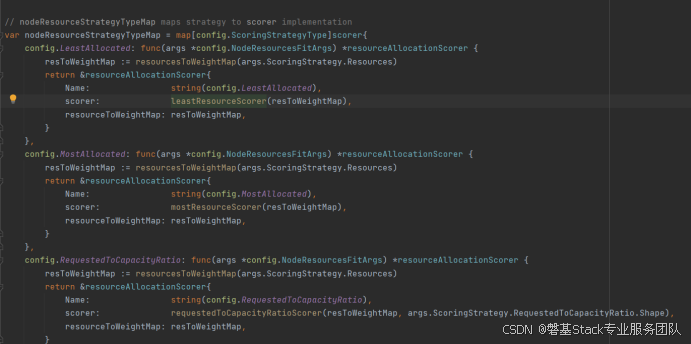
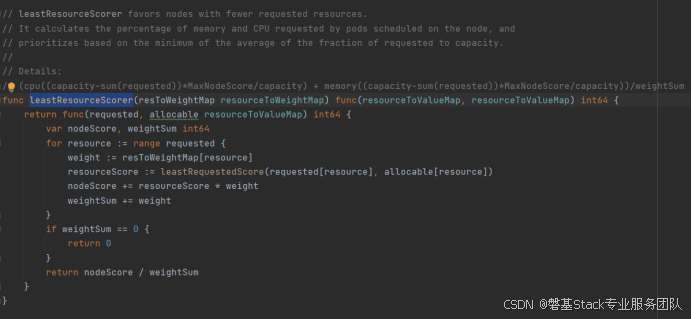
LeaseResourceScorer代码如下:
计算公式:
三、优化方案
简述步骤
1、为预部署pod的node主机打相应标签
2、业务pod部署的yaml文件添加nodeSelector和topologySpreadConstraints配置
3、重新加载yaml,k8s将会重新调度
步骤详解
第一步:给你选中的7台机器打标签
kubectllabelnodesnode-1dedicated=ingress-group-a
kubectllabelnodesnode-2dedicated=ingress-group-a
...
kubectllabelnodesnode-7dedicated=ingress-group-a
你可以用以下命令确认:
kubectlgetnodes--show-labels
第二步:为这40个Deployment的Pod模板添加上面两段配置
nodeAffinity确保只调度到那7台机器上
topologySpreadConstraints确保在这7台机器之间尽可能均衡
(配置参考)
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
-matchExpressions:
-key:dedicated
operator:In
values:
-ingress-group-a#你定义的7台Node上的标签值
topologySpreadConstraints:
-maxSkew:1
topologyKey:kubernetes.io/hostname
whenUnsatisfiable:ScheduleAnyway
labelSelector:
matchLabels:
app:web
整体效果:
Pod只会被调度到相应标签7台机器上
每台机器上的app=web标签的pod数量差异不会超过1
总体保持40个Pod,约等于每台机器5~6个
四、总结
Kubernetes的调度决策基于"多因素打分+总分最大化"的策略,并非简单的"平均调度"。
调度器并不保证所有Pod在各节点之间实现完全的负载均衡,而是尽可能在调度同一个Deployment的多个副本时实现节点间的相对均衡分布。
在仅设置了nodeSelector,未配置Pod亲和性(Affinity)或反亲和性(AntiAffinity)等策略的情况下,调度器的选择空间较大,最终的调度结果更容易受到镜像本地性、资源使用、调度打分策略等多重因素的影响,而不是简单的平均分布。