MVCC,全称Multi-Version Concurrency Control,即多版本并发控制
1、Innodb引擎的mvcc
1.1、数据页内和事务相关的隐藏字段
| 字段名 | 含义 |
|---|---|
| DB_ROW_ID | 6字节,插入操作自增ID标识,如果有聚集索引,索引项则包括这个ID |
| DB_TRX_ID | 6字节,上次执行的插入或更新事务,也可理解为本行记录被哪个事务操作生成 |
| DB_ROLL_PTR | 7字节,回滚指针,指向旧版本的数据位于回滚段中的位置,即前一个版本在UNDO Log中的位置 |
| DB_MIX_ID |
最新的数据存储在数据页面中,其他旧版本存储在回滚段(undo segment),每个回滚段记录1024个undo log segment,mysql5.5开始默认128个回滚段,在线并发事务支持到128*1024个。
5.5到5.7参数innodb_undo_logs设置回滚段的数量
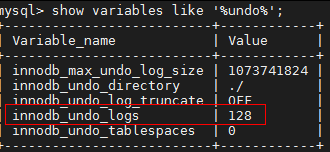
8.0的版本已经取消innodb_undo_logs这个参数,改成了innodb_rollback_segments
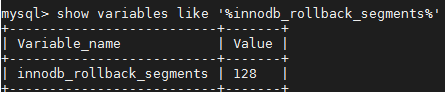
1.2、数据结构(以mysql5.7为例)
mvcc类
mvcc类管理"read view"对象,有创建、关闭等管理功能
mvcc代码节选
cpp
class MVCC {
void view_open(ReadView*& view,trx_t* trx);//创建一个read view
void view_close(ReadView*& view,bool own_mutex);//关闭一个read view
void view_release(ReadView*& view);//是否一个read view
void clone_oldest_view(ReadView* view);
ulint size() const;//返回活动的快照数
static bool is_view_active(ReadView* view)// 若快照活动且有效返回true
{
ut_a(view != reinterpret_cast<ReadView*>(0x1));
return(view != NULL && !(intptr_t(view) & 0x1));
}
static void set_view_creator_trx_id(ReadView* view,trx_id_t id);
...
private:
typedef UT_LIST_BASE_NODE_T(ReadView) view_list_t;
view_list_t m_free;//释放了的read view列表,可重用
view_list_t m_views;
};Read View快照
Read View实质是mvcc技术中的快照,从代码里面可以关注两个重点,一是快照的左右边界,二是如何判断元组的可见性。
ReadView代码节选
cpp
class ReadView{//可以简要理解成活动事务的事务id的范围,一个事务id的区间
class ids_t{...};
public:
...
bool changes_visible( //元组可见性判断
trx_id_t id, const table_name_t& name) const MY_ATTRIBUTE((warn_unused_result)) {
ut_ad(id>0);
if(id<m_up_limit_id || id == m_creator_trx_id) {
//小于快照的最小边界,则可见。表示快照之前发生的事务
return(true);
}
check_trx_id_sanity(id,name);
//检查事务id的合法性,表明m_up_limit_id < trx_sys->max_trx_id
if (id >=m_low_limit_id){
//大于右边界不可见,快照之后发生的事务
return(false);
}else if (m_ids.empty()){
//生成快照时正发生读写操作的事务集合,如为空,表示不存在读写事务,所以可见
return(true);
}
const ids_t::value_type* p = m_ids.data();
//正发生读写操作的事务集合,每个快照都有一个其自己对应的这样一个状态集
return(!std::binary_search(p,p+m_ids.size(),id));
//生成快照时正发生读写操作的事务集合中不包括id指定的事务,则可见;包括则不可见。因为在创建快照时读写集合中包括某事务id表明这个id对应的事务正在运行中,没有提交,所以不可见。这里实现的正式已提交读。
}
...
private:
...
//快照有左右边界,左边界是最小值,右边界是最大值
trx_id_t m_low_limit_id;//右边界
trx_id_t m_up_limit_id;//左边界,小于此值表示事务发生更早
trx_id_t m_creator_trx_id;//正在创建事务的事务id
ids_t m_ids;//快照创建时,处于活动即尚未完成的读写事务的集合
trx_id_t m_low_limit_no;//小于该值,如果也不被其它快照需要将被purge线程回收
}1.3、事务与快照
事务结构体定义节选
cpp
struct trx_t{...
ReadView* read_view;
...}可重复读:事务块内的所有的select操作都要使用同一个快照,在第一个select操作时建立。
已提交读:事务块内的所有的select操作分别创建自己的快照,因此每次读都不同,后面select操作的读就可以读到本次读之前已提交的数据。
1.4、可见性判断
看一段判断元组可见性的代码示例
函数lock_clust_rec_cons_read_sees节选
cpp
//在一个一致性读时,检查记录是否可见
bool lock_clust_rec_cons_read_sees(const rec_t* rec,dict_index_t* index,const ulint* offsets,ReadView* view)//在指定的快照下,查看索引index上的rec记录是否可见
{...
if (srv_read_only_mode || dict_table_is_temporary(index->table)){
//临时表属于某个会话,不能被其他会话操作,因而不存在不一致的问题
ut_ad(view == 0 || dict_table_is_temporary(index->table));
return(true);
}
trx_id_t trx_id = row_get_rec_trx_id(rec,index,offsets);
//获取索引上的记录的事务ID,把此事务ID放到view快照内检查是否可见
return(view->changes_visible(trx_id,index->table->name));
}1.5、多版本实现
多版本结构
1.1提过DB_ROLL_PTR用来记载本记录的前一个版本在UNDO日志中的位置,mysql使用row_get_rec_roll_ptr()函数获取DB_ROLL_PTR的值。
DB_ROLL_PTR 数据结构
| 位置 | 55 | 54~48 | 47~16 | 15~0 |
|---|---|---|---|---|
| 长度bit | 1 | 7 | 32 | 16 |
| 含义 | 操作类型 | 回滚段的ID | UNDO日志页号 | 在UNDO日志页面上的偏移 |
| 可能的值 | 1 INSERT | |||
| 0 UPDATE |
多版本的增删改查
插入调用trx_undo_page_report_insert()函数把插入到索引上的记录的相关信息暂存回滚段(有聚集索引时,只存主键信息)
删除调用trx_undo_page_report_modify(),在undo日志中保存删除标志,用宏TRX_UNDO_DEL_MARK_REC表示
更新调用trx_undo_page_report_modify(),把旧值存入undo日志,同一条记录多次更新时,每次都会存入旧值,DB_ROLL_PTR指向更旧的版本,所有版本构成一个链表。
以上的三个动作可以视为逻辑上多版本的生成,之后mysql会调用trx_undof_page_add_undo_rec_log()函数把相关信息记录到undo日志上完成物理记录。
查找:
未提交读隔离级别,不去找旧版本,在索引上读到的记录直接使用
其它隔离级别,调用row_vers_build_for_consistent_read()函数,通过DB_TRX_ID由changes_visible()判断可见性,通过DB_ROLL_PTR在undo回滚段查找历史版本多版本清理
由purge线程调用trx_purge()函数完成,purge线程会先克隆一个最老的活跃快照(trx_sys->mvcc->clone_oldest_view()),所有在此快照之前提交的事务的数据版本可以被清理。
1.6、一致性读和半一致性读
一致性读
一致性读就是通过快照实现的,这里可以参照1.3。
可重复读隔离级别:一致性读对整个事务块有效
已提交读隔离级别:一致性读对单个语句有效
半一致性读
在已提交读隔离级别的更新操作时会触发半一致性读的特性,更新时允许读到元组,然后交给Mysql Server层判断是否满足where条件,满足再让Innodb层去加锁,避免了先加锁后释放,提升了并发度。
cpp
ha::innobase::try_semi_consistent_read(bool yes)//决定是否可以进行半一致性读
{...
if(yes //表扫描或索引扫描
&& (srv_locks_unsafe_for_binlog
|| m_prebuilt->trx->isolation_level <= TRX_ISO_READ_COMMITTED)){
//隔离级别小于等于已提交读,才可进行半一致性读
m_prebuilt->row_read_type = ROW_READ_TRY_SEMI_CONSISTENT;
}else{ //非表扫描或索引扫描时yes的值为false,例如全文索引的情况
m_prebuilt->row_read_type = ROW_READ_WITH_LOCKS;
}
}2、wiredtiger引擎的mvcc
2.1、WT 如何实现事务
知道了基本的事务概念和 ACID 后,来看看 WT 引擎是怎么来实现事务和 ACID。要了解实现先要知道它的事务的构造和使用相关的技术,WT 在实现事务的时使用主要是使用了三个技术:
snapshot(事务快照)
MVCC(多版本并发控制)
redo log(重做日志,数据持久化与mvcc无关)为了实现这三个技术,它还定义了一个基于这三个技术的事务对象和全局事务管理器。事务对象描述如下
cpp
wt_transaction{
transaction_id: 本次事务的全局唯一的ID,用于标示事务修改数据的版本号
snapshot_object: 当前事务开始或者操作时刻其他正在执行且并未提交的事务集合,用于事务隔离
operation_array: 本次事务中已执行的操作列表,用于事务回滚。
redo_log_buf: 操作日志缓冲区。用于事务提交后的持久化
State: 事务当前状态
}WT 的多版本并发控制
WT 中的 MVCC 是基于 key/value 中 value 值的链表,这个链表单元中存储有当先版本操作的事务 ID 和操作修改后的值。描述如下:
cpp
wt_mvcc{
transaction_id: 本次修改事务的ID
value: 本次修改后的值
}WT 中的数据修改都是在这个链表中进行 append 操作,每次对值做修改都是 append 到链表头上,每次读取值的时候读是从链表头根据值对应的修改事务 transaction_id 和本次读事务的 snapshot 来判断是否可读,如果不可读,向链表尾方向移动,直到找到读事务能读的数据版本。样例如下:
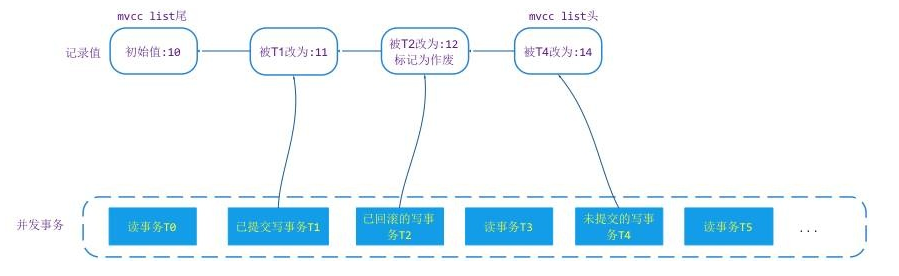
上图中,事务 T0 发生的时刻最早,T5 发生的时刻最晚。T1/T2/T4 是对记录做了修改。那么在 MVCC list 当中就会增加 3 个版本的数据,分别是 11/12/14。如果事务都是基于 snapshot 级别的隔离,T0 只能看到 T0 之前提交的值 10,读事务 T3 访问记录时它能看到的值是 11,T5 读事务在访问记录时,由于 T4 未提交,它也只能看到 11 这个版本的值。这就是 WT 的 MVCC 基本原理。
WT 事务 snapshot
上面多次提及事务的 snapshot,那到底什么是事务的 snapshot 呢?其实就是事务开始或者进行操作之前对整个 WT 引擎内部正在执行或者将要执行的事务进行一次快照,保存当时整个引擎所有事务的状态,确定哪些事务是对自己见的,哪些事务都自己是不可见。说白了就是一些列事务 ID 区间。WT 引擎整个事务并发区间示意图如下:

图2
WT 引擎中的 snapshot_oject 是有一个最小执行事务 snap_min、一个最大事务 snap max 和一个处于 snap_min, snap_max 区间之中所有正在执行的写事务序列组成。如果上图在 T6 时刻对系统中的事务做一次 snapshot,那么产生的
cpp
snapshot_object = {
snap_min=T1,
snap_max=T5,
snap_array={T1, T4, T5},
};T6 能访问的事务修改有两个区间:所有小于 T1 事务的修改 0, T1) 和 \[snap_min, snap_max 区间已经提交的事务 T2 的修改。换句话说,凡是出现在 snap_array 中或者事务 ID 大于 snap_max 的事务的修改对事务 T6 是不可见的。如果 T1 在建立 snapshot 之后提交了,T6 也是不能访问到 T1 的修改。这个就是 snapshot 方式隔离的基本原理。
全局事务管理器
cpp
wt_txn_global{
current_id: 全局写事务ID产生种子,一直递增
oldest_id: 系统中最早产生且还在执行的写事务ID
transaction_array: 系统事务对象数组,保存系统中所有的事务对象
scan_count: 正在扫描transaction_array数组的线程事务数,用于建立snapshot过程的无锁并发
}transaction_array 保存的是图 2 正在执行事务的区间的事务对象序列。在建立 snapshot 时,会对整个 transaction_array 做扫描,确定 snap_min/snap_max/snap_array 这三个参数和更新 oldest_id,在扫描的过程中,凡是 transaction_id 不等于 WT_TNX_NONE 都认为是在执行中且有修改操作的事务,直接加入到 snap_array 当中。整个过程是一个无锁操作过程,这个过程如下:
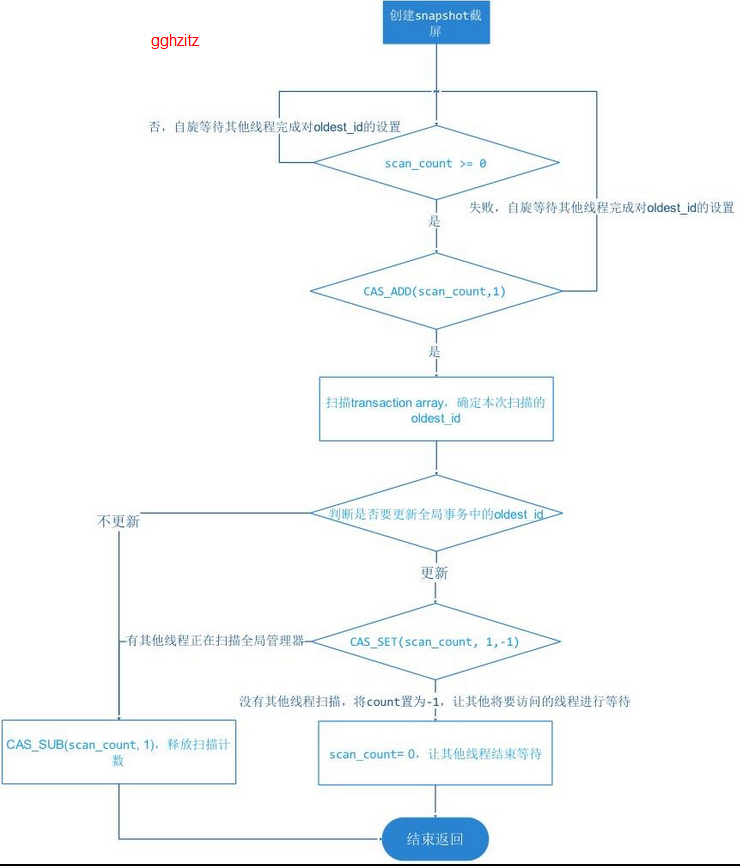
创建 snapshot 快照的过程在 WT 引擎内部是非常频繁,尤其是在大量自动提交型的短事务执行的情况下,由创建 snapshot 动作引起的 CPU 竞争是非常大的开销,所以这里 WT 并没有使用 spin lock,而是采用了上图的一个无锁并发设计,这种设计遵循了我们开始说的并发设计原则。
事务 ID
从 WT 引擎创建事务 snapshot 的过程中,现在可以确定,snapshot 的对象是有写操作的事务,纯读事务是不会被 snapshot 的,因为 snapshot 的目的是隔离 MVCC list 中的记录,通过 MVCC 中 value 的事务 ID 与读事务的 snapshot 进行版本读取,与读事务本身的 ID 是没有关系。
在 WT 引擎中,开启事务时,引擎会将一个 WT_TNX_NONE(= 0) 的事务 ID 设置给开启的事务,当它第一次对事务进行写时,会在数据修改前通过全局事务管理器中的 current_id 来分配一个全局唯一的事务 ID。这个过程也是通过 CPU 的 CAS_ADD 原子操作完成的无锁过程。
2.2、WT 的事务过程
一般事务是两个阶段:事务执行和事务提交。在事务执行前,我们需要先创建事务对象并开启它,然后才开始执行,如果执行遇到冲突和或者执行失败,我们需要回滚事务(rollback)。如果执行都正常完成,最后只需要提交(commit)它即可。从上面的描述可以知道事务过程有:创建开启、执行、提交和回滚。从这几个过程中来分析 WT 是怎么实现这几个过程的。
事务开启
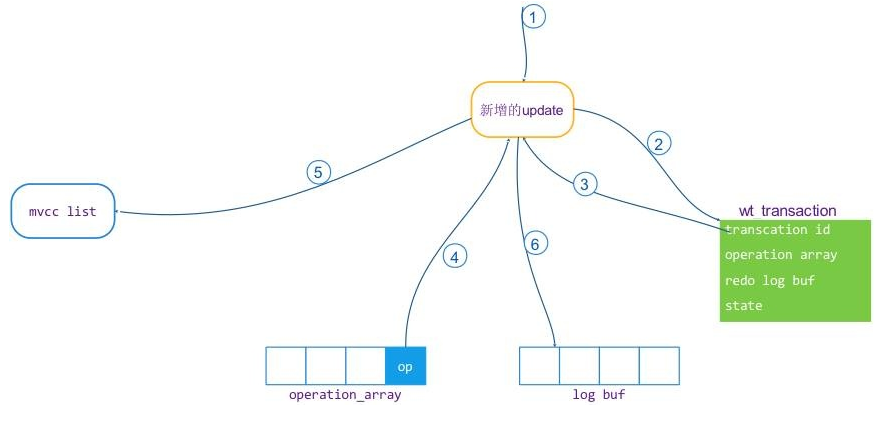
事务在执行阶段,如果是读操作,不做任何记录,因为读操作不需要回滚和提交。如果是写操作,WT 会对每个写操作做详细的记录。在上面介绍的事务对象(wt_transaction)中有两个成员,一个是操作 operation_array,一个是 redo_log_buf。这两个成员是来记录修改操作的详细信息,在 operation_array 的数组单元中,包含了一个指向 MVCC list 对应修改版本值的指针。详细的更新操作流程如下:
创建一个 MVCC list 中的值单元对象(update)
根据事务对象的 transaction id 和事务状态判断是否为本次事务创建了写的事务 ID,如果没有,为本次事务分配一个事务 ID,并将事务状态设成 HAS_TXN_ID 状态。
将本次事务的 ID 设置到 update 单元中作为 MVCC 版本号。
创建一个 operation 对象,并将这个对象的值指针指向 update,并将这个 operation 加入到本次事务对象的 operation_array。
将 update 单元加入到 MVCC list 的链表头上。
写入一条 redo log 到本次事务对象的 redo_log_buf 当中。示意图如下:
事务提交
WT 引擎对事务的提交过程比较简单,先将要提交的事务对象中的 redo_log_buf 中的数据写入到 redo log file(重做日志文件)中,并将 redo log file 持久化到磁盘上。清除提交事务对象的 snapshot object,再将提交的事务对象中的 transaction_id 设置为 WT_TNX_NONE,保证其他事务在创建系统事务 snapshot 时本次事务的状态是已提交的状态。
事务回滚
WT 引擎对事务的回滚过程也比较简单,先遍历整个operation_array,对每个数组单元对应 update 的事务 id 设置以为一个 WT_TXN_ABORTED(= uint64_max),标示 MVCC 对应的修改单元值被回滚,在其他读事务进行 MVCC 读操作的时候,跳过这个放弃的值即可。整个过程是一个无锁操作,高效、简洁。
2.3、WT 的事务隔离
传统的数据库事务隔离分为:
Read-Uncommited(未提交读)
Read-Commited(提交读)
Repeatable-Read(可重复读)
Serializable(串行化)WT 引擎并没有按照传统的事务隔离实现这四个等级,而是基于 snapshot 的特点实现了自己的 Read-Uncommited、Read-Commited 和一种叫做 snapshot-Isolation(快照隔离)的事务隔离方式。
在 WT 中不管是选用的是那种事务隔离方式,它都是基于系统中执行事务的快照来实现的。那来看看 WT 是怎么实现上面三种方式?
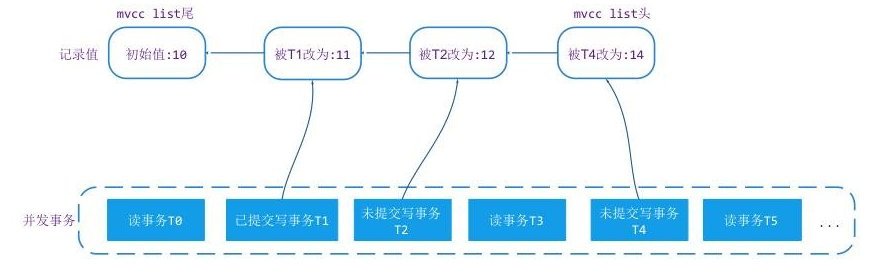
图5
Read-uncommited
Read-Uncommited(未提交读)隔离方式的事务在读取数据时总是读取到系统中最新的修改,哪怕是这个修改事务还没有提交一样读取,这其实就是一种脏读。WT 引擎在实现这个隔方式时,就是将事务对象中的 snap_object.snap_array 置为空即可,在读取 MVCC list 中的版本值时,总是读取到 MVCC list 链表头上的第一个版本数据。
举例说明,在图 5 中,如果 T0/T3/T5 的事务隔离级别设置成 Read-uncommited 的话,T1/T3/T5 在 T5 时刻之后读取系统的值时,读取到的都是 14。一般数据库不会设置成这种隔离方式,它违反了事务的 ACID 特性。可能在一些注重性能且对脏读不敏感的场景会采用,例如网页 cache。
Read-Commited
Read-Commited(提交读)隔离方式的事务在读取数据时总是读取到系统中最新提交的数据修改,这个修改事务一定是提交状态。这种隔离级别可能在一个长事务多次读取一个值的时候前后读到的值可能不一样,这就是经常提到的"幻象读"。在 WT 引擎实现 read-commited 隔离方式就是事务在执行每个操作前都对系统中的事务做一次快照,然后在这个快照上做读写。
还是来看图 5,T5 事务在 T4 事务提交之前它进行读取前做事务
cpp
snapshot={
snap_min=T2,
snap_max=T4,
snap_array={T2,T4},
};在读取 MVCC list 时,12 和 14 修改对应的事务 T2/T4 都出现在 snap_array 中,只能再向前读取 11,11 是 T1 的修改,而且 T1 没有出现在 snap_array,说明 T1 已经提交,那么就返回 11 这个值给 T5。
之后事务 T2 提交,T5 在它提交之后再次读取这个值,会再做一次
cpp
snapshot={
snap_min=T4,
snap_max=T4,
snap_array={T4},
},这时在读取 MVCC list 中的版本时,就会读取到最新的提交修改 12。
Snapshot-Isolation
Snapshot-Isolation(快照隔离)隔离方式是读事务开始时看到的最后提交的值版本修改,这个值在整个读事务执行过程只会看到这个版本,不管这个值在这个读事务执行过程被其他事务修改了几次,这种隔离方式不会出现"幻象读"。WT 在实现这个隔离方式很简单,在事务开始时对系统中正在执行的事务做一个 snapshot,这个 snapshot 一直沿用到事务提交或者回滚。还是来看图 5, T5 事务在开始时,对系统中的执行的写事务做
cpp
snapshot={
snap_min=T2,
snap_max=T4,
snap_array={T2,T4}
},在他读取值时读取到的是 11。即使是 T2 完成了提交,但 T5 的 snapshot 执行过程不会更新,T5 读取到的依然是 11
这种隔离方式的写比较特殊,就是如果有对事务看不见的数据修改,事务尝试修改这个数据时会失败回滚,这样做的目的是防止忽略不可见的数据修改
通过上面对三种事务隔离方式的分析,WT 并没有使用传统的事务独占锁和共享访问锁来保证事务隔离,而是通过对系统中写事务的 snapshot 来实现。这样做的目的是在保证事务隔离的情况下又能提高系统事务并发的能力