1. mcp server开发(通义灵码+typescript-sdk)
1.1. 通义灵码插件生成 mcp server 程序
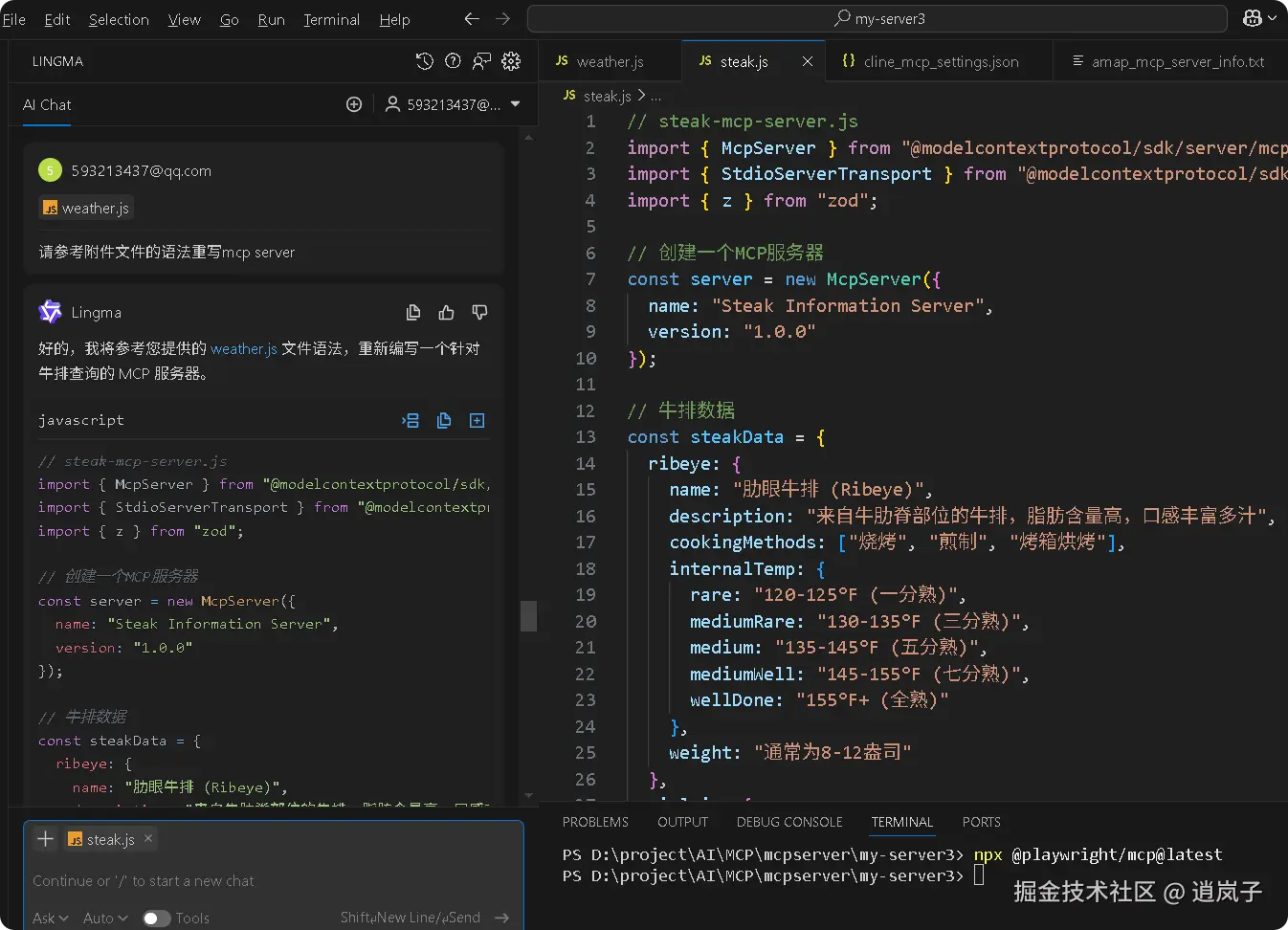
使用nodejs开发一个MCP服邻器,当用户问大模型的提示词中有提到牛排相关的问题时,大模型会调用MCP服务,并返回牛排数据
javascript
// steak-mcp-server.js
import { McpServer } from "@modelcontextprotocol/sdk/server/mcp.js";
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
import { z } from "zod";
// 创建一个MCP服务器
const server = new McpServer({
name: "Steak Information Server",
version: "1.0.0"
});
// 牛排数据
const steakData = {
ribeye: {
name: "肋眼牛排 (Ribeye)",
description: "来自牛肋脊部位的牛排,脂肪含量高,口感丰富多汁",
cookingMethods: ["烧烤", "煎制", "烤箱烘烤"],
internalTemp: {
rare: "120-125°F (一分熟)",
mediumRare: "130-135°F (三分熟)",
medium: "135-145°F (五分熟)",
mediumWell: "145-155°F (七分熟)",
wellDone: "155°F+ (全熟)"
},
weight: "通常为8-12盎司"
},
sirloin: {
name: "西冷牛排 (Sirloin)",
description: "来自牛后腰部位,瘦肉较多,口感有嚼劲",
cookingMethods: ["烧烤", "煎制", "烤箱烘烤"],
internalTemp: {
rare: "120-125°F (一分熟)",
mediumRare: "130-135°F (三分熟)",
medium: "135-145°F (五分熟)",
mediumWell: "145-155°F (七分熟)",
wellDone: "155°F+ (全熟)"
},
weight: "通常为6-10盎司"
},
filetMignon: {
name: "菲力牛排 (Filet Mignon)",
description: "来自牛里脊部位,是最嫩的牛排,脂肪含量低",
cookingMethods: ["煎制", "烧烤", "烤箱烘烤"],
internalTemp: {
rare: "120-125°F (一分熟)",
mediumRare: "130-135°F (三分熟)",
medium: "135-145°F (五分熟)",
mediumWell: "145-155°F (七分熟)",
wellDone: "155°F+ (全熟)"
},
weight: "通常为6-8盎司"
},
tBone: {
name: "T骨牛排 (T-Bone)",
description: "带有T字形骨头,一边是菲力,一边是纽约客牛排",
cookingMethods: ["烧烤", "煎制"],
internalTemp: {
rare: "120-125°F (一分熟)",
mediumRare: "130-135°F (三分熟)",
medium: "135-145°F (五分熟)",
mediumWell: "145-155°F (七分熟)",
wellDone: "155°F+ (全熟)"
},
weight: "通常为10-16盎司"
}
};
// 定义获取牛排信息的工具
server.tool("get_steak_info",
{
steakType: z.enum(["ribeye", "sirloin", "filetMignon", "tBone"]).describe("牛排类型"),
infoType: z.enum(["basic", "cooking", "temperature"]).optional().describe("信息类型:basic(基本信息), cooking(烹饪方法), temperature(温度指南)")
},
async ({steakType, infoType = "basic"}) => {
try {
const steak = steakData[steakType];
if (!steak) {
return {
content: [{ type: "text", text: `未找到牛排类型: ${steakType}` }]
};
}
let responseText = "";
switch (infoType) {
case "cooking":
responseText = `【${steak.name}】推荐烹饪方法:\n${steak.cookingMethods.join("、")}`;
break;
case "temperature":
responseText = `【${steak.name}】烹饪温度指南:\n` +
Object.entries(steak.internalTemp)
.map(([level, temp]) => `${level}: ${temp}`)
.join("\n");
break;
case "basic":
default:
responseText = `【${steak.name}】\n` +
`描述: ${steak.description}\n` +
`重量: ${steak.weight}\n` +
`推荐烹饪方法: ${steak.cookingMethods.join("、")}`;
break;
}
return {
content: [{ type: "text", text: responseText }]
};
} catch (error) {
return {
content: [{ type: "text", text: `获取牛排信息时出错: ${error.message}` }]
};
}
}
);
// 定义获取所有牛排类型列表的工具
server.tool("list_steak_types",
{},
async () => {
try {
const steakList = Object.entries(steakData)
.map(([key, steak]) => `${key}: ${steak.name}`)
.join("\n");
return {
content: [{
type: "text",
text: `可用的牛排类型:\n${steakList}\n\n使用 get_steak_info 工具获取特定牛排的详细信息。`
}]
};
} catch (error) {
return {
content: [{ type: "text", text: `获取牛排列表时出错: ${error.message}` }]
};
}
}
);
// 启动服务器,通过stdin/stdout进行通信
const transport = new StdioServerTransport();
await server.connect(transport);1.2. 编写 mcp server 配置
json
{
"mcpServers": {
"my-steak-server": {
"command": "node",
"args": [
"D:\project\AI\MCP\mcpserver\my-server3\steak.js"
],
"disabled": true,
"autoApprove": []
}
}
}1.3. 配置到 cherry studio 后进行验证
有什么牛排可以点
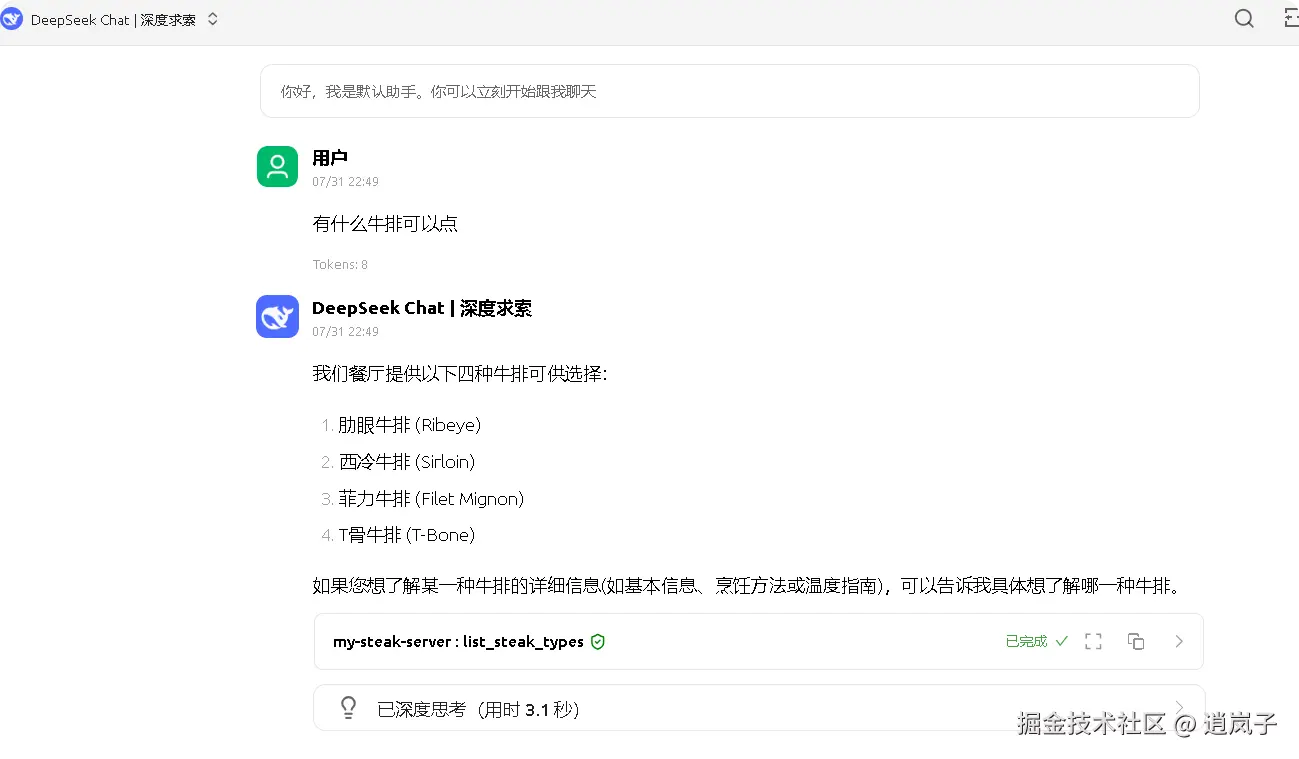
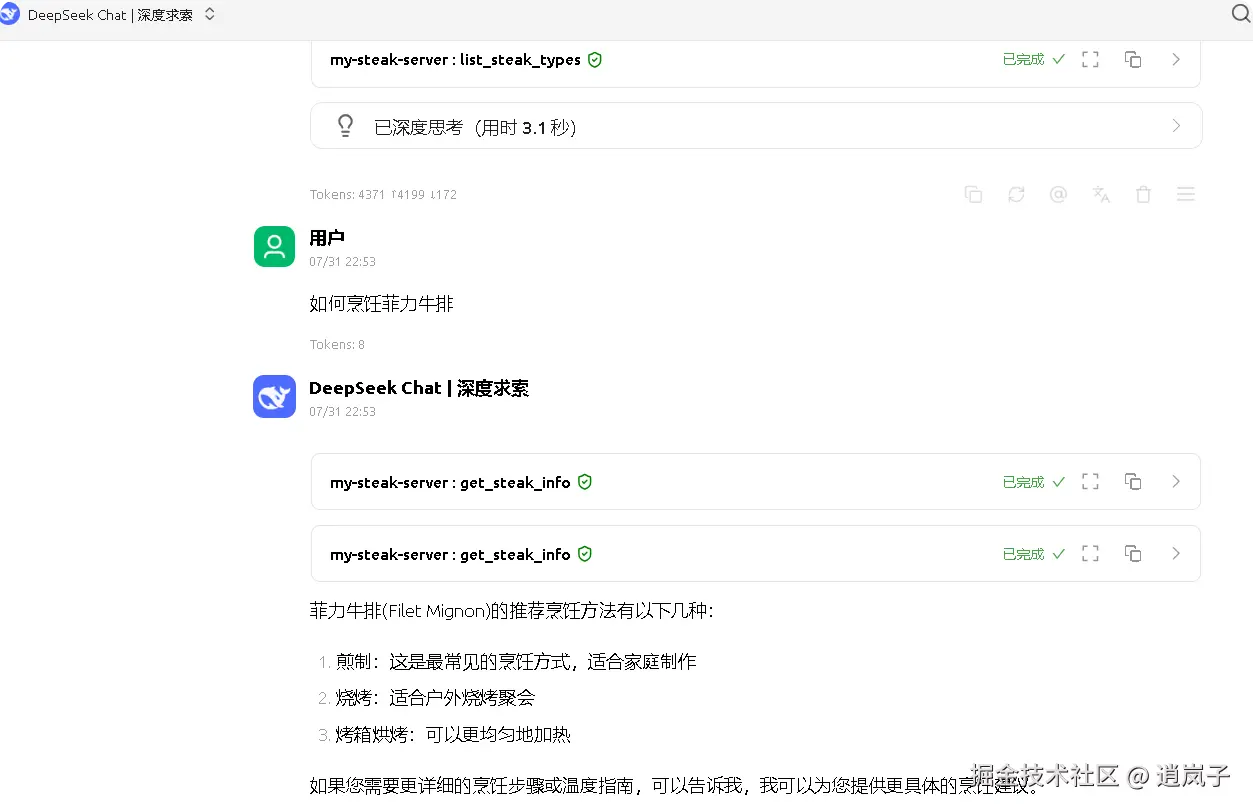
如何烹饪菲力牛排?
2. mcp server开发(typescript-sdk)
2.1. 新建项目
项目名称:my-server3
2.2. 安装 typescript sdk
npm install @modelcontextprotocol/sdk
2.3. 开发加法运算 mcpserver 程序
大模型对数学运算存在精度问题,这里通过示例自定义一个 mcp server 来解决这个问题。
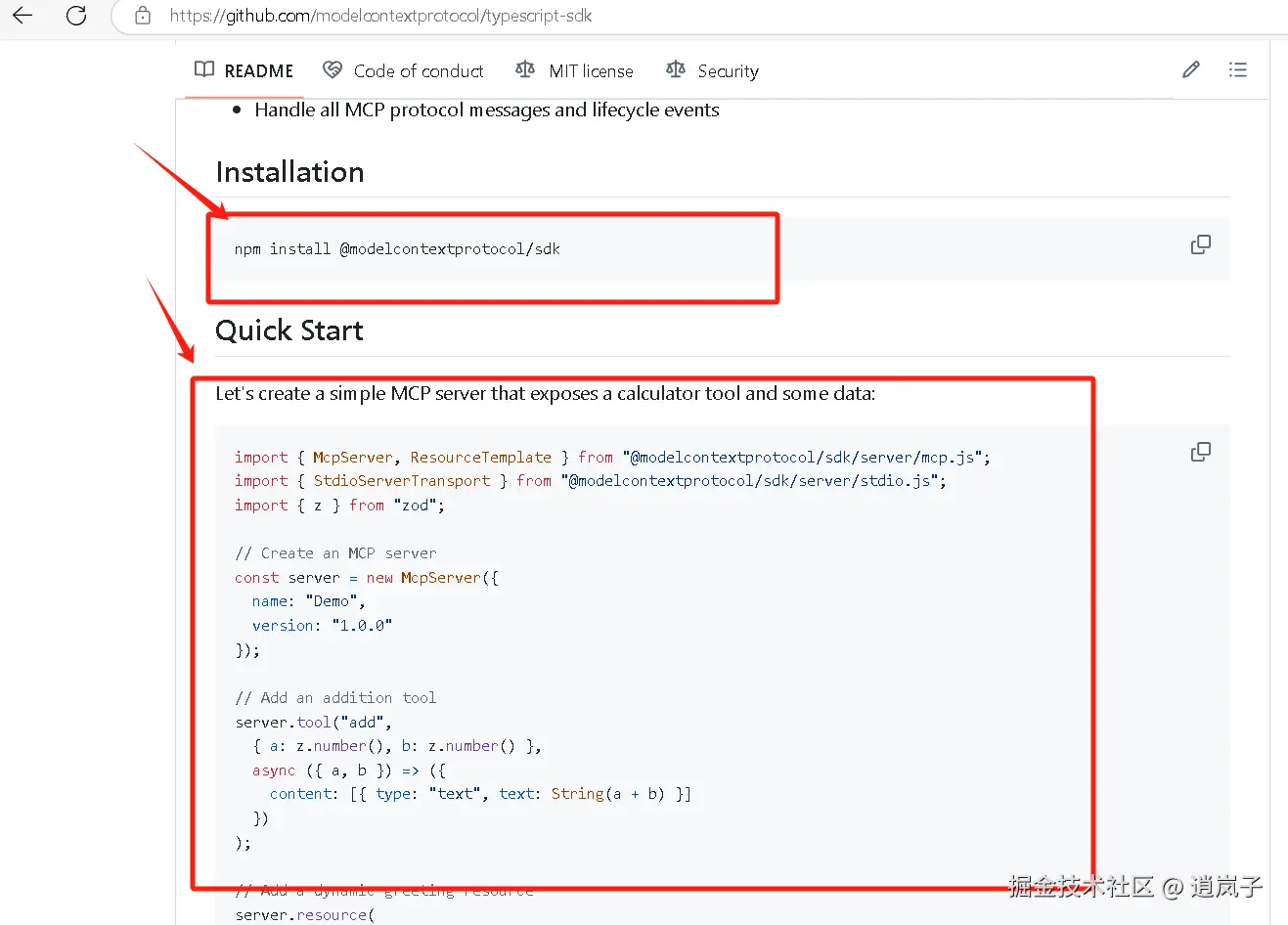
示例代码放到将 demo.js 文件中。
javascript
import { McpServer, ResourceTemplate } from "@modelcontextprotocol/sdk/server/mcp.js";
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
import { z } from "zod";
// Create an MCP server
const server = new McpServer({
name: "Demo",
version: "1.0.0"
});
// Add an addition tool
server.tool("add",
{ a: z.number(), b: z.number() },
async ({ a, b }) => ({
content: [{ type: "text", text: String(a + b) }]
})
);
// Add a dynamic greeting resource
server.resource(
"greeting",
new ResourceTemplate("greeting://{name}", { list: undefined }),
async (uri, { name }) => ({
contents: [{
uri: uri.href,
text: `Hello, ${name}!`
}]
})
);
// Start receiving messages on stdin and sending messages on stdout
const transport = new StdioServerTransport();
await server.connect(transport);2.4. cline 配置 mcp 服务
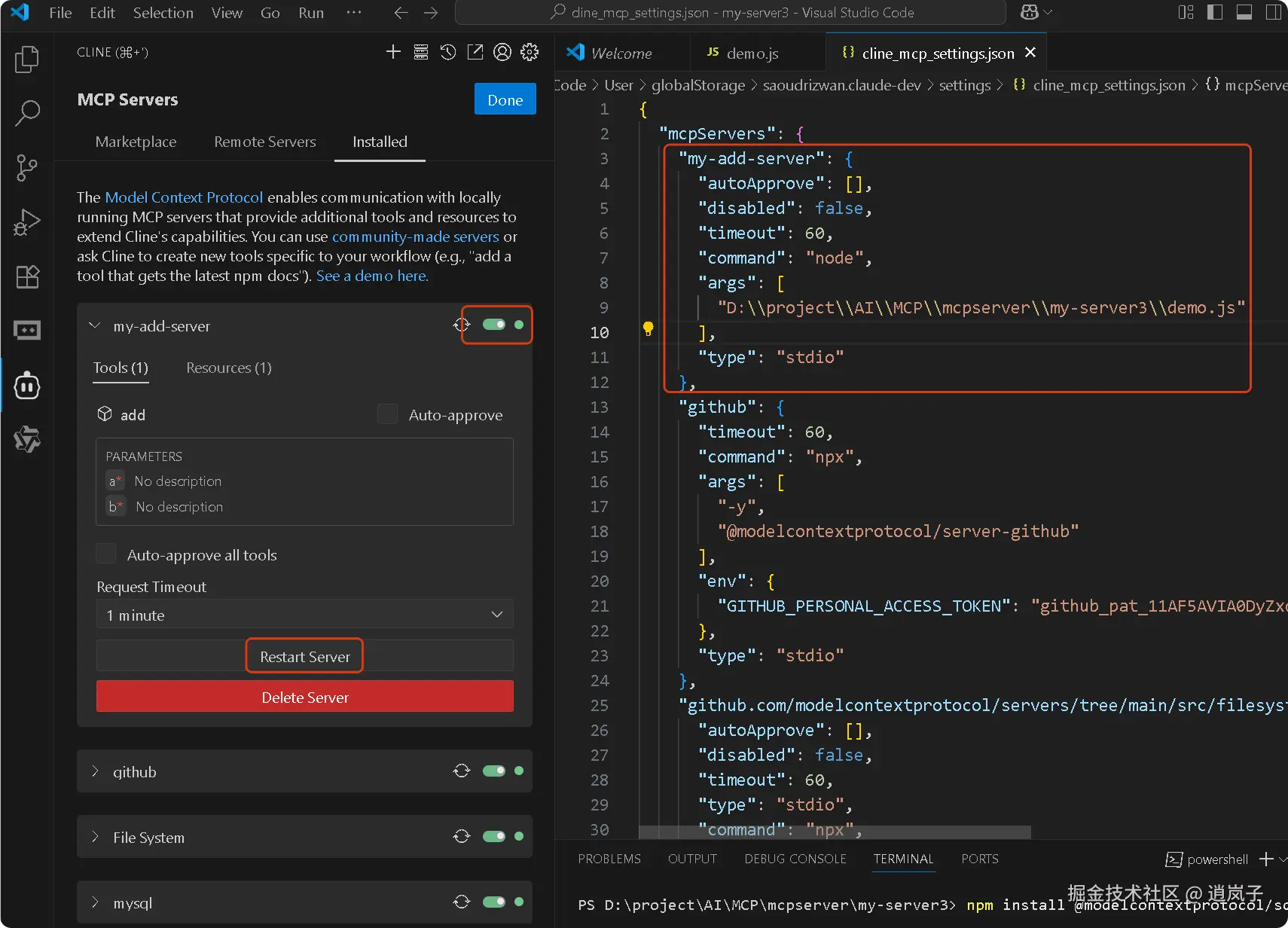
配置如下:
json
{
"mcpServers": {
"my-add-server": {
"command": "node",
"args": [
"D:\project\AI\MCP\mcpserver\my-server3\demo.js"
],
"disabled": true,
"autoApprove": []
}
}
}demo.js 保存后,出现在了左边列表上, 启用该 MCP server,如果是红灯,即点【Restart Server】重启下,变绿后, 然后点【Done】
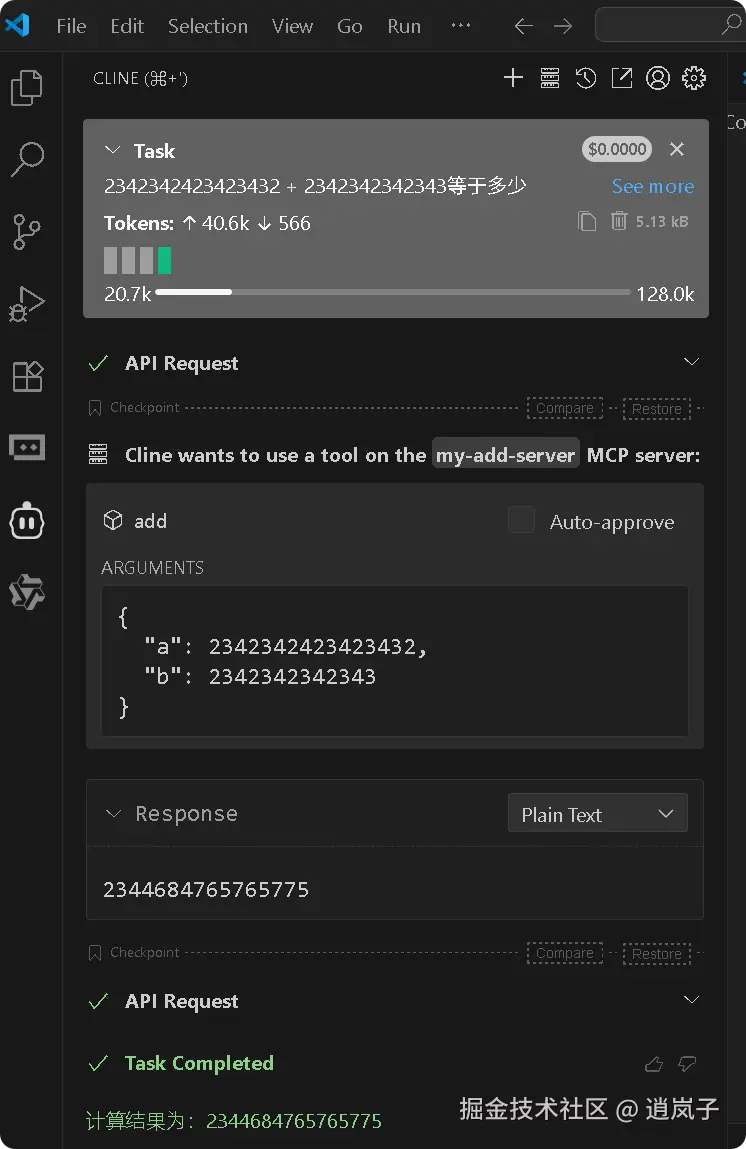
2.5. 测试 mcp 服务
如果是比较小的数值运算,大模型能正常处理,没误差的话,可能就不会调用工具。这种情况下,可以在提示词指定工具。
提问如下:
2342342423423432 + 2342342342343等于多少
示例如下:
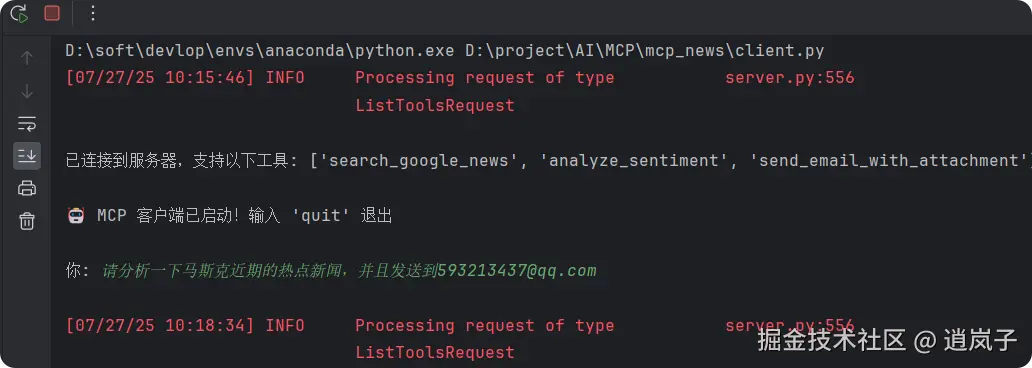
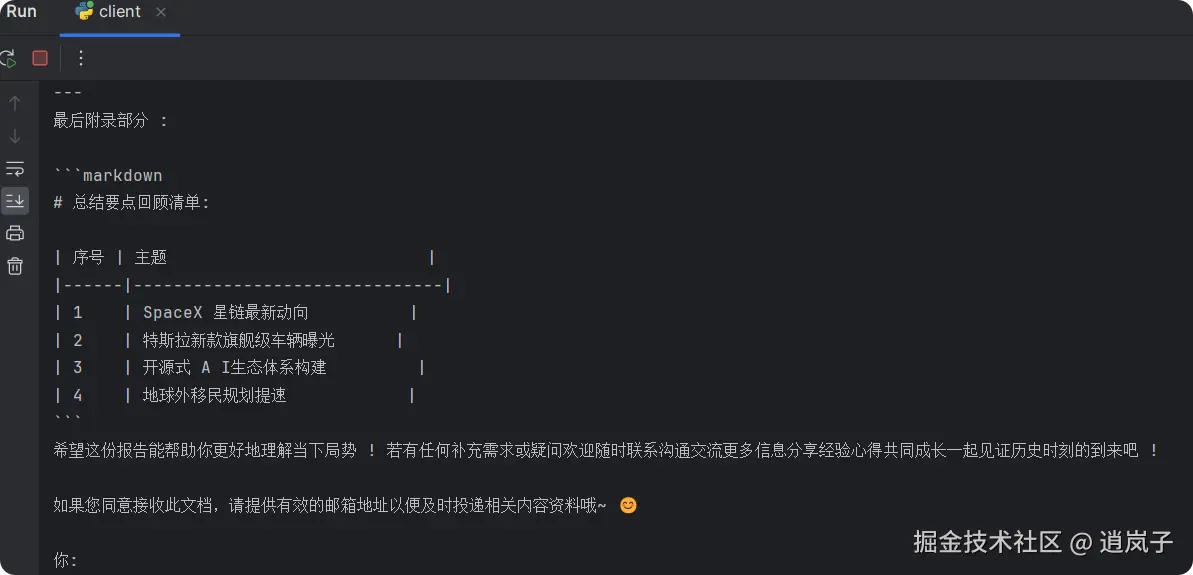
3. mcp server和mcp client开发(python-sdk)
3.1. 项目构建
3.1.1. 初始化项目
uv init mcp_news

3.1.2. 创建 .env, server.py 和 client.py
3.1.3. .evn
ini
BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1"
MODEL=qwen2.5-vl-32b-instruct
DASHSCOPE_API_KEY="sk-bffdxxxxxxe927d67273"
SERPER_API_KEY="618b9909116xxxxx7312428bbba76"
SMTP_SERVER=smtp.163.com
SMTP_PORT=465
EMAIL_USER=codxxxxding@163.com
EMAIL_PASS=AZeDNxxxxxt3Vr3.1.4. client.py
python
import asyncio
import os
import json
from typing import Optional, List
from contextlib import AsyncExitStack
from datetime import datetime
import re
from openai import OpenAI
from dotenv import load_dotenv
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
load_dotenv()
class MCPClient:
def __init__(self):
self.exit_stack = AsyncExitStack()
self.openai_api_key = os.getenv("DASHSCOPE_API_KEY")
self.base_url = os.getenv("BASE_URL")
self.model = os.getenv("MODEL")
if not self.openai_api_key:
raise ValueError("❌ 未找到 OpenAI API Key,请在 .env 文件中设置 DASHSCOPE_API_KEY")
self.client = OpenAI(api_key=self.openai_api_key, base_url=self.base_url)
self.session: Optional[ClientSession] = None
async def connect_to_server(self, server_script_path: str):
# 对服务器脚本进行判断,只允许是 .py 或 .js
is_python = server_script_path.endswith('.py')
is_js = server_script_path.endswith('.js')
if not (is_python or is_js):
raise ValueError("服务器脚本必须是 .py 或 .js 文件")
# 确定启动命令,.py 用 python,.js 用 node
command = "python" if is_python else "node"
# 构造 MCP 所需的服务器参数,包含启动命令、脚本路径参数、环境变量(为 None 表示默认)
server_params = StdioServerParameters(command=command, args=[server_script_path], env=None)
# 启动 MCP 工具服务进程(并建立 stdio 通信)
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))
# 拆包通信通道,读取服务端返回的数据,并向服务端发送请求
self.stdio, self.write = stdio_transport
# 创建 MCP 客户端会话对象
self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))
# 初始化会话
await self.session.initialize()
# 获取工具列表并打印
response = await self.session.list_tools()
tools = response.tools
print("\n已连接到服务器,支持以下工具:", [tool.name for tool in tools])
async def process_query(self, query: str) -> str:
# 准备初始消息和获取工具列表
messages = [{"role": "user", "content": query}]
response = await self.session.list_tools()
available_tools = [
{
"type": "function",
"function": {
"name": tool.name,
"description": tool.description,
"input_schema": tool.inputSchema
}
} for tool in response.tools
]
# 提取问题的关键词,对文件名进行生成。
# 在接收到用户提问后就应该生成出最后输出的 md 文档的文件名,
# 因为导出时若再生成文件名会导致部分组件无法识别该名称。
keyword_match = re.search(r'(关于|分析|查询|搜索|查看)([^的\s,。、?\n]+)', query)
keyword = keyword_match.group(2) if keyword_match else "分析对象"
safe_keyword = re.sub(r'[\/:*?"<>|]', '', keyword)[:20]
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
md_filename = f"sentiment_{safe_keyword}_{timestamp}.md"
md_path = os.path.join("./sentiment_reports", md_filename)
# 更新查询,将文件名添加到原始查询中,使大模型在调用工具链时可以识别到该信息
# 然后调用 plan_tool_usage 获取工具调用计划
query = query.strip() + f" [md_filename={md_filename}] [md_path={md_path}]"
messages = [{"role": "user", "content": query}]
tool_plan = await self.plan_tool_usage(query, available_tools)
tool_outputs = {}
messages = [{"role": "user", "content": query}]
# 依次执行工具调用,并收集结果
for step in tool_plan:
tool_name = step["name"]
tool_args = step["arguments"]
for key, val in tool_args.items():
if isinstance(val, str) and val.startswith("{{") and val.endswith("}}"):
ref_key = val.strip("{} ")
resolved_val = tool_outputs.get(ref_key, val)
tool_args[key] = resolved_val
# 注入统一的文件名或路径(用于分析和邮件)
if tool_name == "analyze_sentiment" and "filename" not in tool_args:
tool_args["filename"] = md_filename
if tool_name == "send_email_with_attachment" and "attachment_path" not in tool_args:
tool_args["attachment_path"] = md_path
result = await self.session.call_tool(tool_name, tool_args)
tool_outputs[tool_name] = result.content[0].text
messages.append({
"role": "tool",
"tool_call_id": tool_name,
"content": result.content[0].text
})
# 调用大模型生成回复信息,并输出保存结果
final_response = self.client.chat.completions.create(
model=self.model,
messages=messages
)
final_output = final_response.choices[0].message.content
# 对辅助函数进行定义,目的是把文本清理成合法的文件名
def clean_filename(text: str) -> str:
text = text.strip()
text = re.sub(r'[\/:*?"<>|]', '', text)
return text[:50]
# 使用清理函数处理用户查询,生成用于文件命名的前缀,并添加时间戳、设置输出目录
# 最后构建出完整的文件路径用于保存记录
safe_filename = clean_filename(query)
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
filename = f"{safe_filename}_{timestamp}.txt"
output_dir = "./llm_outputs"
os.makedirs(output_dir, exist_ok=True)
file_path = os.path.join(output_dir, filename)
# 将对话内容写入 md 文档,其中包含用户的原始提问以及模型的最终回复结果
with open(file_path, "w", encoding="utf-8") as f:
f.write(f"🗣 用户提问:{query}\n\n")
f.write(f"🤖 模型回复:\n{final_output}\n")
print(f"📄 对话记录已保存为:{file_path}")
return final_output
async def chat_loop(self):
# 初始化提示信息
print("\n🤖 MCP 客户端已启动!输入 'quit' 退出")
# 进入主循环中等待用户输入
while True:
try:
query = input("\n你: ").strip()
if query.lower() == 'quit':
break
# 处理用户的提问,并返回结果
response = await self.process_query(query)
print(f"\n🤖 AI: {response}")
except Exception as e:
print(f"\n⚠️ 发生错误: {str(e)}")
async def plan_tool_usage(self, query: str, tools: List[dict]) -> List[dict]:
# 构造系统提示词 system_prompt。
# 将所有可用工具组织为文本列表插入提示中,并明确指出工具名,
# 限定返回格式是 JSON,防止其输出错误格式的数据。
print("\n📤 提交给大模型的工具定义:")
print(json.dumps(tools, ensure_ascii=False, indent=2))
tool_list_text = "\n".join([
f"- {tool['function']['name']}: {tool['function']['description']}"
for tool in tools
])
system_prompt = {
"role": "system",
"content": (
"你是一个智能任务规划助手,用户会给出一句自然语言请求。\n"
"你只能从以下工具中选择(严格使用工具名称):\n"
f"{tool_list_text}\n"
"如果多个工具需要串联,后续步骤中可以使用 {{上一步工具名}} 占位。\n"
"返回格式:JSON 数组,每个对象包含 name 和 arguments 字段。\n"
"不要返回自然语言,不要使用未列出的工具名。"
)
}
# 构造对话上下文并调用模型。
# 将系统提示和用户的自然语言一起作为消息输入,并选用当前的模型。
planning_messages = [
system_prompt,
{"role": "user", "content": query}
]
response = self.client.chat.completions.create(
model=self.model,
messages=planning_messages,
tools=tools,
tool_choice="none"
)
# 提取出模型返回的 JSON 内容
content = response.choices[0].message.content.strip()
match = re.search(r"```(?:json)?\s*([\s\S]+?)\s*```", content)
if match:
json_text = match.group(1)
else:
json_text = content
# 在解析 JSON 之后返回调用计划
try:
plan = json.loads(json_text)
return plan if isinstance(plan, list) else []
except Exception as e:
print(f"❌ 工具调用链规划失败: {e}\n原始返回: {content}")
return []
async def cleanup(self):
await self.exit_stack.aclose()
async def main():
server_script_path = r"D:\project\AI\MCP\mcp_news\server.py"
client = MCPClient()
try:
await client.connect_to_server(server_script_path)
await client.chat_loop()
finally:
await client.cleanup()
if __name__ == "__main__":
asyncio.run(main())3.1.5. server.py
python
import os
import json
import smtplib
from datetime import datetime
from email.message import EmailMessage
import httpx
from mcp.server.fastmcp import FastMCP
from dotenv import load_dotenv
from openai import OpenAI
# 加载环境变量
load_dotenv()
# 初始化 MCP 服务器
mcp = FastMCP("NewsServer")
# @mcp.tool() 是 MCP 框架的装饰器,表明这是一个 MCP 工具。之后是对这个工具功能的描述
@mcp.tool()
async def search_google_news(keyword: str) -> str:
"""
使用 Serper API(Google Search 封装)根据关键词搜索新闻内容,返回前5条标题、描述和链接。
参数:
keyword (str): 关键词,如 "小米汽车"
返回:
str: JSON 字符串,包含新闻标题、描述、链接
"""
# 从环境中获取 API 密钥并进行检查
api_key = os.getenv("SERPER_API_KEY")
if not api_key:
return "❌ 未配置 SERPER_API_KEY,请在 .env 文件中设置"
# 设置请求参数并发送请求
url = "https://google.serper.dev/news"
headers = {
"X-API-KEY": api_key,
"Content-Type": "application/json"
}
payload = {"q": keyword}
async with httpx.AsyncClient() as client:
response = await client.post(url, headers=headers, json=payload)
data = response.json()
# 检查数据,并按照格式提取新闻,返回前五条新闻
if "news" not in data:
return "❌ 未获取到搜索结果"
articles = [
{
"title": item.get("title"),
"desc": item.get("snippet"),
"url": item.get("link")
} for item in data["news"][:5]
]
# 将新闻结果以带有时间戳命名后的 JSON 格式文件的形式保存在本地指定的路径
output_dir = "./google_news"
os.makedirs(output_dir, exist_ok=True)
filename = f"google_news_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json"
file_path = os.path.join(output_dir, filename)
with open(file_path, "w", encoding="utf-8") as f:
json.dump(articles, f, ensure_ascii=False, indent=2)
return (
f"✅ 已获取与 [{keyword}] 相关的前5条 Google 新闻:\n"
f"{json.dumps(articles, ensure_ascii=False, indent=2)}\n"
f"📄 已保存到:{file_path}"
)
# @mcp.tool() 是 MCP 框架的装饰器,标记该函数为一个可调用的工具
@mcp.tool()
async def analyze_sentiment(text: str, filename: str) -> str:
"""
对传入的一段文本内容进行情感分析,并保存为指定名称的 Markdown 文件。
参数:
text (str): 新闻描述或文本内容
filename (str): 保存的 Markdown 文件名(不含路径)
返回:
str: 完整文件路径(用于邮件发送)
"""
# 这里的情感分析功能需要去调用 LLM,所以从环境中获取 LLM 的一些相应配置
openai_key = os.getenv("DASHSCOPE_API_KEY")
model = os.getenv("MODEL")
client = OpenAI(api_key=openai_key, base_url=os.getenv("BASE_URL"))
# 构造情感分析的提示词
prompt = f"请对以下新闻内容进行情绪倾向分析,并说明原因:\n\n{text}"
# 向模型发送请求,并处理返回的结果
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
result = response.choices[0].message.content.strip()
# 生成 Markdown 格式的舆情分析报告,并存放进设置好的输出目录
markdown = f"""# 舆情分析报告
**分析时间:** {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}
---
## 📥 原始文本
{text}
---
## 📊 分析结果
{result}
"""
output_dir = "./sentiment_reports"
os.makedirs(output_dir, exist_ok=True)
if not filename:
filename = f"sentiment_{datetime.now().strftime('%Y%m%d_%H%M%S')}.md"
file_path = os.path.join(output_dir, filename)
with open(file_path, "w", encoding="utf-8") as f:
f.write(markdown)
return file_path
@mcp.tool()
async def send_email_with_attachment(to: str, subject: str, body: str, filename: str) -> str:
"""
发送带附件的邮件。
参数:
to: 收件人邮箱地址
subject: 邮件标题
body: 邮件正文
filename (str): 保存的 Markdown 文件名(不含路径)
返回:
邮件发送状态说明
"""
# 获取并配置 SMTP 相关信息
smtp_server = os.getenv("SMTP_SERVER") # 例如 smtp.qq.com
smtp_port = int(os.getenv("SMTP_PORT", 465))
sender_email = os.getenv("EMAIL_USER")
sender_pass = os.getenv("EMAIL_PASS")
# 获取附件文件的路径,并进行检查是否存在
full_path = os.path.abspath(os.path.join("./sentiment_reports", filename))
if not os.path.exists(full_path):
return f"❌ 附件路径无效,未找到文件: {full_path}"
# 创建邮件并设置内容
msg = EmailMessage()
msg["Subject"] = subject
msg["From"] = sender_email
msg["To"] = to
msg.set_content(body)
# 添加附件并发送邮件
try:
with open(full_path, "rb") as f:
file_data = f.read()
file_name = os.path.basename(full_path)
msg.add_attachment(file_data, maintype="application", subtype="octet-stream", filename=file_name)
except Exception as e:
return f"❌ 附件读取失败: {str(e)}"
try:
with smtplib.SMTP_SSL(smtp_server, smtp_port) as server:
server.login(sender_email, sender_pass)
server.send_message(msg)
return f"✅ 邮件已成功发送给 {to},附件路径: {full_path}"
except Exception as e:
return f"❌ 邮件发送失败: {str(e)}"
if __name__ == "__main__":
mcp.run(transport='stdio')3.2. 运行测试
步骤:
- 直接运行client.py,输入:
2."请分析一下马斯克近期的热点新闻,并且发送到593xx3437@qq.com"
- 执行一段时间后,去邮箱查看