一句总结 :文章提出了一种名为Mobile U-ViT 的轻量级混合网络架构,通过创新的ConvUtr(大核CNN块模拟Transformer模式)、LKLGL(大核局部-全局-局部块)和带下采样跳跃连接的级联解码器设计,有效解决了医学图像与自然图像间的信息密度差异(稀疏特征、模糊边界、高噪声)问题,在显著降低计算开销的同时,在多种2D/3D医学图像分割任务上达到了SOTA性能,并展现出优异的零样本泛化能力和移动端部署潜力。
- 现有的核心问题是什么?
- 临床移动设备上的医学图像分析需要高效执行(低计算开销、高推理速度)。
- 现有针对自然图像优化的轻量模型(MobileViT等)在医学图像分割任务上表现不佳。
- 原因在于医学图像与自然图像存在显著的信息密度差异 :
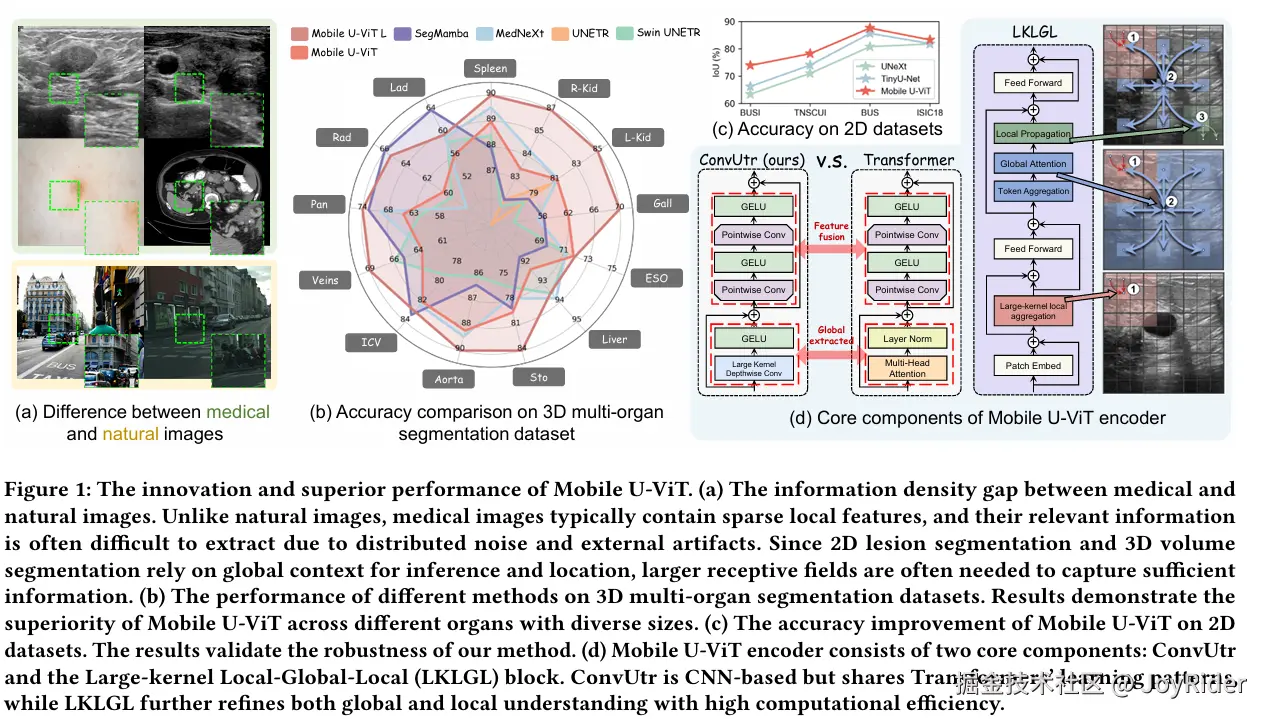
- (i) 稀疏局部信息:相同空间窗口内信息量少,相邻区域相似性高(如图1a),小卷积核难以捕获有效模式。
- (ii) 模糊边界与高噪声:病变边缘不清,目标与背景对比度低,存在解剖背景和成像伪影干扰(如图1a,d),要求模型能同时强调细节、抑制噪声并利用全局上下文。
- 现有方法存在什么缺陷?
- 纯CNN模型:计算高效但感受野有限,难以捕获全局上下文,分割性能瓶颈明显。
- 现有轻量模型(尤其是针对自然图像的):其设计未充分考虑医学图像特有的信息稀疏性和高语义歧义性(稀疏特征、模糊边界、高噪声),导致性能受限。
- 现有混合架构(如TransUNet):虽然结合了CNN和ViT的优势,但往往模型庞大(参数量大)且计算开销高(GFLOPs高),不适合资源受限的移动设备。
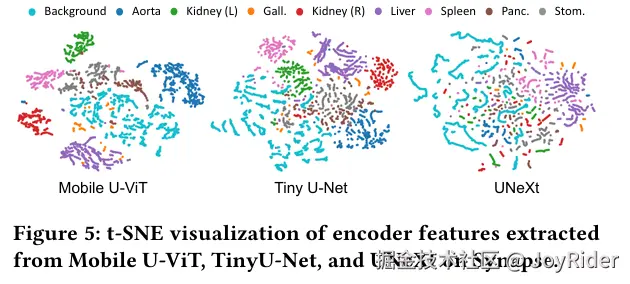
- 现有轻量医学模型:在保持轻量化的同时,难以平衡对全局语义的理解和对局部细节的精确捕捉,尤其在复杂3D分割或面对噪声时表现不足(如图5特征纠缠)。
- 本文的创新解决方案是什么?
-
核心结构创新 :本文提出ConvUtr 作为轻量化的分层块嵌入(Patch Embedding),通过大核深度可分离卷积(DSConv) 扩展感受野捕获全局特征,结合倒置两点卷积 促进通道交互,模拟Transformer的建模模式(如图1d)。这一设计在保留类Transformer表征能力的同时,显著降低了参数量和计算开销(复杂度仅 O(h×w×di×(k2+2×dj)),并采用最大池化下采样抑制医学图像中的背景噪声与模糊边界。
-
信息融合创新 :为解决医学图像局部稀疏与全局语义歧义问题,提出大核局部-全局-局部(LKLGL)模块 (如图1d)。其四步信息流:① 大核DSConv局部聚合(Red),② 池化操作压缩Token数量,③ 注意力机制实现高效全局交互(Blue),④ 转置卷积将精炼信息局部分发(Green)。该设计通过结构化信息流 和Token聚合机制 (计算复杂度降至 O(N2/p4)),在降低计算量的同时强化了局部细节与全局上下文的融合能力。
-
解码优化创新 :采用级联解码器与下采样跳跃连接, 设计级联上采样解码器 ,引入下采样跳跃连接 解决编码器(CNN特征)与解码器(Transformer输出)的语义对齐问题。该连接对多分辨率特征进行下采样操作,过滤冗余背景噪声 并增强边界信息(如图2),使模型在资源受限条件下仍能精准融合低层细节与高层语义,实现高效且准确的密集预测。
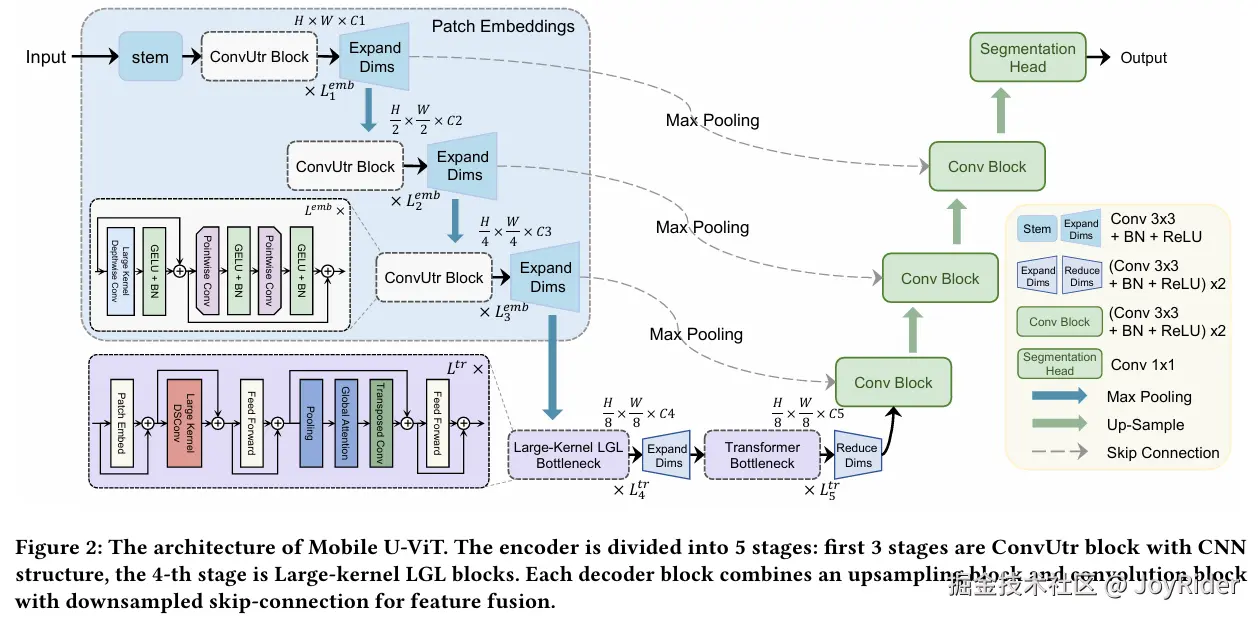 图2展示了Mobile U-ViT的整体U形架构设计,其编码器由前端的ConvUtr模块和后端的LKLGL模块构成:ConvUtr通过大核深度分离卷积与倒置点卷积分层提取特征并下采样,有效捕获医学图像的全局语义;LKLGL模块则通过局部聚合、全局注意力交互和局部分发的结构化信息流进一步融合多尺度上下文。轻量Transformer层作为瓶颈建模长程依赖后,解码器采用级联上采样结构逐步恢复分辨率,并创新性地引入下采样跳跃连接将编码器各阶段特征先下采样再与同尺度解码特征融合,在解决语义错位问题的同时显著抑制背景噪声并强化边界信息,最终实现高效精准的密集预测。
图2展示了Mobile U-ViT的整体U形架构设计,其编码器由前端的ConvUtr模块和后端的LKLGL模块构成:ConvUtr通过大核深度分离卷积与倒置点卷积分层提取特征并下采样,有效捕获医学图像的全局语义;LKLGL模块则通过局部聚合、全局注意力交互和局部分发的结构化信息流进一步融合多尺度上下文。轻量Transformer层作为瓶颈建模长程依赖后,解码器采用级联上采样结构逐步恢复分辨率,并创新性地引入下采样跳跃连接将编码器各阶段特征先下采样再与同尺度解码特征融合,在解决语义错位问题的同时显著抑制背景噪声并强化边界信息,最终实现高效精准的密集预测。