本文的贡献总结如下:
(1)设计了一种新的MS-EIS(多尺度边缘信息选择)架构,通过选择性地聚合多个尺度的边缘和纹理信息,增强细粒度特征表示,以应对复杂背景下小目标和目标检测的难题。
(2)提出了一种新的Add-CGLU(加性卷积门控线性单元)金字塔网络,通过加性融合和门控机制提升特征的表征能力和信息传递效率,帮助网络更好地捕捉复杂场景中的小目标,以处理多尺度变化。
(3)开发了一种新的DEC(细节增强卷积)检测头,通过增强细节特征和精细化空间定位,缓解小目标和模糊边界定位不准的挑战,提升在杂乱或挑战性背景下的检测能力。
(4)定义了一种新的DS(双自知识蒸馏)策略,通过在网络整体进行双重自蒸馏,克服复杂场景下的泛化能力退化问题,进一步提升检测精度和鲁棒性,确保即使面对小型或难以区分的目标也能保持可靠的性能。

博主简介

AI小怪兽 | 计算机视觉布道者 | 视觉检测领域创新者
深耕计算机视觉与深度学习领域,专注于视觉检测前沿技术的探索与突破。长期致力于YOLO系列算法的结构性创新、性能极限优化与工业级落地实践,旨在打通从学术研究到产业应用的最后一公里。
🚀 核心专长与技术创新
-
YOLO算法结构性创新 :于CSDN平台原创发布《YOLOv13魔术师》、《YOLOv12魔术师》等全系列深度专栏。系统性提出并开源了多项原创自研模块 ,在模型轻量化设计、多维度注意力机制融合、特征金字塔重构等关键方向完成了一系列突破性实践,为行业提供了具备高参考价值的技术路径与完整解决方案。
-
技术生态建设与知识传播 :独立运营 "计算机视觉大作战" 公众号(粉丝1.6万),成功构建高质量的技术交流社群。致力于将复杂算法转化为通俗易懂的解读与可复现的工程代码,显著降低了计算机视觉的技术入门门槛。
🏆 行业影响力与商业实践
-
荣获腾讯云年度影响力作者 与创作之星奖项,内容质量与专业性获行业权威平台认证。
-
全网累计拥有 7万+ 垂直领域技术受众,专栏文章总阅读量突破百万,在目标检测领域形成了广泛的学术与工业影响力。
-
具备丰富的企业级项目交付经验,曾为工业视觉检测、智慧城市安防等多个关键领域提供定制化的算法模型与解决方案,驱动业务智能化升级。
💡 未来方向与使命
秉持 "让每一行代码都有温度" 的技术理念,未来将持续聚焦于实时检测、语义分割及工业缺陷检测的商业化闭环等核心方向。愿与业界同仁协同创新,共同推动技术边界,以坚实的技术能力赋能实体经济与行业变革。
原创自研系列, 25年计算机视觉顶会创新点
应用系列篇:
23、24年最火系列,加入24年改进点内涵100+优化改进篇,涨点小能手,助力科研,好评率极高
原理介绍

论文: https://www.mdpi.com/2624-7402/8/1/16
摘要 :随着精准农业对田间杂草实时检测与识别精度提出更高要求,本文提出了一种用于精准农业的多尺度信息增强杂草检测算法MIE-YOLO (Multi-scale Information Enhanced)。该算法基于当前流行的YOLO12(You Only Look Once 12)模型,结合边缘感知多尺度融合、加性门控块及双重自蒸馏技术,在保持轻量化的同时,提升了小目标及边界检测性能。首先,设计了MS-EIS(Multi-Scale-Edge Information Select,多尺度边缘信息选择)架构,有效聚合并选择不同尺度的边缘与纹理信息,以增强细粒度特征表示。其次,提出了Add-CGLU(Additive-Convolutional Gated Linear Unit,加性卷积门控线性单元)金字塔网络,通过加性融合与门控机制,增强多尺度特征的表征能力与信息传递效率。最后,引入了DEC(Detail-Enhanced Convolution,细节增强卷积)检测头,以增强细节感知能力,优化小目标与模糊边界的定位精度。为进一步提升模型检测精度与泛化性能,定义了DS(Double Self-Knowledge Distillation,双重自知识蒸馏)策略,在整个网络内部执行双重自知识蒸馏。在包含8类杂草、共计9257张图像的自建杂草数据集上的实验结果表明,MIE-YOLO将F1分数提升了1.9%,平均精度均值(mAP)提升了2.0%。此外,其计算参数量减少了29.9%,浮点运算量(FLOPs)降低了6.9%,模型大小减少了17.0%,并实现了66.2 FPS的运行时速度。MIE-YOLO在保持一定推理效率的同时,显著提升了杂草检测性能,为精准农业中的田间智能巡检与杂草精准防治提供了有效的技术路径与工程实现参考。源代码已发布于GitHub。
关键词: YOLO12;精准农业杂草检测;多尺度边缘信息选择架构;加性卷积门控线性单元金字塔网络;细节增强卷积检测头;双重自知识蒸馏策略
一、引言
随着全球人口增长和农业现代化进程加速,精准农业技术作为提高作物产量、减少化学品投入及实现可持续管理的重要手段正受到广泛关注。在田间管理中,杂草具有空间分布复杂、物种多样且与作物形态相似等特点,传统的人工巡检和通用图像处理方法已难以满足高精度、低成本、实时检测的需求1。因此,基于深度学习的视觉检测技术,特别是具有实时推理能力的轻量级单阶段目标检测器,已成为实现田间智能巡检与杂草精准防治的关键技术路径2。
近年来,基于深度学习的目标检测方法在精准农业领域受到广泛关注。通过构建神经网络模型,可以实现图像中目标的定位与分类3。根据检测流程的不同,主流方法可分为两类:两阶段算法和单阶段算法4。两阶段算法包括 RCNN5、SPPNet6、Fast RCNN7、Faster RCNN8 和 FPN(特征金字塔网络)9。单阶段算法包括 YOLO(You Only Look Once)10、SSD(Single Shot MultiBox Detector)11、RetinaNet12、CornerNet13、CenterNet14 和 DETR(Detection Transformer)15。两阶段算法首先生成候选区域,然后对每个区域进行精细分类和回归,具有高精度和灵活的扩展性。单阶段算法在单次前向传播中同时完成目标分类和回归,提供出色的实时性能和易于部署的特点。
作为单阶段目标检测领域的代表性方法,YOLO系列算法因其优异的检测速度和精度已在众多领域得到广泛应用。继经典的YOLOv5、YOLOv8和YOLOv916算法之后,YOLOv1017、YOLO1118、YOLO1219和YOLO1320算法也相继发布,检测性能得到进一步提升。
然而,对于精准农业应用,标准的YOLO模型在多尺度小目标检测方面往往表现不佳。小型杂草占据的像素极少,下采样过程会丢失关键的纹理和形状线索,导致漏检或检测合并。尺度变化、遮挡和密集植被进一步损害定位和分类精度,而锚框和非极大值抑制等常见设计选择可能会抑制真实小目标的预测。田间图像还会因光照、运动模糊和不同传感器引入域偏移,嵌入式硬件的实时性约束也限制了简单地扩大网络规模。因此,本文提出一种致力于平衡运行速度与检测精度的多尺度信息增强杂草检测算法。本文的贡献总结如下:
(1)设计了一种新的MS-EIS(多尺度边缘信息选择)架构,通过选择性地聚合多个尺度的边缘和纹理信息,增强细粒度特征表示,以应对复杂背景下小目标和目标检测的难题。
(2)提出了一种新的Add-CGLU(加性卷积门控线性单元)金字塔网络,通过加性融合和门控机制提升特征的表征能力和信息传递效率,帮助网络更好地捕捉复杂场景中的小目标,以处理多尺度变化。
(3)开发了一种新的DEC(细节增强卷积)检测头,通过增强细节特征和精细化空间定位,缓解小目标和模糊边界定位不准的挑战,提升在杂乱或挑战性背景下的检测能力。
(4)定义了一种新的DS(双自知识蒸馏)策略,通过在网络整体进行双重自蒸馏,克服复杂场景下的泛化能力退化问题,进一步提升检测精度和鲁棒性,确保即使面对小型或难以区分的目标也能保持可靠的性能。
二、相关工作
计算机视觉的进步推动了目标检测算法在精准农业中的应用,包括针对性杂草防治、病虫害监测和果树计数。基于深度学习的目标检测算法已逐步取代传统手工特征提取方法,成为田间杂草检测的主流选择。许多研究主要以深度学习算法为基础,旨在通过改进骨干网络、融入注意力模块与多尺度特征融合、扩展感受野和上下文信息、以及优化轻量级后处理等方式,提高田间密集杂草检测的准确性和实时性能。
部分研究者对经典的YOLOv5算法进行了精度和准确度的改进,开创了模块融合的方法。Deng等人21提出了一种基于改进YOLOv5网络的高精度有效杂草检测模型HAD-YOLO。该算法使用HGNetv2作为骨干网络,引入带有注意力机制的SSFF(尺度序列特征融合)模块以提升模型特征提取能力。Wang等人22提出了一种基于增强YOLOv5的先进杂草检测器,该检测器结合了CBAM(卷积块注意力模块)、FasterNet特征提取网络和损失函数来优化网络结构和训练策略。Tao和Wei23提出了一种基于改进YOLOv5的油菜田杂草检测网络STBNA-YOLOv5,该网络通过Swin Transformer增强特征提取能力,使用BiFPN融合NAM(基于归一化的注意力模块)来利用特征信息。Zhang等人24提出了一种基于轻量化和上下文信息融合的杂草检测方法CCCS-YOLO,该方法通过集成Faster Block、上下文聚合模块和CARAF(特征的内容感知重组)来促进上下文信息的融合。
部分研究者也对当前流行的YOLOv8算法进行了轻量化改进,在实时性能优化方面取得了一定进展。Hu等人25提出了一种基于YOLOv8的轻量高精度精准农业棉花杂草识别模型CW-YOLO。该网络引入了结合视觉Transformer和卷积神经网络的双分支结构,并提出了一种RFE(感受野增强)模块以降低计算复杂度和参数量。Chen等人26提出了一种基于YOLOv8的稻田杂草检测算法GE-YOLO,该算法引入了具有特征聚合的分布网络和EMA(高效多尺度注意力)机制,以增强网络融合多尺度特征和检测不同大小杂草的能力。Zheng等人27提出了一种基于优化YOLOv8的棉田杂草识别算法YOLOv8-DMAS,该算法通过DWR(扩张智差残差)模块和ASFF(自适应空间特征融合)机制提高了密集杂草检测的精度。Shuai等人28提出了一种基于改进YOLOv8的用于大豆田的实时杂草检测模型YOLO-SW,引入了Swin Transformer骨干网络以实现高效的全局上下文捕捉。
此外,一些研究者在基于CNN设计网络架构方面取得了最新进展,提高了目标检测在精准农业领域的效率。Umar等人29提出了一种基于深度学习的薰衣草分类方法以提升种植管理和精油质量管理。该模型通过迁移学习、学习率调整和批次优化进行微调。在基线模型中添加了额外层以提高分类性能并减少训练时间。Gulzar30对基于预训练深度学习模型的木瓜叶病害分类进行了比较研究,评估了四种预训练卷积神经网络。他还提出了一种AI驱动的木瓜叶病害早期检测与分类方法PapNet31,该方法利用了先进的架构特征,包括全局平均池化、密集层以及策略性地使用批归一化和Dropout,在区分不同木瓜叶片状况方面表现出优越性能。Han等人32提出了一种基于增强遥感图像的椰子病害精准农业分割技术。他们使用预训练的CNN开发了一个鲁棒的病害分割模型,可以改善椰子种植中的病害管理。
尽管基于YOLO的杂草检测发展迅速,但现有方法仍面临重要限制。基于YOLOv5的模型,如HAD-YOLO和STBNA-YOLOv5,通过注意力模块或Transformer改进了特征提取,但通常增加了计算成本,在资源有限的田间场景中应用困难。基于YOLOv8的模型,包括CW-YOLO和GE-YOLO,实现了更轻量的设计和多尺度融合,但在复杂背景下检测小型、密集或重叠的杂草仍有困难。相比之下,本文提出的方法引入了一个多尺度、细节增强和蒸馏引导的框架,该框架聚合边缘和纹理信息,改进多尺度特征融合,并利用双重自知识蒸馏。此方法增强了对小型和密集杂草的检测能力,提高了在杂乱环境中的鲁棒性,并保持了准确性与实时性能之间的平衡,这是以往基于YOLO的方法未能完全实现的。
三、方法论
3.1. 整体网络结构
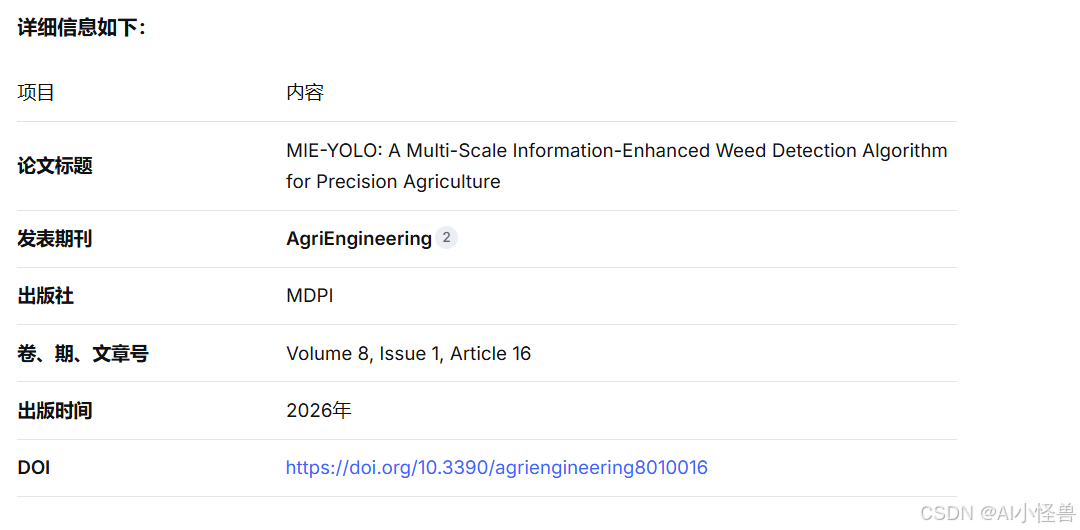
基于YOLO12-N模型,本文独立设计了MS-EIS(多尺度边缘信息选择)架构、Add-CGLU(加性卷积门控线性单元)金字塔网络和DEC(细节增强卷积)检测头。最后,结合DS(双自知识蒸馏)策略对整个结构进行知识蒸馏,从而得到所提出的MIE-YOLO。其整体网络结构如图1所示。
3.2. 多尺度边缘信息选择架构
原始的YOLO12框架由三个基本组件构成:骨干网络(Backbone)、颈部(Neck)和头部(Head),各自实现不同的功能。YOLO12的骨干网络是负责特征提取的核心组件。通过多层卷积操作和模块化结构,它将输入图像逐层转换为多尺度特征图,供后续检测任务使用。该子模块堆栈包括C3k2模块和A2C2f(区域注意力)模块,用于提取包含丰富语义信息的多尺度特征。
与先前版本相比,YOLO12引入了C3k2模块和A2C2f模块,取代了前几代使用的C2f模块。C3k2模块使用两个小核卷积替代一个大核卷积,旨在同时保留特征的全局和局部信息。A2C2f模块保持了大感受野,旨在以简单的方式减少注意力的计算复杂度,从而提高速度。然而,这些模块仍然包含大量的瓶颈(Bottleneck)结构,这可能导致梯度消失和特征冗余,削弱全局感受野的覆盖。
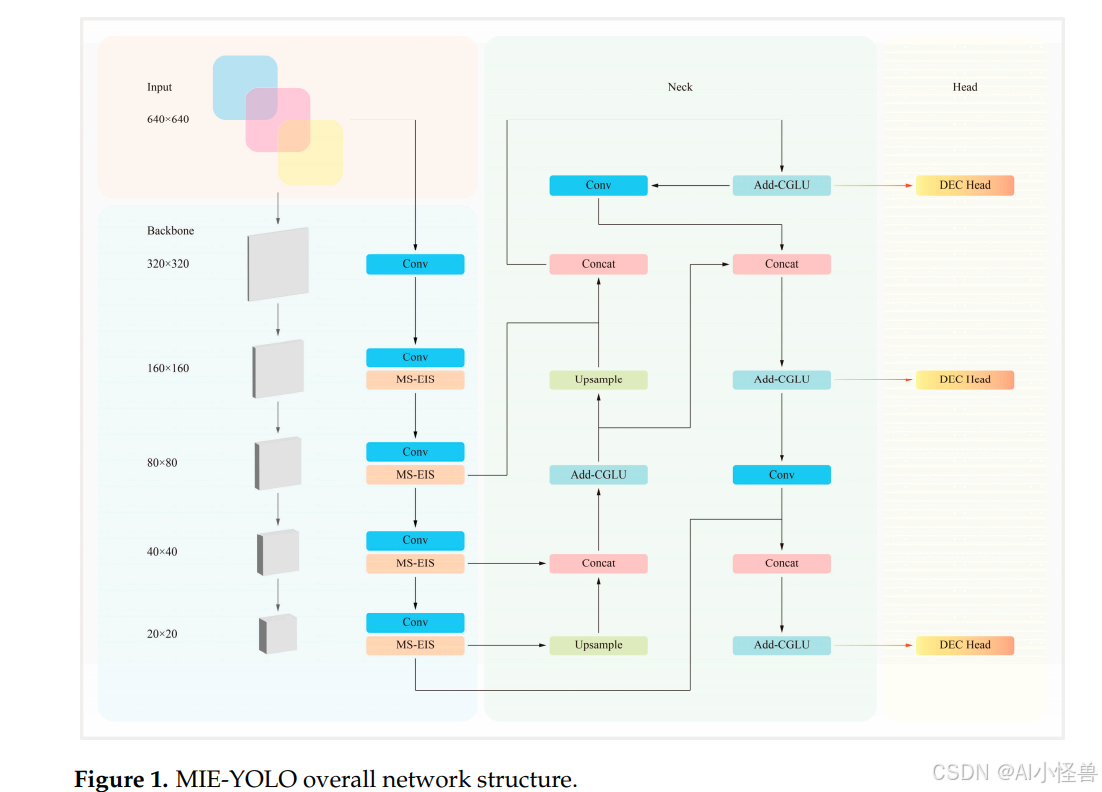
为应对这些挑战,对骨干网络架构中的C3k2和A2C2f模块进行了重新设计。具体而言,开发了一个新的EE(边缘增强器)模块,并融入了Cui等人33提出的DSM(双域选择机制),从而提出了一种新的MS-EIS(多尺度边缘信息选择)架构,以取代C3k2和A2C2f模块中的瓶颈结构。MS-EIS架构的结构如图2所示。
MS-EIS用集成的模块取代了YOLO12骨干网络中使用的简单瓶颈结构。该模块超越了原始的DSM,其结合了基于原理的多尺度池化与可学习的尺度权重、一条由高斯去噪平衡的基于拉普拉斯滤波的显式边缘增强路径、以及一个高效的深度可分离卷积预处理阶段,所有这些都通过一个有针对性的注意力方案进行融合。相较于简单地引用原始DSM,MS-EIS更具规范性和可复现性,因为它指定了具体的算子和超参数,引入了DSM所缺乏的显式信号处理风格的边缘路径,并且它以少量增加的结构为代价,换来了边界和小目标敏感性的显著提升,同时保持了较低的计算开销。
边缘信息是区分杂草与作物的一致且具有判别性的线索,特别是在生长早期,当颜色和纹理信号较弱且植物个体较小时,叶片轮廓、边缘和叶脉定义的边界就成为区分物种最可靠的特征。边缘编码的形状和边界几何对光照变化和颜色相似性较不敏感,它们为微小和部分遮挡的植物提供了强大的定位锚点,并且通过揭示独立的对象轮廓,有助于消除重叠实例的歧义。MS-EIS将边缘线索视为一等信号而非附带特征,因此它通过拉普拉斯路径显式提取高频内容,然后用高斯去噪稳定该信号,同时多尺度池化和可学习的尺度权重允许模块针对给定场景或生长阶段强调最相关的边缘尺度。这与常见的注意力模块(如CBAM)不同,后者对现有特征图上的通道和空间位置进行重新加权,但不会创建专用的、信号处理风格的边缘通道;也不同于简单的索贝尔(Sobel)融合,后者注入固定的单尺度梯度,会放大噪声且无法适应尺度、模糊或成像条件。通过结合原理性的滤波、自适应尺度加权和高效的深度可分离预处理,MS-EIS放大了真实的边界线索,同时抑制噪声并保持低计算量,与通用的注意力机制或朴素的固定边缘融合相比,在杂乱的农业场景中实现了更清晰的边界、更好的小目标定位和更强的鲁棒性。
MS-EIS是一个专为目标检测、分割和特征提取任务优化的深度学习特征增强模块。其主要目标是通过多尺度特征融合和边缘信息增强,提高模型在复杂场景中的目标检测能力。该架构结合了多尺度特征提取、边缘信息增强、深度卷积操作和双区域聚焦注意力机制,以优化特征提取的有效性和鲁棒性。MS-EIS架构的核心思想是利用多尺度平均池化和自适应卷积来提取不同层次的特征信息,结合边缘增强模块进行特征比对和补充,最终通过双区域选择机制实现高效的特征融合。这一过程使MS-EIS能够同时捕捉局部细节和全局上下文信息,在提高检测精度的同时降低计算成本。
具体而言,首先使用四个并行的AAP(自适应平均池化)模块进行多尺度自适应平均池化,以提取不同尺度的特征信息。然后将其与卷积操作结合,获得丰富的语义信息。其核心思想是利用不同尺度的池化操作来捕捉具有不同感受野的全局和局部信息。假设输入特征为X,输入特征图可表示如下:
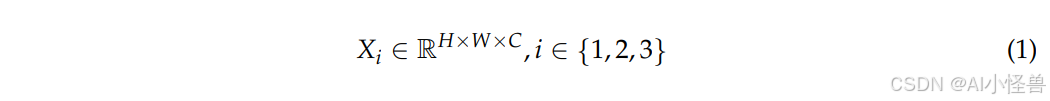
其中实数空间R用于描述特征图的范围,i主要用于索引不同尺度的特征提取过程,具体表示第i个尺度的特征处理步骤。H和W分别是特征图的高度和宽度,C是输入和输出特征的通道数。将多尺度自适应池化与输入特征图上相应的卷积操作结合,构建特征金字塔:
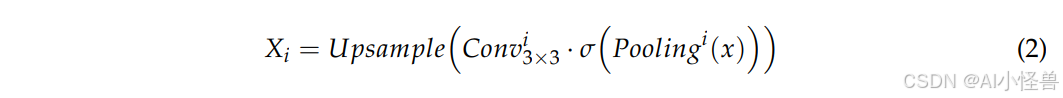
其中,Pooling表示尺度为i的自适应池化操作。通过不同尺度的池化操作,提取特征图的不同分辨率版本,使得网络能够同时关注大目标、中目标和小目标。Conv表示第i级的卷积操作。第一个空间维度为1的卷积用于降维并增强通道间的信息交互,为后续卷积操作提供更有效的输入。第二个空间维度为3的卷积进一步提取局部特征,提高边缘和小目标的检测能力。σ表示归一化和非线性激活操作,通过相应的激活函数变换特征,使其更具表现力。Upsample表示上采样操作,用于恢复输入特征的大小。
不同尺度的池化保留了多层次特征,提高了对小型目标和复杂背景的适应性。多尺度池化还提取了不同大小的局部信息,有助于捕捉图像的多层次特征。然后使用Softmax对不同尺度的特征进行加权,从而实现更平滑的融合,无需依赖手动配置的超参数。最后,融合后的多尺度特征ƑMS计算如下:
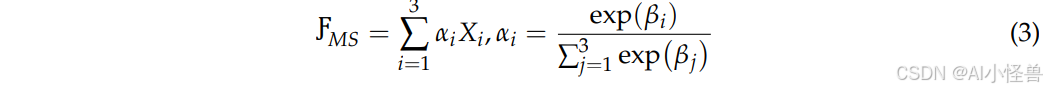
其中ƑMS表示最终融合的多尺度特征,α是归一化的特征加权系数,用于对不同尺度的特征图进行加权。β是可学习参数,表示特征加权系数的原始权重。βi是通过神经网络训练获得的标量值,决定了αi的大小。j是索引变量,用于指示所有尺度上计算的特征权重求和范围。softmax机制自适应地调整不同尺度特征的权重,使模型能够自动选择最重要的尺度特征。此外,引入可学习参数允许不同尺度的特征对最终融合做出不同贡献,提高了特征提取的灵活性。最终融合的多尺度特征同时考虑了大目标和小目标的特征表示。
我们将每个β初始化为零,这样softmax在开始时为各尺度生成相等的权重,提供一个中性的基线。然后每个β作为标量参数通过常规的反向传播过程学习,但采用保守的优化设置,例如降低学习率、专用的学习率乘数以及最小化或无权重衰减,以避免融合分布发生突然或有偏的变化。如果训练不稳定,可以使用简单的稳定器,例如在短暂的预热期内冻结β、应用梯度裁剪,或者添加大于1的softmax温度以平滑所得的权重。在训练过程中,我们监控生成的α值,并进行消融实验,比较固定与可学习的β,以验证学习尺度加权的好处。
EE(边缘增强器)模块是MS-EIS架构中的关键组件。其主要功能是解决传统瓶颈架构无法提取边缘信息的问题,并提高识别目标边缘轮廓的能力。EE模块的核心思想是使用高斯滤波和拉普拉斯算子提取边缘信息,然后通过卷积融合特征图。在此步骤中,首先计算边缘信息:
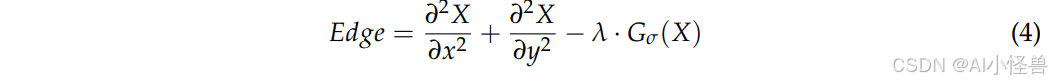
其中,Edge表示提取的边缘信息,偏微分方程表示拉普拉斯运算。Gσ表示标准高斯核,显示高斯滤波结果,主要用于去噪。λ是一个平衡参数,用于控制高斯滤波和梯度增强的加权。
接着,使用一个标准的卷积层对边缘特征进行非线性变换,然后将其添加到原始特征中,从而获得边缘特征:
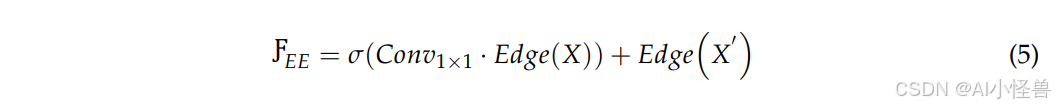
其中,EE 代表最终增强的边缘特征,σ 表示非线性变换。EE模块通过边缘增强提高了模型对边界信息的感知能力,有助于实现精确的目标定位。此外,它结合了高斯滤波和拉普拉斯算子,在增强边缘的同时最大限度地减少了噪声干扰。
总之,EE模块提取边缘信息,增强了网络对边缘的敏感性。这对于目标检测和语义分割等视觉任务至关重要。随后,Concat模块对不同尺度提取的特征进行插值以对齐到同一尺度,并将它们拼接起来。最后,一个标准卷积层融合这些特征,形成一个统一的特征表示,从而提高了模型对多尺度特征的感知能力。
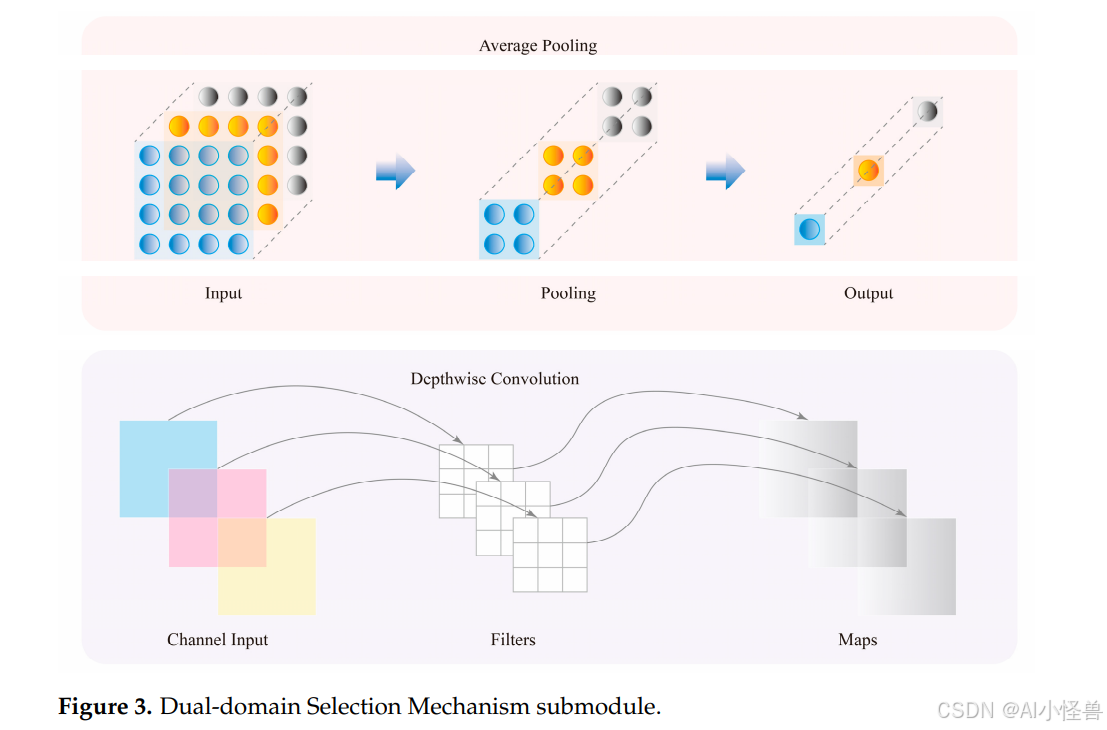
最后,将所有特征输入到DSM(双域选择机制)中。该注意力机制旨在从多尺度边缘信息中高效地选择与目标任务高度相关的关键特征。通过聚焦于图像中更重要的区域,例如复杂的边缘和高频信号,该机制能从多尺度特征中自适应地选择具有更高任务相关性的特征,显著提高了特征选择的准确性和模型的整体性能。图3展示了DSM中每个子模块的详细结构。
DSM模块通过在通道域和空间域中选择最重要的特征来解决特征冗余问题,从而提高检测精度。首先,使用两次深度可分离卷积来降低计算复杂度,同时增强特征表示。深度可分离卷积将标准卷积分解为深度卷积和逐点卷积两个步骤,减少了参数数量和计算量。标准卷积和深度可分离卷积的计算复杂度对比如下:
其中,Conv表示标准卷积,DWConv表示深度可分离卷积,K是卷积核大小,C_in和C_out分别是输入和输出的通道数,H和W是特征图的高度和宽度,DW是最终激活的深度可分离卷积输出,O代表计算复杂度。左侧表示标准卷积,右侧表示深度可分离卷积。与标准卷积相比,深度可分离卷积将计算复杂度降低了大约K²倍。当K为3时,计算复杂度降低了约9倍。
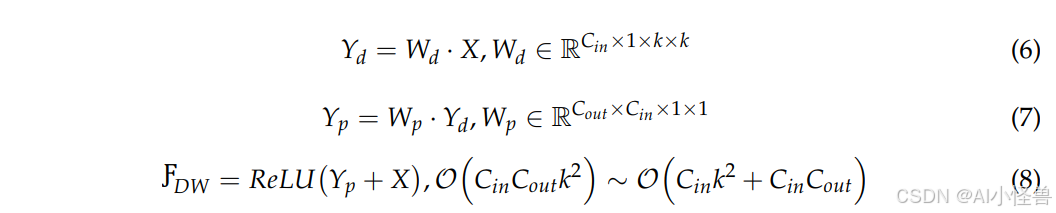
双区域信息选择机制增强了通道域和空间域的信息表达能力。也就是说,DSM模块结合了CA(通道注意力)和SA(空间注意力)机制,使模型能够关注目标的显著特征,同时忽略不重要的信息。首先,在通道维度计算特征重要性权重:
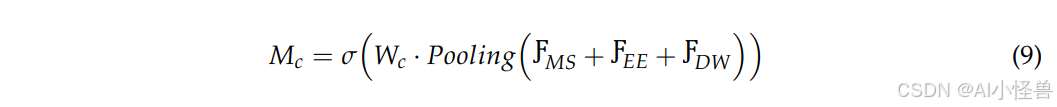
其中,Mc 代表通道注意力权重矩阵,用于评估不同通道的重要性。W_c 代表用于通道加权的可学习参数矩阵,用于调整不同通道的贡献。Pooling 表示GAP(全局平均池化)操作,用于获取每个通道的全局信息。i 和 j 分别代表特征图的像素值。
与传统注意力机制相比,通道注意力仅涉及通道维度而不考虑空间信息,因此计算成本较低。之后,在空间维度计算特征响应:
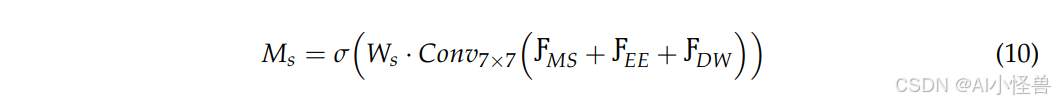
其中,Ms 代表空间注意力权重矩阵,用于指示不同空间位置的重要性。W_s 是用于空间加权的可学习参数矩阵,用于调整不同空间区域的贡献。大核卷积用于在大范围内提取空间特征,增强了目标的完整性和形状感知能力。
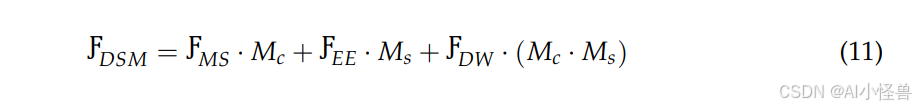
与通道注意力相比,空间注意力直接关注特征图的空间分布,突出重要的目标区域,同时抑制不相关的区域。通过学习不同空间位置的权重,模型能够更准确地定位目标并减少背景干扰。最终,DSM模块的输出如下:
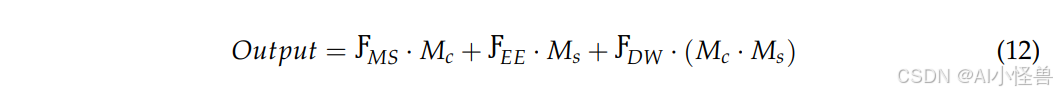
其中,DSM代表双区域选择机制的最终输出特征,· 表示逐元素乘法,用于对不同特征图进行加权。经过深度加权的特征同时受到通道注意力和空间注意力的影响,确保了最终融合的特征在通道和空间维度上都被最优选择。由于注意力机制抑制了不相关的特征,DSM模块输出的特征图包含更紧凑的信息,从而提高了计算效率。对于检测任务,关键目标的边缘和语义特征得到了显著增强,这有助于提升小目标检测能力。
最后,DSM模块输出的特征通过一个标准卷积层进行变换和融合,得到MS-EIS架构的最终输出:
Output = Conv(DSM) (12)
其中,Output 代表 MS-EIS 架构的特征输出。标准卷积层作为最终的特征映射单元,它优化了跨通道信息融合,使得多尺度特征提取和双区域信息选择能够协同工作,提高了目标检测的准确性和鲁棒性。
总的来说,MS-EIS 具备高效的多尺度信息整合能力。其核心组件包括自适应平均池化、边缘增强模块和双区域信息选择机制,它们协同工作以提升目标检测性能。首先,MS-EIS 使用 AAP 结合卷积操作来增强对不同尺度目标的感知,提高检测的尺度适应性。其次,EE 模块通过边缘信息增强优化了目标轮廓特征,使目标在复杂背景中更加突出,从而提高了目标检测的鲁棒性。同时,DSM结合通道注意力和空间注意力,在通道域和空间域筛选关键特征,有效减少了冗余信息,进一步提升了检测精度。
此外,MS-EIS 采用轻量化的池化和注意力加权机制进行高效的信息筛选与融合,在确保高精度的同时也兼顾了计算效率,使其适合实时任务。针对小目标检测,空间注意力增强了目标边缘信息,EE模块强化了目标轮廓,多尺度特征提取则进一步增强了小目标的显著性和可检测性。总体而言,MS-EIS 架构通过多尺度特征提取、边缘信息增强和双区域信息选择的协同优化,实现了高效且准确的目标检测。
3.3. 加性卷积门控线性单元金字塔网络
原始 YOLO12 的颈部(Neck)部分位于骨干网络(Backbone)和头部(Head)之间。其主要功能是融合和增强骨干网络提取的多尺度特征,并将其传递给头部进行预测。其特征金字塔结构结合了上采样和跨尺度连接,实现了对多尺度目标的自适应检测,同时兼顾了全局上下文和局部细节。虽然颈部在一定程度上简化了计算复杂度,但上采样过程可能导致细节丢失或定位精度下降,尤其是在检测小目标或边界模糊的目标时。同时,多尺度特征拼接容易引入信息冗余,干扰有效特征的表达,并增加误检或漏检的可能性。此外,深层特征可能会覆盖浅层特征的局部细节,削弱了对小目标的捕捉能力。
为了在确保实时目标检测的同时提高精度,设计了一种新的 Add-CGLU(加性卷积门控线性单元)金字塔网络来优化颈部部分。该架构借鉴了 Zhang 等人34提出的 CAS-ViT 结构,用加性块(Additive Blocks)替代了堆叠的瓶颈(Bottleneck)结构。新的 Add-CGLU 金字塔网络在设计时借鉴了 Shi35提出的卷积 GLU(门控线性单元)框架。Add-CGLU 金字塔网络的结构如图 4 所示。
Add-CGLU 金字塔网络用加性块(Additive Blocks)取代了堆叠的瓶颈结构,这些加性块结合了三个协调的组件:一个通过标准卷积、批归一化和 GELU 保留浅层空间细节的局部感知(LP)阶段;一个使用加性注意力方案来避免传统自注意力二次方成本的卷积加性令牌混合器(CATM);以及一个将深度卷积与门控路径融合以实现高效特征过滤的卷积门控线性单元(CGLU)。交替的加性块和图像块分割(Patch Segmentation)为颈部提供了可扩展的多尺度融合模式,而 Stem 和池化头部(pooled head)则保持了集成过程的简洁性。与 CAS-ViT 和普通的 GLU 相比,此设计更加以卷积为中心,计算效率更高,并且对算子和超参数的规定更为明确;它在更好地保留局部细节的同时仍能捕捉全局上下文,减少了注意力开销,并且更容易为实时和小目标检测任务进行复现和部署。
尽管门控机制(例如门控线性单元)在 Transformer 和 CNN 架构中已被广泛采用以调节信息流,但本文提出的加性融合与门控相结合代表了一种独特的结构创新,而非简单地应用现有组件。在该设计中,加性融合以互补的方式整合多个特征流,然后门控操作选择性地过滤和强调信息丰富的模式。与通常依赖于线性求和或恒等捷径(identity shortcuts)而不进行自适应特征加权的传统卷积层或标准残差块相比,这种顺序协调实现了更精确的特征调制。因此,该网络实现了更高的计算效率,因为加性融合减少了冗余计算,并缓解了与传统自注意力相关的二次方复杂度,而门控机制确保了只有显著的特征被向前传播。实证表明,这种协同作用改善了对细粒度局部细节的表示,并加强了全局上下文建模,从而带来了更好的检测性能,特别是对于小目标和实时场景,且没有增加模型的参数量或推理开销。
在 Add-CGLU 金字塔网络中,Stem 模块位于初始输入阶段,负责将原始输入转换为合适的特征表示。交替的加性块和图像块分割模块将特征图划分为多个小块,而分类检测头则对最终特征进行全局池化并输出分类结果。
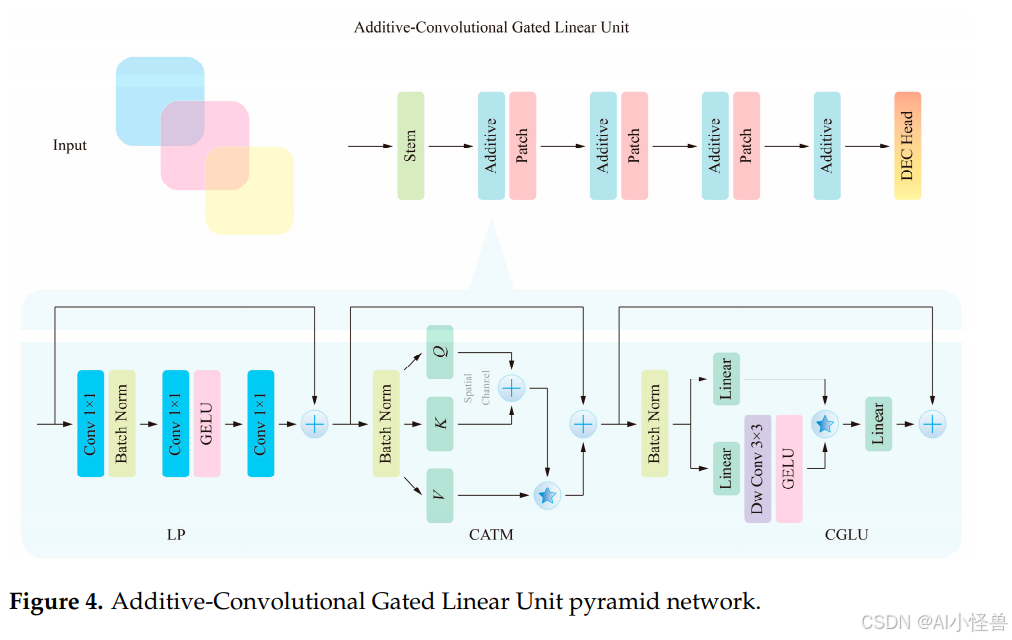
加性块是 Add-CGLU 架构中的核心模块,包含 LP(局部感知)机制、CATM(卷积加性令牌混合器)和 CGLU(卷积门控线性单元)。LP 机制利用局部整合从输入特征中提取局部空间信息,克服了标准卷积层的感受野限制。它使用三个标准卷积层、一个批归一化(BN)层和一个非线性激活函数 GELU(高斯误差线性单元)来初步处理输入特征。假设 x₁ 是输入特征,使用 LP 机制提取局部空间特征的过程可表示如下:
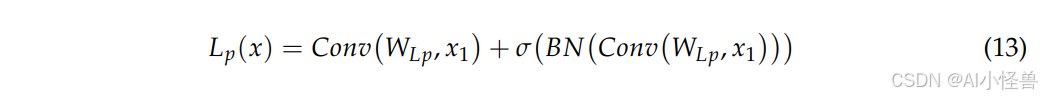
其中 Lp 表示局部感知输出,W 是权重函数,BN 表示批归一化,σ 是激活函数。
输入特征经过 LP 机制感知和提取后,被传递给 CATM 组件。首先,使用一个批归一化层和独立的线性变换将输入信息分成三部分:Q、K 和 V,分别对应于查询(query)、键(key)和值(value)矩阵。此过程使用上述输入特征 x₂ 来演示:
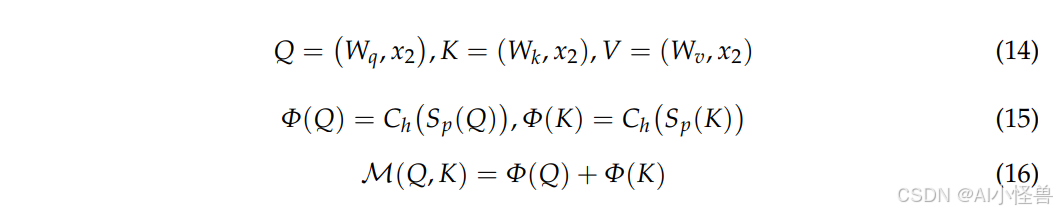
其中 Φ 是上下文映射函数,Ch 代表通道注意力机制,Sp 代表空间注意力机制,Ϻ 是一个镜像函数。
总之,CATM 旨在通过其核心的加性注意力机制捕捉全局上下文信息。结合令牌混合器的结果,该架构在通道和空间两个层面都实现了优化的注意力机制。这种加性方法降低了计算开销,同时保持了模型捕捉全局依赖关系的能力,避免了传统自注意力机制中常见的矩阵乘法的二次方复杂度。CATM 的最终输出如下:
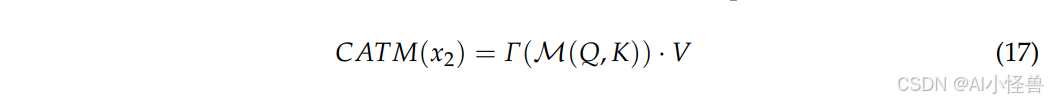
其中 Γ 是一个整合上下文信息并包含必要信息交互的线性变换。
输入特征经过 CATM 增强后,再由 CGLU 进行处理。CGLU 将深度卷积与门控机制相结合,实现了高效的特征过滤和空间感知。一个由批归一化层、标准卷积层和 GELU 激活函数组成的双分支结构处理空间信息,增强了模型捕捉细粒度特征的能力。CGLU 模块的最终输出是两个分支结果的逐元素相乘:
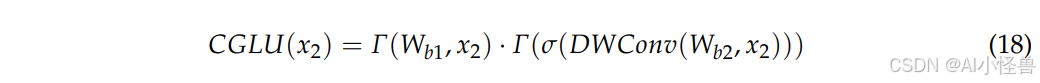
其中 W_b₁ 和 W_b₂ 分别对应每个分支上的权重。CGLU 基于最近邻图像特征融合的通道注意力机制,以更少的计算参数实现了通道混合器的注意力,从而增强了模型的鲁棒性。
3.4. 细节增强卷积检测头
原始 YOLO12 的头部是整个网络结构的最后阶段,负责生成目标检测和分类的最终预测。其核心任务是处理从颈部传递来的特征图,最终输出图像中目标的边界框和类别标签。YOLO12 的头部通过进一步的卷积操作和优化模块来细化特征,采用 C3k2 模块来提高计算效率和特征表示能力。它还融合了 CBS(卷积-批归一化-SiLU)以增强模型的稳定性和非线性表示能力。
然而,原始头部也存在一些缺点。例如,对于小目标的定位精度较低,可能是由于上采样或特征融合过程中的细节丢失,导致边界框预测不准确。在密集场景中也容易受到背景干扰,增加了误检或漏检的风险。此外,对于高分辨率输入的计算开销较大,限制了其在极端实时场景中的适用性。为了解决这些挑战,对原始的 YOLO12 头部框架进行了重新优化,并提出了一种新的 DEC(细节增强卷积)检测头。DEC 检测头的结构如图 5 所示。
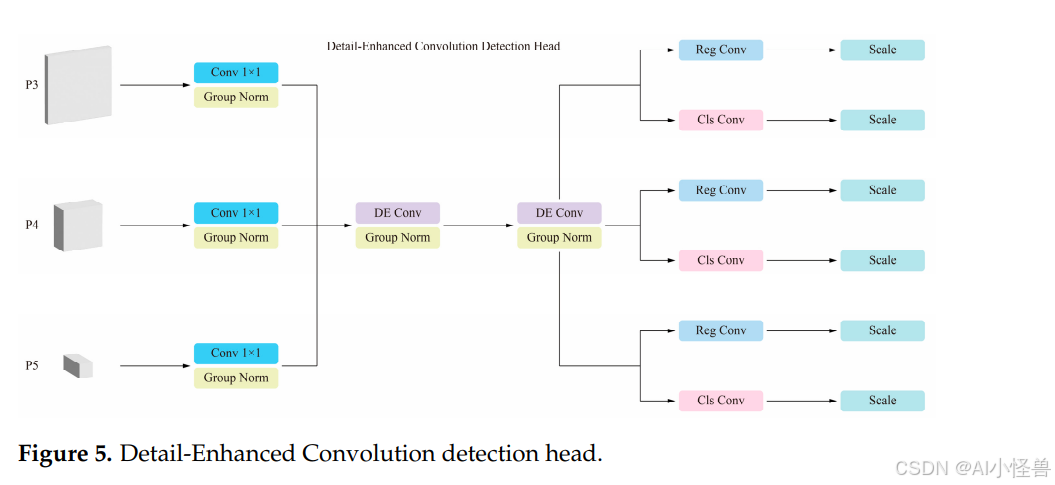
DEC 检测头的设计目标是通过一个共享的特征增强模块来提高细粒度特征提取能力,旨在优化复杂场景中小目标的检测效率。DE Conv(细节增强卷积)是 DEC 检测头的核心组件,最早由 Chen 等人36在 DEA-Net(细节增强注意力网络)中提出。通过对输入特征进行增强,细节信息得到更好的保留。在特征融合阶段,DE Conv 在不同特征尺度之间共享权重信息,增强了特征一致性并降低了计算成本。
具体而言,DE Conv 结合了标准卷积的特征提取能力和细节增强的归一化策略。它使用 GN(组归一化)层对特征进行分组和归一化,减少小批量训练中统计噪声的影响,并避免 BN(批归一化)在小批量训练时的不稳定性。DE Conv 首先对输入特征 x₃ 进行降维并提取空间特征:
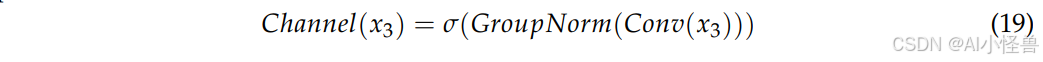
其中 σ 是 Sigmoid 激活函数,确保输出范围在 0 到 1 之间。然后使用内容引导注意力机制为每个位置生成空间权重:
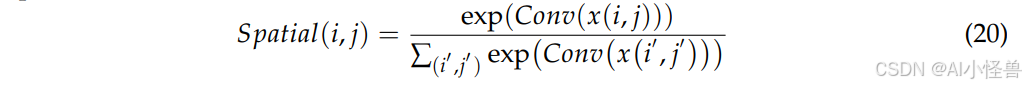
随后调整卷积核的权重分布,以更好地捕捉空间特征的细节。特征的权重分布也随之动态调整,以适应目标的局部变化。在提高深度建模能力的同时,分组机制减少了计算冗余,确保了特征的全局表示能力。DE Conv 的动态核生成过程如下:
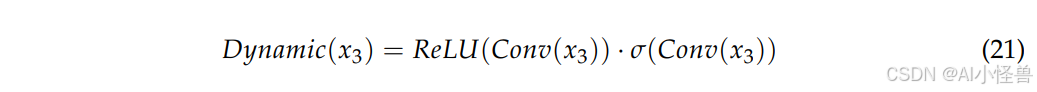
DEC 检测头的末端包含两个子模块:Cls Conv(分类卷积)和 Reg Conv(回归卷积),分别用于目标类别预测和边界框回归。Cls Conv 将特征图映射到类别空间,并使用 Sigmoid 激活函数生成每个锚框的类别概率,而 Reg Conv 输出每个锚框边界框的回归参数。Cls Conv 中的参数也是共享的。无论是小目标、中目标还是大目标,对于分类学习来说都是相同的目标。DEC 检测头使用可分离的损失函数,包括分类损失和回归损失,可表示如下:
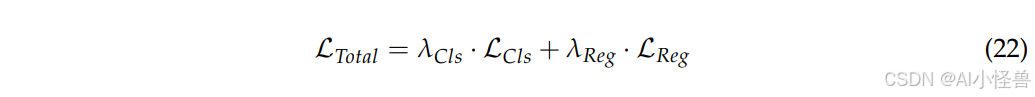
其中 L 代表分类和回归损失,λ 是对应的权重超参数。此外,Reg Conv 中的共享参数需要考虑目标尺度不一致的影响,因此通过 Scale 层对特征进行缩放。Scale 操作也是共享的,允许回归输出进行调整以适应不同尺度的目标。
在 DEC 检测头中,通过使用空洞卷积和内容自适应的滤波器选择进一步细化了细节增强卷积模块。具体来说,空洞卷积在不增加参数数量的情况下扩大了感受野,使网络能够捕捉小目标周围更广泛的上下文信息,同时保留细粒度的局部特征。同时,DE Conv 根据内容引导的注意力图动态调整其卷积核,使网络能够聚焦于信息密度高的区域,例如边缘、角点或模糊的目标边界。这种组合确保了即使是小的或被部分遮挡的目标也能获得增强的特征表示。此外,DE Conv 在每个加性块内使用一组多尺度滤波器,这些滤波器通过空间和通道注意力机制进行自适应加权,使得头部能够选择性地放大相关特征,同时抑制背景噪声。通过整合这些机制,DEC 检测头细化了对小目标和模糊边界的定位,因为动态生成的核强调了关键的空间线索和依赖于上下文的特征变化,减少了边界框预测的错位,提高了在密集或杂乱场景中的精确度和召回率。
总体而言,DEC 检测头通过动态感受野生成和内容引导注意力,实现了对特征图的细粒度增强。其核心是结合动态通道权重和空间权重,生成高度自适应的卷积核,以捕捉目标的局部细节和全局上下文信息。通过多尺度特征融合和精细化处理,它有效提升了小目标检测能力,同时确保了在复杂场景中准确预测目标类别和边界。
3.5. 双重自知识蒸馏策略
本文旨在消除所有轻量化改进对精度的影响,并对模型进行知识蒸馏。该方法最早由 Hinton 等人37提出并应用于分类任务。其原理基于模型之间的知识传递和迁移。知识蒸馏通常通过从大型教师模型转移来的额外监督来训练轻量化的学生模型。教师模型是一个复杂且精确的模型,通常具有大量参数和复杂的结构。它在训练期间通过学习大量数据来拟合目标任务,以提供高精度的预测结果。学生模型是一个简化的模型,通常参数更少,结构更简单。其目标是从教师模型中蒸馏知识,学习教师模型的预测行为,以便在降低模型复杂性的同时保持高性能。
基于知识蒸馏的方法大致可分为特征蒸馏和逻辑蒸馏,每种方法侧重于不同层次的信息传递。逻辑蒸馏主要关注教师模型的最终输出和类别概率分布,通过模仿这些概率来优化学生模型的决策。然而,由于逻辑蒸馏只利用了教师模型的最终预测,而忽略了模型的内部特征表达能力,这种方法可能无法充分发挥教师模型的优势,特别是在学生模型容量较小,难以完全复制教师模型学习能力的情况下。
相比之下,特征蒸馏侧重于教师模型和学生模型之间中间层特征的一致性,使学生模型能够直接学习教师模型的深层特征表示,而不仅仅是最终的类别输出。具体而言,特征蒸馏通过诸如对齐特征图或指导学生模型学习教师模型的注意力分布等方法,使学生模型的特征更接近教师模型。这使学生模型能够更好地捕捉数据的关键特征,从而提高表示能力和泛化性能。由于特征蒸馏比逻辑蒸馏提供了更丰富的信息,因此在需要深度特征表示的任务中,如目标检测和图像分割,它显得尤为重要。
与逻辑蒸馏相比,特征蒸馏的优势在于,它不仅提高了学生模型的最终预测能力,还增强了其在不同层次的特征学习能力,使其能够在参数较少的情况下保持强大的特征提取能力。这种方法特别适用于训练轻量化模型,能有效弥补因模型容量不足造成的性能损失,使小模型能以较低的计算成本接近大模型的性能。因此,在对特征学习要求高的任务中,如计算机视觉,特征蒸馏已成为提升模型性能的重要手段,并广泛应用于模型优化过程。
基于特征蒸馏的原理,Shu 等人38提出了一种通道知识蒸馏方法。基于此原理,本文提出了一种新的 DS(双重自知识蒸馏)策略。具体来说,将使用 YOLO12-N 训练的模型定义为学生模型,将使用 YOLO12-S 训练的模型定义为教师模型,进行第一次知识蒸馏。随后,将得到的模型再次定义为学生模型,并将该学生模型的通道数翻倍后定义为教师模型,进行第二次知识蒸馏。
为了更好地利用模型中每个通道的知识信息,我们对教师网络和学生网络之间对应通道的激活值进行软对齐。我们将教师模型和学生模型分别定义为 T 和 S,T 和 S 的激活图分别定义为 y_T 和 y_S。该通道的损失可表示为:
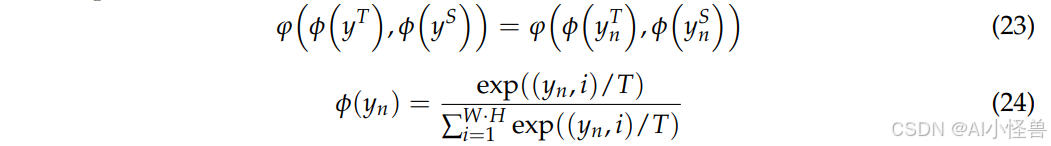
其中 n 代表通道索引,i 代表通道的空间位置,T 是一个温度超参数。此方法在复杂场景目标检测任务中归一化每个通道的激活图。每个通道的激活往往编码了场景类别的显著性。对于每个通道,DS 蒸馏策略指导学生网络专注于模拟具有显著激活效果的区域,从而在目标检测任务中实现更准确的定位。
双重自知识蒸馏策略使用两轮顺序的蒸馏,每轮都配合双路径监督。第一轮,一个容量更大的 YOLO12-S 教师模型引导一个紧凑的 YOLO12-N 学生模型,塑造出鲁棒的通道响应和粗略的注意力模式。之后,将得到的学生模型再次从一个通道数翻倍的放大版兄弟模型进行蒸馏,从而在不改变学生模型推理图的情况下,使其接触到更丰富、更高阶的特征组合。每一轮都联合优化原始检测目标以及逻辑层蒸馏、中间特征对齐和通道级对齐损失。在实践中,第一轮强调通道级对齐以建立稳定的显著性,第二轮则更侧重特征对齐以利用放大版教师模型更精细的特征组合。这种渐进的、双路径的设计缩小了师生容量差距,稳定了训练,让学生先学习粗略的显著性,再吸收更精细的模式,从而在不增加推理成本的情况下,改善了小目标定位和边界清晰度。
与单阶段蒸馏相比,所提出的两阶段方法减少了教师和学生之间的容量差距,并产生了更有效、更稳定的监督。在第一阶段,一个强大但现实的教师模型在轻量级学生模型中塑造了鲁棒的通道响应和注意力模式,这比一步到位地模仿一个非常大的模型要更容易学习。在第二阶段,学生受益于一个容量更大的教师模型,该模型展示了更丰富、更细粒度的特征组合和更高阶的通道关系,有效地细化和扩展了学生的特征表示,而不改变其推理成本。这种渐进式学习策略带来了更平滑的优化、更快的收敛和更好的泛化能力,同时它还起到了正则化的作用,减少了过拟合并提高了在多变田间条件下杂草检测的稳定性。
四、实验
4.1. 杂草数据集
本文训练的所有模型均基于自定义的杂草数据集,该数据集用于精准农业中的实时田间杂草识别与针对性喷药。杂草数据集包含9257张图像,全部采集自中国南方典型的杂草生长环境,主要覆盖广东和福建等省份的路边、田埂、山坡草地和荒地等开阔或半开阔区域,以确保样本的多样性和代表性。数据集中原始图像及其标注的可视化示例如图6所示。

对样本图像的目视检查显示,许多图像帧中的实例密度很高,且单个植物之间经常存在重叠或部分遮挡。某些类别在叶片形状、大小和颜色上表现出较大的类内差异,而其他类别在视觉外观上非常相似,这增加了类别间混淆的风险。背景高度异质,混合了土壤、草、枯叶和碎屑,这些因素引入了纹理噪声并降低了杂草与周围环境的对比度。图像间的拍摄条件差异很大,包括拍摄距离、视角、光照以及偶尔的运动模糊,产生了显著的尺度和外观变化。
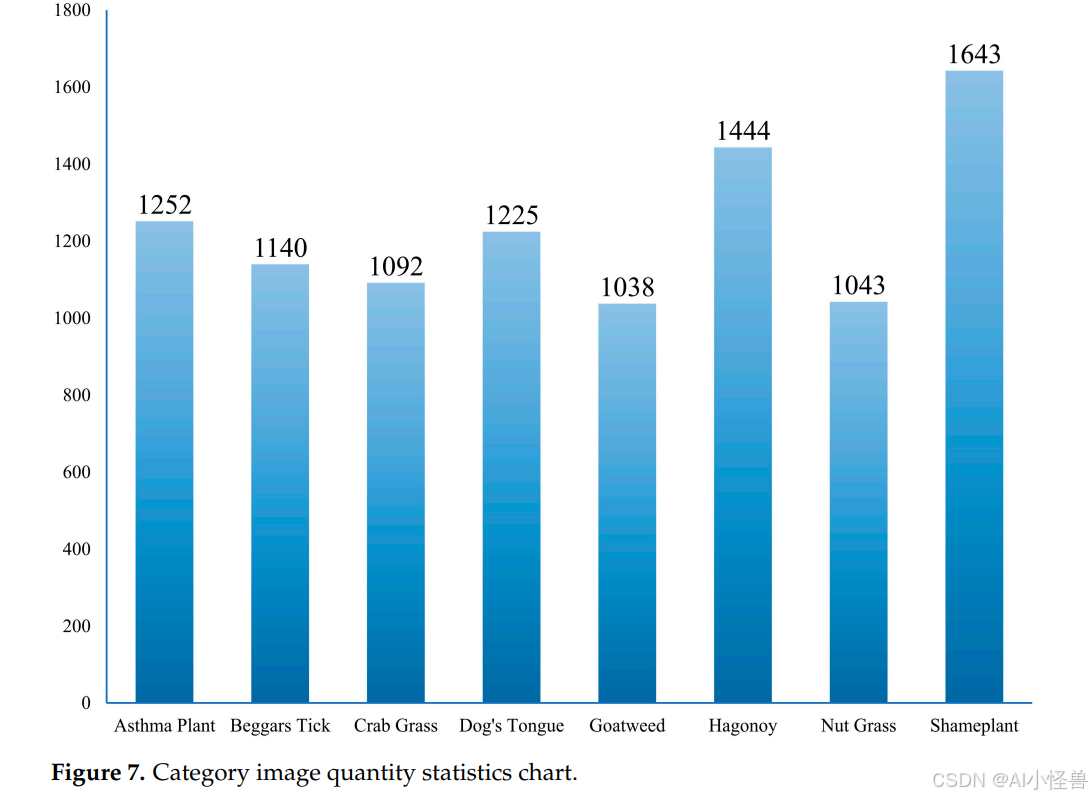
训练集和验证集按9:1的比例划分,训练集共8331张图像,验证集926张图像。杂草数据集的标注类别包括哮喘草、鬼针草、马唐、狗舌草、山羊草、哈贡草、莎草和羞羞草。各分类的具体图像数量如图7所示。
杂草数据集仅覆盖中国南方地区,这可能限制在其上训练的模型对其他地区的泛化能力。物种组成、背景纹理、土壤、光照、季节性生长阶段和相机设置等方面的差异可能产生系统性偏移,从而在模型应用于其他地方时降低其性能。为了帮助评估泛化能力,我们补充了在法国和美国北达科他州采集的外部数据集的实验。减少地理偏差将需要在模型部署到新区域之前,进行更广泛的采样、有针对性的数据增强以及领域自适应微调。
4.2. 训练参数
本文提出的模型基于YOLO12-N,从头开始训练了300个周期,未使用预训练权重。对于所有后续实验,输入图像分辨率均为640像素,批处理大小为16,工作进程数为8。实验平台基于Windows 11操作系统,配备AMD Ryzen 9 5900HX CPU(64 GB RAM)和NVIDIA GeForce RTX 3080 GPU(16 GB VRAM)。使用的深度学习框架为Torch 2.2.2 + cu121, torchvision 0.17.2 + cu121, CUDA 12.1.105和cuDNN 8.9.7.29。
4.3. 评估指标
本文使用常见的评估指标来评估MIE-YOLO在精准农业中的杂草检测性能,同时兼顾准确性和速度。这种划分旨在同时关注精度和速度,从而实现对检测结果的全面评估,并突出模型的优势和劣势。
精度指标主要关注模型的检测准确性和完整性,包括精确度、召回率、F1分数和平均精度均值。这些指标直接衡量模型的准确性和全面性,是评估其在杂草检测任务中表现的关键。精确度、召回率和F1分数的计算公式如下:
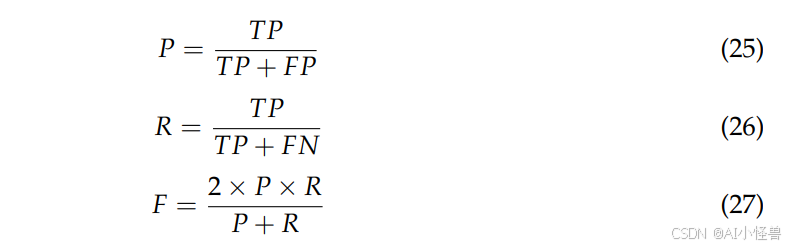
其中,P代表精确度,R代表召回率,F代表F1分数。公式中的TP表示被正确预测为正样本的数量,即正确检测到的目标数量。FP表示被错误预测为正样本的数量,即误报数量。FN表示被错误预测为负样本的数量,即漏报数量。平均精度是通过计算精确度-召回率曲线下的面积得到的,平均精度均值则是取平均值:

其中 P(R) 是一条显示每个检测对象的精确度随召回率变化的曲线。n是检测类别的总数,即8个,包括哮喘草、鬼针草、马唐、狗舌草、山羊草、哈贡草、莎草和羞羞草。
速度指标侧重于模型在训练和推理过程中的计算效率和运行速度,反映了模型在相应硬件条件下的计算负载和处理速度。示例包括模型的参数量、浮点运算量、模型大小和每秒帧数。标准FPS计算公式如下:
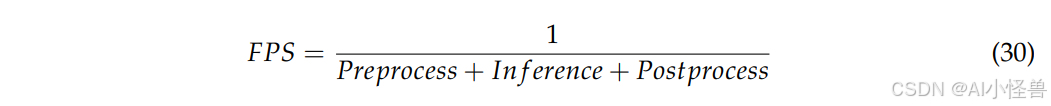
其中标准FPS值是总耗时的倒数,总耗时为图像预处理、模型推理和后处理时间之和。
五、讨论
5.1. 模型对比实验分析
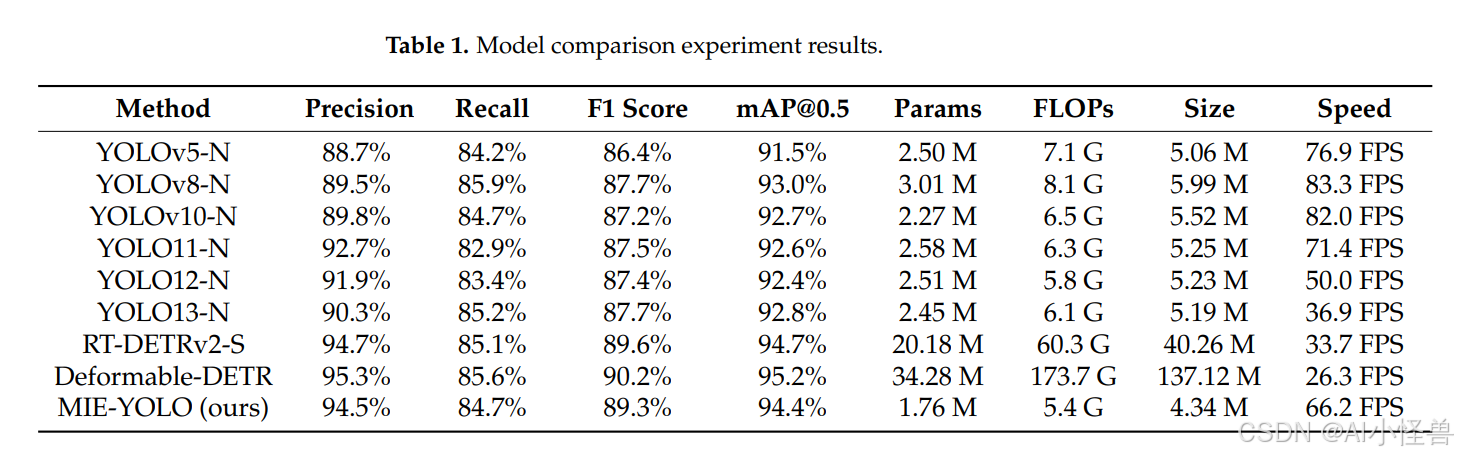
为了全面评估MIE-YOLO的性能,将其与其他经典目标检测算法进行了比较。所有模型均从头开始训练,未使用预训练权重,并在AMD Ryzen 9 5900HX CPU和NVIDIA GeForce RTX 3080 GPU上进行了测试。模型对比实验的结果如表1所示,其中包括精确度、召回率、F1分数、平均精度均值、参数量、浮点运算量、模型大小和每秒帧数等评估指标。
MIE-YOLO以YOLO12-N算法为基准模型。对比的算法包括YOLOv5-N(YOLOv5的最小版本)、YOLOv8-N(YOLOv8的最小版本)、YOLOv10-N(YOLOv10的最小版本)、YOLO11-N(YOLO11的最小版本)、YOLO12-N(YOLO12的最小版本)、YOLO13-N(YOLO13的最小版本)、RT-DETRv2-S(RT-DETRv239的最小版本)和Deformable-DETR(用于端到端目标检测的可变形Transformer40)。
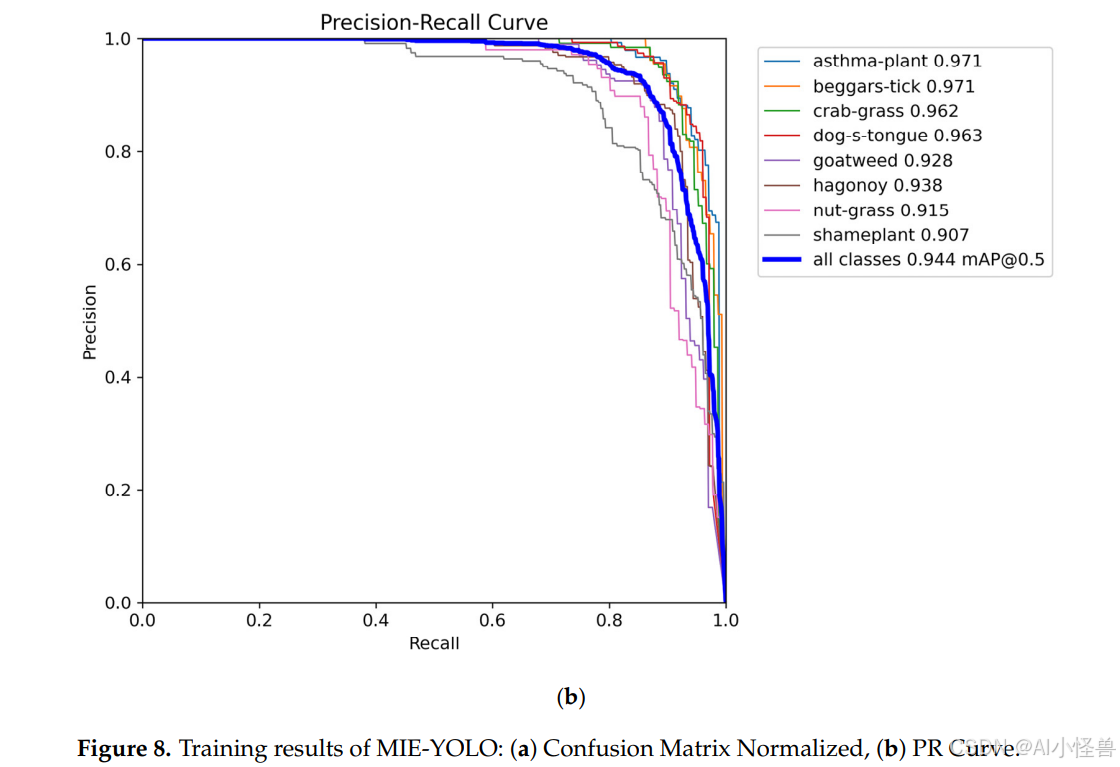
实验结果显示,MIE-YOLO实现了89.3%的F1分数和94.4%的平均精度均值。此外,MIE-YOLO仅需1.76 M的计算参数量、5.4 G的浮点运算量和4.34 M的模型大小,同时以66.2 FPS的高速运行。图8显示了MIE-YOLO的训练结果,包括归一化混淆矩阵和精确度-召回率曲线。
与YOLOv5-N、YOLOv8-N、YOLOv10-N和YOLO11-N等经典YOLO框架相比,MIE-YOLO展现出更优的准确性和轻量性。与最新的YOLO13-N相比,MIE-YOLO在F1分数上提高了1.6%,在平均精度均值上提高了1.6%。同时,计算参数量减少了28.2%,浮点运算量减少了11.5%,模型大小减少了16.4%,运行速度加快了79.4%。因此,MIE-YOLO在精度和实时性能之间实现了更好的平衡,在检测性能上超越了其他YOLO系列算法。
与基于DETR系列的模型RT-DETRv2-S和Deformable-DETR相比,尽管MIE-YOLO的精度略低,但所有计算参数和模型尺寸都显著更小,运行速度达到其FPS的2到3倍。虽然基于DETR的模型实现了稍高的精度,但它们需要更多的参数和计算资源,而MIE-YOLO以更小的模型尺寸和更快的推理速度提供了有竞争力的性能,使其更适合边缘设备和移动农业平台。
与基准YOLO12-N模型相比,MIE-YOLO在效率和准确性上都表现出明显的提升。精确度从91.9%提高到94.5%,F1分数从87.4%提高到89.3%,平均精度均值@0.5从92.4%提高到94.4%,而召回率保持相近,分别为84.7%对83.4%。同时模型变得更加轻量和快速:参数量从2.51 M降至1.76 M,浮点运算量从5.8 G降至5.4 G,模型大小从5.23 M缩至4.34 M,推理速度从50.0 FPS攀升至66.2 FPS。总体而言,MIE-YOLO并未牺牲准确性以换取效率。相反,它在降低计算成本和加速运行时间的同时,提供了更高的检测性能,使其更适合实时和资源有限的农业应用。
5.2. 模块消融实验分析
为了全面验证MIE-YOLO中每个模块的贡献,以YOLO12-N为基准模型对所有改进部分进行了消融实验。具体来说,我们将MS-EIS架构、Add-CGLU金字塔网络和DEC检测头添加到YOLO12-N中,并结合DS策略对整个架构进行知识蒸馏。通过对工作原理的详细讨论,展示了模型的优势。模块消融实验的结果如表2所示,其中模块A代表基准YOLO12-N,模块B代表MS-EIS架构,模块C代表Add-CGLU金字塔网络,模块D代表DEC检测头,模块E代表普通的单阶段蒸馏策略,模块F代表DS知识蒸馏策略。
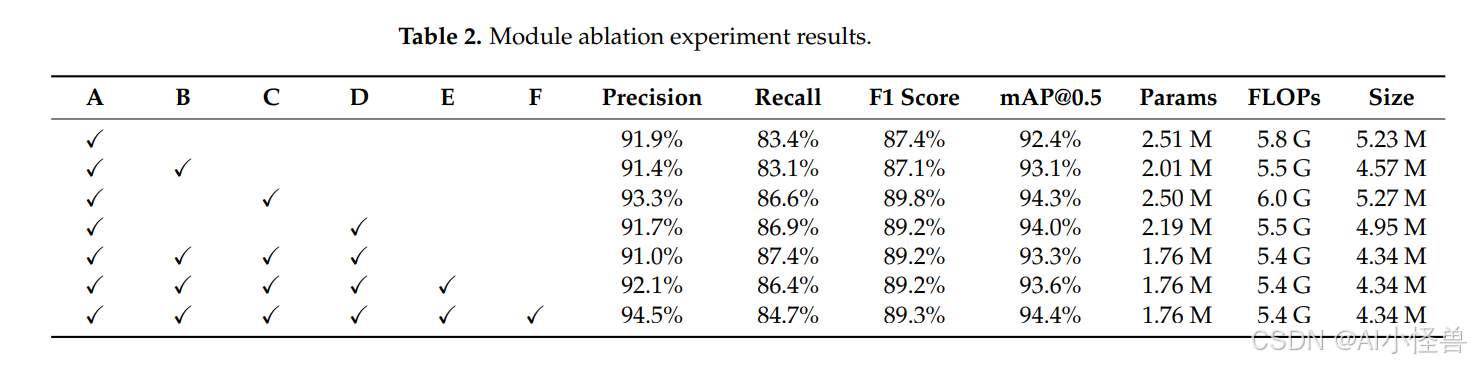
首先,将MS-EIS架构引入YOLO12-N基准模型。与基准模型相比,平均精度均值提高了0.7%,计算参数量减少了19.9%,浮点运算量减少了5.2%,模型大小减少了12.6%,对F1分数的影响可忽略不计。这表明MS-EIS架构通过多尺度特征提取、边缘信息增强、深度卷积操作和双区域聚焦注意力机制,优化了模型的特征表示和任务适应性。
然后,将Add-CGLU金字塔网络整合到YOLO12-N基准模型中。虽然与原始模型相比,浮点运算量和模型大小略有增加,但F1分数和平均精度均值分别提高了2.4%和1.9%。增加的计算成本来自于改进多尺度表示的局部感知、加性令牌混合和门控卷积操作,因此这种权衡是,以浮点运算量和内存占用的适度上升为代价,换取显著提升的检测准确性。这使得Add-CGLU在能够接受资源使用的小幅增加以获得表征能力和信息传递效率提升的场景下具有吸引力。这表明Add-CGLU金字塔网络通过加性融合和门控机制提高了多尺度特征的表征能力和信息传递效率。
接下来,在YOLO12-N基准模型中替换了DEC检测头。这使得F1分数提高了1.8%,平均精度均值提高了1.6%。同时,计算参数量减少了12.7%,浮点运算量减少了5.2%,模型大小减少了5.4%。DEC检测头通过将表征能力集中在关键区域,并用更轻量化的自适应操作和共享参数替换一些繁重的静态卷积,在提高精度的同时减少了参数和浮点运算量。这些改变削减了冗余权重并降低了计算成本,这通常会减少内存使用,并可能在许多设备上加快推理速度。这表明DEC检测头通过细粒度特征增强、动态自适应卷积和共享参数设计,有效降低了计算成本和参数量。
最后,对融合了所有模块改进的模型,使用DS策略进行了知识蒸馏。值得注意的是,模型的轻量性并未受到影响,且F1分数和平均精度均值分别提高了0.1%和1.1%。这表明DS策略在保持模型轻量性的同时,进一步提高了模型的检测精度和泛化性能。
通过关注消融实验的最后三行,可以看出单阶段蒸馏与本文提出的双重自知识蒸馏之间的差异。单阶段蒸馏将精确度从91.0%提高到92.1%,并将平均精度均值从93.3%略微提高到93.6%,同时F1分数保持在89.2%不变,召回率略有下降至86.4%。而DS策略带来了显著更大的提升,将精确度推至94.5%,平均精度均值推至94.4%,F1分数小幅增至89.3%,同时保持了模型的轻量性,参数量为1.76 M,浮点运算量为5.4 G,模型大小为4.34 M。这些结果表明,与单阶段蒸馏相比,DS策略产生了更强、更具判别性的通道级监督,从而锐化了决策边界并减少了误报,因此实现了精确度和平均精度均值的大幅提升。
消融实验证明了轻量化改进和定制的双重自知识蒸馏策略的有效性。MIE-YOLO成功地在精准农业的实时田间杂草识别和针对性喷药任务中,实现了精度与实时性能之间的良好平衡。
5.3. 模型泛化实验分析
为了广泛探索MIE-YOLO的鲁棒性,在ImageWeeds41、VCD42和Weed-Crop43等公共数据集上进行了模型泛化实验。ImageWeeds数据集包含3975张图像,展示了美国北达科他州常见的五种不同杂草。类别包括豚草、水麻、小蓬草、红根苋和地肤。VCD数据集包含2801张图像,描绘了美国北达科他州各种作物的土壤状况、杂草侵扰和生长阶段。类别包括豆类、豆杆、玉米、玉米杆、韭菜和韭菜杆。Weed-Crop数据集包含1120张图像,展示了美国北达科他州的五种杂草和八种作物。类别包括黑豆、油菜、玉米、豌豆、亚麻、小蓬草、地肤、扁豆、豚草、红根苋、大豆、甜菜和水麻。三个数据集的对应样本图像如图9所示。

这些图像揭示了一些明显的分布特征,这些特征会影响检测难度。许多照片包含多个、密集排列的实例,频繁出现重叠和部分遮挡,这增加了漏检率,并使精确的边界框回归更加困难。很大一部分目标相对于图像尺寸较小,导致微小边界框高度集中,目标尺度变化很大。某些类别在形状和颜色上表现出较高的类内变异性,而其他类别在视觉上彼此相似,增加了类别间混淆的可能性。背景高度杂乱,纹理和碎屑混合,降低了信号对比度,并使边缘或纹理线索的可靠性下降。
ImageWeeds数据集包含分辨率低于640的图像,而VCD和Weed-Crop数据集包含分辨率高于640的图像。因此,泛化实验也可以验证MIE-YOLO在分辨率超过640时的性能。MIE-YOLO与基线模型在各数据集上的评估指标比较结果如表3所示。
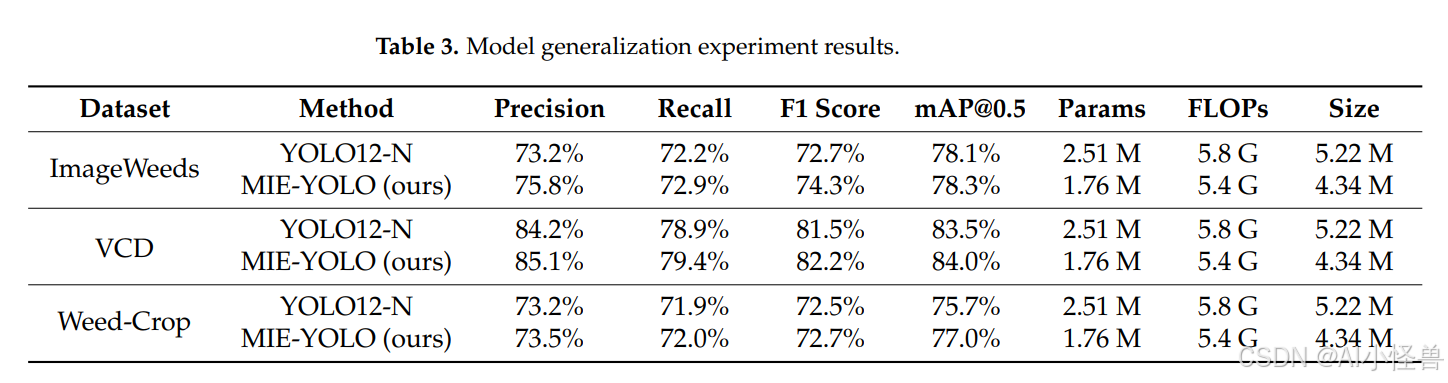
在ImageWeeds数据集上,MIE-YOLO的F1分数提高了1.6%,平均精度均值提高了0.2%。在VCD数据集上,F1分数提高了0.7%,平均精度均值提高了0.5%。在Weed-Crop数据集上,F1分数提高了0.2%,平均精度均值提高了1.3%。此外,MIE-YOLO在全部三个数据集上的轻量性均得到改善:计算参数量减少了29.9%,浮点运算量减少了6.9%,模型大小减少了16.9%。实验结果表明,MIE-YOLO表现出优异的泛化能力,在保持低计算成本和紧凑架构的同时,优化了检测精度和鲁棒性。

这些结果也反映了所提方法在更广泛意义上的鲁棒性。尽管与外部基准相比精度提升有限,但在具有截然不同场景特征的三个数据集上,改进是一致的,这表明MIE-YOLO能够很好地适应成像条件、目标密度和背景杂乱度的变化。更重要的是,所有关键的轻量化指标都显示出大幅度的改进,这意味着模型在显著降低计算负担的同时,保持或略微提高了精度。这种平衡表明,该架构不仅仅是针对单个数据集进行调整,而且在结构上效率更高,且不易过拟合,即使在计算、内存或部署约束收紧的情况下,也能保持性能。在实际的田间应用中,通常需要使用嵌入式设备或实时系统,这种稳定精度与显著降低的复杂性的结合,比那些依赖更重架构以实现更高精度的方法,展现出更强的鲁棒性。
图10展示了YOLO12和MIE-YOLO在三个数据集上的典型失败案例,包括极端场景,如黑暗、遮挡和光照变化。对比图像显示,在具有挑战性的条件下,MIE-YOLO产生了明显更高的置信度分数、更精确的定位和更完整的检测结果。例如,YOLO12以一个约0.41的低置信度标记的一个小蓬草实例,被MIE-YOLO以约0.85的高置信度检测到;许多要么被YOLO12漏检、要么仅有微弱激活的小型植物,在MIE-YOLO的输出中表现为清晰的高置信度边界框。在黑暗、严重遮挡和变化光照条件下,右侧结果显示在叶片边缘和茎秆周围有更密集、对齐更好的边界框,而左侧结果则包含更多分散的低置信度边界框和一些漏检的目标。简而言之,MIE-YOLO识别了更多目标,为正确的检测分配了更高的概率,并且在背景区域上产生的虚假激活更少。

这些改进在实际应用中很重要,因为更高的置信度和改进的定位可以减少漏检和误报,从而降低精准农业中无效喷洒或不必要处理的风险。视觉证据还表明,MIE-YOLO对田间数据中常见的噪声条件更具鲁棒性,在基线检测器性能下降的情况下仍能保持检测质量。这种鲁棒性有助于在部署时做出更可靠的下游决策,特别是在模型紧凑性和输出质量一致性至关重要的嵌入式平台上。
5.4. 模型可视化结果分析
为了直接展示MIE-YOLO的透明度和清晰度,对模型的检测性能进行了可视化。可视化结果包括特征热图和有效感受野,如图11所示。特征热图基于目标梯度将中间特征或响应投影回输入图像,并显示为归一化的热图,直观地揭示了模型对不同空间区域的响应强度。而有效感受野则表示输出单元对输入像素的实际贡献分布。它通常是中心化的、近似高斯的,并且小于理论感受野。它量化了模型聚合上下文信息的有效尺度。

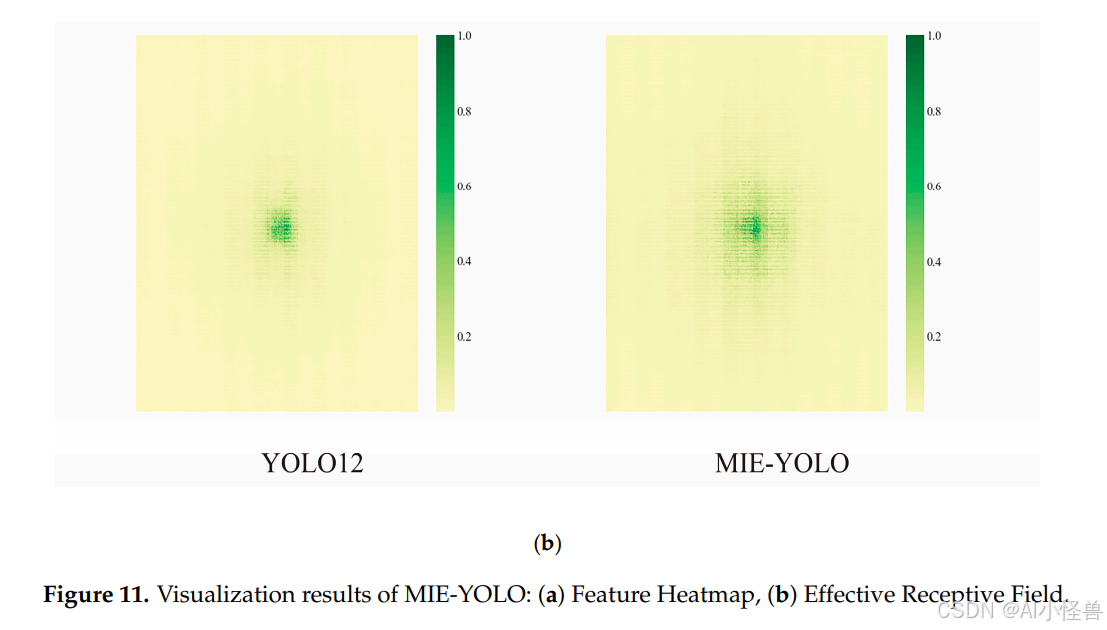
在特征热图的可视化中,MIE-YOLO在多个杂草样本上显示出连续的高响应区域。这些高响应区域通常与叶缘、茎节或植物的典型纹理特征对齐,而不是背景杂草或土壤纹理,这表明尽管存在复杂的遮挡和背景干扰,模型仍能实现更准确的空间注意力。与传统的检测器相比,热图中的高响应块更加集中,边界更清晰,背景虚假激活显著减少。这反映了MIE-YOLO在类别判断和局部特征增强方面的鲁棒性,有助于提高对纹理相近杂草的检出率。
在有效感受野的可视化中,MIE-YOLO的有效感受野显示出比YOLO12更大的响应分布,并且仍然具有显著的中心,表明网络在保持定位精度的同时,能够收集更广泛的上下文信息以支持语义推理。这种更平衡的空间权重分布有助于利用周围的环境线索来区分具有显著尺度和形态差异的杂草,从而提高检测稳定性和召回率。
总之,特征热图和有效感受野的可视化展示了MIE-YOLO在聚焦于显著目标特征以及扩大有效感受野以兼顾局部细节和全局上下文方面的优势。MIE-YOLO在特征注意力和空间感知之间实现了更好的平衡,在复杂多样的环境中展现出检测的鲁棒性和泛化能力。
尽管存在这些优势,但在实际农业环境中部署MIE-YOLO时,仍存在一些实际限制因素。环境可变性是主要挑战之一。强烈的阳光、云层覆盖或作物阴影引起的光照变化会导致剧烈的强度波动,从而降低特征稳定性;而风引起的植物运动导致变形和模糊,这些很难完全建模。土壤背景差异、植物颜色的季节性变化以及杂草生长阶段的变化也可能产生超出训练数据范围的领域差距。当条件偏离训练期间所见时,这些因素可能会削弱特征一致性并降低预测的可靠性。
此外,设备集成限制可能显著影响实际性能。移动农业平台通常依赖低功耗嵌入式处理器,与实验室设置相比,热限制、电池容量和带宽限制可能会降低可实现的推理速度。动态范围较低或安装角度可变的相机传感器可能进一步扭曲特征分布,田间机械的振动会降低图像质量和时间一致性。这些限制表明,尽管MIE-YOLO在受控评估中表现出很强的鲁棒性和泛化能力,但仍需要额外的适应策略,如动态曝光调整、时间稳定化或领域自适应微调,以确保在大规模农业部署中获得持续可靠的性能。表4显示了MIE-YOLO在嵌入式设备或移动平台上的实际推理速度和资源消耗情况。
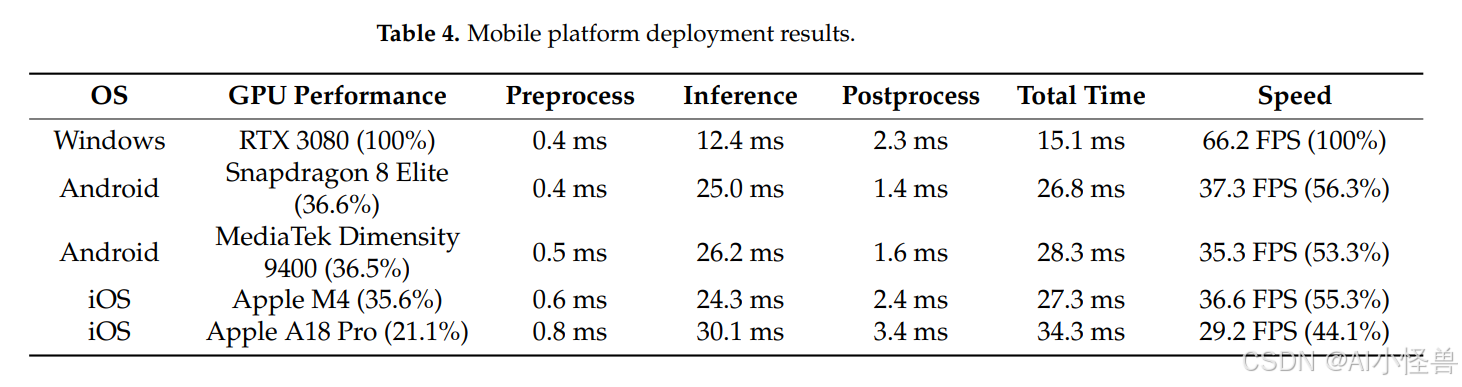
表4显示,MIE-YOLO相对于报道的GPU性能,在移动SoC上实现了不成比例的高速度。在Snapdragon 8 Elite上,该模型的运行速度是RTX 3080速度的56.3%,而该设备GPU的性能为36.6%,差距为19.7个百分点。在Dimensity 9400上,速度为53.3%,GPU性能为36.5%,差距为16.8个百分点。在Apple M4上,速度为55.3%,GPU性能为35.6%,差距为19.7个百分点。即使在低端的A18 Pro上,速度为44.1%,GPU性能为21.1%,差距为23.0个百分点。推理时间保持在20毫秒左右的中段范围,大约产生29到37 FPS,预处理和后处理开销很小,因此大部分运行时间是高效的神经推理。这些运行时优势得益于参数量减少29.9%、浮点运算量减少6.9%和模型大小减少17.0%,这降低了内存占用和计算需求。报道的GPU利用率适中,为多任务处理和节省电池留出了余量,这对于电池供电的喷雾器和无人机等田间部署非常重要。这些事实共同表明,MIE-YOLO实现了比原始设备性能预测更高的实时吞吐量,因此非常适合资源受限的嵌入式和移动平台,同时仍可通过供应商加速、量化或定向剪枝获得进一步的增益。
六、结论
本文提出了一种用于精准农业的多尺度信息增强杂草检测算法MIE-YOLO。通过引入新颖的MS-EIS架构、Add-CGLU金字塔网络和DEC检测头,MIE-YOLO采用DS策略在整个网络中进行知识蒸馏。在自定义杂草数据集上的实验结果表明,MIE-YOLO将F1分数提高了1.9%,平均预测精度均值提高了2.0%。此外,MIE-YOLO将计算参数量减少了29.9%,浮点运算量减少了6.9%,模型大小减少了17.0%,并实现了66.2 FPS的运行速度。这些结果表明,MIE-YOLO实现了对多类别、密集分布和小型杂草目标的高效准确识别。
尽管取得了这些成果,但MIE-YOLO仍存在一些重要的局限性,需要进一步研究。其在极端光照和运动模糊下的性能尚未得到充分验证,因为MS-EIS模块依赖的边缘和纹理线索在此类条件下可能会退化。杂草与作物之间的严重遮挡和密集重叠仍然是挑战,因为DEC增强功能无法总是恢复完全被遮挡的实例。某些作物和杂草之间的细粒度相似性会导致误报,这表明需要更具判别性的特征或类别平衡的训练。诸如标注噪声、对超参数的敏感性以及有限的田间试验等实际问题也可能限制其在实际世界中的转化应用。因此,未来的工作将优先考虑扩展和多样化数据集,并进行有针对性的模型压缩和硬件加速测试以验证部署效果。通过与自动除草机械和精准喷洒系统的深度融合,MIE-YOLO有望在复杂农田环境中实现大规模部署,并为提高作物产量和农药使用效率提供有力支持。