本系列介绍增强现代智能体系统可靠性的设计模式,以直观方式逐一介绍每个概念,拆解其目的,然后实现简单可行的版本,演示其如何融入现实世界的智能体系统。本系列一共 14 篇文章,这是第 8 篇。原文:Building the 14 Key Pillars of Agentic AI
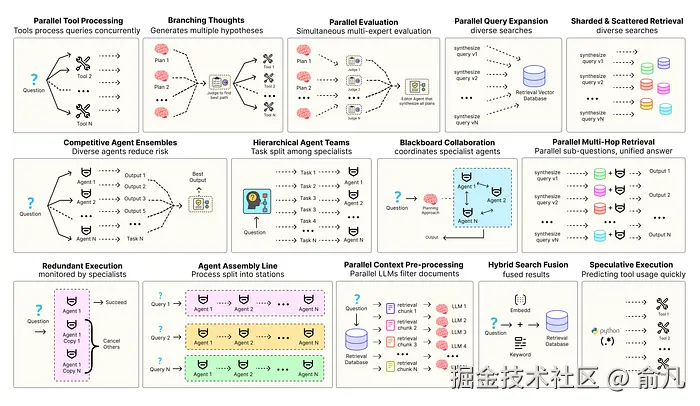
优化智能体解决方案需要软件工程确保组件协调、并行运行并与系统高效交互。例如预测执行,会尝试处理可预测查询以降低时延 ,或者进行冗余执行,即对同一智能体重复执行多次以防单点故障。其他增强现代智能体系统可靠性的模式包括:
- 并行工具:智能体同时执行独立 API 调用以隐藏 I/O 时延。
- 层级智能体:管理者将任务拆分为由执行智能体处理的小步骤。
- 竞争性智能体组合:多个智能体提出答案,系统选出最佳。
- 冗余执行:即两个或多个智能体解决同一任务以检测错误并提高可靠性。
- 并行检索和混合检索:多种检索策略协同运行以提升上下文质量。
- 多跳检索:智能体通过迭代检索步骤收集更深入、更相关的信息。
还有很多其他模式。
本系列将实现最常用智能体模式背后的基础概念,以直观方式逐一介绍每个概念,拆解其目的,然后实现简单可行的版本,演示其如何融入现实世界的智能体系统。
所有理论和代码都在 GitHub 仓库里:🤖 Agentic Parallelism: A Practical Guide 🚀
代码库组织如下:
erlang
agentic-parallelism/
├── 01_parallel_tool_use.ipynb
├── 02_parallel_hypothesis.ipynb
...
├── 06_competitive_agent_ensembles.ipynb
├── 07_agent_assembly_line.ipynb
├── 08_decentralized_blackboard.ipynb
...
├── 13_parallel_context_preprocessing.ipynb
└── 14_parallel_multi_hop_retrieval.ipynb去中心化黑板协作
至今为止我们构建的自主式架构,如层级架构和装配线,都由严格的、预先设定的工作流定义。
但对于那些无法预知解决方案路径的问题呢?对于复杂认知理解或分析任务,需要一种更灵活、适应性更强的方法。
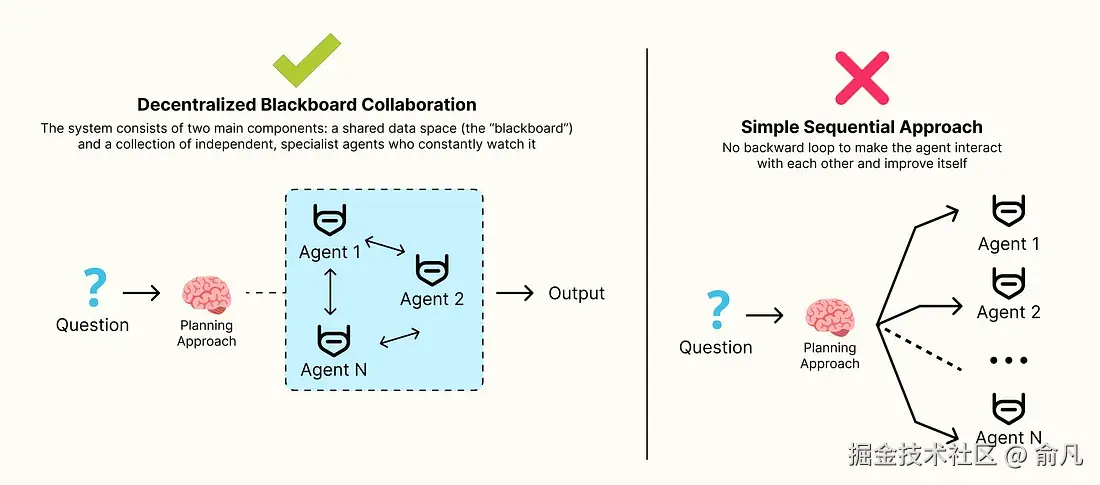
在这种情况下,可以用 去中心化黑板协作(Decentralized Blackboard Collaboration) 模式,该系统由两个主要组件构成:共享数据空间(即"黑板")以及一组独立、专业的代理,持续监控黑板。
- 代理不按固定顺序触发,而是当黑板状态与其专业领域匹配时,会被自行激活。
- 代理读取当前状态,通过向黑板写入来贡献知识,然后返回休眠状态。
- 从而创造动态的、涌现的工作流,解决方案由每个阶段最相关的专家逐步、逐块的构建而成。
为了展示这种模式如何有用,我们构建一个客户支持工单处理系统,该系统由三位专家代理协作:分析器、检索器和提案器,展示这种解耦方法如何比单一代理产生的结果更准确、更具上下文丰富性。
首先定义智能体发布到黑板上的结构化数据对象。
python
from langchain_core.pydantic_v1 import BaseModel, Field
from typing import List, Literal, Optional
class ProblemAnalysis(BaseModel):
"""结构化分析用户的问题,由分析器代理发布"""
product: str = Field(description="The product the user is having an issue with.")
problem_summary: str = Field(description="A concise, one-sentence summary of the technical problem.")
user_sentiment: Literal["Positive", "Negative", "Neutral"] = Field(description="The user's sentiment.")
class Solution(BaseModel):
"""检索器代理发布潜在解决方案"""
relevant_articles: List[str] = Field(description="A list of knowledge base articles relevant to the problem.")
class DraftResponse(BaseModel):
"""由提案器代理发布最终回复"""
response_text: str = Field(description="The complete, user-facing response drafted by the agent.")这些 Pydantic 模型是黑板系统的正式"协作语言"。当分析器代理运行时,必须发布 ProblemAnalysis 对象,从而确保当解决方案检索器激活时,可以可靠的找到 problem_summary 对象来协作。
接下来定义 BlackboardState 本身,包含初始工单以及代理随时间贡献的所有结构化数据。
python
from typing import TypedDict, Annotated
class BlackboardState(TypedDict):
ticket: str
# 'analysis', 'solution', 'draft' 是代理在黑板上发布输出的插槽
analysis: Optional[ProblemAnalysis]
solution: Optional[Solution]
draft: Optional[DraftResponse]
performance_log: Annotated[List[str], operator.add]每个可选字段(analysis,solution,draft)代表拼图的一部分,随着代理填充这些字段,工作流逐步构建起解决问题所需的完整画面。
现在定义专家代理节点,每个都是读取和写入黑板的专业代理,第一个是 analyzer_node。
python
from langchain_core.prompts import ChatPromptTemplate
import time
# 代理 1: 问题分析器
analyzer_prompt = ChatPromptTemplate.from_messages([
("system", "You are a Problem Analyzer. Your job is to read a customer support ticket, identify the product, summarize the problem, and gauge the user's sentiment."),
("human", "Please analyze the following ticket:\n\n---\n{ticket}\n---")
])
analyzer_chain = analyzer_prompt | llm.with_structured_output(ProblemAnalysis)
def analyzer_node(state: BlackboardState):
"""第一个激活的代理:读取工单并在黑板上发布分析"""
print("--- [AGENT: Problem Analyzer] Activating... ---")
start_time = time.time()
result = analyzer_chain.invoke({"ticket": state['ticket']})
execution_time = time.time() - start_time
log = f"[Analyzer] Completed in {execution_time:.2f}s."
print(log)
# 该代理的作用是填写黑板上的 'analysis' 槽
return {"analysis": result, "performance_log": [log]}analyzer_node 是协作的入口点,执行初始的"意义理解"步骤,将无结构用户工单转换为结构化 ProblemAnalysis 对象,并将其发布到黑板上供其他代理查看。
其他代理(retriever_node 和 draftsman_node),遵循类似模式,读取黑板当前状态并添加自己的贡献。
黑板系统最关键的部分是中央路由器,功能是控制每个智能体在对应轮次检查黑板,并决定哪个专家最适合进行下一步动作,是事件驱动、机会主义协作的核心。
python
def router(state: BlackboardState) -> str:
"""中央路由器:检查黑板并决定下一步激活哪个代理"""
print("--- [ROUTER] Inspecting blackboard... ---")
# 路由器的逻辑是一系列按顺序查看的规则
# 规则 1: 如果已经写好了草案,问题就解决了
if state.get('draft'):
print("--- [ROUTER] Decision: Draft is complete. Finishing workflow. ---")
return END
# 规则 2:如果找到了解决方案(但还没有草案),是时候写回应了
if state.get('solution'):
print("--- [ROUTER] Decision: Solution found. Activating Draftsman. ---")
return "draftsman"
# 规则 3:如果完成了分析(但还没有解决方案),是时候找到解决方案了
if state.get('analysis'):
print("--- [ROUTER] Decision: Analysis complete. Activating Solution Retriever. ---")
return "retriever"
# 如果入口点设置正确,理想情况下不应该走到默认路径
return "analyzer"router 是系统的主体部分,是一个动态、状态驱动的决策者。每个节点运行后,图会调用 router 功能,检查 BlackboardState,根据已填充的字段确定最合理的下一步,从而使得工作流根据问题的演变状态自然涌现。
然后组装图,通过中央路由器连接所有节点。
python
from langgraph.graph import StateGraph, START, END
workflow = StateGraph(BlackboardState)
# 添加专家代理节点
workflow.add_node("analyzer", analyzer_node)
workflow.add_node("retriever", retriever_node) # (Defined in the notebook)
workflow.add_node("draftsman", draftsman_node) # (Defined in the notebook)
# 入口点总是分析器
workflow.add_edge(START, "analyzer")
# 每个节点运行后,转到中央路由器来决定下一步
# 这将创建 "hub-and-spoke" 架构,路由器是其核心
workflow.add_conditional_edges("analyzer", router)
workflow.add_conditional_edges("retriever", router)
workflow.add_conditional_edges("draftsman", router)
# 不需要直接到 END,路由器会处理终止条件
app = workflow.compile()
print("Graph constructed and compiled successfully.")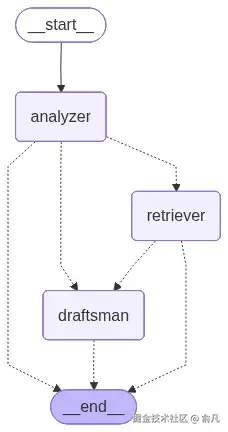
我们检查黑板的最终状态,并定性分析这种协作方式的优势。
python
import json
print("="*60)
print(" FINAL BLACKBOARD STATE")
print("="*60)
# (已经完成完整运行,并填充了 final_state)
print(json.dumps(final_state, indent=4, default=lambda o: o.dict() if hasattr(o, 'dict') else o))
print("\n" + "="*60)
print(" ACCURACY & QUALITY ANALYSIS")
print("="*60 + "\n")得到的结果......
python
#### 输出 ####
============================================================
FINAL BLACKBOARD STATE
============================================================
{
"ticket": "I'm really frustrated. My new Aura Ring isn't syncing my sleep data...",
"analysis": {
"product": "Aura Ring",
"problem_summary": "The Aura Ring app is failing to sync sleep data.",
"user_sentiment": "Negative"
},
"solution": {
"relevant_articles": [
"Article 4: To resolve app connectivity issues with the Aura Ring...",
"Article 1: To reset your Aura Smart Ring..."
]
},
"draft": {
"response_text": "Hi there, I'm sorry to hear you're frustrated with the Aura Ring's sleep sync issue...Here are a couple of common solutions from our knowledge base..."
},
"performance_log": [
"[Analyzer] Completed in 4.55s.",
"[Retriever] Completed in 7.89s.",
"[Draftsman] Completed in 6.21s."
]
}最终草案质量明显优于单一智能体可能产生的质量,原因如下:
- 解耦减少错误:单一智能体可能会误解用户问题并找到错误的解决方案。通过将分析从检索中分离出来,确保检索步骤基于对问题清晰、结构化的总结。
- 专业化深度增加:草案器智能体通过专注于清晰度的提示进行了专业化。接收结构化数据(情绪、问题总结、解决方案)使其能够作出更有帮助的回应,既解决了技术问题,也缓解了用户的挫败感。
- 可审计性与模块化 :黑板上的每个对象(
analysis,solution,draft)都是独立的可审计工件。如果最终草案有误,可以追溯是否是分析出错或检索失败,使得系统比单一黑盒代理更容易调试和改进。
Hi,我是俞凡,一名兼具技术深度与管理视野的技术管理者。曾就职于 Motorola,现任职于 Mavenir,多年带领技术团队,聚焦后端架构与云原生,持续关注 AI 等前沿方向,也关注人的成长,笃信持续学习的力量。在这里,我会分享技术实践与思考。欢迎关注公众号「DeepNoMind」,星标不迷路。也欢迎访问独立站 www.DeepNoMind.com,一起交流成长。