什么是RAG?
RAG(检索增强生成)是一种让AI更聪明的技术,就像给AI配备了一个智能"小抄"。
想象一下:普通的大语言模型(如ChatGPT)只知道它训练时学到的知识,而且这些知识有"截止日期"。如果你想让AI回答关于你公司内部文档、最新研究报告或个人笔记的问题,普通AI就无能为力了。
这时RAG就派上用场了:它能让AI在回答问题前先"查阅资料",就像学生做开卷考试一样。AI会从你提供的文档中找出相关信息,然后基于这些信息生成答案。
简单来说,RAG = 检索(Retrieval) + 生成(Generation),它让AI变得更加实用,能够利用你提供的专业知识来回答问题。
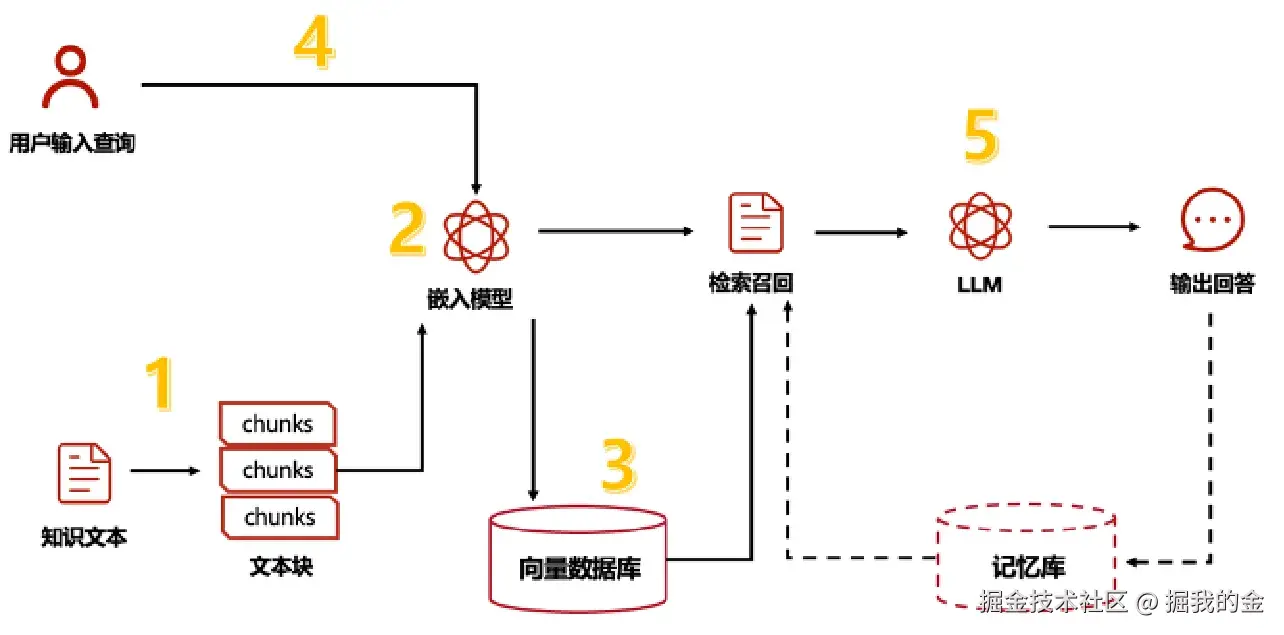
RAG的工作原理
RAG系统的工作方式就像一个高效的图书馆助手,主要分为两大步骤:
1. 索引阶段(准备知识库)
这个阶段就像是整理一个智能图书馆,通常在系统启动前就完成:
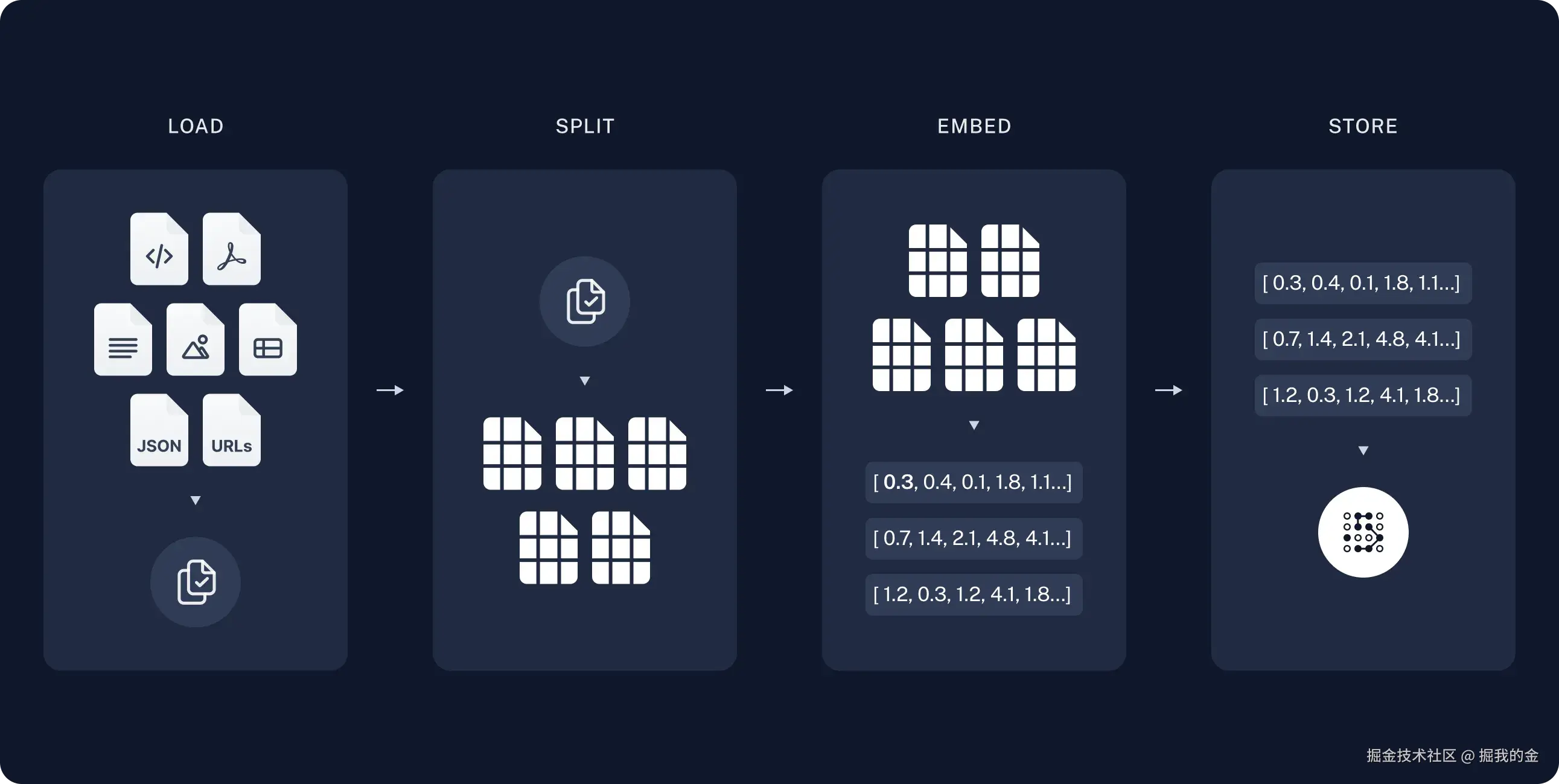
- 加载文档:首先,我们把各种文档(PDF、Word、网页等)导入系统中
- 分割文本:把长文档切成小块(想象成便利贴大小的内容),因为AI一次处理不了太多内容
- 转换为向量:使用"嵌入模型"把每个文本块转换成数字向量(可以理解为给每段文本创建一个"数字指纹")
- 存储向量:把这些向量存入向量数据库,方便以后快速查找
2. 检索和生成阶段(回答问题)
当用户提问时,系统会:

- 处理问题:把用户问题也转换成向量
- 检索相关内容:在向量数据库中找出与问题最相似的几个文本块
- 组合信息:把问题和检索到的相关文本块组合起来
- 生成回答:让大语言模型基于这些信息生成一个准确、相关的回答
文档问答应用实现流程
让我们用生活化的语言来解释如何构建一个文档问答应用:
- 上传文档:用户通过网页上传一个或多个文档(比如PDF、TXT文件等)
- 接收并存储:服务器接收这些文档并暂时保存
- 读取文档:程序打开并读取文档内容
- 切块处理:把文档内容分成小块(就像把一本书分成多个段落)
- 创建向量索引:把每个文本块转换为向量并存入数据库
- 准备回答问题:此时系统已经"学习"了文档内容,准备好回答问题
- 用户提问:用户输入与文档相关的问题
- 智能回答:系统找出相关文本块,让AI生成回答
代码实现
下面我们将使用LangChain和Streamlit构建一个简单的文档问答应用。这个应用允许用户上传文本文件,然后向其提问。
1. 安装必要的库
首先,我们需要安装所需的Python库:
bash
pip install langchain langchain-openai streamlit faiss-cpu2. 创建Streamlit应用
创建一个名为app.py的文件,并添加以下代码:
python
import os
import tempfile
import streamlit as st
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.tools.retriever import create_retriever_tool
from langchain.agents import AgentExecutor, create_react_agent
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.messages import AIMessage, HumanMessage
from langchain.callbacks.streamlit import StreamlitCallbackHandler
# 设置页面标题
st.set_page_config(page_title="文档问答助手", page_icon="📚")
st.title("📚 文档问答助手")
# 设置OpenAI API密钥
os.environ["OPENAI_API_KEY"] = st.sidebar.text_input("OpenAI API Key", type="password")
# 初始化会话状态
if "retriever" not in st.session_state:
st.session_state.retriever = None
if "chat_history" not in st.session_state:
st.session_state.chat_history = []
# 文件上传区域
uploaded_file = st.sidebar.file_uploader("上传文档", type=["txt"])
# 处理文件上传
if uploaded_file and st.session_state.retriever is None:
with st.spinner("正在处理文档..."):
# 创建临时文件
with tempfile.NamedTemporaryFile(delete=False) as tmp_file:
tmp_file.write(uploaded_file.getvalue())
tmp_file_path = tmp_file.name
# 读取文件内容
with open(tmp_file_path, 'r', encoding='utf-8') as f:
text = f.read()
# 删除临时文件
os.unlink(tmp_file_path)
# 文本分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每块文本的大小
chunk_overlap=100, # 块之间的重叠部分
separators=["\n\n", "\n", "。", "!", "?", ".", " ", ""], # 分割符号
)
chunks = text_splitter.split_text(text)
# 创建向量存储
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_texts(chunks, embeddings)
# 创建检索器
st.session_state.retriever = vectorstore.as_retriever(
search_type="similarity", # 相似度搜索
search_kwargs={"k": 3} # 返回前3个最相关的结果
)
st.sidebar.success(f"文档处理完成!共分割为{len(chunks)}个文本块")
# 如果检索器已创建,显示聊天界面
if st.session_state.retriever is not None:
# 创建检索工具
retriever_tool = create_retriever_tool(
st.session_state.retriever,
"document_search",
"在文档中搜索信息,用于回答关于文档内容的问题。"
)
# 创建语言模型
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
# 创建提示模板
prompt = ChatPromptTemplate.from_messages([
("system", """你是一个专业的文档助手,可以回答用户关于文档内容的问题。
使用提供的工具来搜索文档并回答问题。
如果你不知道答案,请诚实地说你不知道,不要编造信息。
始终使用中文回答问题。
"""),
("human", "{input}")
])
# 创建React代理
agent = create_react_agent(llm, [retriever_tool], prompt)
agent_executor = AgentExecutor.from_agent_and_tools(
agent=agent,
tools=[retriever_tool],
verbose=True,
handle_parsing_errors=True
)
# 显示聊天历史
for message in st.session_state.chat_history:
if isinstance(message, HumanMessage):
with st.chat_message("user"):
st.write(message.content)
else:
with st.chat_message("assistant"):
st.write(message.content)
# 获取用户输入
user_input = st.chat_input("请输入您的问题...")
# 处理用户输入
if user_input:
# 显示用户问题
with st.chat_message("user"):
st.write(user_input)
# 添加到聊天历史
st.session_state.chat_history.append(HumanMessage(content=user_input))
# 显示AI思考过程
with st.chat_message("assistant"):
st_callback = StreamlitCallbackHandler(st.container())
response = agent_executor.invoke(
{"input": user_input},
{"callbacks": [st_callback]}
)
answer = response["output"]
st.write(answer)
# 添加到聊天历史
st.session_state.chat_history.append(AIMessage(content=answer))
else:
# 如果还没上传文件,显示说明
st.info("👈 请先上传一个文本文件")3. 运行应用
在命令行中运行以下命令启动应用:
bash
streamlit run app.py4. 使用应用
- 在侧边栏输入你的OpenAI API密钥
- 上传一个文本文件(比如公司手册、研究论文等)
- 等待文件处理完成
- 在聊天框中输入与文档相关的问题
- 观察AI如何回答你的问题
代码解析
让我们来解释上面代码的关键部分:
文档处理流程
python
# 文本分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每块文本的大小
chunk_overlap=100, # 块之间的重叠部分
separators=["\n\n", "\n", "。", "!", "?", ".", " ", ""], # 分割符号
)
chunks = text_splitter.split_text(text)这段代码将长文本分割成小块,每块约1000个字符,相邻块之间重叠100个字符(避免切割导致的信息丢失)。分割时优先按照段落、句子等自然边界进行。
python
# 创建向量存储
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_texts(chunks, embeddings)这里使用OpenAI的嵌入模型将文本块转换为向量,并存储在FAISS向量数据库中。FAISS是一个高效的向量搜索库,专为相似性搜索而设计。
检索工具创建
python
retriever_tool = create_retriever_tool(
st.session_state.retriever,
"document_search",
"在文档中搜索信息,用于回答关于文档内容的问题。"
)这段代码创建了一个检索工具,它可以被代理用来搜索文档。工具名称为"document_search",描述告诉AI这个工具的用途。
React代理创建
python
agent = create_react_agent(llm, [retriever_tool], prompt)
agent_executor = AgentExecutor.from_agent_and_tools(
agent=agent,
tools=[retriever_tool],
verbose=True,
handle_parsing_errors=True
)这里创建了一个React代理,它使用ReAct(Reasoning and Acting)方法,能够在回答问题前先思考应该采取什么行动。verbose=True让我们能看到代理的思考过程,handle_parsing_errors=True使代理能够处理解析错误。
进阶优化建议
- 支持更多文件类型:扩展应用以支持PDF、Word、Excel等更多文件格式
- 记忆对话历史:让AI记住之前的对话,能够进行连续对话
- 多文档管理:允许用户上传多个文档并在它们之间切换
- 高级检索方法:实现混合搜索或重排序,提高检索质量
- 自定义模型选择:让用户选择不同的语言模型和嵌入模型
总结
RAG技术让我们能够构建"有记忆"的AI应用,它可以基于特定文档回答问题,而不仅仅依赖于预训练知识。这对于构建企业知识库、个人助手、研究工具等应用非常有价值。
通过LangChain,我们可以轻松实现RAG系统的各个组件:文档加载、文本分割、向量存储、检索和生成。而Streamlit则提供了一个简单的方式来创建交互式Web界面。
希望这个教程能帮助你理解RAG的工作原理,并开始构建自己的文档问答应用!