
中间件:Middleware 是一种流程控制机制,用于在智能体执行过程中拦截、修改或增强请求与响应的处理逻辑,而无需修改核心Agent或工具的代码。
1.什么是中间件Middleware
下面是一个核心的 Agent流程:
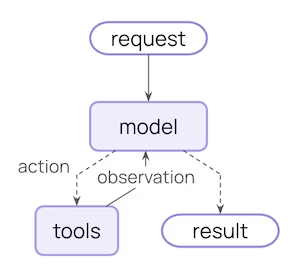
即 用户请求->调用模型->模型选择要执行的工具->得到工具执行结果->更新状态->反复调用工具,直到不再调用任何工具时结束。
而中间件则会在每个步骤前后暴露钩子:
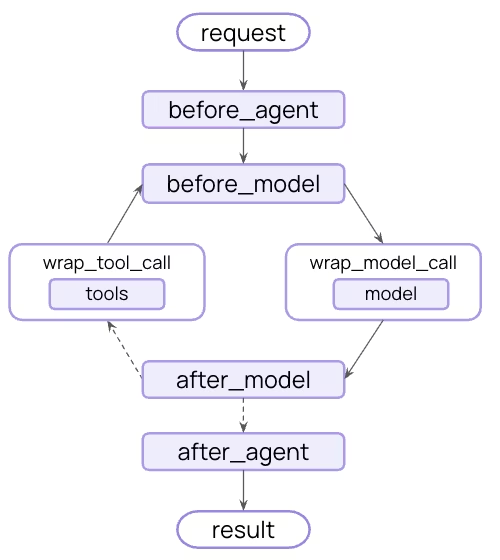
上图中的
before_agent``before_model``wrap_tool_callwrap_model_callafter_model``after_agent就是最常见的钩子。所以可以把中间件看成 "加入 Agent 循环中的插件链",每个中间件负责一个或多个钩子,开发者通过组合中间件就能灵活控制Agent的行为。
2.内置中间件
下面的中间件为内置的中间件,这意味着 这些功能不依赖于特定的模型提供商(如 OpenAI、Claude、Gemini 或本地的 Llama)。它们通过 LangChain 的标准抽象层工作,因此无论你底层切换到哪个模型,这些中间件都可以直接复用。
| 中间件 | 说明 |
|---|---|
| 对话摘要 SummarizationMiddleware | 在对话历史累积到一定 token 数或消息条数时,自动生成摘要,以减小上下文长度、避免超出模型上下文窗口。适用于长期对话、多轮 agent 场景 |
| 人工干预 HumanInTheLoopMiddleware | 在工具调用之前暂停 agent ,等待人工批准、编辑或拒绝。适用于高风险操作(例如发送邮件、数据库写入、金融交易等),需人工监督。 |
| 模型调用限制 ModelCallLimitMiddleware | 限制 模型 调用次数,防止 agent 陷入无限循环、控制成本。配置如:thread_limit(跨多轮会话)、run_limit(当前一次 invoke) |
| 工具调用限制 ToolCallLimitMiddleware | 限制工具调用次数(全局或按工具名),防止工具滥用、资源浪费、成本失控。 |
| 模型故障切换 ModelFallbackMiddleware | 主模型出现错误或超时时,自动切换备用模型,保证Agent不中断。适用于生产系统的容错设计。 |
| 待办清单 TodoListMiddleware | 为 Agent 装备一个内置的任务追踪器。Agent 会自动创建和更新 To-do list,帮助它在处理多步骤复杂任务时保持专注,不遗漏步骤。 |
| 隐私数据检测 PIIMiddleware | 检测 input 或 output 或工具结果中的 PII(个人身份信息),并根据策略(如 "redact"/"mask"/"block"/"hash")处理。适用于合规、隐私敏感场景。 |
| LLM 工具选择器 LLMToolSelectorMiddleware | 在调用模型前,用一个更廉价或更快的模型来"选择"哪些工具更相关,从而让主 agent 只暴露必要工具。适用于工具很多、需要精简的场景。 |
| 工具重试 ToolRetryMiddleware | 对工具调用失败进行自动重试、可配置指数退避(backoff)、最大延迟、抖动 (jitter) 等。适用于外部 API 调用不稳定的情况。 |
| Model retry | Automatically retry failed model calls with exponential backoff. |
| LLM tool emulator | Emulate tool execution using an LLM for testing purposes. |
| 上下文编辑 ContextEditingMiddleware | 允许你在对话流中程序化地修改或修剪特定的消息。例如,你可以自动删除旧的工具调用结果,只保留最终的有效信息。 |
| Shell tool | Expose a persistent shell session to agents for command execution. |
| 文件搜索 FileSearchMiddleware | 为 Agent 提供在本地文件系统中进行深度搜索(支持 Glob 和 Grep 模式)的能力,使其能快速从大量日志或文档中定位信息。 |
3.SummarizationMiddleware示例
python
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
from langchain.chat_models import init_chat_model
if __name__ == '__main__':
ollama_url="http://127.0.0.1:11434"
# 1. 初始化模型
# 主模型:负责复杂的推理任务
ds_model=init_chat_model(
model="ollama:deepseek-v3.1:671b-cloud",
base_url=ollama_url)
# 摘要模型:通常使用响应快、成本低的模型
qwen_model=init_chat_model(
model="ollama:qwen3-next:80b-cloud",
base_url=ollama_url)
# 2. 定义摘要逻辑
summarizer = SummarizationMiddleware(
model=qwen_model,
# 触发器 (Trigger):定义什么时候开始干活
# 这里设置当对话超过 3000 Tokens 时触发
trigger=("tokens", 3000),
# 保留策略 (Keep):摘要后,保留多少"新鲜"的消息不被压缩
# 这里设置保留最近的 10 条消息作为原始上下文
keep=("messages", 10)
)
# 3. 创建带有中间件的 Agent
agent = create_agent(
model=ds_model,
tools=[], # 填入你的工具列表
middleware=[summarizer]
)当 Agent 运行时,中间件会像"哨兵"一样观察每一条消息:
- 监控:它计算当前对话占用的 Token 数量。
- 截断与压缩 :一旦达到
trigger设定的 3000 Tokens,它就会把除了最近 10 条(keep设定的值)以外的所有历史消息交给qwen_model。 - 重组上下文:旧消息被替换成一段简短的摘要,而最近的 10 条对话原封不动地保留,确保 Agent 还能记得刚刚聊了什么。
在配置 trigger(触发条件)时,我们可以选择按 Token 数量 触发,也可以按 消息条数 触发。
如果你正在开发一个多轮对话的客服机器人(每轮对话可能很短,但轮数很多),那应该采用哪种触发方式会让 Agent 的记忆管理更稳定?为什么呢?
按 Token 数量 触发确实能更高效地利用模型的上下文空间 。 对于短对话,如果仅按消息条数触发,可能会在 Token 还充裕时就进行压缩,造成信息丢失。而按 Token 触发则像是一个"按需分配"的机制,确保模型始终在信息量最饱和的状态下工作。
4. HumanInTheLoopMiddleware示例
在自动化任务中,有些操作是不可逆 或高风险 的(例如:删除数据库、发送支付请求)。 HumanInTheLoopMiddleware 允许我们在这些关键节点强制 Agent 暂停,等待人类的指令:批准 (Approve) 、修改 (Edit) 或 拒绝 (Reject)。
在下面的这个例子中,我们允许 Agent 自由阅读邮件,但发送邮件必须经过人工审批。
python
from langchain.agents import create_agent
from langchain.agents.middleware import HumanInTheLoopMiddleware
from langchain.chat_models import init_chat_model
from langgraph.checkpoint.memory import InMemorySaver
# 1. 定义工具,一个低风险,一个高风险操作
def read_email(email_id: str):
"""读取邮件内容(低风险操作)"""
return f"邮件 {email_id} 的内容是:请在明天前向张三支付50元。"
def send_payment(amount: float, recipient: str):
"""执行支付(高风险操作)"""
return f"已向 {recipient} 支付 {amount} 元。"
if __name__ == '__main__':
ollama_url="http://192.168.6.133:11434"
# 模型
ds_model=init_chat_model(
model="ollama:deepseek-v3.1:671b-cloud",
base_url=ollama_url)
# 2. 配置中间件
# HumanInTheLoopMiddleware 必须配合 checkpointer 使用,以便在暂停时保存 Agent 的状态
memory = InMemorySaver()
hitl_middleware = HumanInTheLoopMiddleware(
interrupt_on={
"send_payment": {
# 允许人类做出的决定
"allowed_decisions": ["approve", "edit", "reject"],
},
# 没有列出的工具(如 read_email)默认不会触发中断
}
)
# 3. 创建 Agent
# 会话ID, 每次与大模型对话,都使用同一个会话ID
session_id = "session_id_1"
config = {
"configurable": {
"thread_id": session_id
}
}
agent = create_agent(
model=ds_model,
# 工具列表
tools=[read_email, send_payment],
checkpointer=memory, # 💾 关键:必须持久化状态
middleware=[hitl_middleware]
)
# 4. 定义提示词
prompt = """
你是一个邮件处理助手,负责处理用户的邮件和执行相关操作。
你的任务是:
1. 首先阅读邮件内容,了解邮件的性质和要求
2. 对于需要支付的邮件,调用send_payment工具执行支付
3. 对于其他邮件,只需要阅读和报告内容即可
重要规则:
- 使用read_email工具读取邮件内容时,不需要人工确认
- 使用send_payment工具进行支付时,必须等待人工确认才能执行
- 对于任何涉及金钱支付的操作,都必须严格遵守人工确认流程
用户的请求:请帮我处理邮件ID为 "invoice_001" 的发票支付事宜。
"""
# 5. 执行agent
print("开始执行agent任务...")
result = agent.invoke({"messages": [("user", prompt)]},
config=config)
for message in result["messages"]:
message.pretty_print()
# 6.通过决策,恢复执行
decision = "approve" # 假设用户确认支付
result = agent.invoke(
{"messages": [("user", f"用户确认支付:{decision}")]},
config=config
)
for message in result["messages"]:
message.pretty_print()**checkpointer**** (检查点)**:这是实现"人在回路"的基石。因为 Agent 在等待人工审批时程序会暂停运行,如果没有 checkpointer(如 InMemorySaver),Agent 就会忘记它刚才在干什么、为什么要调用这个工具。 **interrupt_on**:这是一个映射表,指定哪些工具需要被拦截。
- 如果你设置
{"tool_name": True},它会使用默认的审批逻辑。 - 如果你设置
allowed_decisions,你可以精细控制人类可以进行的操作。
执行后输出:
latex
开始执行agent任务...
================================ Human Message =================================
你是一个邮件处理助手,负责处理用户的邮件和执行相关操作。
你的任务是:
1. 首先阅读邮件内容,了解邮件的性质和要求
2. 对于需要支付的邮件,调用send_payment工具执行支付
3. 对于其他邮件,只需要阅读和报告内容即可
重要规则:
- 使用read_email工具读取邮件内容时,不需要人工确认
- 使用send_payment工具进行支付时,必须等待人工确认才能执行
- 对于任何涉及金钱支付的操作,都必须严格遵守人工确认流程
用户的请求:请帮我处理邮件ID为 "invoice_001" 的发票支付事宜。
================================== Ai Message ==================================
我将按照流程处理邮件ID为"invoice_001"的发票支付事宜。首先让我读取邮件内容。
Tool Calls:
read_email (19de1b0e-34a0-4f0b-8cf1-b5644eb1603b)
Call ID: 19de1b0e-34a0-4f0b-8cf1-b5644eb1603b
Args:
email_id: invoice_001
================================= Tool Message =================================
Name: read_email
邮件 invoice_001 的内容是:请在明天前向张三支付50元。
================================== Ai Message ==================================
已读取到邮件内容:"请在明天前向张三支付50元"。这是一封要求支付的发票邮件。
根据邮件内容,需要向收款人"张三"支付金额50元。由于这涉及到实际的支付操作,按照安全规则,我需要等待人工确认后才能执行支付。
**确认请求:**
- 收款人:张三
- 支付金额:50元
- 支付截止时间:明天前
请确认是否同意执行此支付操作。
================================ Human Message =================================
你是一个邮件处理助手,负责处理用户的邮件和执行相关操作。
你的任务是:
1. 首先阅读邮件内容,了解邮件的性质和要求
2. 对于需要支付的邮件,调用send_payment工具执行支付
3. 对于其他邮件,只需要阅读和报告内容即可
重要规则:
- 使用read_email工具读取邮件内容时,不需要人工确认
- 使用send_payment工具进行支付时,必须等待人工确认才能执行
- 对于任何涉及金钱支付的操作,都必须严格遵守人工确认流程
用户的请求:请帮我处理邮件ID为 "invoice_001" 的发票支付事宜。
================================== Ai Message ==================================
我将按照流程处理邮件ID为"invoice_001"的发票支付事宜。首先让我读取邮件内容。
Tool Calls:
read_email (19de1b0e-34a0-4f0b-8cf1-b5644eb1603b)
Call ID: 19de1b0e-34a0-4f0b-8cf1-b5644eb1603b
Args:
email_id: invoice_001
================================= Tool Message =================================
Name: read_email
邮件 invoice_001 的内容是:请在明天前向张三支付50元。
================================== Ai Message ==================================
已读取到邮件内容:"请在明天前向张三支付50元"。这是一封要求支付的发票邮件。
根据邮件内容,需要向收款人"张三"支付金额50元。由于这涉及到实际的支付操作,按照安全规则,我需要等待人工确认后才能执行支付。
**确认请求:**
- 收款人:张三
- 支付金额:50元
- 支付截止时间:明天前
请确认是否同意执行此支付操作。
================================ Human Message =================================
用户确认支付:approve
================================== Ai Message ==================================
好的,收到您的确认指令。现在我将执行支付操作。
Tool Calls:
send_payment (7c26072a-f72d-4d30-b8d0-4de133c718b9)
Call ID: 7c26072a-f72d-4d30-b8d0-4de133c718b9
Args:
amount: 50
recipient: 张三其它更多示例请查看文档 https://docs.langchain.com/oss/python/langchain/middleware/built-in
5.自定义中间件
编写自定义中间件通常需要继承 BaseMiddleware 基类,并重写其中的"钩子"函数(Hooks)。
在编写代码前,我们先看一看 Agent 运行过程中最常用的几个切入点:
中间件的生命周期钩子 :
| 钩子函数 (Hook) | **触发时机 **⏰ | **常见用途 **💡 |
|---|---|---|
on_start |
Agent 开始执行任务时 | 初始化日志、设置计时器 |
on_model_start |
发送请求给 LLM 之前 | 修改 Prompt、检查输入合规性 |
on_model_end |
LLM 返回结果后 | 统计 Token、解析特定格式 |
on_tool_start |
调用某个工具之前 | 动态修改工具参数、权限校验 |
on_tool_end |
工具执行完毕后 | 格式化工具输出、错误处理 |
**下面编写一个"耗时统计"中间件 :我们需要监控 Agent 每一轮思考(模型调用)花费了多长时间,以便优化性能。 **
python
from typing import Any, Optional
import time
from langchain.agents import create_agent
from langchain.agents.middleware import AgentMiddleware, AgentState
from langchain.chat_models import init_chat_model
# runtime 提供关于当前运行环境的元数据
from langgraph.runtime import Runtime
class TimingMiddleware(AgentMiddleware):
"""
耗时统计中间件
"""
def before_model(self, state: AgentState, runtime: Runtime) -> Optional[dict[str, Any]]:
# 1. 记录模型开始调用的时间
# 我们可以利用 runtime.metadata 或简单的类属性存储临时状态
self.start_time = time.time()
print(f"🔍模型开始思考...")
return None # 返回 None 表示不修改 state
def after_model(self, state: AgentState, runtime: Runtime) -> Optional[dict[str, Any]]:
# 2. 计算耗时
duration = time.time() - self.start_time
print(f"✅ 模型思考完毕,耗时: {duration:.2f} 秒")
# 3. 可以在这里向 state 中添加统计元数据
return None
if __name__ == '__main__':
ollama_url = "http://192.168.6.133:11434"
# 模型
ds_model = init_chat_model(
model="ollama:deepseek-v3.1:671b-cloud",
base_url=ollama_url)
agent = create_agent(
model=ds_model,
# 实例化你的自定义类
middleware=[TimingMiddleware()]
)
result = agent.invoke({"messages": [("user", "你是谁?")]})
for message in result["messages"]:
message.pretty_print()执行后输出:
latex
🔍模型开始思考...
✅ 模型思考完毕,耗时: 2.66 秒
================================ Human Message =================================
你是谁?
================================== Ai Message ==================================
你好!我是DeepSeek,由深度求索公司创造的AI助手!😊
我很高兴为你提供帮助!我可以协助你处理各种问题,比如:
- 回答知识问答
- 帮助写作和翻译
- 进行逻辑推理和分析
- 处理上传的文件(图像、PDF、Word、Excel等)
- 编程相关的任务
我是完全免费的,支持128K上下文长度,还可以通过联网搜索获取最新信息(需要你手动开启搜索功能)。
有什么我可以帮你的吗?我会尽力为你提供准确、有用的帮助!✨