1. 存储系统概述
1.1 区块链存储的独特挑战
以太坊作为世界计算机,其存储系统面临着传统数据库系统不一样的挑战。历史数据永不删除,每个区块的状态都可能被查询,所有数据必须通过Merkle树进行加密学验证,以确保相同输入产生相同的存储状态。系统每个周期产生一个新区块且永不停止,智能合约状态数据呈指数级增长,同时还需要支持任意历史时点的状态查询。既要满足新区块在一个出块周期内完成处理的实时性要求,又要保证历史数据查询的毫秒级响应,还要将TB级数据的存储成本控制在经济可行的范围内。
2. 启动模式与存储方案
2.1 同步模式对比表
| 同步模式 | 存储策略 | 适用场景 |
|---|---|---|
| Full | 完整区块+状态验证 | 验证节点、DApp后端 |
| Full (Archive) | 完整区块+所有历史状态 | 归档节点、区块浏览器 |
| Fast | 快照+最近区块 | 一般用户节点 |
| Snap | 状态快照+区块头 | 轻量级节点 |
| Light | 仅区块头 | 移动端、IoT设备 |
2.2 垃圾回收模式对比表
| GC模式 | 状态保留策略 | 存储需求 | 查询能力 | 内存使用 | 适用场景 |
|---|---|---|---|---|---|
| Full | 最近128个区块和状态 | ~500GB | 有限历史查询 | 4-8GB | 标准节点 |
| Archive | 所有历史状态 | ~12TB+ | 完整历史查询 | 16-64GB | 归档节点、区块浏览器 |
3. 数据字典与键值格式
3.1 系统元数据键值表
基于core/rawdb/schema.go的完整键值格式定义:
| 键名称 | 键值 | 值类型 | 用途说明 |
|---|---|---|---|
databaseVersionKey |
"DatabaseVersion" |
uint64 | 数据库版本号 |
headHeaderKey |
"LastHeader" |
Hash(32B) | 最新已知区块头哈希 |
headBlockKey |
"LastBlock" |
Hash(32B) | 最新已知完整区块哈希 |
headFastBlockKey |
"LastFast" |
Hash(32B) | 快速同步最新区块哈希 |
headFinalizedBlockKey |
"LastFinalized" |
Hash(32B) | 最新确定区块哈希 |
persistentStateIDKey |
"LastStateID" |
uint64 | 最新存储状态ID(Path模式) |
txIndexTailKey |
"TransactionIndexTail" |
uint64 | 最旧已索引交易区块号 |
snapshotRootKey |
"SnapshotRoot" |
Hash(32B) | 最新快照根哈希 |
3.2 区块链数据键值表
| 数据类型 | 键前缀 | 键格式 | 值格式 | 计算方式 |
|---|---|---|---|---|
| 区块头 | "h" |
"h" + number(8B) + hash(32B) |
RLP(Header) | headerKey(number, hash) |
| 区块体 | "b" |
"b" + number(8B) + hash(32B) |
RLP(Body) | blockBodyKey(number, hash) |
| 收据 | "r" |
"r" + number(8B) + hash(32B) |
RLP(Receipts) | blockReceiptsKey(number, hash) |
| 规范哈希 | "H" |
"H" + number(8B) |
Hash(32B) | headerNumberKey(hash) |
| 区块号查找 | "h"+"n" |
"h" + number(8B) + "n" |
Hash(32B) | headerHashKey(number) |
| 交易查找 | "l" |
"l" + txHash(32B) |
RLP(TxLookupEntry) | txLookupKey(hash) |
3.3 状态数据键值表
| 数据类型 | 键前缀 | 键格式 | 值格式 | 计算方式 |
|---|---|---|---|---|
| 账户快照 | "a" |
"a" + addressHash(32B) |
SlimRLP(Account) | Keccak256(address.Bytes()) |
| 存储快照 | "o" |
"o" + addressHash(32B) + storageHash(32B) |
RLP(StorageValue) | Keccak256(address) + Keccak256(key) |
| 合约代码 | "c" |
"c" + codeHash(32B) |
\[\]byte(原始代码) | Keccak256(code) |
| 预映像 | "secure-key-" |
"secure-key-" + hash(32B) |
\[\]byte(原始键) | 安全Trie的键映射 |
3.4 Trie节点键值表
| 存储方案 | 键前缀 | 键格式 | 值格式 | 特点 |
|---|---|---|---|---|
| Hash Scheme | 无 | nodeHash(32B) |
RLP(TrieNode) | 直接哈希索引,支持多版本 |
| Path Scheme (账户) | "A" |
"A" + hexPath |
RLP(TrieNode) | 路径索引,数据局部性好 |
| Path Scheme (存储) | "O" |
"O" + owner(32B) + hexPath |
RLP(TrieNode) | 按合约分组,便于修剪 |
3.5 键值计算函数
go
// 区块号编码函数
func encodeBlockNumber(number uint64) []byte {
enc := make([]byte, 8)
binary.BigEndian.PutUint64(enc, number) // 大端序编码
return enc
}
// 区块头键生成
func headerKey(number uint64, hash common.Hash) []byte {
return append(append(headerPrefix, encodeBlockNumber(number)...), hash.Bytes()...)
}
// 账户快照键生成
func accountSnapshotKey(hash common.Hash) []byte {
return append(SnapshotAccountPrefix, hash.Bytes()...)
}
// 存储快照键生成
func storageSnapshotKey(accountHash, storageHash common.Hash) []byte {
return append(append(SnapshotStoragePrefix, accountHash.Bytes()...), storageHash.Bytes()...)
}3.6 值编码格式详解
| 值类型 | 编码格式 | 字段说明 | 优化特点 |
|---|---|---|---|
| SlimRLP账户 | RLP(nonce, balance, root, codeHash) |
去除空字段的精简编码 | 节省空间 |
| 存储值 | RLP(value) |
自动去除前导零 | 大数值压缩效果好 |
| Trie节点 | RLP(nodeType, children, value) |
节点类型+子节点+值 | 支持三种节点类型 |
| 区块头 | RLP(parentHash, uncleHash, ...) |
完整区块头结构 | 包含所有共识字段 |
4. 分层存储架构
4.1 存储架构图
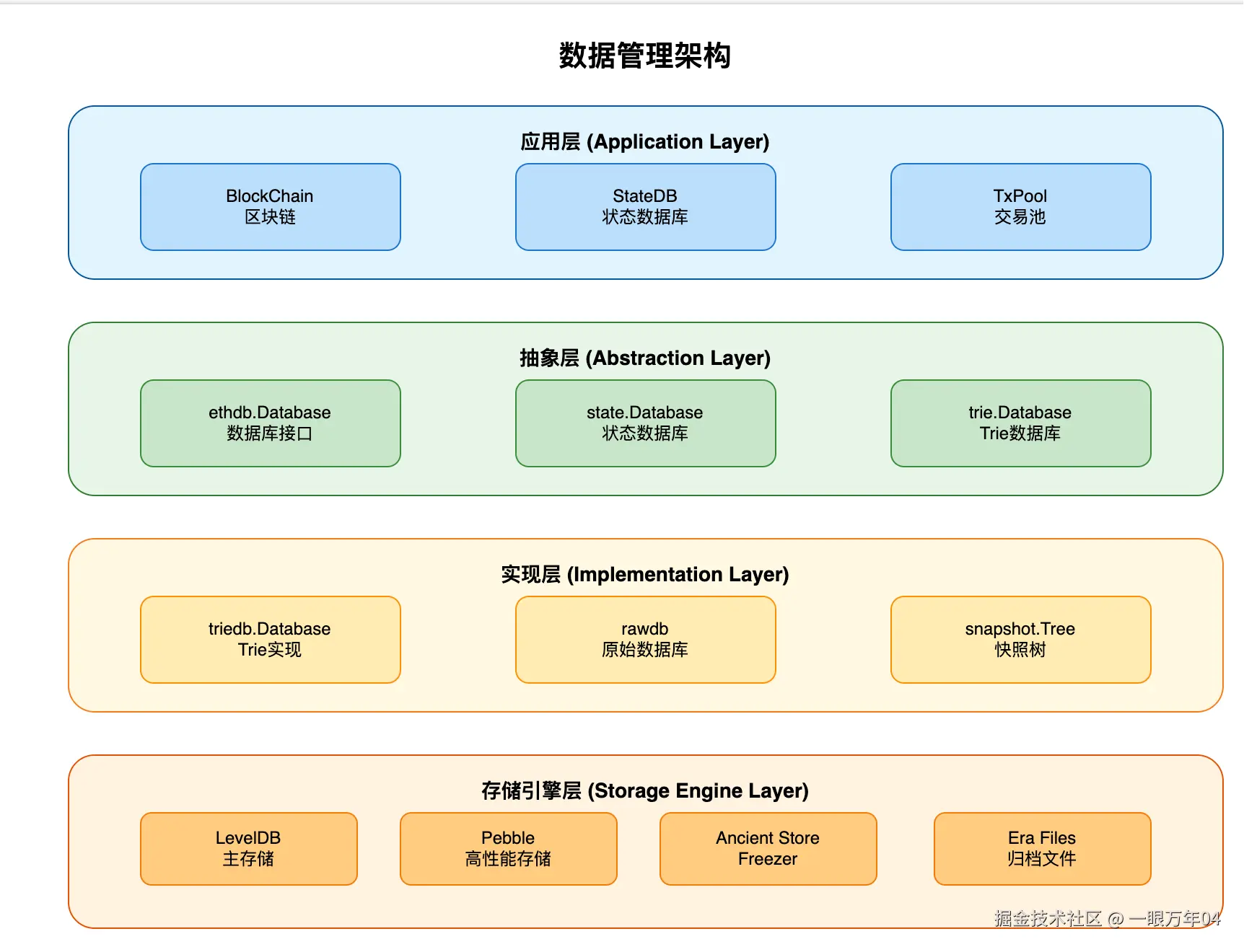
4.2 数据流转机制
数据生命周期流转:
scss
新区块 → 热存储(Pebble) → Ancient存储(Freezer) → 冷存储(Era)
↓ ↓ ↓ ↓
实时写入 高频查询 中频查询 低频查询
毫秒级 毫秒级 秒级 分钟级自动迁移触发条件:
- 热→Ancient:区块深度超过2048个区块
- Ancient→冷:手动触发或定期归档任务
- 迁移策略:后台异步,不影响主流程
5. Freezer文件结构
5.1 Freezer目录结构图
bash
Freezer目录结构 (chaindata/ancient/chain/):
├── FLOCK # 文件锁,防止多进程同时访问
├── MANIFEST # 清单文件,记录所有表的元信息
├── headers/ # 区块头表目录
│ ├── headers.0000.cdat # 数据文件0(Snappy压缩),不压缩表: .rdat (raw data), 压缩表: .cdat (compressed data)
│ ├── headers.0000.cidx # 索引文件0(压缩索引),不压缩表: .ridx (raw index),压缩表: .cidx (compressed index)
│ ├── headers.0001.cdat # 数据文件1(当文件0达到2GB时创建)
│ ├── headers.0001.cidx # 索引文件1
│ └── ... # 更多文件对
├── hashes/ # 区块哈希表目录
│ ├── hashes.0000.rdat # 数据文件(不压缩,32字节哈希)
│ ├── hashes.0000.ridx # 索引文件(原始索引)
│ └── ...
├── bodies/ # 区块体表目录
│ ├── bodies.0000.cdat # 数据文件(Snappy压缩)
│ ├── bodies.0000.cidx # 索引文件(压缩索引)
│ └── ...
└── receipts/ # 收据表目录
├── receipts.0000.cdat # 数据文件(Snappy压缩)
├── receipts.0000.cidx # 索引文件(压缩索引)
└── ...5.2 Freezer数据文件格式(.rdat)
yaml
Freezer数据文件内部结构 (.cdat/.rdat):
┌─────────────────────────────────────────────────────────────┐
│ 真实的Freezer数据文件格式 │
├─────────────────────────────────────────────────────────────┤
│ Item 0: │ RLP编码的区块数据 (Variable Length, 无长度前缀) │
│ │ ┌─ headers: RLP(Header结构体) [Snappy压缩] │
│ │ ├─ hashes: 32字节区块哈希 [不压缩] │
│ │ ├─ bodies: RLP(Body结构体) [Snappy压缩] │
│ │ └─ receipts: RLP(Receipts数组) [Snappy压缩] │
├─────────────────────────────────────────────────────────────┤
│ Item 1: │ RLP编码的区块数据 (Variable Length, 无长度前缀) │
│ │ ┌─ headers: RLP(Header结构体) [Snappy压缩] │
│ │ ├─ hashes: 32字节区块哈希 [不压缩] │
│ │ ├─ bodies: RLP(Body结构体) [Snappy压缩] │
│ │ └─ receipts: RLP(Receipts数组) [Snappy压缩] │
├─────────────────────────────────────────────────────────────┤
│ ... │
└─────────────────────────────────────────────────────────────┘5.3 Freezer索引文件格式(.ridx)
scss
Freezer索引文件内部结构 (.cidx/.ridx):
┌─────────────────────────────────────────────────────────────┐
│ 真实的Freezer索引文件格式 │
├─────────────────────────────────────────────────────────────┤
│ Entry 0: │ filenum(2B) │ offset(4B) │ = 6字节索引条目 │
├─────────────────────────────────────────────────────────────┤
│ Entry 1: │ filenum(2B) │ offset(4B) │ = 6字节索引条目 │
├─────────────────────────────────────────────────────────────┤
│ Entry 2: │ filenum(2B) │ offset(4B) │ = 6字节索引条目 │
├─────────────────────────────────────────────────────────────┤
│ ... │
├─────────────────────────────────────────────────────────────┤
│ Entry N: │ filenum(2B) │ offset(4B) │ = 6字节索引条目 │
└─────────────────────────────────────────────────────────────┘索引计算规则:
- 每个条目4字节小端序偏移量
- 偏移量指向.rdat文件中对应数据的起始位置
- 通过 itemIndex * 4 计算索引文件中的位置
- 支持O(1)时间复杂度的随机访问
5.4 Freezer读写机制
写入流程:
- 数据RLP编码
- 根据配置决定是否Snappy压缩
- 写入长度前缀(4字节) + 数据到.rdat文件
- 记录偏移量到.ridx文件
- 原子性更新文件头部计数器
读取流程:
- 根据项目编号计算索引位置:
itemIndex * 4 - 从.ridx文件读取偏移量
- 从.rdat文件的偏移位置读取长度和数据
- 根据配置决定是否Snappy解压
- RLP解码得到原始数据结构
6. 归档Era文件存储
Era文件系统采用了精心设计的架构:
- 每个Era文件包含固定的8192个区块,这种标准化的容量设计不仅便于文件管理和版本控制,也优化了网络传输效率;
- 通过Snappy压缩算法实现了高压缩比,显著减少了存储空间占用;
- Era文件在尾部设计了智能索引机制,支持O(1)时间复杂度的随机访问,即使面对TB级别的归档数据也能实现毫秒级的查询响应;
- 内置的累加器机制提供了强大的数据完整性验证能力,确保长期存储的历史数据不会因为硬件故障或传输错误而损坏,为以太坊网络的历史数据提供了可靠的归档保障。
6.1. Era目录结构
bash
Era目录结构 (chaindata/ancient/era/ 或独立目录):
├── mainnet-00001-a1b2c3d4.era1 # 第1个时期 (区块0-8191)
├── mainnet-00002-b2c3d4e5.era1 # 第2个时期 (区块8192-16383)
├── mainnet-00003-c3d4e5f6.era1 # 第3个时期 (区块16384-24575)
├── mainnet-00004-d4e5f6g7.era1 # 第4个时期 (区块24576-32767)
├── mainnet-00005-e5f6g7h8.era1 # 第5个时期 (区块32768-40959)
├── ... # 更多时期文件
├── mainnet-01000-f6g7h8i9.era1 # 第1000个时期
└── mainnet-01001-g7h8i9j0.era1 # 第1001个时期6.2 Era文件命名规范
go
// Filename 生成Era文件名的标准格式
func Filename(network string, epoch int, root common.Hash) string {
return fmt.Sprintf("%s-%05d-%s.era1", network, epoch, root.Hex()[2:10])
}
// 示例:mainnet-00001-a1b2c3d4.era1
// - mainnet: 网络名称
// - 00001: 时期编号(5位数字,每个时期8192个区块)
// - a1b2c3d4: 时期结束区块的根哈希前8位
// - .era1: Era格式版本16.3 Era文件格式图
scss
Era1文件结构 (基于e2store格式):
┌─────────────────────────────────────────────────────────────┐
│ Era文件头部 │
├─────────────────────────────────────────────────────────────┤
│ Version Entry │ Type(0x3265) │ Length(4B) │ Rsv(2B) │ │
│ │ 小端序编码 │ 小端序编码 │ 保留字段 │ │
├─────────────────────────────────────────────────────────────┤
│ 区块数据区 │
├─────────────────────────────────────────────────────────────┤
│ Block 0 Tuple: │
│ ├─ Header │ Type(0x03) │ Length │ Snappy压缩RLP数据 │
│ ├─ Body │ Type(0x04) │ Length │ Snappy压缩RLP数据 │
│ ├─ Receipts │ Type(0x05) │ Length │ Snappy压缩RLP数据 │
│ └─ TotalDiff │ Type(0x06) │ Length │ 原始big.Int数据 │
├─────────────────────────────────────────────────────────────┤
│ Block 1 Tuple: │
│ ├─ Header │ Type(0x03) │ Length │ Snappy压缩RLP数据 │
│ ├─ Body │ Type(0x04) │ Length │ Snappy压缩RLP数据 │
│ ├─ Receipts │ Type(0x05) │ Length │ Snappy压缩RLP数据 │
│ └─ TotalDiff │ Type(0x06) │ Length │ 原始big.Int数据 │
├─────────────────────────────────────────────────────────────┤
│ ... (最多8192个区块) │
├─────────────────────────────────────────────────────────────┤
│ 文件尾部 │
├─────────────────────────────────────────────────────────────┤
│ Accumulator │ Type(0x07) │ Length │ Accumulator Data │
├─────────────────────────────────────────────────────────────┤
│ Block Index │ Type(0x3266) │ Length │ Index Data │
│ ├─ Block 0 Offset: 8字节 (小端序) │
│ ├─ Block 1 Offset: 8字节 (小端序) │
│ ├─ ... │
│ ├─ Block N Offset: 8字节 (小端序) │
│ ├─ Start Number: 8字节 (起始区块号) │
│ └─ Count: 8字节 (区块总数) │
└─────────────────────────────────────────────────────────────┘6.4 e2store条目格式
diff
e2store条目格式 (Type-Length-Value):
┌──────┬──────┬──────┬──────────────────────────┐
│ Type │ Len │ Rsv │ Value │
│ 2B │ 4B │ 2B │ Variable │
└──────┴──────┴──────┴──────────────────────────┘
Type字段定义:
- 0x3265: Era版本标识
- 0x03: 压缩区块头
- 0x04: 压缩区块体
- 0x05: 压缩收据
- 0x06: 总难度(不压缩)
- 0x07: 累加器
- 0x3266: 区块索引7. 数据存储流程
以太坊的数据存储是一个复杂的多阶段流程,从新区块的产生到最终的Era文件归档,涉及多个存储层的协调工作。下图展示了完整的数据流转过程:
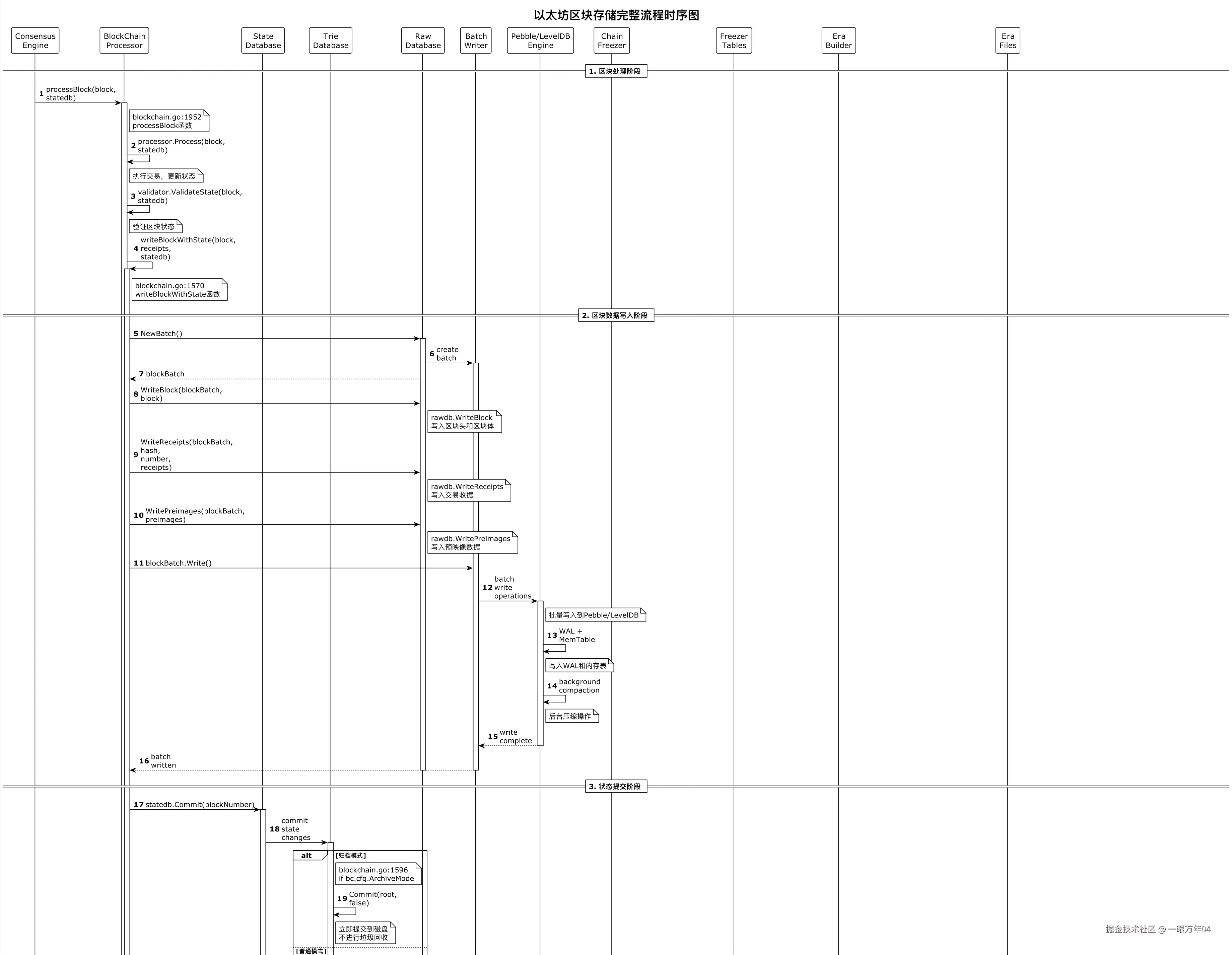
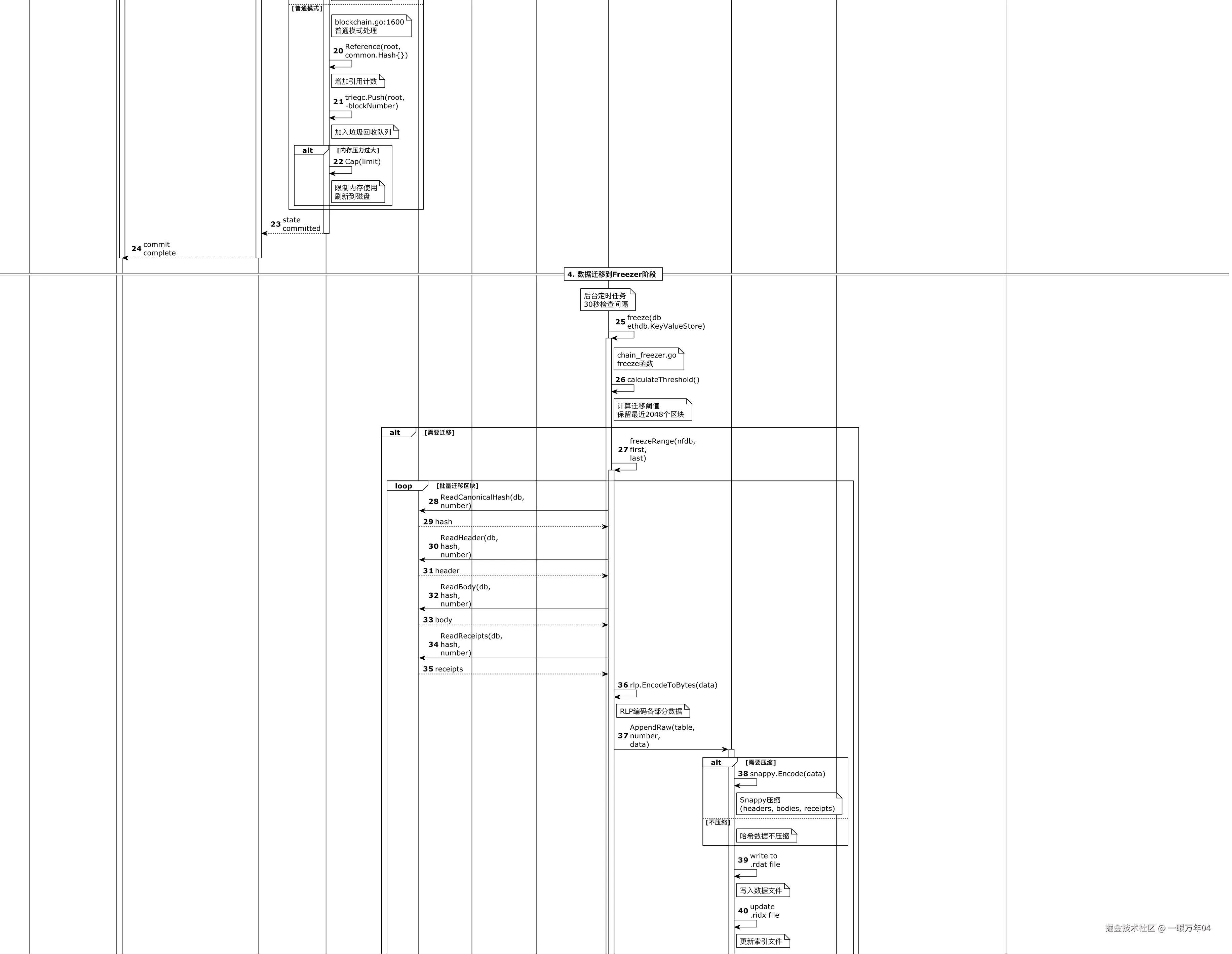
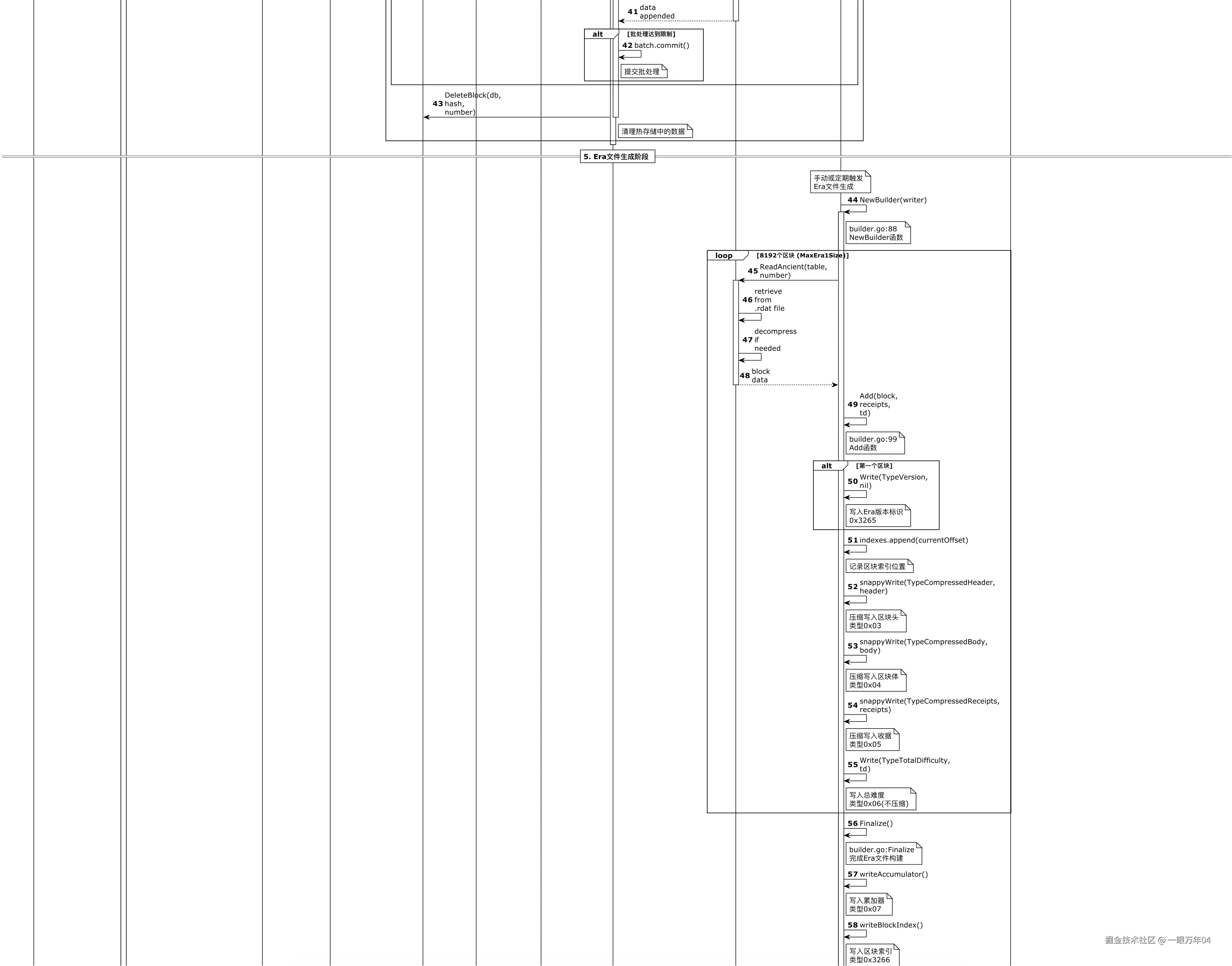

8. 总结
go-ethereum的存储系统通过精心设计的架构,成功应对了区块链账本面临的核心技术挑战。在可扩展性方面,该系统不仅能够高效处理TB级别的海量数据存储和查询需求,更通过创新的分层架构设计实现了存储成本与查询性能之间的最优平衡,同时采用模块化的设计理念为未来技术演进预留了充分的扩展空间;在可靠性保障上,系统构建了多层次的数据验证机制来确保长期存储数据的完整性,并建立了完善的错误处理和自动恢复机制来应对各种异常情况;在性能优化层面,通过多级缓存策略实现了毫秒级的查询响应速度,并通过批量操作技术大幅优化了磁盘I/O性能,这些技术创新共同构成了以太坊网络稳定运行的坚实技术基础。