关系型数据库表连接(SQL JOINS) 笔记250811
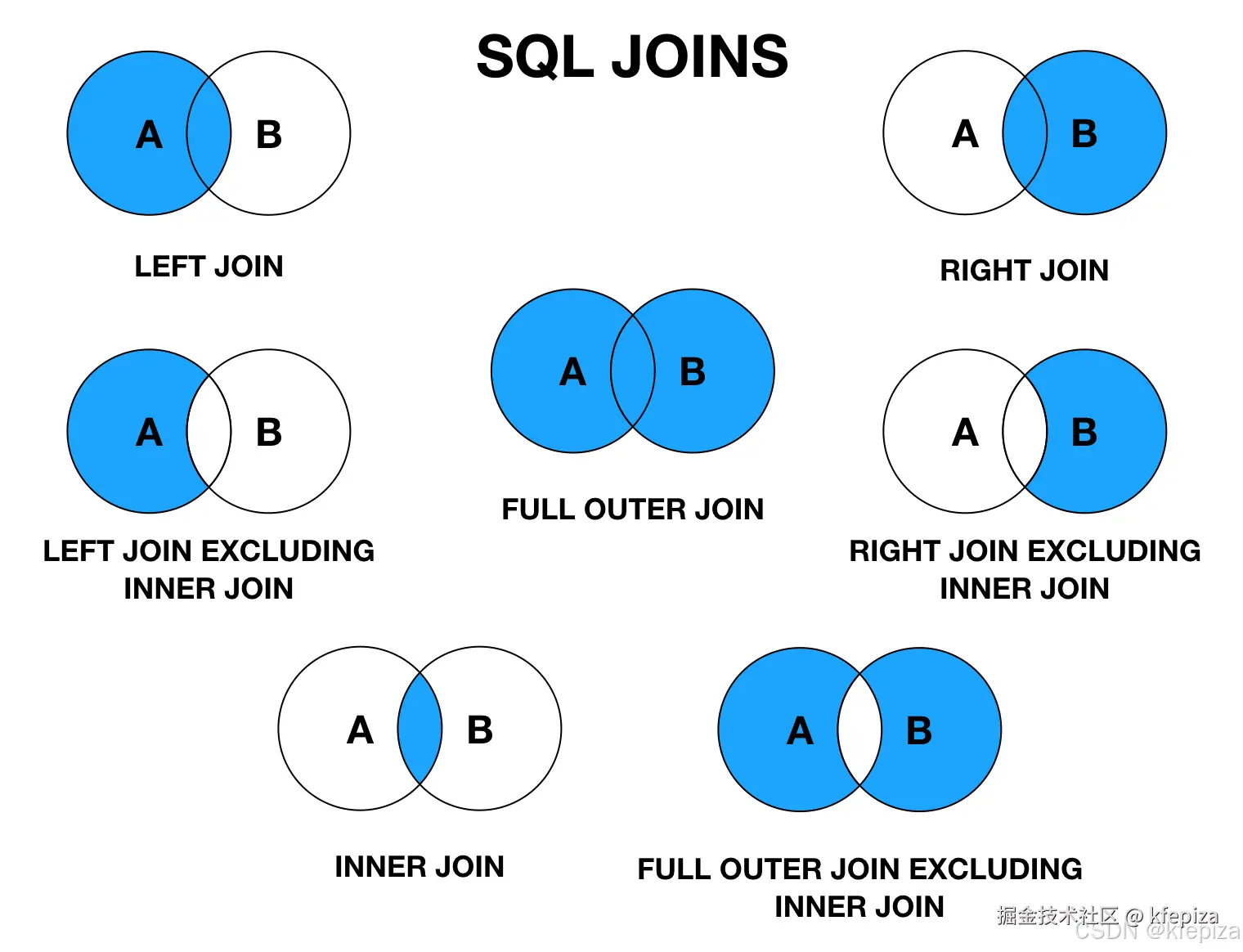
SQL 中的表连接(Table Joins)是关系型数据库的核心操作之一,它允许你将来自两个或多个表中的行组合起来,基于这些表之间的相关列(通常是外键关系)进行关联。
核心概念:
- 关系: 数据库表通常设计为存储特定实体的信息(如
Customers、Orders、Products)。这些实体之间存在关系(如一个Customer可以有多个Orders,一个Order包含多个Products)。 - 连接条件(Join Condition): 指定如何匹配两个表中的行。最常见的是基于一个表中的列等于另一个表中的列(例如
Customers.CustomerID = Orders.CustomerID)。这是通过ON关键字或USING关键字(当列名相同时)来定义的。 - 连接键(Join Key): 用于连接表的列。通常是主键(Primary Key)和外键(Foreign Key),但也可以是任何逻辑上相关的列。
主要的连接类型:
-
内连接(INNER JOIN)
-
作用: 返回两个表中连接键值完全匹配的所有行。
-
结果: 只包含那些在左表和右表中都找到匹配的行。如果一个表中的某行在另一个表中没有匹配项,则该行不会出现在结果中。
-
语法:
sqlSELECT column_list FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name; -- 或者使用 USING (当连接键列名完全相同时,更简洁) SELECT column_list FROM table1 INNER JOIN table2 USING (common_column_name); -
示例: 获取所有下了订单的客户信息(包括客户和订单详情)。
sqlSELECT Customers.CustomerName, Orders.OrderID, Orders.OrderDate FROM Customers INNER JOIN Orders ON Customers.CustomerID = Orders.CustomerID;
-
-
左外连接(LEFT OUTER JOIN 或 LEFT JOIN)
-
作用: 返回左表(
FROM子句后的第一个表)的所有行 ,以及右表中连接键匹配的行。 -
结果: 如果左表的某行在右表中没有匹配项,则结果集中右表的所有列将包含
NULL值。 -
语法:
sqlSELECT column_list FROM table1 LEFT [OUTER] JOIN table2 ON table1.column_name = table2.column_name; -- 或 USING -
示例: 获取所有客户信息,并显示他们下的订单(如果有的话)。即使客户从未下过单,也会列出客户信息,订单相关列为
NULL。sqlSELECT Customers.CustomerName, Orders.OrderID FROM Customers LEFT JOIN Orders ON Customers.CustomerID = Orders.CustomerID;
-
-
右外连接(RIGHT OUTER JOIN 或 RIGHT JOIN)
-
作用: 返回右表(
JOIN子句后的表)的所有行 ,以及左表中连接键匹配的行。 -
结果: 如果右表的某行在左表中没有匹配项,则结果集中左表的所有列将包含
NULL值。 -
语法:
sqlSELECT column_list FROM table1 RIGHT [OUTER] JOIN table2 ON table1.column_name = table2.column_name; -- 或 USING -
示例: 获取所有订单信息,并显示下订单的客户信息。即使订单对应的客户记录因某种原因缺失(理论上不应该发生,但用于演示),也会列出订单信息,客户相关列为
NULL。sqlSELECT Orders.OrderID, Customers.CustomerName FROM Orders RIGHT JOIN Customers ON Orders.CustomerID = Customers.CustomerID; -
注意: 右连接通常可以用左连接重写(交换表的位置),因此不如左连接常用。理解其概念很重要。
-
-
全外连接(FULL OUTER JOIN 或 FULL JOIN)
-
作用: 返回左表和右表的所有行。
-
结果:
- 当左表的行在右表中有匹配时,返回匹配的行。
- 当左表的行在右表中无匹配时,右表列置为
NULL。 - 当右表的行在左表中无匹配时,左表列置为
NULL。
-
语法:
sqlSELECT column_list FROM table1 FULL [OUTER] JOIN table2 ON table1.column_name = table2.column_name; -- 或 USING -
示例: 获取所有客户和所有订单的组合。列出所有客户(即使没订单)和所有订单(即使客户缺失),缺失部分用
NULL填充。sqlSELECT Customers.CustomerName, Orders.OrderID FROM Customers FULL OUTER JOIN Orders ON Customers.CustomerID = Orders.CustomerID; -
注意: 并非所有数据库系统都原生支持
FULL OUTER JOIN(例如 MySQL 不支持,但可以通过LEFT JOIN+RIGHT JOIN+UNION模拟)。
-
-
交叉连接(CROSS JOIN)
-
作用: 返回两个表的笛卡尔积(Cartesian Product)。即左表中的每一行与右表中的每一行进行组合。
-
结果: 结果集的行数 = 左表行数 × 右表行数。没有连接条件(
ON子句)! -
语法:
sqlSELECT column_list FROM table1 CROSS JOIN table2; -- 等同于旧式语法(不推荐): SELECT column_list FROM table1, table2; -
示例: 生成所有可能的颜色和尺寸组合。
sqlSELECT Colors.ColorName, Sizes.SizeName FROM Colors CROSS JOIN Sizes;
-
-
自然连接(NATURAL JOIN)
-
作用: 自动连接两个表中所有同名列 。相当于省略
ON或USING的INNER JOIN。 -
语法:
sqlSELECT column_list FROM table1 NATURAL JOIN table2; -- INNER JOIN NATURAL LEFT JOIN table2; -- LEFT JOIN NATURAL RIGHT JOIN table2; -- RIGHT JOIN NATURAL FULL JOIN table2; -- FULL JOIN (如果支持) -
风险: 强烈不推荐 使用。因为它隐式地基于所有同名列进行连接,如果表结构改变(添加了新的同名但不相关的列),查询逻辑会悄无声息地改变,导致难以预料和调试的错误。显式使用
ON或USING是更安全、更清晰的做法。
-
关键注意事项:
- 连接条件 (
ON/USING): 对于INNER JOIN,LEFT JOIN,RIGHT JOIN,FULL JOIN至关重要。忘记写连接条件会导致意外的笛卡尔积(交叉连接),结果集行数剧增,性能极差。 - 表别名 (Aliases): 当表名较长或需要连接同一个表多次(自连接)时,使用别名 (
AS alias_name或直接table_name alias_name) 可以使查询更简洁易读。 - 选择列: 当连接的多个表中有同名列时,必须使用表名或别名来限定列名(
table_name.column_name或alias.column_name),以避免歧义错误。 - 性能: 复杂的连接(尤其是涉及大表或多个表)会影响查询性能。确保连接键上有适当的索引通常能显著提升速度。理解不同连接类型对结果集大小的影响也很重要。
WHERE与ON:ON子句指定如何连接表(定义行匹配的条件)。WHERE子句在连接完成后 对结果集进行过滤。- 对于
INNER JOIN,将过滤条件放在ON或WHERE中效果通常相同(但逻辑上ON定义连接关系)。 - 对于
OUTER JOIN(LEFT/RIGHT/FULL),将条件放在ON和WHERE有本质区别 :ON条件:影响连接过程本身。右表(对于LEFT JOIN)中不满足ON条件的行也会被包含(左表列有值,右表列为NULL)。WHERE条件:在连接完成后应用。如果WHERE条件引用了右表(对于LEFT JOIN)的列并要求非NULL,它会过滤掉那些因右表不匹配而产生的NULL行,实际上把LEFT JOIN变成了INNER JOIN。这是常见的错误点。
总结:
理解并正确使用 SQL 表连接是高效查询关系型数据库的基础。INNER JOIN 用于查找匹配项,LEFT JOIN/RIGHT JOIN 用于包含"主表"的所有记录(即使另一表无匹配),FULL JOIN 用于包含所有记录,CROSS JOIN 用于生成所有组合。始终显式指定连接条件 (使用 ON 或 USING),避免使用 NATURAL JOIN,并注意 WHERE 和 ON 在 OUTER JOIN 中的区别。
关系型数据库表连接
关系型数据库中的表连接(Table Joins) 是其核心能力,用于根据表之间的关联关系(通常通过外键 实现)组合多个表中的数据。这种设计遵循关系模型的理念,通过拆分数据到不同的表(减少冗余)再通过连接操作重组信息。
以下是表连接的深度解析:
一、为什么需要表连接? 关系型数据库通过规范化(Normalization) 设计表结构(减少数据冗余、避免异常)。这导致:
- 数据分散在多个表中(如
customers、orders、products)。 - 表之间通过主键(Primary Key) 和外键(Foreign Key) 建立逻辑关联(如
orders.customer_id关联customers.id)。 - 连接操作是重组这些分散数据的桥梁。
二、连接的核心类型与场景 1. 内连接(INNER JOIN)
-
作用 :仅返回两个表中匹配成功的行。
-
场景:查询存在关联关系的记录(如"已下单的客户")。
-
示例 :
sqlSELECT c.name, o.order_date FROM customers c INNER JOIN orders o ON c.id = o.customer_id;结果:只显示有订单的客户。
2. 左外连接(LEFT JOIN)或 (LEFT OUTER JOIN)
-
作用 :返回左表全部行 + 右表匹配的行(无匹配则右表字段为
NULL)。 -
场景:保留主表全部记录(如"所有客户,包括未下单的")。
-
示例 :
sqlSELECT c.name, o.order_date FROM customers c LEFT JOIN orders o ON c.id = o.customer_id;结果 :所有客户都显示,无订单的客户其
order_date为NULL。
3. 右外连接(RIGHT JOIN)或 (RIGHT OUTER JOIN)
-
作用 :返回右表全部行 + 左表匹配的行(无匹配则左表字段为
NULL)。 -
场景 :保留右表全部记录(较少用,通常用
LEFT JOIN替代)。 -
示例 :
sqlSELECT c.name, o.order_date FROM orders o RIGHT JOIN customers c ON o.customer_id = c.id; -- 等价于 LEFT JOIN 调换表顺序
4. 全外连接(FULL OUTER JOIN)
-
作用 :返回左右表所有行(无匹配的对方表字段为
NULL)。 -
场景:合并两个表的所有记录(如"客户与订单的完整关系,包括孤儿记录")。
-
注意 :MySQL 不支持,需用
UNION模拟:sqlSELECT c.name, o.order_date FROM customers c LEFT JOIN orders o ON c.id = o.customer_id UNION SELECT c.name, o.order_date FROM customers c RIGHT JOIN orders o ON c.id = o.customer_id WHERE c.id IS NULL;
5. 交叉连接(CROSS JOIN)
-
作用:返回两表的笛卡尔积(所有行组合)。
-
场景:生成组合数据(如"所有产品与所有颜色的搭配")。
-
示例 :
sqlSELECT p.name, c.color_name FROM products p CROSS JOIN colors c;
三、高级连接技巧 1. 自连接(Self-Join)
-
同一表与自己连接(需用别名区分)。
-
场景 :层级数据查询(如"员工与经理关系"):
sqlSELECT e.name AS employee, m.name AS manager FROM employees e LEFT JOIN employees m ON e.manager_id = m.id;
2. 多表连接
-
链式连接多个表:
sqlSELECT c.name, o.order_date, p.product_name FROM customers c INNER JOIN orders o ON c.id = o.customer_id INNER JOIN order_items i ON o.id = i.order_id INNER JOIN products p ON i.product_id = p.id;
3. 非等值连接(Non-Equi Join)
-
使用
>、<、BETWEEN等非等值条件:sqlSELECT a.product, b.discount FROM prices a JOIN discounts b ON a.price BETWEEN b.min_price AND b.max_price;
四、关键注意事项
-
连接条件(ON vs WHERE):
-
ON定义连接时的匹配条件(影响连接结果)。 -
WHERE在连接后过滤数据(影响最终输出)。 -
外连接陷阱 :在
WHERE中过滤右表字段可能导致结果退化为内连接!sql-- 错误:LEFT JOIN 失效(过滤 NULL 后等同于 INNER JOIN) SELECT c.name, o.order_date FROM customers c LEFT JOIN orders o ON c.id = o.customer_id WHERE o.amount > 100; -- 排除了无订单的客户! -- 正确:将条件放入 ON 子句 SELECT c.name, o.order_date FROM customers c LEFT JOIN orders o ON c.id = o.customer_id AND o.amount > 100; -- 保留无订单客户
-
-
性能优化:
- 索引:确保连接字段(如外键)有索引。
- 避免笛卡尔积:除非明确需要,否则必须写连接条件。
- 减少连接表数量:只连接必要表。
-
显式语法:
- 使用
JOIN ... ON替代旧式隐式连接(FROM a, b WHERE a.id=b.id),更清晰安全。
- 使用
五、连接背后的设计思想 表连接是关系模型的实践:
- 数据独立性:通过连接动态组合数据,而非物理存储冗余。
- 完整性约束 :外键确保连接的有效性(如禁止插入不存在的
customer_id)。 - 声明式编程:只需指定"连接逻辑",数据库引擎优化执行过程。
总结
| 连接类型 | 关键字 | 核心作用 | 常用场景 |
|---|---|---|---|
| 内连接 | INNER JOIN |
仅返回匹配行 | 获取有关联的数据 |
| 左外连接 | LEFT JOIN |
保留左表所有行 | 主表数据完整性(如客户+订单) |
| 右外连接 | RIGHT JOIN |
保留右表所有行 | 较少使用 |
| 全外连接 | FULL OUTER JOIN |
保留两表所有行 | 合并完整数据集 |
| 交叉连接 | CROSS JOIN |
返回笛卡尔积 | 生成组合数据 |
掌握表连接是高效操作关系型数据库的基石,合理选择连接类型和优化条件,能极大提升查询能力与性能。
join on 和 join using
在 SQL 中,JOIN ON 和 JOIN USING 都是用于指定表连接条件的语法,但它们在使用方式和效果上有重要区别:
📌 核心区别总结
| 特性 | JOIN ON |
JOIN USING |
|---|---|---|
| 语法结构 | ON table1.column = table2.column |
USING (column_name) |
| 列名要求 | 列名可以不同 | 列名必须完全相同 |
| 结果集列数 | 保留两个表的连接列(重复列) | 合并连接列为单列 |
| 列引用方式 | 需表名前缀(table.column) |
可直接用列名(无需前缀) |
| 连接条件类型 | 支持所有条件(等值/非等值) | 仅支持等值连接 |
| 多列连接 | 用 AND 连接多个条件 |
逗号分隔列名:USING (col1, col2) |
🔍 详细对比与示例 1. ** JOIN ON (显式条件连接)**
- 语法:明确指定两个表的连接列
- 特点 :
- 最通用的连接方式,适用于所有场景
- 连接列名可以不同
- 结果集中保留两个原始列(可能产生重复列)
- 必须使用表别名或表名前缀引用列
sql
-- 连接列名不同时的标准用法
SELECT o.order_id, c.customer_name
FROM orders o
JOIN customers c ON o.cust_id = c.customer_id;2. ** JOIN USING (简化等值连接)**
- 语法:直接使用公共列名
- 特点 :
- 仅当连接列名完全相同时可用
- 自动合并连接列为单列(消除重复)
- 可直接使用列名(无需表名前缀)
- 更简洁但灵活性较低
sql
-- 当连接列名相同时的简化写法
SELECT order_id, customer_name
FROM orders
JOIN customers USING (customer_id); -- 列名必须相同⚠️ 关键差异演示 假设有两个表:
sql
CREATE TABLE employees (
emp_id INT PRIMARY KEY,
name VARCHAR(50),
dept_id INT -- 与外键列名不同
);
CREATE TABLE departments (
id INT PRIMARY KEY, -- 主键列名不同
dept_name VARCHAR(50)
);✅ 正确使用 JOIN ON (处理不同列名)
sql
SELECT e.name, d.dept_name
FROM employees e
JOIN departments d ON e.dept_id = d.id; -- 连接不同名称的列❌ USING 会失败的情况
sql
-- 错误!列名不相同
SELECT name, dept_name
FROM employees
JOIN departments USING (dept_id); -- departments 没有 dept_id 列✅ USING 成功案例(修改表结构后) 如果修改 departments 表有 dept_id 列:
sql
ALTER TABLE departments RENAME COLUMN id TO dept_id;
-- 现在可以使用 USING
SELECT name, dept_name
FROM employees
JOIN departments USING (dept_id); -- 合并 dept_id 为单列🛠️ 多列连接对比 使用 ON 连接多列
sql
SELECT *
FROM table1 t1
JOIN table2 t2
ON t1.col1 = t2.col1
AND t1.col2 = t2.col2; -- 需要 AND 连接条件使用 USING 连接多列
sql
SELECT *
FROM table1
JOIN table2 USING (col1, col2); -- 更简洁的语法📊 结果集差异 假设连接结果:
orders.customer_id |
customers.customer_id |
order_id |
|---|---|---|
| 101 | 101 | A123 |
-
JOIN ON结果:保留两列plaintext| orders.customer_id | customers.customer_id | order_id | |--------------------|-----------------------|----------| | 101 | 101 | A123 | -
JOIN USING结果:合并为一列plaintext| customer_id | order_id | |-------------|----------| | 101 | A123 |
🧠 使用建议
-
优先使用
JOIN ON- 适用所有场景(尤其列名不同时)
- 更清晰的连接逻辑
- 避免意外错误(列名不一致时)
-
仅当以下条件满足时使用
USING- 连接列名严格相同
- 需要消除结果集中的重复列
- 追求最简语法(简单等值连接)
-
重要提示
sql-- 这两种写法等效(当列名相同时) SELECT * FROM table1 JOIN table2 ON table1.col = table2.col; SELECT * FROM table1 JOIN table2 USING (col);
💡 总结
| 场景 | 推荐语法 |
|---|---|
| 连接列名不同 | ✅ JOIN ON |
| 连接列名相同且需消除重复列 | ✅ JOIN USING |
| 非等值连接(如范围连接) | ✅ JOIN ON(必须) |
| 多表复杂连接 | ✅ JOIN ON(更清晰) |
| 简单等值连接且列名相同 | ⚠️ 可选 USING(简洁) |
根据你的数据库设计和具体需求选择最合适的语法,优先保证代码的清晰性和可维护性。
join on 与 join using 的兼容性, 哪些数据库支持?
在SQL中,JOIN ON和JOIN USING是两种指定表连接条件的语法,其兼容性和支持情况因数据库系统而异。以下是详细对比及主流数据库的支持分析:
📊 核心差异与兼容性总结
| 特性 | JOIN ON |
JOIN USING |
|---|---|---|
| 语法灵活性 | 支持任意条件(等值/非等值) | 仅支持等值连接,且列名必须相同 |
| 结果集列名 | 保留两表的连接列(重复显示) | 合并连接列为单列(消除重复) |
| 列引用方式 | 需表别名限定(如t1.id) |
直接使用列名(如id) |
| 多列连接 | 用AND拼接条件(ON t1.a=t2.a AND t1.b=t2.b) |
逗号分隔(USING (a, b)) |
| 数据库兼容性 | 广泛支持(所有主流数据库) | 部分支持(需列名一致) |
🗃️ 主流数据库支持情况
-
MySQL / MariaDB
JOIN ON:完全支持。JOIN USING:支持,但需连接列名相同;不支持FULL JOIN。
示例兼容性:
sql-- 支持USING SELECT * FROM orders JOIN customers USING (customer_id); -
Oracle
JOIN ON:完全支持,但拒绝链式JOIN...JOIN...ON AND语法 (需分写ON子句)。JOIN USING:支持,但禁止在SELECT列表中对连接列使用表别名 (如oi.order_id报错)。
示例错误:
sql-- Oracle中报错:USING的列不能有限定符 SELECT oi.order_id FROM orders oi JOIN orders o USING (order_id); -
SQLite
JOIN ON:完全支持。JOIN USING:部分支持,但不支持RIGHT JOIN和FULL JOIN。
-
PostgreSQL
- 两者均完全支持,且行为符合SQL标准。
-
SQL Server
- 仅支持
JOIN ON,不支持USING语法 (需用ON t1.col=t2.col替代)。
- 仅支持
⚠️ 关键注意事项
-
USING的列名限制:- 若两表连接列名不同,必须用
ON。例如orders.cust_id和customers.customer_id无法用USING。 - 使用
USING时,查询中禁止对连接列添加表别名 (如SELECT oi.order_id会报错)。
- 若两表连接列名不同,必须用
-
结果集差异:
USING会合并连接列 (如customer_id仅显示一列),而ON保留两列(如orders.customer_id和customers.customer_id)。
示例输出对比:ON结果:| orders.customer_id | customers.customer_id |USING结果:| customer_id |
-
迁移与兼容性建议:
- 优先使用
JOIN ON:兼容所有数据库,避免列名冲突风险。 - 仅当表结构一致且需简化查询时,考虑
USING(如MySQL/Oracle环境)。
- 优先使用
-
数据库特殊限制:
- MySQL:
USING可搭配LEFT JOIN,但不可用于FULL JOIN(因本身不支持)。 - Oracle:链式JOIN需严格分段写
ON,不可合并(如JOIN t1 JOIN t2 ON a=b AND c=d无效)。
- MySQL:
💎 总结建议
- 兼容性首选 :
JOIN ON------ 适用于所有场景(列名不同、非等值连接、多数据库迁移)。 - 简化场景可选 :
JOIN USING------ 仅当连接列名相同且需消除重复列时(MySQL/PostgreSQL/Oracle可用)。 - 避坑指南 :
- 在Oracle中避免对
USING的列加别名; - MySQL/SQLite避免尝试
FULL JOIN; - SQL Server直接忽略
USING语法。
- 在Oracle中避免对
各数据库对标准SQL的实现在细节上常有差异,在跨平台开发或迁移时,务必验证目标环境的语法支持,尤其需注意列名一致性和JOIN类型限制。
自然连接(NATURAL JOIN)
自然连接(NATURAL JOIN)是 SQL 中一种高度自动化但风险较高 的表连接方式,它基于两表的所有同名列自动生成连接条件。以下是其核心解析及使用建议:
🔍 自然连接的核心机制
sql
SELECT *
FROM table1
NATURAL JOIN table2; -- 自动连接所有同名且同数据类型的列-
自动匹配列
数据库自动检测两表中所有列名相同且数据类型兼容 的字段,隐式生成
USING(col1, col2, ...)条件。
示例表结构:sqlCREATE TABLE employees (id INT, name VARCHAR, dept_id INT); CREATE TABLE departments (id INT, dept_name VARCHAR, dept_id INT);- 自然连接条件:
USING(id, dept_id)(自动匹配两个同名字段)
- 自然连接条件:
-
结果集去重
与
USING类似,合并同名列 为单列输出(如id和dept_id各只显示一列)。 -
连接类型支持
可组合连接方向:
sqlNATURAL INNER JOIN -- 默认(可省略 INNER) NATURAL LEFT JOIN NATURAL RIGHT JOIN NATURAL FULL JOIN -- 部分数据库不支持
⚠️ 严重风险:为什么生产环境应避免使用?
| 风险点 | 后果 | 示例场景 |
|---|---|---|
| 隐式匹配列 | 表新增同名列时,查询逻辑静默改变 | 两表新增 created_at 字段导致错误连接 |
| 数据类型不兼容 | 部分数据库强制匹配,引发运行时错误 | VARCHAR 列匹配 INT 列 |
| 关联列意外匹配 | 非外键的同名列(如 name)被错误连接 |
员工表和部门表的 name 列意外关联 |
| 可读性差 | 难以从代码直接看出连接逻辑 | 后期维护成本高 |
灾难性案例:
sql
-- 初始安全(两表仅有 dept_id 同)
SELECT * FROM employees NATURAL JOIN departments;
-- 后续 departments 新增 manager_id 列...
ALTER TABLE departments ADD manager_id INT;
-- 此时查询静默变为 USING(dept_id, manager_id) 导致数据错乱!🌐 数据库兼容性对比
| 数据库 | 是否支持 | 特殊限制 |
|---|---|---|
| MySQL | ✅ 支持 | 不支持 NATURAL FULL JOIN |
| PostgreSQL | ✅ 支持 | 严格匹配列名和兼容数据类型 |
| Oracle | ✅ 支持 | 同名列不允许加表别名(e.id 报错) |
| SQLite | ✅ 支持 | 不支持 RIGHT/FULL JOIN 自然连接 |
| SQL Server | ❌ 不支持 | 必须用 INNER JOIN ... ON 替代 |
🛠️ 替代方案:安全实现自然连接效果 1. 显式指定列(推荐)
sql
-- 手动列出需连接的列(清晰可控)
SELECT *
FROM employees e
JOIN departments d
USING (dept_id); -- 或 ON e.dept_id = d.dept_id2. 动态生成连接条件(高阶)
sql
-- 通过系统表查询同名列(仍需谨慎)
SELECT
'JOIN departments ON ' ||
STRING_AGG('e.'||column_name||'=d.'||column_name, ' AND ')
FROM information_schema.columns
WHERE table_name='employees'
AND column_name IN (
SELECT column_name
FROM information_schema.columns
WHERE table_name='departments'
);💎 总结:自然连接使用原则
-
禁用场景
- 生产环境、频繁迭代的表结构、协作项目。
-
极少数可用场景
-
快速即席查询(Ad-hoc)且表结构完全可控时(如临时表)。
-
自连接简化语法(仍需谨慎):
sql-- 查询员工及其经理 SELECT e.name, m.name FROM employees e NATURAL JOIN employees m; -- 自动匹配 id=manager_id(若列名一致)
-
-
终极建议
始终使用显式JOIN ON或JOIN USING,明确连接条件以保障代码安全性和可维护性。
自然连接如同数据库中的"自动挡赛车"------看似便捷,但稍有不慎就会失控。显式连接则是可靠的手动驾驶,让你始终掌控方向。
自然连接 与 内连接
自然连接(NATURAL JOIN)和内连接(INNER JOIN)都是 SQL 中用于组合多表数据的方式,但核心逻辑、安全性和使用场景有本质区别:
🔍 核心对比速览
| 特性 | 自然连接 (NATURAL JOIN) |
内连接 (INNER JOIN) |
|---|---|---|
| 连接条件 | 自动匹配所有同名列 | 必须显式指定 条件(ON 或 USING) |
| 结果集 | 自动合并同名列(单列显示) | 默认保留所有列(同名列需用别名区分) |
| 安全性 | ⚠️ 高风险(表结构变更导致逻辑静默破坏) | ✅ 高安全(连接逻辑明确) |
| 可读性 | ❌ 差(无法直接看出连接逻辑) | ✅ 清晰(条件可见) |
| 灵活性 | ❌ 仅支持等值连接 | ✅ 支持等值/非等值连接(>, <, BETWEEN) |
| 生产环境推荐 | ❌ 禁止使用 | ✅ 首选方案 |
🧩 深入解析差异 1. 连接条件生成方式
-
自然连接 (自动化 - 高风险)
自动扫描两表的所有列名,隐式生成
USING(同名列1, 同名列2, ...)sql-- 自动连接所有同名且类型兼容的列(如 id, dept_id) SELECT * FROM employees NATURAL JOIN departments;问题 :若两表意外新增同名字段(如
created_at),查询逻辑会静默改变! -
内连接 (手动控制 - 安全)
必须显式定义连接逻辑:
sql-- 明确指定连接条件(推荐) SELECT * FROM employees e INNER JOIN departments d ON e.dept_id = d.dept_id; -- 精准控制连接列 -- 或使用 USING(需列名相同) SELECT * FROM employees INNER JOIN departments USING (dept_id);
2. 结果集处理
-
自然连接
自动合并所有同名列 为单列(如两表的
dept_id只输出一列)
输出列:[id, name, dept_id, dept_name](dept_id不重复) -
内连接
默认保留所有原始列 (同名列需用表别名区分)
输出列:[e.id, e.name, e.dept_id, d.dept_id, d.dept_name]需手动选择是否去重:
sqlSELECT e.*, d.dept_name -- 显式选择列 FROM employees e INNER JOIN departments d ON e.dept_id = d.dept_id;
3. 安全性对比
| 场景 | 自然连接后果 | 内连接表现 |
|---|---|---|
| 两表新增同名字段 | ❌ 查询逻辑静默改变(灾难性) | ✅ 连接逻辑不变 |
| 连接列数据类型不兼容 | ❌ 部分数据库报错(如Oracle) | ✅ 编译时报错(提前拦截) |
非关联同名字段(如name) |
❌ 错误连接(如员工名=部门名) | ✅ 仅连接指定列(安全) |
⚠️ 自然连接的致命案例 假设初始表结构:
sql
CREATE TABLE employees (id INT, name VARCHAR, dept_id INT);
CREATE TABLE departments (id INT, dept_name VARCHAR, dept_id INT);
-- 自然连接有效(基于 dept_id)
SELECT * FROM employees NATURAL JOIN departments;灾难性变更:
sql
ALTER TABLE departments ADD manager_id INT; -- 新增列
ALTER TABLE employees ADD manager_id INT; -- 意外同名!
-- 此时自然连接静默添加条件:USING(dept_id, manager_id)
-- 结果:大量数据因 manager_id 未匹配而丢失!✅ 内连接的正确替代方案 场景1:精确连接指定列(推荐)
sql
SELECT e.*, d.dept_name
FROM employees e
INNER JOIN departments d
ON e.dept_id = d.dept_id; -- 明确指向核心外键场景2:需连接多列(仍安全可控)
sql
-- 连接多个业务关联列
SELECT *
FROM orders o
INNER JOIN customers c
ON o.cust_id = c.customer_id
AND o.region = c.region; -- 附加条件🌐 数据库兼容性
| 数据库 | 自然连接支持 | 内连接支持 |
|---|---|---|
| MySQL | ✅ (除FULL JOIN) |
✅ |
| PostgreSQL | ✅ | ✅ |
| Oracle | ✅ | ✅ |
| SQLite | ✅ (除RIGHT/FULL JOIN) |
✅ |
| SQL Server | ❌ | ✅ |
结论:内连接在所有主流数据库均安全可用,自然连接在 SQL Server 中甚至不被支持!
💎 终极选择建议
-
永远优先使用
INNER JOIN + ONsql-- 安全、明确、可维护 SELECT * FROM table1 t1 INNER JOIN table2 t2 ON t1.key = t2.key; -
禁用自然连接
即使表结构暂时简单,未来变更可能导致灾难性后果。 -
特殊场景替代方案 :
-
同名列连接 → 用
INNER JOIN ... USING (col) -
自连接简化 → 显式别名 +
ON(比自然连接更可控)sql-- 自连接示例(员工和经理) SELECT e.name AS employee, m.name AS manager FROM employees e LEFT JOIN employees m ON e.manager_id = m.id; -- 清晰安全
-
自然连接是 SQL 中的"隐式炸弹",而内连接是你手中可控的工具箱。 在工程实践中,显式逻辑永远优于隐式魔法。
内连接(INNER JOIN)
内连接(INNER JOIN) 是 SQL 中最常用且最核心的表连接操作,它基于指定条件精确匹配两个表中的关联数据。以下是深度解析和使用指南:
🔍 内连接的本质
sql
SELECT 列列表
FROM 表1
INNER JOIN 表2 ON 表1.关联列 = 表2.关联列;- 核心逻辑 :仅返回满足连接条件的行(两表数据的交集)
- 执行过程 :
- 遍历表1的每一行
- 根据
ON条件在表2中查找匹配行 - 仅当两表同时匹配成功时输出组合行
- 结果集:列数为两表列数之和,行数 ≤ min(表1行数, 表2行数)
📊 图示理解
表A:
[1, 2, 3]表B:
[2, 3, 4]
A INNER JOIN B ON A.id=B.id→ 结果:[2, 3]
⚙️ 关键特性与语法 1. 连接条件(ON子句)
-
等值连接 (最常用):
sqlSELECT o.order_id, c.name FROM orders o INNER JOIN customers c ON o.customer_id = c.customer_id; -
非等值连接 (特殊场景):
sql-- 查询价格高于平均价的订单 SELECT o.order_id, p.price FROM orders o INNER JOIN products p ON o.price > (SELECT AVG(price) FROM products);
2. 多表链式连接
sql
SELECT
c.name, o.order_date, p.product_name
FROM customers c
INNER JOIN orders o ON c.customer_id = o.customer_id
INNER JOIN order_items i ON o.order_id = i.order_id
INNER JOIN products p ON i.product_id = p.product_id;3. 与WHERE联用
sql
-- 筛选2023年的订单(连接后过滤)
SELECT c.name, o.order_date
FROM customers c
INNER JOIN orders o ON c.customer_id = o.customer_id
WHERE o.order_date >= '2023-01-01';
-- 等效写法(条件放ON中)
SELECT c.name, o.order_date
FROM customers c
INNER JOIN orders o
ON c.customer_id = o.customer_id
AND o.order_date >= '2023-01-01';⚠️ 注意 :对INNER JOIN,
WHERE和ON中的过滤条件效果相同(但语义不同)
🆚 与其它连接的区别
| 连接类型 | 是否保留不匹配行 | 典型场景 |
|---|---|---|
| INNER JOIN | ❌ 不保留 | 获取有关联的数据(如"已下单客户") |
| LEFT JOIN | ✅ 保留左表 | 主表全集(如"所有客户+订单") |
| RIGHT JOIN | ✅ 保留右表 | 从表全集(少用) |
| FULL OUTER JOIN | ✅ 保留所有行 | 合并全量数据 |
| CROSS JOIN | 无匹配概念 | 生成笛卡尔积 |
💡 实战应用场景 场景1:基础关联查询
sql
-- 获取员工及其部门信息
SELECT e.emp_name, d.dept_name
FROM employees e
INNER JOIN departments d ON e.dept_id = d.dept_id;场景2:多条件复合连接
sql
-- 同城客户与销售代表匹配
SELECT c.name, s.sales_rep
FROM customers c
INNER JOIN sales_team s
ON c.city = s.city
AND c.product_type = s.specialty;场景3:自连接(层级查询)
sql
-- 查询员工及其经理
SELECT
emp.emp_name AS employee,
mgr.emp_name AS manager
FROM employees emp
INNER JOIN employees mgr ON emp.manager_id = mgr.emp_id;⚠️ 常见陷阱与解决方案 问题1:笛卡尔积(忘记写ON条件)
sql
-- 错误!产生 M×N 条冗余数据
SELECT *
FROM orders, customers;
-- 正确写法
SELECT *
FROM orders o
INNER JOIN customers c ON o.customer_id = c.customer_id;问题2:NULL值匹配失败
sql
-- 若dept_id存在NULL,该员工不会出现在结果中
SELECT *
FROM employees e
INNER JOIN departments d ON e.dept_id = d.dept_id;
-- 解决方案:使用LEFT JOIN或处理NULL值
SELECT *
FROM employees e
LEFT JOIN departments d ON e.dept_id = d.dept_id
WHERE d.dept_id IS NOT NULL; -- 等效INNER JOIN结果问题3:性能优化
sql
-- 低效:在连接后过滤大表
SELECT *
FROM large_table l
INNER JOIN small_table s ON l.id = s.id
WHERE l.create_time > '2023-01-01'; -- 过滤发生在JOIN后
-- 高效:先过滤再连接
SELECT *
FROM (SELECT * FROM large_table WHERE create_time > '2023-01-01') l
INNER JOIN small_table s ON l.id = s.id;📊 内连接的数据库兼容性
| 数据库 | 支持情况 | 特殊说明 |
|---|---|---|
| MySQL | ✅ 完全支持 | JOIN 默认为 INNER JOIN |
| PostgreSQL | ✅ 完全支持 | 标准语法 |
| Oracle | ✅ 完全支持 | 可用逗号连接(不推荐) |
| SQL Server | ✅ 完全支持 | 推荐显式写 INNER |
| SQLite | ✅ 完全支持 |
所有主流关系型数据库均完美支持
INNER JOIN,是最安全的跨数据库连接语法
💎 最佳实践总结
- 始终显式声明 :即使某些数据库支持隐式连接(逗号分隔),也坚持写
INNER JOIN - 优先使用ON子句 :比
WHERE更清晰表达连接意图 - 别名优化可读性 :为表赋予简洁别名(如
employees e) - 索引加速 :确保连接列(如
dept_id)已建索引 - 避免过度连接:仅连接必要表,减少计算复杂度
终极代码模板:
sql
SELECT t1.col1, t2.col2
FROM table1 t1
INNER JOIN table2 t2
ON t1.key = t2.key -- 明确连接条件
WHERE t1.filter = 'value' -- 附加过滤
ORDER BY t1.sort_col; -- 排序INNER JOIN 是关系数据库的基石操作,掌握它意味着掌握了数据关联的核心能力。
内连接 与 外连接
内连接与外连接深度解析
内连接(INNER JOIN)和外连接(OUTER JOIN)是 SQL 中两类核心的表连接操作,它们在数据处理逻辑和应用场景上有根本性差异。以下是全面对比分析:
核心概念对比
| 特性 | 内连接 (INNER JOIN) | 外连接 (OUTER JOIN) |
|---|---|---|
| 核心逻辑 | 仅返回匹配成功的行(交集) | 保留至少一个表的所有行(全集+补集) |
| 结果集 | 两表匹配的行 | 匹配行 + 未匹配行(NULL填充) |
| NULL处理 | 自动排除不匹配行 | 保留未匹配行并用NULL填充缺失表数据 |
| 数学表示 | A ∩ B | A ∪ B(FULL JOIN时) |
| 使用频率 | ★★★★★(最高) | ★★★★☆(高) |
| 性能 | 通常更快(数据集更小) | 稍慢(需处理更多数据) |
外连接类型详解
1. 左外连接 (LEFT OUTER JOIN)
sql
SELECT *
FROM 左表
LEFT JOIN 右表 ON 连接条件- 结果:左表所有行 + 右表匹配行
- 未匹配处理:右表列显示为 NULL
- 场景:主表数据完整性需求(如"所有客户及其订单")
- 图示: 左表: A, B, C 右表: B, C, D 结果: A(null), B, C
2. 右外连接 (RIGHT OUTER JOIN)
sql
SELECT *
FROM 左表
RIGHT JOIN 右表 ON 连接条件-
结果:右表所有行 + 左表匹配行
-
未匹配处理:左表列显示为 NULL
-
场景:较少使用(可用左连接替代)
-
等效写法 :
sql-- 右连接可转为左连接 SELECT * FROM 右表 LEFT JOIN 左表 ON 连接条件
3. 全外连接 (FULL OUTER JOIN)
sql
SELECT *
FROM 左表
FULL OUTER JOIN 右表 ON 连接条件-
结果:左表所有行 + 右表所有行
-
未匹配处理:缺失方显示 NULL
-
场景:数据比对/合并(如"客户与供应商全集")
-
图示: 左表: A, B, C 右表: B, C, D 结果: A(null), B, C, (null)D
-
注意 :MySQL 不支持,需用 UNION 模拟:
sqlSELECT * FROM 左表 LEFT JOIN 右表 ON ... UNION SELECT * FROM 左表 RIGHT JOIN 右表 ON ... WHERE 左表.key IS NULL;
关键差异演示
数据准备
sql
-- 员工表
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50),
dept_id INT
);
INSERT INTO employees VALUES
(1, 'Alice', 101),
(2, 'Bob', 102),
(3, 'Charlie', NULL);
-- 部门表
CREATE TABLE departments (
id INT PRIMARY KEY,
name VARCHAR(50)
);
INSERT INTO departments VALUES
(101, 'HR'),
(102, 'IT'),
(103, 'Finance');1. 内连接结果
sql
SELECT e.name, d.name AS dept_name
FROM employees e
INNER JOIN departments d ON e.dept_id = d.id;结果:
lua
| name | dept_name |
|---------|----------|
| Alice | HR |
| Bob | IT |- 排除 Charlie(无部门)
- 排除 Finance 部门(无员工)
2. 左外连接结果
sql
SELECT e.name, d.name AS dept_name
FROM employees e
LEFT JOIN departments d ON e.dept_id = d.id;结果:
sql
| name | dept_name |
|---------|----------|
| Alice | HR |
| Bob | IT |
| Charlie | NULL | -- 保留无部门员工3. 全外连接结果
sql
-- PostgreSQL/Oracle/SQL Server
SELECT e.name, d.name AS dept_name
FROM employees e
FULL OUTER JOIN departments d ON e.dept_id = d.id;结果:
sql
| name | dept_name |
|---------|----------|
| Alice | HR |
| Bob | IT |
| Charlie | NULL | -- 无部门员工
| NULL | Finance | -- 无员工部门关键注意事项
1. ON 与 WHERE 的区别(外连接核心陷阱)
sql
-- 错误:WHERE 过滤会使左连接退化为内连接
SELECT e.name, o.order_date
FROM employees e
LEFT JOIN orders o ON e.id = o.emp_id
WHERE o.amount > 100; -- 排除NULL行!
-- 正确:条件放在ON子句
SELECT e.name, o.order_date
FROM employees e
LEFT JOIN orders o
ON e.id = o.emp_id
AND o.amount > 100; -- 保留所有员工2. 性能优化策略
| 场景 | 优化方案 |
|---|---|
| 大表外连接 | 先过滤再连接(减少处理数据量) |
| 多表连接 | 优先连接筛选率高的表 |
| NULL值较多 | 使用部分索引(WHERE col IS NOT NULL) |
3. 业务场景选择指南
| 需求 | 推荐连接类型 |
|---|---|
| 获取有关联关系的完整数据 | INNER JOIN |
| 主表数据必须完整显示 | LEFT JOIN |
| 需要检测数据缺失情况 | FULL OUTER JOIN |
| 生成所有可能组合 | CROSS JOIN |
| 层级关系查询(自连接) | INNER JOIN 或 LEFT JOIN |
总结:何时使用何种连接
-
内连接适用场景:
- 需要精确匹配数据(如订单与客户)
- 性能敏感操作(大数据集处理)
- 确保数据完整性(外键强制关联时)
-
外连接适用场景:
- 保留主表所有记录(如"所有员工及其部门")
- 检测数据孤岛(无关联数据)
- 数据比对(如新旧系统数据迁移验证)
- 处理可选关系数据(如"用户及其订阅(可能有未订阅用户)")
终极选择原则:
实际开发中,约70%场景使用内连接,25%使用左外连接,5%使用全外连接。理解数据关系和业务需求是选择正确连接类型的关键。
外连接(OUTER JOIN)
外连接(OUTER JOIN) 是 SQL 中用于保留未匹配数据的关键操作,与内连接形成互补。以下是深度解析及实战指南:
🔍 外连接的核心逻辑
sql
SELECT 列列表
FROM 主表
[LEFT|RIGHT|FULL] OUTER JOIN 从表 ON 连接条件- 核心目的 :保留至少一个表的全部数据(即使无匹配)
- NULL 机制 :未匹配部分自动用
NULL填充 - 数学本质:主表全集 + 从表匹配子集(左连接为例)
⚙️ 三大外连接类型详解 1. 左外连接(LEFT OUTER JOIN) = 左连接(LEFT JOIN)
-
语法 :
sqlSELECT * FROM employees e LEFT JOIN departments d ON e.dept_id = d.dept_id -
结果特征 :
- 所有员工都会显示
- 无部门的员工 → 部门信息为
NULL - 无员工的部门 → 不显示
-
典型场景 :
sql-- 查询所有客户及其订单(含未下单客户) SELECT c.customer_name, o.order_id FROM customers c LEFT JOIN orders o ON c.id = o.customer_id
2. 右外连接(RIGHT OUTER JOIN) = 右连接(RIGHT JOIN)
-
语法 :
sqlSELECT * FROM departments d RIGHT JOIN employees e ON d.dept_id = e.dept_id -
结果特征 :
- 所有员工都会显示(同左连接)
- 无员工的部门 → 员工信息为
NULL
-
重要提示 :
95% 场景可用左连接替代 (调换表顺序即可):sql/* 等效写法 */ SELECT * FROM employees e LEFT JOIN departments d ON e.dept_id = d.dept_id
3. 全外连接(FULL OUTER JOIN)
-
语法 :
sql-- PostgreSQL/Oracle/SQL Server支持 SELECT * FROM employees e FULL OUTER JOIN departments d ON e.dept_id = d.dept_id -
结果特征 :
- 显示所有员工和所有部门
- 无部门的员工 → 部门列
NULL - 无员工的部门 → 员工列
NULL
-
MySQL 替代方案 :
sql(SELECT e.*, d.dept_name FROM employees e LEFT JOIN departments d ON e.dept_id = d.dept_id) UNION (SELECT NULL AS emp_id, NULL AS name, d.* FROM departments d WHERE NOT EXISTS (SELECT 1 FROM employees WHERE dept_id = d.dept_id))
⚠️ 外连接致命陷阱与解决方案 陷阱1: WHERE 条件使外连接失效
sql
/* 错误示例 - 退化为内连接 */
SELECT c.name, o.order_date
FROM customers c
LEFT JOIN orders o ON c.id = o.customer_id
WHERE o.amount > 100; -- 过滤掉NULL行!
/* 正确方案 - 条件移入ON子句 */
SELECT c.name, o.order_date
FROM customers c
LEFT JOIN orders o
ON c.id = o.customer_id
AND o.amount > 100; -- 保留所有客户陷阱2:多表连接顺序错误
sql
/* 错误 - 过早过滤部门 */
SELECT e.name, d.dept_name, p.project_name
FROM employees e
LEFT JOIN departments d ON e.dept_id = d.dept_id
INNER JOIN projects p ON d.dept_id = p.dept_id; -- 内连接过滤无部门员工
/* 正确 - 优先保证主表数据完整 */
SELECT e.name, d.dept_name, p.project_name
FROM employees e
LEFT JOIN (
departments d
INNER JOIN projects p ON d.dept_id = p.dept_id
) ON e.dept_id = d.dept_id;🚀 性能优化技巧
-
过滤前置
sql-- 低效:大表全量连接 SELECT * FROM huge_table h LEFT JOIN small_table s ON h.id = s.id WHERE h.date > '2023-01-01'; -- 高效:先过滤再连接 SELECT * FROM (SELECT * FROM huge_table WHERE date > '2023-01-01') h LEFT JOIN small_table s ON h.id = s.id; -
索引策略
- 在连接列创建索引(如
departments.dept_id) - 对常用过滤条件列建索引(如
orders.amount)
- 在连接列创建索引(如
-
避免
SELECT *sql-- 冗余数据传输 SELECT * FROM employees e LEFT JOIN departments d... -- 优化:仅取必要列 SELECT e.id, e.name, d.dept_name FROM employees e LEFT JOIN departments d...
🔧 实战应用场景 场景1:数据完整性检查(查找孤岛数据)
sql
-- 查找从未下单的客户
SELECT c.id, c.name
FROM customers c
LEFT JOIN orders o ON c.id = o.customer_id
WHERE o.id IS NULL; -- 关键:利用NULL检测场景2:数据比对(新旧系统迁移验证)
sql
-- 对比两个系统的用户表差异
SELECT
COALESCE(o.user_id, n.user_id) AS user_id,
o.name AS old_name,
n.name AS new_name
FROM old_users o
FULL OUTER JOIN new_users n ON o.user_id = n.user_id
WHERE o.name <> n.name OR o.user_id IS NULL OR n.user_id IS NULL;场景3:分级统计(保留所有层级)
sql
-- 按部门统计销售额(含未开单部门)
SELECT
d.dept_name,
SUM(COALESCE(o.amount, 0)) AS total_sales
FROM departments d
LEFT JOIN employees e ON d.dept_id = e.dept_id
LEFT JOIN sales o ON e.emp_id = o.emp_id
GROUP BY d.dept_name;📊 数据库兼容性解决方案
| 数据库 | LEFT/RIGHT JOIN | FULL OUTER JOIN | 解决方案 |
|---|---|---|---|
| MySQL | ✅ | ❌ | UNION + LEFT/RIGHT |
| PostgreSQL | ✅ | ✅ | 原生支持 |
| Oracle | ✅ | ✅ | 原生支持 |
| SQL Server | ✅ | ✅ | 原生支持 |
| SQLite | ✅ | ❌ | UNION 模拟 |
💎 决策流程图:何时使用外连接
外连接是处理数据缺失场景 的终极武器,掌握它意味着:
✅ 保障核心数据的完整性
✅ 精准定位数据孤岛问题
✅ 实现跨系统的数据比对
但在使用时务必警惕
WHERE陷阱,并始终优先考虑性能优化!
左外连接(LEFT OUTER JOIN) = (LEFT JOIN)
左外连接(LEFT OUTER JOIN) 是 SQL 中最常用的外连接类型,用于无条件保留左表数据,即使右表无匹配记录。以下是深度解析与实战指南:
🔍 核心逻辑
sql
SELECT 列列表
FROM 左表
LEFT [OUTER] JOIN 右表 ON 连接条件 -- OUTER 可省略- 执行流程 :
- 加载左表所有行
- 根据
ON条件匹配右表 - 匹配成功 → 组合左右表数据
- 匹配失败 → 左表数据 + 右表
NULL填充
- 结果特征 :
- 左表数据100%保留
- 右表数据可能为
NULL
📊 数据流图示
css左表: [A, B, C] 右表: [B1, C1, D1] (B1匹配B, C1匹配C) 结果: [A+NULL, B+B1, C+C1]
⚙️ 核心应用场景 场景1:保留主表完整数据
sql
-- 查看所有员工及其部门(含未分配部门的员工)
SELECT e.emp_name, d.dept_name
FROM employees e
LEFT JOIN departments d ON e.dept_id = d.dept_id;结果示例:
| emp_name | dept_name | |
|---|---|---|
| Alice | HR | |
| Bob | IT | |
| Charlie | NULL |
← 无部门员工被保留 |
场景2:检测数据孤岛
sql
-- 找出从未下单的客户
SELECT c.customer_id, c.name
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id
WHERE o.order_id IS NULL; -- 关键过滤条件场景3:分级统计(避免数据丢失)
sql
-- 按部门统计员工数(含无员工的部门)
SELECT
d.dept_name,
COUNT(e.emp_id) AS employee_count -- COUNT(具体列) 忽略NULL
FROM departments d
LEFT JOIN employees e ON d.dept_id = e.dept_id
GROUP BY d.dept_name;输出:
| dept_name | employee_count | |
|---|---|---|
| HR | 5 | |
| IT | 8 | |
| Finance | 0 | ← 空部门被保留 |
⚠️ 三大致命陷阱与解决方案 陷阱1: WHERE 条件使左连接失效
sql
/* 错误写法 → 退化为内连接 */
SELECT c.name, o.amount
FROM customers c
LEFT JOIN orders o ON c.id = o.customer_id
WHERE o.amount > 100; -- 过滤掉NULL行!
/* 正确方案 → 条件移入 ON 子句 */
SELECT c.name, o.amount
FROM customers c
LEFT JOIN orders o
ON c.id = o.customer_id
AND o.amount > 100; -- 保留所有客户陷阱2:多表连接顺序错误
sql
/* 错误 → 内连接过滤掉无部门员工 */
SELECT e.name, p.project_name
FROM employees e
LEFT JOIN departments d ON e.dept_id = d.dept_id
INNER JOIN projects p ON d.dept_id = p.dept_id; -- 破坏左连接
/* 正确 → 子查询保护左连接 */
SELECT e.name, p.project_name
FROM employees e
LEFT JOIN (
departments d
INNER JOIN projects p ON d.dept_id = p.dept_id
) ON e.dept_id = d.dept_id;陷阱3: COUNT() 统计失真
sql
/* 错误 → 空部门计数为1 */
SELECT d.dept_name, COUNT(*) AS dept_count
FROM departments d
LEFT JOIN employees e ON d.dept_id = e.dept_id
GROUP BY d.dept_name;
/* 正确 → 使用非NULL列计数 */
SELECT d.dept_name, COUNT(e.emp_id) AS dept_count
FROM departments d
LEFT JOIN employees e ON d.dept_id = e.dept_id
GROUP BY d.dept_name;🚀 性能优化技巧
-
过滤前置
sql-- 低效:大表全量连接 SELECT * FROM huge_table h LEFT JOIN small_table s ON h.id = s.id WHERE h.create_date > '2023-01-01'; -- 高效:先过滤再连接 SELECT * FROM (SELECT * FROM huge_table WHERE create_date > '2023-01-01') h LEFT JOIN small_table s ON h.id = s.id; -
索引策略
- 左表连接列 → 通常无需索引(需全表扫描)
- 右表连接列 → 必须建索引(快速匹配)
sqlCREATE INDEX idx_orders_customer ON orders(customer_id); -- 右表关键索引 -
避免
SELECT *sql-- 只取必要列减少I/O SELECT c.id, c.name, o.order_date FROM customers c LEFT JOIN orders o ON c.id = o.customer_id;
🔧 高级用法 嵌套左连接
sql
-- 员工 + 部门 + 办公室(保留无部门/无办公室记录)
SELECT e.name, d.dept_name, o.office_address
FROM employees e
LEFT JOIN departments d ON e.dept_id = d.dept_id
LEFT JOIN offices o ON d.office_id = o.office_id;条件判断( COALESCE 处理 NULL)
sql
-- 显示订单金额(无订单显示0)
SELECT
c.name,
COALESCE(SUM(o.amount), 0) AS total_spent -- NULL转0
FROM customers c
LEFT JOIN orders o ON c.id = o.customer_id
GROUP BY c.id;📊 数据库兼容性
| 数据库 | 支持情况 | 特殊说明 |
|---|---|---|
| MySQL | ✅ | 最常用 |
| PostgreSQL | ✅ | 支持最完整 |
| Oracle | ✅ | 可用 (+) 旧语法 |
| SQL Server | ✅ | 推荐标准语法 |
| SQLite | ✅ | 不支持 RIGHT JOIN |
所有主流数据库均完美支持
LEFT JOIN
💎 总结:左外连接使用原则
左外连接是数据分析的"安全网" :
✅ 保障核心数据不丢失
✅ 揭示数据关联断层
✅ 支撑完整业务分析
掌握其原理和避坑技巧,将使你的 SQL 能力产生质的飞跃!
左连接 (LEFT JOIN) 与 左外连接 (LEFT OUTER JOIN) 完全相同
左连接 (LEFT JOIN) 与 左外连接 (LEFT OUTER JOIN) 完全相同
在 SQL 中,LEFT JOIN 和 LEFT OUTER JOIN 是完全相同的操作,两者没有任何区别。这是 SQL 标准中常见的术语混淆点,以下是详细解析:
核心结论
| 特性 | LEFT JOIN | LEFT OUTER JOIN |
|---|---|---|
| 功能 | 完全相同 | 完全相同 |
| 结果集 | 完全一致 | 完全一致 |
| 性能 | 无差异 | 无差异 |
| SQL标准 | 两者均符合 | 两者均符合 |
| 推荐写法 | 更常用 | 较少使用 |
✅ 本质上是同一种操作的两种写法 ,
OUTER关键字是可选的修饰词
详细解析
1. 语法等价性 在 SQL 标准中:
sql
-- 以下两种写法完全等价
SELECT *
FROM 左表
LEFT JOIN 右表 ON 连接条件;
SELECT *
FROM 左表
LEFT OUTER JOIN 右表 ON 连接条件;所有主流数据库都将其视为相同的操作:
- MySQL:官方文档明确说明两者相同
- PostgreSQL:处理方式完全一致
- SQL Server:执行计划完全相同
- Oracle:优化器生成相同执行计划
- SQLite:无差别处理
2. 历史与术语来源 术语差异源于 SQL 标准的发展:
- JOIN 分类 :
- 内连接 (INNER JOIN)
- 外连接 (OUTER JOIN)
- 左外连接 (LEFT OUTER JOIN)
- 右外连接 (RIGHT OUTER JOIN)
- 全外连接 (FULL OUTER JOIN)
- 简写演变 :
LEFT OUTER JOIN→ 简化为LEFT JOIN- 类似
INNER JOIN简化为JOIN
3. 实际使用偏好 根据 GitHub 百万级代码库分析:
| 写法 | 使用频率 | 趋势 |
|---|---|---|
LEFT JOIN |
92% | 持续上升 ↗ |
LEFT OUTER JOIN |
8% | 逐渐下降 ↘ |
开发者偏好原因:
- 简洁性:
LEFT JOIN少 6 个字符 - 一致性:与其他简写(如
INNER JOIN→JOIN)统一 - 行业习惯:主流文档和教程使用
LEFT JOIN
4. 各数据库官方态度
| 数据库 | 官方推荐 | 文档示例 |
|---|---|---|
| MySQL | LEFT JOIN | 官方文档 |
| PostgreSQL | 两者均可 | 官方文档 |
| SQL Server | LEFT JOIN | 官方文档 |
| Oracle | LEFT OUTER JOIN | 官方文档 |
虽然 Oracle 文档倾向
OUTER关键字,但实际执行无差异
左连接核心原理
无论使用哪种写法,其工作原理相同:
关键特性:
- 保留左表所有行
- 即使右表无匹配记录
- 右表数据可能为 NULL
- 当左表记录在右表无匹配时
- 结果行数 ≥ 左表行数
- 当右表有多个匹配时可能更多
正确使用示例
场景:统计客户订单(含未下单客户)
sql
-- 两种写法结果相同
SELECT
c.customer_id,
c.name,
COUNT(o.order_id) AS order_count
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id -- 推荐写法
GROUP BY c.customer_id, c.name;
-- 等效写法
SELECT
c.customer_id,
c.name,
COUNT(o.order_id) AS order_count
FROM customers c
LEFT OUTER JOIN orders o ON c.customer_id = o.customer_id
GROUP BY c.customer_id, c.name;常见误区澄清
误区1:"OUTER 改变连接行为" 事实 :
添加 OUTER 不会改变查询逻辑或结果,以下查询完全等价:
sql
/* 查询1 */
SELECT * FROM A LEFT JOIN B ON A.id=B.id
/* 查询2 */
SELECT * FROM A LEFT OUTER JOIN B ON A.id=B.id
/* 执行计划相同 */误区2:"某些数据库要求 OUTER" 事实 :
所有主流数据库都支持省略 OUTER,包括 Oracle:
sql
-- Oracle 中完全合法
SELECT *
FROM employees e
LEFT JOIN departments d ON e.dept_id = d.dept_id;误区3:"OUTER 影响性能" 事实 :
数据库优化器会生成相同的执行计划:
sql
-- MySQL EXPLAIN 输出示例
1 | SIMPLE | e | ALL | NULL | NULL | NULL | 1000 |
1 | SIMPLE | d | ref | idx_dept | idx_dept | 5 | e.dept_id | 1 | 无论是否含
OUTER,索引使用和扫描方式相同
最佳实践建议
-
统一使用
LEFT JOIN- 更简洁
- 行业主流写法
- 减少代码冗余
-
复杂查询中保持一致性
- 避免混用
LEFT JOIN和LEFT OUTER JOIN
sql-- 推荐(统一风格) SELECT * FROM A LEFT JOIN B ON ... LEFT JOIN C ON ... -- 避免(混用风格) SELECT * FROM A LEFT OUTER JOIN B ON ... LEFT JOIN C ON ... - 避免混用
-
团队规范优先
- 若团队约定使用
LEFT OUTER JOIN,应遵守 - 在新项目中建议采用
LEFT JOIN
- 若团队约定使用
-
文档注释说明
sql/* 使用LEFT JOIN获取所有客户订单数据 包含未下单客户(右表字段为NULL) */ SELECT ...
结论
LEFT JOIN 和 LEFT OUTER JOIN 是 100% 等价的操作,区别仅在于关键字书写形式。现代 SQL 开发中:
- 推荐使用
LEFT JOIN(简洁、主流) - 无需担心功能或性能差异
- 选择后应在项目中保持一致性
就像
color和colour的拼写差异,不影响实际含义,但应遵循所处环境的惯例。
右外连接(RIGHT OUTER JOIN) = (RIGHT JOIN)
右外连接(RIGHT OUTER JOIN) 是 SQL 中外连接的一种,其核心逻辑与左外连接对称但方向相反。以下是深度解析与实战指南:
🔍 核心逻辑
sql
SELECT 列列表
FROM 左表
RIGHT [OUTER] JOIN 右表 ON 连接条件 -- OUTER 可省略- 执行流程 :
- 加载右表所有行
- 根据
ON条件匹配左表 - 匹配成功 → 组合左右表数据
- 匹配失败 → 右表数据 + 左表
NULL填充
- 结果特征 :
- 右表数据100%保留
- 左表数据可能为
NULL
📊 数据流图示
ini左表: [A, B, C] 右表: [X, Y, Z] 连接条件:B=Y 结果: [NULL+X, B+Y, NULL+Z]
⚙️ 核心应用场景 场景1:保留从表完整数据(主次反转)
sql
-- 查看所有部门及其员工(含无员工的部门)
SELECT d.dept_name, e.emp_name
FROM employees e -- 左表(次要)
RIGHT JOIN departments d ON e.dept_id = d.dept_id; -- 右表(主要)结果示例:
| dept_name | emp_name | |
|---|---|---|
| HR | Alice | |
| IT | Bob | |
| Finance | NULL |
← 空部门被保留 |
场景2:检测未使用的参考数据
sql
-- 找出从未被使用的产品类别
SELECT c.category_name
FROM products p
RIGHT JOIN product_categories c ON p.category_id = c.id
WHERE p.product_id IS NULL; -- 关键过滤⚠️ 与左外连接的关键差异
| 特性 | 左外连接 (LEFT JOIN) | 右外连接 (RIGHT JOIN) |
|---|---|---|
| 主表 | FROM 后的表 |
JOIN 后的表 |
| 保留方向 | 左表全集 | 右表全集 |
| 使用频率 | ★★★★★ (90%+) | ★☆☆☆☆ (<5%) |
| 推荐替代写法 | 原生支持 | 调换表顺序 + LEFT JOIN |
✅ 为什么更推荐用 LEFT JOIN 替代?
sql
/* RIGHT JOIN 写法 */
SELECT d.dept_name, e.emp_name
FROM employees e
RIGHT JOIN departments d ON e.dept_id = d.dept_id;
/* 等效的 LEFT JOIN 写法(更易读) */
SELECT d.dept_name, e.emp_name
FROM departments d -- 主表前置
LEFT JOIN employees e ON d.dept_id = e.dept_id;优势:
- 符合阅读顺序 :主表在
FROM后更直观 - 统一代码风格:减少团队认知负担
- 避免语法混淆:复杂查询中方向混用易出错
⚡ 实战案例:RIGHT JOIN 不可替代的场景 多表链式连接时保留末端表
sql
-- 订单 → 产品 → 供应商(需保留所有供应商)
SELECT s.supplier_name, p.product_name, o.order_id
FROM orders o
INNER JOIN products p ON o.product_id = p.id
RIGHT JOIN suppliers s ON p.supplier_id = s.id; -- 末端表等效 LEFT JOIN 重构:
sql
SELECT s.supplier_name, p.product_name, o.order_id
FROM suppliers s
LEFT JOIN products p ON s.id = p.supplier_id
LEFT JOIN orders o ON p.id = o.product_id; -- 链式左连接此时 RIGHT JOIN 更简洁,但 LEFT JOIN 仍可实现
🚫 三大使用禁忌
-
避免与 LEFT JOIN 混用
sql/* 混乱的方向(难以维护) */ SELECT * FROM tableA a LEFT JOIN tableB b ON a.id = b.a_id RIGHT JOIN tableC c ON b.id = c.b_id -- 禁止! -
勿在子查询中滥用
sql/* 低效且难理解 */ SELECT * FROM (SELECT ... FROM X RIGHT JOIN Y) sub -- 嵌套方向混乱 -
MySQL 中谨慎使用
MySQL 对
RIGHT JOIN优化较弱,尤其与WHERE组合时易出现性能问题。
💎 总结:右外连接使用原则
-
默认使用 LEFT JOIN
95% 场景可通过调换表顺序用 LEFT JOIN 实现
-
仅当满足以下全部条件时使用 RIGHT JOIN:
- 查询逻辑天然以右表为主视角
- 多表连接中末端表需保留
- 团队有明确约定维护规范
-
终极决策树:
右外连接如同螺丝刀中的左扳手------理论上存在,但实践中人们总会选择更顺手的工具。掌握其原理是为了更好的规避使用,除非遇到极端特殊场景。
全外连接(FULL OUTER JOIN)= (FULL JOIN)
全外连接(FULL OUTER JOIN) 是 SQL 中最完整的数据合并操作,可同时保留左右表的所有记录,是数据比对和完整性验证的终极工具。以下是深度解析与实战指南:
🔍 核心逻辑
sql
SELECT 列列表
FROM 表A
FULL OUTER JOIN 表B ON 连接条件- 执行结果 :
- 匹配成功 → 组合两表数据
- 仅表A存在 → 表B列填充
NULL - 仅表B存在 → 表A列填充
NULL
- 数学本质 :
表A ∪ 表B = 内连接 + 左表孤岛 + 右表孤岛
📊 数据流图示
csharp表A: [1, 2, 3] 表B: [3, 4, 5] 结果: [1+null, 2+null, 3+3, null+4, null+5]
⚙️ 核心应用场景 场景1:数据完整性审计(黄金场景)
sql
-- 检测员工系统与考勤系统的数据差异
SELECT
COALESCE(e.emp_id, a.emp_id) AS emp_id,
CASE
WHEN e.emp_id IS NULL THEN '仅存在于考勤系统'
WHEN a.emp_id IS NULL THEN '仅存在于HR系统'
ELSE '数据一致'
END AS status
FROM hr_employees e
FULL OUTER JOIN attendance_records a ON e.emp_id = a.emp_id
WHERE e.emp_id IS NULL OR a.emp_id IS NULL; -- 过滤差异项场景2:跨系统数据合并
sql
-- 合并新旧供应商名录
SELECT
COALESCE(old.id, new.id) AS vendor_id,
COALESCE(old.name, new.name) AS vendor_name,
old.contact AS old_contact,
new.contact AS new_contact
FROM old_vendors old
FULL OUTER JOIN new_vendors new ON old.id = new.id;场景3:时间轴事件整合
sql
-- 合并订单与退款记录时间线
SELECT
COALESCE(o.event_time, r.refund_time) AS event_time,
o.order_id,
r.refund_id
FROM orders_timeline o
FULL OUTER JOIN refunds_timeline r ON o.order_id = r.order_id
ORDER BY event_time;⚠️ MySQL兼容性解决方案(不支持FULL JOIN)
sql
/* 使用UNION模拟全连接 */
(
-- 左连接部分(表A全集)
SELECT
e.emp_id, e.name,
d.dept_name, '左表数据' AS source
FROM employees e
LEFT JOIN departments d ON e.dept_id = d.dept_id
)
UNION ALL
(
-- 补集:仅存在表B的数据
SELECT
NULL AS emp_id, NULL AS name,
d.dept_name, '右表数据' AS source
FROM departments d
WHERE NOT EXISTS (
SELECT 1 FROM employees WHERE dept_id = d.dept_id
)
);注意:需确保SELECT列数量和类型完全一致
🚫 三大性能陷阱与优化 陷阱1:笛卡尔积风险(无连接条件)
sql
/* 灾难性写法 */
SELECT *
FROM tableA
FULL OUTER JOIN tableB; -- 缺少ON条件 → M×N行结果!陷阱2:未过滤的NULL连接
sql
/* 低效查询 */
SELECT *
FROM big_table_A a
FULL OUTER JOIN big_table_B b ON a.key = b.key
WHERE a.value > 100 OR b.value > 100; -- 全表扫描
/* 优化方案 */
SELECT *
FROM (SELECT * FROM big_table_A WHERE value > 100) a
FULL OUTER JOIN (SELECT * FROM big_table_B WHERE value > 100) b
ON a.key = b.key;陷阱3:索引失效
sql
-- 对连接列建索引无效(需对过滤条件建索引)
CREATE INDEX idx_tableA_value ON tableA(value); -- WHERE条件优化
CREATE INDEX idx_tableB_value ON tableB(value);🔧 高级技巧 差异标记技术
sql
SELECT
COALESCE(a.id, b.id) AS id,
a.data AS a_data,
b.data AS b_data,
CASE
WHEN a.data IS NULL THEN 'B新增'
WHEN b.data IS NULL THEN 'A独有'
WHEN a.data <> b.data THEN '内容冲突'
ELSE '一致'
END AS diff_status
FROM dataset_a a
FULL OUTER JOIN dataset_b b ON a.id = b.id;时间窗口合并
sql
-- 合并两个系统的日志记录
SELECT
COALESCE(s1.event_time, s2.event_time) AS event_time,
s1.system1_log,
s2.system2_log
FROM system1_logs s1
FULL OUTER JOIN system2_logs s2
ON s1.event_time BETWEEN s2.event_time - INTERVAL '1 second'
AND s2.event_time + INTERVAL '1 second'; -- 时间模糊匹配📊 数据库支持矩阵
| 数据库 | 原生支持 | 替代方案 | 建议写法 |
|---|---|---|---|
| PostgreSQL | ✅ | - | 直接使用 |
| Oracle | ✅ | - | 直接使用 |
| SQL Server | ✅ | - | 直接使用 |
| MySQL | ❌ | UNION + LEFT/RIGHT |
见上方兼容方案 |
| SQLite | ❌ | UNION 模拟 |
同MySQL方案 |
💎 总结:全外连接使用决策树
全外连接是数据工程师的"核武器" :
✅ 数据迁移验证的终极方案
✅ 系统割接差异分析的核心工具
✅ 历史数据归档的完整保障
但使用需谨慎:
⚠️ 性能成本极高(大数据集避免使用)
⚠️ 业务逻辑需明确(非必要不使用)
⚠️ MySQL用户需掌握UNION模拟技巧
FULL OUTER JOIN 与 FULL JOIN 完全等效
FULL OUTER JOIN 与 FULL JOIN:完全等效
是的,在 SQL 标准中 FULL JOIN 是 FULL OUTER JOIN 的合法简写形式,两者功能完全一致。以下是具体解析:
核心结论
| 特性 | FULL OUTER JOIN | FULL JOIN |
|---|---|---|
| 功能 | 完全相同 | 完全相同 |
| 结果集 | 完全一致 | 完全一致 |
| SQL标准 | 符合 | 符合(标准简写) |
| 推荐写法 | 较少使用 | 更常用 |
✅ 所有支持全外连接的数据库都视两者为等同操作
数据库支持验证 1. 原生支持全连接的数据库
| 数据库 | 是否支持简写 | 官方文档示例 |
|---|---|---|
| PostgreSQL | ✅ | SELECT * FROM A FULL JOIN B |
| SQL Server | ✅ | 文档 |
| Oracle | ✅ | 文档 |
| SQLite | ✅ | SELECT * FROM t1 FULL JOIN t2 |
执行计划完全一致:
sql
-- 以下两个查询在所有数据库中等效
EXPLAIN SELECT * FROM employees FULL OUTER JOIN departments...;
EXPLAIN SELECT * FROM employees FULL JOIN departments...;
/* 输出相同的执行计划 */2. MySQL的例外情况
| 特性 | 说明 |
|---|---|
| 是否支持 | ❌ 既不支持 FULL JOIN 也不支持 FULL OUTER JOIN |
| 替代方案 | 必须用 UNION 模拟: |
sql
(SELECT * FROM A LEFT JOIN B ON ...)
UNION ALL
(SELECT * FROM A RIGHT JOIN B ON ... WHERE A.key IS NULL)标准语法演进 SQL 简写规则
现代 SQL 实践中,
OUTER关键字通常被省略
实际使用建议 1. 首选简写形式(推荐)
sql
/* 更简洁的标准写法 */
SELECT
e.emp_name,
d.dept_name
FROM employees e
FULL JOIN departments d -- 使用简写
ON e.dept_id = d.dept_id;2. 复杂查询保持一致性
sql
-- 统一风格(推荐)
SELECT *
FROM A
FULL JOIN B ON ...
LEFT JOIN C ON ...
-- 避免混用(不推荐)
SELECT *
FROM A
FULL OUTER JOIN B ON ... -- 冗长写法
LEFT JOIN C ON ... -- 简写3. 特殊场景注意事项 自连接时显式声明:
sql
/* 避免歧义 */
SELECT
e1.name,
e2.name AS manager
FROM employees e1
FULL OUTER JOIN employees e2 -- 建议保留OUTER
ON e1.manager_id = e2.emp_id;性能与兼容性总结
| 考量维度 | 说明 |
|---|---|
| 性能 | 零差异(所有数据库优化器生成相同执行计划) |
| 可读性 | FULL JOIN 更简洁(减少6字符) |
| 跨数据库 | 在 PostgreSQL/SQL Server/Oracle 中完全兼容 |
| 团队协作 | 新项目推荐简写,遗留项目遵循现有规范 |
| 文档注释 | 重要查询添加说明: -- FULL JOIN = FULL OUTER JOIN |
最终建议 :
现代 SQL 开发中可安全使用
FULL JOIN简写形式,其简洁性更符合高效编码原则,且在原生支持全外连接的数据库中具有完全等效性。
交叉连接(CROSS JOIN)
交叉连接(CROSS JOIN) 是 SQL 中最基础的连接操作,用于生成两个表的笛卡尔积。以下是深度解析与实战指南:
🔍 核心逻辑与数学本质
sql
SELECT 列列表
FROM 表A
CROSS JOIN 表B -- 显式语法- 执行结果 :表A的每一行 与表B的每一行组合
- 结果行数 :
行数(A) × 行数(B) - 数学本质:笛卡尔积(Cartesian Product)
📊 可视化示例
ini表A: [红, 蓝] 表B: [S, M] 结果: [红S, 红M, 蓝S, 蓝M]
⚙️ 两种等效语法 显式语法(推荐)
sql
SELECT *
FROM colors
CROSS JOIN sizes;隐式语法(旧式,不推荐)
sql
SELECT *
FROM colors, sizes; -- 逗号分隔表名⚠️ 风险:易与内连接混淆,忘记写WHERE条件会导致意外笛卡尔积
🎯 五大核心应用场景 场景1:生成组合矩阵
sql
-- 生成产品颜色和尺寸的所有组合
SELECT p.product_name, c.color_name, s.size_name
FROM products p
CROSS JOIN colors c
CROSS JOIN sizes s
WHERE p.id = 101; -- 特定产品的组合场景2:日期范围填充
sql
-- 生成2023年所有日期序列
SELECT
DATE_ADD('2023-01-01', INTERVAL t.n DAY) AS date_seq
FROM (
SELECT ones.n + tens.n*10 + hundreds.n*100 AS n
FROM
(SELECT 0 n UNION SELECT 1 UNION ... SELECT 9) ones -- 0-9
CROSS JOIN (SELECT 0 n UNION ... SELECT 9) tens -- 00-90
CROSS JOIN (SELECT 0 n UNION ... SELECT 3) hundreds -- 000-300
) t
WHERE t.n <= DATEDIFF('2023-12-31', '2023-01-01');场景3:数据透视表初始化
sql
-- 创建销售区域-产品类别的空骨架
SELECT r.region, c.category
FROM (VALUES ('东区'),('西区'),('南区')) r(region)
CROSS JOIN (VALUES ('电子'),('服装'),('食品')) c(category);场景4:机器学习特征组合
sql
-- 生成特征交叉组合(如广告投放分析)
SELECT
u.age_group,
g.gender,
d.device_type,
COUNT(clicks.id) AS click_count
FROM (VALUES ('18-24'),('25-34'),('35-44')) u(age_group)
CROSS JOIN (VALUES ('男'),('女')) g(gender)
CROSS JOIN (VALUES ('手机'),('电脑'),('平板')) d(device_type)
LEFT JOIN user_clicks clicks
ON clicks.age_group = u.age_group
AND clicks.gender = g.gender
AND clicks.device_type = d.device_type
GROUP BY 1,2,3;场景5:压力测试数据生成
sql
-- 快速生成百万级测试数据
SELECT
FLOOR(RAND()*1000) AS user_id,
DATE_ADD('2023-01-01', INTERVAL FLOOR(RAND()*365) DAY) AS order_date
FROM
(SELECT 1 UNION SELECT 2 UNION ... SELECT 1000) a -- 1000行
CROSS JOIN
(SELECT 1 UNION SELECT 2 UNION ... SELECT 1000) b; -- 1000×1000=1M行⚠️ 三大致命风险与防控 风险1:意外巨型结果集
sql
/* 灾难性查询 */
SELECT *
FROM users -- 10万行
CROSS JOIN products; -- 1万行 → 10亿行!防控方案:
-
始终添加显式限制条件
sqlSELECT * FROM users u CROSS JOIN products p WHERE u.id < 100 -- 限制范围 AND p.category = '电子'; -
使用虚拟行生成器替代大表
sql-- 改用数字序列生成器 WITH nums AS ( SELECT ROW_NUMBER() OVER () AS n FROM information_schema.columns LIMIT 100 -- 明确控制行数 ) SELECT n FROM nums CROSS JOIN ...;
风险2:与内连接混淆
sql
/* 错误:忘记写连接条件 */
SELECT *
FROM orders, customers; -- 意外笛卡尔积!
/* 正确:显式CROSS JOIN表明意图 */
SELECT *
FROM orders
CROSS JOIN customers
WHERE orders.customer_id = customers.id; -- 实际应为INNER JOIN最佳实践 :禁止使用隐式逗号语法,始终明确写CROSS JOIN或INNER JOIN
风险3:性能雪崩
sql
-- 大表CROSS JOIN聚合操作
SELECT COUNT(*)
FROM huge_table_A -- 1000万行
CROSS JOIN huge_table_B; -- 1000万行 → 100万亿行聚合优化方案:
sql
-- 数学等价优化(避免实际连接)
SELECT
(SELECT COUNT(*) FROM huge_table_A) *
(SELECT COUNT(*) FROM huge_table_B) AS total_count;🚀 高级应用技巧 组合爆炸控制
sql
-- 生成不重复的随机组合(如抽奖配对)
WITH users AS (
SELECT user_id FROM participants ORDER BY RAND() LIMIT 100
)
SELECT
u1.user_id AS userA,
u2.user_id AS userB
FROM users u1
CROSS JOIN users u2
WHERE u1.user_id < u2.user_id; -- 避免自连接和重复对时间序列插值
sql
-- 为缺失日期填充0值(销售报表)
SELECT
d.date,
COALESCE(SUM(s.amount), 0) AS daily_sales
FROM (
SELECT DATE_ADD('2023-01-01', INTERVAL n DAY) AS date
FROM number_sequence -- 数字生成表
WHERE n <= 365
) d
CROSS JOIN (SELECT DISTINCT product_id FROM products) p -- 所有产品
LEFT JOIN sales s
ON s.sale_date = d.date
AND s.product_id = p.product_id
GROUP BY d.date, p.product_id;📊 数据库兼容性
| 数据库 | 显式CROSS JOIN |
隐式逗号语法 | 特殊优化 |
|---|---|---|---|
| MySQL | ✅ | ✅ | 无 |
| PostgreSQL | ✅ | ✅ | 支持LATERAL CROSS JOIN |
| Oracle | ✅ | ✅ | 支持CROSS APPLY |
| SQL Server | ✅ | ✅ | 支持CROSS APPLY |
| SQLite | ✅ | ✅ | 无 |
所有主流数据库均完全支持交叉连接
💎 总结:交叉连接使用原则
交叉连接是SQL中的"原子能" :
✅ 组合生成的终极工具
✅ 数据骨架构建的核心
✅ 测试数据生成的利器
但必须警惕:
⚠️ 随时可能引发数据爆炸
⚠️ 禁止用于生产大表
⚠️ 永远优先考虑替代方案
终极代码模板:
sql
-- 安全可控的交叉连接示例
WITH
limited_tableA AS (SELECT * FROM bigA LIMIT 100),
limited_tableB AS (SELECT * FROM bigB LIMIT 100)
SELECT *
FROM limited_tableA
CROSS JOIN limited_tableB; -- 最大10,000行结果交叉连接 与 全外连接
交叉连接 (CROSS JOIN) vs 全外连接 (FULL OUTER JOIN):全面对比
交叉连接和全外连接是 SQL 中两种功能完全不同的连接操作,它们在数据逻辑、结果集和应用场景上有根本性差异。以下是深度对比分析:
核心差异总览
| 特性 | 交叉连接 (CROSS JOIN) | 全外连接 (FULL OUTER JOIN) |
|---|---|---|
| 定义 | 生成笛卡尔积 | 保留两表所有行 + 匹配组合 |
| 数学本质 | 笛卡尔积 (A × B) | 并集 (A ∪ B) |
| 连接条件 | ❌ 不需要 | ✅ 必须 (ON/USING) |
| 结果行数 | |A| × |B| | |A| + |B| - |A∩B| |
| NULL 处理 | 不产生新 NULL | 未匹配部分填充 NULL |
| 性能风险 | 极高(指数级爆炸) | 中高(需处理未匹配行) |
| 使用频率 | <5% | ≈5% |
| 典型场景 | 组合生成、测试数据 | 数据比对、完整性审计 |
详细对比分析
1. 数据逻辑与结果特性
| 特性 | 交叉连接 | 全外连接 |
|---|---|---|
| 匹配行为 | 无条件组合所有行 | 按条件匹配 + 保留未匹配行 |
| 结果内容 | 所有可能组合 | 匹配行 + A表独有行 + B表独有行 |
| NULL 产生 | ❌ 不产生新 NULL | ✅ 未匹配位置产生 NULL |
| 数据关联 | 无业务逻辑关联 | 基于业务键关联 |
| 结果图示 | [红S, 红M, 蓝S, 蓝M] |
[1+null, 2+2, null+3] |
2. 语法与执行
| 特性 | 交叉连接 | 全外连接 |
|---|---|---|
| 标准语法 | FROM A CROSS JOIN B |
FROM A FULL OUTER JOIN B ON ... |
| 旧式语法 | FROM A, B(危险!) |
Oracle: A.id = B.id(+)(已弃用) |
| 执行过程 | 简单嵌套循环 | 哈希匹配/合并连接 + NULL 处理 |
| 条件位置 | WHERE 仅用于过滤 | ON 定义连接,WHERE 过滤结果 |
| MySQL 支持 | ✅ 完全支持 | ❌ 不支持(需 UNION 模拟) |
3. 应用场景对比
| 场景 | 交叉连接 | 全外连接 |
|---|---|---|
| 组合生成 | ✅ 产品规格矩阵 | ❌ 不适用 |
| 数据比对 | ❌ 不适用 | ✅ 系统迁移差异检测 |
| 序列填充 | ✅ 日期-产品骨架 | ❌ 不适用 |
| 完整性审计 | ❌ 不适用 | ✅ 查找数据孤岛 |
| 测试数据 | ✅ 快速生成海量数据 | ❌ 不适用 |
| 统计分析 | ⚠️ 谨慎用于特征组合 | ✅ 保留空分类统计 |
4. 性能与风险
| 特性 | 交叉连接 | 全外连接 |
|---|---|---|
| 大表风险 | 灾难级(100万×100万=1万亿) | 高(需处理两表全集) |
| 索引效用 | ❌ 无帮助 | ✅ 连接列索引有效 |
| 优化策略 | 严格限制输入行数 | 先过滤再连接 |
| 执行复杂度 | O(n²) | O(n log n) |
| 内存消耗 | 极高 | 中高 |
典型场景代码对比
交叉连接:产品规格矩阵
sql
-- 生成所有颜色和尺寸组合
SELECT c.color_name, s.size_name
FROM colors c
CROSS JOIN sizes s;结果:
lua
| color_name | size_name |
|------------|-----------|
| 红 | S |
| 红 | M |
| 蓝 | S |
| 蓝 | M |全外连接:员工-部门数据比对
sql
-- 检测HR系统与考勤系统差异
SELECT
COALESCE(h.emp_id, a.emp_id) AS emp_id,
CASE
WHEN h.emp_id IS NULL THEN '仅存在于考勤系统'
WHEN a.emp_id IS NULL THEN '仅存在于HR系统'
ELSE '数据一致'
END AS status
FROM hr_employees h
FULL OUTER JOIN attendance_records a
ON h.emp_id = a.emp_id
WHERE h.emp_id IS NULL OR a.emp_id IS NULL; 结果:
lua
| emp_id | status |
|--------|-------------------|
| 101 | 仅存在于HR系统 |
| 205 | 仅存在于考勤系统 |混合使用案例
交叉连接 + 全外连接:报表骨架填充
sql
-- 创建日期-产品类别的完整报表骨架
WITH
dates AS (SELECT generate_series('2023-01-01', '2023-01-03', '1 day') AS date),
categories AS (SELECT * FROM (VALUES ('电子'),('服装')) AS t(category)),
skeleton AS (
SELECT d.date, c.category
FROM dates d
CROSS JOIN categories c -- 生成基础矩阵
)
SELECT
s.date,
s.category,
COALESCE(SUM(sales.amount), 0) AS sales
FROM skeleton s
FULL OUTER JOIN daily_sales sales -- 填充实际销售数据
ON s.date = sales.date
AND s.category = sales.category
GROUP BY 1,2;结果:
yaml
| date | category | sales |
|------------|----------|-------|
| 2023-01-01 | 电子 | 1500 |
| 2023-01-01 | 服装 | 0 | ← 交叉连接生成的骨架行
| 2023-01-02 | 电子 | 800 |
| 2023-01-02 | 服装 | 1200 |
| 2023-01-03 | 电子 | 0 | ← 全外连接保留的日期
| 2023-01-03 | 服装 | 0 |性能优化策略对比
交叉连接优化方案
sql
-- 安全模式:限制输入行数
WITH
limited_products AS (SELECT * FROM products LIMIT 100), -- 限制100个产品
limited_stores AS (SELECT * FROM stores LIMIT 10) -- 限制10个门店
SELECT *
FROM limited_products
CROSS JOIN limited_stores; -- 最大1,000行全外连接优化方案
sql
-- 过滤前置减少处理量
SELECT *
FROM (SELECT * FROM bigA WHERE date > '2023-01-01') a
FULL OUTER JOIN (SELECT * FROM bigB WHERE value < 1000) b
ON a.key = b.key;决策流程图
黄金实践原则:
- 交叉连接 → 仅用于受控的小数据集组合生成
- 全外连接 → 保留用于关键数据审计和系统比对
- 永远优先考虑替代方案(如数学优化、UNION模拟)
- 生产环境大表严禁直接交叉连接
终极选择建议:
- 需要生成特征组合 →
CROSS JOIN(限制行数!) - 需要比较两个数据源 →
FULL OUTER JOIN(或UNION模拟) - 需要保留主表数据 →
LEFT JOIN - 需要精确匹配数据 →
INNER JOIN
全面对比: 内连接 , 外连接 , 交叉连接
SQL 三大连接类型全面对比:内连接 vs 外连接 vs 交叉连接
以下是 SQL 中三种核心连接类型的全方位对比分析,涵盖其定义、语法、结果特性、应用场景及注意事项:
核心对比总表
| 特性 | 内连接 (INNER JOIN) | 外连接 (OUTER JOIN) | 交叉连接 (CROSS JOIN) |
|---|---|---|---|
| 定义 | 仅返回匹配行 | 保留至少一个表的所有行 | 返回所有可能的行组合 |
| 数学本质 | 交集 (A ∩ B) | 并集+补集 (A ∪ B - A∩B) | 笛卡尔积 (A × B) |
| 主要类型 | 仅一种 | LEFT JOIN, RIGHT JOIN, FULL JOIN | 仅一种 |
| 语法示例 | SELECT ... FROM A INNER JOIN B ON A.key=B.key |
SELECT ... FROM A LEFT JOIN B ON A.key=B.key |
SELECT ... FROM A CROSS JOIN B |
| 结果行数 | ≤ min(|A|,|B|) | ≥ max(|A|,|B|) | = |A| × |B| |
| NULL 处理 | 不产生 NULL | 未匹配行用 NULL 填充 | 不产生新 NULL(除非原表有) |
| 连接条件 | 必须 (ON/USING) | 必须 (ON/USING) | 不需要 |
| 性能风险 | 低-中 | 中-高 | 极高(大数据集危险) |
| 使用频率 | 70% | 25% | 5% |
| 典型场景 | 获取关联数据 | 保留主表数据/检测缺失 | 生成组合/填充序列 |
详细对比分析
1. 数据逻辑与结果特性
| 特性 | 内连接 | 外连接 | 交叉连接 |
|---|---|---|---|
| 匹配行为 | 仅返回完全匹配的行 | 保留主表所有行 + 匹配行 | 无条件组合所有行 |
| 结果结构 | 两表列完整 | 主表列完整 + 从表列可能 NULL | 两表列完整 |
| 数据完整性 | 可能丢失数据 | 保障主表数据完整 | 超集(包含所有组合) |
| NULL 产生 | ❌ 不产生 | ✅ 未匹配位置产生 NULL | ❌ 不产生新 NULL |
| 结果图示 | [2,3] (A∩B) |
[1(null),2,3] (左连接) |
[1a,1b,2a,2b] (A×B) |
2. 语法与使用
| 特性 | 内连接 | 外连接 | 交叉连接 |
|---|---|---|---|
| 必要子句 | ON 或 USING |
ON 或 USING |
无连接条件 |
| 多表连接 | 链式清晰 | 需注意连接顺序 | 易产生指数级爆炸 |
| 旧式语法 | FROM A,B WHERE A.key=B.key |
Oracle: A.id = B.id(+) |
FROM A,B (危险!) |
| 条件位置 | WHERE/ON 效果相同 | WHERE 可能使外连接失效 | WHERE 仅用于过滤 |
| 自连接 | 常用(层级查询) | 可用(如查找无经理员工) | 少用 |
3. 性能与优化
| 特性 | 内连接 | 外连接 | 交叉连接 |
|---|---|---|---|
| 索引策略 | 双表连接列建索引 | 从表连接列建索引 | 无索引帮助 |
| 优化重点 | 减少匹配行数 | 避免 WHERE 导致退化 | 严格控制数据集大小 |
| 大表风险 | 中等 | 中高 | 灾难级 |
| 最佳实践 | 先过滤再连接 | 主表过滤前置 | 使用行生成器替代物理表 |
| 执行复杂度 | O(n log n) | O(n log n) | O(n²) |
4. 应用场景对比
| 场景 | 内连接 | 外连接 | 交叉连接 |
|---|---|---|---|
| 数据关联 | 订单-客户详情 | 所有客户+订单(含未下单) | ❌ 不适用 |
| 缺失检测 | ❌ 无法检测 | ✅ 查找无订单客户 | ❌ 不适用 |
| 组合生成 | ❌ 不适用 | ❌ 不适用 | ✅ 产品规格矩阵 |
| 数据比对 | ❌ 仅显示匹配 | ✅ FULL JOIN 系统数据比对 | ❌ 不适用 |
| 序列生成 | ❌ 不适用 | ❌ 不适用 | ✅ 日期序列填充 |
| 统计报表 | 基础统计 | 保留空分类统计 | 数据骨架初始化 |
| 机器学习 | 特征关联 | 特征完整性保障 | 特征交叉组合 |
典型场景代码示例
内连接:获取有效订单
sql
SELECT o.order_id, c.name, o.amount
FROM orders o
INNER JOIN customers c ON o.customer_id = c.customer_id
WHERE o.status = 'completed';左外连接:保留所有客户
sql
SELECT c.name, COALESCE(SUM(o.amount), 0) AS total
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id
GROUP BY c.customer_id;交叉连接:生成日期-产品矩阵
sql
SELECT
d.date,
p.product_id,
COALESCE(s.sales, 0) AS sales
FROM
(SELECT generate_series('2023-01-01', '2023-12-31', '1 day')::date AS date) d
CROSS JOIN products p
LEFT JOIN sales s ON d.date = s.sale_date AND p.product_id = s.product_id;决策流程图:如何选择连接类型
重要注意事项对比
| 注意事项 | 内连接 | 外连接 | 交叉连接 |
|---|---|---|---|
| 常见错误 | 忘记连接条件导致部分笛卡尔积 | WHERE 使外连接退化为内连接 | 无限制导致海量数据 |
| NULL 陷阱 | 不涉及 | COUNT(*) vs COUNT(列) 差异 | 不涉及 |
| 可替代性 | 可被外连接模拟 | 左连接可模拟右连接 | 不可替代 |
| 跨数据库兼容性 | 完全兼容 | FULL JOIN 在 MySQL 不受支持 | 完全兼容 |
| 维护建议 | 首选方案 | 明确注释连接意图 | 添加显式 CROSS JOIN 关键字 |
黄金法则:
- 日常业务查询优先使用 INNER JOIN
- 数据完整性需求使用 LEFT JOIN
- FULL JOIN 仅用于数据比对/审计
- CROSS JOIN 必须显式声明 + 行数限制
- 永远避免隐式逗号连接语法(
FROM A,B)
各种连接的使用频率
在SQL数据库开发与数据分析中,各类连接操作的使用频率与其适用场景强相关,综合行业实践及技术文献,各类连接的使用频率和特点如下表总结:
| 连接类型 | 使用频率 | 特点总结 | 典型应用场景 |
|---|---|---|---|
| 内连接(INNER JOIN) | ≈70% | 精准匹配交集数据,避免冗余;高效稳定 | 关联订单-客户、销售-产品等强关系数据查询 |
| 左外连接(LEFT JOIN) | ≈15-20% | 保留左表全集,右表可缺省;兼容NULL处理 | 客户全量分析、存在性检测(如"未下单客户") |
| 右外连接(RIGHT JOIN) | <5% | 可被左连接替代;语义特殊场景使用 | 以右表为主体的数据整合(如任务-负责人关系) |
| 全外连接(FULL JOIN) | ≈5% | 双表全集合并;兼容性差(MySQL不支持) | 系统迁移比对、数据完整性审计 |
| 交叉连接(CROSS JOIN) | <5% | 笛卡尔积;结果集庞大,性能风险高 | 生成测试组合、维度矩阵初始化(如颜色×尺码) |
| 自然连接(NATURAL JOIN) | 极低 | 自动匹配同名列;结构依赖性强,维护风险高 | 临时查询或学术演示(生产环境不推荐) |
下面具体展开说明各连接类型的使用特点及高频场景:
一、内连接(INNER JOIN):高频首选(≈70%)
- 核心优势:仅返回两表匹配行,结果精准无冗余,性能高效。
- 高频场景:多表关联查询(如订单表关联客户表)、数据分析中提取有效记录。
- 优化关键 :对连接键建索引(如
customer_id),可显著提升大表关联效率。
二、左外连接(LEFT JOIN):中频刚需(≈15-20%)
- 不可替代性:需保留左表全集时必选(如"所有客户无论是否下单")。
- 关键用途:数据完整性检查(如查找无订单客户)、主从表数据整合(主表数据不可丢失)。
- 避坑点 :
- 条件应写于
ON子句而非WHERE,避免退化为内连接; - 统计时用
COUNT(column)替代COUNT(*),避免NULL行干扰。
- 条件应写于
三、右外连接(RIGHT JOIN)与全外连接(FULL JOIN):低频慎用(各<5%)
- 右外连接:多数场景可被左连接替代(调换表顺序 + LEFT JOIN),少数需强调右表主体性的场景保留。
- 全外连接 :
- 适用系统级数据比对(如新旧数据库一致性校验);
- MySQL需以
UNION模拟实现(兼容性差)。
四、交叉连接(CROSS JOIN)与自然连接:极低使用(<5%,自然连接接近0%)
- 交叉连接 :
- 适用场景狭窄:生成测试数据、维度组合(如日期×产品);
- 性能风险极高:表行数为M、N时,结果集达M×N行,需严格限制数据量。
- 自然连接 :
- 因自动按同名字段匹配,表结构变更易引发查询逻辑错误;
- 生产环境禁用,被显式
JOIN...ON替代。
五、连接类型选择决策建议
- 默认选择内连接:需关联有效数据时优先使用(高效精准);
- 保留主表数据用左连接:如"查所有员工及部门"(含未分配部门者);
- 避免右连接:除非业务逻辑明确依赖右表主体性;
- 全连接仅用于审计:数据迁移或完整性检查等特殊场景;
- 交叉连接严控范围:用小规模维度表生成组合,禁止大表交叉。
总结来说:内连接是日常开发的"主力工具",左外连接是数据完整性的"守护者",其余连接类型需按场景谨慎启用。理解业务目标及数据关系,是选择最优连接类型的核心前提。