点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年10月13日更新到:
Java-147 深入浅出 MongoDB 分页查询详解:skip() + limit() + sort() 实现高效分页、性能优化与 WriteConcern 写入机制全解析
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
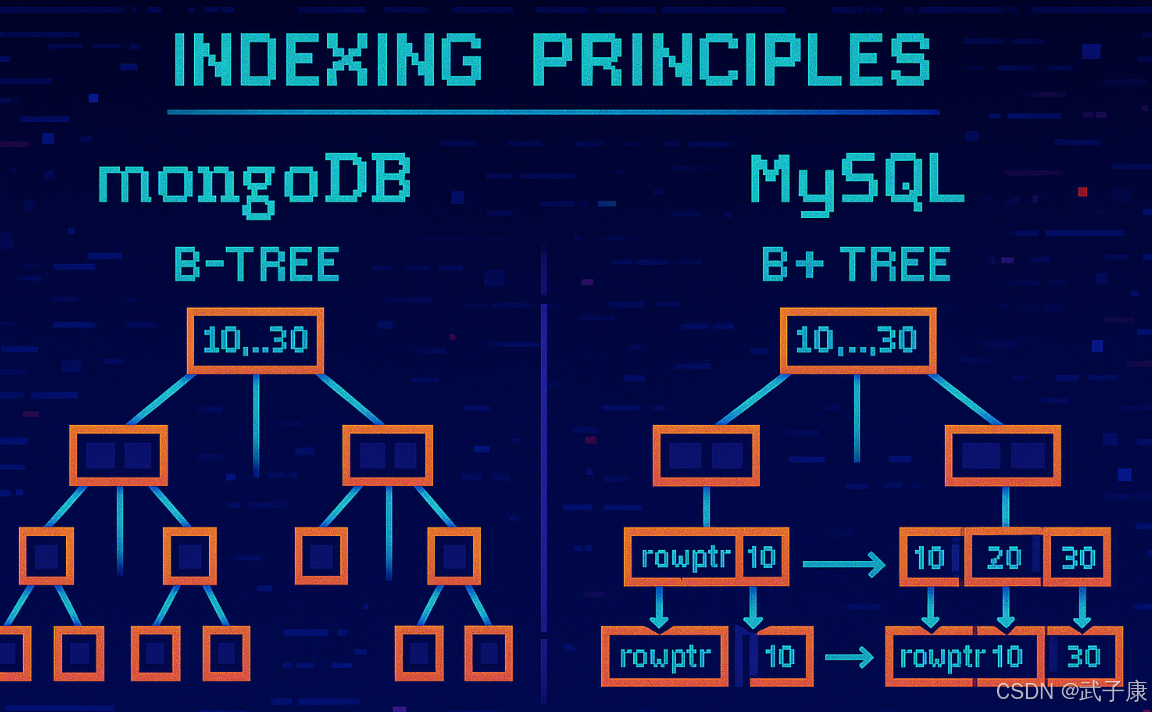
索引原理
基本原理
MongoDB 是一种流行的开源文档型数据库,由 MongoDB Inc. 公司开发并维护。它采用类似 JSON 的 BSON(Binary JSON)格式来存储数据,这种格式在 JSON 的基础上增加了对二进制数据的支持,同时保持了轻量级和可读性的特点。
与传统的关系型数据库(如 MySQL、Oracle)相比,MongoDB 的文档存储方式具有显著优势:
- 灵活的数据模型:不需要预先定义严格的表结构,可以随时添加或删除字段
- 水平扩展能力:通过分片(Sharding)技术实现数据分布式存储
- 高性能查询:支持丰富的查询语言和索引类型
- 原生支持高可用性:通过复制集(Replica Set)实现自动故障转移
MongoDB 广泛应用于以下场景:
- 内容管理系统(CMS)
- 移动应用后端
- 物联网(IoT)数据存储
- 实时分析系统
- 用户个性化配置存储
例如,在电商平台中,MongoDB 可以轻松存储不同结构的商品信息,有些商品可能有尺寸属性,而另一些可能有颜色选项,这种灵活的数据结构正是文档型数据库的优势所在。
在关系型数据库(如 MySQL)中,我们需要预先定义严格的表结构,并通过外键建立不同表之间的关联关系。例如,处理用户和订单数据时,通常需要创建至少两张表:
- 用户表(users)包含用户ID、姓名等基本信息
- 订单表(orders)包含订单ID、用户ID(外键)、商品信息等
当查询某个用户的订单时,必须执行表连接操作,这在数据量大时会影响性能。
而 MongoDB 采用了完全不同的存储方式。在 MongoDB 中,我们可以将相关联的数据直接嵌套存储在同一个文档中。例如一个用户文档可以这样表示:
json
{
"_id": "user123",
"name": "张三",
"orders": [
{
"orderId": "order001",
"items": [
{"product": "手机", "price": 2999},
{"product": "耳机", "price": 399}
],
"total": 3398
},
{
"orderId": "order002",
"items": [
{"product": "笔记本", "price": 5999}
],
"total": 5999
}
]
}这种存储方式具有以下优势:
- 数据结构直观,更贴近应用程序中的对象模型
- 减少了复杂的表连接操作,查询效率更高
- 可以灵活地调整文档结构,不需要预先定义严格的schema
- 支持嵌套数组和子文档,可以自然地表示一对多关系
在实际应用中,MongoDB 特别适合以下场景:
- 内容管理系统(CMS)
- 用户个性化配置存储
- 物联网设备数据收集
- 实时分析系统
需要注意的是,MongoDB 也不是万能的。对于需要强事务保证或复杂多表关联的业务场景,传统关系型数据库可能仍然是更好的选择。
MySQL 是典型的关系型数据库管理系统(RDBMS),其核心特征就是强调数据之间的关联性,通过外键约束、JOIN 操作等方式维护表与表之间的关系。在实际应用中,区间查询(如 BETWEEN、>、< 等范围操作)是非常常见的查询场景。
MySQL 底层采用 B+树作为索引的数据结构,这种结构具有以下特点:
- 所有数据都存储在叶子节点上,非叶子节点只存储键值和指针
- 叶子节点之间通过双向指针连接形成有序链表
- 这种结构使得范围查询非常高效,例如要查询 age 在 20-30 之间的记录,只需:
- 先定位到 age=20 的叶子节点
- 然后沿着指针顺序扫描直到 age=30 的节点
- 整个过程只需一次树搜索和顺序遍历
相比之下,MongoDB 作为文档型数据库,使用 B-树(B树)作为索引结构:
- B-树的特点是所有节点(包括内部节点)都可能包含数据
- 查询时一旦在某个节点找到匹配的键值,就可以直接获取数据
- 对于精确查询(如 find({_id:123})),这种结构可能比 MySQL 更快,因为:
- 不需要像 B+树那样必须搜索到叶子节点
- 可能在中间层就找到数据并返回
- 但 B-树的范围查询效率较低,因为:
- 数据分散在各个层级
- 缺乏 B+树那样的叶子节点链表结构
- 需要进行多次树遍历才能收集范围内的所有数据
在实际应用中,MySQL 的 B+树索引特别适合需要频繁进行范围查询的场景,如:
- 金融系统中的交易记录时间范围查询
- 电商系统中的价格区间筛选
- 日志系统中的时间段分析
而 MongoDB 的 B-树索引则更适合:
- 主键查询
- 不需要范围查询的简单条件查询
- 对单条记录的快速访问
B-树是一种自平衡搜索树,形式很简答:
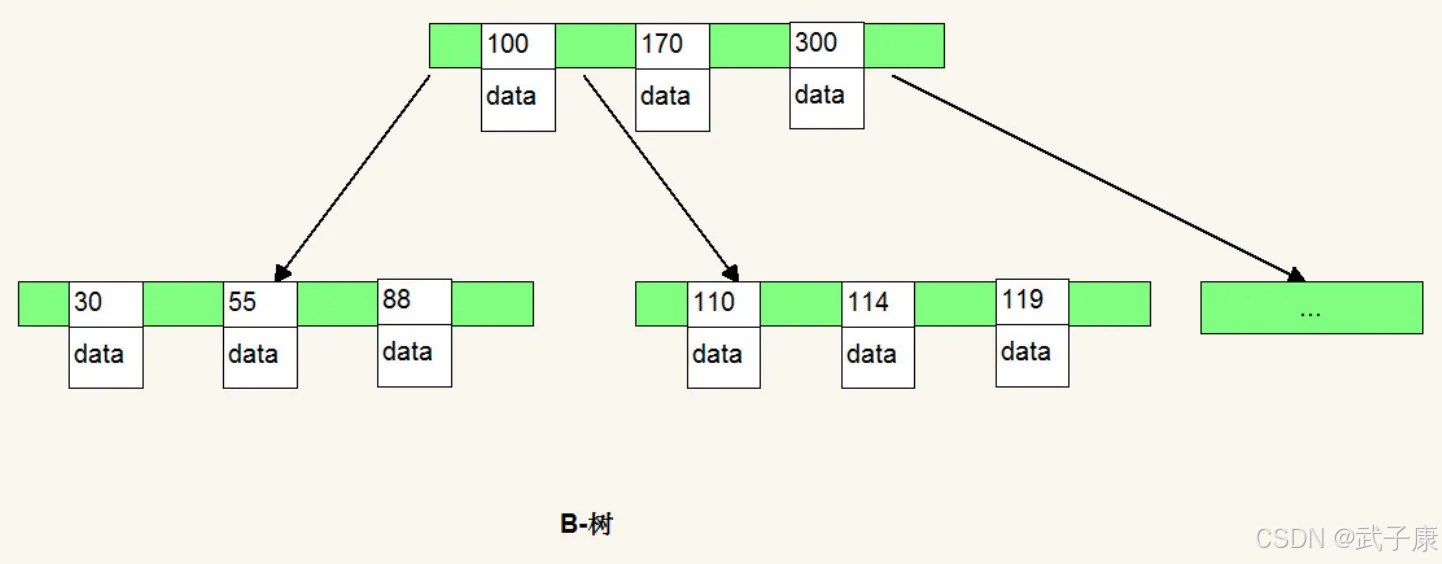
B-树
● 多路二叉树(Multiway Tree)
多路二叉树是一种树形数据结构,每个节点可以有多个子节点(通常多于两个),与二叉树的严格左右子树限制不同。它适用于存储大量数据并需要高效检索的场景,如文件系统、数据库索引(B树、B+树)等。多路树通过减少树的高度来提升查询效率,尤其适合磁盘存储等I/O密集型操作。
● 节点结构:数据与索引双重存储
每个节点不仅存储实际数据(如键值对、记录指针等),还保存用于快速定位子节点的索引信息。例如:
- 在B树中,节点包含有序的键值数组,每个键关联一个子节点指针,形成
(key₁, ptr₁), (key₂, ptr₂), ..., (keyₙ, ptrₙ)的结构。 - 数据可能直接嵌入节点(如B树叶子节点),或通过指针间接引用(如B+树的数据仅存于叶子节点)。
● 二分查找加速搜索过程
由于节点内的键值是有序排列的,搜索时可在节点内部使用二分查找算法快速定位目标区间。具体步骤:
- 从根节点开始,比较目标键与当前节点的键序列;
- 通过二分查找确定下一个子节点的指针(如目标键∈(keyᵢ, keyᵢ₊₁)则选择ptrᵢ₊₁);
- 递归进入子节点直至找到目标或到达叶子节点。
例如:在一个3路树节点[10, 20, 30]中搜索25,二分法会定位到20和30之间的子节点路径,减少比较次数。
应用场景:数据库索引通过多路二叉树(如B+树)实现高速检索,其中数千万记录仅需3-4次磁盘I/O即可定位,显著优于线性扫描。
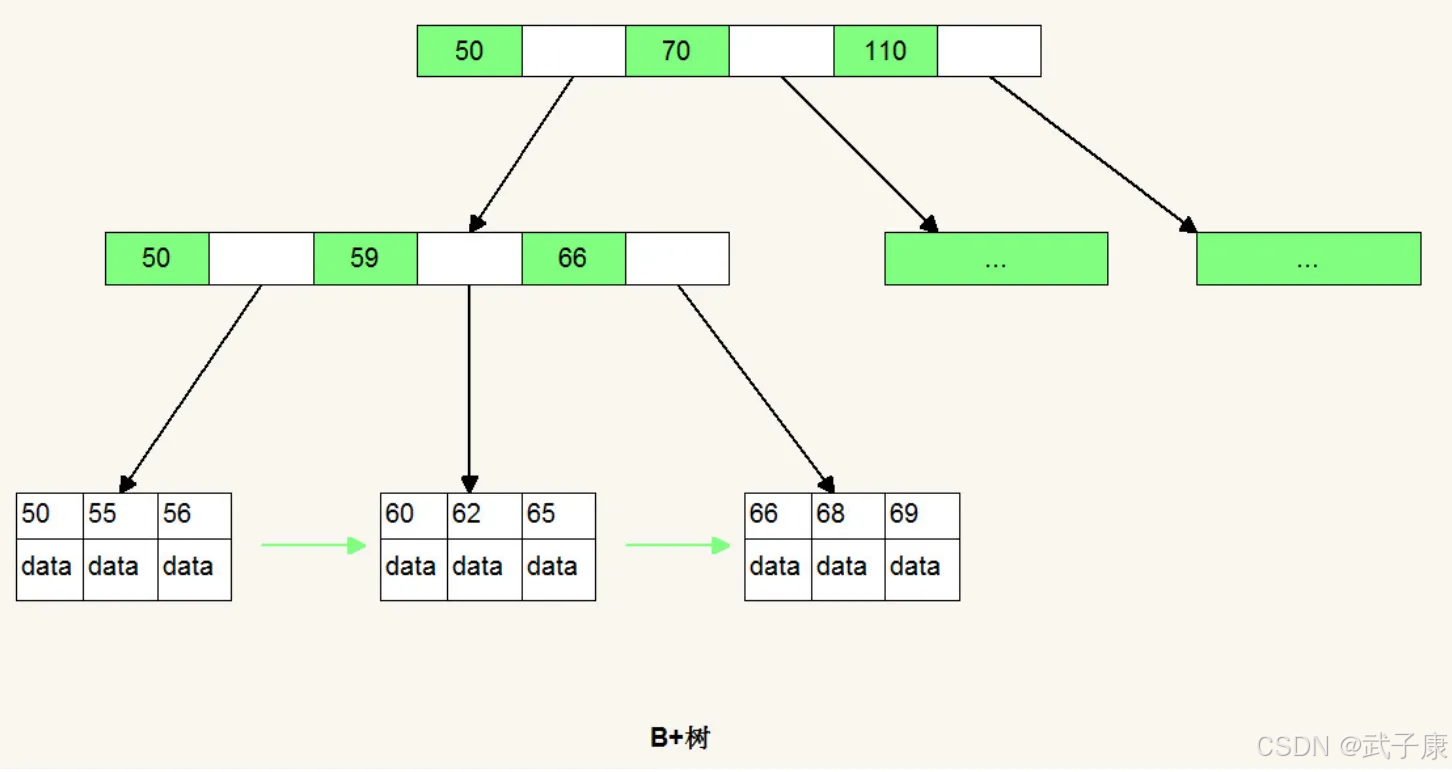
B+树
● 多路非二叉结构
- 采用多叉树结构(如B树/B+树),每个节点可包含多个子节点(典型为m/2到m个子节点)
- 相比二叉树,树高显著降低,减少磁盘I/O次数(例如4阶B树存储百万数据只需3-4层)
- 节点分裂策略:当子节点数超过上限时,中间key上升至父节点,节点分裂为两个
● 分层数据存储规则
- 内部节点仅存储索引键(如B+树的中间节点只存key不存data)
- 叶子节点形成有序链表,完整存储键值对数据
- 示例:数据库索引中,非叶节点存储
[10,20,30],叶节点存储(10:rowptr)→(20:rowptr)→...
● 类二分查找过程
- 从根节点开始,用二分法确定key所在区间(如key=15在10,20之间)
- 沿对应指针下探到下层节点,直至叶子层
- 时间复杂度保持O(log_m N),m为节点分支因子
● 双向指针优化
- 叶子节点间增加前驱/后继指针(如B+树的叶子双向链表)
- 支持高效范围查询:定位起始点后直接遍历指针(
WHERE id BETWEEN 100 AND 200) - 实际应用:MySQL的InnoDB引擎通过双向链表实现全表顺序扫描
两者区别
从上面分析可以看出,MongoDB和MySQL最核心的区别主要体现在以下两个方面:
-
数据存储方式的不同
- MySQL采用行式存储(Row-based Storage),数据以固定的表结构存储在硬盘上,每个表都有明确的列定义
- MongoDB采用文档存储(Document Storage),数据以灵活的BSON文档形式存储,每个文档可以有不同的字段结构
- 实际应用场景示例:在电商系统中,MySQL适合存储订单信息这类结构化数据,而MongoDB更适合存储商品信息这类可能包含变长属性的数据
-
数据关联方式的差异
- MySQL通过外键(Foreign Key)建立表间关系,支持JOIN操作实现跨表查询
- MongoDB通过引用(Reference)或嵌入式文档(Embedded Documents)实现数据关联,通常在一个文档中嵌套相关数据
- 性能影响示例:在社交网络应用中,MySQL需要多次JOIN查询才能获取完整的用户社交关系,而MongoDB可以通过嵌入式文档一次性获取用户及其好友信息
这两种根本性的差异直接导致了它们在以下方面的不同表现:
- 查询性能:MySQL适合复杂的关系查询,MongoDB适合快速读取文档数据
- 扩展方式:MySQL通常垂直扩展,MongoDB更容易水平扩展
- 事务支持:MySQL支持完整ACID事务,MongoDB在4.0版本后才支持多文档事务
- 开发效率:MongoDB的灵活模式更适合快速迭代的开发场景
● B+树与B-树的区间查询性能对比
- B+树通过相邻节点的指针连接(叶子节点间形成的链表结构),可以高效支持范围查询操作。例如:当执行"SELECT * FROM table WHERE id BETWEEN 100 AND 200"时,只需定位到起始键值节点,然后沿指针顺序遍历即可
- B-树由于每个节点的key和data紧密耦合在一起,且节点间没有额外的链接指针,进行范围查询时需要反复执行树遍历操作,性能明显较差
● 外存存储结构的优化设计
- B+树的非叶子节点仅存储索引键值(不包含实际数据),使得单个节点可容纳更多索引项。例如:在4KB的磁盘页大小下,B+树节点可存储约200个索引键,而B-树可能只能存储100个键值对(含数据)
- 磁盘预读特性(通常每次预读4KB-16KB数据)能被B+树更好利用,因为预读的索引节点包含更多有效的查找键。而B-树预读时可能包含大量不会被查询到的数据域,造成I/O浪费
● 树深度与I/O效率的权衡
- B-树的优势场景:
- 所有节点都存储数据,平均树深较浅(通常比B+树少1-2层)
- 适合随机点查询(如主键查找),最坏情况下只需3-4次磁盘I/O
- 示例:MongoDB的默认索引采用B-树结构,优化单文档查询性能
- B+树的优势场景:
- 数据只存储在叶子节点,导致树深增加(可能多1-2次I/O)
- 但顺序访问性能极佳,适合全表扫描、范围查询等操作
- 示例:MySQL的InnoDB引擎采用B+树索引,优化范围查询和排序操作