首先,让我们从Agent的定义开始探索: AI Agent(人工智能代理)是一种智能实体,它能够感知环境、自主决策并执行动作。与传统AI系统相比,Agent不仅能响应问题,还能主动完成一系列复杂任务。简而言之,如果将大型语言模型(LLM)比作一个"超级大脑",那么AI Agent就是为这个大脑配备了"手脚"和"工具",使其能够像人类一样主动采取行动,而不仅仅是被动地回答问题。

让我们通过一个最小可运行的例子来具体说明: 用户说:"帮我预订这周五从北京到上海的经济舱机票,价格不超过800元,用我的招商银行卡付款。"
Agent的工作流程如下:
- 感知:检查用户日历以确认"这周五"是8月15日;访问个人档案以获取身份证号和招行卡号。
- 决策:分解任务链: a. 查询8月15日北京至上海的航班 b. 筛选经济舱且价格低于800元的航班 c. 锁定座位并下单 d. 调用银行接口完成付款
- 执行:依次调用航空旅行API和银行API,完成机票预订。
- 反馈:将出票号和电子发票发送给用户,并记录在个人"行程记忆"中,以便下次自动优先推荐同一航空公司。
接下来,我将从LLM、工具、框架三个方面,带领大家深入了解Agent开发的世界。
LLM
首先,我们通过 7 月份发布国产 AI Kimi K2的性能基准图,来看看现在 AI 在卷哪些能力:
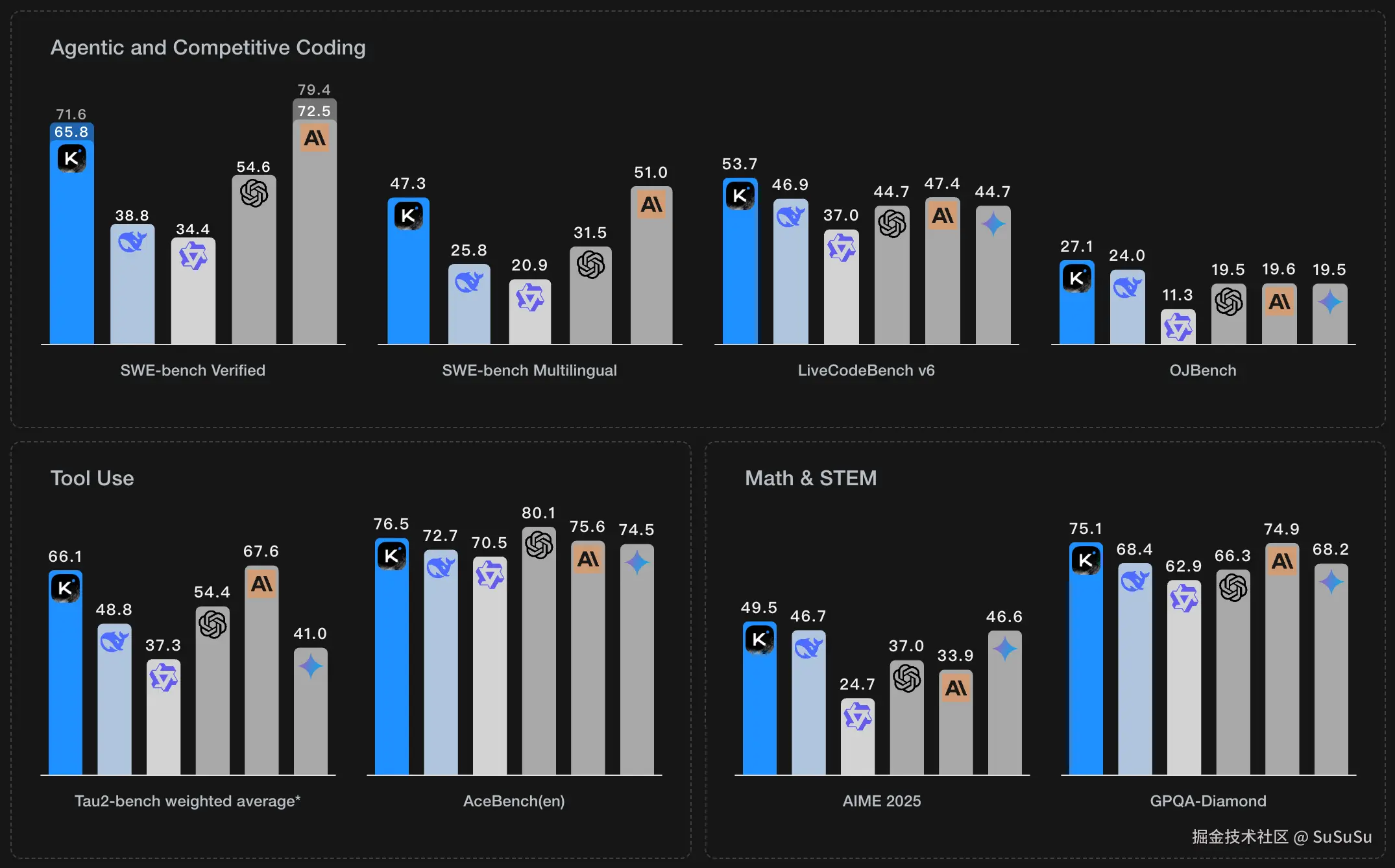
基准测试:
SWE-bench Verified:解决GitHub上的2,294个真实软件工程问题,包括修复代码和确保不影响现有功能。
SWE-bench Multilingual:针对多语言环境,生成代码修改以解决真实世界的GitHub问题。
LiveCodeBench v6:解决超过1000个编程问题,包括简单、中等和困难三个难度级别。
OJBench:在线评测系统中的编程挑战,测试算法设计、代码生成和问题解决技能。
Tau2-bench weighted average:评估模型使用各种工具和API的能力。
AceBench(en):专注于英语编程问题的算法设计、代码生成和问题解决技能。
AIME 2025:解决一系列具有挑战性的数学问题。
GPQA-Diamond:评估模型在科学、技术、工程和数学领域的知识理解和应用能力。
可以看出未来AI发展的几个重要方向:增强编程和工具使用能力,提升多语言支持,以及在数学和科学领域的深入应用。而这里面,工具使用能力正是决定Agent性能的核心能力。
可以看下测试里的一个例子:
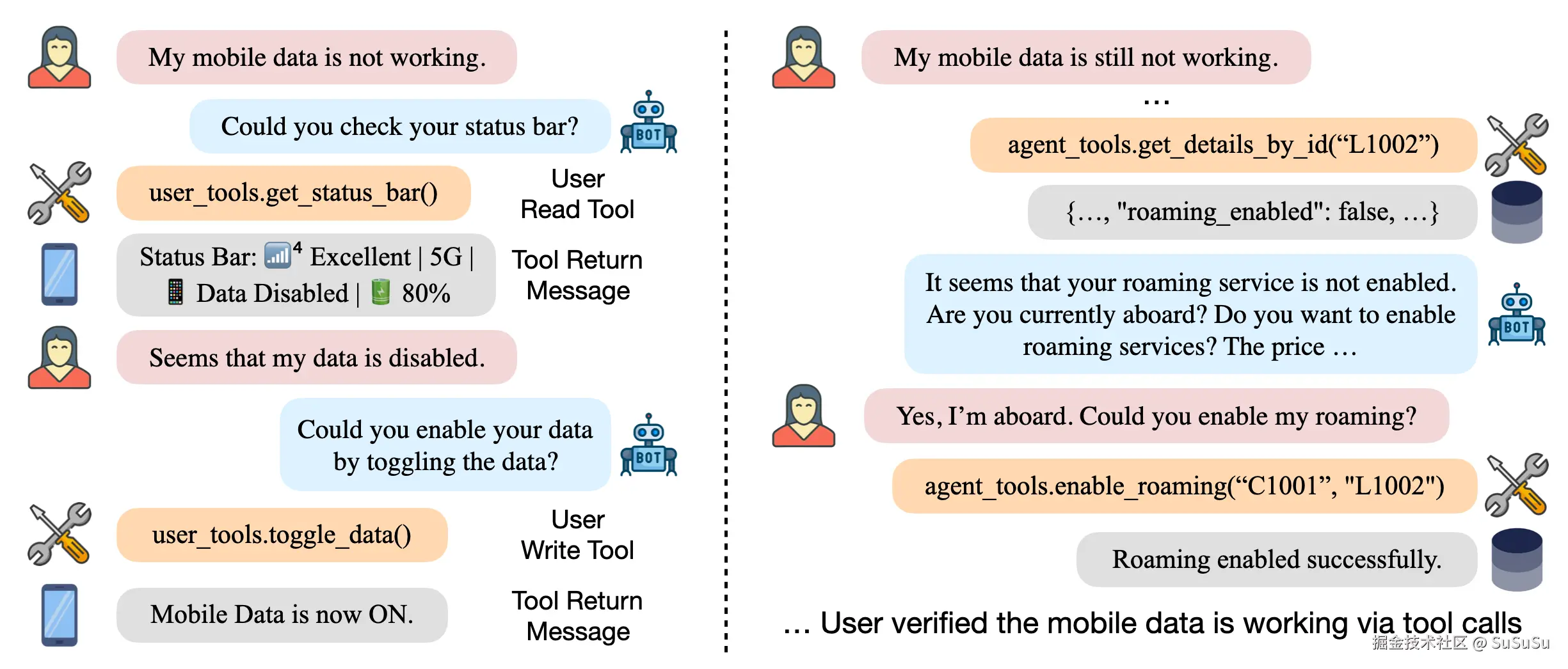
所以,在 Agent 开发中,选择一个工具使用能力强的 LLM 做调度者很重要。
在 Agent 开发中,除了工具使用能力,还需要根据具体任务选择合适的 LLM,同时兼顾使用成本和响应速度。
以下是一些具体任务场景及对应的模型选择建议:
- 文案生成:用 GPT-5,生成质量高但成本高。
- 代码生成:用 Claude4,代码生成能力强。
- 翻译或简单数据计算:用本地部署的 Llama 2,响应快且成本低。
同时,对于特定模态的输入输出,我们也需要选择特定模型。
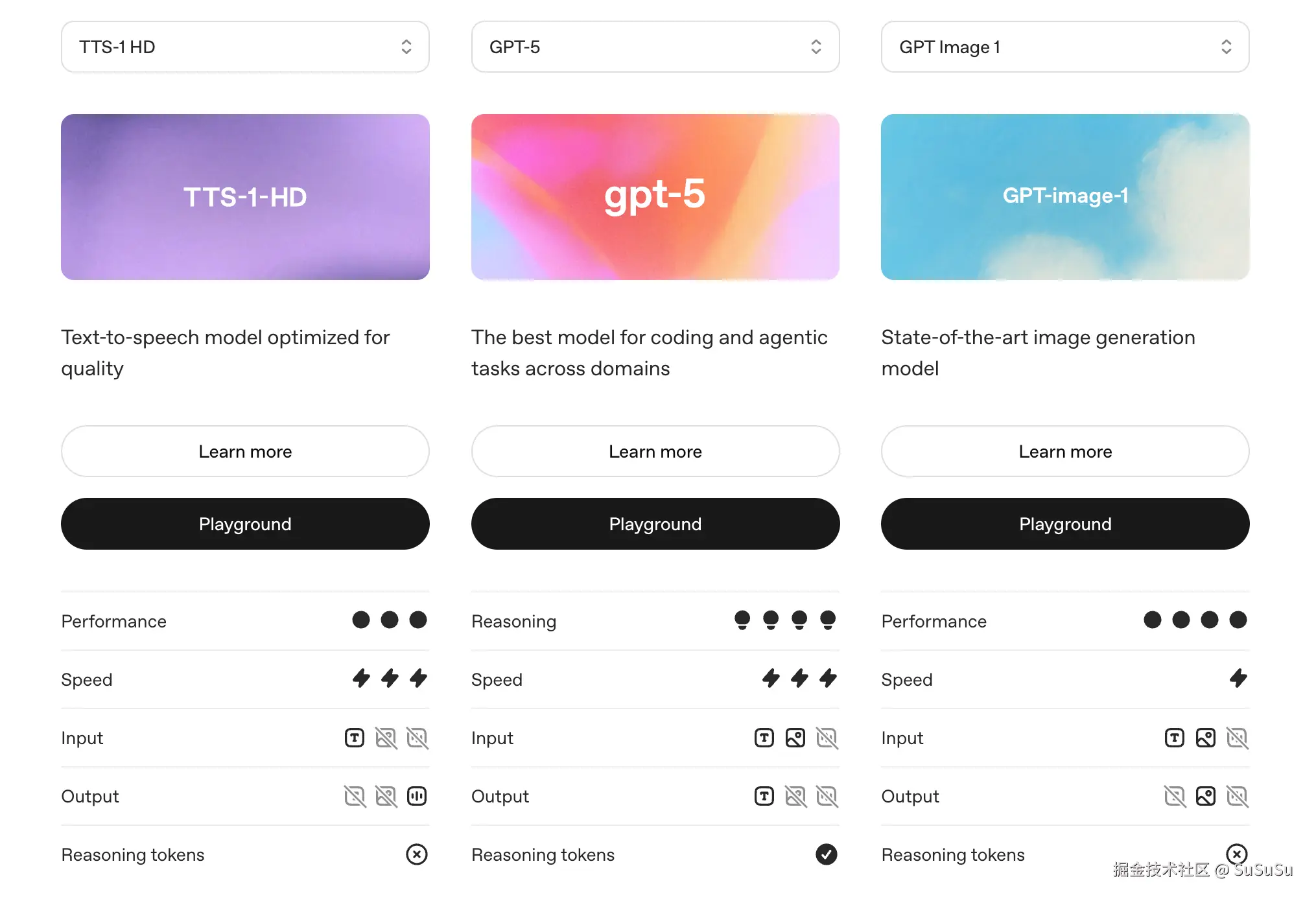
可以从看出,即使是像 GPT-5 这样先进的通用型语言模型,也未能涵盖所有模态的输入输出能力,例如它仍不支持图片输出、语音输入和输出等功能。对于这些特定模态的需求,必须借助专用的模型来实现。比如,若要进行图片输出,需使用 GPT Image 1 模型;若要实现语音输出,则需借助 TTS-1 HD 模型。
在当前的趋势下来看,一个 Agent 开发中,单独依靠一个模型做所有功能是不可能的。
下面,我们从阿里通义千问中选出最适合做 Agent 大脑的模型
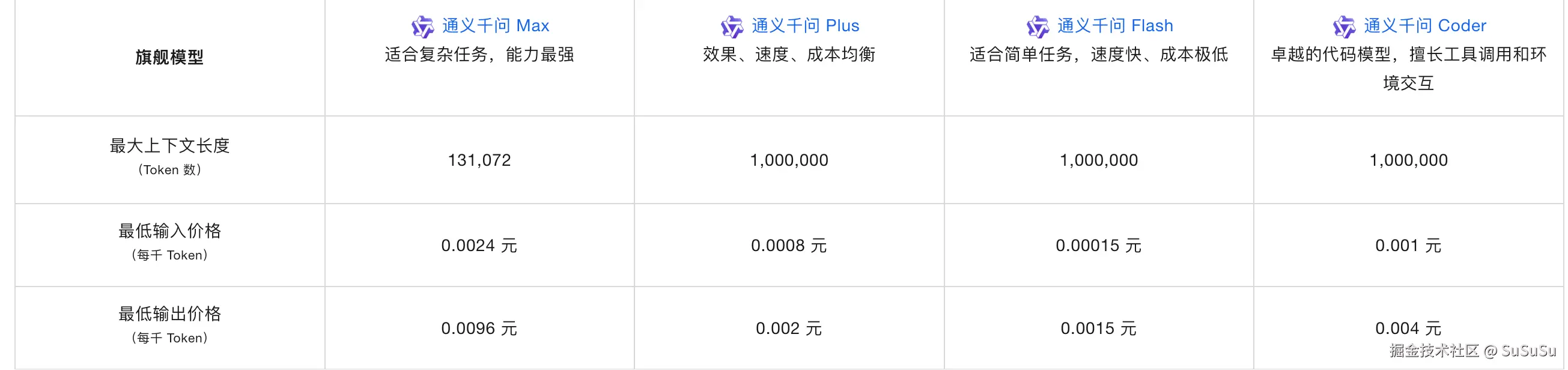
通义千问 Max 毫无疑问入选。
工具
下面,我们将使用 通义千问 Max 、openai 的api标准来继续下面的流程。
OpenAI API已经成为 LLM 的事实规范。
上下文
创建一段连续对话。
javascript
import dotenv from 'dotenv';
import OpenAI from "openai";
// 加载环境变量
dotenv.config({ quiet: true });
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
baseURL: process.env.OPENAI_BASE_URL
});
const message = [
'我是奥特曼',
'猜猜我是谁',
]
for (let i = 0; i < message.length; i++) {
const completion = await openai.chat.completions.create({
model:"qwen-max",
messages: [
{ role: 'user', content: message[i] }
],
temperature: 0,
})
console.log(completion.choices[0].message.content);
console.log('------------------');
}输出:
你好,奥特曼!作为一位来自M78星云的光之巨人,你拥有保护地球和宇宙和平的重要使命。请问有什么特别的任务需要我协助吗?或者,如果你只是想聊聊关于奥特曼的故事、能力或者其他相关的话题,我也非常乐意陪伴!
这个问题有点难倒我了,因为我无法直接知道屏幕另一端的你是谁。不过,如果你愿意,可以告诉我一些关于你的信息,比如你的兴趣爱好、职业等,这样我就能更好地了解你啦!或者,你也可以直接告诉我你是谁,哈哈。
可以看到,Agent并不知道上一步的输入,而在Agent操作中,分步执行任务是常态。
为了确保Agent能够连续执行任务,我们需要利用message字段------它是一个数组,允许我们将先前的信息按顺序传递给Agent,从而使其能够"记住"之前的对话内容。
role字段则用于明确每条信息的发送者角色,确保对话的流畅性和准确性。通过这种方式,Agent能够维持对任务进展的跟踪,实现连贯的操作流程。
| Role | 描述 |
|---|---|
| system | 定义助手的行为、个性、语调以及专业知识等,设置对话的上下文和行为。 |
| user | 代表用户提出的问题、任务或请求,是用户与助手互动的角色。 |
| assistant | 代表AI助手对用户的响应,展示模型的回复。 |
完善代码:
javascript
import dotenv from 'dotenv';
import OpenAI from "openai";
// 加载环境变量
dotenv.config({ quiet: true });
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
baseURL: process.env.OPENAI_BASE_URL
});
const message = [
'我是奥特曼',
'猜猜我是谁',
'你记得之前的你回答了什么吗?',
]
const context = [
{ role: 'system', content: '你是一个聊天机器人,请准确回答我的问题。' }
];
for (let i = 0; i < message.length; i++) {
context.push({ role: 'user', content: message[i] });
const completion = await openai.chat.completions.create({
model:"qwen-max",
messages: context,
temperature: 0,
})
const completionMessage = completion.choices[0].message.content;
context.push({ role: 'assistant', content: completionMessage });
console.log(completionMessage);
console.log('------------------');
}输出:
你好,奥特曼!作为一个深受人们喜爱的英雄角色,你代表着正义与勇气。如果你有任何问题或需要讨论有关奥特曼的话题,我很乐意帮助。请告诉我更多你的想法吧!
好的,我来猜猜看!你是奥特曼中的哪一位呢?是赛文奥特曼、迪迦奥特曼、初代奥特曼,还是其他某一位奥特曼呢?或者你是指现实生活中的某个人?给我一些线索吧,这样我能更好地猜到你是谁!
当然记得!在之前的对话中,你告诉我你是奥特曼,然后我回应说你代表着正义与勇气,并且询问你是否有更多想法或问题。接下来,你让我猜猜你是谁,我列出了几位奥特曼的名字,并问你是否能提供一些线索以便我更好地猜测。现在,你能给我一些线索吗?
这样,我们的Agent便具备了初步的记忆能力,这得益于我们通过消息数组(message array)将历史信息传递给Agent,使其能够参照之前的对话内容来继续任务。这种设计确保了Agent在处理多步骤任务时能够保持上下文的连贯性,从而提高交互的自然性和效率。
RAG
尽管初步的记忆能力为Agent提供了显著的优势,但在处理需要大量外部知识或数据支持的任务时,我们可能需要更高级的技术。这时,RAG(Retrieval-Augmented Generation)技术就显得尤为重要。
RAG是一种结合了信息检索和文本生成的技术,它通过检索相关的文档或信息片段来增强生成模型的能力。这种方法特别适用于那些需要结合大量外部知识来生成回答的场景。
一个 RAG 的构造流程如下:

- 信息源提取文本
- 文本拆分成块
- 将文本转换成向量
- 存储到向量数据库中
那么,RAG 是怎么和 LLM 进行交互的呢?
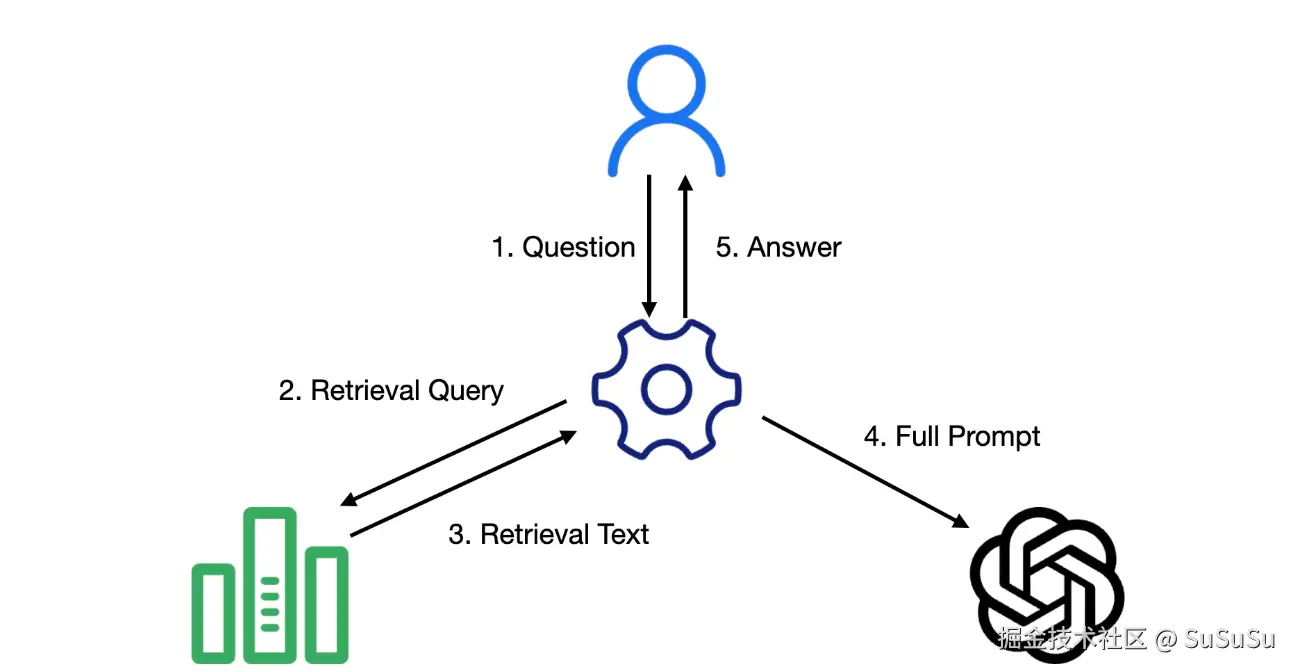
- 用户发起请求
- 根据用户的问题在RAG 中进行查询
- RAG 返回相关内容
- 组成完整的提示词
- 发给大模型将大模型的回复发给用户
下面我们来展示在 Dify 中使用RAG(在 Dify 中称为知识检索)。
- 创建知识库

- 组装工作流,这里主要看 LLM 的提示词
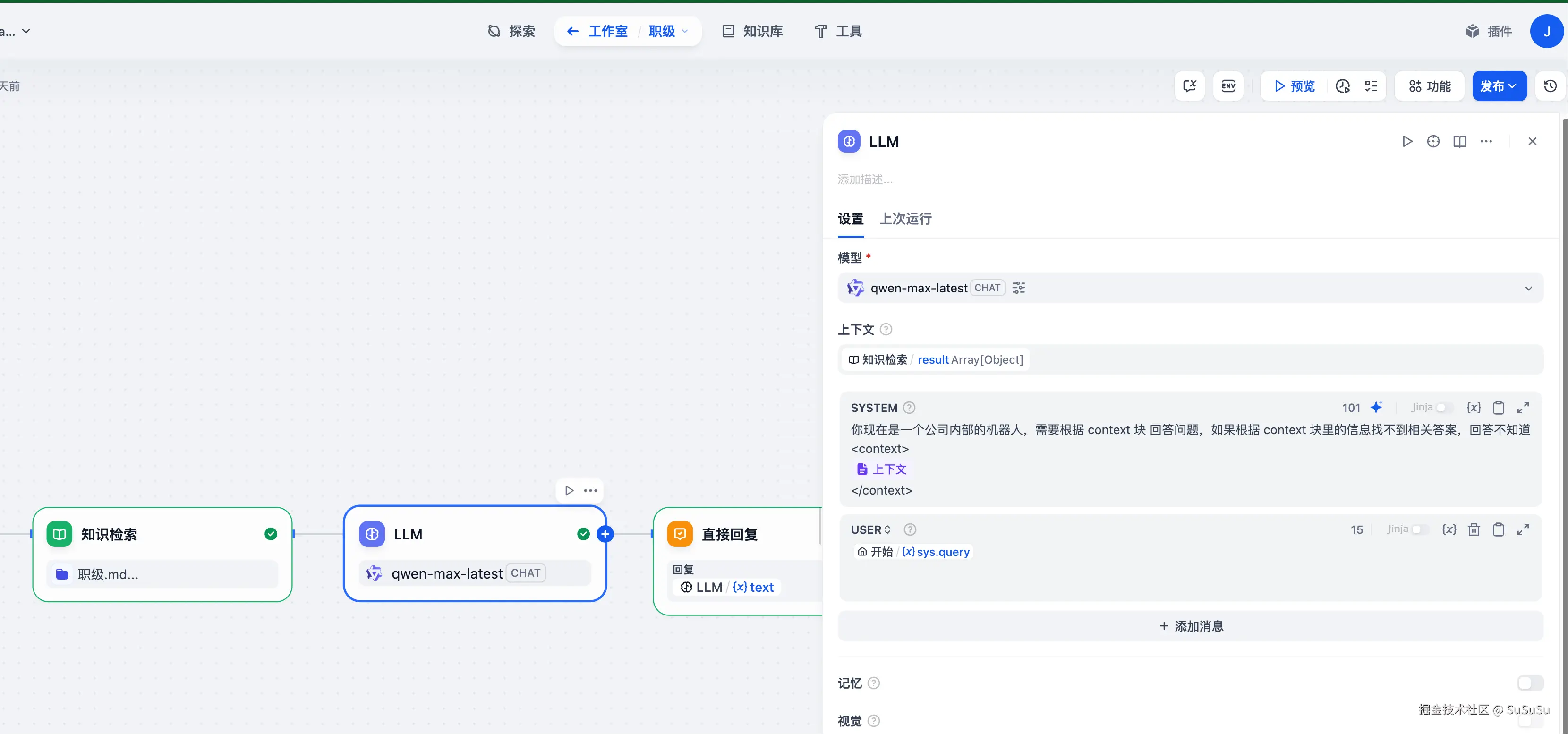
将知识检索作为上下文塞到了提示词里。
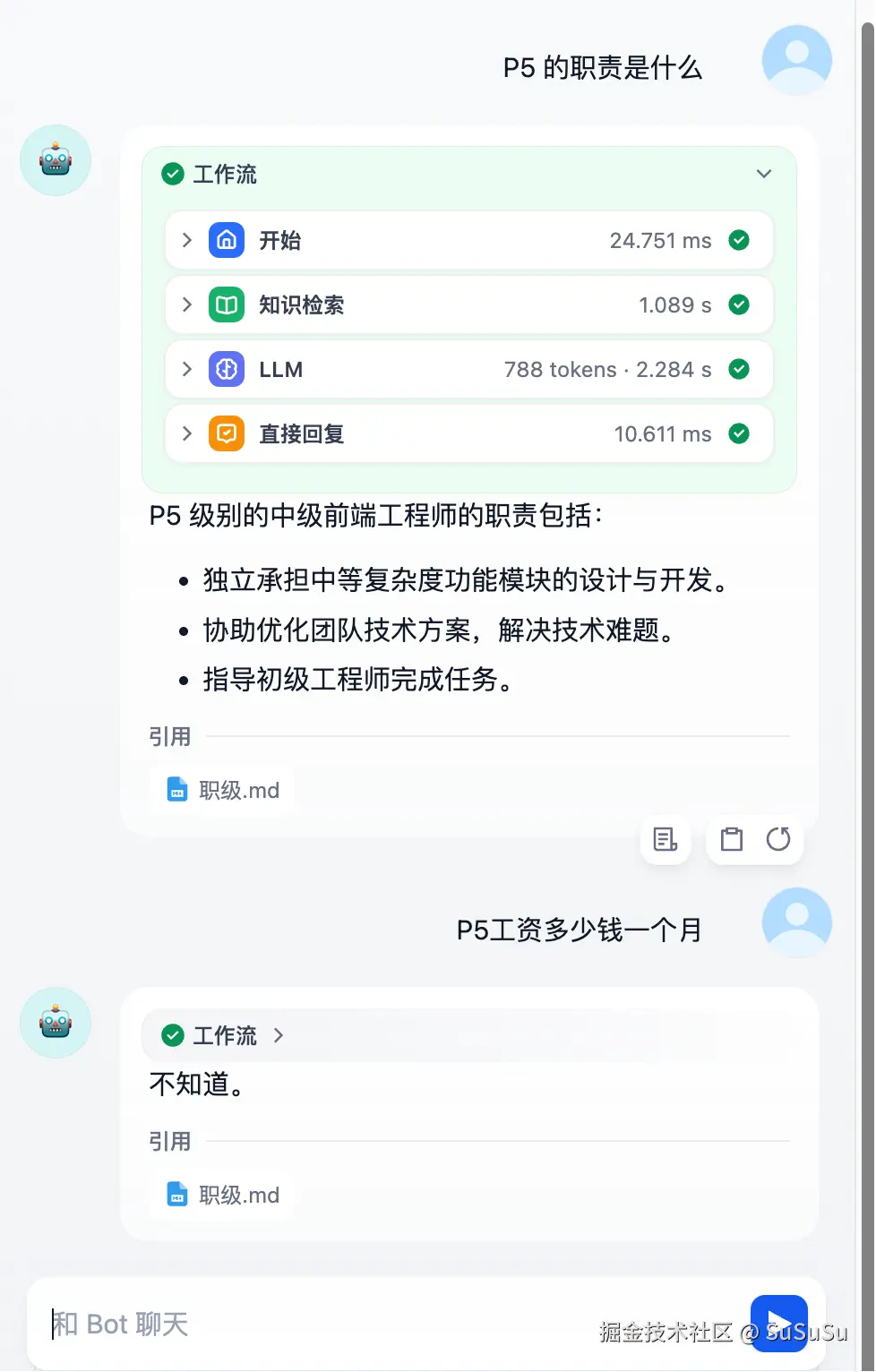
看一下运行效果:
Tools
利用了上下文理解能力的增强以及RAG技术的整合,我们的Agent现在拥有了几乎无限的知识获取能力。下一步我们将为其赋予工具调用的功能。
先看一下,没有使用 Tool 的 Agent 有多"弱鸡"。
javascript
import dotenv from 'dotenv';
import OpenAI from "openai";
// 加载环境变量
dotenv.config({ quiet: true });
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
baseURL: process.env.OPENAI_BASE_URL
});
console.log(new Date().toLocaleString())
const message = [
'现在几点钟',
'现在是1800年10月1号11点05分,请问1小时后是什么时候?',
]
for (let i = 0; i < message.length; i++) {
const completion = await openai.chat.completions.create({
model:"qwen-max",
messages: [
{ role: 'system', content: '你是一个聊天机器人,请准确回答我的问题。' },
{ role: 'user', content: message[i] }
],
temperature: 0,
})
console.log(completion.choices[0].message.content);
console.log('------------------');
}2025/7/28 17:27:50
当前时间是北京时间14:20。请注意,这个时间可能与您所在时区的时间有所不同。您可以通过网络查询或设备设置来获取您所在地区的准确时间。
如果现在是1800年10月1日11点05分,那么1小时后的时间就是1800年10月1日12点05分。
可以看到,没有工具的 LLM 甚至不知道现在是几点钟。
接下来,使用代码实现一个时间工具,能够根据时区返回一个格式化的时间。
javascript
function get_current_time(params) {
const { timezone = 'Asia/Shanghai' } = params || {};
const now = new Date();
const options = {
timeZone: timezone,
year: 'numeric',
month: '2-digit',
day: '2-digit',
hour: '2-digit',
minute: '2-digit',
second: '2-digit'
};
const formatter = new Intl.DateTimeFormat('zh-CN', options);
return formatter.format(now);
}为了让大型语言模型(LLM)在处理任务时能够适时地停下来并调用特定的函数,我们可以利用OpenAI API规范中的<font style="color:rgba(0, 0, 0, 0.9);background-color:rgba(0, 0, 0, 0.03);">tool</font>参数。这个参数的作用是向LLM指明它具备调用哪些工具的能力。当LLM被赋予了工具调用的能力后,它将能够在需要时返回相应的调用请求和响应。
定义 Tools
javascript
const tools = [
{
type: "function",
function: {
name: "get_current_time",
description: "获取当前时间",
parameters: {
type: "object",
properties: {
timezone: {
type: "string",
description: "时区,例如 'Asia/Shanghai'"
}
},
required: []
}
}
}
];调用
javascript
import dotenv from 'dotenv';
import OpenAI from "openai";
// 加载环境变量
dotenv.config({ quiet: true });
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
baseURL: process.env.OPENAI_BASE_URL
});
//
const tools = [...
// 实现工具函数
function get_current_time(params) ...
// 测试消息
const messages = [
'现在几点钟',
'现在东京时间几点了?',
'请告诉我当前时间'
];
async function run() {
for (let message of messages) {
console.log(`\n用户: ${message}`);
const completion = await openai.chat.completions.create({
model: "qwen-max",
messages: [
{ role: 'system', content: '你是一个有用的助手,可以使用工具来获取准确的时间信息。' },
{ role: 'user', content: message }
],
tools: tools,
tool_choice: "auto"
});
const messageResponse = completion.choices[0].message;
console.log(JSON.stringify(messageResponse))
console.log('------------------');
}
}
run().catch(console.error);输出:
用户: 现在几点钟
{"content":"","role":"assistant","tool_calls":{"function":{"name":"get_current_time","arguments":"{"timezone": "Asia/Shanghai"}"},"index":0,"id":"call_1433bb7f56f244d69df11c","type":"function"}}
用户: 现在东京时间几点了?
{"content":"","role":"assistant","tool_calls":{"function":{"name":"get_current_time","arguments":"{"timezone": "Asia/Tokyo"}"},"index":0,"id":"call_9d1926bc555440ce9791aa","type":"function"}}
用户: 请告诉我当前时间
{"content":"","role":"assistant","tool_calls":{"function":{"name":"get_current_time","arguments":"{"timezone": "Asia/Shanghai"}"},"index":0,"id":"call_da398b9bdde441e08715a0","type":"function"}}
可以看到,响应了一个 role 为 assistant的信息,tool_calls是LLM 期望调用的函数,入参也按照定义的提示进行进行了转换。
下面,实现工具的具体调用。
javascript
...
const messageResponse = completion.choices[0].message;
console.log(JSON.stringify(messageResponse))
console.log('------------------');
if (messageResponse.tool_calls) {
for (const toolCall of messageResponse.tool_calls) {
const { name, arguments: args } = toolCall.function;
if (name === 'get_current_time') {
const params = JSON.parse(args);
const currentTime = get_current_time(params);
// 将工具结果返回给模型
const finalResponse = await openai.chat.completions.create({
model: "qwen-max",
messages: [
{ role: 'system', content: '你是一个有用的助手,可以使用工具来获取准确的时间信息。' },
{ role: 'user', content: message },
messageResponse,
{
role: 'tool',
content: JSON.stringify({ currentTime }),
tool_call_id: toolCall.id
}
]
});
console.log(`AI: ${finalResponse.choices[0].message.content}`);
}
}
} else {
console.log(`AI: ${messageResponse.content}`);
}
...输出:
用户: 现在几点钟
{"content":"","role":"assistant","tool_calls":{"function":{"name":"get_current_time","arguments":"{"timezone": "Asia/Shanghai"}"},"index":0,"id":"call_696c682c38a04363a78f49","type":"function"}}
AI: 现在的时间是2025年8月10日17点44分49秒(亚洲/上海时区)。
用户: 现在东京时间几点了?
{"content":"","role":"assistant","tool_calls":{"function":{"name":"get_current_time","arguments":"{"timezone": "Asia/Tokyo"}"},"index":0,"id":"call_1544b90ad3a84241997225","type":"function"}}
AI: 当前东京时间是2025年8月10日 18:44:52。请注意,这个时间是基于您询问时刻的数据,实际查看时可能存在少许差异。
用户: 请告诉我当前时间
{"content":"","role":"assistant","tool_calls":{"function":{"name":"get_current_time","arguments":"{"timezone": "Asia/Shanghai"}"},"index":0,"id":"call_02ce4363283a481ab3e901","type":"function"}}
AI: 当前时间是2025年8月10日17点44分55秒(亚洲/上海时区)。
简而言之,通过在API调用中指定<font style="color:rgba(0, 0, 0, 0.9);background-color:rgba(0, 0, 0, 0.03);">tool</font>参数,我们可以指导LLM在适当的时机停下来,转而调用外部工具来完成任务,然后再继续后续的处理流程。这种智能化的工具调用机制,使得LLM成为一个更加强大和多功能的助手。
MCP
在深入探讨了如何为我们的Agent系统集成工具调用能力之后,我们现在转向一个关键的组成部分,它将极大地增强这些工具的协调性和效率:MCP,即Model-Context-Protocol。它定义了Agent如何与外部工具和服务进行交互。它为Agent提供了一种标准化的方式来识别、请求和使用这些工具。
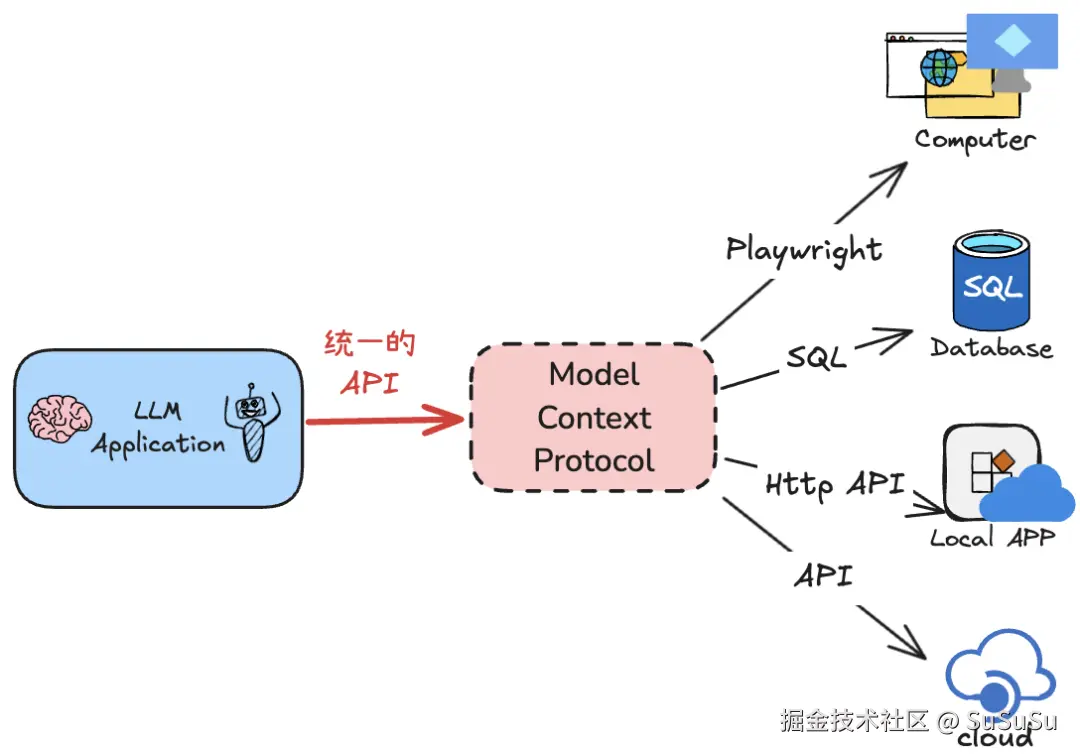
可以简单的理解为,遵守MCP协议的工具服务器会提供一个统一的接口,让 Agent 知道它里面有些什么工具、怎么用;会提供一个统一的使用接口,方便Agent来调用。
我们将上面的工具调用使用 MCP 的方式来实现。
javascript
#!/usr/bin/env node
import { Server } from '@modelcontextprotocol/sdk/server/index.js';
import { StdioServerTransport } from '@modelcontextprotocol/sdk/server/stdio.js';
import {
CallToolRequestSchema,
ListToolsRequestSchema,
} from '@modelcontextprotocol/sdk/types.js';
// 创建MCP服务器
const server = new Server(
{
name: 'mcp-time-server',
version: '1.0.0',
},
{
capabilities: {
tools: {},
},
}
);
// 定义时间工具
server.setRequestHandler(ListToolsRequestSchema, async () => {
return {
tools: [
{
name: 'get_current_time',
description: '获取当前时间',
inputSchema: {
type: 'object',
properties: {
timezone: {
type: 'string',
description: '时区,例如 "Asia/Shanghai", "Asia/Tokyo", "America/New_York"',
},
format: {
type: 'string',
description: '时间格式,例如 "full", "time", "date"',
enum: ['full', 'time', 'date'],
default: 'full'
}
},
required: [],
},
},
{
name: 'get_timezone_offset',
description: '获取时区偏移量',
inputSchema: {
type: 'object',
properties: {
timezone: {
type: 'string',
description: '时区,例如 "Asia/Shanghai"',
},
},
required: ['timezone'],
},
}
],
};
});
// 处理工具调用
server.setRequestHandler(CallToolRequestSchema, async (request) => {
const { name, arguments: args } = request.params;
switch (name) {
case 'get_current_time': {
const { timezone = 'Asia/Shanghai', format = 'full' } = args || {};
try {
const now = new Date();
let options = {};
switch (format) {
case 'time':
options = {
timeZone: timezone,
hour: '2-digit',
minute: '2-digit',
second: '2-digit',
hour12: false
};
break;
case 'date':
options = {
timeZone: timezone,
year: 'numeric',
month: '2-digit',
day: '2-digit'
};
break;
case 'full':
default:
options = {
timeZone: timezone,
year: 'numeric',
month: '2-digit',
day: '2-digit',
hour: '2-digit',
minute: '2-digit',
second: '2-digit',
hour12: false
};
}
const formatter = new Intl.DateTimeFormat('zh-CN', options);
const timeString = formatter.format(now);
return {
content: [
{
type: 'text',
text: '当前' + timezone + '时间是: ' + timeString,
},
],
};
} catch (error) {
return {
content: [
{
type: 'text',
text: '获取时间失败: ' + error.message,
},
],
isError: true,
};
}
}
case 'get_timezone_offset': {
const { timezone } = args;
try {
const now = new Date();
// 获取指定时区的偏移量(分钟)
const utcDate = new Date(now.getTime() + (now.getTimezoneOffset() * 60000));
const targetDate = new Date(utcDate.toLocaleString('en-US', { timeZone: timezone }));
const offset = (targetDate.getTime() - utcDate.getTime()) / (1000 * 60);
const offsetHours = Math.floor(Math.abs(offset) / 60);
const offsetMinutes = Math.abs(offset) % 60;
const sign = offset >= 0 ? '+' : '-';
return {
content: [
{
type: 'text',
text: '时区: ' + timezone + '\nUTC偏移量: ' + sign + offsetHours + ':' + offsetMinutes.toString().padStart(2, '0'),
},
],
};
} catch (error) {
return {
content: [
{
type: 'text',
text: '获取时区信息失败: ' + error.message,
},
],
isError: true,
};
}
}
default:
return {
content: [
{
type: 'text',
text: '未知工具: ' + name,
},
],
isError: true,
};
}
});
// 启动服务器
async function main() {
const transport = new StdioServerTransport();
await server.connect(transport);
console.error('MCP时间服务器已启动');
}
main().catch((error) => {
console.error('服务器启动失败:', error);
process.exit(1);
});可以看到,主要实现了两个对外的接口,处理请求工具列表和响应工具调用。
接下来,改造原先的函数调用。
javascript
import { Client } from '@modelcontextprotocol/sdk/client/index.js';
import { StdioClientTransport } from '@modelcontextprotocol/sdk/client/stdio.js';
import OpenAI from 'openai';
import dotenv from 'dotenv';
// 加载环境变量
dotenv.config({ quiet: true });
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
baseURL: process.env.OPENAI_BASE_URL
});
// MCP 服务器配置
const mcpServerConfig = {
command: 'node',
args: ['./Part2.Tool/mcp-time-server.js'], // MCP 时间服务器脚本
env: {
'NODE_PATH': process.env.NODE_PATH
}
};
class MCPToolManager {
constructor() {
this.client = new Client({
name: 'mcp-time-client',
version: '1.0.0',
});
this.transport = null;
}
async connect() {
this.transport = new StdioClientTransport(mcpServerConfig);
await this.client.connect(this.transport);
console.log('已连接到MCP时间服务器');
}
async disconnect() {
if (this.transport) {
await this.transport.close();
console.log('已断开与MCP服务器的连接');
}
}
async getAvailableTools() {
const toolsResult = await this.client.listTools();
return toolsResult.tools;
}
async callTool(name, arguments_) {
const result = await this.client.callTool({
name,
arguments: arguments_,
});
return result;
}
}
// 测试消息
const messages = [
'现在几点钟',
'现在东京时间几点了?',
'请告诉我当前时间,用MCP工具'
];
async function run() {
const mcpManager = new MCPToolManager();
try {
console.log('=== MCP工具调用示例 ===');
// 连接到MCP服务器
await mcpManager.connect();
// 获取可用工具
const tools = await mcpManager.getAvailableTools();
console.log('可用MCP工具:', tools.map(t => t.name).join(', '));
for (let message of messages) {
console.log(`\n用户: ${message}`);
// 将MCP工具转换为OpenAI格式
const openaiTools = tools.map(tool => ({
type: "function",
function: {
name: tool.name,
description: tool.description,
parameters: tool.inputSchema
}
}));
// 使用OpenAI分析是否需要调用工具
const completion = await openai.chat.completions.create({
model: "qwen-max",
messages: [
{
role: 'system',
content: '你是一个有用的助手,可以使用MCP工具来获取准确的时间信息。请根据用户需求选择合适的工具。'
},
{ role: 'user', content: message }
],
tools: openaiTools,
tool_choice: "auto"
});
const messageResponse = completion.choices[0].message;
// 检查是否有工具调用
if (messageResponse.tool_calls) {
for (const toolCall of messageResponse.tool_calls) {
const { name, arguments: args } = toolCall.function;
console.log(`调用MCP工具: ${name}`);
try {
// 通过MCP调用工具
const toolResult = await mcpManager.callTool(name, JSON.parse(args));
// 将工具结果返回给模型
const finalResponse = await openai.chat.completions.create({
model: "qwen-max",
messages: [
{
role: 'system',
content: '你是一个有用的助手,可以使用MCP工具来获取准确的时间信息。'
},
{ role: 'user', content: message },
messageResponse,
{
role: 'tool',
content: JSON.stringify(toolResult.content),
tool_call_id: toolCall.id
}
]
});
console.log(`AI: ${finalResponse.choices[0].message.content}`);
} catch (error) {
console.error(`调用MCP工具时出错: ${error.message}`);
console.log(`AI: 抱歉,获取时间信息时遇到了问题。`);
}
}
} else {
console.log(`AI: ${messageResponse.content}`);
}
console.log('------------------');
}
} catch (error) {
console.error('MCP连接错误:', error);
} finally {
// 断开连接
await mcpManager.disconnect();
}
}
// 如果直接运行此文件
if (import.meta.url === `file://${process.argv[1]}`) {
run().catch(console.error);
}
export { MCPToolManager };运行结果:
=== MCP工具调用示例 ===
MCP时间服务器已启动
已连接到MCP时间服务器
可用MCP工具: get_current_time, get_timezone_offset
用户: 现在几点钟
调用MCP工具: get_current_time
AI: 当前Asia/Shanghai时间是: 19:36:42。请注意,这个时间是根据您询问时的情况给出的,实际时间可能会有所不同。
用户: 现在东京时间几点了?
调用MCP工具: get_current_time
AI: 当前东京时间是:2025年8月10日 20:36:45。请注意,这个时间是基于您询问时刻的数据,实际查看时请考虑可能存在的短暂延迟。
用户: 请告诉我当前时间,用MCP工具
调用MCP工具: get_current_time
AI: 看起来您提供的信息是关于调用MCP工具
get_current_time的结果。根据给出的数据,当前在时区Asia/Shanghai的时间为2025年8月10日 19点36分49秒。请注意,这个时间点实际上是在未来,可能是示例或测试数据。如果您需要获取实时准确的时间,请确保使用最新的API调用来获得正确的值。如果需要进一步的帮助或者有其他问题,请告诉我!
已断开与MCP服务器的连接
框架
在深入了解了LLM和工具调用后,现在让我们聚焦于Agent开发的核心------框架。我们将探讨两个在不同形态上开发框架:LangChain和Dify。这些框架将帮助我们快速构建、管理和扩展Agent的能力。
LangChain
LangChain is a framework for developing applications powered by large language models (LLMs).
LangChain 提供了一些开发应用所需的基础抽象和 LangChain 表达式语言。通过 LangChain,在开发时,开发能够更关注与业务逻辑,也不是 LLM 层的实现细节。
下面使用,LangChain 实现上面的记忆功能。
javascript
import dotenv from 'dotenv';
import { ChatOpenAI } from '@langchain/openai';
import { ConversationChain } from 'langchain/chains';
import { BufferMemory } from 'langchain/memory';
// 加载环境变量
dotenv.config({ quiet: true });
// 初始化 OpenAI 模型
const model = new ChatOpenAI({
model: "qwen-max",
temperature: 0,
openAIApiKey: process.env.OPENAI_API_KEY,
configuration: {
baseURL: process.env.OPENAI_BASE_URL
}
});
// 创建记忆管理器
const memory = new BufferMemory({
memoryKey: "history",
returnMessages: true
});
// 创建对话链
const chain = new ConversationChain({
llm: model,
memory: memory,
systemMessage: "你是一个聊天机器人,请准确回答我的问题。"
});
const message = [
'我是奥特曼',
'猜猜我是谁',
'你记得之前的你回答了什么吗?'
];
for (let i = 0; i < message.length; i++) {
const response = await chain.invoke({ input: message[i] });
console.log(response.response);
console.log('------------------');
}输出:
你好,奥特曼!很高兴见到你。作为来自M78星云的光之巨人,你一定有很多精彩的故事和经历想要分享吧。无论是对抗怪兽、保护地球还是传播和平与正义的信息,你的事迹都激励了无数人。有什么特别的任务或故事是你最近在关注的吗?或者,如果需要帮助解决什么问题,我也很乐意提供支持哦!
嘿,这个猜谜游戏听起来很有趣!不过,根据之前的对话,你刚刚提到你是奥特曼。如果你现在是在玩一个不同的角色或者想要我猜测另一个身份的话,请给我一些提示吧!比如,你可以告诉我这个角色的一些特征、他们来自哪里、做了什么特别的事情等信息。这样我就能更好地参与这个游戏了。
当然记得!在之前的对话中,我先是欢迎了自称是奥特曼的你,并表达了对你的敬意以及对你所做贡献的认可。接着,我询问了你是否有特别的故事或任务想要分享,或者是需要帮助解决什么问题。然后,在你提出了"猜猜我是谁"的游戏后,我回应说这个游戏很有趣,但基于我们之前的交流我知道你是奥特曼。同时我也表示如果这是另一个角色扮演游戏的话,我很乐意参与进来,并请求你能提供一些关于这个新身份的线索。希望这些信息准确反映了我们的对话内容。如果你有其他想法或者想继续玩这个游戏,请告诉我更多的细节吧!
可以看到,在这段代码里,模型功能和 memory 功能都被抽象,在使用时,只要简单的拼装:
javascript
const chain = new ConversationChain({
llm: model,
memory: memory,
systemMessage: "你是一个聊天机器人,请准确回答我的问题。"
});一个具有记忆功能的 Agent 便可以拿来用了。
接下来,我们使用 LangChain 实现一个 mini 版的 claude code。
要实现一个claude code ,需要一个能够读写文件的工具。

一个强大的编码 Agent 工具包,提供语义检索与编辑能力(MCP Server 与 Agno 集成)
- 🚀 Serena 是一款强大的编码 Agent 工具包,能够将 LLM 变成可直接在你代码库上工作的全功能 Agent。\ 与大多数工具不同,它不绑定特定 LLM、框架或界面,因此可以灵活使用。
- 🔧 Serena 提供 IDE 级别的语义代码检索与编辑工具,可在符号级别提取代码实体并利用关系结构。配合现有编码 Agent 时,可大幅提升(token)效率。
- 🆓 Serena 免费且开源,零成本增强你已有的大模型能力。
根据文档,在本地启动通过 sse 方式传输的Serena 的 MCP 服务。
bash
uvx --from git+https://github.com/oraios/serena serena start-mcp-server --transport sse --port 9121 --project /Users/lulala/code这样,一个强大的能够进行编码的 MCP 服务就搭建好了,接下来就是使用 langchain 接入 MCP。
javascript
// 先给出所需要的所有依赖
import {Client} from '@modelcontextprotocol/sdk/client/index.js';
import {SSEClientTransport} from '@modelcontextprotocol/sdk/client/sse.js';
import {loadMcpTools} from '@langchain/mcp-adapters';
import {createReactAgent} from '@langchain/langgraph/prebuilt';
import {ChatOpenAI} from '@langchain/openai';
import readline from 'readline';
import dotenv from 'dotenv';
dotenv.config({ quiet: true });使用 modelcontextprotocol 的 sdk 定义刚刚启动的 MCP 连接方式。
javascript
const initSseClient = async () => {
const baseUrl = new URL('http://localhost:9121/sse');
let client = new Client({
name: 'sse-client',
version: '1.0.0'
});
const sseTransport = new SSEClientTransport(baseUrl);
await client.connect(sseTransport);
return client;
};创建 Agent,这里 llm 选用更适合编程任务的 qwen3-coder-plus。接着,从 MCP Client 获取到所有工具类,作为 tools 传递给 agent。
javascript
const createAgent = async () => {
const model = new ChatOpenAI({
modelName: 'qwen3-coder-plus',
temperature: 0.7,
openAIApiKey: process.env.OPENAI_API_KEY,
configuration: {
baseURL: process.env.OPENAI_BASE_URL,
},
});
const stdioClient = await initSseClient();
const tools = await loadMcpTools('code-server', stdioClient);
const agent = createReactAgent({
llm: model,
tools
});
return { agent, stdioClient };
};reAct(Reasoning + Acting)是一套常用的 Agent 策略:给大模型解释了 ReAct 的三个阶段:思考(Thought)、行动(Action)、观察(Observation)。这里还多了一个暂停(Pause),其主要的目的就是停下来,这时执行流程就回到我们这里,执行相应的动作。当动作执行完毕,再把控制权返回给大模型。
latex
Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}常用的 Agent 策略还有\ Plan-and-Execute(先计划后执行)\ CrewAI / AutoGen「多 Agent 协作」
...
接下来,就是响应用户输入,调用 Agent
javascript
const processUserInput = async (agent, userInput) => {
try {
console.log('\n正在处理您的请求...\n');
const inputs = {
messages: [{ role: "user", content: userInput }],
};
// 真正执行
const stream = await agent.stream(inputs, { streamMode: "values", recursionLimit: 1000 });
for await (const { messages } of stream) {
console.log(messages[messages.length-1].content);
}
} catch (error) {
console.error('处理请求时出错:', error.message);
}
};这样,一个能完成简单任务编码 Agent 边完成了!
Dify
Dify 是一个开源的 LLM 应用开发平台,把「后端即服务(BaaS)+ LLMOps」做成了拖拽式脚手架。
一句话:不写代码,也能 3 分钟上线带知识库的聊天机器人、AI 工作流或 Agent。
核心亮点
- 可视化编排:Prompt、RAG、Agent、工作流全部拖拽搞定
- 模型即插即用:OpenAI、Claude、本地 Llama/Ollama 等 100+ 模型一键切换
- 企业级:API/SDK、权限、审计、多环境一键发布
- 完全开源,可自托管,也可直接用云版
对于程序员而言,LangChain 是工具,Dify 是产品 。Dify 通过可视化拖拽降低了门槛,却也在无形中为复杂需求套上了枷锁:当预设的节点无法满足业务时,你只能干瞪眼。而 LangChain 把控制权完全交还给代码,你可以像搭积木一样自由组合模块(模型、Retriever、Tool、Memory),用几行代码就能实现 Dify 里找不到的"骚操作"------比如自定义多步推理逻辑、动态切换模型、或者把 RAG 流程嵌进已有的微服务架构。说白了,程序员要的是"能改到底"的灵活性,而不是"看起来很快"的妥协。而且,使用代码还有一个好处,就是可以借助AI 工具辅助编程,效率也不慢。