一、爬虫目标
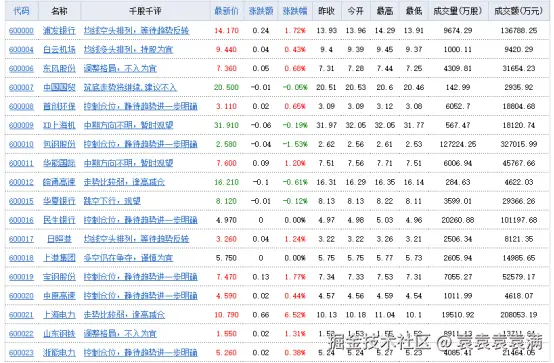
本次的爬虫目录是某财经网站的股票数据,获取代码、名称、评论、最新价、涨跌额、涨跌幅、昨日收盘、今日开盘、最高、最低、成交量(万股)、成交额(万元)字段:
二、准备工作
2.1 环境搭建
Python:3.10
编辑器:PyCharm
第三方模块,自行安装:
csharp
pip install requests # 网页数据爬取
pip install lxml # 提取网页数据
pip install pandas #写入Excel表格2.2 获取代理
为了保证可以安全快速的获取到数据,博主每次写爬虫代码的时候,都会使用巨量IP家的代理,无论是电商网站、热搜网站、视频图片网站等等,使用代理后都可以轻松拿下,并且新用户可以领取1000IP,接下来跟着博主一起来获取吧。
1、打开官网:巨量IP
2、创建账号
3、注册好了以后,参考说明文档:说明文档
4、通过爬虫去获取API接口的里面的代理IP(注意:下面URL换成自己的API链接)
python
import requests
import time
import random
def get_ip():
url = "这里放你自己的API链接"
while 1:
try:
r = requests.get(url, timeout=10)
except:
continue
ip = r.text.strip()
if '请求过于频繁' in ip:
print('IP请求频繁')
time.sleep(1)
continue
break
proxies = {
'https': '%s' % ip
}
return proxies
if __name__ == '__main__':
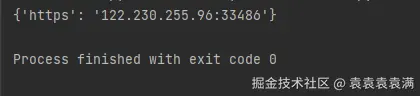
proxies = get_ip()
print(proxies)运行结果,可以看到返回了接口中的代理IP:
5、接下来我们写爬虫代理的时候就可以挂上代理IP去发送请求了,只需要将proxies当成参数传给requests.get函数去请求其他网址
python
requests.get(url, headers=headers, proxies=proxies) 三、爬虫实战
3.1 分析网站
3.1.2 翻页分析
第一页地址:
python
http://vip.stock.finance.sina.com.cn/q/go.php/vInvestConsult/kind/qgqp/index.phtml?t=sh_a&p=1第二页地址:
python
http://vip.stock.finance.sina.com.cn/q/go.php/vInvestConsult/kind/qgqp/index.phtml?t=sh_a&p=2第三页地址:
python
http://vip.stock.finance.sina.com.cn/q/go.php/vInvestConsult/kind/qgqp/index.phtml?t=sh_a&p=3我们可以看到每次翻页的时候,只有参数p的数字随着页码增加而增加,那么就可以通过程序来构造url链接。
3.1.2 数据分析
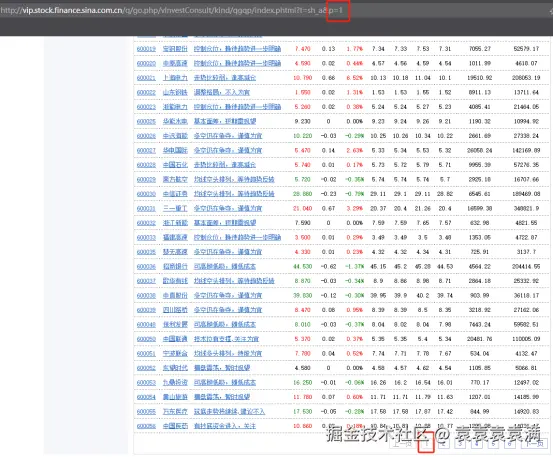
按下f12,在网页元素中可以看到数据都纯在table下,一行tr代表一行数据,td中为每一列数据的具体值:
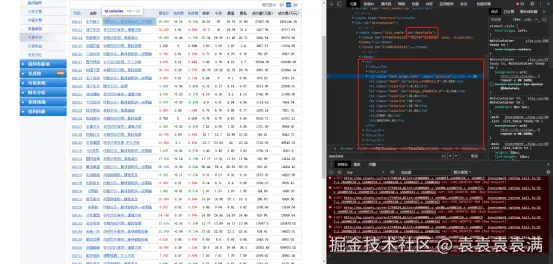
数据没问题接下来我们就可以开始写代码了!
3.2 导入模块
python
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为Elements对象
import pandas as pd # 用于将数据写入Excel文件
import time # 防止爬取过快可以睡眠一秒3.3 构造分页
通过for循环构造url链接,页码可以自行调整:
python
def main():
page_num = 6 # 页码
data_list = [] # 存储数据的列表
# 循环构造分页
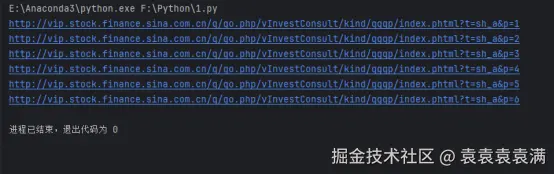
for i in range(1, page_num + 1):
url = f'http://vip.stock.finance.sina.com.cn/q/go.php/vInvestConsult/kind/qgqp/index.phtml?t=sh_a&p={i}'
print(url)运行结果:
3.4 携带代理IP发送请求
携带代理IP发送请求获取网页源代码,注意,下面代码get_ip()函数中的url需要看2.2节获取并添加代理IP链接:
python
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为Elements对象
import pandas as pd # 用于写入Excel文件
import time # 防止爬取过快可以睡眠一秒
def get_ip():
url = "这里放你自己的API链接"
while 1:
try:
r = requests.get(url, timeout=10)
except:
continue
ip = r.text.strip()
if '请求过于频繁' in ip:
print('IP请求频繁')
time.sleep(1)
continue
break
proxies = {
'https': '%s' % ip
}
return proxies
def get_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.5845.97 Safari/537.36 Core/1.116.537.400 QQBrowser/19.4.6561.400"
}
# 每一次访问都切换一次IP
proxies = get_ip()
response = requests.get(url, headers,proxies=proxies)
# 获取网页源码
html_str = response.text
return html_str
def main():
page_num = 1 # 页码
data_list = [] # 存储数据的列表
# 一、循环构造分页
for i in range(1, page_num + 1):
url = f'http://vip.stock.finance.sina.com.cn/q/go.php/vInvestConsult/kind/qgqp/index.phtml?t=sh_a&p={i}'
print(url)
# 二、携带代理IP发送请求
html_str = get_html(url)
print(html_str)
if __name__ == '__main__':
main()运行结果:
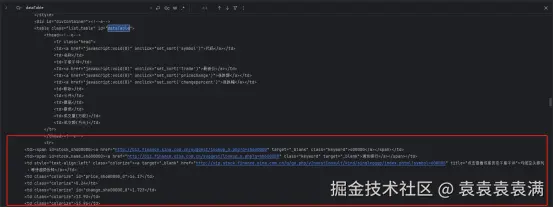
网页源码分析,可以看到正确给我们返回了表格数据,但是仔细看:没有了tbody标签包裹每行tr数据了,那么我们定位的时候就需要特别注意了。
3.5 解析提取数据
我们写一个get_data(data_list, html_str) 函数,传入空列表和网页源码,先测试一下,表格的行数对不对:
python
def get_data(data_list, html_str):
# 将网页源码转为'lxml.etree._Element'对象
etree_Element = etree.HTML(html_str)
print(type(etree_Element))
# 定位获取table表格下的每一行tr标签
tr_list = etree_Element.xpath('//table[@id="dataTable"]/tr')
print("tr的行数:",len(tr_list))运行结果返回,正确的行数说明我们的成功定位到了每一行数据:
python
<class 'lxml.etree._Element'>
tr的行数: 40遍历tr_list 获取到每一个tr对象,然后通过xpath定位到每一列数据,将数据写入data_list 列表即可:
python
def get_data(data_list, html_str):
# 将网页源码转为'lxml.etree._Element'对象
etree_Element = etree.HTML(html_str)
# print(type(etree_Element))
# 定位获取table表格下的每一行tr标签
tr_list = etree_Element.xpath('//table[@id="dataTable"]/tr')
# print("tr的行数:",len(tr_list))
for tr in tr_list:
code = tr.xpath('./td[1]/span/a/text()')[0]
name = tr.xpath('./td[2]/span/a/text()')[0]
comment = tr.xpath('./td[3]/a/text()')[0]
latest_price = tr.xpath('./td[4]/text()')[0]
rise_and_fall_amount = tr.xpath('./td[5]/text()')[0]
Chg = tr.xpath('./td[6]/text()')[0]
yesterday_closing = tr.xpath('./td[7]/text()')[0]
today_open = tr.xpath('./td[8]/text()')[0]
highest = tr.xpath('./td[9]/text()')[0]
minimum = tr.xpath('./td[10]/text()')[0]
turnover = tr.xpath('./td[11]/text()')[0]
transaction_volume = tr.xpath('./td[12]/text()')[0]
print({'代码': code, '名称': name, '千股千评': comment, '最新价': latest_price, '涨跌额': rise_and_fall_amount,
'涨跌幅': Chg, '昨日收盘': yesterday_closing, '今日开盘': today_open, '最高': highest, '最低': minimum,
'成交量(万股)': turnover, '成交额(万元)': transaction_volume})
data_list.append(
{'代码': code, '名称': name, '千股千评': comment, '最新价': latest_price, '涨跌额': rise_and_fall_amount,
'涨跌幅': Chg, '昨日收盘': yesterday_closing, '今日开盘': today_open, '最高': highest, '最低': minimum,
'成交量(万股)': turnover, '成交额(万元)': transaction_volume})运行结果,可以看到成功打印每一行数据:

3.6 保存数据
将获取到的数据写入Excel,当然大家也可以写入数据库:
python
def save(data_list):
"""写入Excel"""
df = pd.DataFrame(data_list)
df.drop_duplicates() # 删除重复数据
df.to_excel('财经股票数据.xlsx')3.7 完整代码
==免责声明:本文爬虫思路、相关技术和代码仅用于学习参考,对阅读本文后的进行爬虫行为的用户不承担任何法律责任:==
python
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为Elements对象
import pandas as pd # 用于写入Excel文件
import time # 防止爬取过快可以睡眠一秒
def get_ip():
url = "这里放你自己的API链接"
while 1:
try:
r = requests.get(url, timeout=10)
except:
continue
ip = r.text.strip()
if '请求过于频繁' in ip:
print('IP请求频繁')
time.sleep(1)
continue
break
proxies = {
'https': '%s' % ip
}
return proxies
def get_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.5845.97 Safari/537.36 Core/1.116.537.400 QQBrowser/19.4.6561.400"
}
# 每一次访问都切换一次IP
proxies = get_ip()
response = requests.get(url, headers,proxies=proxies)
html_str = response.text
return html_str
def get_data(data_list, html_str):
# 将网页源码转为'lxml.etree._Element'对象
etree_Element = etree.HTML(html_str)
# print(type(etree_Element))
# 定位获取table表格下的每一行tr标签
tr_list = etree_Element.xpath('//table[@id="dataTable"]/tr')
# print("tr的行数:",len(tr_list))
for tr in tr_list:
code = tr.xpath('./td[1]/span/a/text()')[0]
name = tr.xpath('./td[2]/span/a/text()')[0]
comment = tr.xpath('./td[3]/a/text()')[0]
latest_price = tr.xpath('./td[4]/text()')[0]
rise_and_fall_amount = tr.xpath('./td[5]/text()')[0]
Chg = tr.xpath('./td[6]/text()')[0]
yesterday_closing = tr.xpath('./td[7]/text()')[0]
today_open = tr.xpath('./td[8]/text()')[0]
highest = tr.xpath('./td[9]/text()')[0]
minimum = tr.xpath('./td[10]/text()')[0]
turnover = tr.xpath('./td[11]/text()')[0]
transaction_volume = tr.xpath('./td[12]/text()')[0]
print({'代码': code, '名称': name, '千股千评': comment, '最新价': latest_price, '涨跌额': rise_and_fall_amount,
'涨跌幅': Chg, '昨日收盘': yesterday_closing, '今日开盘': today_open, '最高': highest, '最低': minimum,
'成交量(万股)': turnover, '成交额(万元)': transaction_volume})
data_list.append(
{'代码': code, '名称': name, '千股千评': comment, '最新价': latest_price, '涨跌额': rise_and_fall_amount,
'涨跌幅': Chg, '昨日收盘': yesterday_closing, '今日开盘': today_open, '最高': highest, '最低': minimum,
'成交量(万股)': turnover, '成交额(万元)': transaction_volume})
def save(data_list):
"""写入Excel"""
df = pd.DataFrame(data_list)
df.drop_duplicates() # 删除重复数据
df.to_excel('财经股票数据.xlsx')
def main():
page_num = 6 # 页码
data_list = [] # 存储数据的列表
# 一、循环构造分页
for i in range(1, page_num + 1):
url = f'http://vip.stock.finance.sina.com.cn/q/go.php/vInvestConsult/kind/qgqp/index.phtml?t=sh_a&p={i}'
print(url)
# 二、携带代理IP发送请求
html_str = get_html(url)
# print(html_str)
# 三、解析提取数据
get_data(data_list, html_str)
# time.sleep(2) # 如果使用了代理IP可以关掉这行代码
# 四、保存数据
save(data_list)
if __name__ == '__main__':
main()3.8 结果展示
运行成功,并将数据写入excel:
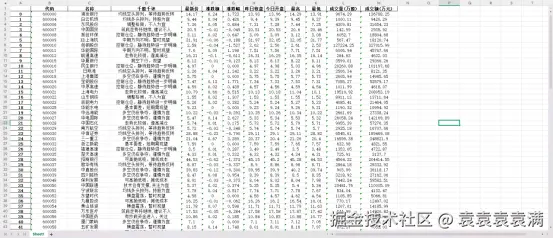
后续大家可以自行增加定时更新功能、ai自动分析功能,但是需要注意的是如果你想要每天或者每一小时高频率更新数据的话就必须要使用看2.2节获取代理了,接下来就自己分析股票数据啦。
四、代理推荐
博主用过无数代理了,长期使用的还是认为巨量IP最靠谱,无论是质量还是性价比都很高,巨量IP在采集领域的综合优势:
1、实际使用效果: 依托分布式服务器集群与千万级动态IP池,可实现高并发、低延迟采集,采集成功率超99%,适用于电商监控、金融风控、舆情分析等复杂场景。
2、性价比之王: 提供按时、按量、混合计费模式,兼顾灵活性与成本优化。经常看博主文章都小伙伴都知道,我编写爬虫代码的时候喜欢每次访问切换代理,所以用的最多的是不限量套餐 、隧道代理,博主自己对比下来发现巨量IP性价比最高。
3、品牌口碑: 服务10万+企业及个人用户,客户案例涵盖头部电商平台、金融科技公司等,稳定性与专业性获广泛认可。