一、GPT-5,终于降临了
2025年2月,Sam Altman说"再过几个月"。那时候的我们,以为这只是又一次画饼。
那时候,o3刚刚展示了惊人的推理能力。
那时候,我们还在对奥特曼的模型布局,嗤之以鼻。
ChatGPT4o、GPT4.5、GPT4.1、o3、o4-mini、o4-mini-high、o3 pro,这还不算完,每个模型还有3、4个小版本模型。
就好像,谁的模型多,谁更牛逼一样!!
那时候,Sam Altman又说了,即将发布的GPT-5是一个"统一模型",结合了ChatGPT4o的多模态、o3的深度推理、GPT4.5的多愁善感、GPT4.1独步武林的编码能力.....我擦,牛逼!
结果,今日凌晨,所有的等待都有了答案。
在无数个日夜的打磨之后,GPT-5,带着100万token的上下文、持久记忆、真正的多模态能力,重新定义了什么叫做AI。
OpenAI CEO Sam Altman在发布会上表示,GPT-5更智能、更快速、"更加实用",特别是在写作、编程和医疗保健等领域表现突出。这次发布不仅仅是一次常规升级,而是AI能力的一次质的飞跃。
二、产品版本与定位
1、🧠 GPT-5:统一智能系统
统一模型架构:GPT-5 集成了多个模型,自动根据任务复杂度选择最适合的模型进行处理。
多版本支持:包括标准版、迷你版(GPT-5-mini)、纳米版(GPT-5-nano)和专业版(GPT-5 Pro),满足不同用户的需求。
增强的推理能力:在数学、编程、视觉感知和健康等领域表现出色,超越了前代模型。
实时路由系统:根据用户输入的复杂度,自动选择合适的模型进行处理,无需用户手动切换。
2、🧩 GPT-5 Thinking:深度推理模式
GPT-5 Thinking 是 GPT-5 系列中的一个特定模式,专为处理复杂任务而设计。
多步推理:在生成回答前,进行更多的推理步骤,适用于需要深度分析的问题。
高准确性:在处理复杂问题时,能提供更准确和可靠的答案。
适用场景:适用于科学研究、复杂编程任务和高难度的逻辑推理等领域。
国内直接使用GPT-5
谷歌浏览器访问:www.nezhasoft.cloud
私信哪吒,备注体验ai,领取体验码。
还包含了GPT-5、GPT-5 Thinking、Claude Sonnet 4、Gemini 2.5 Pro、Grok4、DeepSeek R1 0528等模型。
三、核心技术创新
1、统一架构设计
GPT-5最大的创新在于其统一架构设计。与以往需要在不同专业模型之间切换不同,GPT-5将OpenAI在逻辑、思维链和多模态设计方面的进展统一到了一个系统中。这意味着用户不再需要纠结选择哪个模型,系统会自动根据任务需求选择最合适的处理方式。
GPT-5是一个统一系统,包含智能高效的模型来回答大多数问题,更深层的推理模型(GPT-5 thinking)处理更难的问题,以及实时路由器根据对话类型、复杂性、工具需求和用户明确意图快速决定使用哪个模型。
2、深度推理能力
GPT-5引入了更加深思熟虑的多步骤思考能力。它不仅仅是增加参数数量,而是结合了o1和o3模型的推理组件,如思维链、上下文基础、提示链和嵌入式规划逻辑。这使得GPT-5能够分步思考、修正结论并证明输出结果的合理性。
在评估中,GPT-5(带思考功能)的性能比OpenAI o3更好,同时输出token减少50-80%,涵盖视觉推理、智能编码和研究生级科学问题解决等能力。这种效率的提升意味着更快的响应速度和更低的计算成本。
3、多模态能力增强
更强的多模态性能意味着ChatGPT可以更准确地推理图像和其他非文本输入------无论是解释图表、总结演示文稿照片,还是回答关于图表的问题。GPT-5不仅能处理文本、图像和语音,还支持视频输入,实现了真正的全方位多模态交互。
GPT-4o引入了实时文本、图像和语音处理,但GPT-5进一步推进------允许跨不同类型输入进行更高级的交互。这种多模态能力的提升让AI助手能够更自然地理解和处理现实世界的复杂信息。
4、持久记忆功能
与GPT-4在会话之间会忘记所有内容不同,GPT-5能记住用户偏好、语气和过去的指令,使其真正具有适应性。这是一个突破性的功能,让AI助手能够提供真正个性化的服务。
GPT-5还引入了100万token的上下文窗口,远超GPT-4的12.8万token限制。这意味着GPT-5可以在长文档、密集代码库或整个用户会话中跟踪上下文而不失连贯性。
四、性能表现全面提升
1、基准测试成绩
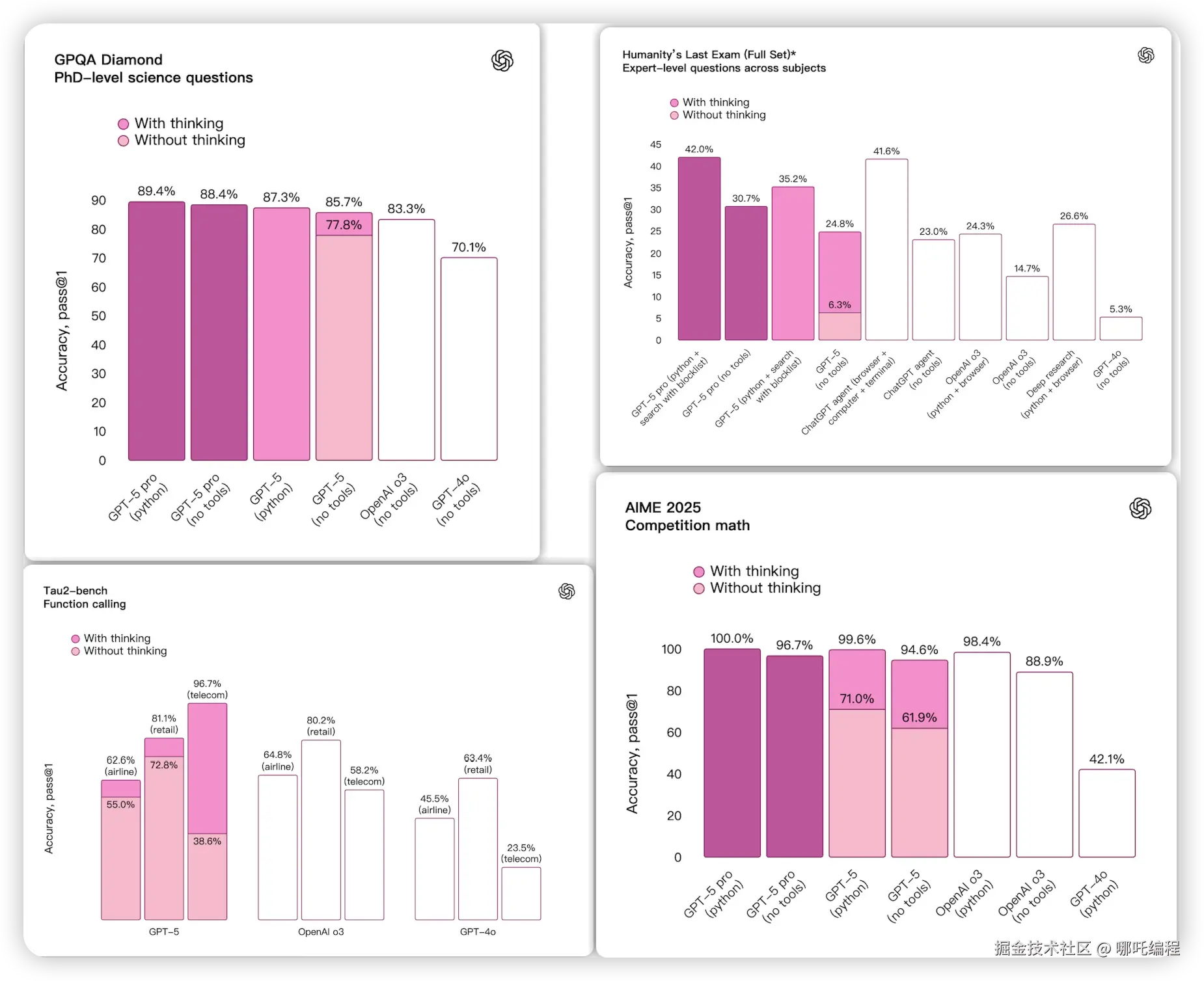
GPT-5在学术和人类评估基准测试中表现更加智能,特别是在数学、编码、视觉感知和健康方面。它在多个领域创造了新的最高水平:数学(AIME 2025无工具94.6%)、现实世界编码(SWE-bench Verified 74.9%,Aider Polyglot 88%)、多模态理解(MMMU 84.2%)和健康(HealthBench Hard 46.2%)。
2、幻觉问题改善
OpenAI表示GPT-5的幻觉率更低,这意味着模型较少编造答案。在启用网络搜索的情况下,GPT-5的回答包含事实错误的可能性比GPT-4o低约45%,当进行思考时,GPT-5的回答包含事实错误的可能性比OpenAI o3低约80%。
3、真实性与诚实度
除了提高事实准确性,GPT-5(带思考功能)更诚实地向用户传达其行动和能力------特别是对于不可能完成、规格不明确或缺少关键工具的任务。在测试中,当从多模态基准CharXiv的提示中删除所有图像时,OpenAI o3仍然在86.7%的情况下对不存在的图像给出自信的答案,相比之下GPT-5只有9%。
4、创意写作
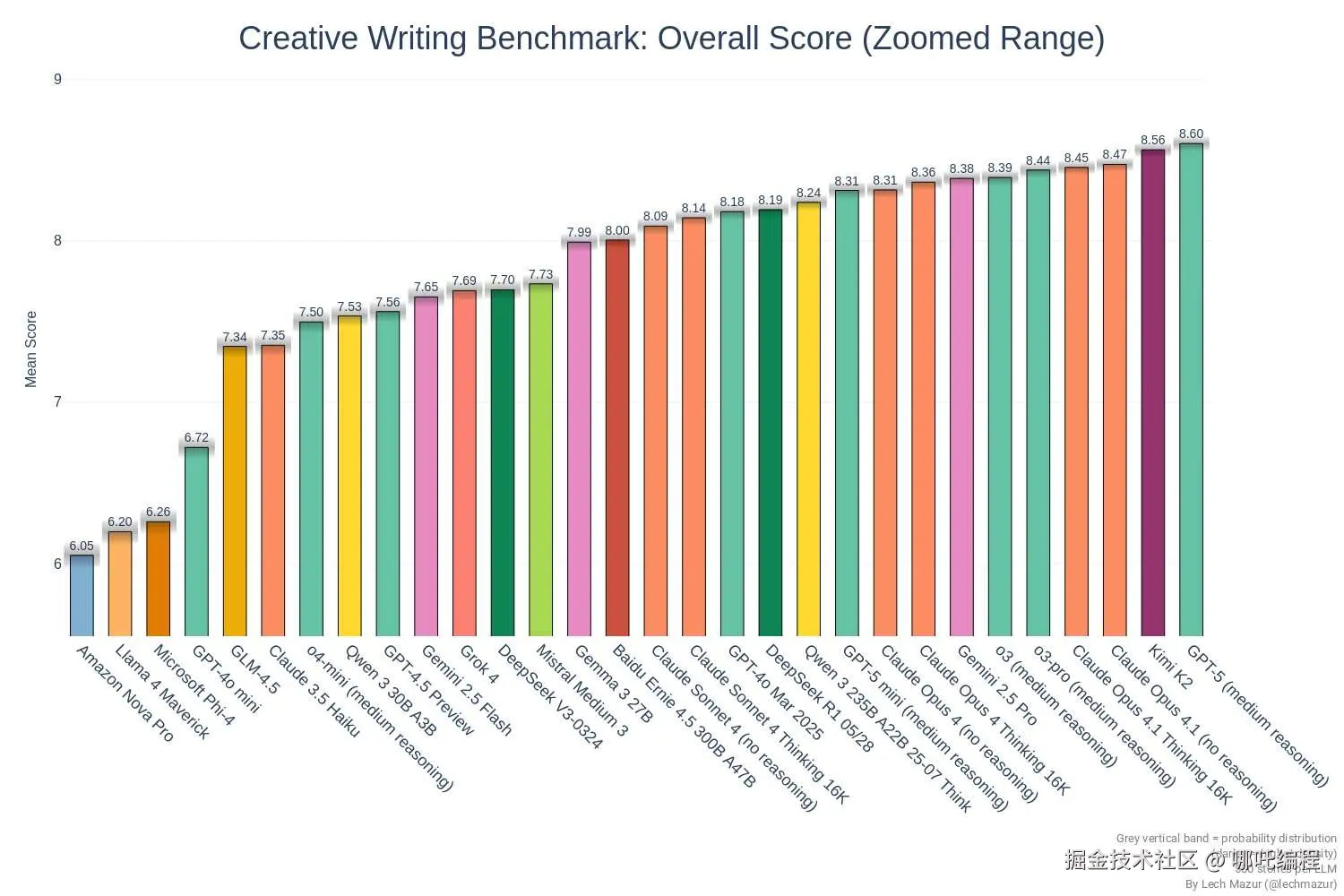
这是一个创意写作基准测试的评分排行榜,展示了各个AI模型在创意写作能力上的表现对比。
GPT-5(包括medium和no reasoning两个版本)以8.60的最高分傲居榜首,明显领先于其他所有模型。这个成绩不仅超越了自家的前代产品GPT-4系列(8.14-8.19分),更是大幅领先于其他竞争对手如Claude系列(最高8.45分)和Gemini系列(最高8.44分)。
这个评分差距意味着GPT-5在故事创作、诗歌写作、剧本编写等创意任务上具有更强的想象力、更好的文笔和更丰富的表达能力,标志着AI创意写作能力的又一次重大飞跃。
5、科研
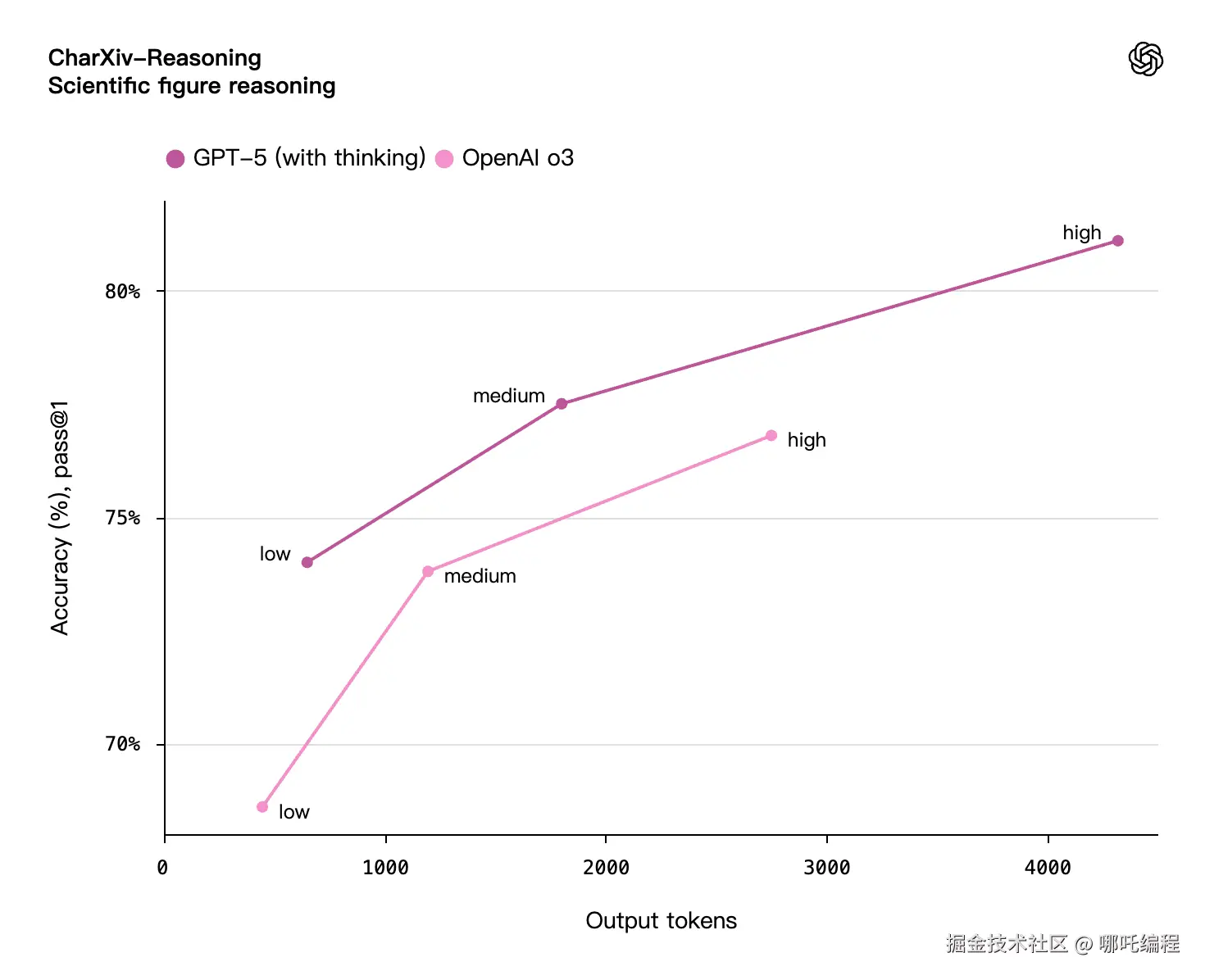
这是一个科学图表推理测试(CharXiv-Reasoning)的性能对比图,专门评估AI模型理解和分析科学图表的能力。
图中展示了GPT-5(带思考功能)与OpenAI o3两个模型在不同输出长度下的准确率表现。横轴表示输出的token数量(可理解为回答的详细程度),纵轴表示准确率。
GPT-5展现出惊人的性能优势:
- 在低难度任务中,即使输出很短(约500个token),GPT-5就能达到74%的准确率
- 随着允许输出更多内容,GPT-5的表现稳步提升,在中等难度达到77%,高难度突破81%
- 这种"思考"功能让GPT-5能够通过更详细的推理过程得出更准确的答案
相比之下,OpenAI o3虽然也表现不错,但整体低于GPT-5约5-6个百分点。特别是在需要深度推理的高难度任务上,GPT-5的优势更加明显。
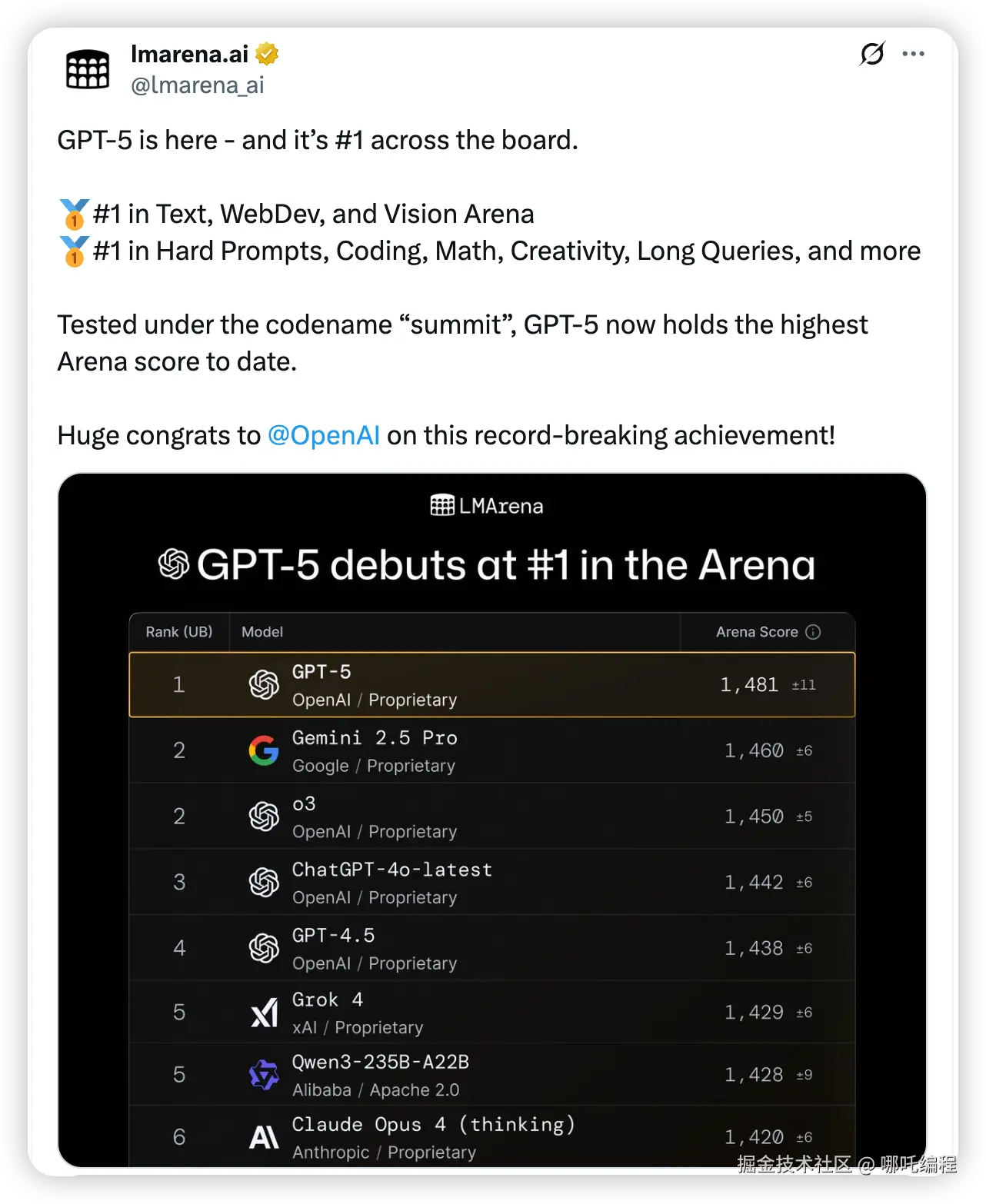
6、大语言模型竞技场
GPT-5以1,481的Arena Score荣登榜首,这是该平台历史最高分!它在测试时使用了代号"summit"(巅峰),完美诠释了其性能。 具体来看,GPT-5在全方位碾压竞争对手:
🥇 在文本处理、网页开发和视觉理解领域均排名第一
🏆 在困难提示、编程、数学、创意写作、长文本查询等多个维度都是冠军
从分数差距看,GPT-5领先第二名的Gemini 2.5 Pro整整21分,比自家的o3模型高出31分。更令人印象深刻的是,OpenAI包揽了前5名中的4个位置(GPT-5、o3、ChatGPT-4o-latest、GPT-4.5),展现了绝对的技术统治力。
五、满血GPT-5
1、全新UI设计
2、GPT-5
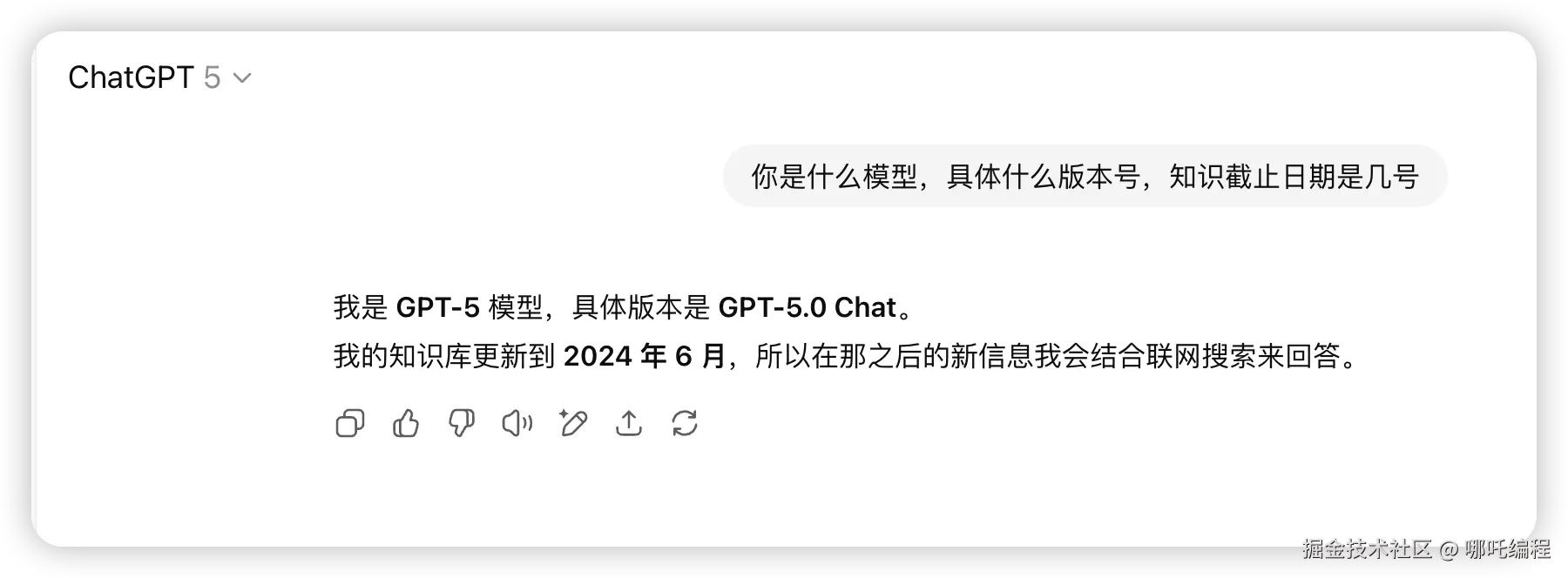
你是什么模型,具体什么版本号,知识截止日期是几号
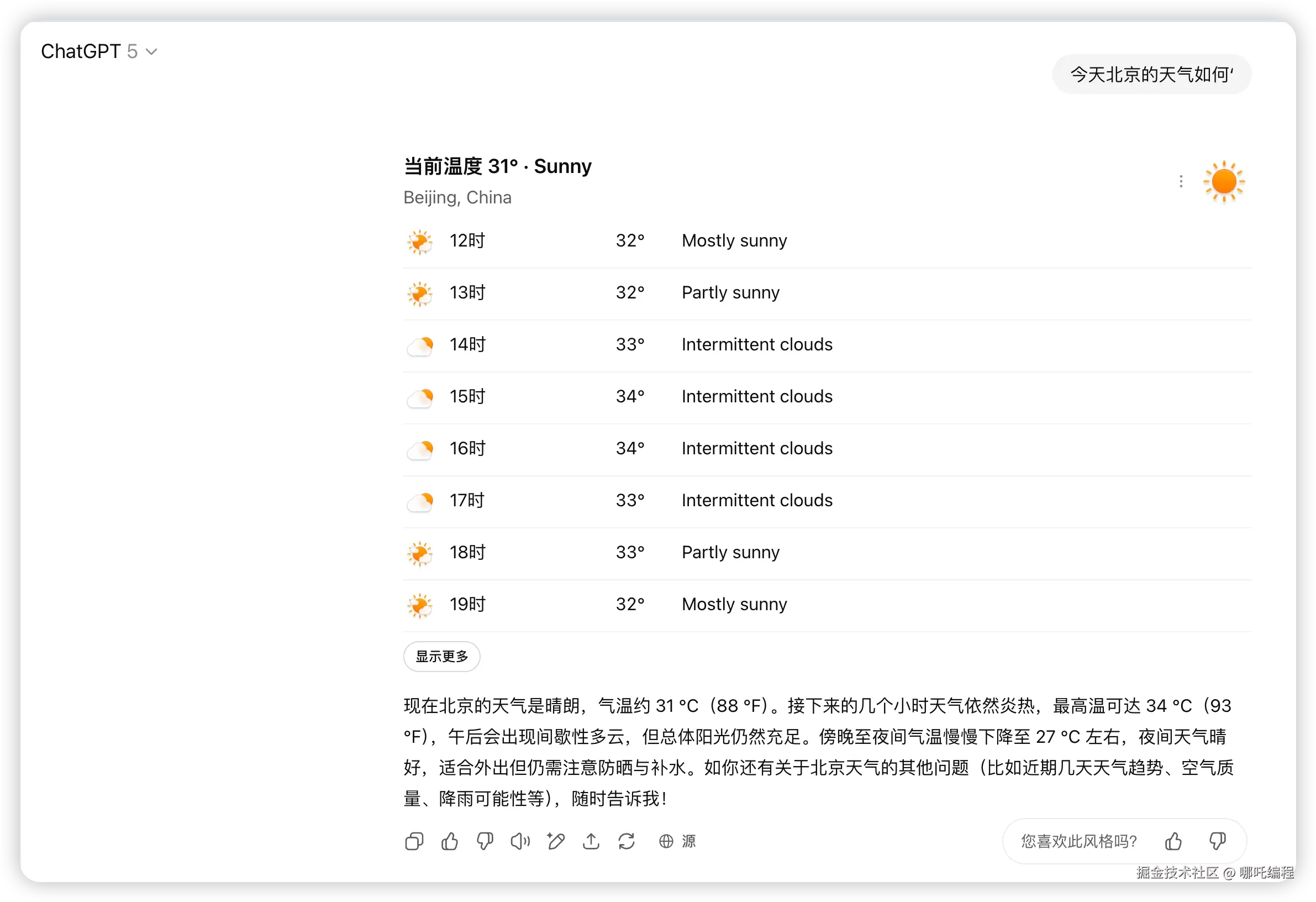
3、联网实时查询
4、写作
全国一卷作文题目:"民族魂"
材料内容:
- "他想要给孩子们唱上一段,可是心里直翻腾,开不了口。" ------老舍《鼓书艺人》
- "假如我是一只鸟,我也应该用嘶哑的喉咙歌唱" ------艾青《我爱这土地》
- "我要以带血的手和你们一一拥抱,因为一个民族已经起来" ------穆旦《赞美》
写作要求: 以上材料引发了你怎样的联想和思考?请写一篇文章。要求选准角度,确定立意,明确文体,自拟标题;不要套作,不得抄袭;不得泄露个人信息;不少于800字。

5、编程
问一道经典的很复杂的华为OD算法题。
作为程序员,我个人觉得GPT-5的编程能力确实提升明显,之前GPT编程太弱了,终于补齐了GPT最后一块短板!

GPT-5还会友好的提示用户,是否还要进行后续的操作,上下文超长。

6、识别图片
openai发布最新模型GPT-5,分析图片内容,总结下,1000字,通俗易懂,中文

7、上传文件
根据文档内容,总结一份springboot的学术论文大纲,3000字,中文
