数据库核心语法与实战案例详解
一、多表连接(JOIN)
1. 连接类型对比
| 连接类型 | 作用 | 示例 |
|---|---|---|
| INNER JOIN | 只返回两表匹配的行 | SELECT u.name, o.order_id FROM users u INNER JOIN orders o ON u.id = o.user_id |
| LEFT JOIN | 返回左表所有行 + 右表匹配行(不匹配时右表字段为NULL) | SELECT u.name, o.order_id FROM users u LEFT JOIN orders o ON u.id = o.user_id |
| RIGHT JOIN | 返回右表所有行 + 左表匹配行(不匹配时左表字段为NULL) | SELECT u.name, o.order_id FROM users u RIGHT JOIN orders o ON u.id = o.user_id |
| FULL JOIN | 返回两表所有行(MySQL不支持,可用UNION模拟) | SELECT u.name, o.order_id FROM users u LEFT JOIN orders o ON u.id = o.user_id UNION SELECT u.name, o.order_id FROM users u RIGHT JOIN orders o ON u.id = o.user_id WHERE u.id IS NULL |
2. 性能优化技巧
sql
-- 使用EXISTS替代JOIN(当只需要判断存在性时)
SELECT u.name FROM users u
WHERE EXISTS (SELECT 1 FROM orders o WHERE o.user_id = u.id);
-- 小表驱动大表(MySQL优化器会自动处理,但可显式控制)
SELECT /*+ STRAIGHT_JOIN */ u.name, o.order_id
FROM small_table u JOIN large_table o ON u.id = o.user_id;二、聚合函数与GROUP BY高级用法
1. 常用聚合函数
sql
-- 基础聚合
SELECT
COUNT(*) AS user_count,
AVG(salary) AS avg_salary,
MAX(age) AS max_age
FROM employees;
-- GROUP BY多字段分组
SELECT
department,
gender,
COUNT(*) AS count
FROM employees
GROUP BY department, gender;2. HAVING过滤分组
sql
-- 筛选平均薪资>10000的部门
SELECT
department,
AVG(salary) AS avg_salary
FROM employees
GROUP BY department
HAVING AVG(salary) > 10000;3. ROLLUP与CUBE(多维分析)
sql
-- ROLLUP层级聚合(MySQL支持)
SELECT
department,
gender,
COUNT(*) AS count
FROM employees
GROUP BY department, gender WITH ROLLUP;
-- 输出示例:
-- IT,Male,50
-- IT,Female,30
-- IT,NULL,80 <- 部门小计
-- NULL,NULL,200 <- 总计三、窗口函数
1. 核心函数对比
| 函数 | 作用 | 示例 |
|---|---|---|
| ROW_NUMBER() | 唯一序号(相同值不同排名) | SELECT name, salary, ROW_NUMBER() OVER(ORDER BY salary DESC) AS rank FROM employees |
| RANK() | 并列排名会跳过后续序号(如1,2,2,4) | SELECT name, salary, RANK() OVER(ORDER BY salary DESC) AS rank FROM employees |
| DENSE_RANK() | 并列排名不跳号(如1,2,2,3) | SELECT name, salary, DENSE_RANK() OVER(ORDER BY salary DESC) AS rank FROM employees |
| LAG()/LEAD() | 访问当前行之前/之后的行 | SELECT date, revenue, LAG(revenue,1) OVER(ORDER BY date) AS prev_revenue FROM sales |
2. 实战案例:查询第N高薪水
sql
-- 查询第3高薪水(DENSE_RANK版)
SELECT DISTINCT salary
FROM (
SELECT
salary,
DENSE_RANK() OVER(ORDER BY salary DESC) AS rnk
FROM employees
) t
WHERE rnk = 3;四、递归查询(WITH RECURSIVE)
1. 组织结构树查询
sql
-- 查询ID=5的员工及其所有下属
WITH RECURSIVE emp_tree AS (
-- 基础查询(锚成员)
SELECT id, name, manager_id
FROM employees
WHERE id = 5
UNION ALL
-- 递归查询(递归成员)
SELECT e.id, e.name, e.manager_id
FROM employees e
JOIN emp_tree et ON e.manager_id = et.id
)
SELECT * FROM emp_tree;2. 路径枚举
sql
-- 查询从员工到CEO的完整汇报路径
WITH RECURSIVE emp_path AS (
SELECT id, name, manager_id, name AS path
FROM employees
WHERE id = 10 -- 起始员工ID
UNION ALL
SELECT e.id, e.name, e.manager_id,
CONCAT(ep.path, ' -> ', e.name)
FROM employees e
JOIN emp_path ep ON e.id = ep.manager_id
)
SELECT * FROM emp_path;五、行列转换
1. CASE WHEN实现
sql
-- 将行转为列(每月销售额转列)
SELECT
product_id,
SUM(CASE WHEN month = '2023-01' THEN amount ELSE 0 END) AS jan_amount,
SUM(CASE WHEN month = '2023-02' THEN amount ELSE 0 END) AS feb_amount
FROM sales
GROUP BY product_id;2. PIVOT(SQL Server/Oracle支持)
sql
-- SQL Server语法
SELECT *
FROM (
SELECT product_id, month, amount
FROM sales
) src
PIVOT (
SUM(amount)
FOR month IN ([2023-01], [2023-02])
) pvt;六、连续登录用户判断
1. LAG/LEAD方案
sql
-- 找出连续3天登录的用户
WITH login_dates AS (
SELECT
user_id,
login_date,
LAG(login_date, 2) OVER(PARTITION BY user_id ORDER BY login_date) AS prev_date
FROM user_logins
)
SELECT DISTINCT user_id
FROM login_dates
WHERE DATEDIFF(login_date, prev_date) = 2; -- 日期差正好2天(3个连续日期)2. 分组标识法(通用方案)
sql
-- 通过日期差生成分组标识
WITH login_groups AS (
SELECT
user_id,
login_date,
DATE_SUB(login_date, INTERVAL ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY login_date) DAY) AS grp
FROM user_logins
)
SELECT
user_id,
MIN(login_date) AS start_date,
MAX(login_date) AS end_date,
COUNT(*) AS days
FROM login_groups
GROUP BY user_id, grp
HAVING COUNT(*) >= 3; -- 连续3天以上总结对比表
| 技术点 | 核心要点 | 典型应用场景 |
|---|---|---|
| 多表连接 | 根据关联键匹配数据,LEFT JOIN保留左表全量 | 订单-用户信息关联查询 |
| 窗口函数 | 不减少原表行数,在OVER()中定义计算窗口 | 排名、同比/环比计算 |
| 递归查询 | WITH RECURSIVE实现树形结构遍历 | 组织架构、评论层级查询 |
| 行列转换 | CASE WHEN或PIVOT重组数据布局 | 报表展示、交叉分析 |
| 连续登录判断 | 用日期差值或LAG/LEAD识别连续性 | 用户活跃度分析、营销活动效果统计 |
数据库设计与模型转换详解
一、三大范式深度解析
1. 范式对比与取舍
| 范式级别 | 核心要求 | 反范式设计场景 | 案例对比 |
|---|---|---|---|
| 1NF | 列不可再分(原子性),无重复组 | 需要JSON存储非结构化数据 | 范式设计 : users(id, name, address_street, address_city) 反范式 : users(id, name, address_json)(存储{"street":"Main St","city":"NY"}) |
| 2NF | 满足1NF + 非主键字段完全依赖主键(消除部分依赖) | 高频查询需要跨表JOIN时 | 范式设计 : orders(id, user_id, product_id) + products(id, name) 反范式 : orders(id, user_id, product_name)(直接冗余产品名称) |
| 3NF | 满足2NF + 非主键字段间无传递依赖(消除冗余) | 实时分析系统需要宽表 | 范式设计 : employees(id, dept_id) + departments(id, name) 反范式 : employees(id, dept_name) |
性能取舍原则:
-
读多写少:适当反范式减少JOIN(如电商商品详情页)
-
写多读少:严格范式保证一致性(如银行交易系统)
2. 宽表设计场景
实时分析系统案例:
sql
-- 范式设计(需要多表JOIN)
SELECT
o.order_id,
u.name,
p.product_name,
SUM(oi.quantity * oi.price) AS total
FROM orders o
JOIN users u ON o.user_id = u.id
JOIN order_items oi ON o.id = oi.order_id
JOIN products p ON oi.product_id = p.id
GROUP BY o.order_id, u.name, p.product_name;
-- 宽表设计(预计算+冗余)
CREATE TABLE order_analytics (
order_id INT,
user_name VARCHAR(100),
product_name VARCHAR(100),
total DECIMAL(10,2), -- 预计算存储
PRIMARY KEY (order_id)
);优势 :查询性能提升10倍+ 代价:数据更新需同步维护宽表(可通过触发器或CDC实现)
二、ER模型到物理模型
1. 关系识别与实现
| 关系类型 | ER模型表示 | 物理模型实现方案 | 示例 |
|---|---|---|---|
| 1:1 | 直线连接两实体 | 主键互为主外键,或合并为单表 | users(id PK, passport_id FK UNIQUE) + passports(id PK, user_id FK UNIQUE) |
| 1:N | 箭头指向"1"方 | "N"方表添加外键 | departments(id PK) + employees(id PK, dept_id FK) |
| M:N | 菱形关联实体 | 新增关联表,包含双方主键 | students(id PK) + courses(id PK) + enrollments(student_id FK, course_id FK, grade) |
M:N关系进阶设计:
sql
-- 带属性的关联表
CREATE TABLE user_roles (
user_id INT,
role_id INT,
assigned_at TIMESTAMP, -- 关联属性
PRIMARY KEY (user_id, role_id),
FOREIGN KEY (user_id) REFERENCES users(id),
FOREIGN KEY (role_id) REFERENCES roles(id)
);2. 继承关系实现方案
| 方案 | 优点 | 缺点 | 适用场景 | SQL示例 |
|---|---|---|---|---|
| 单表继承 | 查询简单,无需JOIN | 存在大量NULL字段 | 子类差异小的场景 | vehicles(id, type, car_wheel_count, truck_load_capacity)(type标识子类) |
| 多表继承 | 无冗余字段 | 查询需UNION ALL | 子类差异大的场景 | cars(id, wheel_count) + trucks(id, load_capacity) + vehicles(id, common_attrs) |
| JOIN继承 | 结构清晰 | 性能较差 | 需要多态查询的场景 | vehicles(id, type) + cars(vehicle_id FK, wheel_count) + trucks(vehicle_id FK, load_capacity) |
单表继承示例:
sql
-- 所有车辆类型存一张表
CREATE TABLE vehicles (
id INT PRIMARY KEY,
type ENUM('car', 'truck'), -- 鉴别字段
license_plate VARCHAR(20),
-- 公共字段
manufacturer VARCHAR(50),
-- 汽车专属字段
seat_count INT NULL,
-- 卡车专属字段
max_load_kg DECIMAL(10,2) NULL,
CHECK (
(type = 'car' AND seat_count IS NOT NULL) OR
(type = 'truck' AND max_load_kg IS NOT NULL)
);JOIN继承示例:
sql
-- 基础表
CREATE TABLE vehicles (
id INT PRIMARY KEY,
type VARCHAR(20),
license_plate VARCHAR(20)
);
-- 子类表
CREATE TABLE cars (
vehicle_id INT PRIMARY KEY,
seat_count INT,
FOREIGN KEY (vehicle_id) REFERENCES vehicles(id)
);
-- 多态查询
SELECT
v.*,
c.seat_count,
t.max_load_kg
FROM vehicles v
LEFT JOIN cars c ON v.id = c.vehicle_id
LEFT JOIN trucks t ON v.id = t.vehicle_id;三、实战建议
-
范式选择
-
OLTP系统:优先3NF(如订单系统)
-
OLAP系统:采用宽表(如数据仓库)
-
-
继承方案选型
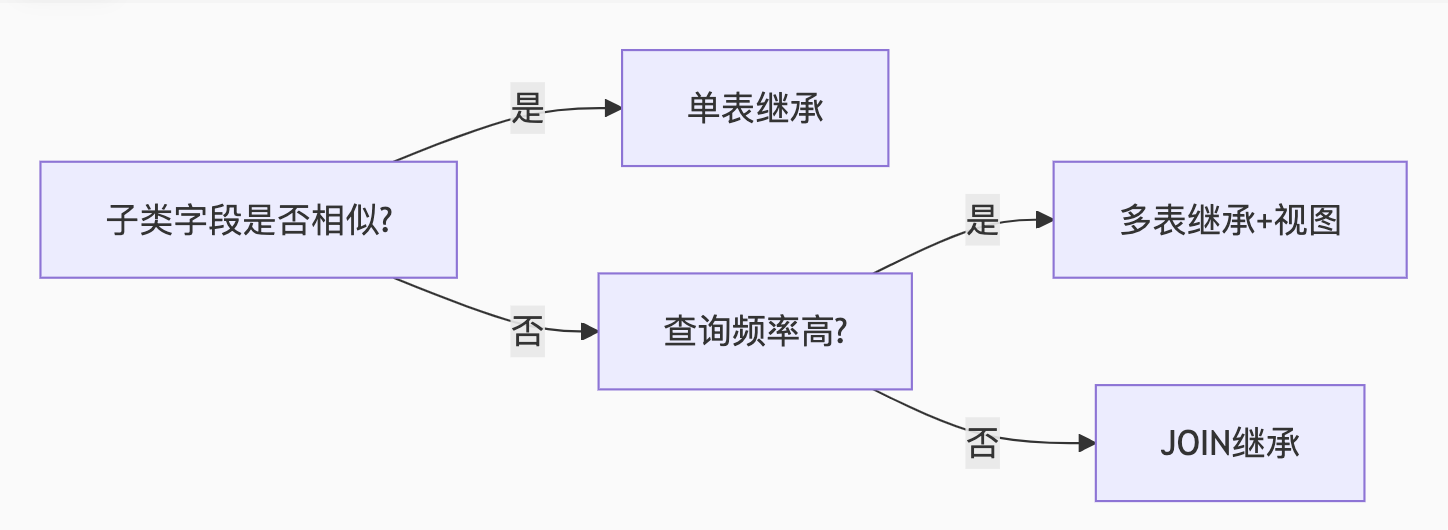
-
ER设计工具
-
MySQL Workbench(可视化建模)
-
Navicat(支持正向/逆向工程)
-
索引原理深度解析与实战案例
一、B+树为什么是数据库索引的标准结构?
1. 与Hash/B树的对比
| 结构 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Hash | O(1)查询速度 | 无法范围查询 不支持排序 | 内存表/等值查询(如Redis) |
| B树 | 数据可存在非叶子节点 | 节点大小固定导致树更高 范围查询效率低于B+树 | 文件系统 |
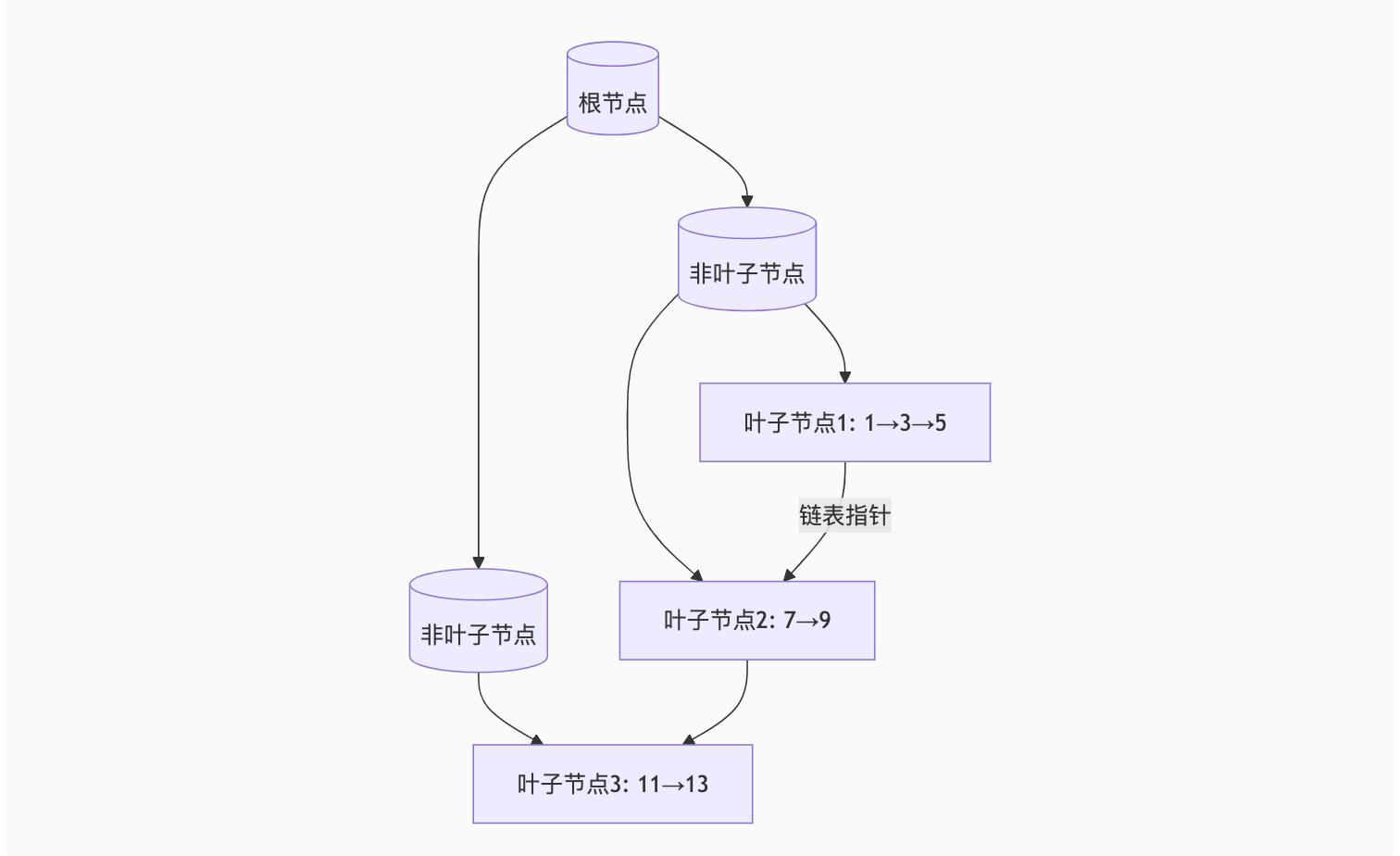
| B+树 | 叶子节点链表结构适合范围查询 树高更低(3-4层可存千万数据) | 插入需维护节点平衡 | 99%的数据库索引 |
B+树可视化:
2. B+树在MySQL中的实现
-
InnoDB默认索引高度:3层可支持约2000万数据(假设每页16KB,主键8B,指针6B)
sql16KB / (8B + 6B) ≈ 1170 条目/页 1170^3 ≈ 1600万行
二、聚簇索引 vs 非聚簇索引
1. 核心区别
| 特性 | 聚簇索引(InnoDB主键) | 非聚簇索引(二级索引) |
|---|---|---|
| 数据存储 | 叶子节点存储完整行数据 | 叶子节点存储主键值 |
| 索引数量 | 每表只能有一个 | 每表可建多个 |
| 查询速度 | 主键查询极快 | 需回表查询(查到主键后再查聚簇索引) |
| 典型场景 | 主键查询、范围查询 | WHERE条件非主键列 |
2. 物理存储对比
sql
-- 表结构
CREATE TABLE users (
id INT PRIMARY KEY, -- 聚簇索引
name VARCHAR(100),
age INT,
INDEX idx_age (age) -- 非聚簇索引
);
-- 存储示意
聚簇索引叶子节点: [id:1, name:"Alice", age:25]
非聚簇索引叶子节点: [age:25, pk:1] → 需回表查id=1的记录3. 性能影响案例
sql
-- 慢查询(回表)
SELECT * FROM users WHERE age > 20; -- 要查两次索引
-- 优化方案1:覆盖索引
SELECT id, age FROM users WHERE age > 20; -- 只需查非聚簇索引
-- 优化方案2:索引合并
ALTER TABLE users ADD INDEX idx_age_name (age, name);
SELECT name, age FROM users WHERE age > 20; -- 覆盖索引三、覆盖索引优化技巧
1. 什么是覆盖索引?
定义 :查询的所有字段都包含在索引中,无需回表
效果:性能可提升5-10倍
2. 实战案例
场景:查询用户姓名和城市
sql
-- 原始表(低效)
CREATE TABLE customers (
id INT PRIMARY KEY,
name VARCHAR(100),
city VARCHAR(100),
INDEX idx_city (city)
);
-- 查询需回表
EXPLAIN SELECT name, city FROM customers WHERE city = 'Beijing';
-- 结果:Using index condition; Using filesort
-- 优化方案:创建覆盖索引
ALTER TABLE customers ADD INDEX idx_city_name (city, name);
EXPLAIN SELECT name, city FROM customers WHERE city = 'Beijing';
-- 结果:Using index3. 最左前缀原则
sql
-- 复合索引 (a,b,c) 能优化的查询:
WHERE a = ?
WHERE a = ? AND b = ?
WHERE a = ? AND b = ? AND c = ?
-- 不能优化的查询:
WHERE b = ?
WHERE c = ?
WHERE a = ? AND c = ? -- 只能用到a列索引4. 索引选择策略
sql
-- 优先选择高区分度列
CREATE INDEX idx_good ON users(age); -- 年龄区分度低(0-100)
CREATE INDEX idx_better ON users(email); -- 邮箱唯一性高
-- 字符串前缀索引(减少索引大小)
CREATE INDEX idx_name ON users(name(10)); -- 只索引前10字符四、索引失效的雷区
1. 常见失效场景
sql
-- 1. 对索引列计算
SELECT * FROM users WHERE YEAR(create_time) = 2023; -- 失效
-- 改为:
SELECT * FROM users WHERE create_time BETWEEN '2023-01-01' AND '2023-12-31';
-- 2. 隐式类型转换
SELECT * FROM users WHERE phone = 13800138000; -- phone是varchar类型
-- 改为:
SELECT * FROM users WHERE phone = '13800138000';
-- 3. 前导通配符
SELECT * FROM users WHERE name LIKE '%John%'; -- 失效
-- 可改用(仍不理想):
SELECT * FROM users WHERE name LIKE 'John%';2. 强制索引提示
sql
-- 优化器可能选错索引时强制指定
SELECT * FROM users FORCE INDEX(idx_age) WHERE age BETWEEN 10 AND 20;五、高级索引策略
1. 索引下推(ICP)
sql
-- MySQL 5.6+ 特性:在存储引擎层过滤数据
CREATE INDEX idx_age_name ON users(age, name);
-- 旧版本:先查age>20的所有id,再回表过滤name
-- 启用ICP后:在索引内直接过滤age>20 AND name LIKE 'A%'
SELECT * FROM users WHERE age > 20 AND name LIKE 'A%';2. 自适应哈希索引
-
InnoDB自动为频繁访问的索引页建立哈希索引
-
查看状态:
SHOW ENGINE INNODB STATUS的HASH ADAPTIVE部分
总结对比表
| 知识点 | 核心要点 | 最佳实践 |
|---|---|---|
| B+树选择 | 适合磁盘IO的批量读取,支持高效范围查询 | 默认使用,无需手动选择 |
| 聚簇索引 | 主键即数据文件,避免二次查找 | 主键尽量短(建议自增INT/BIGINT) |
| 覆盖索引 | 避免回表,极大提升性能 | SELECT字段尽量与索引匹配 |
| 索引失效 | 函数操作、类型转换、前导%模糊查询 | 用EXPLAIN分析执行计划 |
索引失效场景案例详解(附解决方案)
一、索引失效的根本原因
核心原理 :索引失效的本质是 数据库优化器无法有效利用索引的有序性。当SQL写法导致无法按索引顺序检索时,优化器会放弃使用索引。
二、7大经典失效场景与解决方案
1. 对索引列使用函数或计算
sql
-- 失效案例(使用YEAR函数)
SELECT * FROM orders WHERE YEAR(create_time) = 2023;
-- 优化方案:改为范围查询
SELECT * FROM orders
WHERE create_time BETWEEN '2023-01-01 00:00:00' AND '2023-12-31 23:59:59';
-- 执行计划对比
EXPLAIN SELECT ... WHERE YEAR(create_time) = 2023; -- type: ALL(全表扫描)
EXPLAIN SELECT ... WHERE create_time BETWEEN ...; -- type: range(索引生效)原理: 索引存储的是原始值,对列计算后无法匹配索引结构。
2. 隐式类型转换
sql
-- 失效案例(phone是varchar但传入数字)
SELECT * FROM users WHERE phone = 13800138000;
-- 优化方案:保持类型一致
SELECT * FROM users WHERE phone = '13800138000';
-- 验证方法(查看实际执行的SQL)
SHOW WARNINGS; -- 可能显示:'CONVERT(phone USING utf8mb4) = 13800138000'常见陷阱:
-
字符串字段与数字比较
-
字符集不匹配(如utf8与utf8mb4)
3. 前导通配符模糊查询
sql
-- 失效案例(前导%)
SELECT * FROM products WHERE name LIKE '%手机%';
-- 优化方案1:使用后缀匹配(需结合业务)
SELECT * FROM products WHERE name LIKE '苹果%';
-- 优化方案2:全文索引(MySQL 5.6+)
ALTER TABLE products ADD FULLTEXT INDEX ft_idx_name(name);
SELECT * FROM products WHERE MATCH(name) AGAINST('+手机' IN BOOLEAN MODE);
特殊技巧: 对LIKE '%xxx'(只有后缀通配符),可考虑 逆序存储+索引:
ALTER TABLE products ADD COLUMN name_reverse VARCHAR(255);
UPDATE products SET name_reverse = REVERSE(name);
CREATE INDEX idx_name_reverse ON products(name_reverse);
SELECT * FROM products WHERE name_reverse LIKE REVERSE('%手机');4. 使用OR条件(非全覆盖)
sql
-- 失效案例(age有索引,gender无索引)
SELECT * FROM employees WHERE age = 25 OR gender = 'F';
-- 优化方案1:改用UNION ALL
SELECT * FROM employees WHERE age = 25
UNION ALL
SELECT * FROM employees WHERE gender = 'F' AND age != 25; -- 避免重复
-- 优化方案2:创建复合索引
ALTER TABLE employees ADD INDEX idx_age_gender (age, gender);
注意:MySQL 8.0+的 索引合并优化(Index Merge)可能自动处理部分OR场景。5. 不符合最左前缀原则
sql
-- 表有复合索引 (department, position)
CREATE INDEX idx_dept_pos ON employees(department, position);
-- 失效案例1:跳过左列
SELECT * FROM employees WHERE position = '工程师';
-- 失效案例2:范围查询中断后续列
SELECT * FROM employees
WHERE department LIKE 'A%' AND position = '经理'; -- 只能用到department索引
-- 优化方案:调整索引顺序或查询条件
CREATE INDEX idx_pos_dept ON employees(position, department); -- 按查询需求设计6. 使用NOT、!=、<> 操作符
sql
-- 失效案例
SELECT * FROM users WHERE status != 1;
-- 优化方案1:改为IN查询
SELECT * FROM users WHERE status IN (0, 2, 3);
-- 优化方案2:使用覆盖索引+条件反转
SELECT * FROM users WHERE status = 1; -- 先查满足条件的,业务层处理剩余7. 索引列参与数学运算
sql
-- 失效案例
SELECT * FROM products WHERE price * 0.8 > 100;
-- 优化方案:调整等式形式
SELECT * FROM products WHERE price > 100 / 0.8;三、如何诊断索引失效?
1. 使用EXPLAIN分析
sql
EXPLAIN SELECT * FROM users WHERE email LIKE '%@example.com';重点关注:
-
type:ALL表示全表扫描 -
key:NULL表示未用索引 -
Extra:Using where; Using filesort是危险信号
2. 开启优化器跟踪(MySQL 5.6+)
sql
SET optimizer_trace="enabled=on";
SELECT * FROM users WHERE ...;
SELECT * FROM information_schema.optimizer_trace;
SET optimizer_trace="enabled=off";四、高级解决方案
1. 函数索引(MySQL 8.0+)
sql
-- 对计算列创建索引
ALTER TABLE orders ADD INDEX idx_create_year ((YEAR(create_time)));
SELECT * FROM orders WHERE YEAR(create_time) = 2023; -- 现在可用索引2. 生成列(Generated Columns)
sql
-- 创建存储计算结果的列
ALTER TABLE products
ADD COLUMN name_length INT AS (LENGTH(name)) STORED,
ADD INDEX idx_name_length (name_length);
SELECT * FROM products WHERE name_length > 10;3. 使用强制索引
sql
-- 当优化器选错索引时
SELECT * FROM users FORCE INDEX(idx_email) WHERE email LIKE 'a%';总结:索引失效速查表
| 失效场景 | 解决方案 | 原理简述 |
|---|---|---|
| 索引列使用函数 | 改为范围查询/使用函数索引 | 破坏索引的有序性 |
| 隐式类型转换 | 保持类型一致 | 比较前需要转换类型 |
| 前导%模糊查询 | 改用后缀匹配/全文索引/逆序存储 | 无法利用索引的有序结构 |
| OR条件非全覆盖 | 改用UNION ALL/创建复合索引 | 部分条件无法使用索引 |
| 违反最左前缀 | 调整索引顺序或查询条件 | 索引按定义顺序组织 |
| 使用NOT/!= | 改为IN查询/覆盖索引 | 无法形成有效的扫描区间 |
| 数学运算 | 调整等式形式 | 运算后无法匹配索引值 |
黄金法则:
"让查询条件与索引的存储顺序一致" 通过
EXPLAIN验证索引使用情况,避免猜测!
执行计划(EXPLAIN)深度解析与性能优化
一、EXPLAIN核心字段详解
通过EXPLAIN可查看SQL的执行策略,以下是关键字段的解析:
| 字段 | 含义 | 常见值及说明 |
|---|---|---|
| type | 访问类型(性能关键指标) | 从优到差:system > const > eq_ref > ref > range > index > ALL |
| key | 实际使用的索引 | 显示索引名,NULL表示未用索引 |
| rows | 预估需要扫描的行数 | 数值越小越好,严重偏差可能需ANALYZE TABLE更新统计信息 |
| Extra | 额外信息(重要性能提示) | Using index(好现象), Using filesort(需优化)等 |
二、type访问类型详解
1. 性能排序与示例
sql
-- 性能从优到差示例
EXPLAIN SELECT * FROM users WHERE id = 1; -- type: const(主键等值)
EXPLAIN SELECT * FROM users WHERE email = 'admin@example.com'; -- type: ref(普通索引)
EXPLAIN SELECT * FROM users WHERE age > 18; -- type: range(范围查询)
EXPLAIN SELECT * FROM users WHERE name LIKE 'A%'; -- type: range(前缀匹配)
EXPLAIN SELECT * FROM users; -- type: ALL(全表扫描)2. 特殊类型说明
-
eq_ref:多表JOIN时,主键或唯一索引关联
sqlEXPLAIN SELECT * FROM orders JOIN users ON orders.user_id = users.id; -- users表的type为eq_ref -
index:全索引扫描(比ALL稍好)
sqlEXPLAIN SELECT COUNT(*) FROM users; -- 如果count(*)走索引
三、Extra字段的致命陷阱
1. 危险信号
| 值 | 问题原因 | 优化方案 |
|---|---|---|
| Using filesort | 排序无法利用索引,需额外文件排序 | 为ORDER BY字段创建索引 |
| Using temporary | 需要创建临时表(常见于GROUP BY、DISTINCT) | 优化GROUP BY字段顺序或使用覆盖索引 |
| Using where | 存储引擎返回数据后,Server层需再次过滤 | 检查WHERE条件是否可被索引覆盖 |
| Select tables optimized away | 优化器已优化掉表访问(如MIN/MAX走索引) | 好现象,无需处理 |
2. 优化案例对比
问题SQL:
sql
EXPLAIN SELECT * FROM orders WHERE user_id = 100 ORDER BY create_time DESC;
-- 可能结果:type: ref, Extra: Using filesort优化方案:
sql
-- 创建复合索引
ALTER TABLE orders ADD INDEX idx_user_create (user_id, create_time);
-- 再次EXPLAIN
EXPLAIN SELECT * FROM orders WHERE user_id = 100 ORDER BY create_time DESC;
-- 预期结果:type: ref, Extra: Using index四、性能瓶颈实战分析
1. Using filesort 场景
sql
-- 案例:按未索引字段排序
EXPLAIN SELECT * FROM products ORDER BY price;
-- 结果:type: ALL, Extra: Using filesort
-- 优化方案1:为排序字段加索引
ALTER TABLE products ADD INDEX idx_price (price);
-- 优化方案2:使用覆盖索引
CREATE INDEX idx_price_name ON products(price, name);
EXPLAIN SELECT price, name FROM products ORDER BY price;
-- 结果:type: index, Extra: Using index2. Using temporary 场景
sql
-- 案例:GROUP BY非索引列
EXPLAIN SELECT category, COUNT(*) FROM products GROUP BY category;
-- 结果:type: ALL, Extra: Using temporary; Using filesort
-- 优化方案:创建复合索引
ALTER TABLE products ADD INDEX idx_category (category);
-- 再次执行:type: range, Extra: Using index for group-by3. 索引合并优化
sql
-- 案例:多个单列索引的OR条件
EXPLAIN SELECT * FROM users WHERE age = 25 OR email LIKE 'a%';
-- 可能结果:type: index_merge, Extra: Using union(idx_age,idx_email)
-- 更优方案:创建复合索引
ALTER TABLE users ADD INDEX idx_age_email (age, email);五、执行计划分析流程图
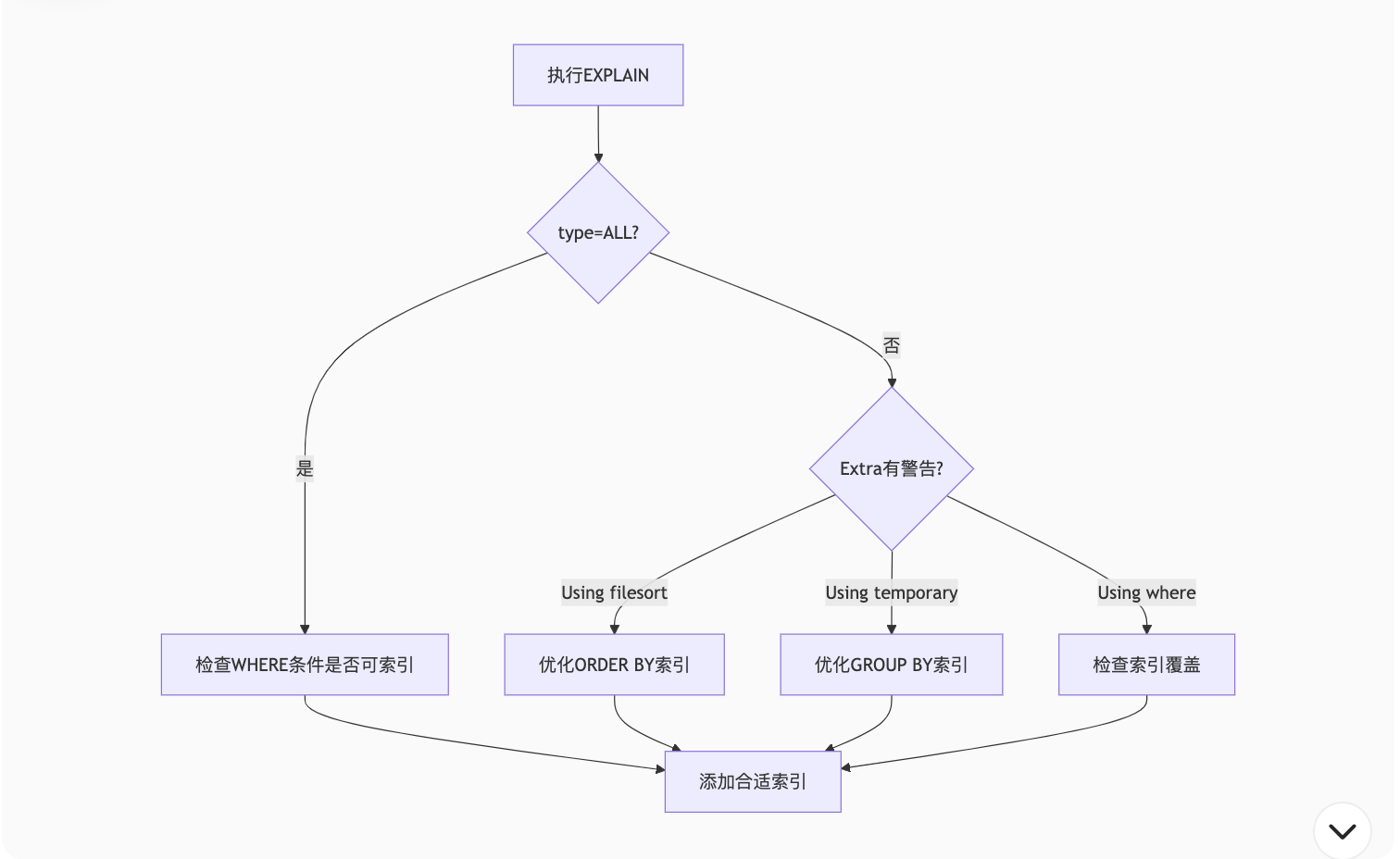
六、高级技巧
1. 格式化输出(MySQL 8.0+)
sql
EXPLAIN FORMAT=JSON SELECT * FROM users WHERE age > 20;
-- 获取详细的成本估算数据2. 检查索引使用率
sql
-- 查看索引实际使用情况
SELECT * FROM sys.schema_index_statistics
WHERE table_schema = 'your_db' AND table_name = 'users';3. 强制索引使用对比
sql
-- 对比不同索引的执行计划
EXPLAIN SELECT * FROM users USE INDEX(idx_age) WHERE age > 20;
EXPLAIN SELECT * FROM users IGNORE INDEX(idx_age) WHERE age > 20;总结:EXPLAIN调优速查表
| 问题现象 | 诊断要点 | 优化手段 |
|---|---|---|
| type: ALL | 全表扫描 | 添加WHERE条件涉及的索引 |
| Extra: Using filesort | 排序未走索引 | 创建ORDER BY字段的复合索引 |
| Extra: Using temporary | 临时表开销大 | 优化GROUP BY或使用覆盖索引 |
| rows值远大于实际 | 统计信息不准 | 执行ANALYZE TABLE更新统计信息 |
黄金法则:
"避免ALL类型,消灭filesort和temporary" 通过
EXPLAIN+ 索引优化,可解决80%的SQL性能问题!
ACID实现原理深度解析
一、Redo Log:持久性(Durability)的守护者
1. 核心作用
-
确保已提交事务的数据永不丢失
-
解决随机IO性能问题:将随机写磁盘(数据页)转换为顺序写(日志)
2. 工作原理
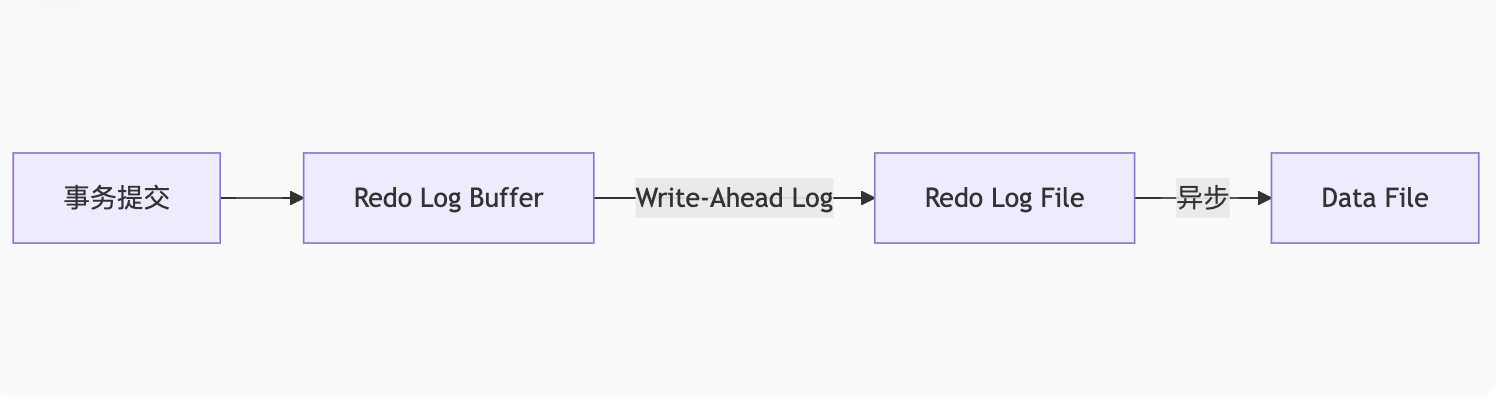
3. 关键机制
-
两阶段提交:
-
Prepare阶段:Redo Log写入磁盘
-
Commit阶段:Binlog写入磁盘后标记Redo Log为提交状态
-
-
循环写入: Redo Log文件组固定大小循环使用(如4个文件,每个1GB)
4. 崩溃恢复案例
sql
-- 事务执行过程
BEGIN;
UPDATE accounts SET balance = balance - 100 WHERE id = 1; -- 页A修改
UPDATE accounts SET balance = balance + 100 WHERE id = 2; -- 页B修改
COMMIT;
-- 崩溃场景:
1. 页A修改未刷盘,页B修改已刷盘
2. 通过Redo Log重放恢复两个页的修改5. 查看Redo Log
sql
SHOW VARIABLES LIKE 'innodb_log_file%';
-- innodb_log_file_size: 单个文件大小
-- innodb_log_files_in_group: 文件数量二、Undo Log:原子性(Atomicity)的基石
1. 核心作用
-
事务回滚:记录数据修改前的状态
-
MVCC实现:为读请求提供历史版本数据
2. 存储结构
| 修改类型 | Undo Log记录内容 |
|---|---|
| INSERT | 主键ID(用于回滚时删除) |
| DELETE | 完整数据(用于回滚时恢复) |
| UPDATE | 被修改字段的旧值 |
3. 工作流程
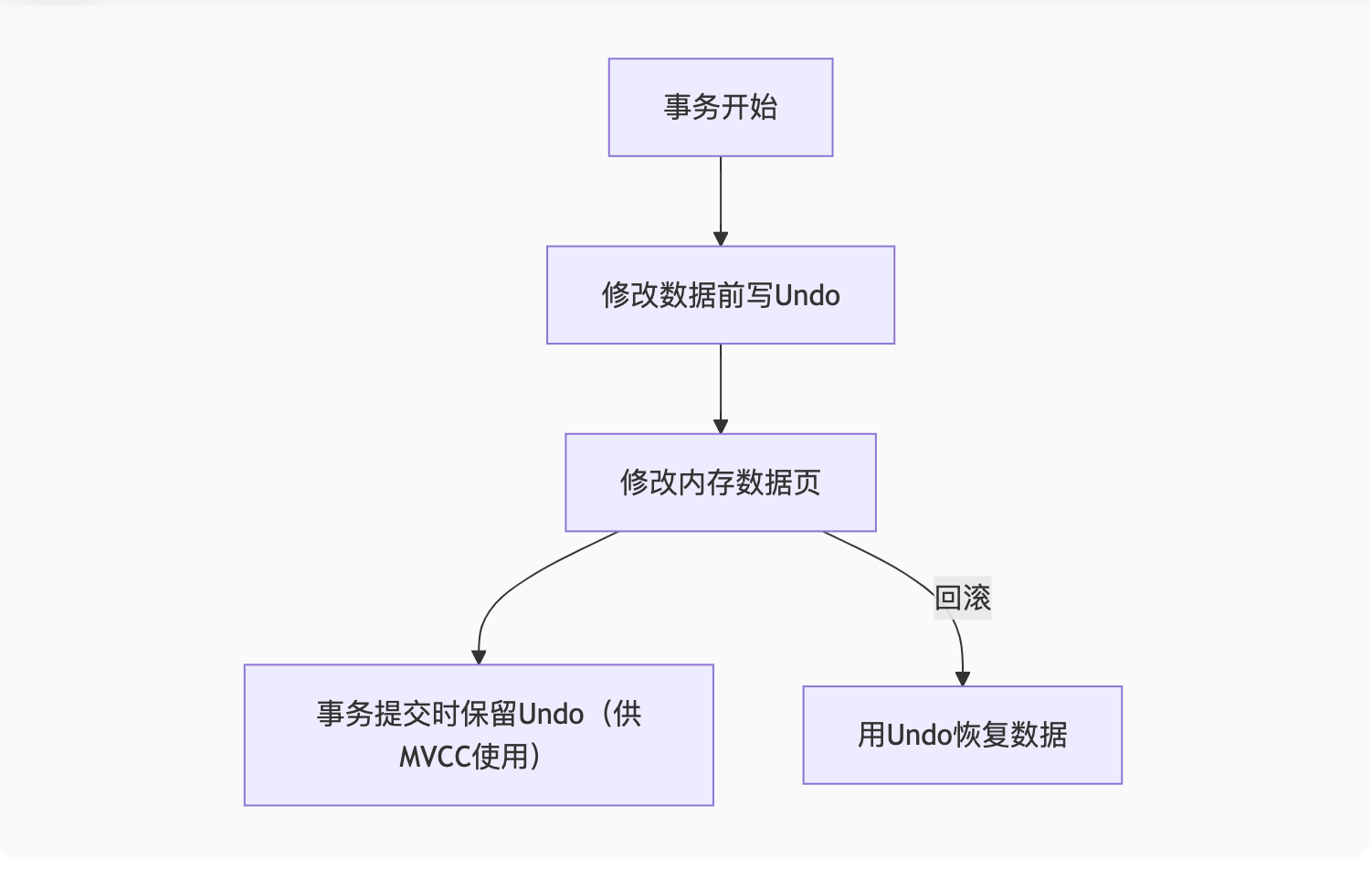
4. 回滚案例演示
sql
-- 事务执行
BEGIN;
UPDATE products SET stock = stock - 1 WHERE id = 101; -- 原始stock=10
-- Undo Log记录: (id=101, stock=10)
-- 回滚场景:
ROLLBACK;
-- 系统通过Undo Log将stock恢复为105. 空间管理
-
独立表空间 :MySQL 5.6+默认将Undo Log存入独立表空间(
innodb_undo_tablespaces) -
清理机制:后台线程purge清理不再需要的Undo Log
三、Redo与Undo的协同作战
1. 事务提交过程
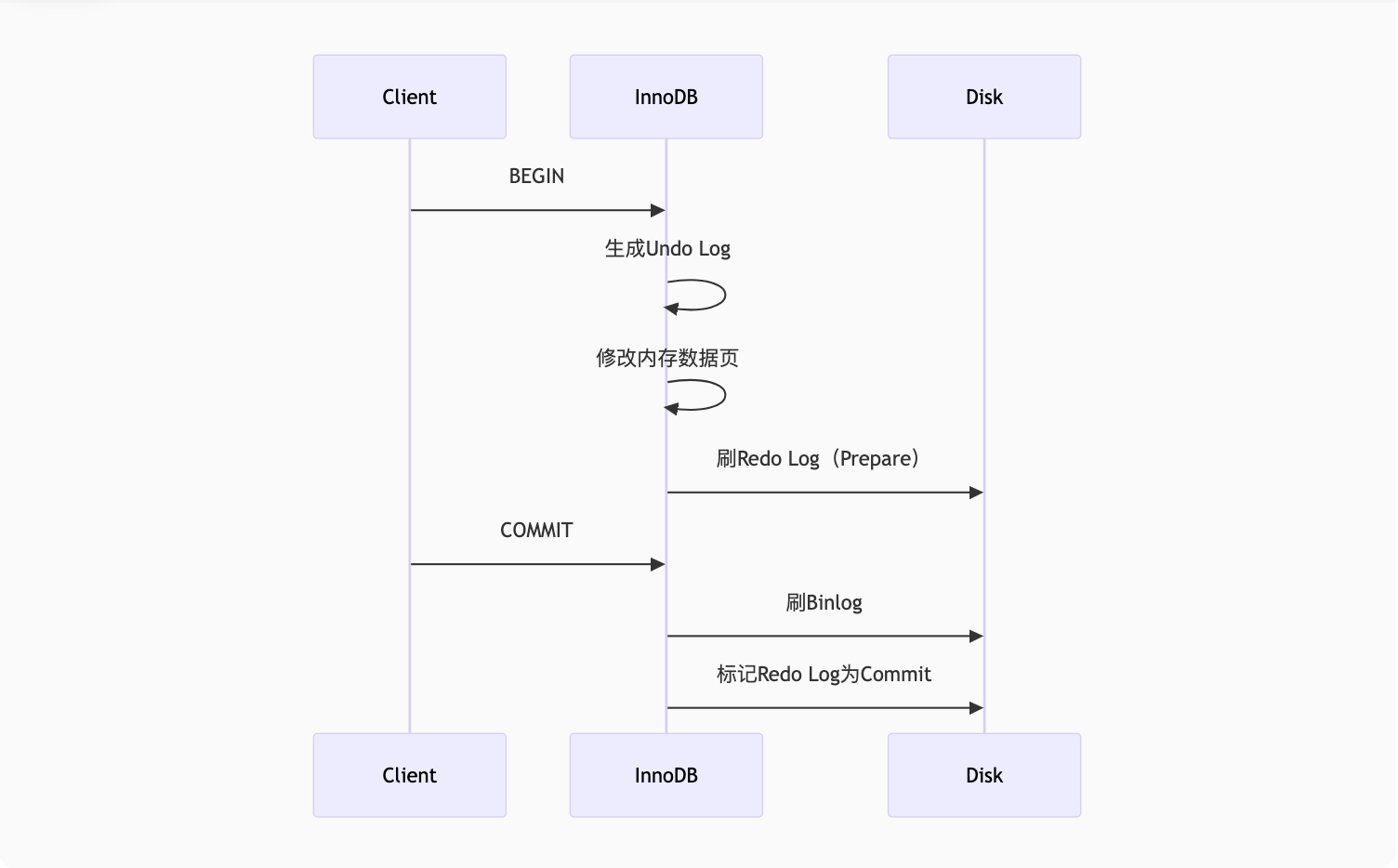
2. 崩溃恢复流程
-
检查Redo Log的Prepare但未Commit的事务
-
对比Binlog:
-
Binlog完整 ⇒ 重放Redo Log
-
Binlog不完整 ⇒ 回滚Undo Log
-
3. 性能优化参数
sql
-- 控制Redo Log刷盘策略
SET GLOBAL innodb_flush_log_at_trx_commit = 1; -- 1=最安全, 2=折衷, 0=最快
-- 控制Undo Log清理频率
SET GLOBAL innodb_purge_batch_size = 300; -- 每次purge的Undo页数量四、InnoDB ACID完整实现
| ACID属性 | 实现机制 | 关键组件 |
|---|---|---|
| 原子性 | Undo Log回滚能力 | Rollback Segment |
| 一致性 | 原子性+隔离性+持久性共同保证 | 整套机制协同 |
| 隔离性 | 锁+MVCC | 行锁/Next-Key Lock |
| 持久性 | Redo Log强制刷盘 | Log Buffer/File |
五、实战案例分析
案例1:银行转账的ACID保障
sql
-- 转账事务
BEGIN;
UPDATE accounts SET balance = balance - 100 WHERE id = 1; -- ①写Undo
UPDATE accounts SET balance = balance + 100 WHERE id = 2; -- ②写Undo
-- 此时Redo Log记录①和②的修改
COMMIT; -- Redo Log刷盘崩溃场景处理:
-
若在COMMIT前崩溃 ⇒ 通过Undo回滚
-
若在COMMIT后崩溃 ⇒ 通过Redo重放
案例2:电商库存超卖防护
sql
BEGIN;
SELECT stock FROM products WHERE id = 1001 FOR UPDATE; -- 加锁
-- Undo Log记录stock旧值
UPDATE products SET stock = stock - 1 WHERE id = 1001;
COMMIT;双重保障:
-
锁防止其他事务并发修改
-
Undo Log确保异常时可回滚
六、监控与调优
1. 监控日志状态
sql
-- 查看Redo Log刷新情况
SHOW ENGINE INNODB STATUS\G
-- LOG部分显示:
-- Log sequence number(最新LSN)
-- Log flushed up to(已刷盘LSN)
-- 查看Undo空间使用
SELECT tablespace_name, status FROM information_schema.innodb_tablespaces
WHERE tablespace_name LIKE '%undo%';2. 关键性能指标
| 指标 | 健康值 | 检查方法 |
|---|---|---|
| Redo Log写入延迟 | < 10ms | SHOW STATUS LIKE 'Innodb_log_waits' |
| Undo Log堆积量 | 活跃事务数*平均Undo大小 | SHOW ENGINE INNODB STATUS的TRANSACTIONS部分 |
总结:
Redo Log是"InnoDB的救生艇",确保数据不丢失
Undo Log是"事务的后悔药",保障操作可回滚 二者协同实现"提交即持久,回滚即消失"的ACID特性
数据库锁机制深度解析与实战案例
一、锁的类型全景图
| 按粒度分 | 按模式分 |
|---|---|
| 表锁 | 共享锁(S) |
| 行锁 | 排他锁(X) |
| 间隙锁 | 意向锁(IS/IX) |
二、行级锁实战案例
1. 记录锁(Record Lock)
场景:防止商品超卖
sql
-- 事务1(购买商品)
BEGIN;
SELECT stock FROM products WHERE id = 1001 FOR UPDATE; -- 加X锁
UPDATE products SET stock = stock - 1 WHERE id = 1001;
COMMIT;
-- 事务2(同时购买)
BEGIN;
SELECT stock FROM products WHERE id = 1001 FOR UPDATE; -- 被阻塞直到事务1提交关键点:
-
FOR UPDATE施加排他锁 -
锁冲突时,后到事务等待(默认超时50秒)
2. 间隙锁(Gap Lock)
场景:防止幻读(RR隔离级别)
sql
-- 表数据:id=5, 10, 15
BEGIN;
SELECT * FROM users WHERE id BETWEEN 8 AND 12 FOR UPDATE;
-- 锁定范围:(5,10), (10,15) 的间隙,阻止插入id=9,11等数据测试案例:
sql
-- 事务A
BEGIN;
SELECT * FROM users WHERE age > 20 FOR UPDATE; -- 加间隙锁
-- 事务B(会被阻塞)
INSERT INTO users(age) VALUES(25); -- 尝试插入20以上的数据三、表级锁应用场景
1. 元数据锁(MDL)
案例:在线DDL阻塞查询
sql
-- 会话1
BEGIN;
SELECT * FROM orders; -- 获取MDL读锁
-- 会话2(被阻塞)
ALTER TABLE orders ADD INDEX idx_amount(amount); -- 需要MDL写锁
-- 解决方案:设置锁超时
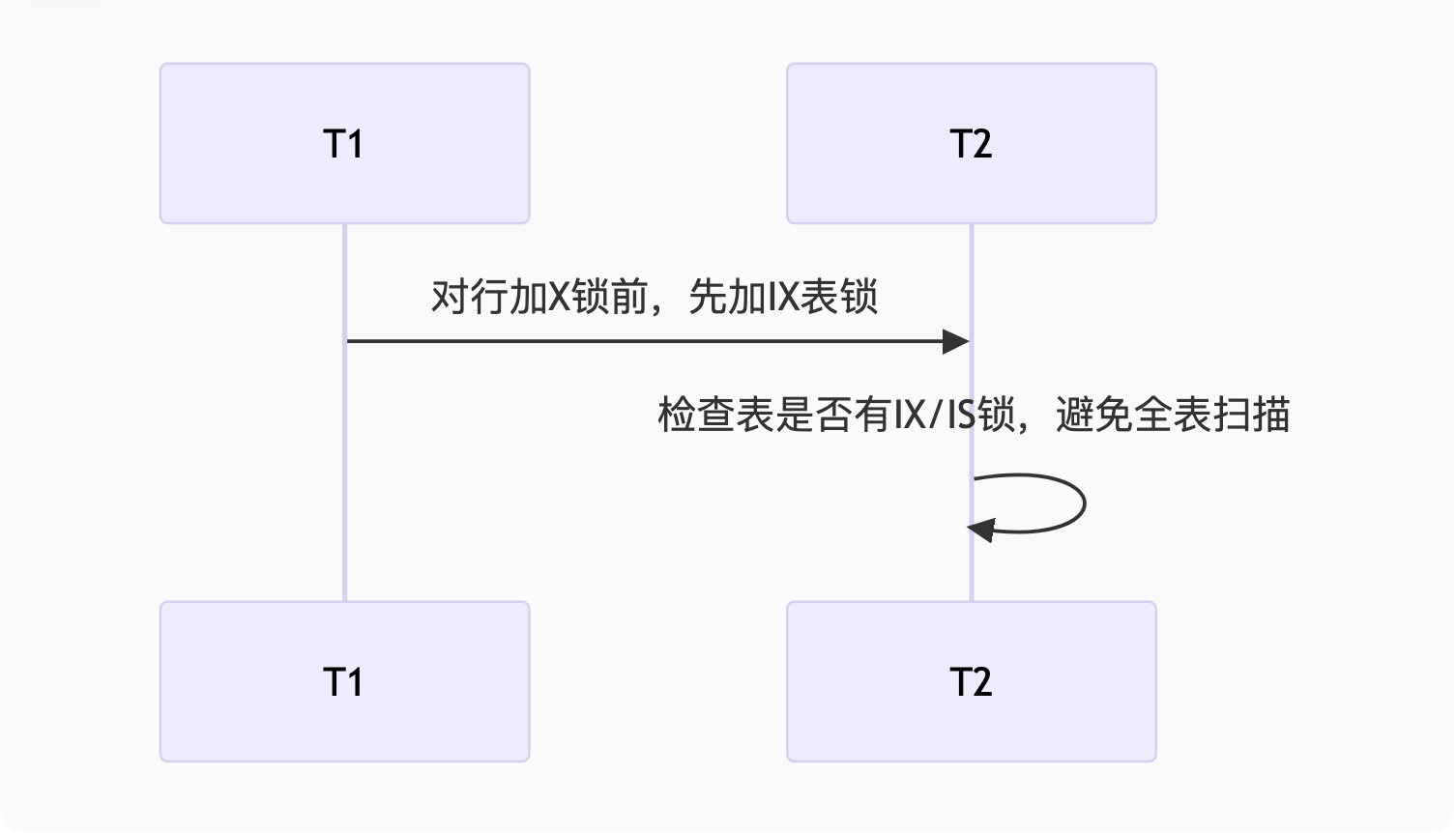
SET lock_wait_timeout = 5; -- 超时5秒2. 意向锁(Intention Lock)
作用:快速判断表是否被锁定
四、死锁分析与解决
1. 经典死锁案例
sql
-- 事务A
BEGIN;
UPDATE accounts SET balance = balance - 100 WHERE id = 1; -- 锁住id=1
UPDATE accounts SET balance = balance + 100 WHERE id = 2; -- 尝试锁id=2
-- 事务B(同时运行)
BEGIN;
UPDATE accounts SET balance = balance - 50 WHERE id = 2; -- 锁住id=2
UPDATE accounts SET balance = balance + 50 WHERE id = 1; -- 尝试锁id=1死锁日志:
sql
LATEST DETECTED DEADLOCK
*** (1) TRANSACTION: UPDATE accounts SET balance = balance + 100 WHERE id = 2
*** (1) HOLDS THE LOCK(S): id=1
*** (2) TRANSACTION: UPDATE accounts SET balance = balance + 50 WHERE id = 1
*** (2) HOLDS THE LOCK(S): id=22. 解决方案
-
统一加锁顺序
sql-- 所有事务按id从小到大加锁 UPDATE accounts SET ... WHERE id IN (1, 2) ORDER BY id; -
设置死锁超时
sqlSET innodb_lock_wait_timeout = 3; -- 超时3秒自动回滚 -
监控工具
sqlSHOW ENGINE INNODB STATUS\G -- 查看死锁日志
五、乐观锁 vs 悲观锁
1. 悲观锁实现(数据库原生)
sql
-- 使用SELECT FOR UPDATE
BEGIN;
SELECT * FROM inventory WHERE item_id = 1001 FOR UPDATE;
UPDATE inventory SET stock = stock - 1 WHERE item_id = 1001;
COMMIT;适用场景:高并发写操作(如秒杀)
2. 乐观锁实现(应用层控制)
sql
-- 使用版本号
UPDATE products
SET stock = stock - 1, version = version + 1
WHERE id = 1001 AND version = 5; -- 若影响行数=0则重试适用场景:读多写少(如评论点赞)
六、锁监控与优化
1. 查看锁状态
sql
-- 当前运行事务
SELECT * FROM information_schema.INNODB_TRX;
-- 锁等待关系
SELECT * FROM sys.innodb_lock_waits;2. 关键参数调优
sql
-- 控制锁超时(默认50秒)
SET GLOBAL innodb_lock_wait_timeout = 10;
-- 死锁检测开关(高并发时可临时关闭)
SET GLOBAL innodb_deadlock_detect = OFF;锁机制总结表
| 锁类型 | 应用场景 | 案例 | 解决方案 |
|---|---|---|---|
| 记录锁 | 精确更新单行 | 商品库存扣减 | SELECT FOR UPDATE |
| 间隙锁 | 防止幻读 | 范围查询时阻止插入 | 降低隔离级别为RC |
| Next-Key | RR隔离级默认锁 | 防止区间数据修改 | 使用唯一索引查询 |
| 乐观锁 | 并发冲突低的场景 | 文章阅读数更新 | 版本号/CAS机制 |
| 死锁 | 交叉更新多行 | 转账互相阻塞 | 统一加锁顺序 |
最佳实践:
事务尽量短小
访问数据顺序一致
合理设置隔离级别(通常RR够用)
监控
innodb_row_lock_waits指标
死锁分析与解决方案详解
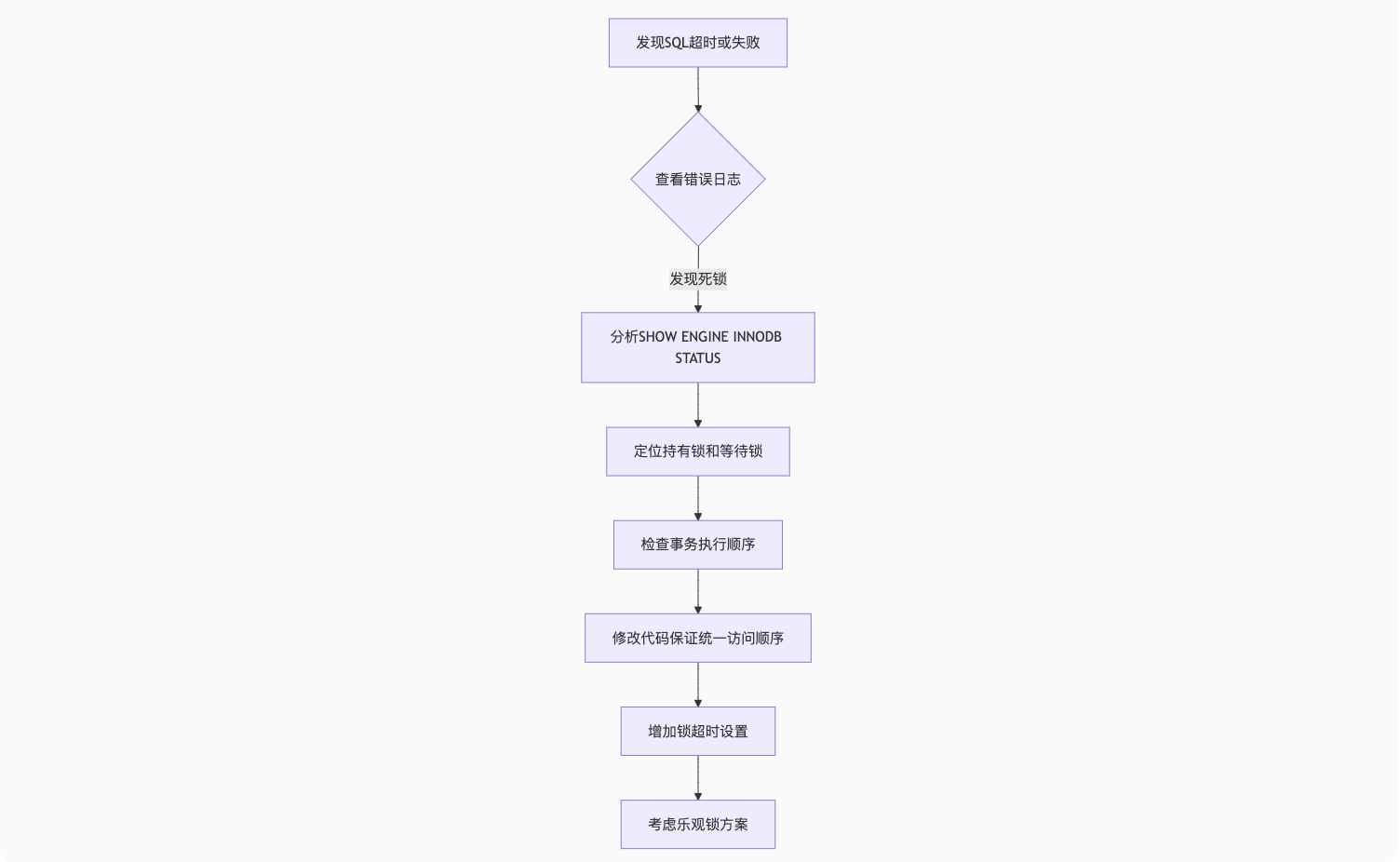
一、死锁检测:SHOW ENGINE INNODB STATUS
1. 查看死锁日志
sql
-- 查看最近一次死锁信息
SHOW ENGINE INNODB STATUS\G关键信息区域:
sql
------------------------
LATEST DETECTED DEADLOCK
------------------------
2023-08-20 10:00:00 0x7f8c12345600
*** (1) TRANSACTION:
TRANSACTION 12345, ACTIVE 2 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 3 lock struct(s), heap size 1136, 2 row lock(s)
MySQL thread id 100, OS thread handle 123456, query id 1000 updating
UPDATE accounts SET balance = balance - 100 WHERE id = 1
*** (1) HOLDS THE LOCK(S):
RECORD LOCKS space id 100 page no 10 n bits 72 index PRIMARY of table `test`.`accounts` trx id 12345 lock_mode X locks rec but not gap
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 100 page no 20 n bits 72 index PRIMARY of table `test`.`accounts` trx id 12345 lock_mode X locks rec but not gap waiting
*** (2) TRANSACTION:
TRANSACTION 67890, ACTIVE 1 sec starting index read
mysql tables in use 1, locked 1
3 lock struct(s), heap size 1136, 2 row lock(s)
MySQL thread id 200, OS thread handle 654321, query id 2000 updating
UPDATE accounts SET balance = balance + 100 WHERE id = 2
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 100 page no 20 n bits 72 index PRIMARY of table `test`.`accounts` trx id 67890 lock_mode X locks rec but not gap
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 100 page no 10 n bits 72 index PRIMARY of table `test`.`accounts` trx id 67890 lock_mode X locks rec but not gap waiting
*** WE ROLL BACK TRANSACTION (2)2. 日志解析要点
| 字段 | 说明 |
|---|---|
TRANSACTION [ID] |
事务ID |
HOLDS THE LOCK(S) |
当前持有的锁(示例中事务1持有id=1的X锁) |
WAITING FOR |
正在等待的锁(事务1等待id=2的X锁) |
WE ROLL BACK |
被牺牲的事务(通常选择回滚代价小的事务) |
二、死锁避免策略
1. 固定顺序更新(最有效方案)
问题代码:
java
// 线程A执行:
updateAccount(1, 2, 100); // 先更新id=1,再更新id=2
// 线程B执行:
updateAccount(2, 1, 50); // 先更新id=2,再更新id=1优化方案:
java
// 统一按id从小到大更新
public void transfer(int fromId, int toId, int amount) {
int firstId = Math.min(fromId, toId);
int secondId = Math.max(fromId, toId);
updateBalance(firstId, -amount);
updateBalance(secondId, amount);
}2. 锁超时设置
sql
-- 设置锁等待超时(默认50秒)
SET innodb_lock_wait_timeout = 3; -- 缩短为3秒
-- 事务中显式设置
START TRANSACTION;
/* 设置当前事务等待锁超时时间 */
SET LOCAL innodb_lock_wait_timeout = 1;
UPDATE accounts ...;
COMMIT;3. 乐观锁替代
sql
-- 使用版本号控制
UPDATE products
SET stock = stock - 1, version = version + 1
WHERE id = 1001 AND version = 5;
-- 检查affected_rows,若为0则重试三、死锁案例深度分析
案例1:交叉更新导致的死锁
sql
-- 事务A
BEGIN;
UPDATE users SET score = score + 10 WHERE id = 1; -- 持有id=1的X锁
UPDATE users SET score = score - 5 WHERE id = 2; -- 请求id=2的X锁
-- 事务B(同时执行)
BEGIN;
UPDATE users SET score = score + 8 WHERE id = 2; -- 持有id=2的X锁
UPDATE users SET score = score - 3 WHERE id = 1; -- 请求id=1的X锁解决方案 : 所有事务按id升序更新:
sql
UPDATE users SET score = score + 10 WHERE id IN (1, 2) ORDER BY id;案例2:间隙锁死锁
sql
-- 表数据:id=5, 10, 15
-- 事务A
BEGIN;
SELECT * FROM users WHERE id BETWEEN 8 AND 12 FOR UPDATE; -- 获得(5,10),(10,15)间隙锁
-- 事务B
BEGIN;
SELECT * FROM users WHERE id BETWEEN 9 AND 14 FOR UPDATE; -- 请求重叠间隙锁
INSERT INTO users(id) VALUES(11); -- 被阻塞解决方案 : 降低隔离级别为READ COMMITTED(慎用):
sql
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;四、InnoDB死锁处理机制
-
检测机制:
-
等待图(Wait-for Graph)检测环路
-
默认每10ms检测一次(
innodb_deadlock_detect控制)
-
-
解决策略:
-
选择回滚代价小的事务(依据事务修改的行数)
-
记录到
innodb_status文件
-
-
监控指标:
sqlSHOW STATUS LIKE 'innodb_row_lock%'; -- Innodb_row_lock_waits: 等待锁总次数 -- Innodb_row_lock_time_avg: 平均等待时间(ms)
五、预防死锁的最佳实践
-
事务设计原则
-
保持事务短小精悍
-
避免事务内交互式操作(如等待用户输入)
-
-
访问规范
java// 好的实践:统一顺序 + 批量操作 public void batchUpdate(List<Integer> ids) { ids.sort(); // 先排序 for (int id : ids) { updateById(id); } } -
数据库配置
bash# my.cnf优化 innodb_print_all_deadlocks = 1 # 记录所有死锁到错误日志 innodb_lock_wait_timeout = 5 # 设置合理超时
死锁分析流程图
分库分表拆分策略详解与实战案例
一、拆分策略全景图
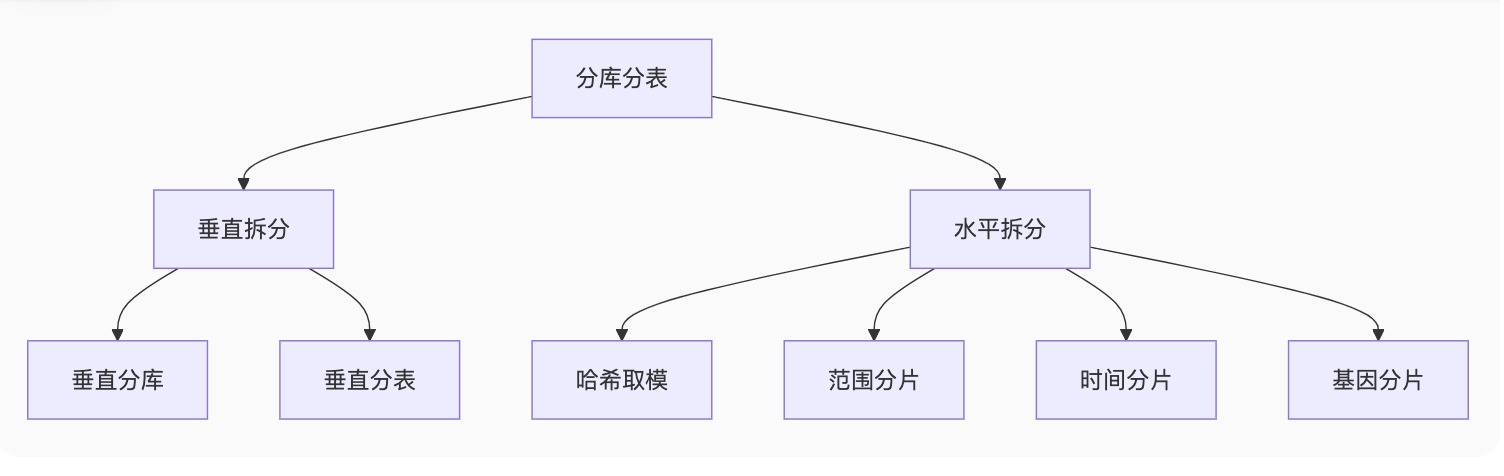
二、垂直拆分(按业务维度)
1. 垂直分库案例
场景:电商系统解耦
sql
-- 原始单体库
shop_db
├── users
├── products
├── orders
└── payments
-- 拆分后
user_db (用户服务)
├── users
├── user_address
product_db (商品服务)
├── products
├── categories
order_db (订单服务)
├── orders
└── order_items优势:
-
业务隔离,故障影响小
-
不同库可部署在不同服务器
2. 垂直分表案例
场景:用户表冷热数据分离
sql
-- 原始表
CREATE TABLE users (
id BIGINT,
name VARCHAR(100),
email VARCHAR(100),
last_login TIMESTAMP,
profile_json TEXT, -- 大字段
PRIMARY KEY(id)
);
-- 拆分后
CREATE TABLE users_base ( -- 热数据
id BIGINT,
name VARCHAR(100),
email VARCHAR(100),
last_login TIMESTAMP,
PRIMARY KEY(id)
);
CREATE TABLE users_ext ( -- 冷数据
user_id BIGINT,
profile_json TEXT,
FOREIGN KEY(user_id) REFERENCES users_base(id)
);查询示例:
sql
-- 高频查询只访问users_base
SELECT name, email FROM users_base WHERE id = 1001;
-- 低频完整查询需JOIN
SELECT * FROM users_base b JOIN users_ext e ON b.id = e.user_id;三、水平拆分(按数据维度)
1. 哈希取模分片
场景:用户表均匀分布
sql
-- 分片键:user_id
-- 分4个库,每个库16张表(共64张表)
shard_key = user_id % 64
db_no = shard_key / 16
table_no = shard_key % 16
-- 实际路由
db = user_db_{db_no}
table = users_{table_no}优势 :数据分布均匀 缺点:扩容需数据迁移
2. 范围分片(Range)
场景:订单按时间归档
sql
-- 按季度分表
orders_2023q1 (1-3月订单)
orders_2023q2 (4-6月订单)
orders_2023q3 (7-9月订单)
-- 查询需指定分片
SELECT * FROM orders_2023q2 WHERE user_id = 1001;优势:
-
易于冷热数据分离
-
无需复杂路由计算
3. 时间分片(适用于日志)
场景:操作日志按月分表
sql
-- 动态表名
SET @table_name = CONCAT('logs_', DATE_FORMAT(NOW(), '%Y%m'));
SET @sql = CONCAT('SELECT * FROM ', @table_name, ' WHERE user_id = 1001');
PREPARE stmt FROM @sql;
EXECUTE stmt;4. 基因分片(解决关联查询)
场景:订单与订单项关联查询
sql
-- 订单和订单项使用相同分片规则
order_id = 123456
-- 末2位作为分片基因
shard_key = order_id % 100
db_no = shard_key / 25 -- 分4个库
table_no = shard_key % 25 -- 每库25张表
-- 订单和订单项始终在同一库
orders_3.order_15 --> order_items_3.item_15四、分库分表示例架构
1. 电商系统分片设计
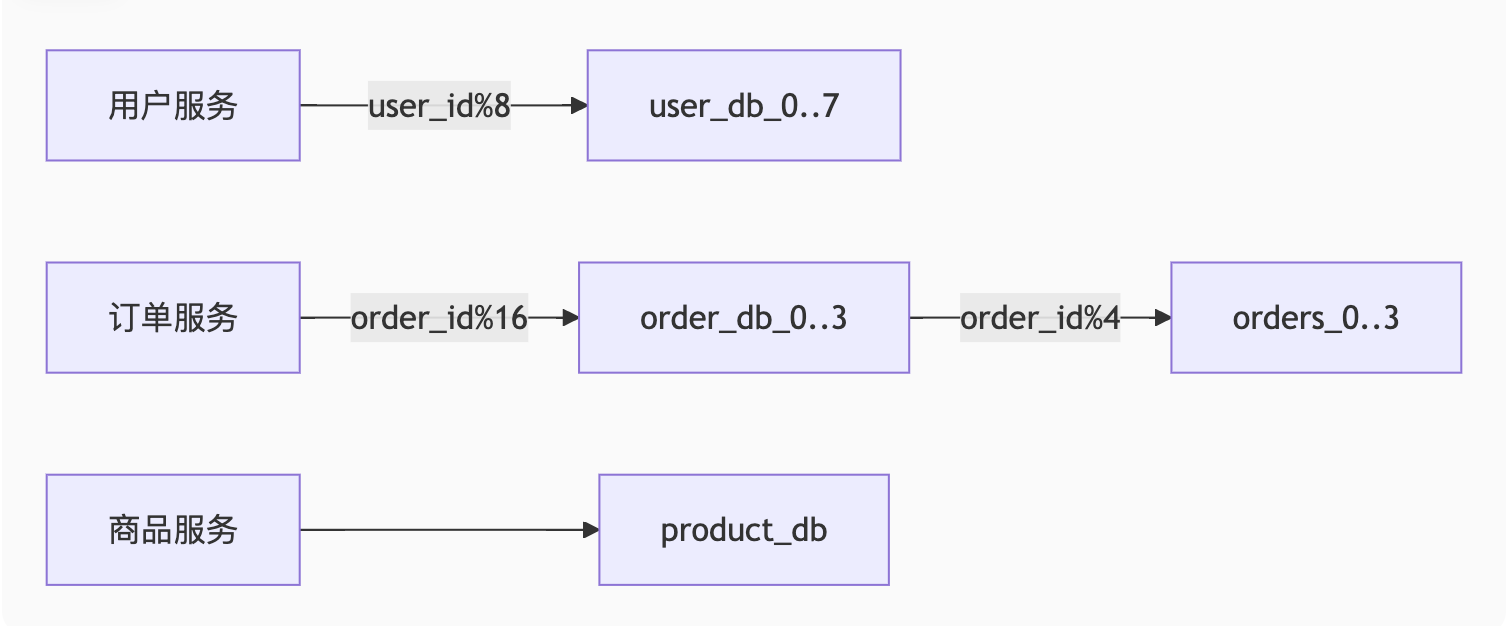
2. 分片路由代码示例(Java)
java
// 分库分表路由工具
public class ShardingUtil {
// 计算数据源
public static String getDataSource(String logicDb, long shardKey, int dbCount) {
int dbNo = (int) (shardKey % dbCount);
return logicDb + "_" + dbNo;
}
// 计算表名
public static String getTableName(String logicTable, long shardKey, int tableCount) {
int tableNo = (int) (shardKey % tableCount);
return logicTable + "_" + tableNo;
}
}
// 使用示例
String ds = ShardingUtil.getDataSource("order_db", 123456L, 4); // order_db_1
String table = ShardingUtil.getTableName("orders", 123456L, 8); // orders_0五、拆分带来的问题与解决方案
1. 全局ID生成
sql
-- Snowflake算法ID组成
| 1bit符号位 | 41bit时间戳 | 10bit机器ID | 12bit序列号 |
-- 适用场景:分布式系统,每毫秒可生成4096个ID
-- 数据库自增序列(需中心化)
CREATE TABLE sequence (
name VARCHAR(64) PRIMARY KEY,
value BIGINT NOT NULL
);2. 跨分片查询
方案:
-
字段冗余:订单表冗余商家名称
-
数据异构:使用Elasticsearch做聚合查询
-
广播表:基础数据表全库同步
3. 分布式事务
java
// Seata AT模式示例
@GlobalTransactional
public void placeOrder() {
orderService.create(); // 主事务
inventoryService.deduct(); // 分支事务
}六、分库分表中间件对比
| 中间件 | 特点 | 适用场景 |
|---|---|---|
| ShardingSphere | 透明化分片,支持多种分片策略 | 新项目,需要灵活分片 |
| MyCat | 简单易用,Proxy层架构 | 中小型项目快速落地 |
| TDDL | 阿里系,客户端直连模式 | 阿里云环境 |
拆分策略选择流程图
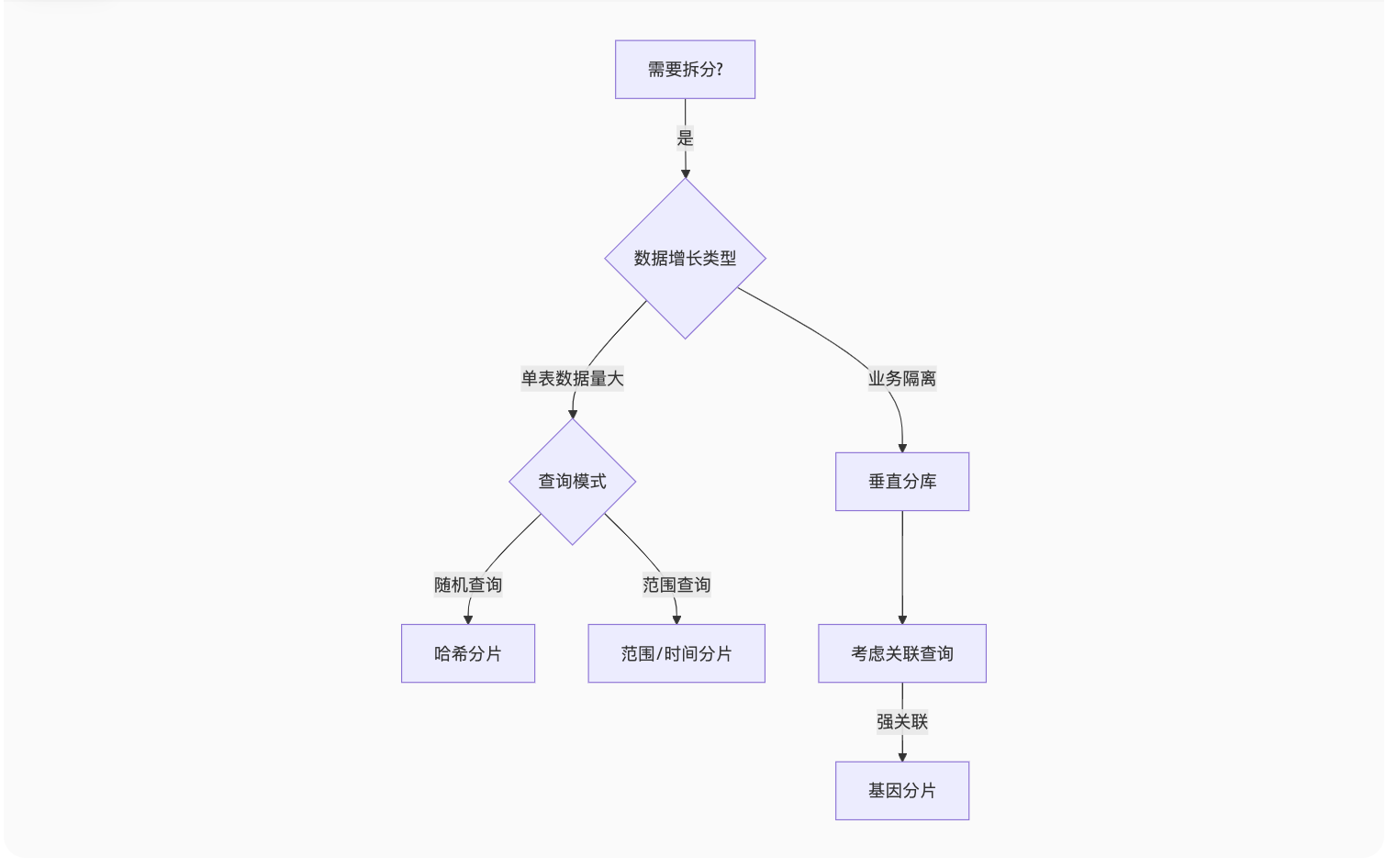
黄金法则:
-
先垂直后水平
-
分片键选择常用查询条件
-
单表建议不超过500万行
-
预留20%容量应对增长
分库分表 & 读写分离中间件实战指南
一、中间件核心作用
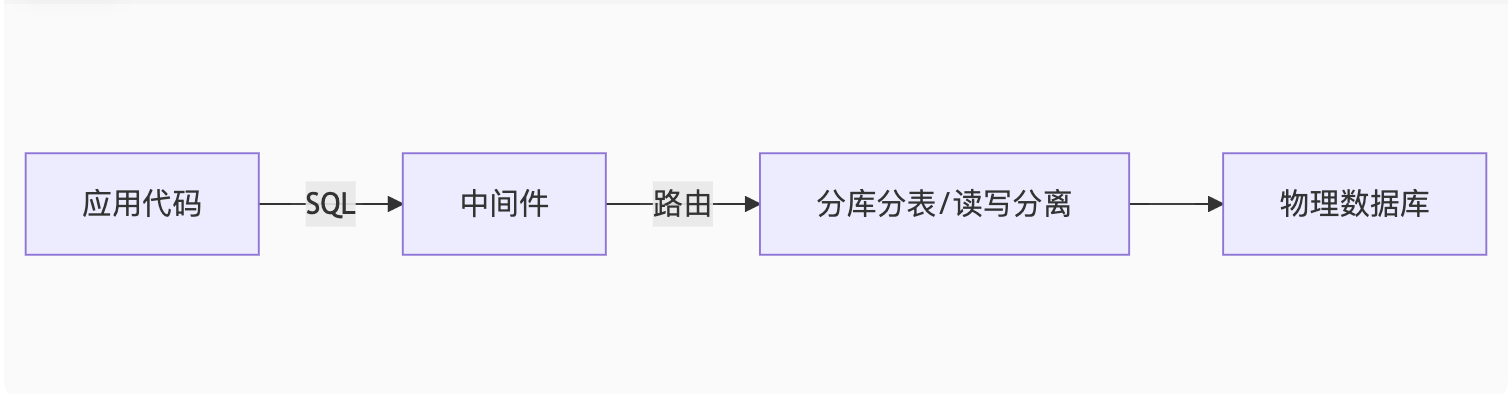
二、分库分表中间件实战
1. ShardingSphere-JDBC(推荐)
特点:
-
轻量级Java库,无需额外代理
-
支持多种分片策略
配置示例:
XML
# application.yml
spring:
shardingsphere:
datasource:
names: ds0,ds1
ds0: # 数据源0配置
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://db0:3306/order_db
username: root
password: 123456
ds1: # 数据源1配置...
sharding:
tables:
orders:
actual-data-nodes: ds$->{0..1}.orders_$->{0..15} # 分2库,每库16表
table-strategy:
inline:
sharding-column: order_id
algorithm-expression: orders_$->{order_id % 16}
database-strategy:
inline:
sharding-column: user_id
algorithm-expression: ds$->{user_id % 2}代码无需改造 : 原SQL SELECT * FROM orders WHERE user_id=100 会被自动路由到对应分片。
2. MyCat(Proxy模式)
部署架构:
XML
App → MyCat Proxy → MySQL集群关键配置(server.xml):
XML
<schema name="order_db">
<table name="orders" primaryKey="id" dataNode="dn0,dn1" rule="mod-long" />
</schema>
<dataNode name="dn0" dataHost="host1" database="order_db_0" />
<dataNode name="dn1" dataHost="host2" database="order_db_1" />
<dataHost name="host1" maxCon="1000" balance="1" writeType="0">
<heartbeat>select user()</heartbeat>
<writeHost host="master" url="db0:3306" user="root" password="123456"/>
<readHost host="slave" url="db0-slave:3306" user="root" password="123456"/>
</dataHost>三、读写分离中间件实战
1. 基于ShardingSphere
XML
spring:
shardingsphere:
masterslave:
name: ms_group
master-data-source-name: master
slave-data-source-names: slave1,slave2
props:
sql.show: true # 显示路由日志读写分离规则:
-
写操作自动路由到master
-
读操作轮询slave节点
2. MySQL Router(官方方案)
部署方式:
bash
# 启动路由
mysqlrouter --bootstrap root@master:3306 --directory myrouter
myrouter/start.sh连接示例:
bash
# 写端口6446,读端口6447
mysql -h 127.0.0.1 -P 6446 -u root -p # 写连接
mysql -h 127.0.0.1 -P 6447 -u root -p # 读连接四、避坑指南
-
分片键选择
-
避免选频繁更新的字段(如状态字段)
-
优先选择查询频繁的字段(如user_id)
-
-
分布式ID生成
java// 雪花算法ID生成 Snowflake snowflake = new Snowflake(workerId); long id = snowflake.nextId(); // 生成全局唯一ID -
跨库JOIN解决
-
字段冗余(如订单表冗余商家名)
-
数据异构到ES/ClickHouse
-
-
事务处理
java// 使用Seata处理分布式事务 @GlobalTransactional public void crossDbUpdate() { orderDao.update(); // 操作DB1 userDao.update(); // 操作DB2 }
五、中间件选型对比
| 中间件 | 分库分表 | 读写分离 | 架构模式 | 适合场景 |
|---|---|---|---|---|
| ShardingSphere-JDBC | ✅ | ✅ | 嵌入式 | Java应用,需灵活分片 |
| MyCat | ✅ | ✅ | 代理层 | 多语言混合技术栈 |
| MySQL Router | ❌ | ✅ | 官方代理 | 纯MySQL环境 |
| Atlas | ❌ | ✅ | 代理层 | 简单读写分离 |
六、性能监控
sql
-- ShardingSphere执行日志
SET sql.show=true;
-- MyCat监控
SHOW @@backend; # 查看数据节点状态
SHOW @@connection; # 查看连接数部署架构示例
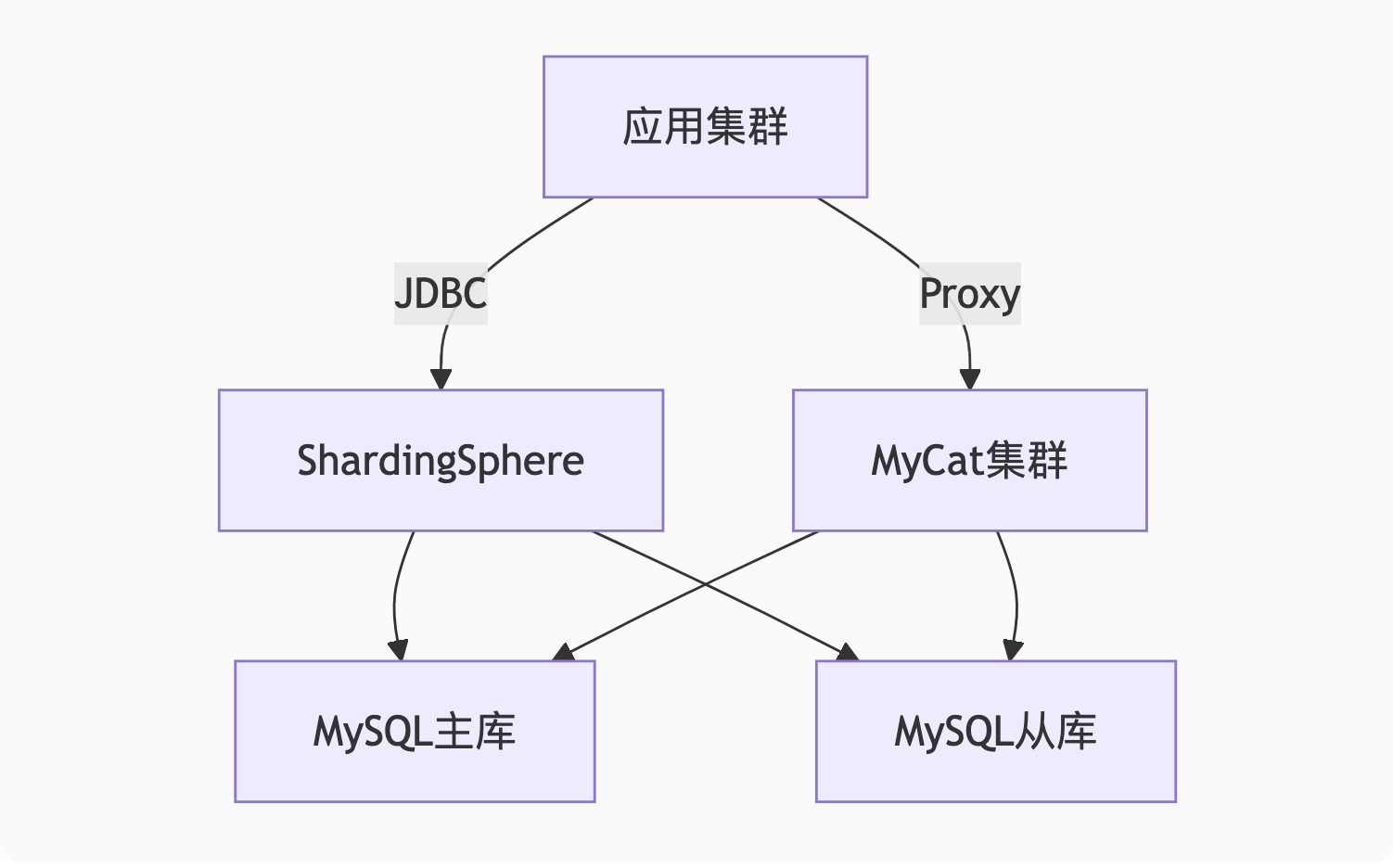
最佳实践:
-
中小项目优先用ShardingSphere-JDBC
-
混合语言技术栈用MyCat
-
简单读写分离用MySQL Router
分布式事务深度解析与实战案例
一、2PC(XA协议)
1. 核心原理
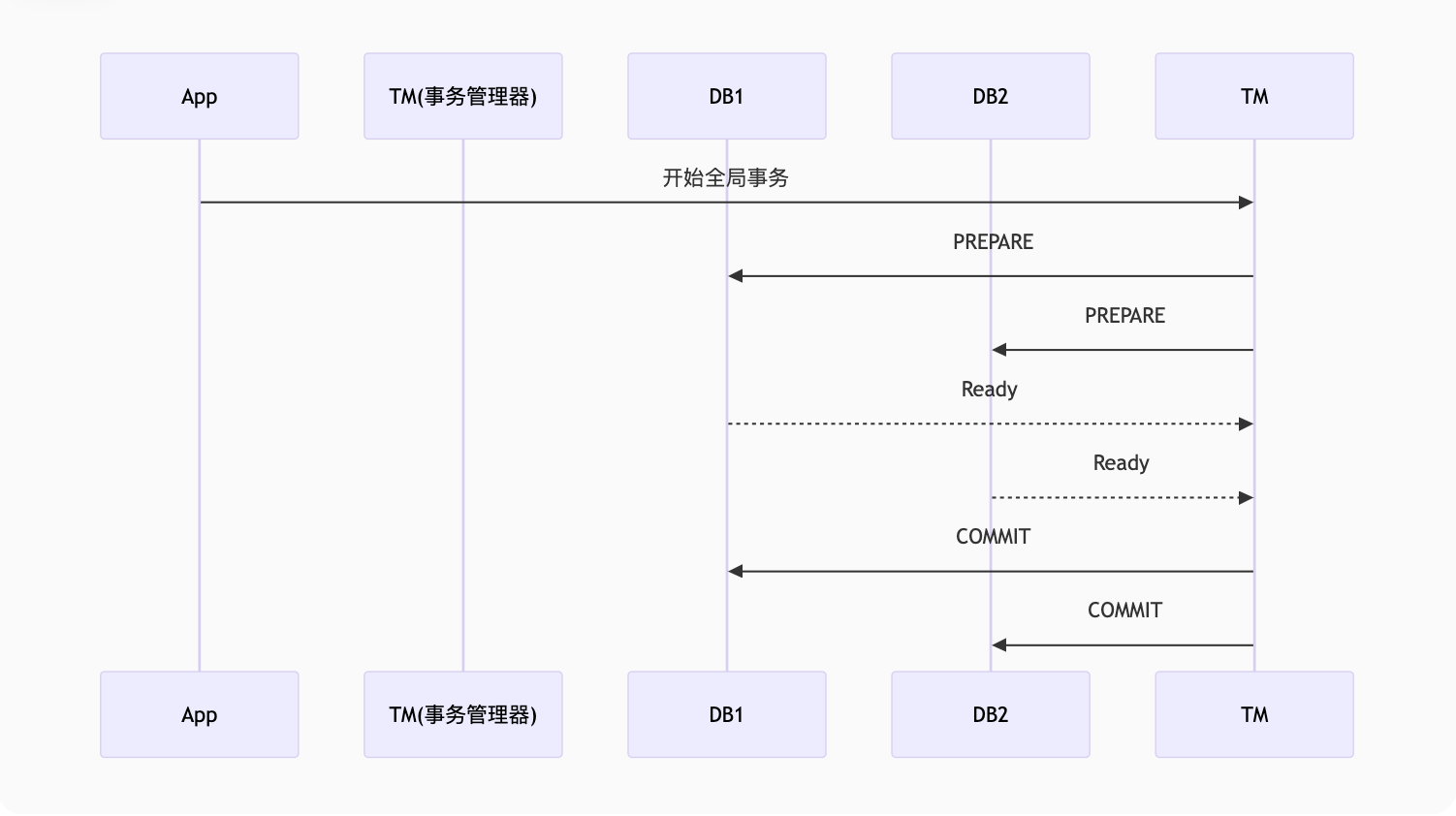
2. 优缺点对比
| 优点 | 缺点 |
|---|---|
| 强一致性保证 | 同步阻塞(参与者等待协调者指令) |
| 数据库原生支持(MySQL XA) | 单点故障(协调者宕机导致资源锁定) |
3. MySQL XA实战
sql
-- 参与者1
XA START 'transaction1';
UPDATE account SET balance = balance - 100 WHERE user_id = 1;
XA END 'transaction1';
XA PREPARE 'transaction1';
-- 参与者2
XA START 'transaction1';
UPDATE account SET balance = balance + 100 WHERE user_id = 2;
XA END 'transaction1';
XA PREPARE 'transaction1';
-- 协调者
XA COMMIT 'transaction1'; -- 或 XA ROLLBACK二、TCC(补偿事务)
1. 三阶段设计
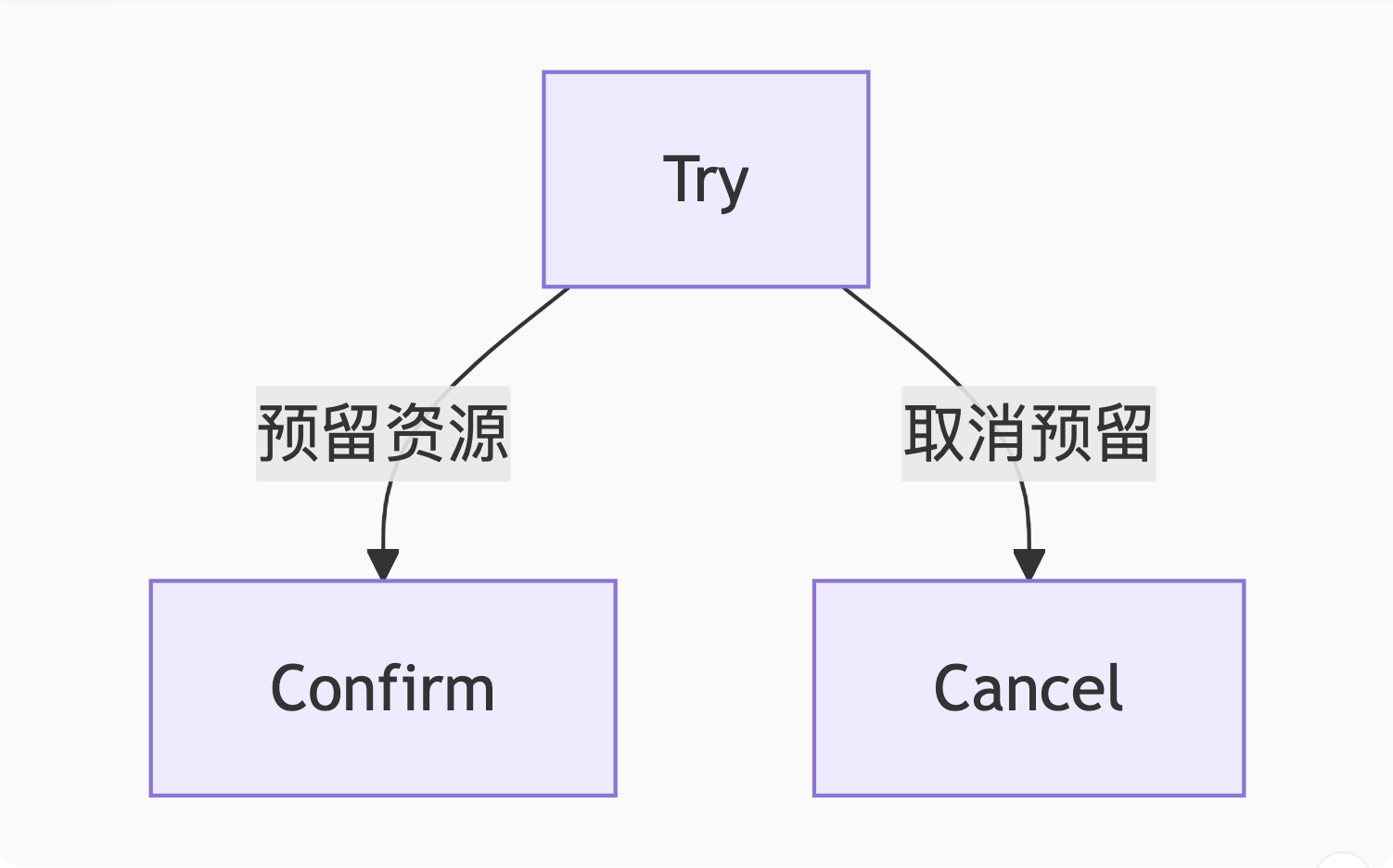
2. 电商下单案例
java
// Try阶段
public boolean orderTry(Order order) {
// 1. 冻结库存
inventoryService.freeze(order.getItems());
// 2. 生成预订单(状态=处理中)
orderDao.createPending(order);
}
// Confirm阶段
public void orderConfirm(Long orderId) {
// 1. 扣减真实库存
inventoryService.deduct(orderId);
// 2. 更新订单状态=成功
orderDao.updateStatus(orderId, "CONFIRMED");
}
// Cancel阶段
public void orderCancel(Long orderId) {
// 1. 释放冻结库存
inventoryService.unfreeze(orderId);
// 2. 更新订单状态=取消
orderDao.updateStatus(orderId, "CANCELLED");
}3. 关键注意事项
-
幂等设计:网络重试可能导致重复调用
-
空回滚:Try未执行时收到Cancel需特殊处理
-
悬挂控制:Cancel比Try先到的场景
三、Seata AT模式
1. 核心原理
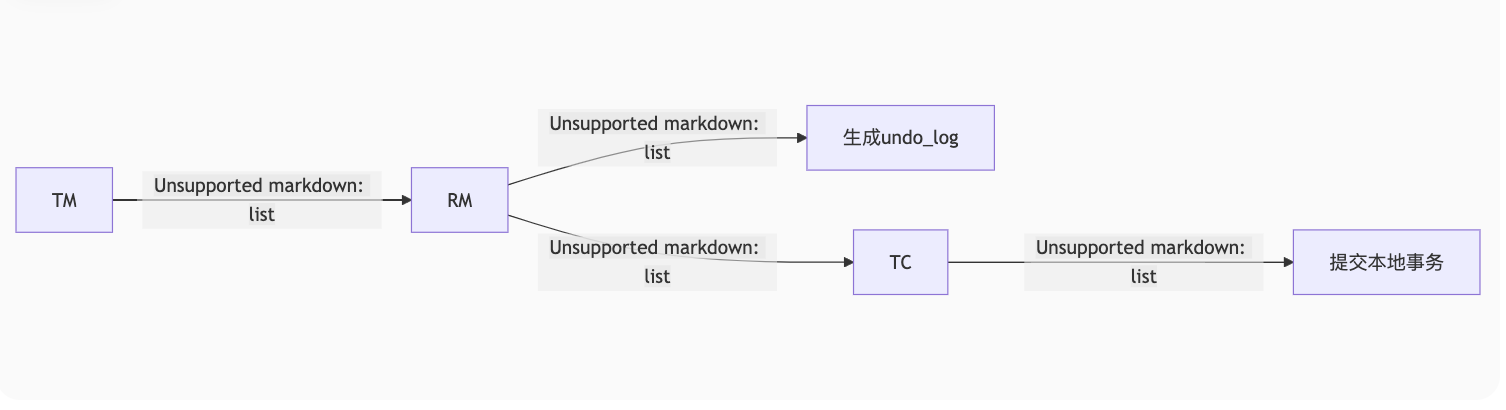
2. 自动补偿机制
原始SQL:
sql
UPDATE products SET stock = stock - 1 WHERE id = 1001;Seata自动记录:
sql
// undo_log
{
"afterImage": {"id":1001, "stock": 99},
"beforeImage": {"id":1001, "stock": 100}
}回滚时自动生成:
sql
UPDATE products SET stock = 100 WHERE id = 1001; -- 反向SQL3. 部署架构
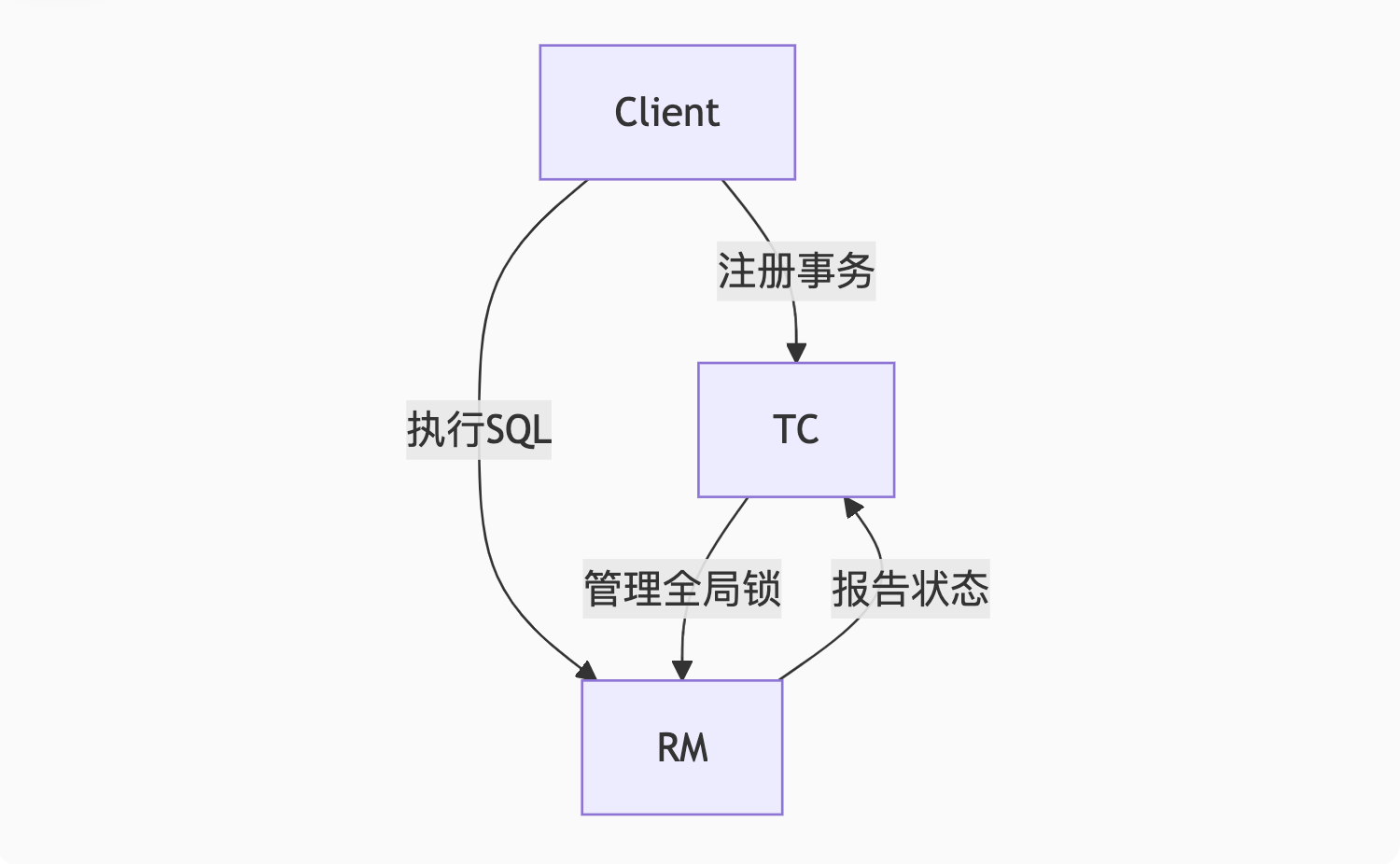
4. 快速入门
配置示例:
sql
# seata.conf
service.vgroup_mapping.my_tx_group=default
store.mode=db
store.db.url=jdbc:mysql://127.0.0.1:3306/seata代码使用:
java
@GlobalTransactional
public void purchase() {
orderService.create();
inventoryService.deduct();
}四、方案对比与选型
| 维度 | 2PC | TCC | Seata AT |
|---|---|---|---|
| 一致性 | 强一致 | 最终一致 | 最终一致 |
| 性能 | 差(同步阻塞) | 中(需编码补偿) | 高(无侵入) |
| 适用场景 | 跨数据库交易 | 金融/高一致性要求 | 常规业务系统 |
| 复杂度 | 低(数据库内置) | 高(需实现三阶段) | 中(需部署TC服务) |
五、实战避坑指南
-
Seata AT的全局锁冲突
- 优化方案:减小事务粒度,避免热点数据竞争
-
TCC的空补偿处理
javapublic void cancel(Long orderId) { if (!orderDao.exists(orderId)) { // 检查Try是否执行 log.warn("空补偿,orderId={}", orderId); return; } // 正常补偿逻辑... } -
XA超时设置
sqlSET GLOBAL innodb_xa_timeout=30; -- MySQL XA超时(秒)
总结:分布式事务技术选型流程图
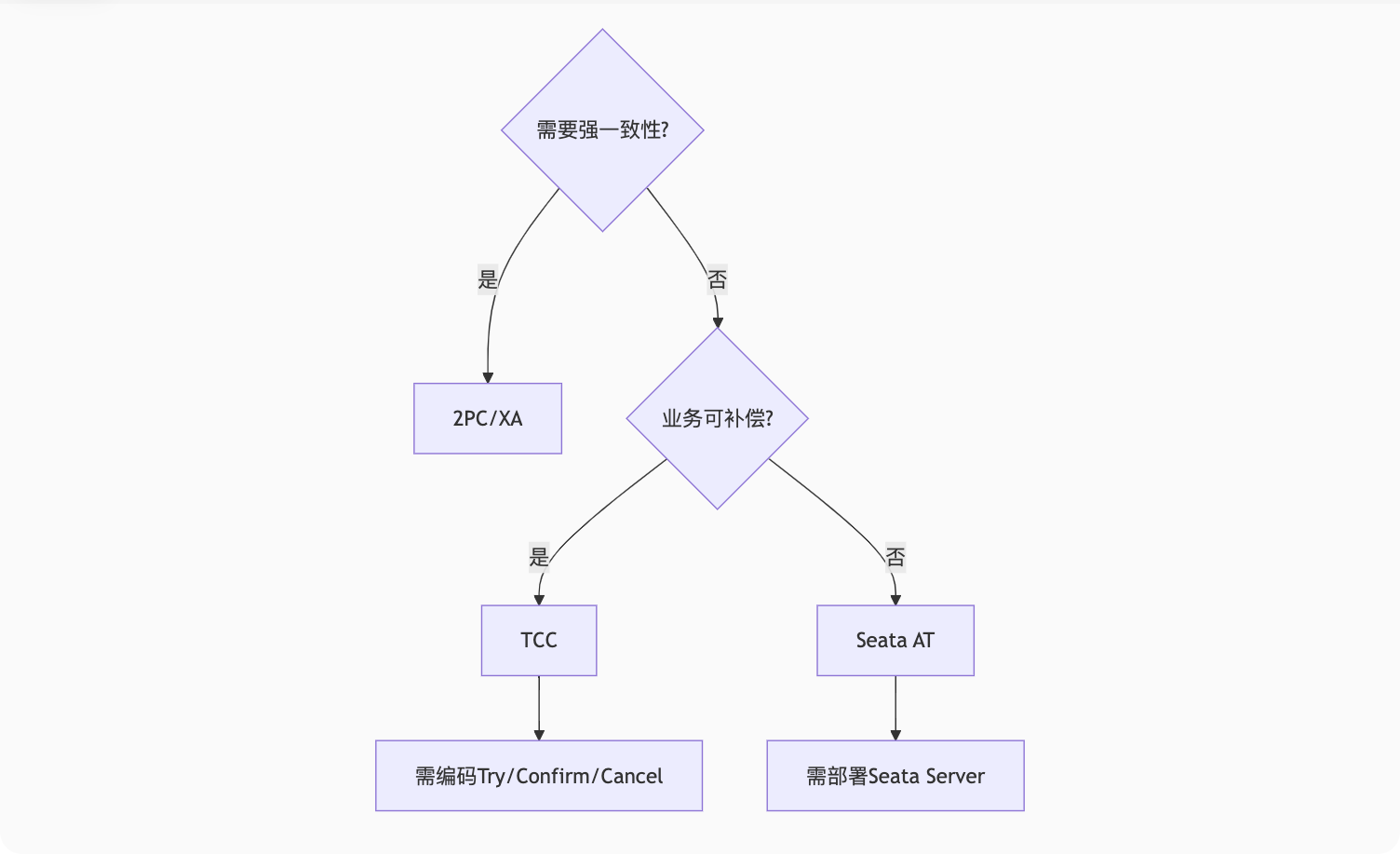
黄金法则:
-
金融支付用TCC
-
普通交易用Seata AT
-
传统数据库整合用XA
Redis核心应用实战指南
一、数据结构选型策略
1. 5大核心数据结构对比
| 数据结构 | 底层实现 | 时间复杂度 | 典型应用场景 |
|---|---|---|---|
| String | SDS动态字符串 | O(1) | 缓存、计数器(如文章阅读量) |
| Hash | 哈希表+ziplist | O(1) | 对象属性存储(用户资料、商品信息) |
| List | 双向链表+ziplist | O(n) | 消息队列、最新文章列表 |
| Set | 哈希表+intset | O(1) | 标签系统、共同好友 |
| ZSet | 跳表+哈希表 | O(logN) | 排行榜、延迟队列 |
2. 实战选型案例
场景1:电商商品缓存
bash
# 错误示范 - 用String存JSON
SET product:1001 '{"id":1001,"name":"iPhone","price":6999}'
# 正确示范 - 用Hash存储
HSET product:1001 id 1001 name iPhone price 6999优势:可单独修改价格字段,内存更节约
场景2:实时排行榜
bash
# ZSet实现点击榜
ZINCRBY article:click:rank 1 "article_1001"
ZREVRANGE article:click:rank 0 9 # 获取TOP10二、持久化方案详解
1. RDB vs AOF对比
| 维度 | RDB | AOF |
|---|---|---|
| 持久化方式 | 定时内存快照 | 记录每条写命令 |
| 恢复速度 | 快(大数据量) | 慢(需重放命令) |
| 数据安全 | 可能丢失最后一次快照后的数据 | 最多丢失1秒数据(everysec配置) |
| 文件大小 | 小(二进制压缩) | 大(可重写优化) |
2. 混合持久化配置(推荐)
bash
# redis.conf
save 900 1 # 15分钟至少1个key变化则触发RDB
appendonly yes # 开启AOF
appendfsync everysec # 每秒刷盘
aof-use-rdb-preamble yes # 混合模式恢复流程:
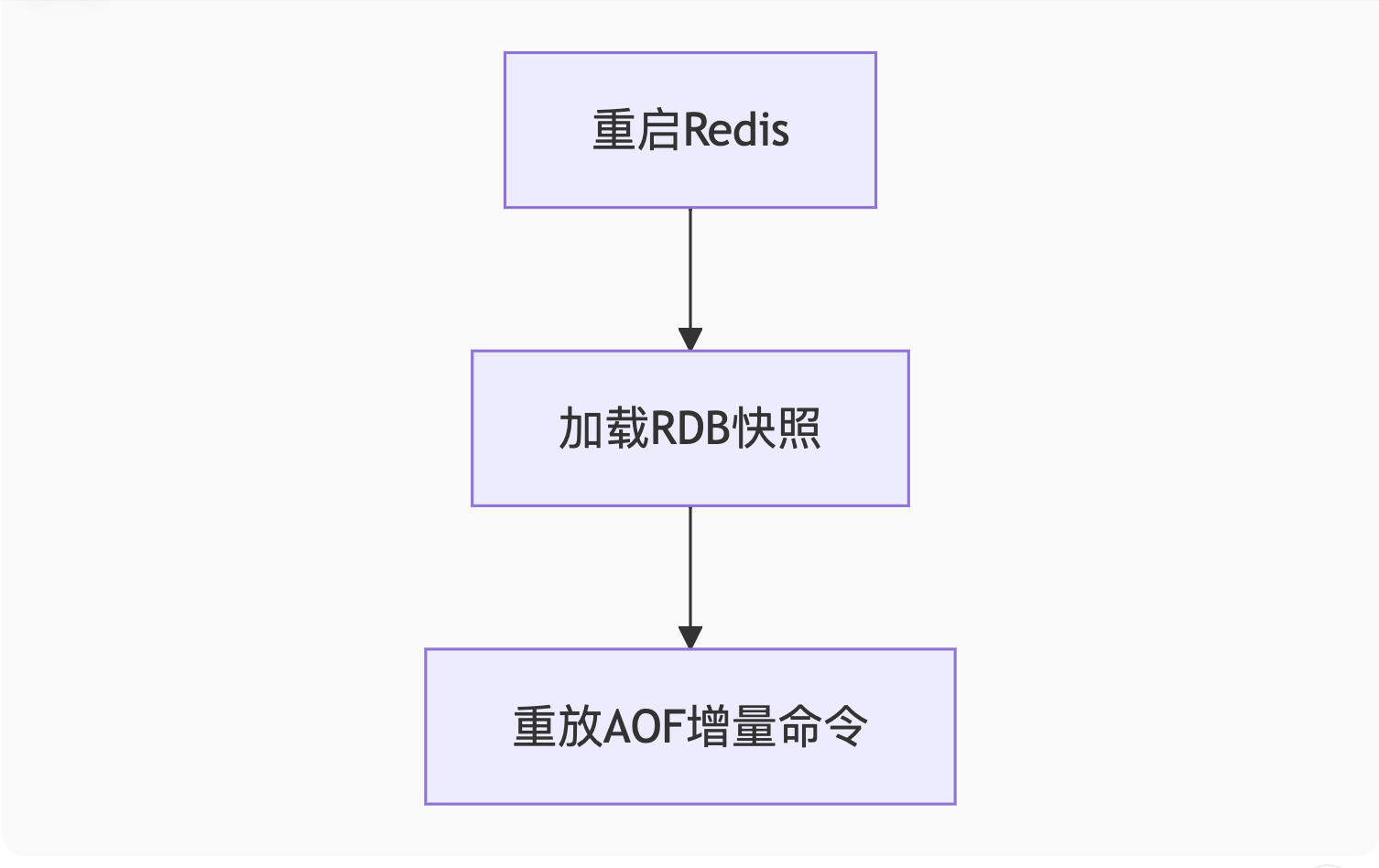
3. 数据恢复演练
bash
# 手动触发RDB
redis-cli SAVE # 阻塞式
redis-cli BGSAVE # 后台执行
# AOF重写(压缩命令)
redis-cli BGREWRITEAOF三、缓存异常解决方案
1. 缓存穿透(查不存在数据)
问题现象 :大量请求绕过缓存直接访问DB 解决方案:
bash
// 布隆过滤器伪代码
public boolean isExist(long id) {
if (!bloomFilter.mightContain(id)) {
return false; // 肯定不存在
}
return cache.get(id) != null; // 可能存在
}
// 缓存空值示例
String data = redis.get(key);
if (data == null) {
data = db.get(key);
redis.setex(key, 300, data == null ? "NULL" : data); // 空值缓存5分钟
}2. 缓存雪崩(批量失效)
问题现象 :大量key同时过期导致DB压力暴增 解决方案:
bash
# 差异化过期时间
redis-cli SETEX product:1001 $((3600 + RANDOM % 600)) "data" # 1小时±10分钟
# 多级缓存架构
浏览器缓存 → CDN → Redis集群 → DB3. 缓存击穿(热点key失效)
问题现象 :单个热点key过期时突发大量请求 解决方案:
bash
// 互斥锁伪代码
public String getData(String key) {
String data = redis.get(key);
if (data == null) {
if (redis.setnx(key + ":mutex", "1", 60)) { // 获取锁
data = db.get(key); // 查数据库
redis.setex(key, 300, data);
redis.del(key + ":mutex"); // 释放锁
} else {
Thread.sleep(100); // 重试
return getData(key);
}
}
return data;
}四、高级应用场景
1. 分布式锁优化版
bash
-- Lua脚本保证原子性
local lockKey = KEYS[1]
local requestId = ARGV[1]
local ttl = tonumber(ARGV[2])
if redis.call('setnx', lockKey, requestId) == 1 then
redis.call('pexpire', lockKey, ttl)
return 1
else
return 0
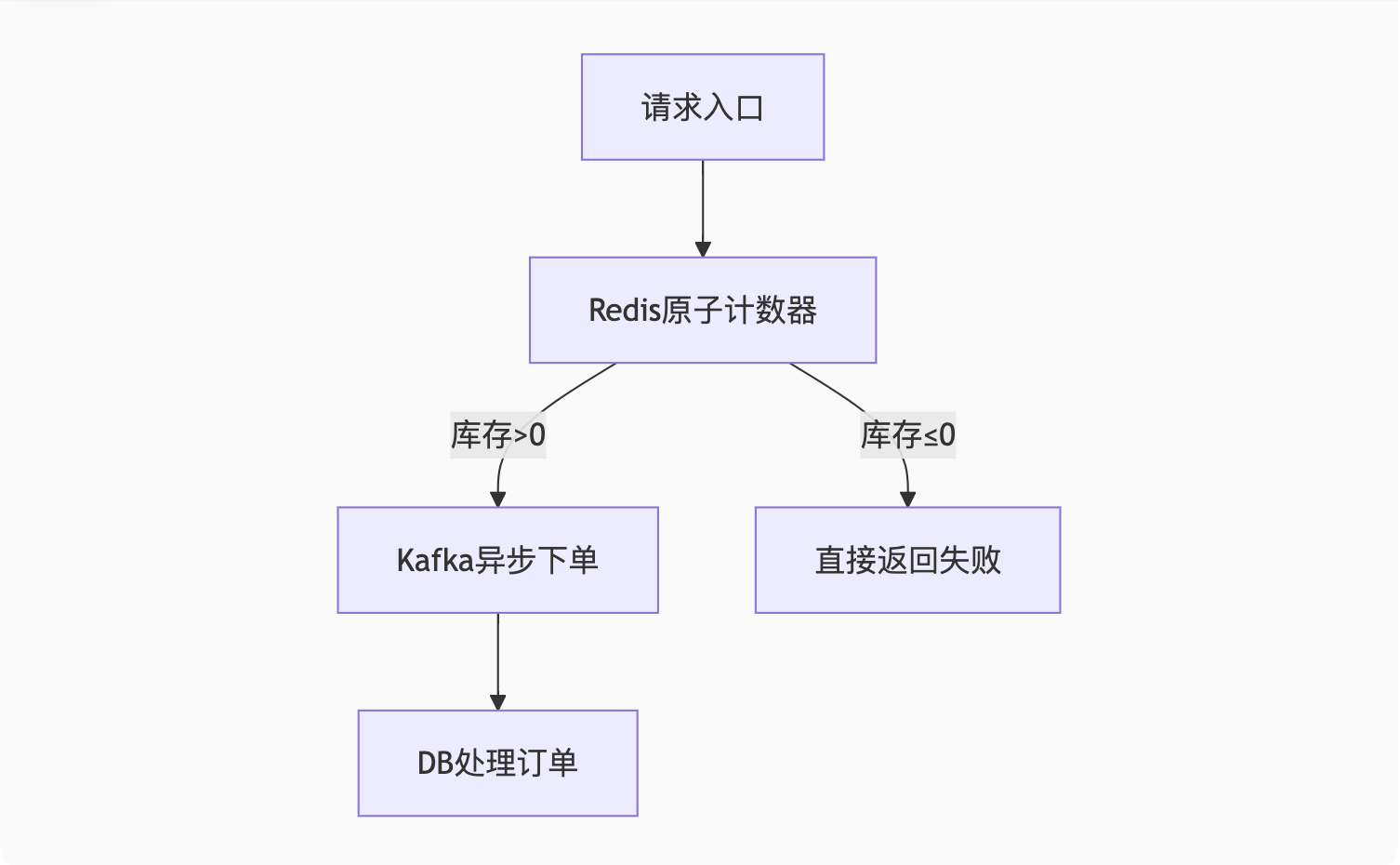
end2. 秒杀系统设计
3. 热点数据发现
bash
# 使用redis-cli监控热点key
redis-cli --hotkeys --intrinsic-latency 100Redis运维关键指标
| 指标 | 健康值 | 检查命令 |
|---|---|---|
| 内存使用率 | < 80% | INFO MEMORY |
| 连接数 | < maxclients的50% | INFO CLIENTS |
| 持久化延迟 | AOF延迟<1秒 | INFO PERSISTENCE |
| 键空间命中率 | > 95% | INFO STATS |
性能优化口诀:
"String存简单,Hash存对象,List当队列,Set去重快,ZSet做排序" "RDB快照保底,AOF增量跟,混合最稳妥" "穿透布隆挡,雪崩时间散,击穿加锁防"
MongoDB核心应用场景与实战案例
一、JSON文档模型设计
1. 灵活的数据建模优势
与传统关系型数据库对比:
javascript
// 关系型数据库设计(需要多表关联)
users表: { id: 1, name: "张三" }
orders表: { id: 101, user_id: 1, items: [...] }
order_items表: { order_id: 101, product_id: 1001 }
// MongoDB文档模型(嵌套设计)
{
_id: 1,
name: "张三",
orders: [
{
order_id: 101,
items: [
{ product_id: 1001, name: "iPhone", price: 6999 },
{ product_id: 1002, name: "AirPods", price: 999 }
]
}
]
}2. 典型应用场景
案例1:电商产品目录
javascript
// 支持多变的商品属性
{
_id: "1001",
type: "手机",
name: "iPhone 15",
attributes: {
color: ["深空黑", "星光色"],
memory: [128, 256, 512],
camera: {
front: "12MP",
back: ["48MP", "12MP", "12MP"]
}
},
price: 6999
}优势:无需预定义表结构,轻松应对产品属性变化
案例2:物联网设备数据
javascript
// 设备上报的异构数据
{
device_id: "D1001",
timestamp: ISODate("2023-08-20T10:00:00Z"),
readings: {
temperature: 26.5,
humidity: 45,
voltage: 3.7,
location: { type: "Point", coordinates: [116.404, 39.915] }
}
}二、地理空间索引(LBS应用)
1. 空间索引类型
| 索引类型 | 适用查询 | 示例 |
|---|---|---|
| 2dsphere | 地球球面几何计算 | 附近的人、电子围栏 |
| 2d | 平面坐标计算(游戏地图) | 简单的位置碰撞检测 |
2. 实战案例:附近餐厅搜索
步骤1:创建地理空间索引
javascript
db.restaurants.createIndex({ location: "2dsphere" })步骤2:插入带坐标的数据
javascript
db.restaurants.insertMany([
{
name: "北京烤鸭店",
location: { type: "Point", coordinates: [116.404, 39.915] },
address: "北京市东城区"
},
{
name: "上海小笼包",
location: { type: "Point", coordinates: [121.474, 31.230] },
address: "上海市黄浦区"
}
])步骤3:执行地理查询
javascript
// 查询1公里范围内的餐厅
db.restaurants.find({
location: {
$near: {
$geometry: { type: "Point", coordinates: [116.404, 39.915] },
$maxDistance: 1000 // 单位:米
}
}
})
// 多边形区域查询(电子围栏)
db.restaurants.find({
location: {
$geoWithin: {
$geometry: {
type: "Polygon",
coordinates: [[
[116.30, 39.90], [116.50, 39.90],
[116.50, 39.95], [116.30, 39.95],
[116.30, 39.90]
]]
}
}
}
})3. 性能优化技巧
javascript
// 复合索引提升查询性能
db.restaurants.createIndex({
location: "2dsphere",
rating: -1 // 评分降序
})
// 查询时按距离和评分排序
db.restaurants.find({
location: { $near: { ... } }
}).sort({ rating: -1 }).limit(10)三、MongoDB适用场景总结
| 场景 | 核心优势 | 典型案例 |
|---|---|---|
| 动态Schema | 无需预定义字段 | CMS系统、用户自定义表单 |
| 嵌套数据结构 | 减少关联查询 | 社交网络的用户档案、订单历史 |
| 高吞吐写入 | 适合日志、物联网数据 | 设备监控数据、点击流分析 |
| 地理空间查询 | 原生空间索引支持 | 外卖配送、共享单车定位 |
| 水平扩展 | 分片集群轻松扩容 | 海量用户数据的社交平台 |
四、MongoDB vs 关系型数据库选型
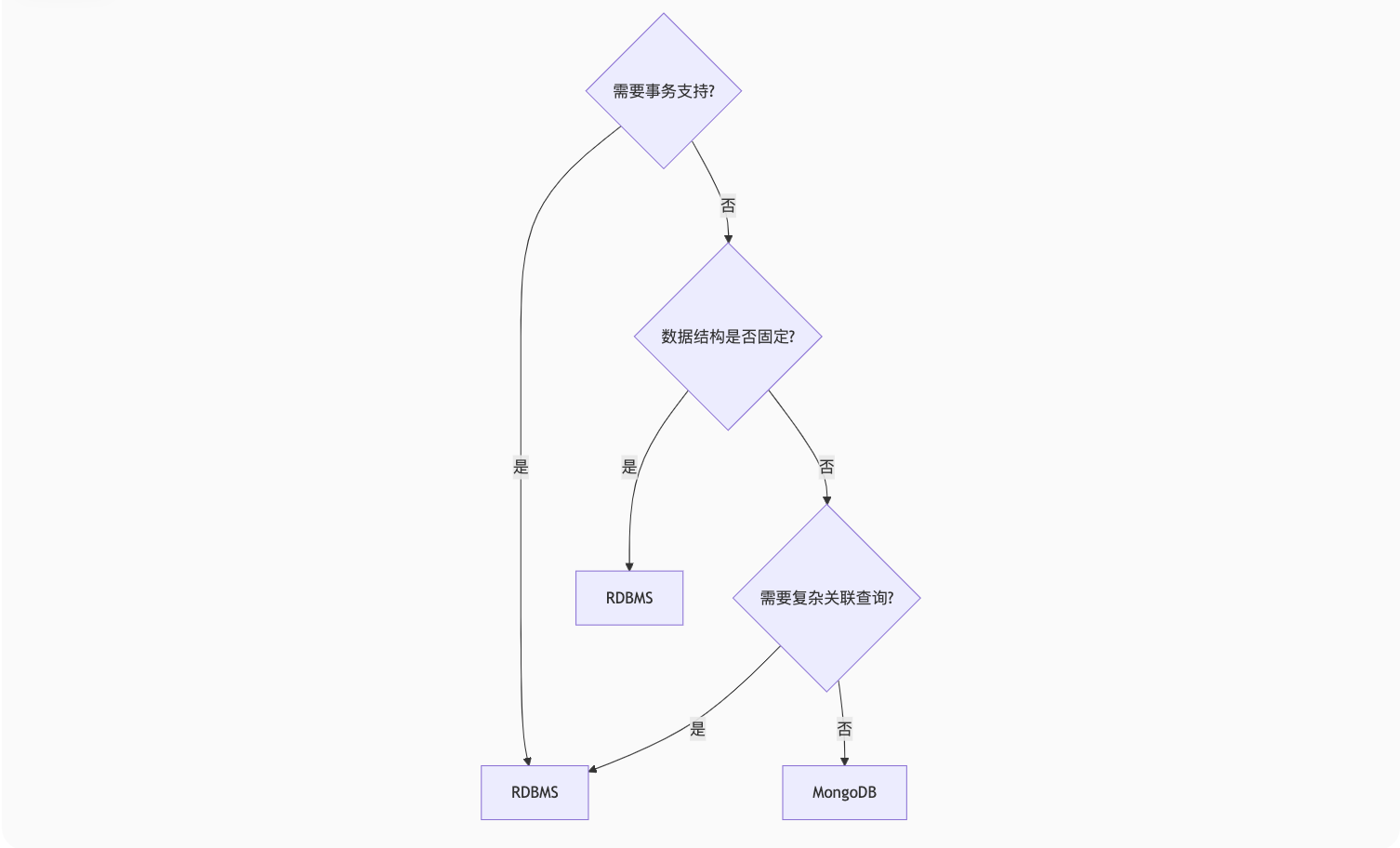
黄金法则:
-
选择MongoDB当:数据结构多变、需要快速迭代、读写比高
-
选择关系型数据库当:需要复杂事务、强一致性保证
五、实际应用架构案例
LBS平台技术栈:
javascript
前端 → API服务 → MongoDB分片集群(带2dsphere索引)
→ Redis缓存热点数据
→ Elasticsearch文本搜索文档设计技巧:
-
适度的数据冗余:在订单中嵌入商品快照,避免历史数据变动
-
引用式关联:超过16MB的文档考虑拆分引用
javascript// 用户基础信息 { _id: "user123", name: "李四", profile_id: "profile_user123" // 引用关联 } // 用户详情(大文档) { _id: "profile_user123", bio: "...", education: [...], work_history: [...] }
数据库性能调优实战指南
一、SQL语句优化
1. 慢查询定位
sql
-- MySQL开启慢查询日志
SET GLOBAL slow_query_log = ON;
SET GLOBAL long_query_time = 1; -- 超过1秒的记录2. EXPLAIN执行计划分析
sql
EXPLAIN SELECT * FROM orders WHERE user_id = 100 AND status = 'paid';关键字段解读:
-
type :
ALL(全表扫描)→ 需优化为range或ref -
key :
NULL表示未用索引 -
Extra :
Using filesort/Using temporary需警惕
3. 索引优化案例
问题SQL:
bash
SELECT * FROM users WHERE DATE(create_time) = '2023-08-20';优化方案:
sql
-- 改为范围查询
SELECT * FROM users
WHERE create_time BETWEEN '2023-08-20 00:00:00' AND '2023-08-20 23:59:59';
-- 添加索引
ALTER TABLE users ADD INDEX idx_create_time (create_time);二、索引设计策略
1. 最左前缀原则
sql
-- 复合索引 (status, create_time)
ALTER TABLE orders ADD INDEX idx_status_time (status, create_time);
-- 能使用索引的查询
SELECT * FROM orders WHERE status = 'paid';
SELECT * FROM orders WHERE status = 'paid' AND create_time > '2023-01-01';
-- 不能使用索引的查询
SELECT * FROM orders WHERE create_time > '2023-01-01'; -- 未用到最左列2. 覆盖索引优化
sql
-- 原始查询(需回表)
SELECT user_name, email FROM users WHERE age > 20;
-- 优化方案:创建覆盖索引
ALTER TABLE users ADD INDEX idx_age_name_email (age, user_name, email);3. 索引选择性原则
sql
-- 计算字段选择性(越接近1越好)
SELECT
COUNT(DISTINCT gender)/COUNT(*) AS gender_selectivity,
COUNT(DISTINCT phone)/COUNT(*) AS phone_selectivity
FROM users;三、数据库参数调优
1. InnoDB关键参数
sql
# my.cnf 配置示例
[mysqld]
innodb_buffer_pool_size = 12G # 建议物理内存的70%-80%
innodb_log_file_size = 2G # 重做日志大小
innodb_flush_log_at_trx_commit = 1 # 1=安全, 2=性能折衷
innodb_read_io_threads = 8 # 读线程数
innodb_write_io_threads = 4 # 写线程数2. 连接池配置
XML
# Spring Boot配置
spring:
datasource:
hikari:
maximum-pool-size: 20 # 根据CPU核心数调整
connection-timeout: 3000
idle-timeout: 600000四、分库分表策略
1. 水平分片规则
java
// 用户ID取模分片
public String getShard(String logicTable, long userId, int shardCount) {
int shardNo = (int) (userId % shardCount);
return logicTable + "_" + shardNo;
}2. 全局ID生成方案
java
// 雪花算法实现
public class SnowflakeIdGenerator {
private final long workerId;
private long sequence = 0L;
public synchronized long nextId() {
long timestamp = System.currentTimeMillis();
return ((timestamp - 1288834974657L) << 22) |
(workerId << 12) |
(sequence++ & 4095);
}
}五、锁优化实战
1. 减少锁竞争
sql
-- 悲观锁优化(缩小锁定范围)
BEGIN;
SELECT * FROM orders WHERE order_id = 1001 FOR UPDATE;
-- 处理业务...
COMMIT;
-- 乐观锁替代
UPDATE products
SET stock = stock - 1, version = version + 1
WHERE id = 1001 AND version = 5;2. 死锁监控
sql
-- 查看最近死锁信息
SHOW ENGINE INNODB STATUS\G
-- 锁等待监控
SELECT * FROM performance_schema.events_waits_current
WHERE EVENT_NAME LIKE '%lock%';六、缓存整合策略
1. 多级缓存架构
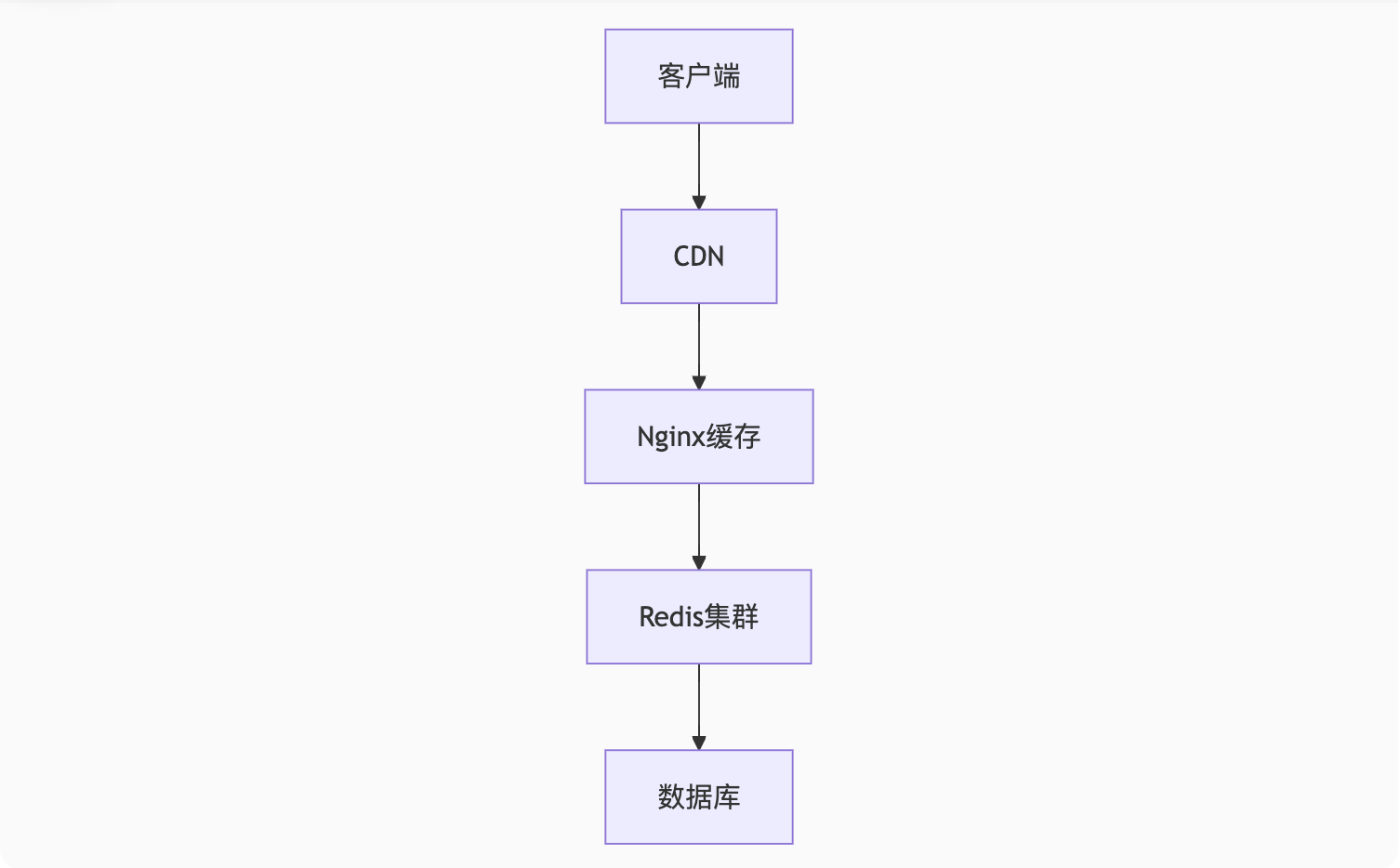
2. Redis缓存模式
java
// 缓存穿透防护
public Product getProduct(long id) {
// 1. 布隆过滤器预检
if (!bloomFilter.mightContain(id)) return null;
// 2. 查询缓存
Product product = redis.get("product:" + id);
if (product != null) return product;
// 3. 查询数据库
product = db.query("SELECT * FROM products WHERE id = ?", id);
redis.setex("product:" + id, 300, product == null ? "NULL" : product);
return product;
}七、监控与持续优化
1. 关键性能指标
| 指标 | 健康值 | 监控命令 |
|---|---|---|
| QPS | 根据硬件调整 | SHOW GLOBAL STATUS LIKE 'Questions' |
| 连接数利用率 | < 70% | SHOW STATUS LIKE 'Threads_connected' |
| 缓存命中率 | > 95% | SHOW STATUS LIKE 'Innodb_buffer_pool_hit_rate' |
2. 自动化运维工具
-
Percona Toolkit :
pt-query-digest分析慢日志 -
Prometheus + Grafana:可视化监控
-
Ansible:批量配置管理
性能调优速查表
| 问题类型 | 排查步骤 | 优化手段 |
|---|---|---|
| CPU利用率高 | 检查慢查询、全表扫描 | 添加索引、优化SQL |
| 内存不足 | 监控innodb_buffer_pool_hit |
增加innodb_buffer_pool_size |
| IO瓶颈 | 检查iowait和磁盘队列 |
使用SSD、调整innodb_io_capacity |
| 锁等待严重 | 分析SHOW ENGINE INNODB STATUS |
减少事务粒度、改用乐观锁 |
黄金法则:
-
先测量再优化 :用
EXPLAIN和慢查询日志定位问题 -
索引不是越多越好:每个索引增加写操作开销
-
避免过早优化:优先解决瓶颈最严重的20%问题
云原生数据库与分布式SQL引擎深度解析
一、云原生数据库
1. AWS Aurora架构(计算存储分离)
核心设计:
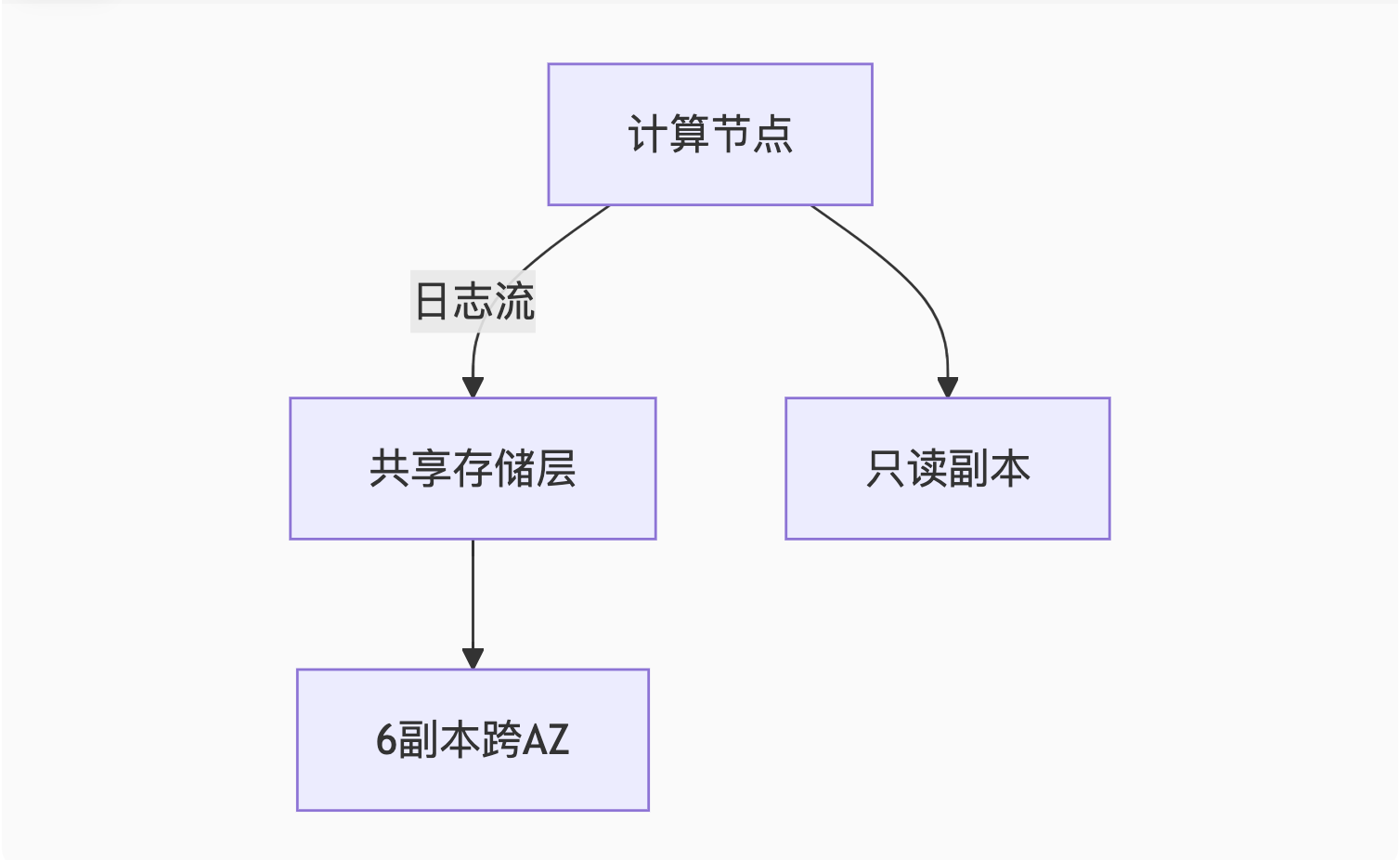
关键创新:
-
日志即数据库:仅同步redo日志而非数据页,网络开销降低90%
-
存储自动扩展:从10GB到128TB无缝扩容
-
快速故障恢复:秒级重建计算节点
性能对比:
| 指标 | Aurora MySQL | 标准RDS MySQL |
|---|---|---|
| 读吞吐量 | 5倍 | 基准 |
| 写吞吐量 | 3倍 | 基准 |
| 复制延迟 | <10ms | 100ms+ |
适用场景:
-
高可用企业应用(如金融交易系统)
-
需要秒级故障转移的关键业务
2. PolarDB HTAP(混合负载分析)
架构亮点:
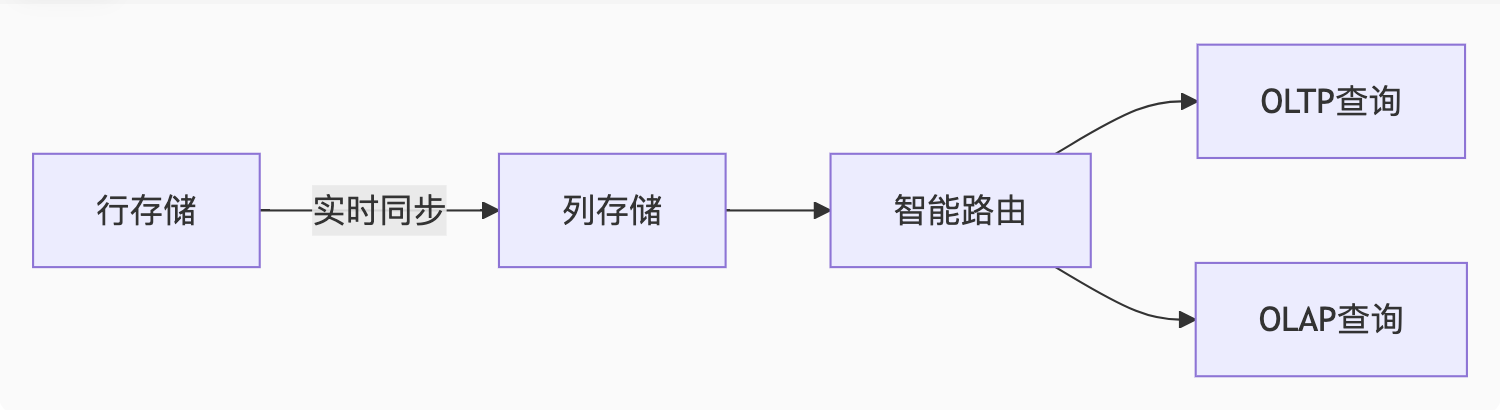
核心技术:
-
行列混存:TP引擎采用行存,AP引擎自动转列存
-
智能CBO:优化器自动选择执行引擎
-
内存计算:Apache Arrow内存格式加速分析
实战案例:
sql
-- 同一SQL同时服务交易和分析
BEGIN;
INSERT INTO orders VALUES(...); -- OLTP写入行存
COMMIT;
-- 立即分析(无需ETL)
SELECT user_id, SUM(amount)
FROM orders
WHERE create_time > NOW() - INTERVAL 1 DAY -- 智能路由到列存
GROUP BY user_id;性能收益:
-
分析查询比传统方案快10倍
-
资源隔离保证TP业务不受AP影响
二、分布式SQL引擎
1. TiDB(Raft+MVCC)
架构图解:
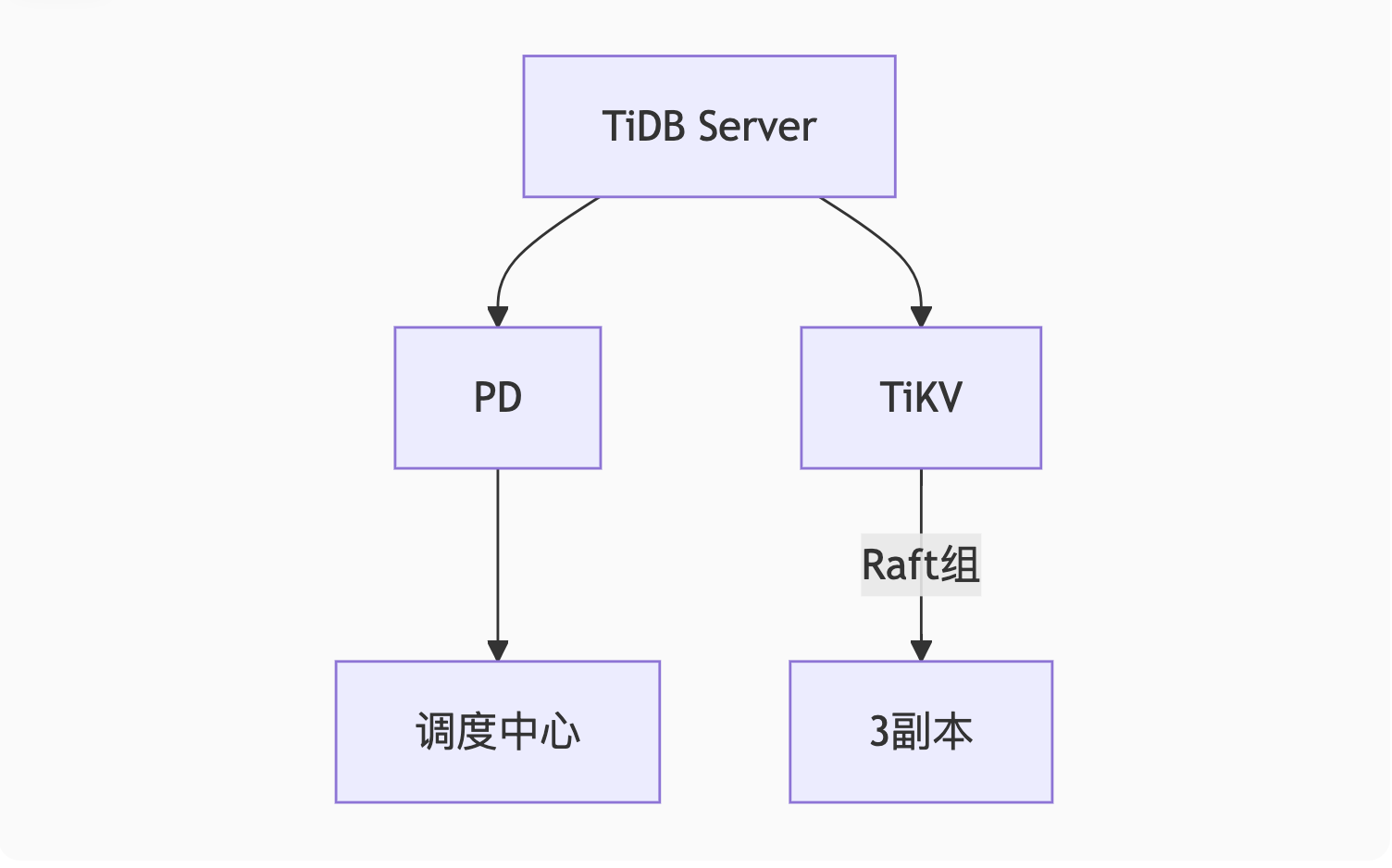
核心机制:
-
Multi-Raft:数据分片(Region)独立维护Raft组
-
分布式事务:
Go// Percolator模型实现 func Commit(txn *Transaction) { primaryLock := txn.Locks[0] if !checkLock(primaryLock) { txn.Rollback() } parallelCommitSecondaries(txn) // 异步提交二级锁 } -
混合部署:TiFlash列存节点实时同步行数据
典型应用:
-
替换MySQL分库分表(如58同城帖子库)
-
实时数仓(替代Hadoop+Spark批处理)
2. CockroachDB(Geo-Partitioning)
地理分区示例:
sql
-- 按地域分区用户表
CREATE TABLE users (
id UUID PRIMARY KEY,
name STRING,
region STRING AS (
CASE
WHEN country IN ('CN','JP','KR') THEN 'asia'
WHEN country IN ('US','CA') THEN 'america'
ELSE 'europe'
END
) STORED
) PARTITION BY LIST (region);
-- 自动将亚洲用户数据存储在东京机房
ALTER PARTITION asia CONFIGURE ZONE USING constraints = '[+region=asia]';全球部署优势:
-
低延迟访问:用户总是读写最近副本
-
弹性扩展:支持跨云多活(AWS+GCP+Azure)
-
强一致性:使用HLC时钟替代TrueTime
与Spanner对比:
| 特性 | CockroachDB | Google Spanner |
|---|---|---|
| 时钟依赖 | 无需原子钟 | 依赖TrueTime |
| 开源程度 | 完全开源 | 闭源+托管 |
| 地理分区灵活性 | 动态调整 | 需预定义 |
三、技术选型决策树
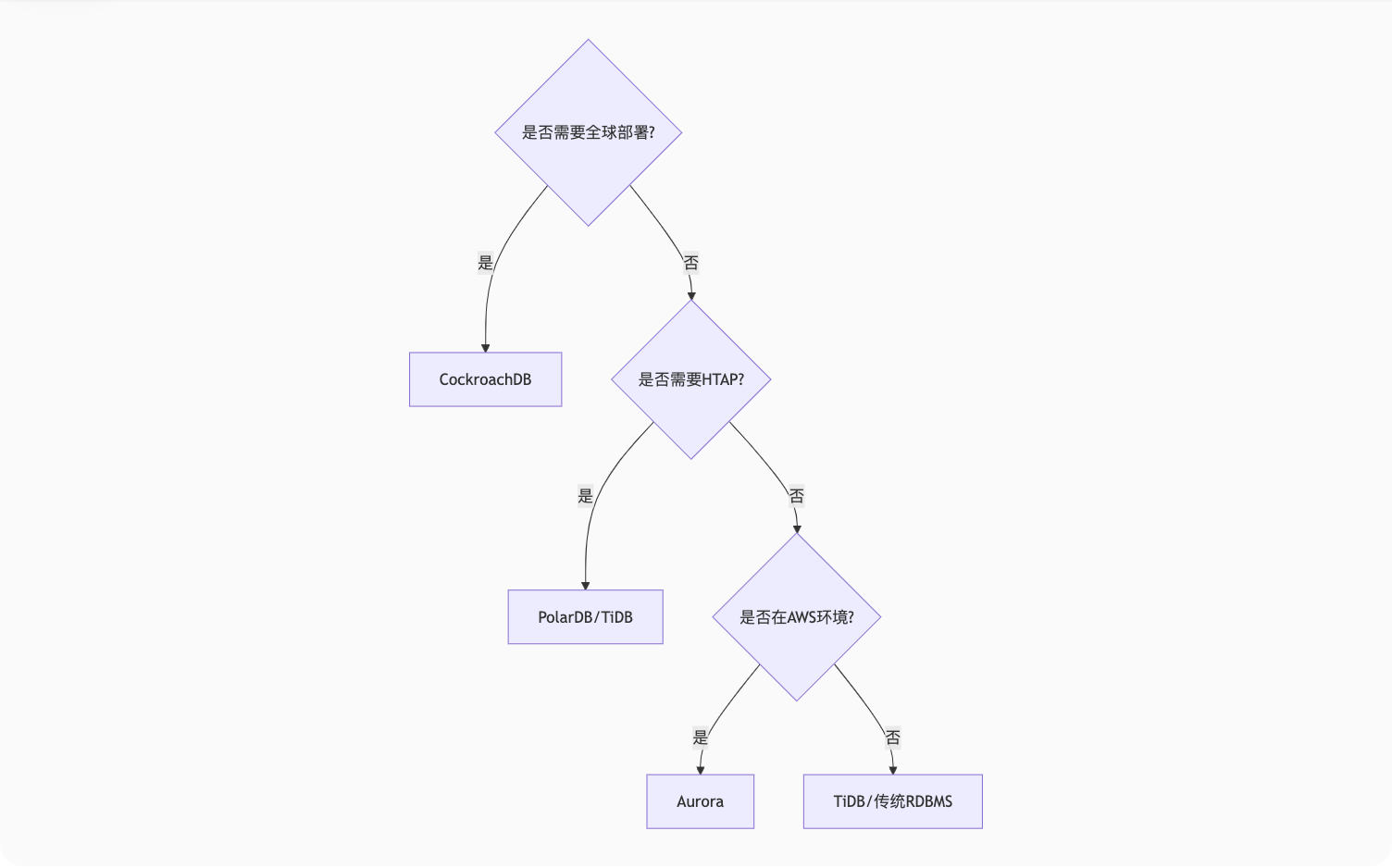
关键考量因素:
-
数据分布:全球业务选CockroachDB,国内业务选TiDB
-
负载类型:TP为主选Aurora,混合负载选PolarDB
-
技术栈:Go生态优选CockroachDB,Kubernetes友好选TiDB
四、未来趋势
-
Serverless数据库:如Aurora Serverless v2按用量自动扩缩容
-
AI优化器:TiDB 6.0引入机器学习索引推荐
-
多云协同:CockroachDB的多云联邦查询
数据库高级知识点深度解析
一、事务机制
1. MVCC实现原理(ReadView机制)
核心数据结构:
cpp
struct ReadView {
trx_id_t m_low_limit_id; // 高水位(大于此ID的事务不可见)
trx_id_t m_up_limit_id; // 低水位(小于此ID的事务均可见)
trx_id_t m_creator_trx_id; // 创建该ReadView的事务ID
ids_t m_ids; // 活跃事务ID列表
};可见性判断逻辑:
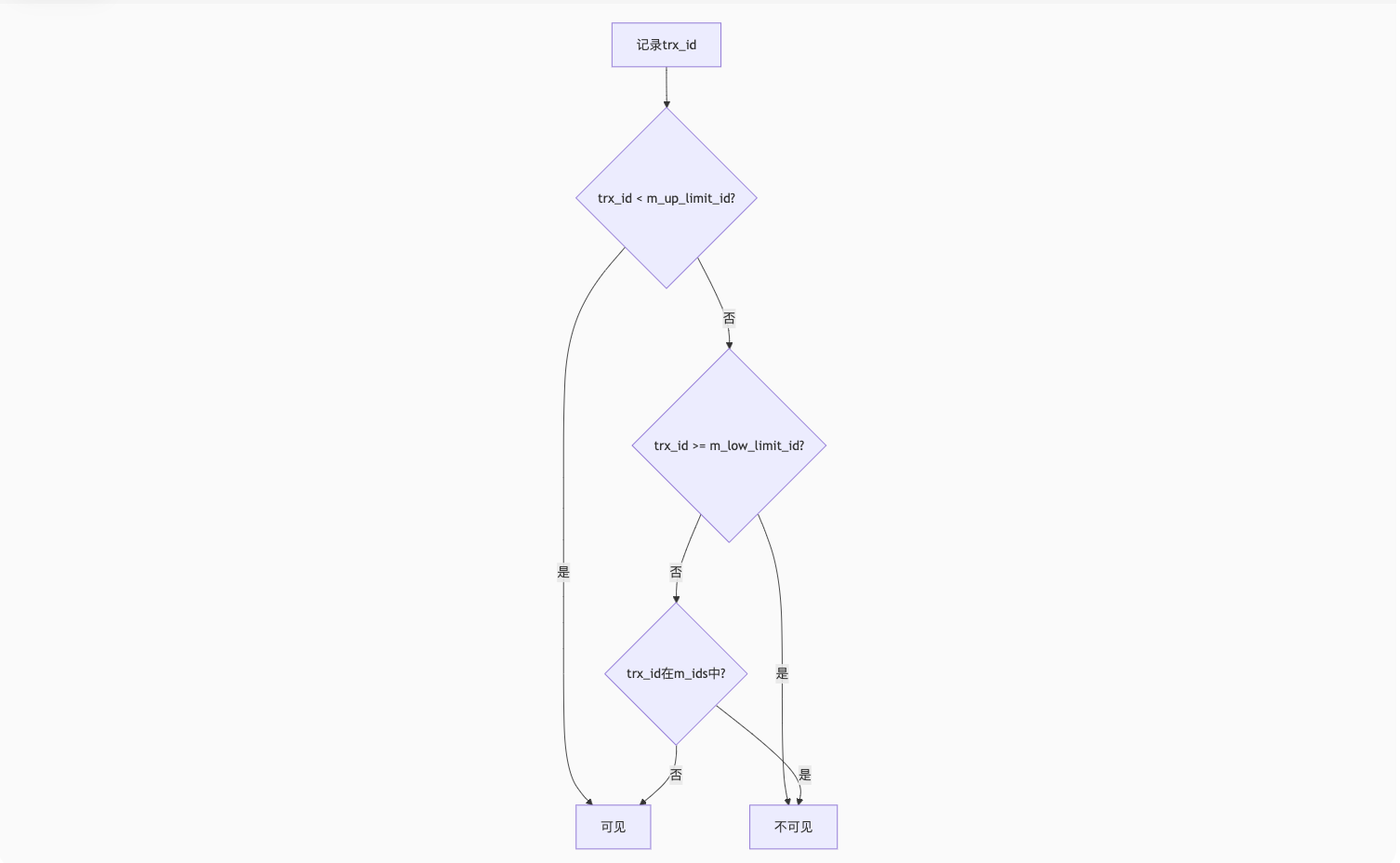
案例演示:
sql
-- 事务1(ID=100)
BEGIN;
UPDATE users SET name='Alice' WHERE id=1; -- 未提交
-- 事务2(ID=200)的ReadView:
-- m_up_limit_id=100, m_low_limit_id=201, m_ids=[100]
SELECT * FROM users WHERE id=1; -- 看到修改前的旧版本2. RR隔离级如何避免幻读?
Next-Key Lock锁机制:
sql
-- 表数据:id=5, 10, 15
BEGIN;
SELECT * FROM users WHERE id > 12 FOR UPDATE; -- 锁定(10,15], (15,+∞)区间
-- 其他事务无法插入id>12的记录实际锁范围:
sql
(-∞,5] (5,10] (10,15] (15,+∞)
^ ^
|_______| 被锁定的范围二、索引优化
1. 为什么索引列不能存NULL?
B+树存储问题:
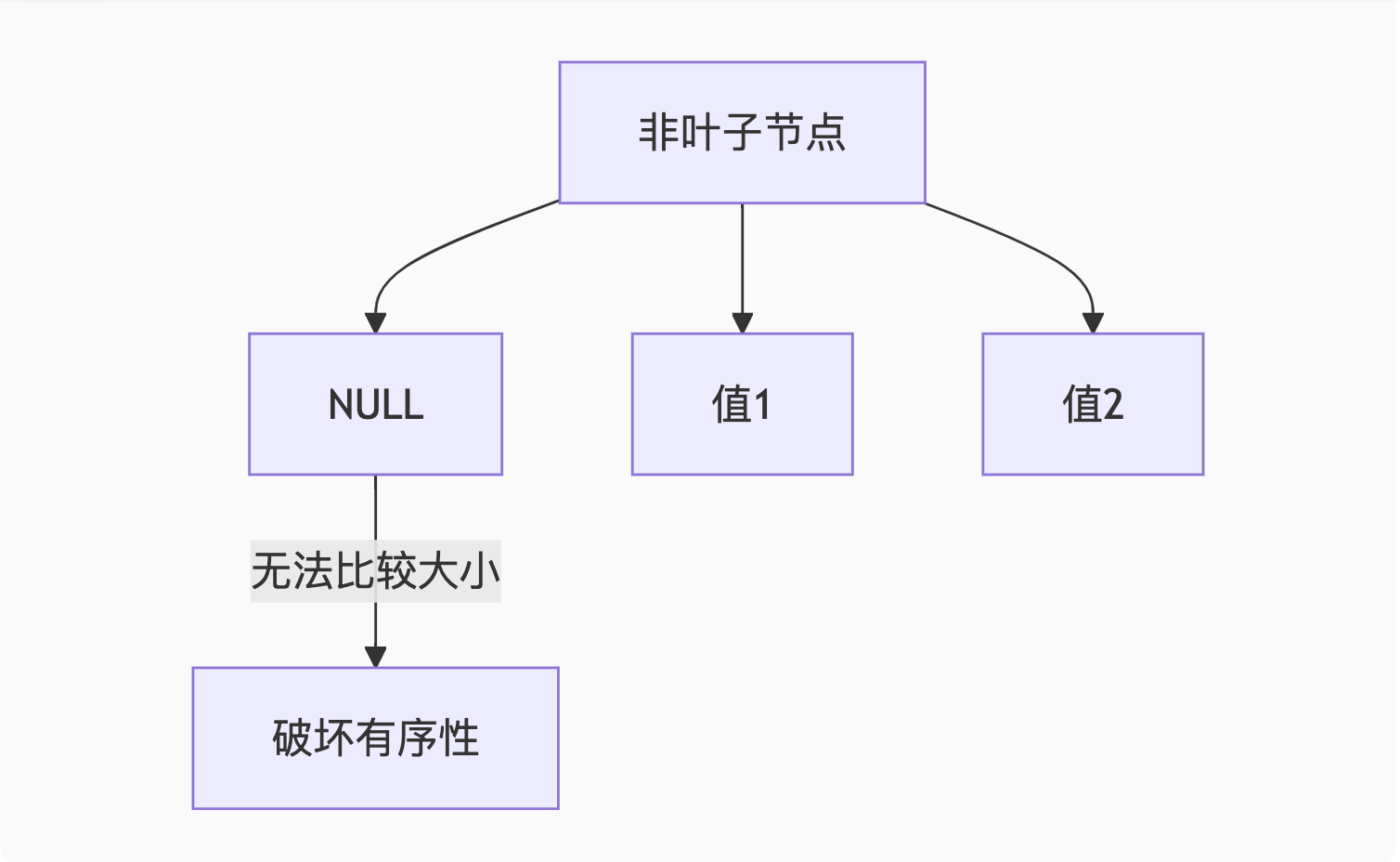 解决方案:
解决方案:
sql
-- 方案1:设置默认值
ALTER TABLE users MODIFY age INT DEFAULT 0;
-- 方案2:使用特殊值
ALTER TABLE products MODIFY price DECIMAL(10,2) DEFAULT -1;2. 联合索引(A,B,C)有效查询
| 查询条件 | 是否用索引 | 说明 |
|---|---|---|
| WHERE A=1 | ✅ | 使用最左列 |
| WHERE A=1 AND B=2 | ✅ | 使用前两列 |
| WHERE B=2 | ❌ | 不满足最左前缀 |
| WHERE A=1 AND C=3 | ✅ | 部分使用(仅A列) |
| WHERE A>1 AND B=2 | ✅ | 范围查询后停止匹配 |
| WHERE A=1 ORDER BY B | ✅ | 排序利用索引 |
三、系统设计实战
1. 点赞系统设计
高并发方案:
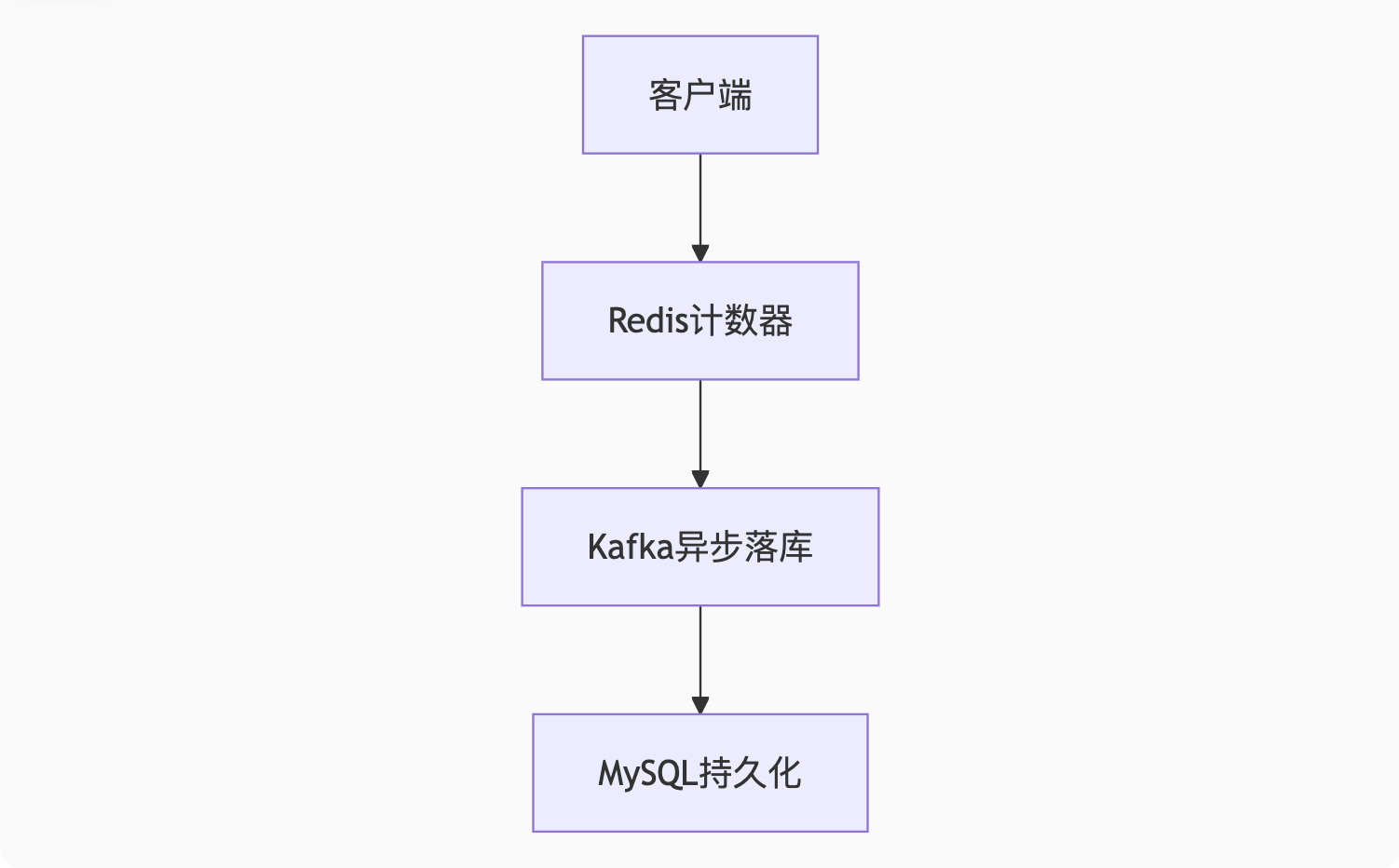
Redis数据结构:
bash
# 文章点赞数
INCR article:1001:likes
# 用户点赞记录(Set)
SADD user:123:liked 1001
# 判断是否已点赞
SISMEMBER user:123:liked 1001防刷策略:
-
用户ID + IP + 设备指纹多重校验
-
滑动窗口限流(如10秒内最多3次)
2. 深度分页优化(1000万数据)
问题SQL:
sql
SELECT * FROM orders ORDER BY id LIMIT 10000000, 10; -- 扫描10000010行优化方案:
sql
-- 方案1:游标分页(推荐)
SELECT * FROM orders WHERE id > 10000000 ORDER BY id LIMIT 10;
-- 方案2:延迟关联
SELECT t.* FROM orders t
JOIN (SELECT id FROM orders ORDER BY id LIMIT 10000000, 10) tmp
ON t.id = tmp.id;
-- 方案3:业务妥协(禁止跳页)
"只能下一页":传递last_id参数性能对比:
| 方案 | 耗时 | 缺点 |
|---|---|---|
| 传统LIMIT | 5.2秒 | 扫描全部数据 |
| 游标分页 | 0.01秒 | 需连续分页 |
| 延迟关联 | 1.8秒 | 仍需扫描索引 |
技术要点总结
-
MVCC本质:通过ReadView实现快照读,避免读写冲突
-
幻读防护:RR隔离级靠Next-Key Lock锁定范围+间隙
-
索引设计:NULL破坏B+树有序性,联合索引需遵循最左前缀
-
点赞系统:Redis抗并发 + 异步持久化保证最终一致
-
深度分页:用游标替代OFFSET是性能优化的关键