精彩专栏推荐订阅:在 下方专栏👇🏻👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖
文章目录
- 一、项目介绍
- 二、开发环境
- 三、视频展示
- 四、项目展示
- 五、代码展示
- 六、项目文档展示
- 七、总结
-
- [<font color=#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦👇🏻👇🏻👇🏻](#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦👇🏻👇🏻👇🏻)
一、项目介绍
随着中国老龄化进程加速,国家统计局数据显示,截至2022年底,我国60岁及以上人口已达2.8亿,占总人口的19.8%,预计到2035年将突破4亿,占比超过30%。面对如此庞大的老年群体,其健康状况直接关系到社会医疗资源分配和国家养老政策制定。传统老年健康数据分析方法难以应对海量、多维、异构的健康数据,难以挖掘深层次的健康规律和趋势。而大数据技术的发展为解决这一问题提供了新思路。卫健委《"健康中国2030"规划纲要》明确提出要"推进健康医疗大数据应用",建设"覆盖全民的健康信息平台"。在此背景下,开发基于Spark的全国健康老龄化数据分析系统,利用Hadoop、Spark等大数据技术,结合Python、Django、Vue和Echarts等开发工具,构建全面的老年健康数据分析平台,对促进健康老龄化具有重要意义。
本系统的开发具有多方面的现实意义。在医疗资源优化方面,通过分析老年人就医频率与健康状况的关系,能够帮助医疗机构更合理地配置资源,减少浪费,提高服务效率。对政策制定而言,系统提供的老年人健康风险聚类分析结果,可为分层分类的老年健康政策提供数据支持,使政策更具针对性。从预防医学角度看,系统能够识别高风险老年群体的特征,为早期干预提供依据,降低疾病发生率。对老年人自身来说,系统生成的多维健康评分可以增强健康自我管理意识,改善生活质量。技术层面上,该系统将Spark大数据处理与健康老龄化领域深度融合,探索了大数据技术在特定垂直领域的应用模式,为类似系统的开发提供了参考框架。这些价值使得本系统不仅是一个技术实现,更是解决社会现实问题的有效工具。
二、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts
- 软件工具:Pycharm、DataGrip、Anaconda
- 可视化 工具 Echarts
三、视频展示
计算机大数据专业选题推荐-基于大数据的全国健康老龄化数据分析系统【Hadoop、Spark、大屏可视化】
四、项目展示
登录模块:

可视化分析模块:
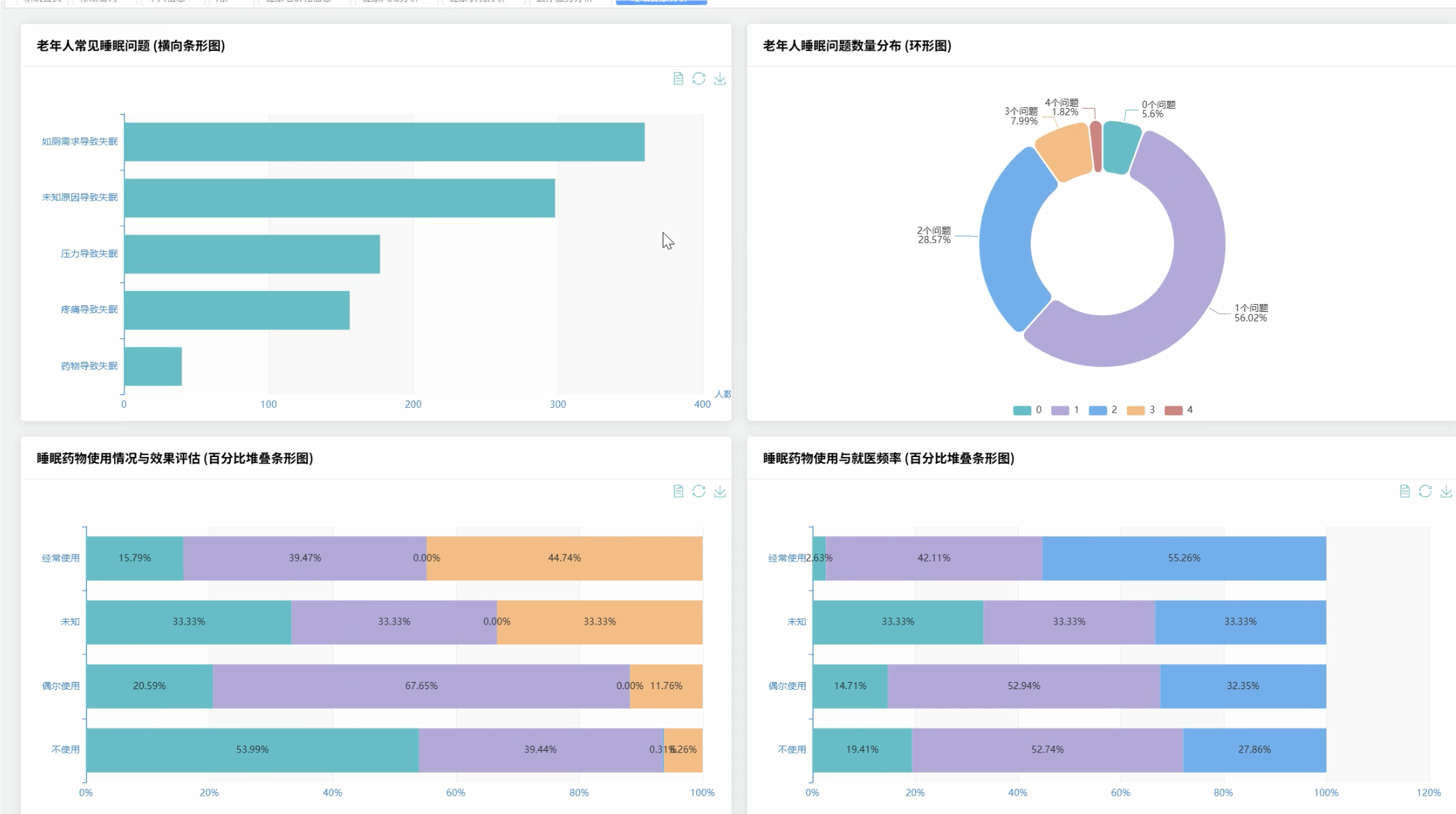
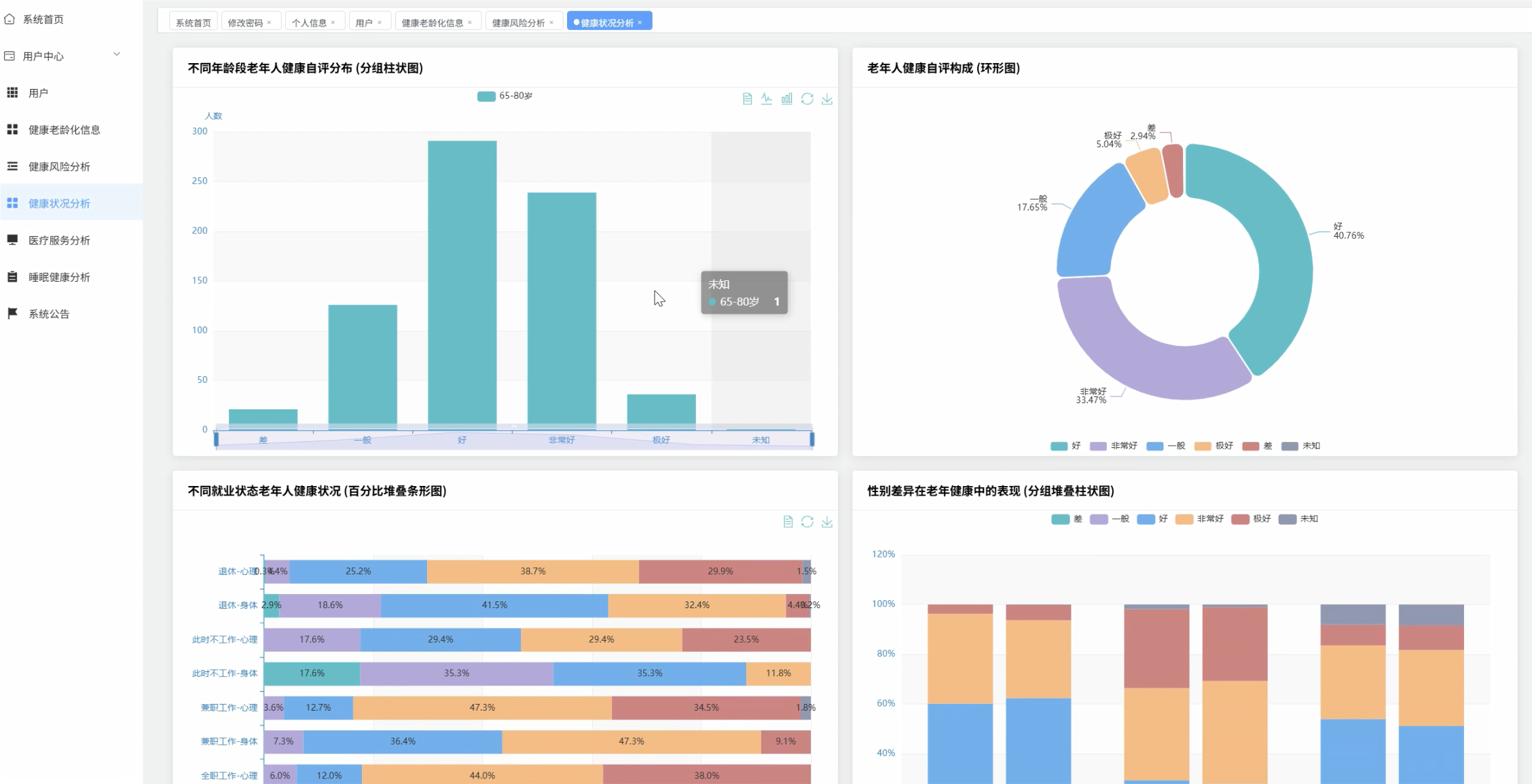
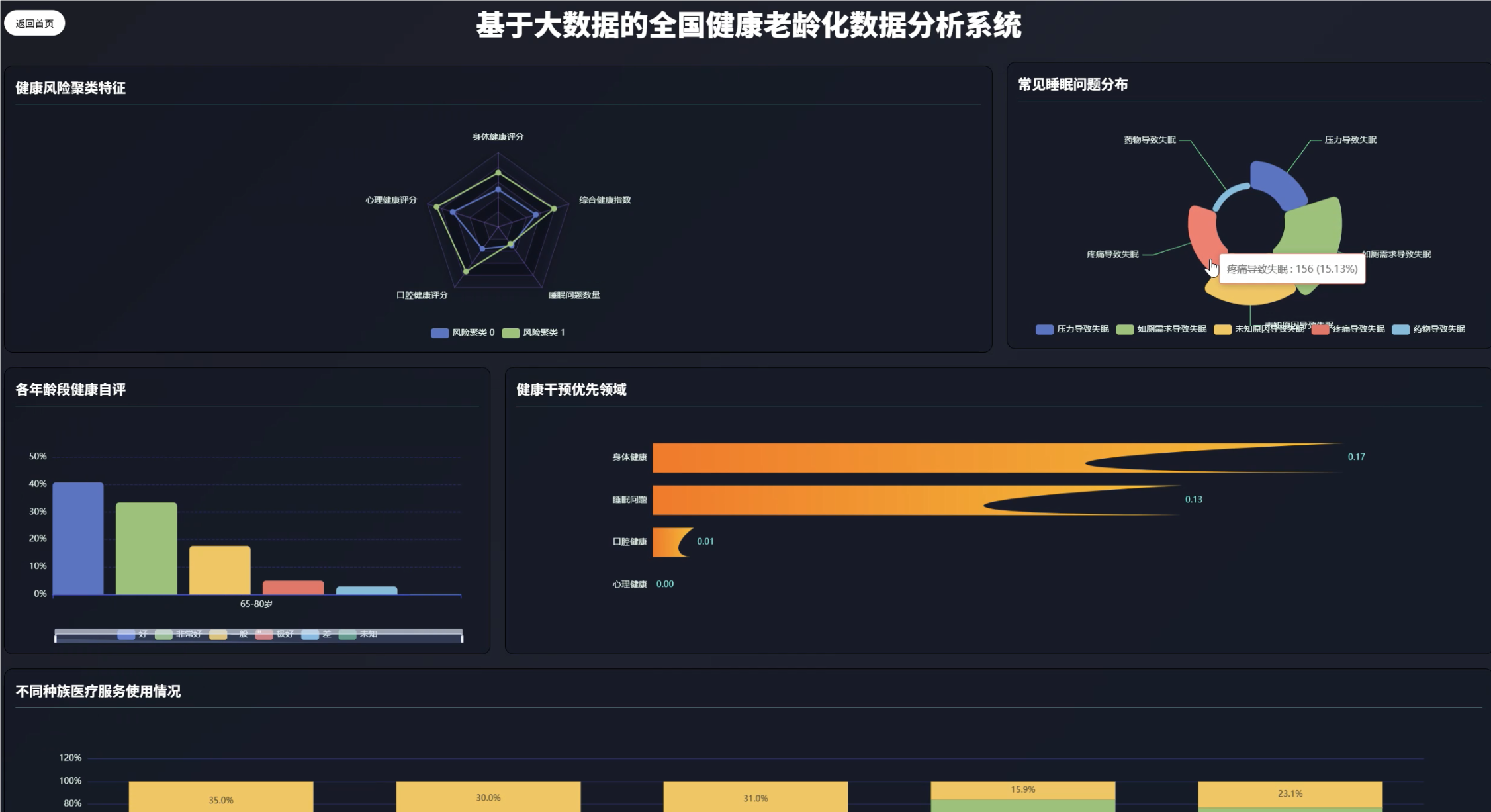
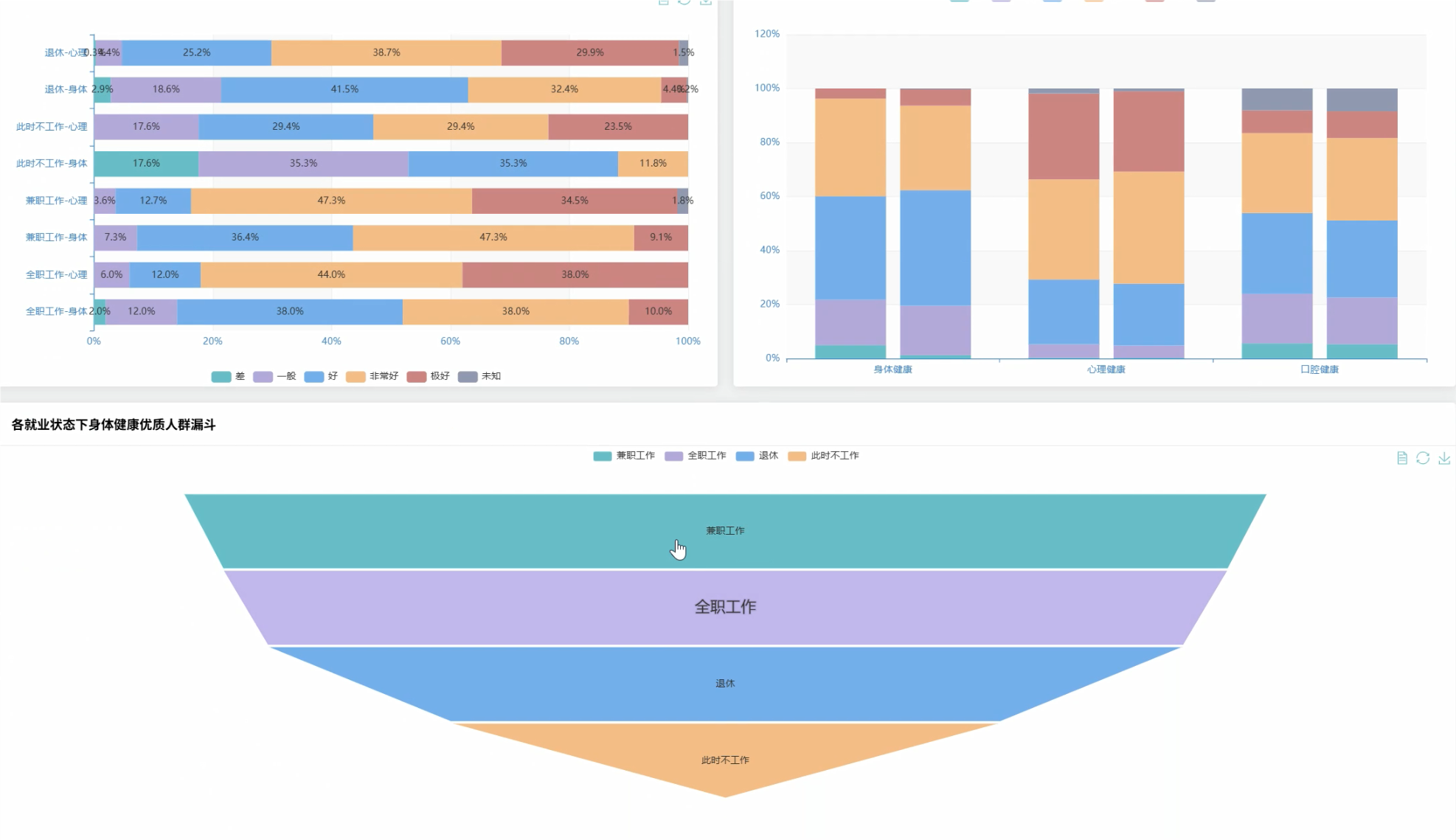
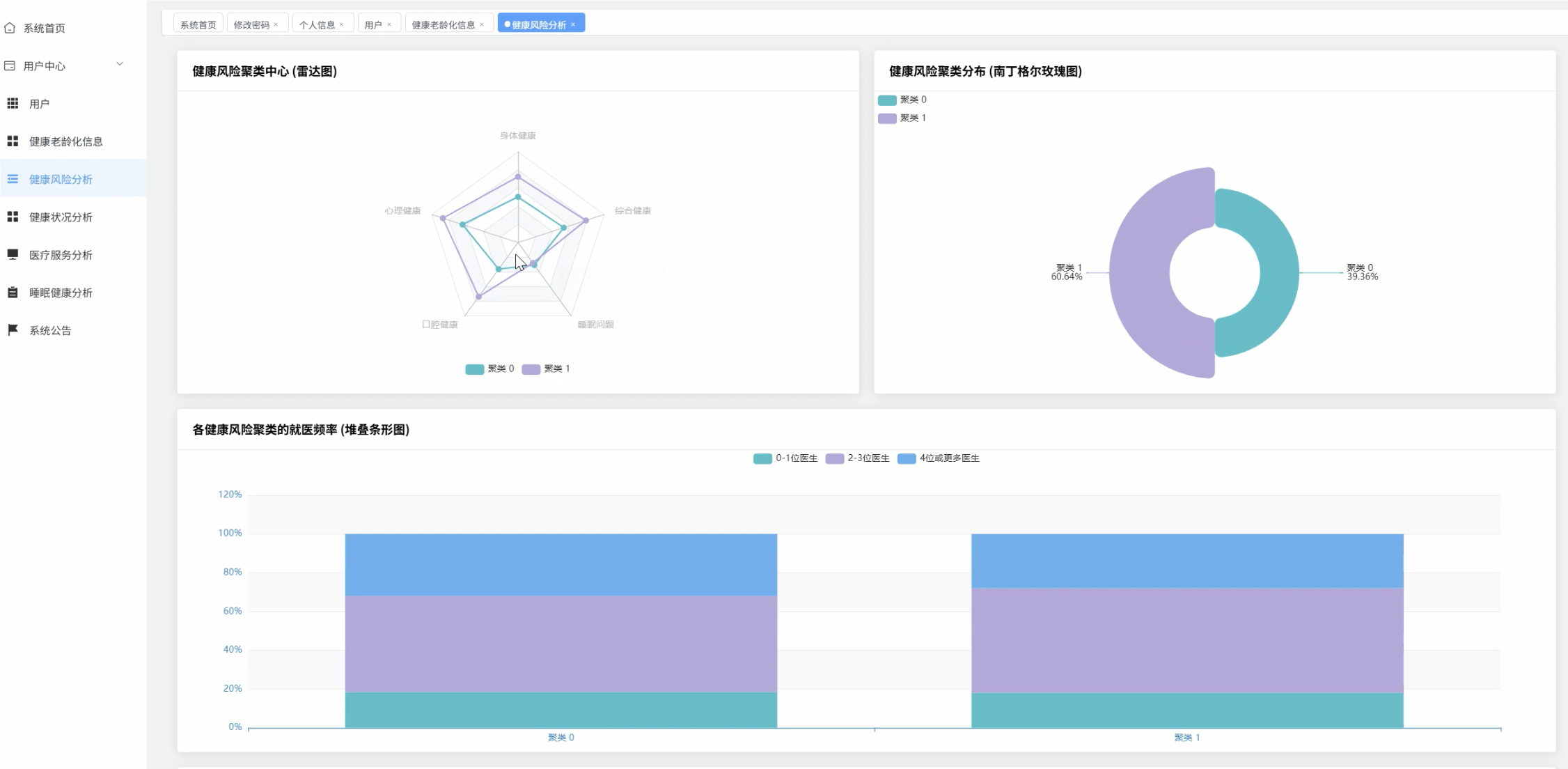
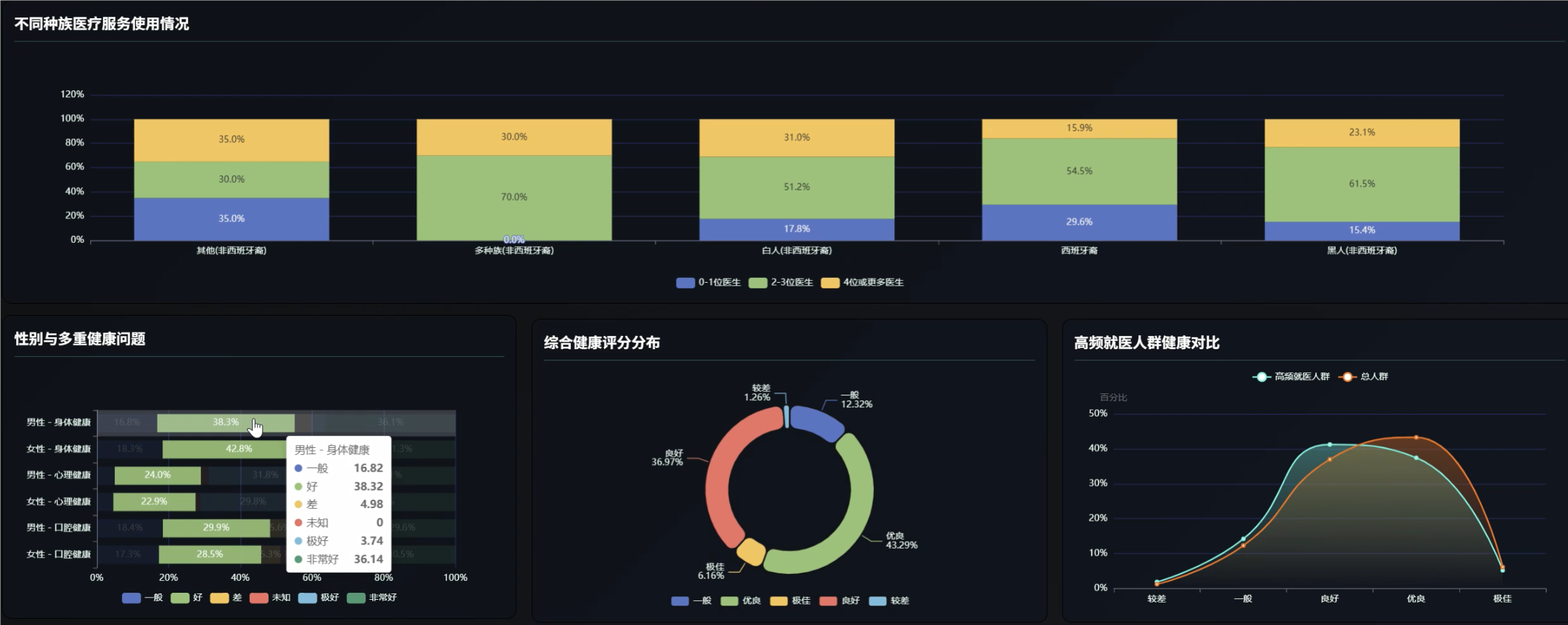
五、代码展示
bash
# 核心功能1: 老年人健康风险聚类分析
def health_risk_clustering(spark_session, data_path):
# 读取健康数据
health_df = spark_session.read.parquet(data_path)
# 数据预处理
from pyspark.sql.functions import col, when, isnull
processed_df = health_df.select(
"id", "age", "gender", "physical_health", "mental_health",
"dental_health", "trouble_sleeping", "number_of_doctors_visited"
).na.fill({
"physical_health": 0,
"mental_health": 0,
"dental_health": 0,
"trouble_sleeping": 0
})
# 特征工程 - 创建健康风险指标
from pyspark.sql.functions import expr
feature_df = processed_df.withColumn(
"health_risk_index",
expr("physical_health * 0.4 + mental_health * 0.3 + dental_health * 0.2 + trouble_sleeping * 0.1")
).withColumn(
"medical_dependency",
when(col("number_of_doctors_visited") >= 3, 1.0).otherwise(0.0)
)
# 将Spark DataFrame转换为用于机器学习的特征向量
from pyspark.ml.feature import VectorAssembler
assembler = VectorAssembler(
inputCols=["age", "physical_health", "mental_health", "dental_health",
"trouble_sleeping", "health_risk_index", "medical_dependency"],
outputCol="features"
)
vector_df = assembler.transform(feature_df)
# 应用K-means聚类算法
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
# 尝试不同的k值以找到最佳聚类数
silhouette_scores = []
for k in range(2, 8):
kmeans = KMeans(k=k, seed=42)
model = kmeans.fit(vector_df)
predictions = model.transform(vector_df)
# 评估聚类效果
evaluator = ClusteringEvaluator()
silhouette = evaluator.evaluate(predictions)
silhouette_scores.append((k, silhouette))
# 选择最佳k值
best_k = max(silhouette_scores, key=lambda x: x[1])[0]
# 使用最佳k值进行最终聚类
final_kmeans = KMeans(k=best_k, seed=42)
final_model = final_kmeans.fit(vector_df)
clustered_df = final_model.transform(vector_df)
# 分析各聚类的特征
cluster_centers = final_model.clusterCenters()
cluster_profiles = []
for i, center in enumerate(cluster_centers):
cluster_df = clustered_df.filter(col("prediction") == i)
cluster_size = cluster_df.count()
avg_age = cluster_df.agg({"age": "avg"}).collect()[0][0]
avg_health_risk = cluster_df.agg({"health_risk_index": "avg"}).collect()[0][0]
high_med_dependency = cluster_df.filter(col("medical_dependency") == 1.0).count() / cluster_size
cluster_profiles.append({
"cluster_id": i,
"size": cluster_size,
"avg_age": avg_age,
"avg_health_risk": avg_health_risk,
"high_medical_dependency_ratio": high_med_dependency,
"center_features": center.toArray()
})
return {
"cluster_profiles": cluster_profiles,
"clustered_data": clustered_df,
"best_k": best_k
}
# 核心功能2: 老年人睡眠健康与生活质量分析
def sleep_health_analysis(spark_session, data_path):
# 读取睡眠健康相关数据
sleep_df = spark_session.read.parquet(data_path)
# 数据预处理 - 提取睡眠相关变量
from pyspark.sql.functions import col, when, lit, expr
sleep_factors_df = sleep_df.select(
"id", "age", "gender", "physical_health", "mental_health",
"trouble_sleeping", "stress_keeps_from_sleeping", "medication_keeps_from_sleeping",
"pain_keeps_from_sleeping", "bathroom_needs_keeps_from_sleeping",
"unknown_keeps_from_sleeping", "prescription_sleep_medication",
"number_of_doctors_visited"
)
# 创建睡眠问题复杂度指标
sleep_complexity_df = sleep_factors_df.withColumn(
"sleep_problem_count",
(col("stress_keeps_from_sleeping").cast("int") +
col("medication_keeps_from_sleeping").cast("int") +
col("pain_keeps_from_sleeping").cast("int") +
col("bathroom_needs_keeps_from_sleeping").cast("int") +
col("unknown_keeps_from_sleeping").cast("int"))
).withColumn(
"sleep_complexity_score",
when(col("sleep_problem_count") == 0, 0)
.when(col("sleep_problem_count") == 1, 1)
.when(col("sleep_problem_count") == 2, 3)
.when(col("sleep_problem_count") >= 3, 5)
)
# 分析睡眠问题与健康状况的关系
from pyspark.sql.functions import avg, count, sum, stddev, corr
# 计算各睡眠因素的分布情况
sleep_factors_distribution = sleep_factors_df.agg(
avg("stress_keeps_from_sleeping").alias("stress_factor_ratio"),
avg("medication_keeps_from_sleeping").alias("medication_factor_ratio"),
avg("pain_keeps_from_sleeping").alias("pain_factor_ratio"),
avg("bathroom_needs_keeps_from_sleeping").alias("bathroom_factor_ratio"),
avg("unknown_keeps_from_sleeping").alias("unknown_factor_ratio")
).collect()[0]
# 分析睡眠困难与健康自评的相关性
sleep_health_corr = sleep_complexity_df.select(
corr("trouble_sleeping", "physical_health").alias("sleep_physical_corr"),
corr("trouble_sleeping", "mental_health").alias("sleep_mental_corr"),
corr("sleep_complexity_score", "physical_health").alias("complexity_physical_corr"),
corr("sleep_complexity_score", "mental_health").alias("complexity_mental_corr")
).collect()[0]
# 分析睡眠药物使用情况与效果
medication_analysis = sleep_complexity_df.groupBy("prescription_sleep_medication").agg(
avg("trouble_sleeping").alias("avg_sleep_trouble"),
avg("number_of_doctors_visited").alias("avg_doctor_visits"),
count("id").alias("patient_count")
).collect()
# 压力与睡眠健康的关系分析
stress_impact = sleep_complexity_df.filter(col("stress_keeps_from_sleeping") == True).agg(
avg("mental_health").alias("avg_mental_health"),
avg("physical_health").alias("avg_physical_health"),
avg("number_of_doctors_visited").alias("avg_doctor_visits")
).collect()[0]
# 疼痛与睡眠质量研究
pain_impact = sleep_complexity_df.filter(col("pain_keeps_from_sleeping") == True).agg(
avg("physical_health").alias("avg_physical_health"),
avg("number_of_doctors_visited").alias("avg_doctor_visits"),
count("id").alias("patient_count")
).collect()[0]
# 睡眠问题复杂度与健康状况的关系
complexity_health_relation = sleep_complexity_df.groupBy("sleep_complexity_score").agg(
avg("physical_health").alias("avg_physical_health"),
avg("mental_health").alias("avg_mental_health"),
avg("number_of_doctors_visited").alias("avg_doctor_visits"),
count("id").alias("patient_count")
).orderBy("sleep_complexity_score").collect()
# 年龄段与睡眠问题的关系
age_sleep_relation = sleep_complexity_df.withColumn(
"age_group",
when(col("age") < 65, "50-64")
.when(col("age") <= 80, "65-80")
.otherwise("80+")
).groupBy("age_group").agg(
avg("trouble_sleeping").alias("avg_sleep_trouble"),
avg("sleep_complexity_score").alias("avg_sleep_complexity"),
count("id").alias("patient_count")
).orderBy("age_group").collect()
return {
"sleep_factors_distribution": sleep_factors_distribution,
"sleep_health_correlation": sleep_health_corr,
"medication_analysis": medication_analysis,
"stress_impact": stress_impact,
"pain_impact": pain_impact,
"complexity_health_relation": complexity_health_relation,
"age_sleep_relation": age_sleep_relation
}
# 核心功能3: 多维健康评分体系构建与医疗需求分析
def health_scoring_system(spark_session, data_path):
# 读取健康数据
health_df = spark_session.read.parquet(data_path)
# 数据预处理
from pyspark.sql.functions import col, when, lit, expr, udf
from pyspark.sql.types import FloatType, StringType
processed_df = health_df.select(
"id", "age", "gender", "race", "employment",
"physical_health", "mental_health", "dental_health",
"trouble_sleeping", "number_of_doctors_visited"
).na.fill({
"physical_health": 0,
"mental_health": 0,
"dental_health": 0,
"trouble_sleeping": 0
})
# 构建多维健康评分
# 1. 身体健康评分 (占总分40%)
# 2. 心理健康评分 (占总分30%)
# 3. 口腔健康评分 (占总分15%)
# 4. 睡眠健康评分 (占总分15%)
# 对各维度进行归一化处理 (假设原始分数范围为0-10,越高表示问题越严重)
health_scored_df = processed_df.withColumn(
"physical_score", (10 - col("physical_health")) / 10 * 40
).withColumn(
"mental_score", (10 - col("mental_health")) / 10 * 30
).withColumn(
"dental_score", (10 - col("dental_health")) / 10 * 15
).withColumn(
"sleep_score", (10 - col("trouble_sleeping")) / 10 * 15
).withColumn(
"total_health_score",
col("physical_score") + col("mental_score") + col("dental_score") + col("sleep_score")
)
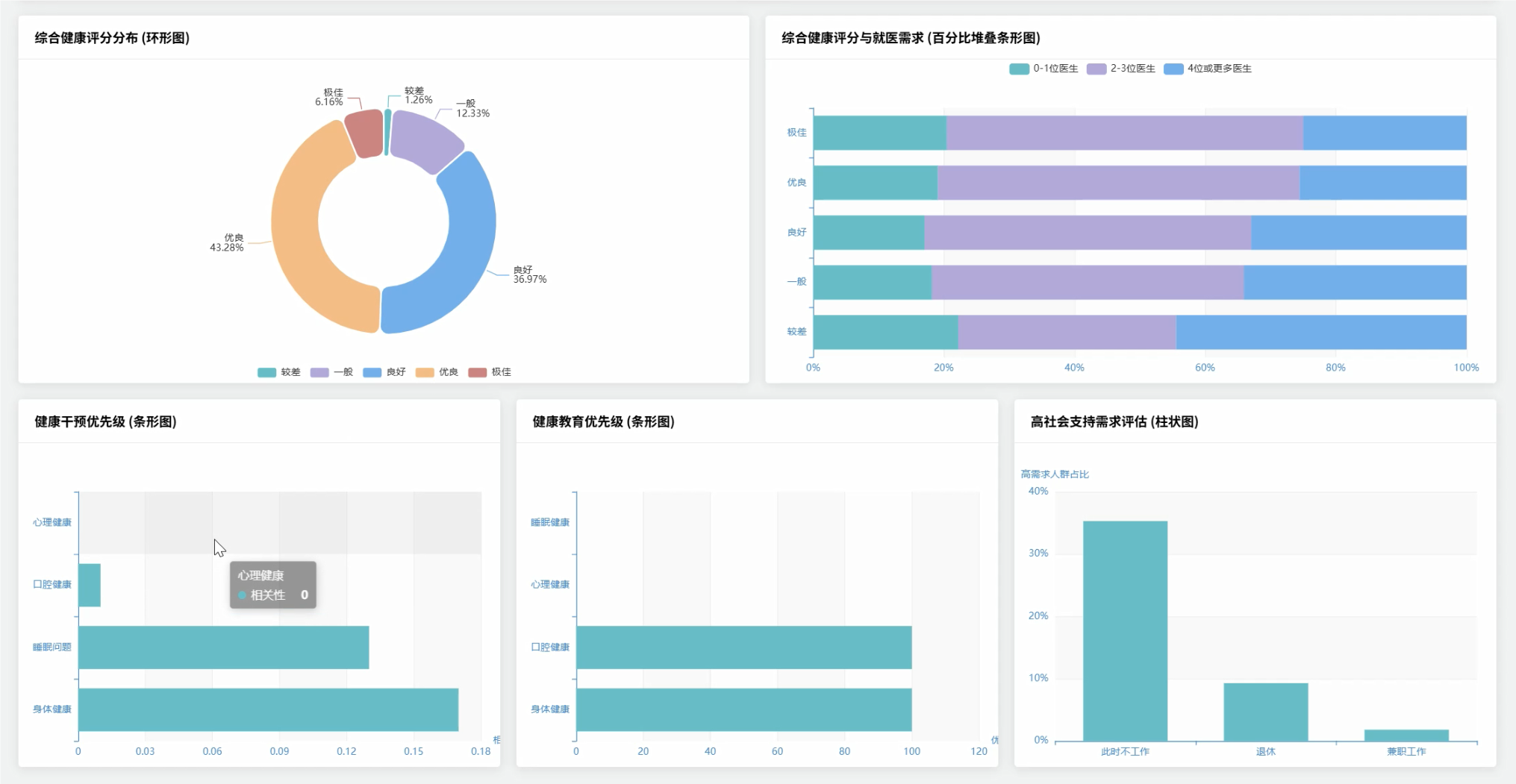
# 根据总分划分健康等级
health_graded_df = health_scored_df.withColumn(
"health_grade",
when(col("total_health_score") >= 85, "优秀")
.when(col("total_health_score") >= 70, "良好")
.when(col("total_health_score") >= 60, "一般")
.when(col("total_health_score") >= 50, "较差")
.otherwise("差")
)
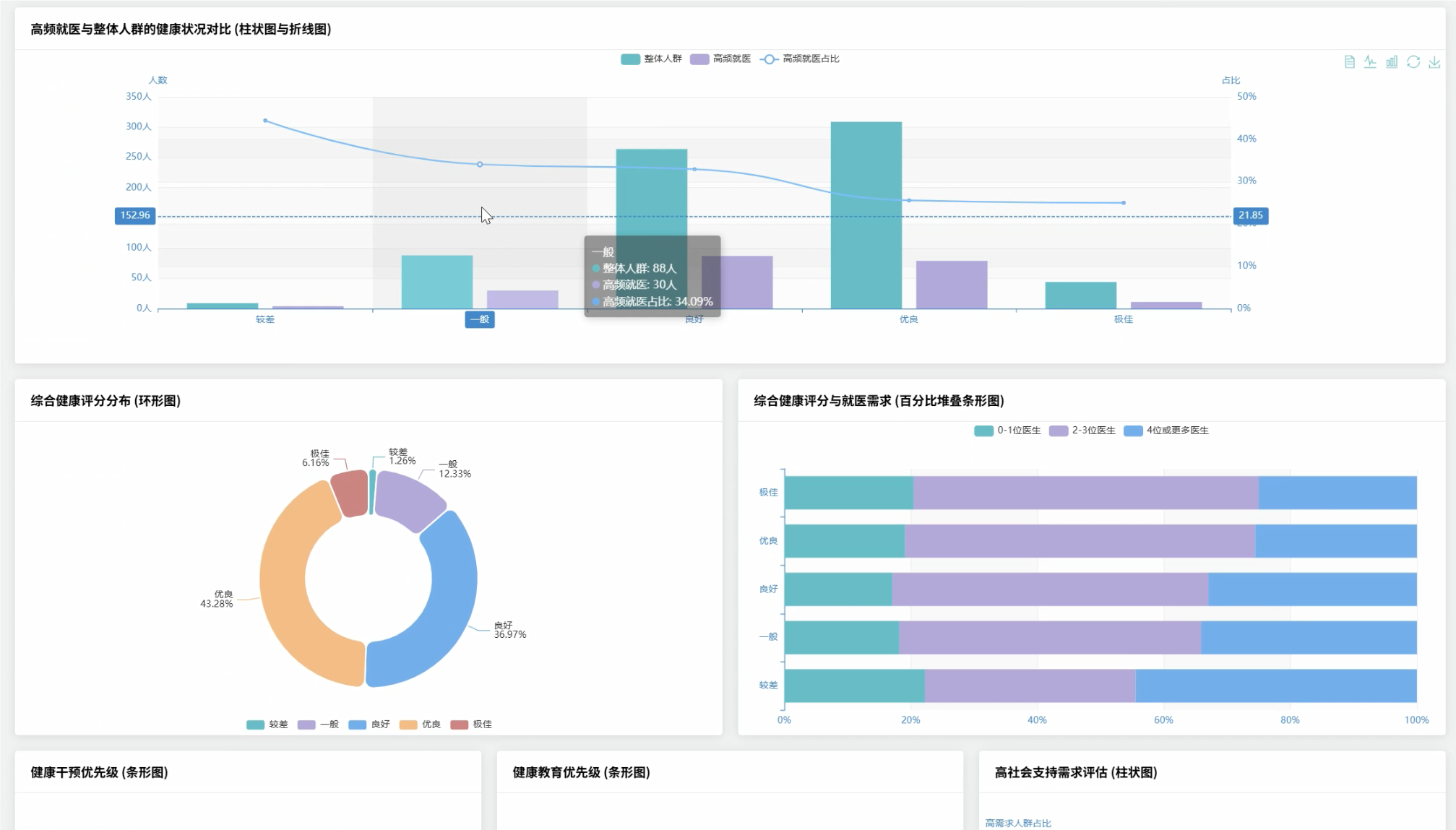
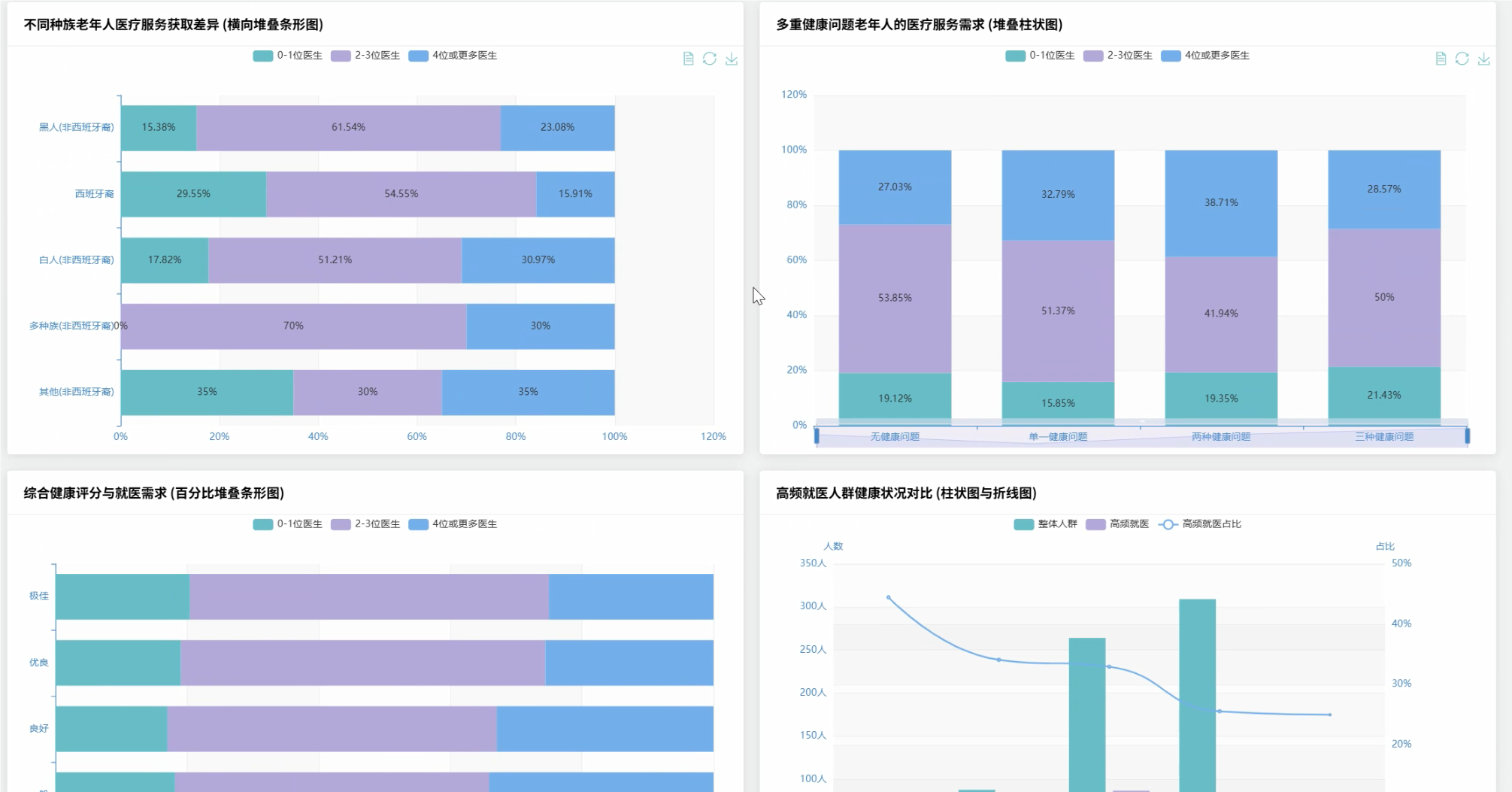
# 分析健康评分与就医需求的关系
from pyspark.sql.functions import avg, count, sum, stddev, corr
# 计算健康评分与就医频率的相关性
score_medical_corr = health_graded_df.select(
corr("total_health_score", "number_of_doctors_visited").alias("score_visit_correlation")
).collect()[0]
# 分析不同健康等级的就医频率
grade_medical_relation = health_graded_df.groupBy("health_grade").agg(
avg("number_of_doctors_visited").alias("avg_doctor_visits"),
count("id").alias("patient_count")
).orderBy("health_grade").collect()
# 识别高频就医人群的健康特征
high_medical_users = health_graded_df.filter(col("number_of_doctors_visited") >= 3)
high_medical_profile = high_medical_users.agg(
avg("total_health_score").alias("avg_health_score"),
avg("physical_score").alias("avg_physical_score"),
avg("mental_score").alias("avg_mental_score"),
avg("dental_score").alias("avg_dental_score"),
avg("sleep_score").alias("avg_sleep_score"),
count("id").alias("patient_count")
).collect()[0]
# 分析不同人口特征的健康评分分布
# 年龄段分析
age_health_relation = health_graded_df.withColumn(
"age_group",
when(col("age") < 65, "50-64")
.when(col("age") <= 80, "65-80")
.otherwise("80+")
).groupBy("age_group").agg(
avg("total_health_score").alias("avg_health_score"),
avg("physical_score").alias("avg_physical_score"),
avg("mental_score").alias("avg_mental_score"),
count("id").alias("patient_count")
).orderBy("age_group").collect()
# 性别分析
gender_health_relation = health_graded_df.groupBy("gender").agg(
avg("total_health_score").alias("avg_health_score"),
avg("physical_score").alias("avg_physical_score"),
avg("mental_score").alias("avg_mental_score"),
count("id").alias("patient_count")
).collect()
# 种族分析
race_health_relation = health_graded_df.groupBy("race").agg(
avg("total_health_score").alias("avg_health_score"),
avg("number_of_doctors_visited").alias("avg_doctor_visits"),
count("id").alias("patient_count")
).collect()
# 就业状态分析
employment_health_relation = health_graded_df.groupBy("employment").agg(
avg("total_health_score").alias("avg_health_score"),
avg("physical_score").alias("avg_physical_score"),
avg("mental_score").alias("avg_mental_score"),
count("id").alias("patient_count")
).collect()
# 识别健康自我管理能力较强的群体特征
good_self_managers = health_graded_df.filter(
(col("physical_score") >= 30) &
(col("sleep_score") >= 12) &
(col("number_of_doctors_visited") <= 1)
)
self_management_profile = good_self_managers.agg(
avg("age").alias("avg_age"),
count("id").alias("patient_count")
).collect()[0]
return {
"health_scored_data": health_graded_df,
"score_medical_correlation": score_medical_corr,
"grade_medical_relation": grade_medical_relation,
"high_medical_users_profile": high_medical_profile,
"age_health_relation": age_health_relation,
"gender_health_relation": gender_health_relation,
"race_health_relation": race_health_relation,
"employment_health_relation": employment_health_relation,
"self_management_profile": self_management_profile
}六、项目文档展示

七、总结
《基于Spark的全国健康老龄化数据分析系统》通过整合Hadoop和Spark大数据技术,结合Python、Django、Vue和Echarts等开发工具,构建了一套全面的老年健康数据分析平台。系统成功实现了老年人基本健康状况评估、医疗服务利用与健康需求分析、老年人睡眠健康与生活质量分析以及老龄化健康风险评估与干预建议四大核心功能模块。特别是在健康风险聚类分析方面,系统通过K-means算法识别不同健康风险模式的老年人群体,为分层健康管理提供了数据支持;在睡眠健康分析方面,系统深入研究了压力、药物、疼痛等因素对老年人睡眠质量的影响,揭示了睡眠问题与整体健康的关联;在多维健康评分体系构建方面,系统综合考量身体、心理、口腔和睡眠健康,形成了科学的老年健康评估工具,并分析了健康评分与医疗需求的关系。通过这些功能,系统不仅为医疗资源优化配置、老年健康政策制定提供了数据依据,也为预防性健康干预和老年人自我健康管理提供了科学指导。本系统的开发与应用,对于应对我国日益严峻的人口老龄化挑战,促进健康老龄化进程具有重要的现实意义
大家可以帮忙点赞、收藏、关注、评论啦👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖