前言
由于公司项目采用JDK 21作为运行环境,我们直接使用了ZGC垃圾收集器。此前我对ZGC的了解仅限于其缩短STW(Stop-The-World)的特性,现在借此机会对其实现原理和核心机制进行系统性的梳理。
目前网上的资料参差不齐,尤其是不同的博文使用不同的JDK版本,让读者容易困惑,我在写此篇时,加了一些说明用于读者比较差异, 并且加了一些自己的理解。
ZGC简介
ZGC中的Z代表什么含义?
ZGC 本身不代表任何含义,只是一个名称。它最初的灵感来源于 ZFS(文件系统),或者说是对 ZFS 的致敬。------维基-openjdk官网
 ZGC 于 2017 由 Oracle 贡献给社区,在 JDK 11 及以上版本的各种 release 中几乎都包含该 GC。
ZGC 于 2017 由 Oracle 贡献给社区,在 JDK 11 及以上版本的各种 release 中几乎都包含该 GC。
ZGC 最初是在 JDK 11 中作为一项实验性功能引入的,并在 JDK 15 中被宣布为可用于生产环境。在 JDK 21 中被重新实现以支持分代。
目前多个大厂已经纷纷投入ZGC的怀抱,如转转、携程、京东、美团。
传统GC的痛点
Parallel/CMS/G1 :随着堆内存增大(如 100GB+),Full GC 或并发标记阶段的停顿时间可能达到秒级,导致服务不可用。
CMS :存在并发模式失败,退化为 Serial GC,停顿时间剧增。Concurrent Mode Failure:CMS 正在并发执行垃圾回收时,应用程序继续运行并分配新对象。如果此时老年代空间不足(新对象晋升速度 > CMS 回收速度),JVM 会放弃并发回收,触发一次 STW 的 Serial Old GC(单线程 Full GC))。
G1 :虽然优化了停顿,但在大堆下仍可能产生 200ms+ 的停顿。
ZGC的核心优势

- 解决大堆内存的长时间停顿(STW)问题。(达到 TB 级别的堆内存管理,以及最大 10ms 的停顿时间)
- 解决内存碎片化问题。
- 解决高吞吐与低延迟的矛盾(15% 以内的吞吐量下降,有的文章说是和G1对比,但是其实传统的垃圾回收器吞吐量最高的是Parallel GC, 在低延迟的情况下,顶多15%吞吐量下降)
- 易于调优、配置:自动调整回收策略,减少手动调优需求
一、GC流程
与CMS中的ParNew和G1类似,ZGC也采用标记-复制算法,不过ZGC对该算法做了重大改进:ZGC在标记、转移和重定位阶段几乎都是并发的,这是ZGC实现停顿时间小于10ms目标的最关键原因。
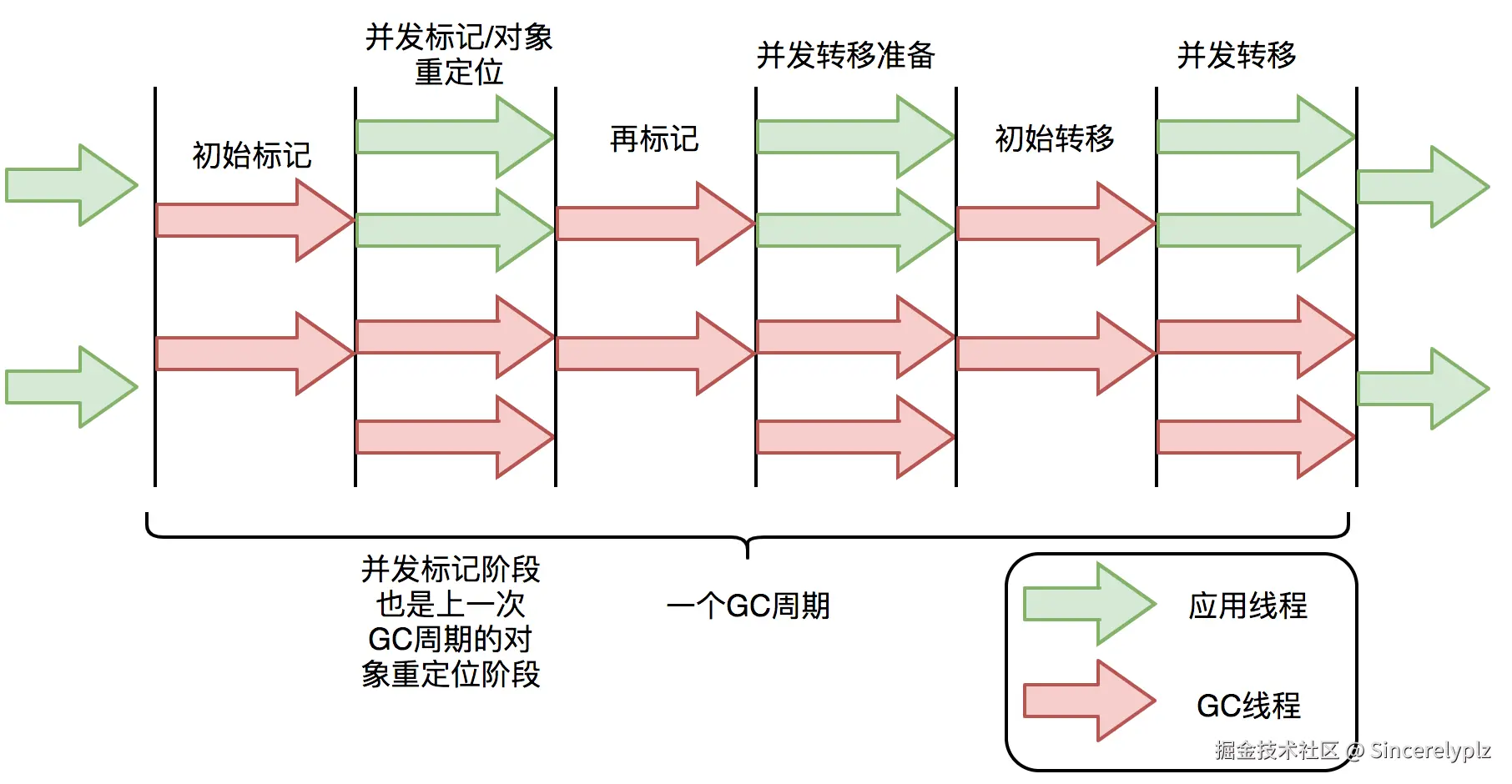
(直接引用的美团的图片)
- GC Roots标记:会STW。
- 并发扫描:根据GC Roots并发找到所有对象的引用关系。
- 再标记:找到并发扫描的同时,新产生的GC Roots。
- 并发转移准备:并发过程,为对象搬迁做准备(确定哪些 Region(内存块)需要回收、哪些对象要搬迁,更新相关的元数据(转移表 relocation table))。
- 初始转移:会STW,开始搬迁某些对象,把 GC Roots 中引用的对象(寄存器、线程栈,JNI引用,静态变量指向的堆中的对象)先搬迁到新位置,更新引用指针。
- 并发转移 :并发执行,将存活对象压缩整理到新的内存区域,消除碎片,完成剩余对象的搬迁。
ZGC 相比 G1 的核心优化之一就是实现了完全并发的对象转移(Concurrent Relocation) ,从而彻底消除了 G1 在转移阶段必须 STW(Stop-The-World)的瓶颈。
| 特性 | G1 | ZGC |
|---|---|---|
| 转移是否并发 | ❌ 必须 STW(并行但非并发) | ✅ 完全并发(无 STW) |
| 停顿时间 | 10~200ms(依赖堆大小) | <1ms(与堆大小无关) |
| 实现原理 | 增量并行转移 + 记忆集 (RSet,最后会补充介绍) | 染色指针 + 读屏障 + 内存多重映射 |
| 内存碎片化处理 | 通过转移整理,但需 STW | 并发压缩,无碎片化问题 |
为什么G1不支持并发转移对象?
并发转移中"并发"意味着GC线程在转移对象的过程中,应用线程也在不停地访问对象。假设对象发生转移,但对象地址未及时更新,那么应用线程可能访问到旧地址,从而造成错误。
ZGC是怎么做的?
在ZGC中,应用线程访问对象将触发"读屏障",如果发现对象被移动了,那么"读屏障"会把读出来的指针更新到对象的新地址上,这样应用线程始终访问的都是对象的新地址。那么,JVM是如何判断对象被移动过呢?就是利用对象引用的地址,即染色指针。下面介绍染色指针和读屏障技术细节。
二、染色指针
指针压缩
在64位系统中,指针(对象引用)默认占用64位(8字节) ,但实际应用中大多数对象不需要如此大的寻址空间。为了节省内存并提高性能,JVM引入了指针压缩(Compressed Oops,即 "Compressed Ordinary Object Pointers"),将指针从64位压缩到32位
64位指针的浪费: 64位指针理论寻址空间为 2^64(16EB),但实际堆内存通常远小于此(如32GB)。高64位地址全为0,造成空间浪费。
指针压缩:将64位转为32位时,对象的地址变小,对象的引用也就变小了(8字节->4字节),同时更小的指针占用更小的CPU缓存行,提高访问速度。
指针压缩原理
直接使用32位指针,但最大仅支持4GB堆(2^32)。
但是我们发现,我们并不要实际存储对象的地址,因为JVM要求对象按8字节对齐 ,那么也就是说对象地址的末三位一定是0(因为得是8的倍数),所以我们就不需要存储实际地址,而是存储偏移量,也就是这个实际地址去掉三个0的地址,但是我们发现可以使用省下的三个0,来让我们支持的堆变的更大。
32位偏移量 + 3位对齐 → 2^35 = 32GB
如果我们将JVM的对齐调整为16字节,则可以支持64GB
染色指针
染色指针与指针压缩恰恰相反,目的不同。
指针压缩 :采用更小的地址来提高堆的利用率,和CPU缓存的利用率,来提高访问速度和节省空间的目的。 染色指针:利用高位来存储其他信息,利用空间换时间的原理,使用高16位来存储GC标记。
染色指针地址位布局(也就是对象引用,即虚拟地址)
虽然指针是64位,但实际虚拟地址仅使用低48位(最大寻址256TB),而高16位(48~63)需全为0或全为1(称为"规范地址")。 ZGC 在此基础上进一步优化,将地址空间划分为三部分:
| 0 - 41 | 42 | 保留最后三位(通常为0,用于8字节对齐,因为没有使用指针压缩,其实就是实际地址,而不是偏移量) |
|---|
| 42 - 45 | 4 | 4个GC标记位(Marked0、Marked1、Remapped、Finalizable) |
|---|
| 46 - 63 | 18 | 必须全为0(符号扩展,高16位) |
|---|
之所以叫染色指针,本质是指 在指针的高位比特中嵌入垃圾回收(GC)的元数据,就像给指针"染色"以标记其状态,也就是4个GC标志位。
关于ZGC地址位布局的说明:
我参考的不同资料中对ZGC地址位的描述存在差异(42位或44位),这主要是由于JDK版本演进导致的:
-
早期版本(JDK 15及之前)
- 采用42位地址空间(支持4TB堆)
- 4位元数据位(42-45位)
- 高18位固定为0
-
JDK 16+版本
- 扩展为44位地址空间
- 2位元数据位
- 可支持最大16TB堆内存
-
版本差异原因
- 随着ZGC的成熟,后期版本通过优化内存对齐策略
- 在保持染色指针机制的前提下扩展了地址空间
-
当前JDK 21情况
- 默认仍使用42位布局(4TB)
- 通过
-XX:ObjectAlignmentInBytes=16参数 - 可启用44位地址模式(16TB)
染色指针原理
染色指针是 ZGC/Shenandoah 等现代垃圾回收器的核心技术,其核心思想是 "将GC元数据直接嵌入指针地址中" ,从而彻底消除传统GC需要的全局数据结构(如卡表、记忆集)和STW暂停。
1. 初始化时
ZGC初始化之后,整个内存空间的地址视图被设置为Remapped。程序正常运行,在内存中分配对象,满足一定条件后垃圾回收启动,此时进入标记阶段。
2. 并发标记时,无需STW
GC线程遍历对象图,将存活对象的指针 42~45位 设为 Marked0 或 Marked1(为了区别前一次标记和当前标记)程序线程访问对象时,通过 读屏障(Load Barrier) 检查标记位,确保一致性。
java
// 伪代码
Object obj = field; // 读取对象
if (!obj.isMarked()) { // 检查42~45位
obj.mark(); // 标记为存活
}3. 并发转移时
移动对象到新地址:
- GC线程复制对象到新地址,将新指针的
Remapped位置1。 - 旧指针的
Remapped位保持为0,但通过内存多重映射,新旧地址同时指向同一物理内存
指针自愈
- 程序访问旧指针时,读屏障发现
Remapped=0,自动返回新地址并更新指针值。 - 后续访问直接使用新地址,无需再检查。
4. 并发引用处理
弱引用/软引用回收:通过 Finalizable 位快速识别待回收对象,无需全局扫描。
三、读屏障
操作系统将同一物理内存映射到多个虚拟地址(旧地址A和新地址B)。读屏障通过检查染色位决定返回A或B,但对程序透明。
当发现对象移动时,读屏障怎么知道新地址在哪里?
- GC线程在移动对象时会先在转移表(Forwarding Table) 中记录旧地址到新地址的映射。 工作原理基本如下:
java
Object obj = field; // 程序读取对象引用
// 读屏障隐式插入的逻辑:
if (obj.address & REMAPPED_MASK == 0) { // 如果Remapped=0,说明对象可能被移动了
Object newObj = lookupForwardingTable(obj); // 查转移表
if (newObj != null) {
field = newObj; // 自愈:替换为新的引用
return newObj;
} }
return obj;如果回收的时候,还有人在访问旧对象怎么办?
当GC将对象从地址A移动到地址B时,若程序线程仍在访问旧地址A,传统GC必须STW冻结所有线程,否则会导致数据错误。
但是我们可以让旧地址A和新地址B同时指向同一块物理内存 ,对象转移时,将对象从A复制到B,物理内存内容不变(仅虚拟地址变化)。在转移表 中记录虚拟地址 A → B 的映射。
转移表会在压缩的前置准备阶段完成清除。
四、基于区域的内存管理(Region-based)
ZGC根据对象大小将内存区域分为三类:
- 小型区域(Small):默认2MB,存放小于256KB的对象
- 中型区域(Medium):默认32MB,存放大于256KB小于4MB的对象
- 大型区域(Large):大小不固定,专门存放4MB以上的大对象 这种设计让ZGC能够:
针对不同大小的对象采用不同的回收策略,根据应用需求动态分配和释放区域, 减少内存碎片,提高内存利用率。
五、分代ZGC
为什么有分代ZGC
分代ZGC是ZGC的一个实现版本,依据假说:应用中的大部分对象都是短生命周期的,被设计为分代,即:年轻代、老年代。相对ZGC,分代ZGC提高了应用吞吐率、降低了Allocation Stall频率、且依然能够保持对应用的暂停时间小于1ms。
ZGC最早于JDK 11 作为实验性功能推出,此时采用不分代设计,通过并发压缩、染色指针等技术实现低延迟(STW停顿不超过10ms) 。
核心目标是通过并发操作减少暂停时间,但由于没有进行分代设计, 存在内存回收效率不足的问题,需频繁扫描整个堆 。
JDK 21 首次引入分代ZGC ,将堆划分为年轻代(Young Generation) 和老年代(Old Generation) ,针对性优化回收策略 。
JDK 23将分代ZGC设为默认模式(JEP 474),标志着其稳定性和生产适用性成熟。
- 年轻代:存放短生命周期对象,采用高频回收策略(Minor GC),避免存活对象快速进入老年代68。
- 老年代:存放长生命周期对象,通过低频并发标记-压缩(Major GC)减少扫描开销16。
ZGC的内存模型
分代ZGC将堆内存分为两个逻辑区域:年轻代、老年代。
和其他的垃圾回收器一样,对象首先会先分给年轻代,如果年轻代多次垃圾回收之后,仍存活则会被晋升到老年代。在实际的内存分布中,年轻代、老年代会分布在不连续的内存区域。
1. Minor Collection 年轻代回收
该阶段只回收年轻代,访问年轻代以及老年代对象中指向年轻代对象的字段,访问他们的主要原因是:
(1)GC Marking Roots:这样的字段包含唯一引用,使年轻代Object Graph的一部分保持可达。GC必须将这些字段视为Object Graph的根,以确保所有存活的对象都被发现,并标记他们的存活状态。
(2)老年代中的陈旧指针:收集年轻代时,会移动对象,这些对象的指针没有被立即更新。 老年代到年轻代的指针集合称为remembered set,包含了所有指向年轻代的指针。
2. Major Collection 全堆回收
该阶段期望回收整个堆,既访问年轻代,也访问老年代。
和Minor Collection类似,找到GC Marking Roots,以及年轻代中指向老年代的Roots。
当年轻代收集完之后,可以找到所有老年代中存活的对象。当估算到所有存活的对象之后,就可以移动对象、回收内存。
分代ZGC不再使用多重映射
与不分代ZGC的4个颜色位相比,分代ZGC需要12个颜色位来标识不同的GC阶段,这显然不能用多重映射内存来实现了。(说明!! 很多文章提到分代ZGC并不是完全不使用多重映射,而是在老年代依旧保持了多重映射的机制。这种说法是错误的!可以参考官方的资料,官方地址:openjdk.org/jeps/439)
为什么 分代ZGC不再使用多重映射技术?
在不分代的ZGC中,通过指针中不同的标记位区分不同的虚拟空间,而这些不同标记位指向的不同的虚拟空间通过mmap映射到同一物理地址。
也就映射3次(M0/M1/remaped),最终造成普通ZGC的RSS指标(RSS统计的虚拟内存地址)翻了3倍。
以下是我个人理解(纯原创, 请勿搬运):
其实我这里有一个好奇的点
为什么要映射三次?为什么不直接用一个虚拟地址,然后通过标志位来标志不同的状态?
这是因为当对象创建时,就直接分给了其三个虚拟地址,a,b c表达其三个不同的状态,(mark0,mark1), remaped。 这三个地址都映射到了同一片物理内存 当用户访问的引用对象处于迁移过程中,GC 会将该引用的指针的高位标志从 a或b(比如 Mark0 或 Mark1)改为 c(Remapped 状态)。此时,带有 c 标志的指针仍然映射到对应的物理内存。访问时,Load Barrier 会检测到该指针处于 Remapped 状态,通过转发表找到对象的新地址 d,并将该引用更新为指向 d 的新指针。
这里我一开始有一个很大的误区:也就是我以为mark0和mark1代表新地址和旧地址,但是其实两者都是旧地址,包括Remapped也是存的旧地址,三者都是映射的旧地址,当为对象分配新地址时,需要一个转发的状态,也就是检测Remapped,然后找到映射表转发。
第二个误区是,我以为ZGC强大的一点是因为对象回收时,不会动物理内存,有的只是虚拟内存来表示其是否回收,但是其实其会在垃圾回收时,将对象迁移到新的物理页。 也就是其使用的标记压缩算法,用于整理内存碎片。
也正是因为上述特点,其可以在边标记的同时,并发去进行压缩,因为他能够解决单个对象的迁移过程中的并发使用问题。
而新地址仍然采用的三个虚拟地址,那映射表映射的是哪一个虚拟地址呢? 这取决于当前的全局状态,如果当前是第一次回收(mark0)那么就会映射到mark0的对应的虚拟地址上面。而全局状态只会有两种mark0和mark1,用于标志当前的回收轮次。如果当前是全局状态mark0,部分对象是mark1,则说明此mark1的虚拟地址的引用是未被标记的,Mark1状态的对象在当前GC周期里不被认为是存活的,GC会将这些Mark1对象视为垃圾,准备回收它们所占的内存,同时,GC在本轮标记过程中,会将存活的对象标记为Mark0。
分代ZGC需要更多的标记位,如果还使用muli-map的方式,第一可用内存会因为多加标记位减少;第二RSS指标可能是实际使用内存高出更多倍,所以分代ZGC在把虚拟内存交给操作系统的时候,需要清除标记位。
这也是为啥ZGC一开始不支持分代的原因。
至于分代ZGC,除了分代ZGC不再使用多重映射 其实还做了非常多的优化,比如
- 优化的屏障
- 双缓冲记忆集
- 无需额外堆内存的重定位
- 密集堆区域
- 大型物体
- 完整垃圾收集
但是由于相关资料较少,我不认为,我的表述一定会比官方更加准确,所以建议读者直接参考官方文档进行理解: openjdk.org/jeps/439
但是后续一定开坑,继续写完分代ZGC的原理!!不写是狗!