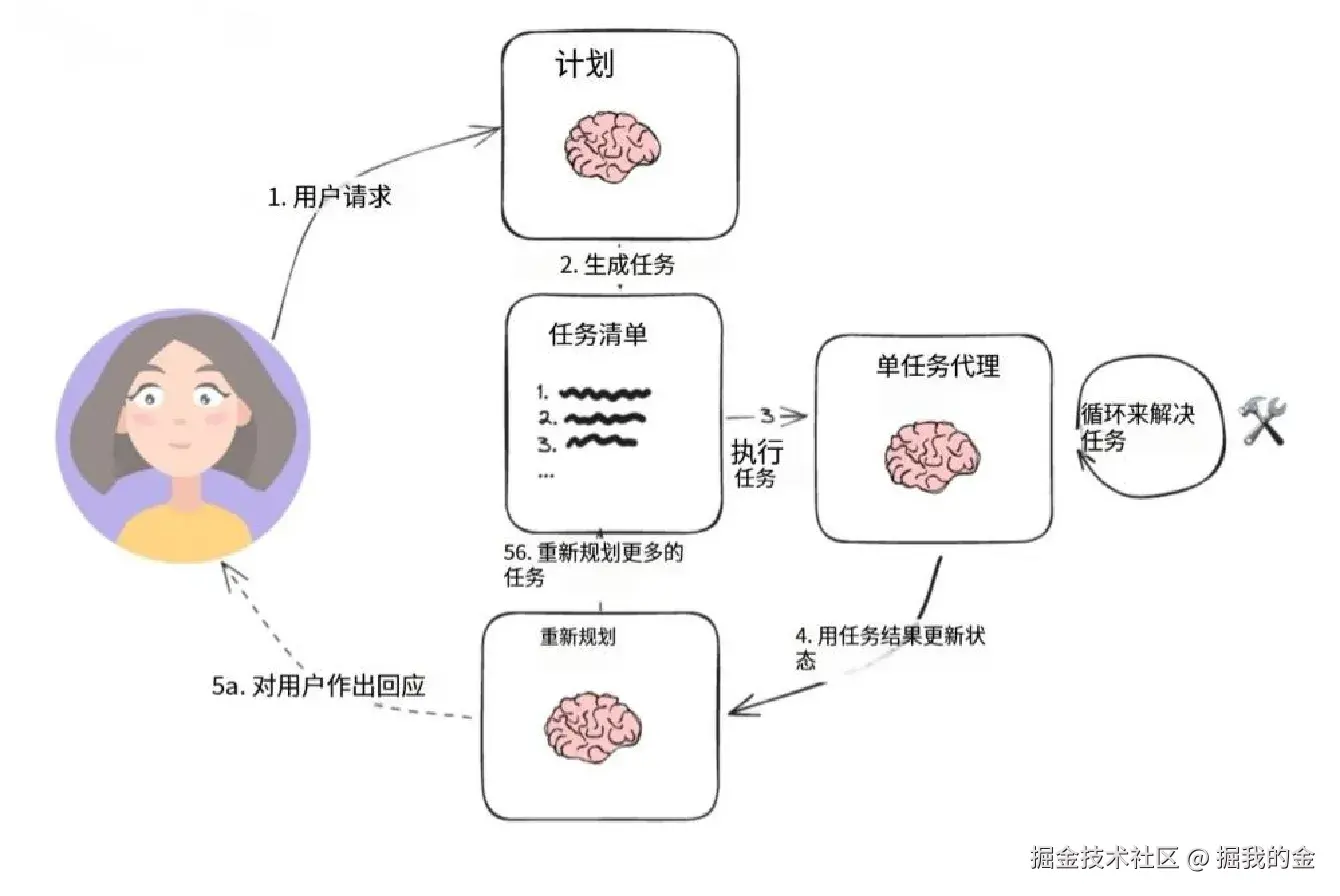
引言:从单步到多步Agent
在上一篇教程中,我们介绍了LangGraph的基础概念。现在,我们将进一步探索如何使用LangGraph构建更复杂的Agent工作流应用,特别是"计划并执行"风格的代理系统。
传统的ReAct模式代理每次只思考一步,而"计划并执行"模式则先制定完整计划,再逐步执行。这种方法有两大优势:
- 明确的长期规划:即使是强大的LLM也可能难以在单步思考中保持长期一致性
- 模型分工:可以在规划阶段使用更强大的模型,执行阶段使用更小/更专业的模型,提高效率和降低成本
环境准备
首先,我们需要安装必要的软件包并设置API密钥:
bash
# 安装必要的包
pip install langgraph langchain-openai langchain-community
python
import os
from typing import List, Dict, Tuple, Any, Annotated, TypedDict, Sequence
from langchain_core.messages import HumanMessage, AIMessage
from langchain_openai import ChatOpenAI
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.tools import tool
from langgraph.graph import StateGraph, END
# 设置API密钥
os.environ["OPENAI_API_KEY"] = "你的OpenAI API密钥"
os.environ["TAVILY_API_KEY"] = "你的Tavily API密钥"
# 可选:设置LangSmith(提供可视化和调试功能)
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "你的LangSmith API密钥"定义工具
在这个示例中,我们将使用Tavily搜索工具作为代理可以使用的工具:
python
# 创建搜索工具
search = TavilySearchResults(max_results=3)
# 定义工具列表
tools = [search]定义执行代理
接下来,我们创建用于执行任务的代理。这个代理将负责执行计划中的每个步骤:
python
# 创建执行代理的语言模型
execution_model = ChatOpenAI(temperature=0, model="gpt-3.5-turbo")
# 绑定工具到语言模型
execution_model_with_tools = execution_model.bind_tools(tools)
def execute_task(state):
"""执行单个任务的函数"""
# 获取当前任务
task = state["plan"][0]
# 构建提示
messages = [
HumanMessage(content=f"执行以下任务: {task}. 使用提供的工具来帮助完成任务。")
]
# 调用模型执行任务
response = execution_model_with_tools.invoke(messages)
# 更新状态
return {
"completed_tasks": state["completed_tasks"] + [(task, response.content)],
"plan": state["plan"][1:], # 移除已完成的任务
}定义状态
在LangGraph中,我们需要明确定义代理的状态。对于"计划并执行"代理,我们需要跟踪以下信息:
python
# 使用TypedDict定义状态结构
class AgentState(TypedDict):
"""代理状态类型"""
# 原始用户输入
input: str
# 当前计划(任务列表)
plan: List[str]
# 已完成的任务及其结果
completed_tasks: List[Tuple[str, str]]
# 最终响应
final_response: str定义规划步骤
规划步骤负责根据用户输入生成初始计划:
python
# 创建规划模型(使用更强大的模型进行规划)
planning_model = ChatOpenAI(temperature=0, model="gpt-4")
def create_plan(state):
"""创建初始计划的函数"""
user_input = state["input"]
# 构建规划提示
planning_prompt = f"""
根据用户的请求: "{user_input}",
制定一个分步计划来解决这个问题。每个步骤应该是一个具体、可执行的任务。
返回一个有序的任务列表,格式如下:
1. 第一个任务
2. 第二个任务
...等等
确保计划是全面的,能够完整解决用户的请求。
"""
# 调用规划模型
response = planning_model.invoke(planning_prompt)
# 解析计划(将文本转换为任务列表)
plan_text = response.content
plan_lines = [line.strip() for line in plan_text.split("\n") if line.strip()]
# 提取任务(去掉序号和点)
tasks = []
for line in plan_lines:
if any(line.startswith(f"{i}.") for i in range(1, 20)):
task = line.split(".", 1)[1].strip()
tasks.append(task)
# 更新状态
return {"plan": tasks}定义重新规划步骤
重新规划步骤会根据已完成任务的结果,调整剩余的计划:
python
def replan(state):
"""根据执行结果重新规划的函数"""
user_input = state["input"]
completed_tasks = state["completed_tasks"]
remaining_plan = state["plan"]
# 如果没有剩余任务,则不需要重新规划
if not remaining_plan:
return {}
# 构建重新规划提示
replan_prompt = f"""
原始请求: "{user_input}"
已完成的任务:
{format_completed_tasks(completed_tasks)}
当前计划的剩余任务:
{format_plan(remaining_plan)}
根据已完成任务的结果,评估当前计划是否仍然适合解决用户的请求。
如果需要,请调整剩余的计划。
返回一个有序的任务列表,格式如下:
1. 第一个任务
2. 第二个任务
...等等
"""
# 调用规划模型
response = planning_model.invoke(replan_prompt)
# 解析新计划
plan_text = response.content
plan_lines = [line.strip() for line in plan_text.split("\n") if line.strip()]
# 提取任务(去掉序号和点)
tasks = []
for line in plan_lines:
if any(line.startswith(f"{i}.") for i in range(1, 20)):
task = line.split(".", 1)[1].strip()
tasks.append(task)
# 如果解析出任务,则更新计划
if tasks:
return {"plan": tasks}
return {}
# 辅助函数:格式化已完成任务
def format_completed_tasks(completed_tasks):
result = ""
for i, (task, outcome) in enumerate(completed_tasks, 1):
result += f"{i}. 任务: {task}\n 结果: {outcome}\n\n"
return result
# 辅助函数:格式化计划
def format_plan(plan):
return "\n".join(f"{i+1}. {task}" for i, task in enumerate(plan))定义最终响应步骤
当所有任务完成后,我们需要生成最终响应:
python
def generate_final_response(state):
"""生成最终响应的函数"""
user_input = state["input"]
completed_tasks = state["completed_tasks"]
# 构建最终响应提示
final_prompt = f"""
原始请求: "{user_input}"
已完成的任务:
{format_completed_tasks(completed_tasks)}
根据以上信息,请提供一个全面、清晰的回答,解决用户的原始请求。
确保回答是连贯的,并整合所有任务的结果。
"""
# 调用模型生成最终响应
response = planning_model.invoke(final_prompt)
# 更新状态
return {"final_response": response.content}创建工作流图
现在,我们将所有组件连接起来,创建一个完整的工作流图:
python
# 创建状态图
workflow = StateGraph(AgentState)
# 添加节点
workflow.add_node("create_plan", create_plan)
workflow.add_node("execute_task", execute_task)
workflow.add_node("replan", replan)
workflow.add_node("generate_final_response", generate_final_response)
# 设置入口点
workflow.set_entry_point("create_plan")
# 定义条件函数:检查是否有剩余任务
def has_tasks_remaining(state):
return len(state["plan"]) > 0
def should_replan(state):
# 每完成3个任务或任务数量变化时重新规划
completed_count = len(state["completed_tasks"])
return completed_count > 0 and completed_count % 3 == 0
# 添加边(定义执行流程)
workflow.add_conditional_edges(
"create_plan",
lambda state: "execute_task" if has_tasks_remaining(state) else "generate_final_response"
)
workflow.add_conditional_edges(
"execute_task",
lambda state: "replan" if should_replan(state) and has_tasks_remaining(state)
else "execute_task" if has_tasks_remaining(state)
else "generate_final_response"
)
workflow.add_conditional_edges(
"replan",
lambda state: "execute_task" if has_tasks_remaining(state) else "generate_final_response"
)
workflow.add_edge("generate_final_response", END)
# 编译图
agent = workflow.compile()使用代理解决问题
现在我们可以使用构建好的代理来解决实际问题:
python
# 初始化状态
initial_state = {
"input": "我想了解太阳能电池板的工作原理以及它们对普通家庭的成本效益",
"plan": [],
"completed_tasks": [],
"final_response": ""
}
# 运行代理
result = agent.invoke(initial_state)
# 输出最终响应
print("最终响应:")
print(result["final_response"])
# 输出执行轨迹
print("\n执行轨迹:")
for i, (task, outcome) in enumerate(result["completed_tasks"], 1):
print(f"任务 {i}: {task}")
print(f"结果: {outcome[:100]}..." if len(outcome) > 100 else f"结果: {outcome}")
print("-" * 50)高级功能:添加人类反馈环节
在某些情况下,我们可能希望在代理执行过程中加入人类反馈。以下是如何添加人类审核计划的步骤:
python
def human_review_plan(state):
"""让人类审核和修改计划"""
plan = state["plan"]
# 显示当前计划
print("当前计划:")
for i, task in enumerate(plan, 1):
print(f"{i}. {task}")
# 询问是否需要修改
need_modification = input("\n是否需要修改计划? (是/否): ").lower() in ["是", "y", "yes"]
if need_modification:
# 收集修改后的计划
print("\n请输入修改后的计划,每行一个任务,输入空行结束:")
new_plan = []
while True:
task = input("> ")
if not task:
break
new_plan.append(task)
# 更新状态
return {"plan": new_plan}
# 如果不需要修改,返回空字典表示不变
return {}
# 将人类审核节点添加到图中
workflow.add_node("human_review_plan", human_review_plan)
workflow.add_edge("create_plan", "human_review_plan")
workflow.add_conditional_edges(
"human_review_plan",
lambda state: "execute_task" if has_tasks_remaining(state) else "generate_final_response"
)高级功能:任务并行执行
对于某些可以并行执行的任务,我们可以修改代理以支持并行执行:
python
def identify_parallel_tasks(state):
"""识别可以并行执行的任务"""
plan = state["plan"]
parallel_groups = []
# 简单示例:将连续的搜索任务分组
current_group = []
for task in plan:
if "搜索" in task or "查找" in task:
current_group.append(task)
else:
if current_group:
parallel_groups.append(current_group)
current_group = []
parallel_groups.append([task])
if current_group:
parallel_groups.append(current_group)
return {"parallel_task_groups": parallel_groups, "plan": []}
def execute_parallel_tasks(state):
"""并行执行任务组"""
task_group = state["parallel_task_groups"][0]
results = []
# 在实际应用中,这里可以使用多线程或异步执行
for task in task_group:
messages = [HumanMessage(content=f"执行以下任务: {task}")]
response = execution_model_with_tools.invoke(messages)
results.append((task, response.content))
# 更新状态
return {
"completed_tasks": state["completed_tasks"] + results,
"parallel_task_groups": state["parallel_task_groups"][1:],
}总结
通过本教程,我们学习了如何使用LangGraph构建"计划并执行"风格的代理工作流。这种代理具有以下特点:
- 分阶段执行:先规划后执行,使任务处理更有条理
- 动态调整:根据执行结果重新规划,适应变化的情况
- 灵活扩展:可以添加人类反馈、并行执行等高级功能
这种工作流特别适合处理复杂的多步骤任务,如研究报告生成、数据分析流程、复杂问题解决等场景。通过合理设计状态和节点函数,你可以构建出适合自己特定需求的智能代理系统。
进阶应用场景
- 研究助手:自动收集资料、分析信息、生成研究报告
- 个人助理:帮助规划日程、处理邮件、准备会议材料
- 数据分析工作流:自动收集数据、清洗数据、执行分析、生成可视化
- 客户服务:理解客户问题、收集相关信息、提供解决方案
通过LangGraph的强大功能,你可以将这些复杂的工作流程自动化,大大提高工作效率。