引言:智能客服的演进
随着人工智能技术的发展,客服系统正从简单的规则型响应向更加智能化的方向发展。传统的客服系统通常只能回答预设问题,而基于大语言模型的智能客服则能够理解复杂问题并提供个性化解答。本教程将介绍如何结合LangGraph和RAG(检索增强生成)技术,构建一个功能强大的智能客服应用。
AI智能体的发展趋势
AI领域正在经历一场重要的变革,从基础的RAG系统向更智能的AI智能体进化。这些智能体能够:
- 处理更复杂的任务
- 适应新信息
- 进行多轮对话
- 记住对话历史
- 根据用户反馈调整回答
LangGraph作为LangChain库的扩展,为开发者提供了构建具有状态管理和循环计算能力的先进AI系统的工具,特别适合构建智能客服应用。
LangGraph核心概念
LangGraph是LangChain的高级库,为大型语言模型(LLM)带来循环计算能力。它超越了LangChain的线性工作流,通过循环支持复杂的任务处理。
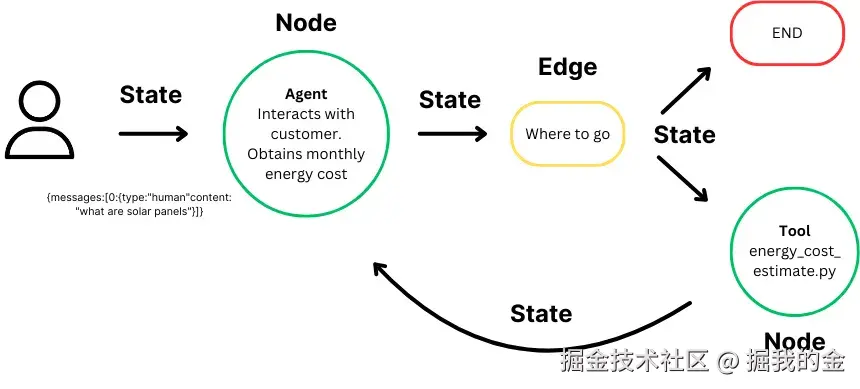
LangGraph的三个核心组件:
-
状态(State):
- 维护计算过程中的上下文
- 实现基于累积数据的动态决策
- 在客服场景中,可以保存用户的历史问题和系统的回答
-
节点(Node):
- 代表计算步骤,执行特定任务
- 可定制以适应不同工作流
- 在客服系统中,可以是查询理解、知识检索、回答生成等功能模块
-
边(Edge):
- 连接节点,定义计算流程
- 支持条件逻辑,实现复杂工作流
- 允许系统根据不同情况选择不同的处理路径
LangGraph简化了AI开发,自动管理状态,保持上下文,使AI能智能响应变化。它让开发者专注于创新,而非技术细节,同时确保应用程序的高性能和可靠性。
RAG技术原理
RAG(检索增强生成)是一种结合了检索系统和生成模型的技术,特别适合需要基于特定知识库回答问题的场景,如客服系统。
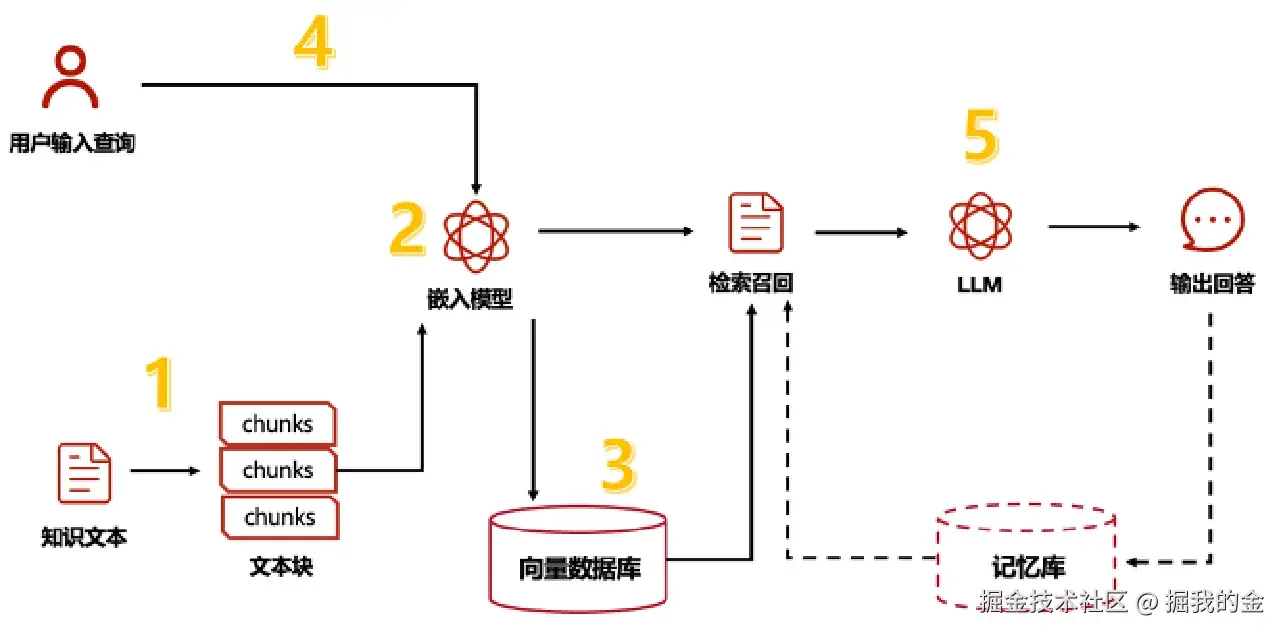
一个典型的RAG应用有两个主要组成部分:
-
索引(Indexing):从数据源获取数据并建立索引的管道(pipeline)。这通常在离线状态下进行。
-
检索和生成(Retrieval and generation):实际的RAG链,在运行时接收用户查询,从索引中检索相关数据,然后将其传递给模型。
从原始数据到答案的完整流程如下:
索引(Indexing)
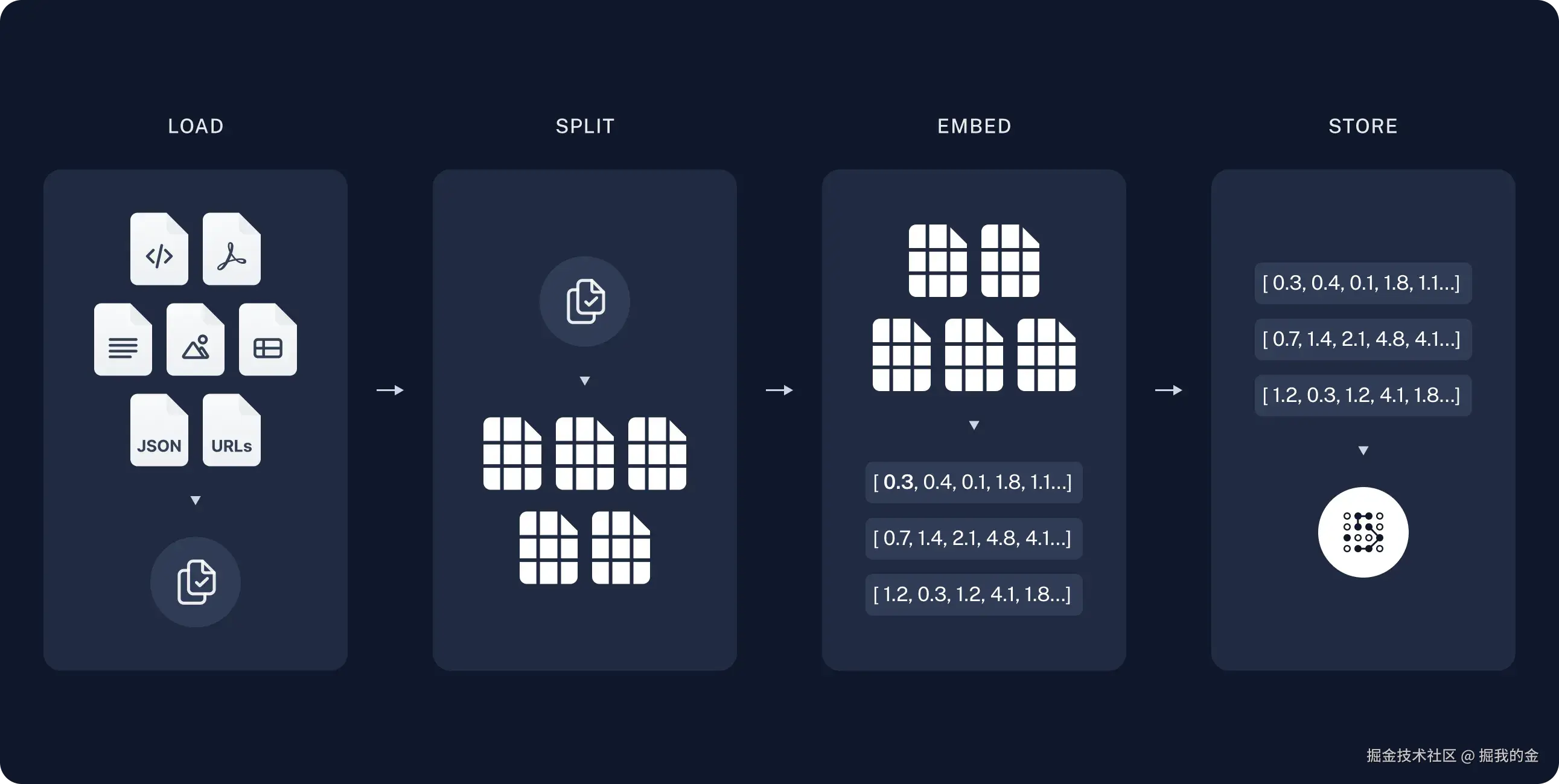
-
加载(Load):首先我们需要加载数据。这是通过文档加载器(Document Loaders)完成的。
- 可以加载PDF、Word、HTML、Markdown等多种格式的文档
- 在客服场景中,通常是加载产品手册、常见问题解答、操作指南等
-
分割(Split):文本分割器(Text splitters)将大型文档(Documents)分成更小的块(chunks)。
- 大块数据更难搜索,且不适合模型有限的上下文窗口
- 合理的分块大小能提高检索精度和生成质量
-
存储(Store):我们需要一个地方来存储和索引我们的分割(splits),以便后续可以对其进行搜索。
- 通常使用向量存储(VectorStore)和嵌入模型(Embeddings model)
- 将文本转换为向量表示,便于相似度搜索
检索和生成(Retrieval and generation)
-
检索(Retrieve):给定用户输入,使用检索器(Retriever)从存储中检索相关的文本片段。
- 基于语义相似度找到最相关的文档片段
- 可以使用各种策略优化检索结果,如混合检索、重排序等
-
生成(Generate):ChatModel使用包含问题和检索到的数据的提示来生成答案。
- 大语言模型基于检索到的上下文生成回答
- 确保回答准确、相关且符合客服语气
构建智能客服应用
接下来,我们将使用LangGraph和RAG技术构建一个智能客服应用。这个应用将能够回答用户关于产品、服务、账户等方面的问题。
环境准备
首先,我们需要准备开发环境:
bash
# 创建虚拟环境(建议使用Python 3.10或更高版本)
python -m venv customer_service_env
source customer_service_env/bin/activate # Linux/Mac
# 或
customer_service_env\Scripts\activate # Windows
# 安装依赖
pip install langchain langgraph langchain-openai langchain-community chromadb gradio配置API密钥
python
import os
# 设置OpenAI API密钥
os.environ["OPENAI_API_KEY"] = "你的OpenAI API密钥"
# Windows导入环境变量(每次执行完,需要重启PyCharm才能生效)
# set OPENAI_API_KEY=你的OpenAI API密钥
# Mac导入环境变量
# export OPENAI_API_KEY=你的OpenAI API密钥准备知识库
我们需要准备一些文档作为客服系统的知识库。这些文档可以是产品手册、常见问题解答、操作指南等。
python
import os
from langchain_community.document_loaders import DirectoryLoader, TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
# 加载文档
loader = DirectoryLoader("./knowledge_base", glob="**/*.txt", loader_cls=TextLoader)
documents = loader.load()
# 分割文档
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["\n\n", "\n", ".", "!", "?", ",", " ", ""],
length_function=len,
)
chunks = text_splitter.split_documents(documents)
# 创建向量数据库
embedding_model = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embedding_model,
persist_directory="./chroma_db"
)
# 持久化存储
vectorstore.persist()定义状态类型
使用TypedDict定义我们的状态类型,包含对话历史、当前问题、检索结果和最终回答等信息:
python
from typing import List, Dict, TypedDict, Sequence, Optional
from langchain_core.documents import Document
from langchain_core.messages import HumanMessage, AIMessage, BaseMessage
class CustomerServiceState(TypedDict):
"""客服系统状态"""
# 对话历史
chat_history: List[BaseMessage]
# 当前用户问题
question: str
# 检索到的文档
retrieved_documents: Optional[List[Document]]
# 生成的回答
answer: Optional[str]
# 是否需要澄清问题
need_clarification: bool
# 澄清问题的提示
clarification_prompt: Optional[str]定义节点函数
接下来,我们定义LangGraph工作流中的各个节点函数:
python
from langchain_openai import ChatOpenAI
from langchain_core.retrievers import BaseRetriever
from langchain_core.prompts import ChatPromptTemplate
# 初始化模型
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo")
# 1. 查询理解节点
def understand_query(state: CustomerServiceState) -> Dict:
"""分析用户查询,判断是否需要澄清"""
question = state["question"]
chat_history = state["chat_history"]
# 构建提示
system_prompt = """
你是一个客服系统的查询分析组件。你的任务是分析用户的问题,判断是否清晰明确。
如果问题不够明确或缺少关键信息,请指出需要澄清的部分。
如果问题已经足够明确,请直接返回"清晰"。
"""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": f"用户问题: {question}\n\n历史对话: {format_chat_history(chat_history)}\n\n这个问题是否清晰明确?"}
]
response = llm.invoke(messages)
# 判断是否需要澄清
need_clarification = "清晰" not in response.content
return {
"need_clarification": need_clarification,
"clarification_prompt": response.content if need_clarification else None
}
# 2. 检索知识节点
def retrieve_knowledge(state: CustomerServiceState) -> Dict:
"""从知识库中检索相关信息"""
question = state["question"]
chat_history = state["chat_history"]
# 创建检索器
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 5}
)
# 检索相关文档
retrieved_documents = retriever.invoke(question)
return {"retrieved_documents": retrieved_documents}
# 3. 生成回答节点
def generate_answer(state: CustomerServiceState) -> Dict:
"""根据检索到的信息生成回答"""
question = state["question"]
retrieved_documents = state["retrieved_documents"]
chat_history = state["chat_history"]
# 构建上下文
context = "\n\n".join([doc.page_content for doc in retrieved_documents])
# 构建提示模板
prompt = ChatPromptTemplate.from_messages([
("system", """
你是一个专业的客服助手。根据提供的上下文信息回答用户的问题。
如果上下文中没有相关信息,请礼貌地表示你没有这方面的信息,并建议用户联系人工客服。
回答要简洁、准确、有礼貌,使用友好的语气。
不要编造信息,只使用提供的上下文。
"""),
("human", "历史对话:\n{chat_history}\n\n上下文信息:\n{context}\n\n用户问题:{question}")
])
# 格式化提示
formatted_prompt = prompt.format(
chat_history=format_chat_history(chat_history),
context=context,
question=question
)
# 生成回答
response = llm.invoke(formatted_prompt)
# 更新对话历史
new_chat_history = chat_history + [
HumanMessage(content=question),
AIMessage(content=response.content)
]
return {
"answer": response.content,
"chat_history": new_chat_history
}
# 4. 澄清问题节点
def clarify_question(state: CustomerServiceState) -> Dict:
"""生成澄清问题的回答"""
clarification_prompt = state["clarification_prompt"]
question = state["question"]
chat_history = state["chat_history"]
# 构建提示
prompt = ChatPromptTemplate.from_messages([
("system", """
你是一个友好的客服助手。用户的问题需要进一步澄清。
请根据提供的澄清提示,生成一个礼貌的回应,询问用户提供更多信息。
回答要简洁、有礼貌,使用友好的语气。
"""),
("human", "用户问题:{question}\n\n澄清提示:{clarification_prompt}")
])
# 格式化提示
formatted_prompt = prompt.format(
question=question,
clarification_prompt=clarification_prompt
)
# 生成回答
response = llm.invoke(formatted_prompt)
# 更新对话历史
new_chat_history = chat_history + [
HumanMessage(content=question),
AIMessage(content=response.content)
]
return {
"answer": response.content,
"chat_history": new_chat_history
}
# 辅助函数:格式化对话历史
def format_chat_history(chat_history: List[BaseMessage]) -> str:
if not chat_history:
return "无历史对话"
formatted = ""
for i, message in enumerate(chat_history):
if isinstance(message, HumanMessage):
formatted += f"用户: {message.content}\n"
elif isinstance(message, AIMessage):
formatted += f"助手: {message.content}\n"
return formatted构建工作流图
现在,我们使用LangGraph将这些节点连接起来,构建完整的工作流:
python
from langgraph.graph import StateGraph, END
# 创建状态图
workflow = StateGraph(CustomerServiceState)
# 添加节点
workflow.add_node("understand_query", understand_query)
workflow.add_node("retrieve_knowledge", retrieve_knowledge)
workflow.add_node("generate_answer", generate_answer)
workflow.add_node("clarify_question", clarify_question)
# 设置入口点
workflow.set_entry_point("understand_query")
# 添加边(定义执行流程)
workflow.add_conditional_edges(
"understand_query",
lambda state: "clarify_question" if state["need_clarification"] else "retrieve_knowledge"
)
workflow.add_edge("retrieve_knowledge", "generate_answer")
workflow.add_edge("clarify_question", END)
workflow.add_edge("generate_answer", END)
# 编译图
customer_service_agent = workflow.compile()构建Web界面
最后,我们使用Gradio构建一个简单的Web界面,让用户可以与智能客服系统交互:
python
import gradio as gr
# 初始化对话历史
chat_history = []
def respond(message, history):
"""处理用户消息并返回回答"""
# 准备初始状态
initial_state = {
"chat_history": [HumanMessage(content=h[0]), AIMessage(content=h[1]) for h in history],
"question": message,
"retrieved_documents": None,
"answer": None,
"need_clarification": False,
"clarification_prompt": None
}
# 运行代理
result = customer_service_agent.invoke(initial_state)
# 返回回答
return result["answer"]
# 创建Gradio界面
demo = gr.ChatInterface(
fn=respond,
title="智能客服系统",
description="请输入您的问题,我将尽力为您解答",
theme="soft",
examples=[
"如何查询账户余额?",
"我想修改我的密码",
"你们的营业时间是什么时候?",
"如何申请信用卡?"
]
)
# 启动Web界面
if __name__ == "__main__":
demo.launch()运行项目
使用以下命令行运行webui:
bash
python app.py验证效果
现在,我们可以通过Web界面与智能客服系统进行交互。例如,我们可以询问:
如何查询账户余额?
系统会检索相关知识,并生成一个专业、友好的回答。
高级功能扩展
1. 添加多轮对话优化
为了提高多轮对话的连贯性,我们可以添加对话历史总结节点:
python
def summarize_conversation(state: CustomerServiceState) -> Dict:
"""总结当前对话,提取关键信息"""
chat_history = state["chat_history"]
if len(chat_history) < 6: # 对话不够长,不需要总结
return {}
# 构建提示
prompt = ChatPromptTemplate.from_messages([
("system", """
你是一个对话总结专家。请总结以下对话的关键信息,保留重要的用户需求和系统回应。
总结应该简洁但包含所有关键点。
"""),
("human", "对话历史:\n{chat_history}")
])
# 格式化提示
formatted_prompt = prompt.format(
chat_history=format_chat_history(chat_history)
)
# 生成总结
response = llm.invoke(formatted_prompt)
# 创建新的对话历史,只保留总结和最近两轮对话
new_chat_history = [
AIMessage(content=f"[对话总结] {response.content}")
] + chat_history[-4:] # 保留最近两轮对话
return {"chat_history": new_chat_history}
# 将总结节点添加到工作流中
workflow.add_node("summarize_conversation", summarize_conversation)
workflow.add_conditional_edges(
"generate_answer",
lambda state: "summarize_conversation" if len(state["chat_history"]) >= 6 else END
)
workflow.add_edge("summarize_conversation", END)2. 添加用户反馈机制
我们可以添加用户反馈机制,收集用户对回答的评价,并用于改进系统:
python
def process_feedback(feedback: str, question: str, answer: str):
"""处理用户反馈"""
# 记录反馈
with open("feedback_log.txt", "a") as f:
f.write(f"问题: {question}\n回答: {answer}\n反馈: {feedback}\n\n")
# 如果是负面反馈,可以触发额外处理
if feedback.lower() in ["不满意", "不好", "差", "不准确"]:
# 这里可以添加额外的处理逻辑
pass
return "感谢您的反馈!我们将不断改进服务质量。"
# 在Gradio界面中添加反馈按钮
with gr.Blocks() as demo:
chatbot = gr.Chatbot()
msg = gr.Textbox(label="输入您的问题")
clear = gr.Button("清除对话")
with gr.Row():
thumbs_up = gr.Button("👍 满意")
thumbs_down = gr.Button("👎 不满意")
feedback_result = gr.Textbox(label="反馈结果", interactive=False)
def user_message(message, history):
# 保存当前问题用于反馈
global current_question, current_answer
current_question = message
# 处理消息
response = respond(message, history)
current_answer = response
return "", history + [[message, response]]
msg.submit(user_message, [msg, chatbot], [msg, chatbot])
clear.click(lambda: None, None, chatbot, queue=False)
# 处理反馈
def handle_positive_feedback():
return process_feedback("满意", current_question, current_answer)
def handle_negative_feedback():
return process_feedback("不满意", current_question, current_answer)
thumbs_up.click(handle_positive_feedback, None, feedback_result)
thumbs_down.click(handle_negative_feedback, None, feedback_result)3. 添加知识库更新机制
为了保持知识库的更新,我们可以添加一个定期更新知识库的功能:
python
def update_knowledge_base(new_documents_path: str):
"""更新知识库"""
global vectorstore
# 加载新文档
loader = DirectoryLoader(new_documents_path, glob="**/*.txt", loader_cls=TextLoader)
new_documents = loader.load()
# 分割文档
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["\n\n", "\n", ".", "!", "?", ",", " ", ""],
length_function=len,
)
new_chunks = text_splitter.split_documents(new_documents)
# 更新向量数据库
vectorstore.add_documents(new_chunks)
vectorstore.persist()
return f"成功添加 {len(new_chunks)} 个文档片段到知识库"
# 添加知识库更新界面
with gr.Blocks() as admin_panel:
gr.Markdown("## 知识库管理")
new_docs_path = gr.Textbox(label="新文档路径")
update_button = gr.Button("更新知识库")
result = gr.Textbox(label="更新结果")
update_button.click(update_knowledge_base, new_docs_path, result)总结
通过本教程,我们学习了如何使用LangGraph和RAG技术构建一个智能客服应用。这个应用具有以下特点:
-
基于知识库的准确回答:系统能够从预先准备的知识库中检索相关信息,提供准确的回答。
-
多轮对话能力:系统能够记住对话历史,理解上下文,提供连贯的回答。
-
问题澄清机制:当用户问题不够明确时,系统会主动要求用户提供更多信息。
-
灵活的工作流:使用LangGraph构建的工作流可以根据不同情况选择不同的处理路径。
-
用户友好界面:通过Gradio构建的Web界面,用户可以方便地与系统交互。
这种智能客服系统可以应用于各种场景,如银行客服、电商客服、技术支持等,大大提高客服效率和用户满意度。
进阶应用场景
- 金融客服:回答账户查询、交易问题、产品咨询等
- 电商客服:处理订单查询、退换货、产品咨询等
- IT技术支持:解答软件使用问题、故障排除、系统配置等
- 医疗咨询:提供基础医疗信息、预约指导、健康建议等
通过LangGraph和RAG技术的结合,我们可以构建出更加智能、高效的客服系统,为用户提供更好的服务体验。