一、为什么需要 Dubbo?从项目架构说起
想理解 Dubbo,得先知道它解决了什么问题。我们从项目变大的过程来看:
核心概念:集群 vs 分布式
- 集群:多个相同的服务一起干活(比如 3 个订单服务同时接请求),抗住更多用户。
- 分布式:多个不同的服务分工合作(用户服务管登录、订单服务管下单),合起来完成整个业务。
1. 项目架构的演进
从单体到微服务的进化之路

架构演进对比表
| 架构类型 | 核心思想 | 优点 | 缺点 | 典型技术 |
|---|---|---|---|---|
| 单体架构 | 所有功能集中部署 | ✅ 开发部署简单 ✅ 小型项目首选 | ❌ 启动慢 ❌ 可靠性差 ❌ 扩展性差 | Servlet/JSP |
| 垂直架构 | 按业务拆分为独立系统 | ✅ 解耦业务模块 ✅ 独立部署 | ❌ 功能重复 ❌ 资源浪费 | 多SpringBoot应用 |
| 分布式架构 | 抽取公共服务,RPC调用 | ✅ 服务复用 ✅ 减少重复开发 | ❌ 服务变更影响所有消费者 | Dubbo/GRPC |
| SOA架构 | ESB统一管理服务 | ✅ 服务治理 ✅ 负载均衡 | ❌ 中心化瓶颈 ❌ 性能损耗 | Dubbo+ESB |
| 微服务架构 | 彻底服务化,独立部署 | ✅ 技术自由 ✅ 独立扩展 ✅ 容错性强 | ❌ 运维复杂 ❌ 分布式事务挑战 | SpringCloud/K8s |
关键演进解析
1. 单体 → 垂直架构
- 突破点:业务拆分
- 痛点解决:缓解单体臃肿问题
- 遗留问题:登录、支付等通用功能重复开发
2. 垂直 → 分布式架构
- 突破点:公共服务抽取 + RPC调用
- 核心技术:
bash
// RPC调用示例
UserService userService = (UserService) Naming.lookup("rmi://localhost:1099/UserService");
User user = userService.findById(1);- 遗留问题:服务变更引发"牵一发而动全身"
3. 分布式 → SOA架构
- 突破点:引入ESB企业服务总线
- 核心组件:
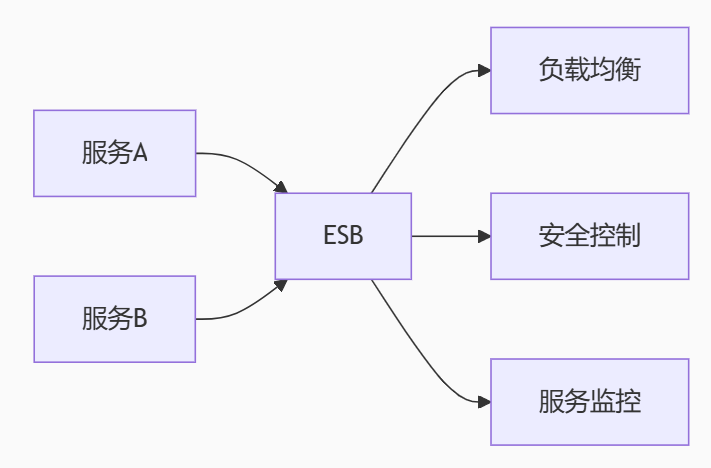 典型方案:Dubbo + ZooKeeper
典型方案:Dubbo + ZooKeeper
4. SOA → 微服务架构
本质区别:
| 维度 | SOA | 微服务 |
|---|---|---|
| 服务粒度 | 粗粒度(业务模块) | 细粒度(业务能力) |
| 数据管理 | 共享数据库 | 私有数据库 |
| 治理方式 | 集中式(ESB) | 去中心化 |
| 技术栈 | 统一技术 | 混合技术 |
- 核心特征:
- 🛠️ 技术异构性:不同服务可用不同语言开发
- 🗃️ 独立数据库:每个服务私有数据存储
- 🚀 自动化运维:CI/CD流水线部署
技术选型定位
- Dubbo:SOA时代的分布式服务治理解决方案
- SpringCloud:微服务时代的全家桶技术
关系 :微服务架构 ≈ SOA架构的升华 + 容器化赋能
演进本质:通过不断解耦和拆分,追求更高的灵活性、可用性和可维护性,每一步演进都是为了解决上一阶段的痛点。
2. Dubbo 的作用
Dubbo 就是解决 "分布式服务之间怎么调用" 的工具,它是一个RPC 框架(远程过程调用)。简单说:
你在 A 服务里调用 B 服务的方法,就像调用本地方法一样简单,不用关心网络传输、地址这些复杂细节。
还能管理服务(比如哪个服务在线、出问题了怎么处理)。
Dubbo定位:SOA时代的分布式服务框架,SpringCloud是微服务时代的解决方案
二、Dubbo核心概念
Dubbo 是阿里巴巴开源的高性能 RPC 框架,主要用于分布式系统中服务之间的调用和管理。
- Dubbo = 高性能RPC框架 + 服务治理能力
- 特点:轻量级、高性能、支持多种协议
- 官网:https://dubbo.apache.org
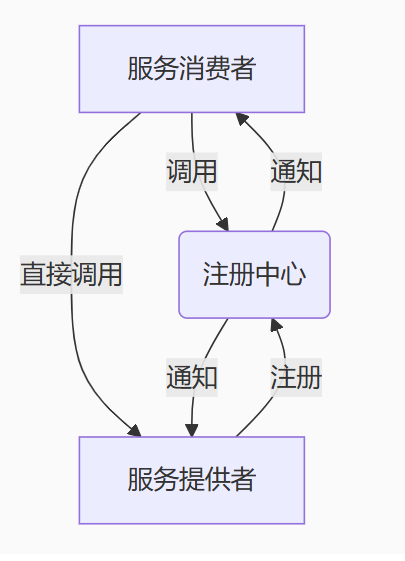
核心角色(4 个)
- 服务提供者(Provider):提供服务的一方(比如 "用户服务" 提供查询用户信息的功能)。
- 服务消费者(Consumer):调用服务的一方(比如 "订单服务" 调用 "用户服务")。
- 注册中心(Registry):服务的 "通讯录",提供者把地址告诉它,消费者从它这查地址(常用 Zookeeper)。
- 监控中心(Monitor):可选,看服务调用次数、耗时等。
Dubbo架构图
三、快速入门:3步实现服务调用(基于Spring Boot)
以 "订单服务调用用户服务" 为例,用 Spring Boot + Zookeeper(注册中心)实操。
准备工作
安装 Zookeeper(注册中心):
下载地址:Apache Zookeeper
启动:双击bin/zkServer.cmd(Windows),默认端口 2181。
步骤 1:创建服务提供者(Provider)
1.1 新建 Spring Boot 项目,加依赖
bash
<!-- Dubbo核心依赖 -->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-spring-boot-starter</artifactId>
<version>3.0.9</version>
</dependency>
<!-- Zookeeper依赖 -->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-dependencies-zookeeper-curator5</artifactId>
<version>3.0.9</version>
<type>pom</type>
</dependency>1.2 写服务接口和实现
bash
// 接口(单独抽出来,消费者也要用)
public interface UserService {
String getUsername(Long userId);
}
// 实现类(用@DubboService暴露服务)
@DubboService // 告诉Dubbo这是一个服务提供者
public class UserServiceImpl implements UserService {
@Override
public String getUsername(Long userId) {
return "用户" + userId + "的名字是小明"; // 模拟查询数据库
}
}1.3 配置 application.yml
bash
dubbo:
application:
name: user-service # 服务名,随便起但要唯一
registry:
address: zookeeper://localhost:2181 # 注册中心地址
protocol:
name: dubbo # 协议名
port: -1 # 端口(-1表示随机,避免冲突)1.4 启动类加注解@EnableDubbo
bash
@SpringBootApplication
@EnableDubbo // 开启Dubbo功能
public class UserServiceApplication {
public static void main(String[] args) {
SpringApplication.run(UserServiceApplication.class, args);
}
}步骤 2:创建服务消费者(Consumer)
2.1 新建 Spring Boot 项目,依赖和提供者一样
2.2 引入服务接口(复制提供者的 UserService 接口,包名要一致)
2.3 写调用代码
bash
@RestController
public class OrderController {
// 用@DubboReference远程注入服务
@DubboReference
private UserService userService;
@GetMapping("/order/{userId}")
public String getOrder(@PathVariable Long userId) {
// 调用远程服务,就像调用本地方法
String username = userService.getUsername(userId);
return "订单所属用户:" + username;
}
}2.4 配置 application.yml
bash
dubbo:
application:
name: order-service # 消费者服务名
registry:
address: zookeeper://localhost:2181 # 同样连接注册中心
server:
port: 8081 # 消费者端口,避免和提供者冲突2.5 启动类加 @EnableDubbo
bash
@SpringBootApplication
@EnableDubbo
public class OrderServiceApplication {
public static void main(String[] args) {
SpringApplication.run(OrderServiceApplication.class, args);
}
}步骤 3:测试
先启动 Zookeeper,再启动提供者,最后启动消费者。
访问消费者接口:http://localhost:8081/order/100,会返回:
订单所属用户:用户100的名字是小明
四、Dubbo 高级特性:小白必知 5 个功能
1. 服务治理工具:Dubbo-Admin
一个图形化界面,能看哪些服务在线、调用次数等。
下载地址:Dubbo-Admin
启动后访问localhost:8080,可以直观管理服务。
2. 超时与重试配置
- 超时:调用服务时,如果超过指定时间没响应,就断开连接(避免一直等)。
- 配置:@DubboService(timeout = 3000)(单位毫秒)。
- 重试 :调用失败后,自动重试几次(比如网络抖动导致失败)。
- 配置:@DubboService(retries = 2)(默认重试 2 次)。
bash
@DubboReference(
timeout = 3000, // 3秒超时
retries = 2 // 失败重试2次
)
private OrderService orderService;3. 负载均衡策略
bash
@DubboReference(loadbalance = "roundrobin") // 轮询策略
private ProductService productService;| 策略 | 特点 | 适用场景 |
|---|---|---|
| Random(默认) | 按权重随机 | 大多数场景 |
| RoundRobin | 按权重轮询 | 均匀分配请求 |
| LeastActive | 优先调用活跃数小的服务 | 避免雪崩 |
| ConsistentHash | 相同参数总是发到同一提供者 | 需要会话保持场景 |
4. 集群容错:服务调用失败的"应急预案"
当服务提供者是集群(多台服务器)时,如果其中一台调用失败,Dubbo 提供了多种 "容错策略" 来应对,避免整个请求失败。
6 种常用策略,按场景选择:
| 策略名称 | 核心逻辑 | 适合场景 |
|---|---|---|
| Failover Cluster(失败重试) | 调用失败后,自动重试其他服务器(默认重试 2 次,可通过retries配置)。 | 读操作(如查询数据),允许偶尔失败重试,不影响数据一致性。 |
| Failfast Cluster(快速失败) | 只调用一次,失败立即报错,不重试。 | 写操作(如创建订单),避免重复提交(比如重试导致多下单)。 |
| Failsafe Cluster(失败安全) | 调用出错时直接忽略,返回空结果,不影响主流程。 | 非核心功能(如日志收集、统计上报),失败了也不影响用户使用。 |
| Failback Cluster(失败自动恢复) | 调用失败后,后台记录请求,定时重试。 | 需保证最终成功的操作(如消息通知、数据同步),暂时失败没关系,后面补做。 |
| Forking Cluster(并行调用) | 同时调用多个服务器,只要有一个成功就返回结果。 | 实时性要求高的场景(如抢票),多服务器并行处理,快的先返回。 |
| Broadcast Cluster(广播调用) | 逐个调用所有服务器,有一个失败则整体失败。 | 需全量更新的操作(如清空缓存),必须所有服务器都执行成功才有效。 |
bash
@DubboReference(cluster = "failfast") // 快速失败
private PaymentService paymentService;5. 服务降级:非核心业务拖垮系统?"先砍了再说"
当系统压力过大(比如秒杀时流量暴增),可以主动 "降级" 非核心服务,保证核心功能(如支付)正常运行。
Dubbo 提供 2 种降级方式,通过mock配置:
| 降级方式 | 效果 | 适用场景 |
|---|---|---|
| mock=force:return null(强制返回空) | 调用服务时,不发起远程请求,直接返回 null(或自定义默认值)。 | 非核心服务(如推荐商品、热门评论),直接关掉不影响主流程。 |
| mock=fail:return null(失败后返回空) | 正常调用服务,失败后才返回 null,不抛异常。 | 半核心服务(如用户头像加载),能正常用就用,失败了也不报错。 |
bash
@DubboReference(mock = "force:return null") // 强制返回空
private LogService logService;五、常见问题解决方案
问题1:注册中心宕机后服务是否可用?
答案:可以!Dubbo会将服务地址缓存在本地
问题2:如何实现灰度发布?
方案:使用多版本控制
bash
// 提供者
@DubboService(version = "2.0")
public class NewUserServiceImpl implements UserService {}
// 消费者
@DubboReference(version = "1.0") // 默认使用旧版
private UserService userService;问题3:如何监控服务调用?
方案:集成Prometheus + Grafana
bash
dubbo:
metrics:
protocol: prometheus
enable: true六、最佳实践总结
- 服务拆分:按业务领域划分微服务
- 版本管理:每次变更升级服务版本号
- 超时设置:根据业务特点设置合理超时
- 熔断降级:核心服务配置降级策略
- 监控告警:实时监控服务健康状态