前言
- 💖💖作者:计算机程序员小杨
- 💙💙个人简介:我是一名计算机相关专业的从业者,擅长Java、微信小程序、Python、Golang、安卓Android等多个IT方向。会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。热爱技术,喜欢钻研新工具和框架,也乐于通过代码解决实际问题,大家有技术代码这一块的问题可以问我!
- 💛💛想说的话:感谢大家的关注与支持!
- 💕💕文末获取源码联系 计算机程序员小杨
- 💜💜
- 网站实战项目
- 安卓/小程序实战项目
- 大数据实战项目
- 深度学习实战项目
- 计算机毕业设计选题
- 💜💜
一.开发工具简介
- 大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
- 开发语言:Python+Java(两个版本都支持)
- 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
- 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
- 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
- 数据库:MySQL
二.系统内容简介
基于大数据的海洋塑料污染数据分析与可视化系统是一套专门针对海洋环境保护领域设计的综合性数据处理平台,该系统充分运用了当前主流的大数据技术栈来解决海洋塑料污染数据的存储、处理和分析难题。系统采用Hadoop分布式文件系统HDFS作为底层数据存储架构,能够高效处理海量的海洋污染监测数据,同时结合Spark大数据计算引擎和Spark SQL进行快速的数据查询与分析处理,显著提升了数据处理效率。在开发技术选型上,系统提供Python+Django和Java+Spring Boot两套完整的后端解决方案,前端采用Vue框架结合ElementUI组件库构建用户界面,通过Echarts图表库实现丰富的数据可视化展示效果。系统核心功能模块包括系统首页、用户信息管理、海洋塑料污染数据管理、污染时间尺度分析、污染区域分布分析、塑料来源构成分析以及海洋污染综合分析等八大功能板块,每个模块都针对海洋塑料污染的不同维度进行深入分析。通过Pandas和NumPy等数据分析库的支持,系统能够对海洋塑料污染的时空分布特征、污染源头构成、污染程度变化趋势等关键指标进行精准分析,并通过直观的图表和地图可视化展示分析结果,为海洋环境保护决策提供科学的数据支撑,同时也为相关研究人员和环保工作者提供了一个功能完备的海洋塑料污染数据分析工具。
三.系统功能演示
你知道用Spark处理海洋污染大数据有多震撼吗?这套可视化系统告诉你答案
四.系统界面展示

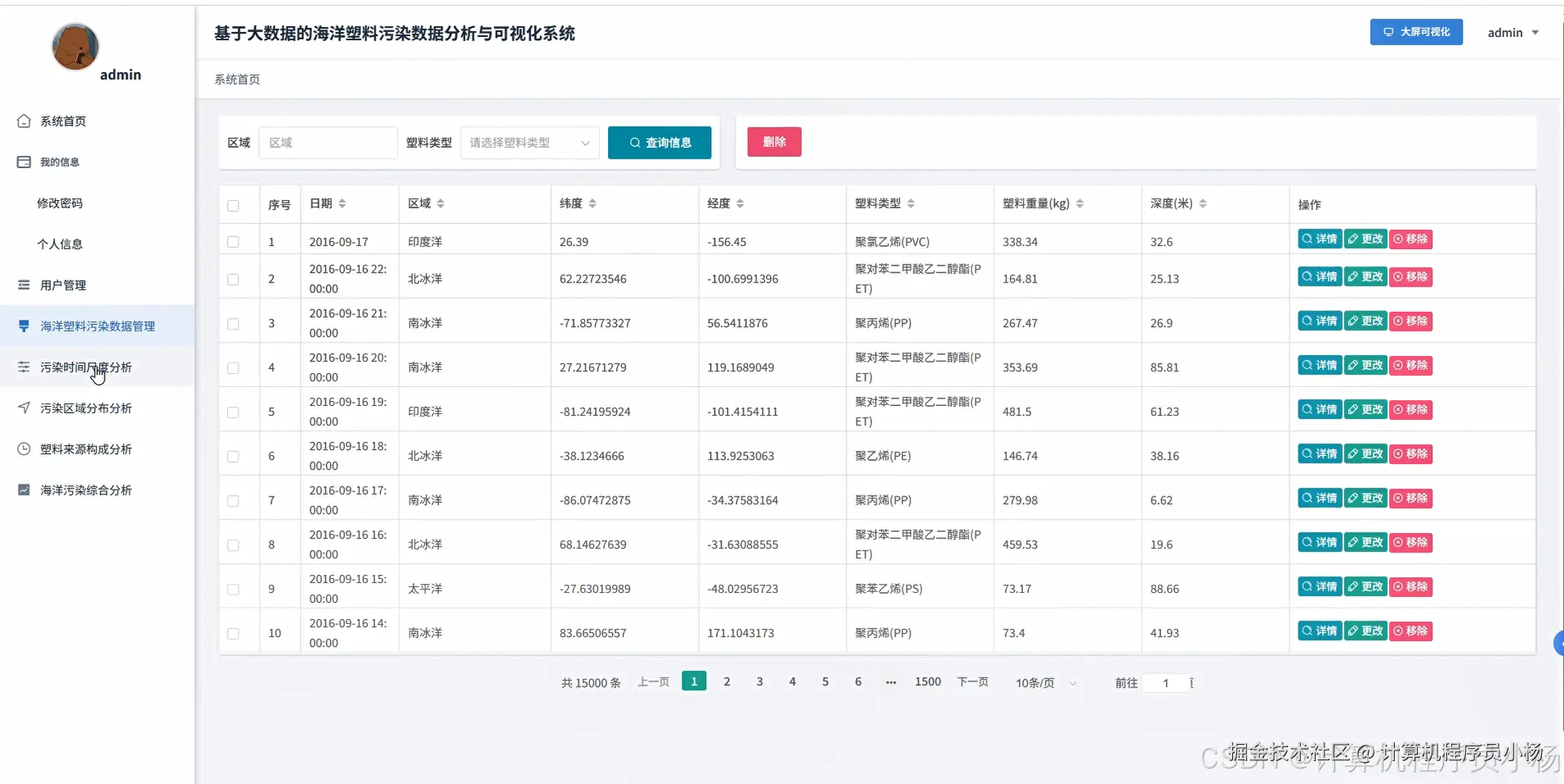
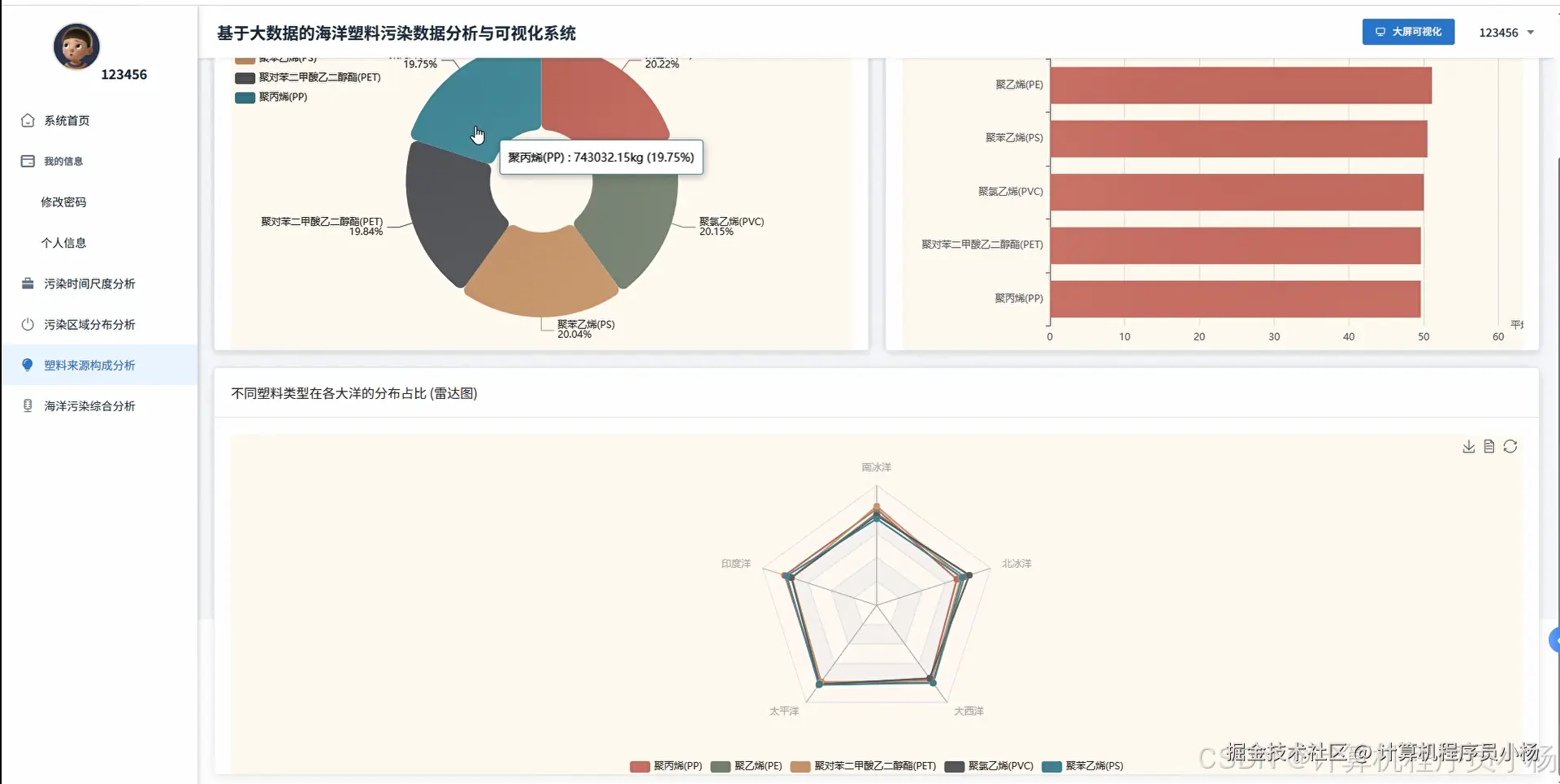
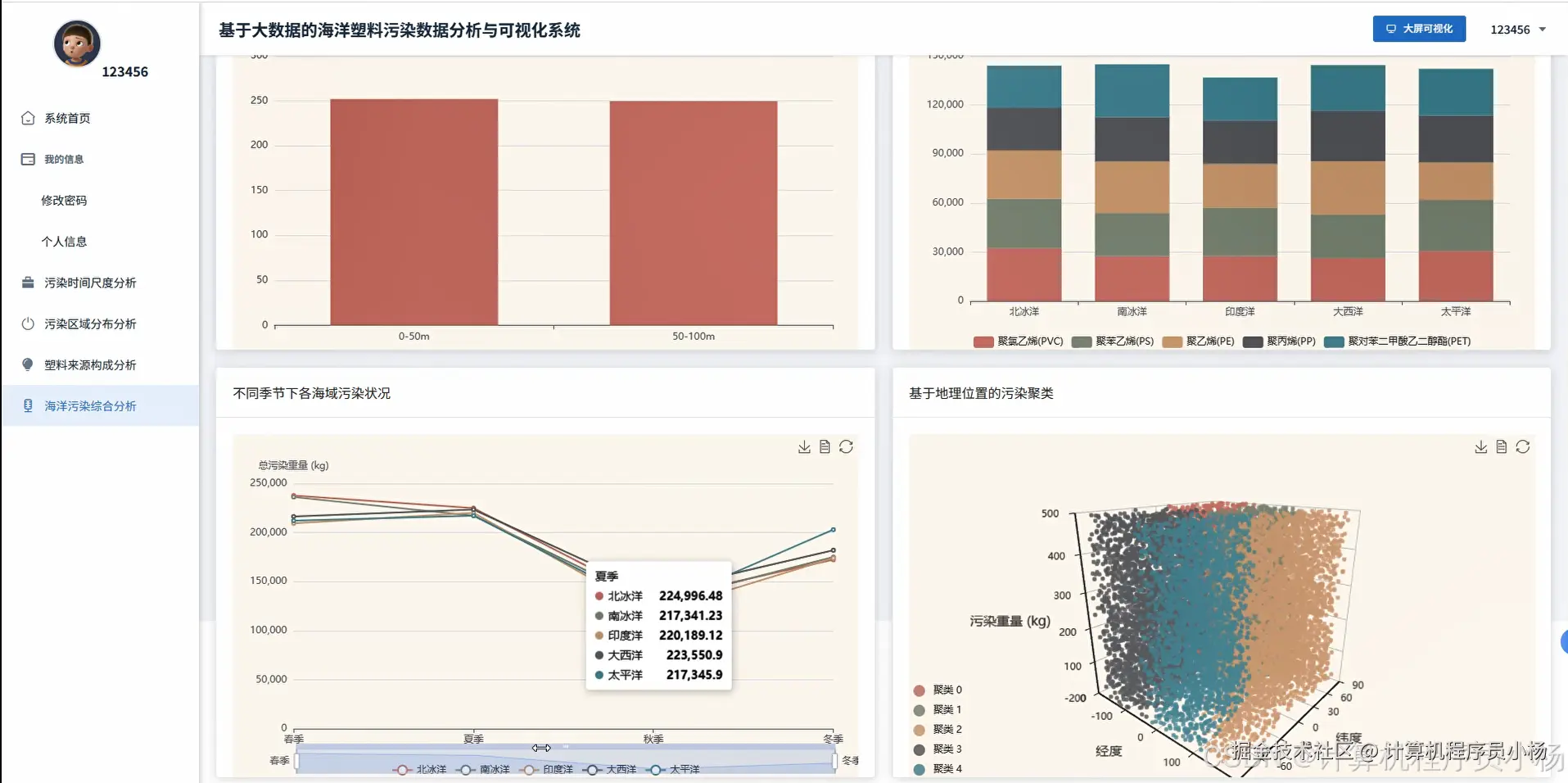
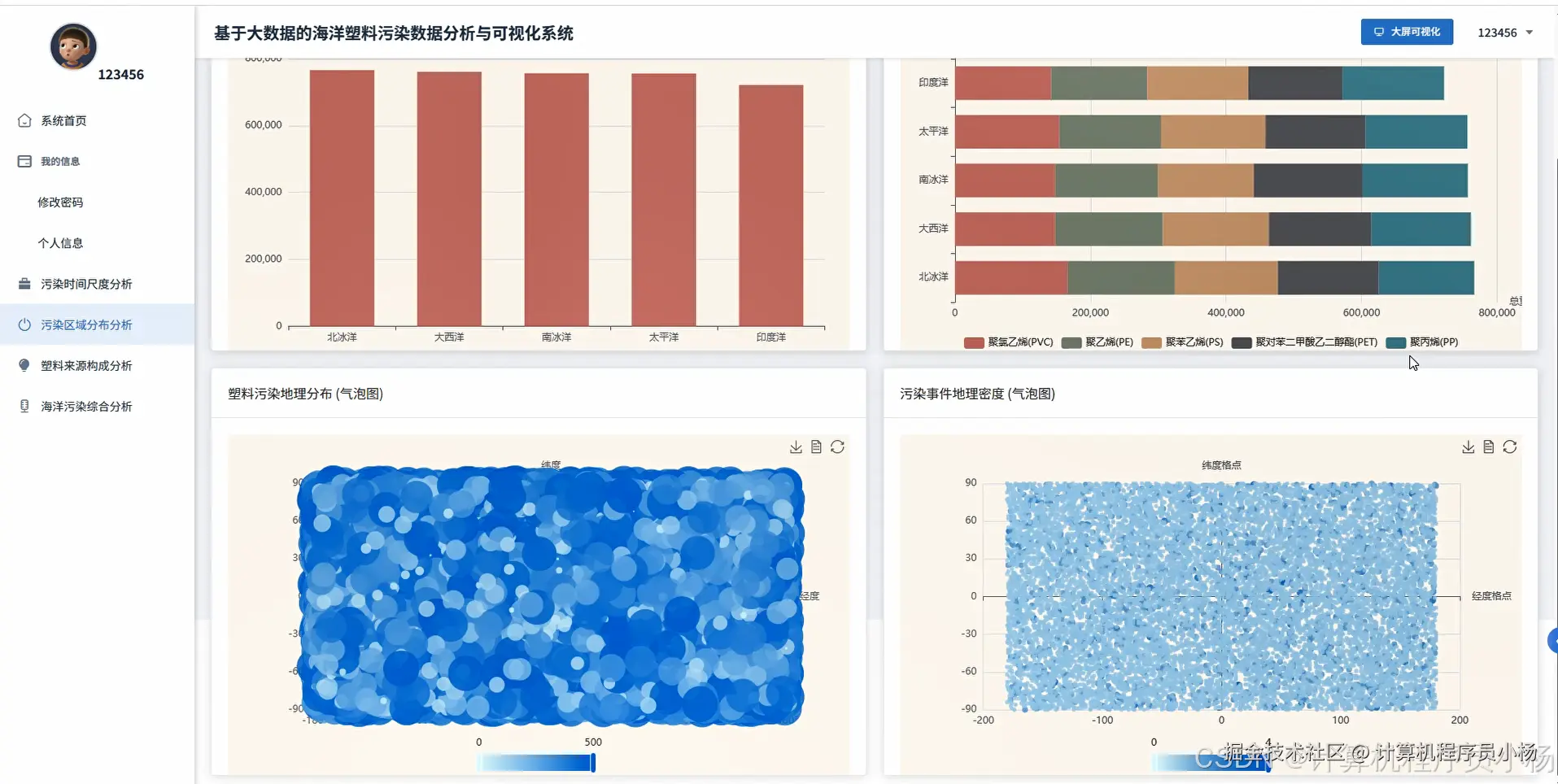
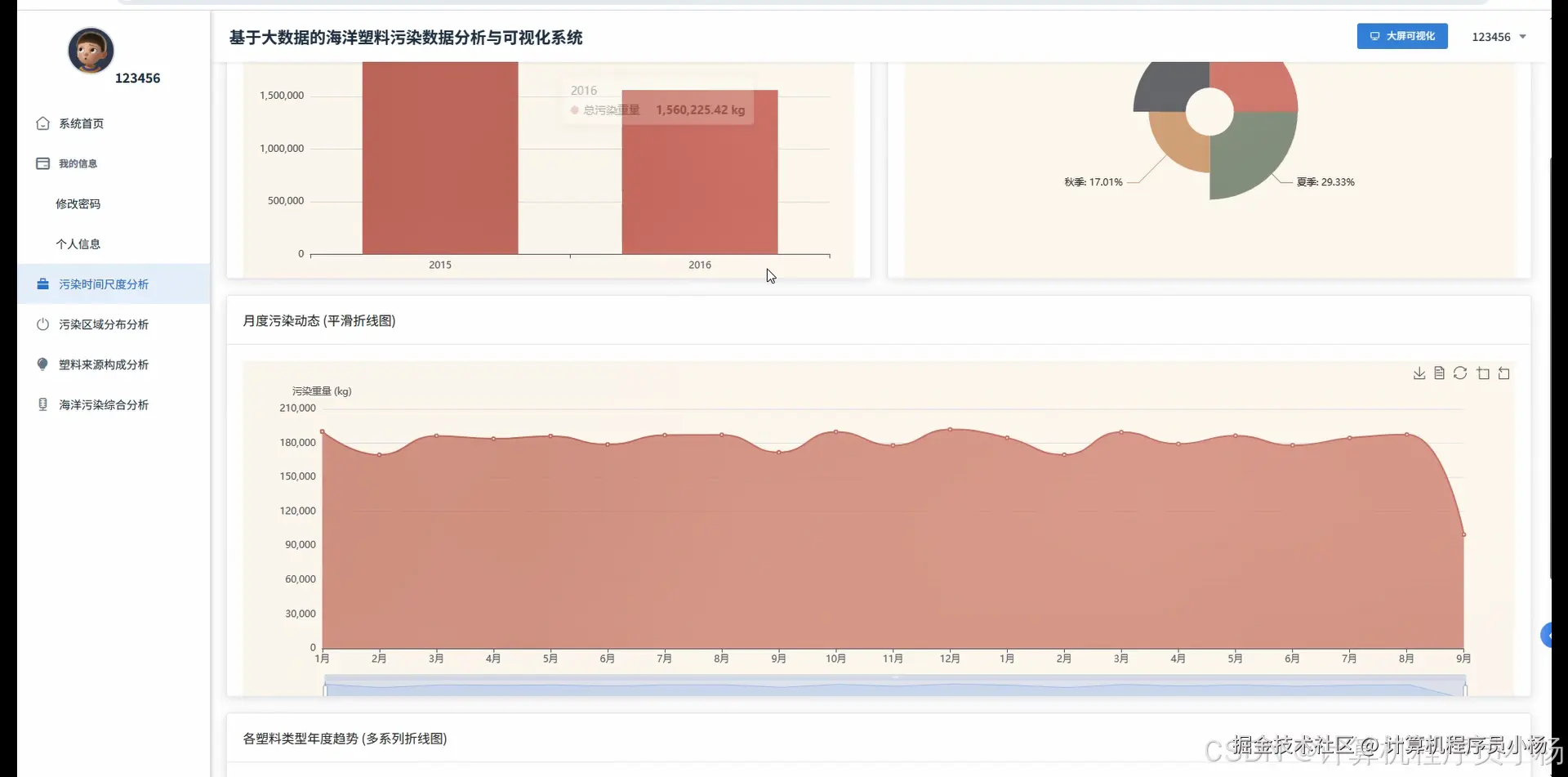
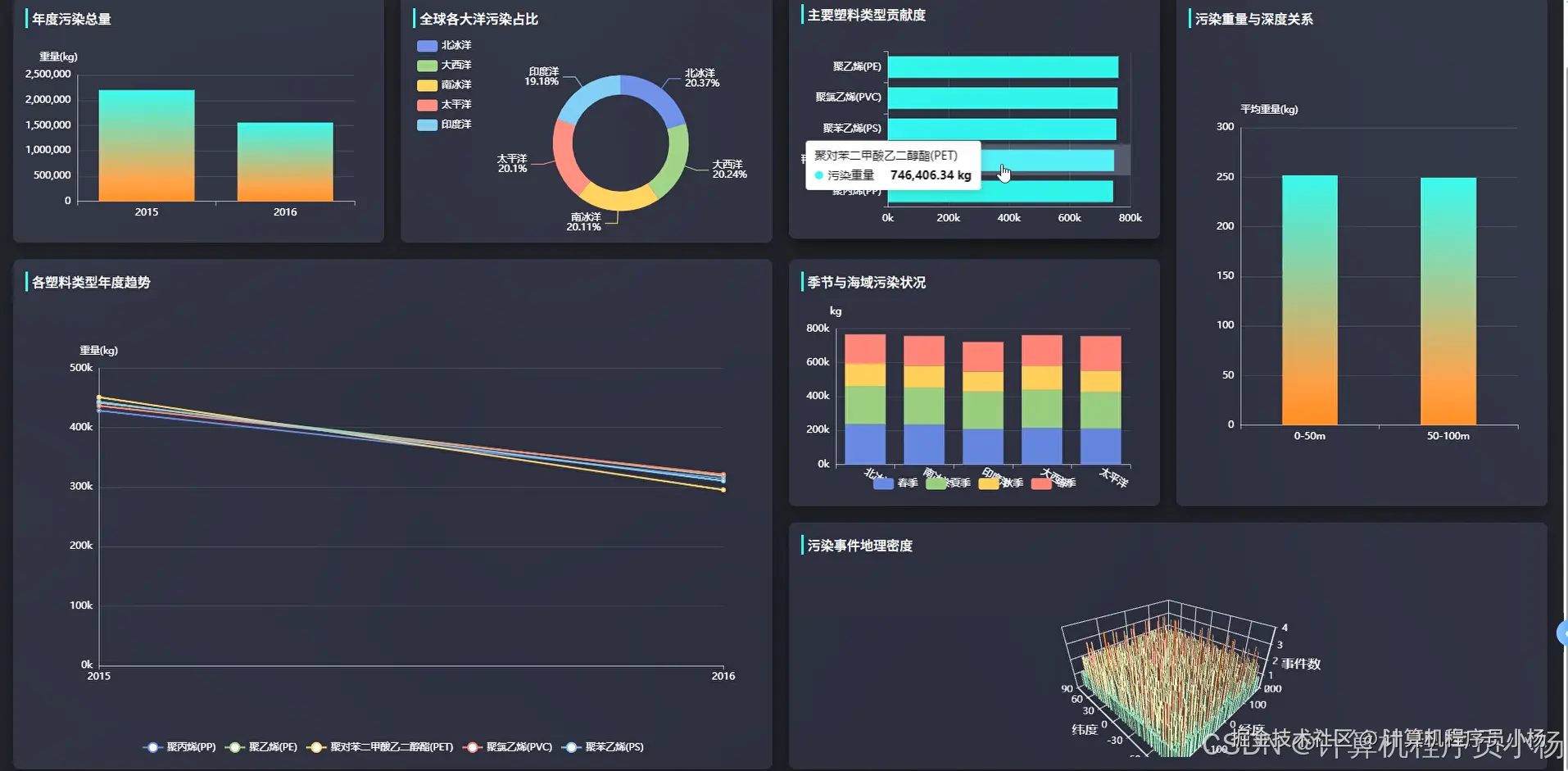
五.系统源码展示
python
# 核心功能1:海洋塑料污染数据管理
def add_pollution_data(request):
if request.method == 'POST':
data = json.loads(request.body)
location_name = data.get('location_name')
latitude = float(data.get('latitude'))
longitude = float(data.get('longitude'))
pollution_level = data.get('pollution_level')
plastic_type = data.get('plastic_type')
sample_date = datetime.strptime(data.get('sample_date'), '%Y-%m-%d')
concentration = float(data.get('concentration'))
water_depth = float(data.get('water_depth'))
# 数据验证和清洗
if not all([location_name, latitude, longitude, pollution_level, plastic_type]):
return JsonResponse({'error': '必填字段不能为空'}, status=400)
if not (-90 <= latitude <= 90) or not (-180 <= longitude <= 180):
return JsonResponse({'error': '经纬度范围不正确'}, status=400)
# 使用Spark处理大数据存储
spark_session = SparkSession.builder.appName("OceanPollutionData").getOrCreate()
pollution_df = spark_session.createDataFrame([{
'location_name': location_name,
'latitude': latitude,
'longitude': longitude,
'pollution_level': pollution_level,
'plastic_type': plastic_type,
'sample_date': sample_date,
'concentration': concentration,
'water_depth': water_depth,
'created_time': datetime.now()
}])
# 写入HDFS分布式存储
pollution_df.write.mode('append').parquet('/hadoop/ocean_pollution/raw_data/')
# 同步写入MySQL数据库
pollution_record = OceanPollutionData(
location_name=location_name,
latitude=latitude,
longitude=longitude,
pollution_level=pollution_level,
plastic_type=plastic_type,
sample_date=sample_date,
concentration=concentration,
water_depth=water_depth
)
pollution_record.save()
return JsonResponse({'message': '海洋塑料污染数据添加成功', 'id': pollution_record.id})
# 核心功能2:污染时间尺度分析
def time_scale_analysis(request):
start_date = request.GET.get('start_date')
end_date = request.GET.get('end_date')
analysis_type = request.GET.get('analysis_type', 'monthly')
# 初始化Spark会话
spark = SparkSession.builder.appName("TimeScaleAnalysis").getOrCreate()
# 从HDFS读取数据
pollution_df = spark.read.parquet('/hadoop/ocean_pollution/raw_data/')
pollution_df.createOrReplaceTempView("pollution_data")
# 根据分析类型构建SQL查询
if analysis_type == 'monthly':
sql_query = """
SELECT
YEAR(sample_date) as year,
MONTH(sample_date) as month,
AVG(concentration) as avg_concentration,
COUNT(*) as sample_count,
MAX(concentration) as max_concentration,
MIN(concentration) as min_concentration,
plastic_type
FROM pollution_data
WHERE sample_date BETWEEN '{}' AND '{}'
GROUP BY YEAR(sample_date), MONTH(sample_date), plastic_type
ORDER BY year, month
""".format(start_date, end_date)
elif analysis_type == 'yearly':
sql_query = """
SELECT
YEAR(sample_date) as year,
AVG(concentration) as avg_concentration,
COUNT(*) as sample_count,
SUM(CASE WHEN pollution_level = 'high' THEN 1 ELSE 0 END) as high_pollution_count,
plastic_type
FROM pollution_data
WHERE sample_date BETWEEN '{}' AND '{}'
GROUP BY YEAR(sample_date), plastic_type
ORDER BY year
""".format(start_date, end_date)
# 执行Spark SQL查询
result_df = spark.sql(sql_query)
# 使用Pandas进行进一步数据处理
pandas_df = result_df.toPandas()
# 计算时间趋势和变化率
pandas_df['concentration_change_rate'] = pandas_df.groupby('plastic_type')['avg_concentration'].pct_change()
# 识别污染高峰期
peak_periods = pandas_df.groupby('plastic_type').apply(
lambda x: x.nlargest(3, 'avg_concentration')[['year', 'month', 'avg_concentration']]
if analysis_type == 'monthly' else x.nlargest(3, 'avg_concentration')[['year', 'avg_concentration']]
).to_dict('records')
# 计算季节性变化模式
if analysis_type == 'monthly':
seasonal_pattern = pandas_df.groupby(['month', 'plastic_type'])['avg_concentration'].mean().unstack(fill_value=0)
seasonal_data = seasonal_pattern.to_dict('index')
else:
seasonal_data = {}
analysis_result = {
'time_series_data': pandas_df.to_dict('records'),
'peak_periods': peak_periods,
'seasonal_pattern': seasonal_data,
'total_samples': int(pandas_df['sample_count'].sum()),
'analysis_period': f"{start_date} 至 {end_date}",
'trend_summary': generate_trend_summary(pandas_df)
}
return JsonResponse(analysis_result)
# 核心功能3:污染区域分布分析
def regional_distribution_analysis(request):
region_type = request.GET.get('region_type', 'coordinate')
pollution_threshold = float(request.GET.get('threshold', 0.5))
# 启动Spark分析引擎
spark = SparkSession.builder.appName("RegionalAnalysis").getOrCreate()
# 读取HDFS中的海洋污染数据
pollution_df = spark.read.parquet('/hadoop/ocean_pollution/raw_data/')
pollution_df.createOrReplaceTempView("regional_pollution")
# 基于经纬度进行区域聚类分析
coordinate_analysis_sql = """
SELECT
ROUND(latitude, 1) as lat_zone,
ROUND(longitude, 1) as lng_zone,
COUNT(*) as pollution_points,
AVG(concentration) as avg_pollution,
MAX(concentration) as max_pollution,
AVG(water_depth) as avg_depth,
COLLECT_LIST(plastic_type) as plastic_types
FROM regional_pollution
GROUP BY ROUND(latitude, 1), ROUND(longitude, 1)
HAVING AVG(concentration) > {}
ORDER BY avg_pollution DESC
""".format(pollution_threshold)
regional_stats = spark.sql(coordinate_analysis_sql)
pandas_regional = regional_stats.toPandas()
# 计算污染密度热力图数据
heatmap_data = []
for _, row in pandas_regional.iterrows():
pollution_intensity = min(row['avg_pollution'] / pollution_threshold, 5.0)
heatmap_data.append({
'lat': float(row['lat_zone']),
'lng': float(row['lng_zone']),
'intensity': float(pollution_intensity),
'count': int(row['pollution_points']),
'max_pollution': float(row['max_pollution'])
})
# 识别污染热点区域
hotspot_threshold = pandas_regional['avg_pollution'].quantile(0.8)
hotspot_regions = pandas_regional[pandas_regional['avg_pollution'] >= hotspot_threshold]
# 计算区域污染等级分布
pollution_levels_sql = """
SELECT
pollution_level,
COUNT(*) as count,
ROUND(latitude/10)*10 as region_lat,
ROUND(longitude/10)*10 as region_lng
FROM regional_pollution
GROUP BY pollution_level, ROUND(latitude/10)*10, ROUND(longitude/10)*10
"""
level_distribution = spark.sql(pollution_levels_sql).toPandas()
# 使用NumPy计算空间相关性
import numpy as np
coordinates = pandas_regional[['lat_zone', 'lng_zone']].values
concentrations = pandas_regional['avg_pollution'].values
# 计算最近邻污染相关性
spatial_correlation = np.corrcoef(coordinates[:, 0], concentrations)[0, 1] if len(coordinates) > 1 else 0
# 生成区域风险评估
risk_assessment = []
for _, region in hotspot_regions.iterrows():
risk_score = calculate_risk_score(region['avg_pollution'], region['pollution_points'], region['avg_depth'])
risk_assessment.append({
'location': f"({region['lat_zone']}, {region['lng_zone']})",
'risk_level': get_risk_level(risk_score),
'pollution_value': float(region['avg_pollution']),
'sample_density': int(region['pollution_points'])
})
distribution_result = {
'heatmap_data': heatmap_data,
'hotspot_regions': hotspot_regions.to_dict('records'),
'pollution_level_distribution': level_distribution.to_dict('records'),
'spatial_correlation': float(spatial_correlation),
'risk_assessment': risk_assessment,
'total_analyzed_regions': len(pandas_regional),
'high_risk_region_count': len(risk_assessment)
}
return JsonResponse(distribution_result)
def generate_trend_summary(df):
if df.empty:
return "暂无足够数据进行趋势分析"
latest_avg = df['avg_concentration'].iloc[-1] if len(df) > 0 else 0
earliest_avg = df['avg_concentration'].iloc[0] if len(df) > 0 else 0
change_rate = ((latest_avg - earliest_avg) / earliest_avg * 100) if earliest_avg > 0 else 0
trend_direction = "上升" if change_rate > 5 else "下降" if change_rate < -5 else "稳定"
return f"污染浓度整体呈{trend_direction}趋势,变化幅度为{abs(change_rate):.1f}%"
def calculate_risk_score(pollution_level, sample_count, water_depth):
base_score = pollution_level * 10
density_factor = min(sample_count / 100, 2.0)
depth_factor = 1.5 if water_depth < 50 else 1.0
return base_score * density_factor * depth_factor
def get_risk_level(score):
if score >= 15:
return "极高风险"
elif score >= 10:
return "高风险"
elif score >= 5:
return "中等风险"
else:
return "低风险"六.系统文档展示

结束

💕💕文末获取源码联系 计算机程序员小杨