■ 背景:扩散模型推理成本亟待优化
扩散模型(Diffusion Models)近年来在高保真图像和视频生成上取得了令人瞩目的成果。然而,这类模型在推理阶段需要经过数十步乃至上百步的迭代去噪,每一步都要运行庞大的 U-Net 或 Transformer 模型,导致推理耗时巨大。对于高分辨率生成或视频生成等应用,迭代推理的开销更是呈指数级上涨,使实时应用变得非常困难。如何在不牺牲生成质量的前提加速扩散模型的推理,已成为学界和工业界共同关注的课题。
01
扩散模型推理优化的总体方案
基于上述需求,PaddleMIX 从模型蒸馏、模型推理缓存(Training-Free)以及深度学习框架编译优化等多个技术维度出发,打造了 Fast-Diffusers 扩散模型推理加速工具箱,便于开发者根据实际场景灵活组合运用,从而有效提升扩散模型的推理速度。在第一期中我们介绍了动态跳过冗余计算(SortBlock)、智能缓存复用特征(TeaBlockCache)和数学近似预测(FirstBlock-Taylor)等 Training-Free 加速算法,在保持与原始模型几乎一致的生成质量的同时,将扩散模型的推理速度提升了2倍以上。本期稿件将从蒸馏加速和框架高性能优化两个方面介绍 Fast-Diffusers 工具箱中扩散模型的加速策略。
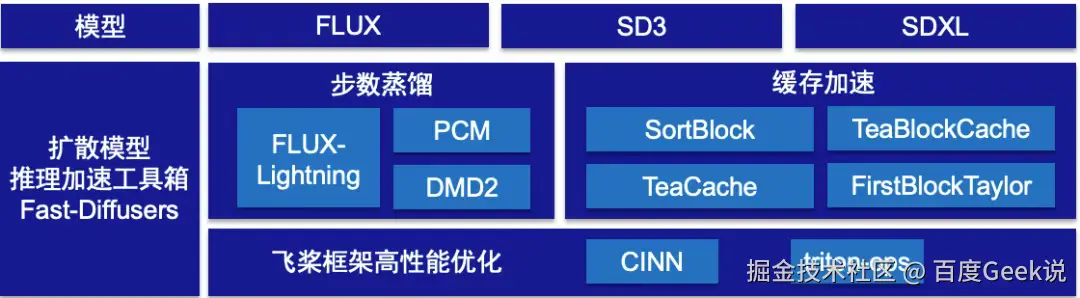 图1 推理加速工具箱
图1 推理加速工具箱
▎蒸馏加速方案和框架性能优化
主流的扩散模型蒸馏加速方法包括有一致性模型(Consistency Models),渐进式蒸馏(Progressive Distillation)以及分布匹配蒸馏(Distribution Matching Distillation)等。一致性模型建立在概率流常微分方程(PF-ODE)上,使用一致性函数将 PF-ODE 轨迹上任何时间步的点映射到轨迹的起点,支持一步生成高质量样本,同时保留多步采样能力以平衡计算成本与生成质量。分布匹配蒸馏通过分布级对齐(Distribution Matching)而非路径级模仿,在保持图像质量的同时实现数量级的速度提升,通过要求学生模型生成的图像分布应与教师模型生成的分布的一致性,完成一步生成图像的过程。
PaddleMIX 最新发布的扩散模型工具箱 PPDiffusers 中,集成了一致性模型 PCM(Phased Consistency Distillation)和 DMD2(Improved Distribution Matching Distillation for Fast Image Synthesis)算法,同时 **PaddleMIX 推出自研蒸馏加速模型 FLUX-Lightning,实现4步快速的高质量高分辨率图像生成,生成效果超越业界开源和闭源模型,达到业界 SOTA 水平。**另外使用飞桨深度学习编译器 CINN 进一步优化推理性能,对比 torch compile、Onediff、TensorRT 等主流推理优化框架,推理性能取得了显著的性能提升。
02
FLUX-Lightning 简介
PPDiffusers 提出了基于 FLUX 的蒸馏加速模型 FLUX-Lightning,可以在4步极少步数下,生成高分辨率高质量的图像,定量指标和定性指标均超越业界开源和闭源模型,达到了业界 SOTA 水平。

图2 FLUX-Lightning 4步推理结果
我们提出的 FLUX-Lightning 模型主要包含4个部分,区间一致性蒸馏(Phased Consistency Distillation),对抗学习(Adversarial Learning),分布匹配蒸馏(Distribution Matching Distillation),矫正流损失(reflow loss),完整框架如下图所示。
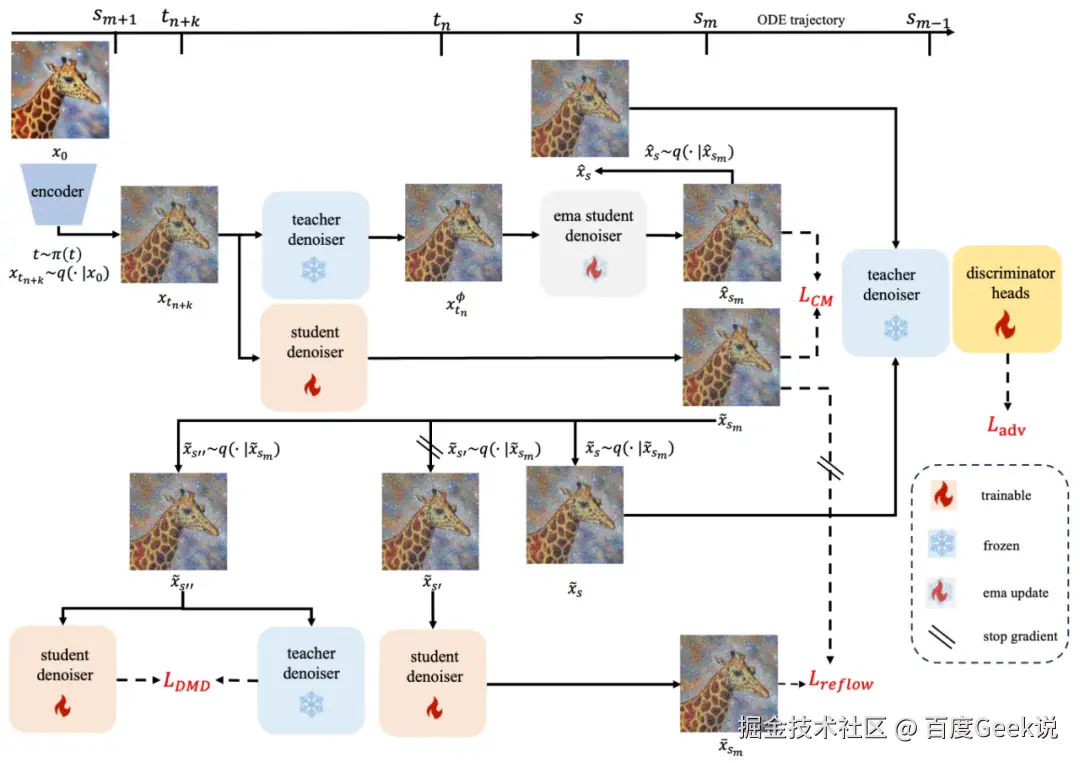
图3 FLUX-Lightning 框架
▎区间一致性蒸馏


▎对抗学习
为了进一步提升少步数下的图像生成质量,FLUX-Lightning 模型引入了对抗学习(Adversarial Learning),使用 discriminator 在 latent space 判别真实样本和虚假样本。
discriminator 模型由冻结的 teacher denoiser 和多个可训练的 discriminator heads 组成,前者负责提取图像特征,后者负责进行判别工作。图3展示了以 FLUX 为 teacher denoiser 的 discriminator 模型结构,FLUX 包含19个 FluxTransformerBlock 和38个 FluxSignleTransformerBlock,共计57个 TransformerBlock,将每个 TransformerBlock 的输出的图像特征 hidden states 输入到可训练的 discriminator heads 中,discriminator heads 由多个卷积层和残差结构组成,判别输入样本为真实样本还是虚假样本。
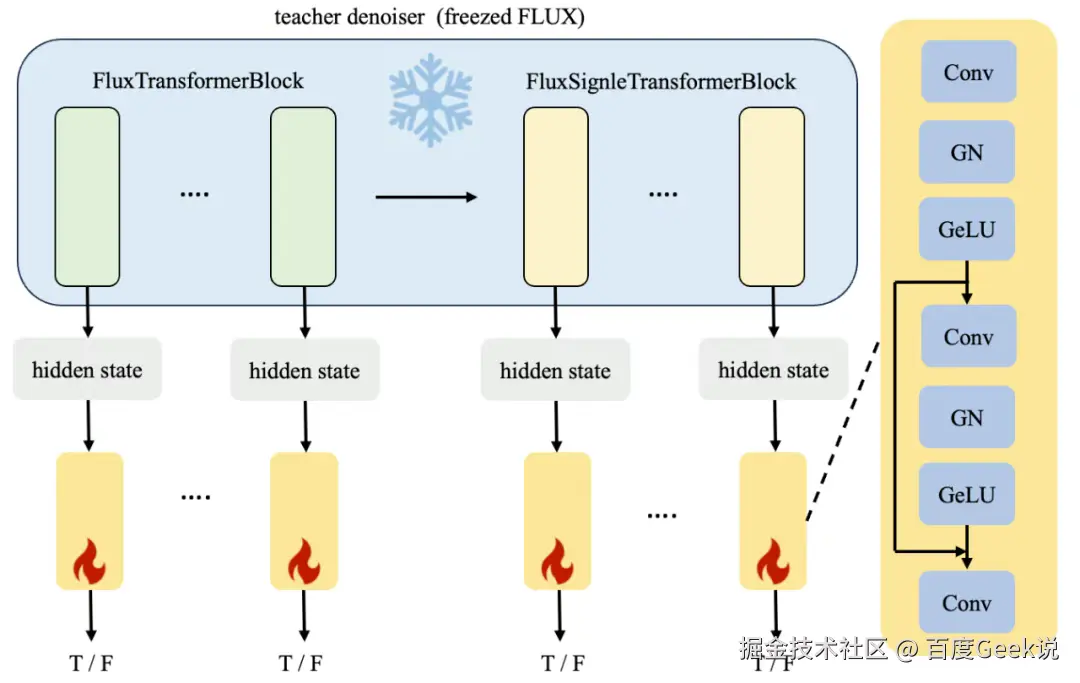
图4 discriminator 网络架构

▎分布匹配蒸馏

▎矫正流损失

▎算法流程
算法完整流程如下所示

03
飞桨编译器高性能推理
深度学习编译器是一种专门为深度学习模型优化和部署而设计的工具,用于提高模型的计算效率、降低内存占用、加速训练推理过程,核心价值在于弥合高层算法描述与底层硬件指令集之间的语义鸿沟。编译器功能上是将高层次的深度学习模型转换为低层次的、高效的、底层硬件可执行的代码。编译器通过将框架输出的初始计算图转化为具有严格语义定义的中间表示层,保留计算图的完整结构,随后在中间表示层实施多轮迭代优化,最终通过目标硬件感知的代码生成模块,将优化后的中间表示转化为高度特化的机器指令序列。简单来说,深度学习编译器在深度学习框架和底层硬件之间充当了"翻译"的角色,能够将用户定义的神经网络模型描述转化为底层硬件能够理解和执行的指令。编译器在实现这种转换的过程中,应用了一系列优化技术,以提高模型在各种硬件平台上(如 CPU、GPU)的执行效率。以下是飞桨框架编译器(CINN, Compiler Infrastructure for Neural Networks)整体流程图。
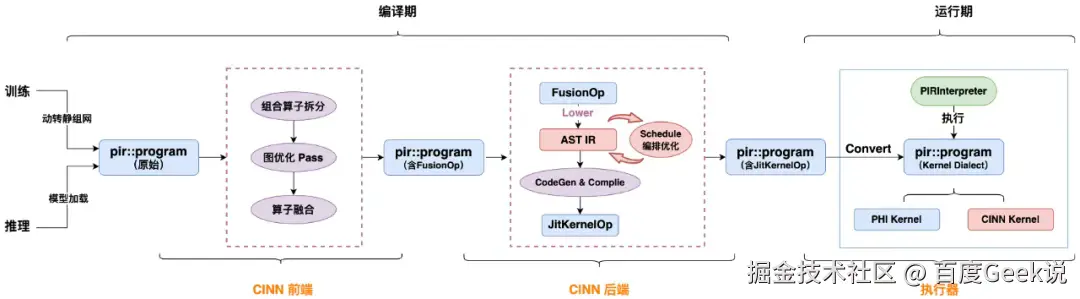
▎生成模型结合 CINN 推理性能优化
针对多模态生成模型推理时间长的问题,基于飞桨深度学习编译器 CINN,我们对于 FLUX 模型在 A800单卡推理情况下进行了飞桨框架推理性能优化实验,对比基于 xDiT 优化框架提供的 Torch Compile、Onediff 和 TensorRT 推理优化性能指标作为竞品。通过编译器优化所带来的性能加速,飞桨在 FLUX.1-dev 和 FLUX.1-schnell 这两个官方模型配置的推理中都取得了显著的性能提升,并且实现对比竞品的性能优势。
飞桨单卡推理性能测速和性能优化提升如下表所示。
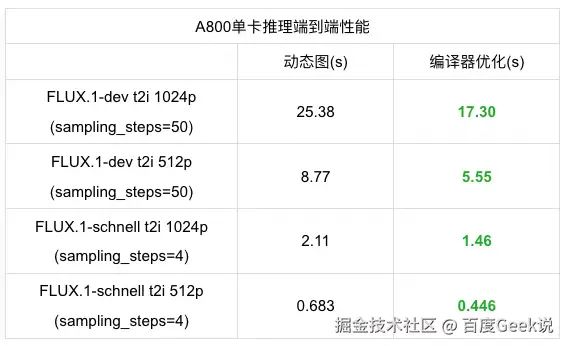
FLUX 模型动态图编译器推理性能
通过表格中的性能测速对比可以发现,对于 FLUX.1-dev 模型的推理性能,输出图像维度为1024p 和512p 的情况下,使用飞桨编译器优化对比原生动态图推理性能提升分别达到31.8%和36.7%,而对于 FLUX.1-schnell 模型的推理性能,使用编译器优化对比原生动态图推理性能提升分别达到30.8%和34.6%,对于不同配置下 FLUX 系列模型都表现出了显著性能提升。
飞桨单卡推理性能测速和性能竞品对比如下表所示。
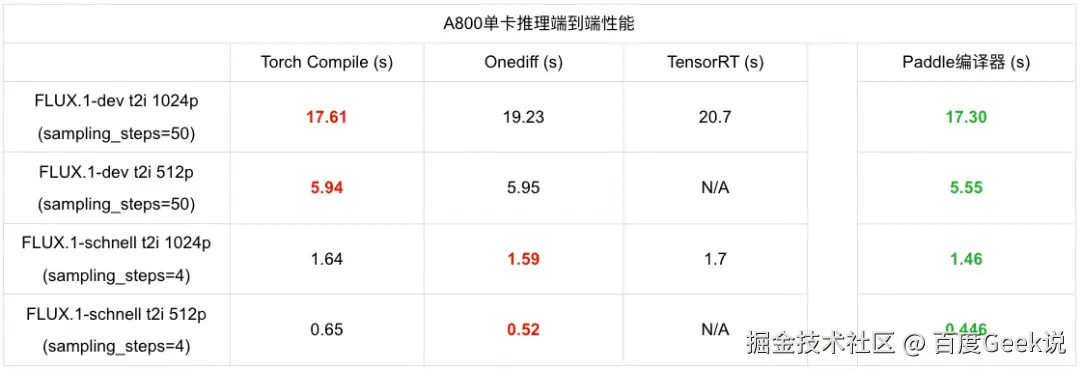
▎FLUX 模型推理性能竞品对比
我们对于市场上文生图大模型推理性能优化策略进行了性能分析,包括 torch compile、Onediff、TensorRT 等主流推理优化框架。通过对比可以发现基于飞桨编译器优化实现的 FLUX 推理在各个配置下都体现出了领先的推理性能。对于 FLUX.1-dev 模型,输出图像维度为1024p 和512p 的情况下,飞桨编译器推理性能对比竞品中性能最优的 Torch compile 推理性能提升分别达到1.4%和6.5%, 对于 FLUX.1-schnell 模型,飞桨编译器推理性能对比竞品中性能最优的 Onediff 推理性能提升分别达到1.4%和6.5%, 体现出了飞桨框架在市场中的推理性能方面的领先性,以及在 FLUX 模型各不同配置和参数设置情况下稳定的性能优势。同时我们也将该技术应用到自研蒸馏加速模型 FLUX-Lightning 中,开启 CINN 后在 A800上单卡推理时延能从2.21s 进一步降低到1.66s。
04
实验结果
▎实验设置
数据方面,我们基于 laion-aesv2数据集筛选45w 数据,筛选条件为:图像长宽都大于1024,美学指标 aes>6,水印概率分数<0.5。使用 COCO-10k 作为评测数据集。
模型方面,选用目前文生图领域最新的 FLUX 模型作为基础模型,由于 FLUX 模型自带 CFG 蒸馏,将 guidance scale 进行 embedding 后作为模型输入,所以训练时默认使用 CFG-augmented ODE solver。
评测指标,方面选择 CLIP 指标和 FID-FLUX,其中 FID-FLUX 指标参考 PCM 模型的 FID-SD 指标,使用原始 FLUX dev 模型的生成结果(50 step)计算 FID 分数。CLIP 指标用于评价生成结果与 prompt 的符合程度。
模型训练方面,使用 lora 训练的方式(lora rank=32),有效节省计算资源消耗。模型总 loss 如下所示,其中
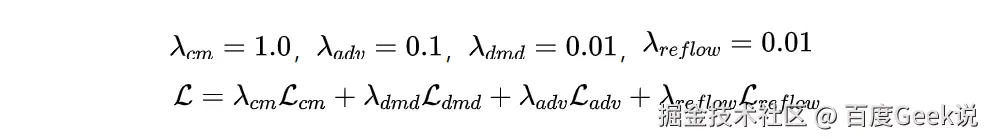
▎定量结果
消融实验定量结果显示,我们使用的 Adversarial Learning,Distribution Matching Distillation 以及 reflow loss 都获得了模型效果的提升,证明了 FLUX-Lightning 优化点的有效性。
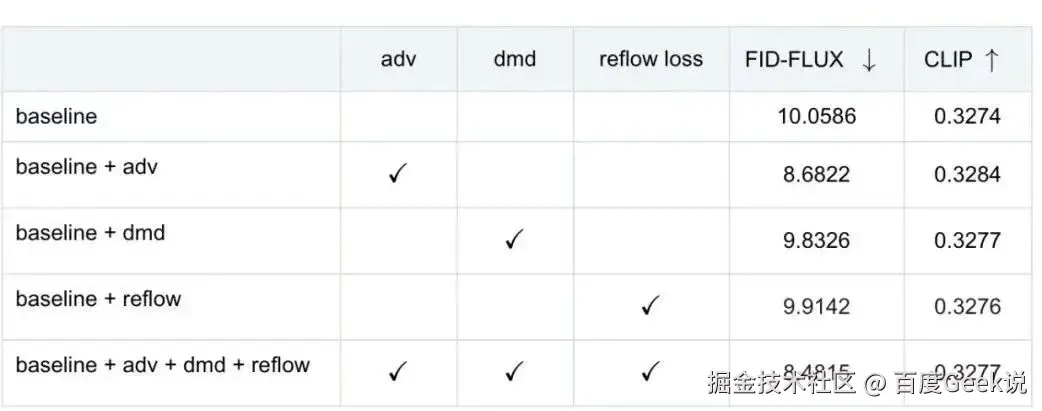
表1 消融实验
为了进一步验证 FLUX-Lightning 模型的效果,我们和目前 SOTA 的基于 FLUX 的蒸馏加速模型进行了全面的对比,包括 FLUX schnell,TDD (Target-Driven Distillation: Consistency Distillation with Target Timestep Selection and Decoupled Guidance),SwD (Scale-wise Distillation of Diffusion Models)以及 hyper-flux,其中 flux schnell 和 Hyper-FLUX 是闭源模型,TDD 和 Swd 为开源模型,且所有模型均基于 FLUX 蒸馏得到。对比结果如下所示,在 FID-FLUX 指标上 FLUX-Lightning 模型获得了最好的效果(8.0182),CLIP 指标上也展现出了具有竞争力的分数。
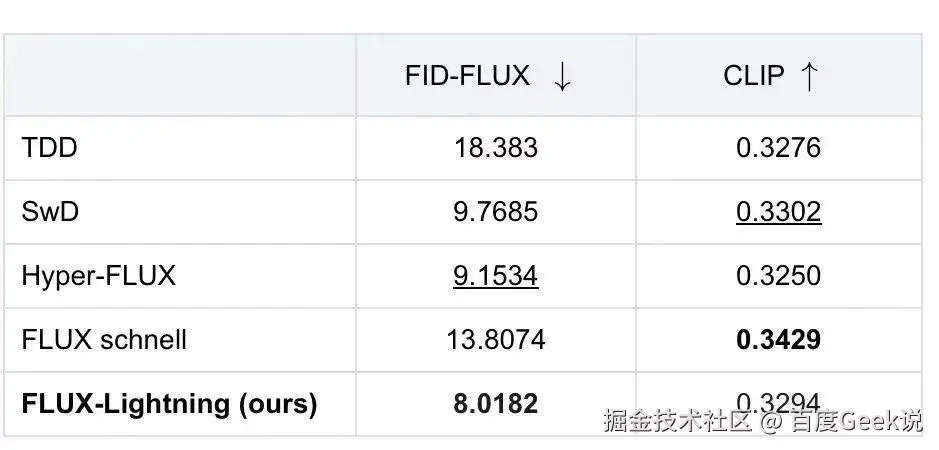
表2 定量实验结果
备注:消融实验使用28w 数据实验,完整 FLUX-Lightning 模型使用全量45w 数据训练
▎定性结果
下面展示了我们的 FLUX-Lightning 模型和其他竞品之间的图像生成效果对比,可以看到 FLUX-Lightning 模型在图像质量、prompt 一致性、生成准确性方面都超过了其他竞品。具体来说:
FLUX-Lightning 在人体部位的生成上更加准确。例如第一行大部分竞品生成的脚部都很怪异,FLUX-Lightning 生成了正确的脚部同时更加符合"没有被毯子盖住"的含义。第二行和第三行中大部分竞品生成的手指数量不对或者形状不对,FLUX-Lightning 的手指数量性状则完全正确。
FLUX-Lightning 具有更好的文字生成的能力。在第4行中需要生成"New York City, 100 miles"的文字,TDD 生成了模糊不清的文字,SwD 缺少"miles",Hyper-FLUX 的"100"很模糊,FLUX schnell 生成了不需要的"ew caft"的乱码,只有 FLUX-Lightning 生成了清晰的"New York City, 100 miles"文字。
FLUX-Lightning 可以生成更合理的人体姿态。第5行展示了抛棒球的运动员,TDD 和 Hyper-FLUX 的手臂部分出现明显扭曲,SwD 的手部和棒球合在了一起,FLUX-Lightning 生成的整体动作以及局部特征更加合理准确;第6行展示了跑步的运动员,SwD 生成的腿部和 FLUX schnell 生成的手臂都有明显问题,TDD 和 Hyper-FLUX 则是生成了不合理的背部文字,只有 FLUX-Lightning 生成了正确的跑步姿势以及背部"8"的文字。
FLUX-Lightning 生成内容和 prompt 更加契合。第7行要求生成"一家三口",SwD 和 flux schnell 仅仅生成了两个人,Hyper-FLUX 则是生成了2个男人,TDD 生成了一家三口但是人物形态扭曲,FLUX-Lightning 正确生成了一家三口,同时人物形态正常。第8行中,TDD 和 FLUX schnell 没有体现出"大象扬起鼻子"的样子,SwD 和 Hyper-FLUX 的图像细节和背景丰富度较差,FLUX-Lightning 在大象形态和背景丰富程度上更加优秀。最后一行中,TDD 和 SwD 的手部细节扭曲,Hyper-FLUX 没有展现出"正在梳头"的状态,flux schnell 则是生成了奇怪的梳子,FLUX-Lightning 在人物细节、物体细节和动作上都更胜一筹。

▎人工评测
为了更加全面地评测 FLUX-Lightning 的效果,我们进行了图像生成效果的人工评测。具体来说,我们生成了50个富有挑战性的 prompt,对 TDD,SwD,Hyper-FLUX,FLUX schnell 及 FLUX-Lightning 共计5个模型的生成结果进行排序,4位评审员采样盲评的方式,按照结果好坏从高到低分别得到10分,7分,5分,3分,1分,最终取平均分。部分 prompt 示例如下所示,第一行中,需要考察生成结果是否包含"3个女性","医院","病床,医疗设备"等元素。第二行中,考察生成模型是否包含"蒙古包","马头琴"以及"墙上的乐器"等元素,同时还要依据人物是否扭曲、图像质量等多个维度进行评判。


图5 人工评测 prompt 示例
人工评测结果如下所示,其中 FLUX-Lightning 获得了最高分7.37分,表明 FLUX-Lightning 可以生成更符合人类审美的图像,体现了模型的优异效果。
表3 人工评测结果
05
使用教程
PaddleMIX 已将 FLUX-Lightning 模型开源集成到其扩散模型推理库(PPDiffusers)中,源码和使用说明都可以在 PaddleMIX 的 GitHub 仓库中获取,代码链接为:
感兴趣的开发者可以查阅开源代码,了解各模块的实现细节和参数配置,并对自己的扩散模型进行蒸馏加速。
▎训练
数据准备:下载 laion 训练数据和数据列表
bash
wget https://dataset.bj.bcebos.com/PaddleMIX/flux-lightning/laion-45w.tar.gz
wget https://dataset.bj.bcebos.com/PaddleMIX/flux-lightning/filelist_hwge1024_pwatermarkle0.5.txt数据解压之后,文件结构如下所示
lua
|-- your_path
|-- laion-45wlaion-45w
|-- 0000000.txt
|-- 0000001.txt
|-- 0000002.txt
....
|-- filelist_hwge1024_pwatermarkle0.5.txt模型训练命令:
css
python -u -m paddle.distributed.launch --gpus "0,1,2,3,4,5,6,7" train_flux_lightning_lora.py \
--data_path "your_path/laion-45w" \
--file_list_path "your_path/filelist_hwge1024_pwatermarkle0.5.txt" \
--pretrained_teacher_model "black-forest-labs/FLUX.1-dev" \
--output_dir outputs/lora_flux_lightning \
--tracker_project_name lora_flux_lightning \
--mixed_precision "bf16" \
--fp16_opt_level "O2" \
--resolution "1024" \
--lora_rank "32" \
--learning_rate "5e-6" \
--loss_type "huber" \
--adam_weight_decay "1e-3" \
--max_train_steps "28652" \
--dataloader_num_workers "32" \
--guidance_scale "3.5" \
--validation_steps "20000" \
--checkpointing_steps "1000" \
--checkpoints_total_limit "30" \
--train_batch_size "1" \
--gradient_accumulation_steps "1" \
--resume_from_checkpoint "latest" \
--seed "453645634" \
--num_euler_timesteps "100" \
--multiphase "4" \
--gradient_checkpointing \
--adv_weight=0.1 \
--adv_lr=1e-5 \
--pre_alloc_memory 76 \
--use_dmd_loss \
--dmd_weight 0.01 \
--apply_reflow_loss \
--reflow_loss_weight 0.01▎推理
下载模型权重
bash
wget https://dataset.bj.bcebos.com/PaddleMIX/flux-lightning/paddle_lora_weights.safetensors推理命令
css
python text_to_image_generation_flux_lightning.py --path_to_lora your_path/paddle_lora_weights.safetensors --prompt "a beautiful girl" --output_dir ./text_to_image_generation_flux_lightning.py 中的内容为
ini
# Copyright (c) 2025 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import os
os.environ["USE_PEFT_BACKEND"] = "True"
import paddle
from ppdiffusers import FluxPipeline
parser = argparse.ArgumentParser(description="Simple example of a training script.")
parser.add_argument(
"--path_to_lora",
type=str,
required=True,
help="Path to paddle_lora_weights.safetensors",
)
parser.add_argument(
"--prompt",
type=str,
required=True,
default="a beautiful girl",
)
parser.add_argument(
"--guidance_scale",
type=float,
required=False,
default=3.5,
)
parser.add_argument(
"--height",
type=int,
required=False,
default=1024,
)
parser.add_argument(
"--width",
type=int,
required=False,
default=1024,
)
parser.add_argument(
"--lora_scale",
type=float,
required=False,
default=0.25,
)
parser.add_argument(
"--step",
type=int,
required=False,
default=4,
)
parser.add_argument(
"--seed",
type=int,
required=False,
default=42,
)
parser.add_argument(
"--output_dir",
type=str,
required=False,
default="./",
)
args = parser.parse_args()
pipe = FluxPipeline.from_pretrained("black-forest-labs/FLUX.1-dev", map_location="cpu", paddle_dtype=paddle.bfloat16)
pipe.load_lora_weights(args.path_to_lora)
with paddle.no_grad():
result_image = pipe(
prompt=args.prompt,
negative_prompt="",
height=args.height,
width=args.width,
num_inference_steps=args.step,
guidance_scale=args.guidance_scale,
generator=paddle.Generator().manual_seed(args.seed),
joint_attention_kwargs={"scale": args.lora_scale},
).images[0]
result_image.save(os.path.join(args.output_dir, "test_flux_lightning.png"))使用 CINN 技术加速推理 FLUX-Lightning 方法如下:
ini
export FLAGS_use_cuda_managed_memory=true
export FLAGS_prim_enable_dynamic=true
export FLAGS_prim_all=true
export FLAGS_use_cinn=1
python text_to_image_generation_flux_lightning_cinn.py --path_to_lora your_path/paddle_lora_weights.safetensors --prompt "a beautiful girl" --output_dir ./ --inference_optimize06
总结与展望
本文介绍了 PaddleMIX 最新推出的 FLUX-Lightning 模型,通过区间一致性蒸馏(Phased Consistency Distillation),对抗学习(Adversarial Learning),分布匹配蒸馏(Distribution Matching Distillation),矫正流损失(reflow loss)等技术,在保持图像生成质量的前提下,可以做到4步快速生成,大幅提升了图像生成的性能,叠加上 CINN 推理优化,单图推理仅需1.66s(A800)。模型效果也达到了业界 SOTA 的水平,定量和定性结果显示超越了目前市面上基于 FLUX 的各种开源和闭源的蒸馏加速模型,开发者可以根据需求简单地对自己的扩散模型进行蒸馏加速。
展望未来,随着扩散模型在更大规模数据和更多应用领域的发展,此类推理高效化的需求将更加迫切。我们有理由相信,蒸馏加速方法还有很大潜力可挖------例如使用 TrigFlow 消除 CM 模型中的量化误差、更加高效的对抗损失设计等,都有望在保持图像生成质量的前提下进一步提升生成效率。PaddleMIX 也将持续完善多模态模型的工具链,在提供强大模型能力的同时兼顾实际部署效率。希望这些加速方法能够帮助开发者更快地落地扩散模型应用,激发出更丰富的创意,实现高质量生成与高效推理的双赢。
▎开源代码链接:
PaddleMIX 扩散模型加速插件相关代码已在 GitHub 开源 。欢迎大家访问仓库获取源码并提出宝贵意见,共同推进扩散模型技术的发展与应用!