TDengine 介绍
TDengine 是一款开源、高性能、云原生的时序数据库,专为物联网、车联网、工业互联网、金融、IT 运维等场景优化设计。它不仅提供了高效的数据存储和查询功能,还带有内建的缓存、流式计算、数据订阅等系统功能,能大幅减少系统设计的复杂度,降低研发和运营成本。
观测云
观测云是一款专为 IT 工程师打造的全链路可观测产品,它集成了基础设施监控、应用程序性能监控和日志管理,为整个技术栈提供实时可观察性。这款产品能够帮助工程师全面了解端到端的用户体验追踪,了解应用内函数的每一次调用,以及全面监控云时代的基础设施。此外,观测云还具备快速发现系统安全风险的能力,为数字化时代提供安全保障。
部署 DataKit
DataKit 是一个开源的、跨平台的数据收集和监控工具,由观测云开发并维护。它旨在帮助用户收集、处理和分析各种数据源,如日志、指标和事件,以便进行有效的监控和故障排查。DataKit 支持多种数据输入和输出格式,可以轻松集成到现有的监控系统中。
登录观测云控制台,在「集成」 - 「DataKit」选择对应安装方式,当前采用 Linux 主机部署 DataKit。
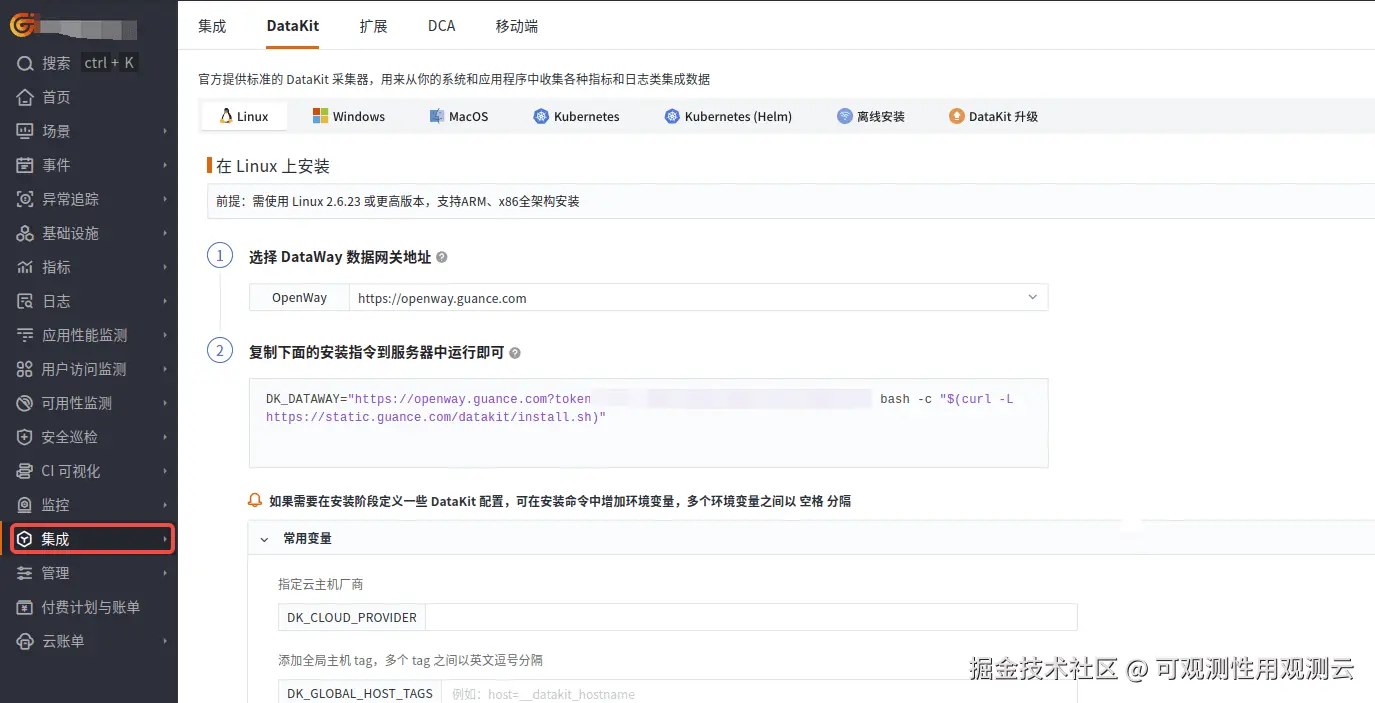
采集器配置
进入 DataKit 安装目录下的 conf.d/db 目录,复制 tdengine.conf.sample 并命名为 tdengine.conf。示例如下:
ini
[[inputs.tdengine]]
## adapter restApi Addr, example: http://taosadapter.test.com (Required)
adapter_endpoint = "http://<FQND>:6041"
user = "<userName>"
password = "<pw>"
## log_files: TdEngine log file path or dirName (optional).
## log_files = ["tdengine_log_path.log"]
## pipeline = "tdengine.p"
## Set true to enable election
election = true
## add tag (optional)
[inputs.tdengine.tags]
## Different clusters can be distinguished by tag. Such as testing,product,local ,default is 'testing'
# cluster_name = "testing"
# some_tag = "some_value"
# more_tag = "some_other_value"配置好后,重启 DataKit 即可。
关键指标
- 标签
| 标签名 | 描述 |
|---|---|
| client_ip | 表示与 TDengine 进行交互的客户端的 IP 地址。通过该标签可以追踪不同客户端对数据库的访问行为,有助于排查与特定客户端相关的问题,比如访问权限、连接异常等情况。 |
| cluster_name | 代表 TDengine 所在的集群名称。在分布式的 TDengine 环境中,通过该标签可以区分不同的集群,方便对不同集群的资源使用、性能等方面进行管理和监控。 |
| host | 表示 TDengine 服务所在的主机信息。通过该标签可以了解数据库运行的物理或虚拟主机环境,在进行资源分配、性能优化以及故障排查时,主机信息是重要的参考依据。 |
| region | 代表 TDengine 服务所在的区域。在多区域部署的情况下,该标签有助于对不同区域的数据库进行分类管理和统计分析,比如对比不同区域的资源使用情况、性能表现等。 |
| zone_id | 指 TDengine 服务所在的区域标识。在一些分布式架构中,可能会将不同的区域划分为不同的 zone,该标签可以用于区分和管理不同 zone 中的数据库实例,有助于实现数据的分区存储和负载均衡等功能。 |
- 指标列表
td_adapter
| 指标名 | 字段类型 | 描述 |
|---|---|---|
| client_ip_count | float | 表示连接到 TDengine 数据库的客户端 IP 地址的数量。该指标可用于监控数据库的客户端访问情况,通过观察其变化,能了解到有多少不同的客户端在与数据库进行交互,数量的异常增长或减少可能暗示着业务访问模式的改变或存在潜在的安全问题。 |
| cpu_percent | float | 指 TDengine 进程占用 CPU 的百分比。此指标直观地反映了 TDengine 对 CPU 资源的使用程度,过高的 CPU 百分比可能导致数据库性能下降,影响数据的读写操作效率,可据此判断是否需要对数据库进行优化或调整系统资源分配。 |
| mem_percent | float | 是 TDengine 进程使用内存占系统总内存的百分比。它能帮助我们了解 TDengine 在内存使用方面的情况,当该百分比接近或达到 100% 时,可能会引发内存不足的问题,进而影响数据库的正常运行,需要及时采取措施进行内存管理或优化。 |
| total_req_count | float | 代表 TDengine 数据库接收到的请求总数。这个指标综合反映了数据库的工作负载情况,请求总数的变化可以体现出业务对数据库的访问频繁程度,若请求总数突然大幅增加,可能需要考虑数据库的性能瓶颈和扩展性问题;若请求总数过少,则可能表示业务活动不活跃或存在异常。 |
td_node_usage
| 指标名 | 字段类型 | 描述 |
|---|---|---|
| cpu_cores | float | 表示 TDengine 运行所在服务器的 CPU 核心数量。该指标反映了服务器的 CPU 硬件资源基础,可用于评估系统的计算能力上限。 |
| cpu_engine | float | 指 TDengine 引擎占用的 CPU 资源比例。该指标用于监控 TDengine 引擎在运行过程中对 CPU 的使用情况,若该值过高,可能会影响引擎的性能和响应速度。 |
| cpu_system | float | 代表系统整体的 CPU 使用率,包括 TDengine 引擎及其他运行在该服务器上的进程。此指标能让我们了解服务器的整体 CPU 负载情况,判断是否存在资源竞争问题。 |
| disk_percent | float | 是磁盘空间的使用百分比,即已使用磁盘空间占总磁盘空间的比例。该指标可帮助我们监控磁盘的使用情况,及时发现磁盘空间不足的问题。 |
| disk_total | float | 表示服务器上用于 TDengine 存储数据的磁盘总容量大小。了解该指标有助于规划数据存储和评估磁盘扩容需求。 |
| disk_used | float | 指当前已被 TDengine 及相关进程使用的磁盘空间大小。结合 disk_total 指标,可以直观地了解磁盘的剩余可用空间。 |
| io_read_taosd | float | 衡量 TDengine 进程从磁盘读取数据的 I/O 速率。该指标反映了 TDengine 对磁盘读取操作的频繁程度和速率,过高的读取速率可能会导致磁盘 I/O 瓶颈。 |
| io_write_taosd | float | 表示 TDengine 进程向磁盘写入数据的 I/O 速率。该指标体现了 TDengine 对磁盘写入操作的频繁程度和速率,过高的写入速率同样可能引发磁盘 I/O 问题。 |
| mem_engine | float | 指 TDengine 引擎使用的内存量大小。监控该指标有助于了解 TDengine 引擎的内存占用情况,避免因内存不足导致性能下降。 |
| mem_engine_percent | float | 是 TDengine 引擎使用的内存量占系统总内存的百分比。该指标能更直观地反映 TDengine 引擎在内存使用方面的占比情况。 |
| mem_system | float | 表示系统当前可用的内存量。该指标可用于判断服务器的整体内存资源是否充足,以及是否需要进行内存优化或扩容。 |
| mem_total | float | 指服务器的总内存容量大小。了解该指标有助于评估系统的内存资源上限,为合理分配内存提供依据。 |
| net_in | float | 代表服务器的网络流入带宽,即单位时间内从外部网络流入服务器的数据量。该指标可用于监控服务器的网络接收情况,判断是否存在网络拥塞或异常流量。 |
| net_out | float | 表示服务器的网络流出带宽,即单位时间内从服务器发送到外部网络的数据量。该指标可用于监控服务器的网络发送情况,评估网络使用效率。 |
| uptime | float | 指 TDengine 服务的连续运行时间。该指标反映了 TDengine 服务的稳定性,较长的运行时间通常表示服务比较稳定。 |
| vnodes_num | float | 表示 TDengine 集群中的虚拟节点数量。虚拟节点是 TDengine 中数据存储和处理的基本单元,该指标可用于评估集群的规模和数据处理能力。 |
td_cluster
| 指标名 | 字段类型 | 描述 |
|---|---|---|
| connections_total | float | 表示当前与 TDengine 数据库建立的总连接数。该指标可用于监控数据库的并发访问情况,连接数过高可能导致性能下降,过低则可能表示业务访问不活跃。 |
| database_count | float | 指 TDengine 数据库中创建的数据库总数。该指标能反映系统的数据存储组织规模,数据库数量的变化可能影响系统的整体管理和性能。 |
| dnodes_alive | float | 代表当前处于活跃状态的数据节点数量。数据节点是 TDengine 分布式架构中负责存储和处理数据的节点,该指标可用于监控数据节点的可用性和健康状况。 |
| dnodes_total | float | 表示 TDengine 集群中数据节点的总数量。结合 dnodes_alive 指标,可以判断有多少数据节点处于异常状态。 |
| master_uptime | float | 指 TDengine 主节点的连续运行时间。主节点在集群中起着关键的管理和协调作用,较长的运行时间通常表示系统的稳定性较好。 |
| mnodes_alive | float | 表示当前处于活跃状态的管理节点数量。管理节点负责集群的元数据管理和调度,该指标可用于监控管理节点的可用性。 |
| mnodes_total | float | 是 TDengine 集群中管理节点的总数量。与 mnodes_alive 对比,可了解管理节点的健康情况。 |
| table_count | float | 指 TDengine 数据库中创建的表的总数。表是数据存储的基本单位,该指标反映了数据的结构化程度和存储规模。 |
| vgroups_alive | float | 代表当前处于活跃状态的虚拟组(VGroup)数量。VGroup 是 TDengine 中数据存储和复制的基本单位,该指标可用于监控数据存储和复制的可用性。 |
| vgroups_total | float | 表示 TDengine 集群中虚拟组的总数量。结合 vgroups_alive 指标,可以判断有多少 VGroup 处于异常状态。 |
| vnodes_alive | float | 表示当前处于活跃状态的虚拟节点(VNode)数量。VNode 是 VGroup 中的具体存储单元,该指标可用于监控 VNode 的可用性和健康状况。 |
| vnodes_total | float | 指 TDengine 集群中虚拟节点的总数量。通过与 vnodes_alive 对比,可了解 VNode 的整体健康情况。 |
场景视图
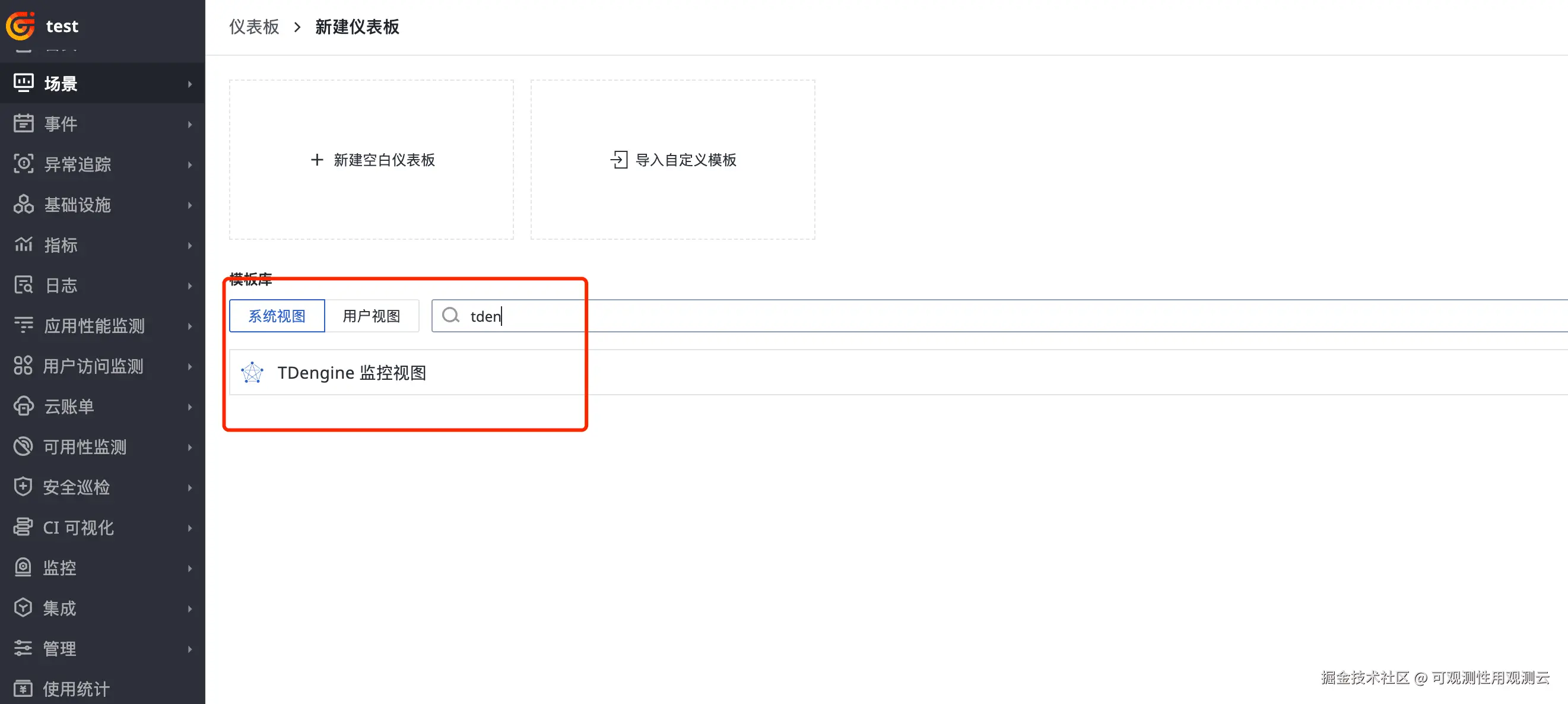
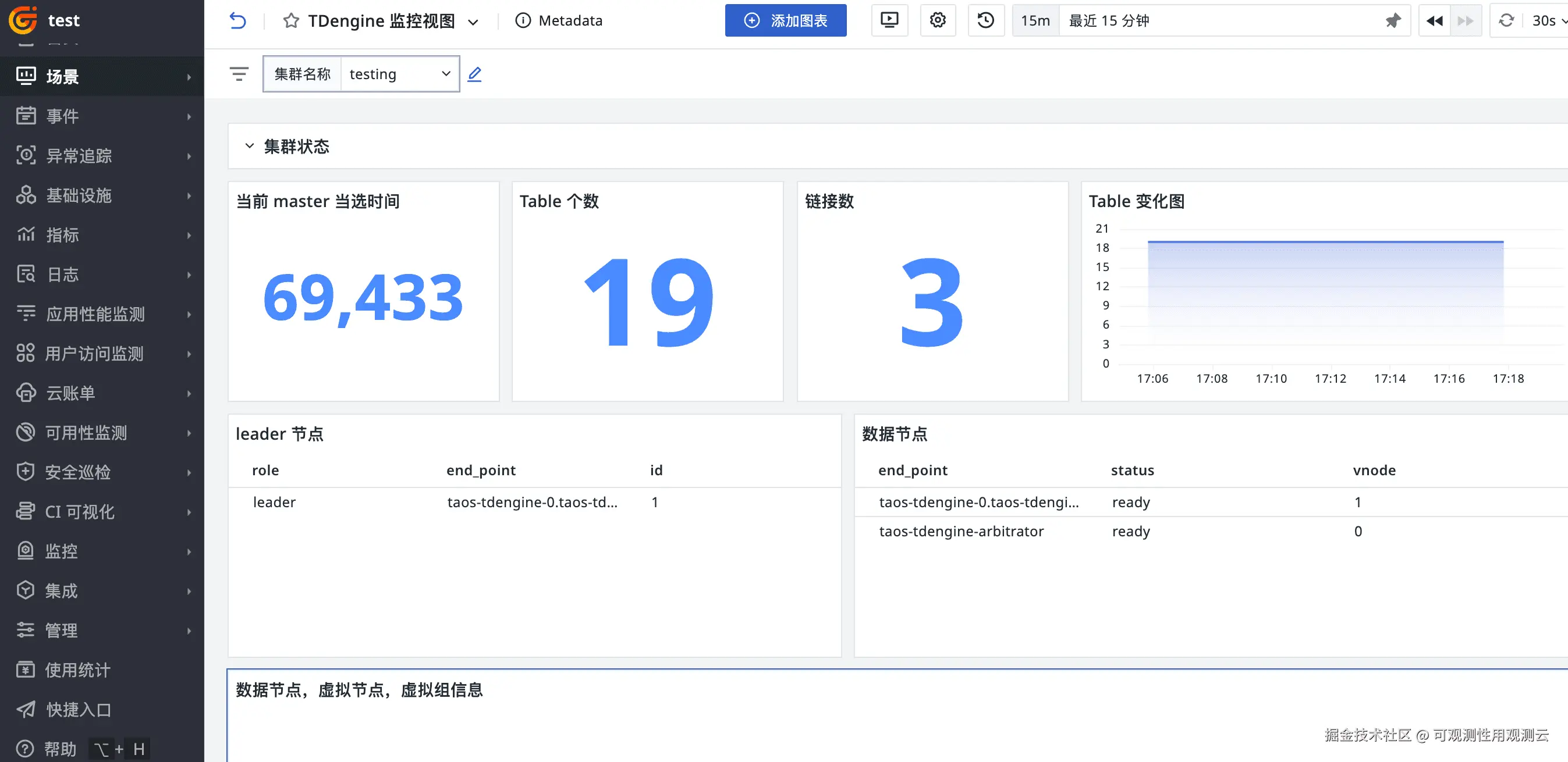
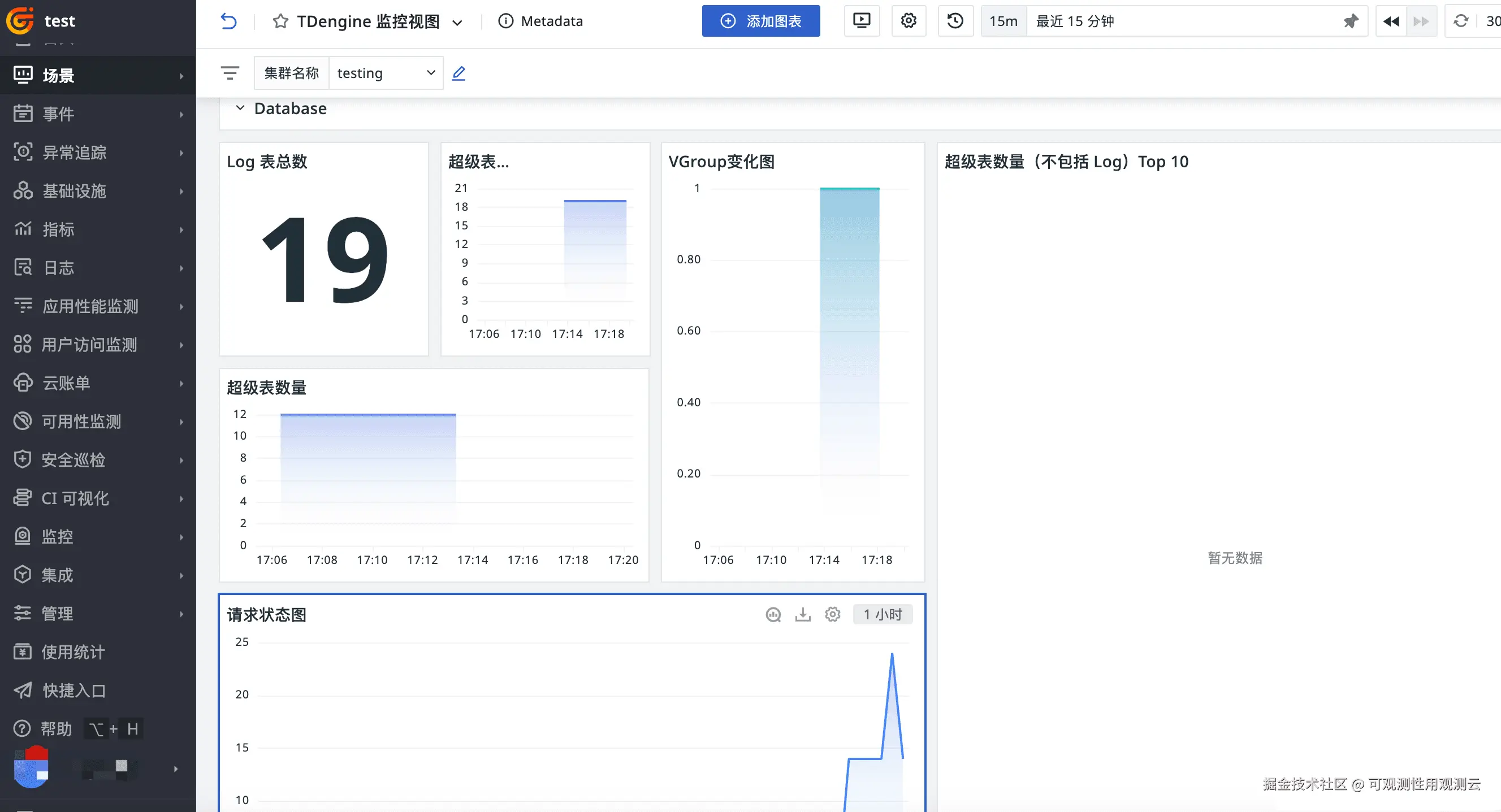
登录观测云控制台,点击「场景」 -「新建仪表板」,输入 "TDengine 监控视图", 选择 "TDengine 监控视图",点击 "确定" 即可添加视图。
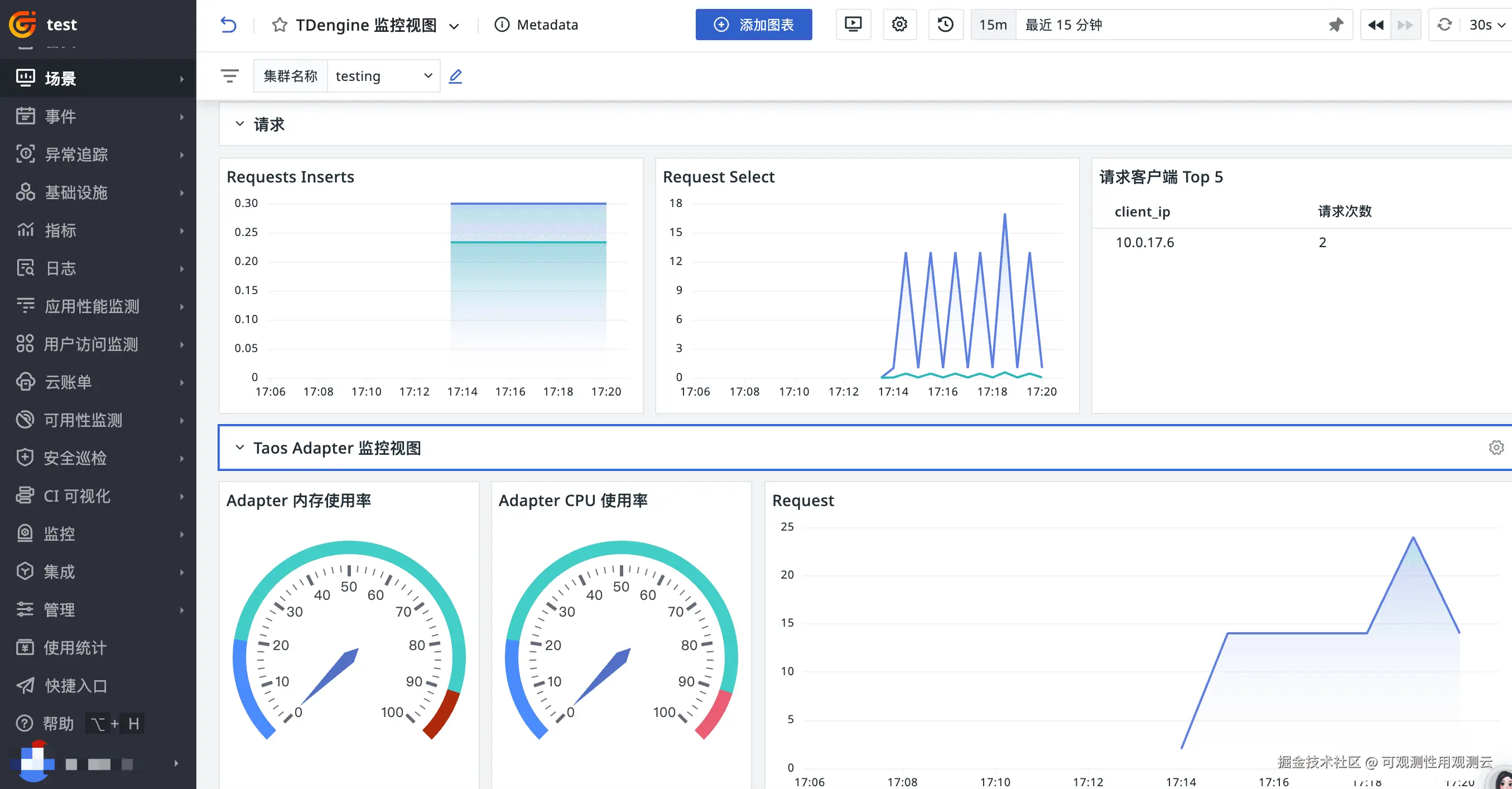
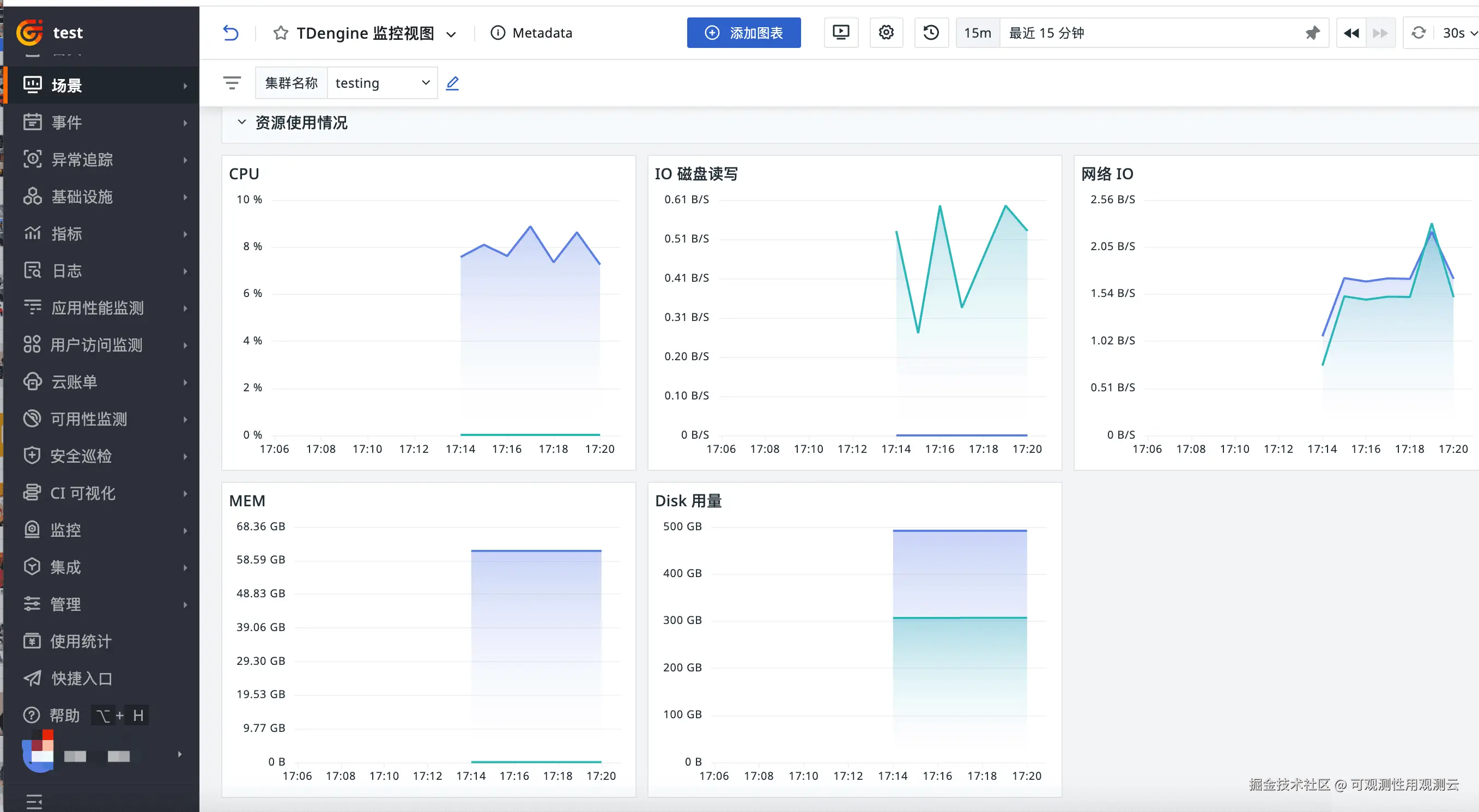
监控器(告警)
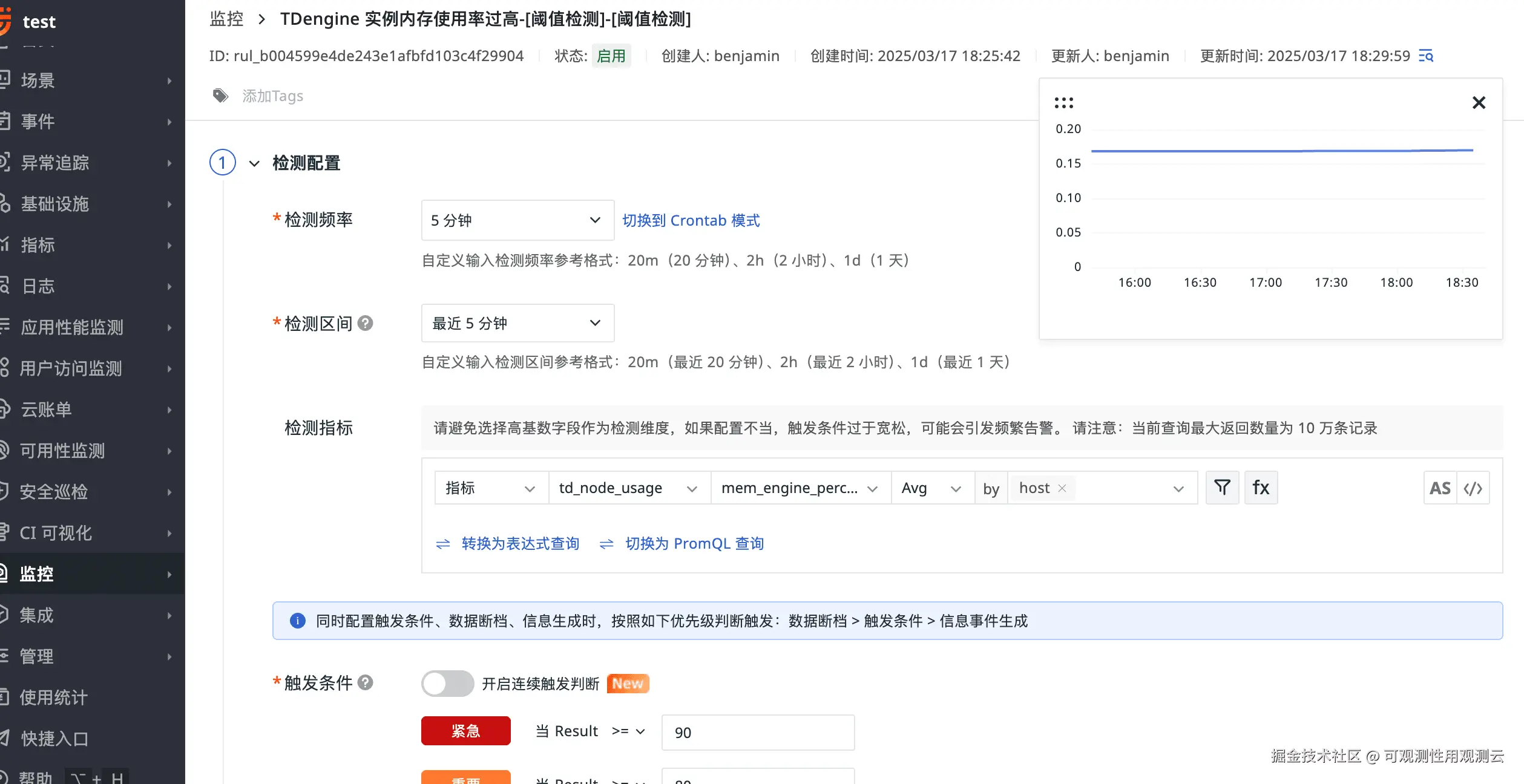
TDengine 内存过高检测
指标:mem_engine_percent
简要描述:指 TDengine 引擎使用的内存占系统总内存的百分比。通过监控这个指标,可以了解引擎在内存使用方面的占比,避免因内存过度占用而引发性能问题。当 mem_engine_percent 接近 100% 时,可能会出现内存不足,导致数据库响应缓慢甚至无法正常工作。
告警配置如下图所示:
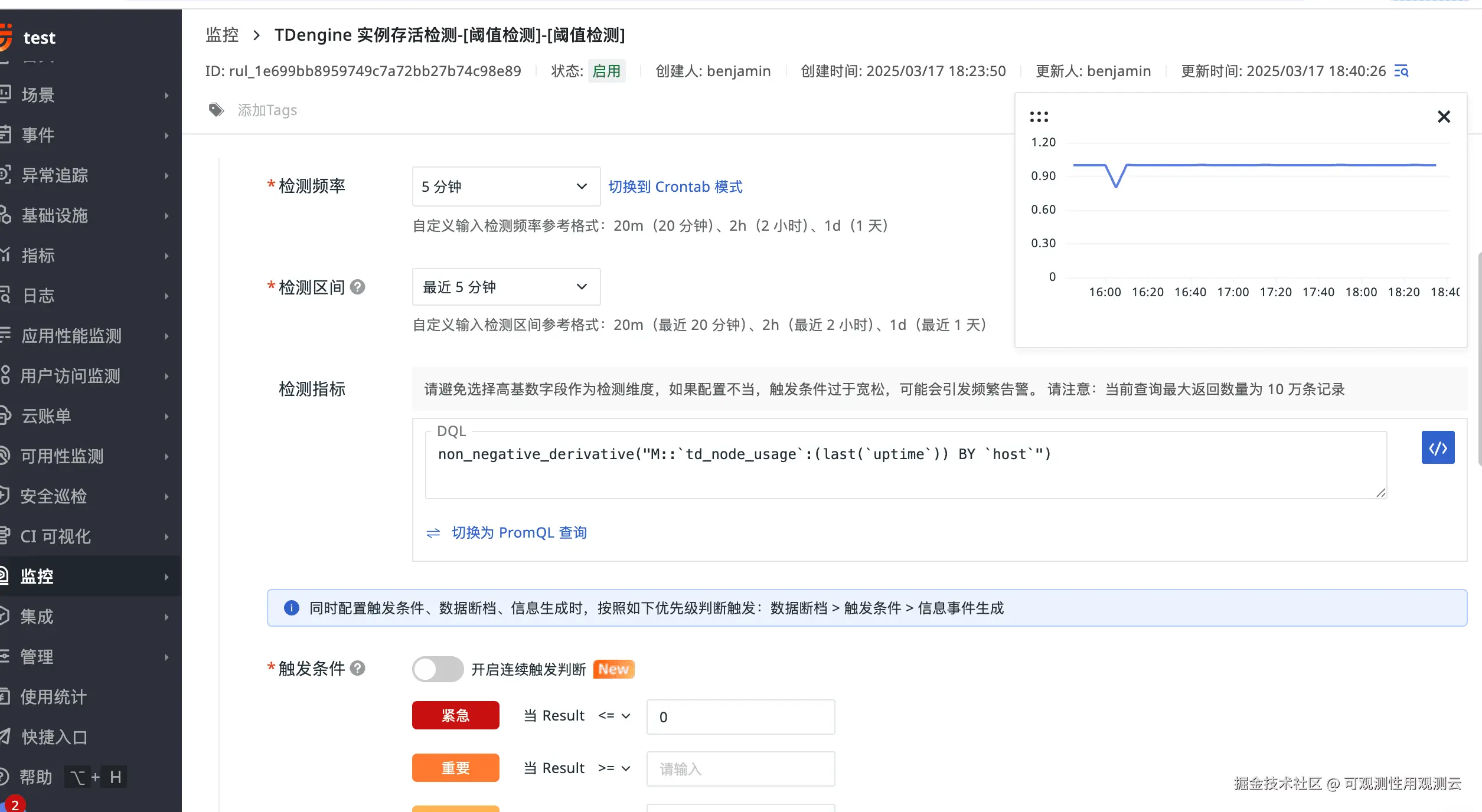
TDengine 实例存活检测
指标:cpu_engine
简要描述:uptime 记录了从 TDengine 服务节点最近一次启动开始,到当前时刻所持续运行的时长。它反映了服务节点在一段时间内保持稳定运行的状态,是衡量服务稳定性的一个重要指标。
告警配置如下图所示:
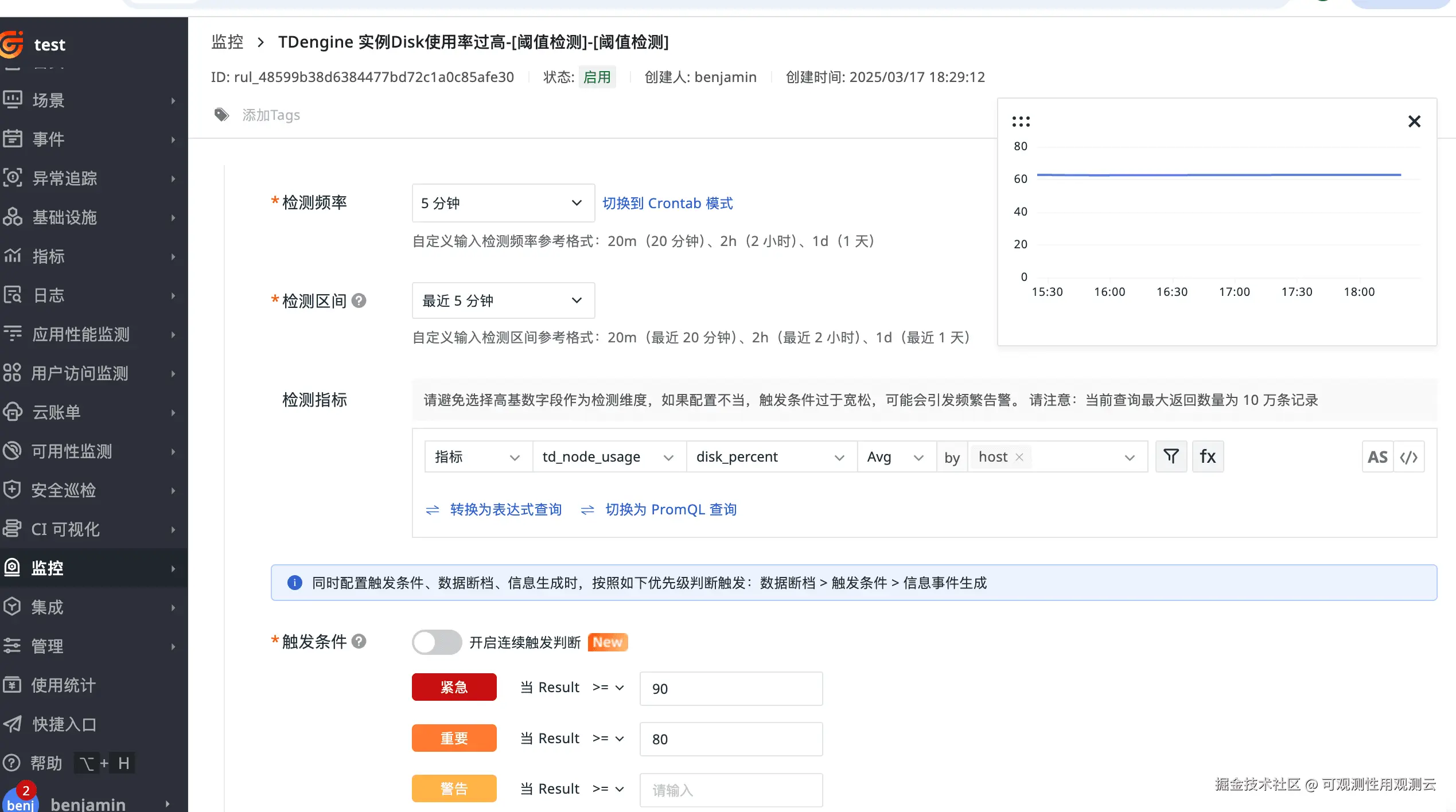
TDengine DISK 过高检测
指标:disk_percent
简要描述:代表磁盘空间的使用百分比,即已用磁盘空间占总磁盘空间的比例。磁盘空间是数据库存储数据的基础,disk_percent 过高意味着磁盘快被占满,可能影响新数据的写入和查询操作的性能。当该指标达到一定阈值(如 80% 或 90%)时,就需要考虑清理无用数据或扩展磁盘空间。
告警配置如下图所示:
总结
观测云是一款全链路可观测产品,集成了基础设施监控、应用程序性能监控以及日志管理等功能。借助开源工具 DataKit,用户可以轻松实现对 TDengine 数据的采集,仅需通过简单配置文件并重启系统,即可快速完成相关设置。
TDengine 提供了丰富的关键指标,涵盖客户端访问、资源使用、集群状态以及请求处理等多个方面。在观测云控制台中,用户可以便捷地新建"TDengine 监控视图"。同时,针对 TDengine 的重要指标,如内存使用率(mem_engine_percent)、实例存活情况(uptime、cpu_engine)、磁盘空间占用率(disk_percent)等,用户可以灵活设置告警规则。当这些指标达到特定阈值,例如内存使用率接近 100%、服务运行时间异常或磁盘空间占比过高时,系统将及时发出告警,助力运维人员保障 TDengine 的稳定高效运行。