介绍
1、Redis 分片集群主要用来解决主从 + 哨兵模式无法处理的海量数据存储和高并发写请求问题。 2、主从 + 哨兵模式解决了高可用和高并发读的问题,但所有写请求最终都落到单个主节点上,在数据量或写并发过大时会成为瓶颈。分片集群正是为了解决这两个痛点:
1)解决海量数据存储
2)支撑高并发写
==》
下面我们正式介绍分片句群的特点
-
多主架构:集群包含多个独立的主节点,每个主节点负责存储一部分数据,彼此之间不共享数据。(这样,数据存储的上限就取决于master节点的数量,从而应对海量数据的存储)。
-
主从备份:每个主节点都可以挂载多个从节点,用于实现高可用和读写分离。
-
节点间心跳 :主节点之间会通过
ping命令互相监测健康状态,实现故障自动发现。 -
透明路由:客户端可以连接集群中的任意节点,请求会被自动转发到存储对应数据的节点上。
数据分片与寻址原理
redis分片集群引入了哈希槽的概念。是一种用来实现数据分片和路由的机制。它的目的是把海量的 Key 均匀地映射到集群的多个节点上,同时让节点的扩容、缩容变得更简单。
它基本的原理是:
1)槽分配: Redis 集群固定包含 16384 个哈希槽,这个数量在集群创建后不会改变。
集群初始化时,这 16384 个槽会被分配给所有主节点。每个主节点负责一部分连续或离散的槽。
2)key映射到槽:
我们对 Key(或 Key 中 {} 包裹的有效部分)执行 CRC16 哈希计算,得到一个哈希值。将哈希值对 16384 取模,得到 0~16383 之间的一个整数,这个整数就是该 Key 对应的哈希槽编号。
3)路由到节点:
集群会维护一张 "槽→节点" 的映射表。客户端或集群节点通过这张表,就能知道哪个 Key 该去哪个节点读写。
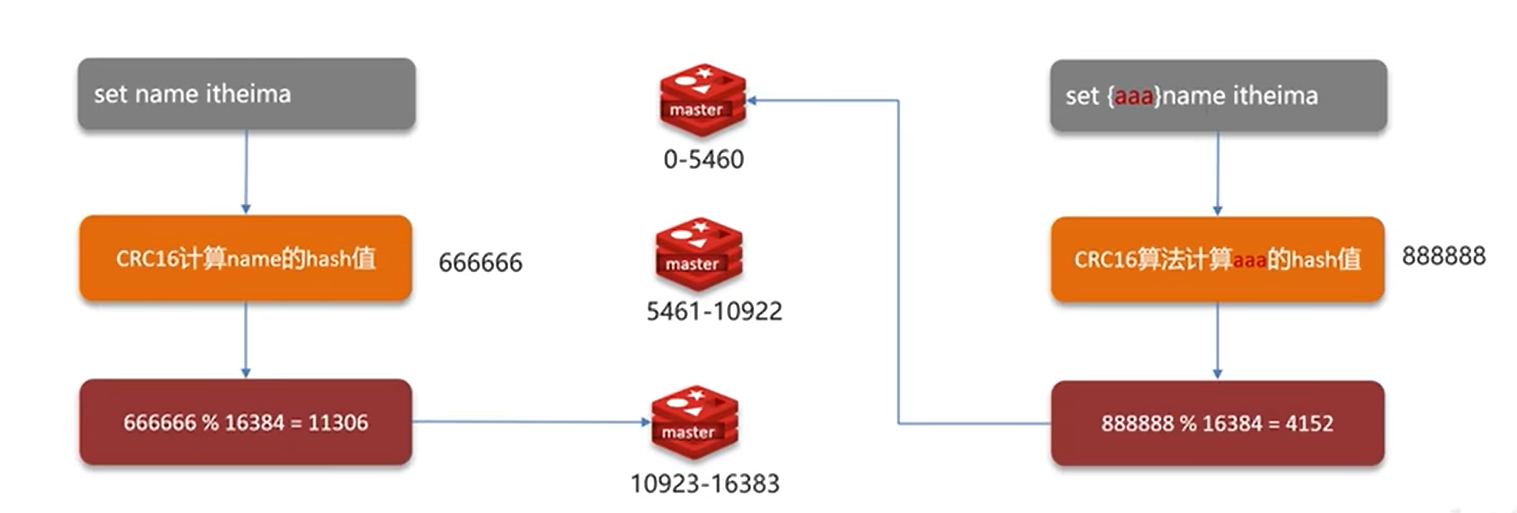
举个例子
-
对 Key
user:100计算 CRC16 哈希值为88888。 -
88888 % 16384 = 4152,所以这个 Key 被映射到槽4152。 -
如果槽
4152被分配给节点 A,那么对user:100的所有操作都会被路由到节点 A。
讨论:
1、分片集群是怎么解决海量数据存储和高并发写的问题呢?
===》
1)解决海量数据存储:将数据分散存储在多个主节点上,突破单节点的内存容量限制。 2)支撑高并发写:多个主节点可以同时处理写请求,提升集群整体的写吞吐能力。
总结:为实现redis集群中解决海量数据存储和支撑高并发写,本文提出了redis分片集群,并介绍了它的特点:(多主架构,主从备份,节点间心跳,透明路由)。还介绍了 哈希槽来实现数据分片和路由的机制(实现了将Key 均匀地映射到集群的多个节点上),介绍了它的基本的原理并举了个例子来具体说明。