光看图,你能猜出这是哪儿吗?

当同事出差回来扔到群里这么一张图,我们也是猜了半天,但毫无头绪。
直到另一位同事把图扔给智谱的新模型 ------GLM-4.5V,这个谜团才解开。
把照片截图传给 GLM-4.5V(避免模型利用照片的 EXIF 元数据),它很快就推理出了结果。
没错,图里的地方是多瑙河畔。尽管同事拍照的角度和风格和小某书上的精美照片大相径庭,但智谱的新模型还是通过深度分析给出了准确答案。
你可能要说,这个能力,OpenAI 的 o3、o4 mini 早就有了,没什么稀奇。但如果我告诉你,这个模型是开源的呢?
听说,它还参加了大名鼎鼎的「图寻」游戏全球积分赛,和里面的两万多名人类玩家对战了 7 天。
出于好奇,我们打开这个游戏玩了玩,结果一上来就懵了:这比赛只给 3 分钟时间思考,碰到带地标的还好,像这种普通的街道、山路,不积累点人文、地理知识,连大概范围都不好确定,更别提按照题目要求定位出经纬度了。

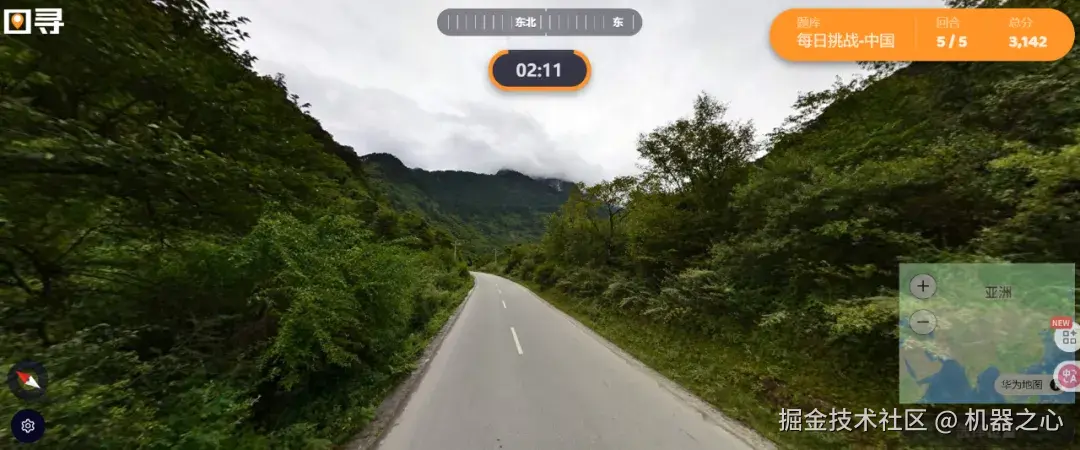
但就是在这样的赛制里比了 7 天之后,GLM-4.5V 击败了 99.99% 的人类玩家。
这个游戏玩得好意味着什么?意味着 GLM-4.5V 拥有了超强的视觉推理能力,它能够自动识别图片中的细微线索 ------ 从建筑风格、植被类型、道路标识,到天空颜色、光线角度等环境信息,并基于这些信息进行推理,在必要时,它还会主动调用工具去分析图像中的关键细节。
理论上,这种超强的视觉推理能力不仅可以用来识图定位,还可以用来完成一些更实际、更复杂的现实任务,比如处理复杂图表、多图长文本......
为了验证这个推测,在 GLM-4.5V 开源上线之后,我们第一时间进行了全面实测。测试结果超出预期,因为除了前面提到的任务,它在处理长视频方面也很出色,而且对于网页等交互界面元素的解读也很到位,这让它具备了作为 GUI Agent 应用底层模型的潜力。
整体来看,无论是国内还是国外,GLM-4.5V 都称得上是第一梯队的开源视觉推理模型。能把这样的模型开源出来,智谱的诚意确实值得点赞。
除了模型,智谱还同步开源了一个桌面助手应用。它基于 GLM-4.5V 模型的原生能力,能够通过截屏和录屏实时获得屏幕信息,处理多种视觉推理任务,比如和你一起写代码、看视频、解谜题。感兴趣的同学可以去体验一下。
-
体验地址:chat.z.ai/
-
HuggingFace 开源地址:huggingface.co/zai-org/GLM...
-
GitHub 开源地址:github.com/zai-org/GLM...
-
桌面助手下载地址:huggingface.co/spaces/zai-...
拿到图,它就是福尔摩斯
对图像的识别与推理,一直是多模态模型能力的重要试金石。GLM-4.5V 在这一领域展现出强大的综合实力。它就像一个侦探一样,能从照片的点滴细节中一点点抽丝剥茧,寻找答案。
看到这张照片,估计很多人都有些摸不着头脑,它制造了一个视觉错觉,让人第一眼误以为男人穿了高跟鞋, 对于这种强错位摄影,不知 GLM-4.5V 表现如何?
我们输入提示:这张照片,到底谁站着,谁坐着?
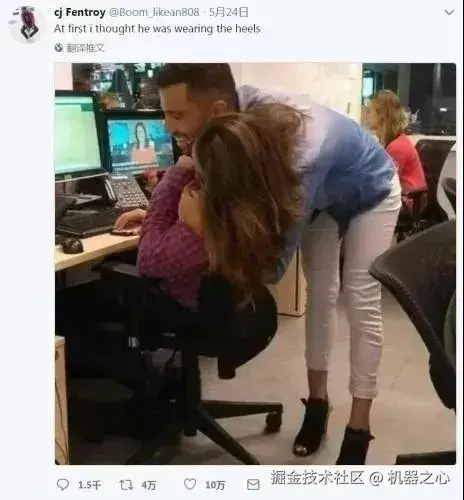
GLM-4.5V 几乎不需要长时间推理,就直接给出了准确的答案,站着的是穿蓝色上衣和白色裤子的人,坐着的是穿紫色衣服的人。
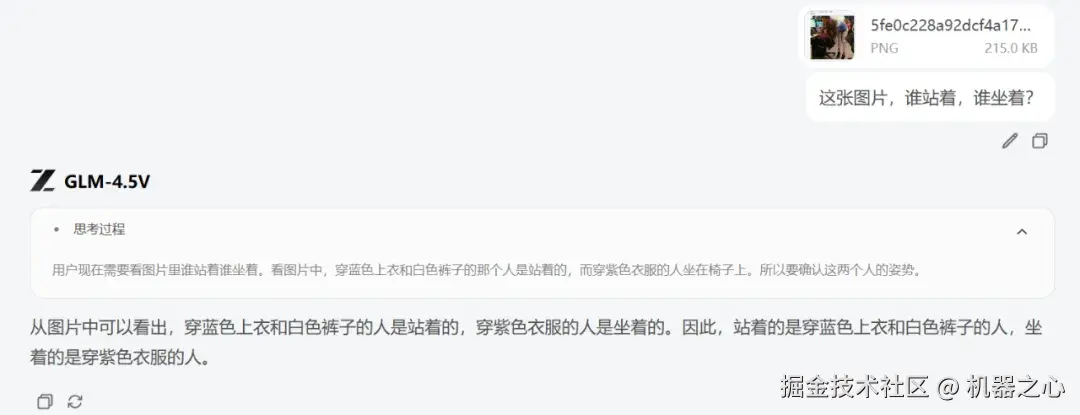
我们进一步追问坐着的是男生还是女生,对人类来说,这个问题可能比较难以回答。然而,GLM-4.5V 却能够轻松地做出判断。

这也意味着,GLM-4.5V 在面对含有视觉错觉、人物遮挡和细节干扰的图片时,依然能够快速锁定有效特征进行精确识别。这样的能力,不仅适用于趣味图像辨析,更在安防监控、人物识别等需要高准确率的场景中具备实用价值。
实际上,GLM-4.5V 的能力远不止于此,它甚至能够通过风景或街景图片,准确推测出具体的地点,甚至给出精确的经纬度。
我们经常看到有人在网络上分享旅游照片,自己心中也有去一探究竟的冲动,但往往因为不好意思直接询问而作罢。现在,借助 GLM-4.5V,只需要一张照片,它便能为你揭示照片背后的地点信息。
我们输入一张图,然后输入提示:「这张图来自哪里。请在得出结论之后用 json 格式输出:大洲 - 国家 - 省份 / 州 - 市 - 地名 - 纬度 - 经度,键名为:'continent', 'country', 'state', 'city', 'place_name', 'lat', 'lng'。」

GLM-4.5V 通过高耸的通讯塔,山体岩石裸露、植被分布等特征,推断出这是泰山,并给出相应的经纬度。

再来一个小众一点的地方。

只见 GLM-4.5V 精准定位到了 HDC 这个关键信息,然后给出这是华为小镇中的一座建筑。
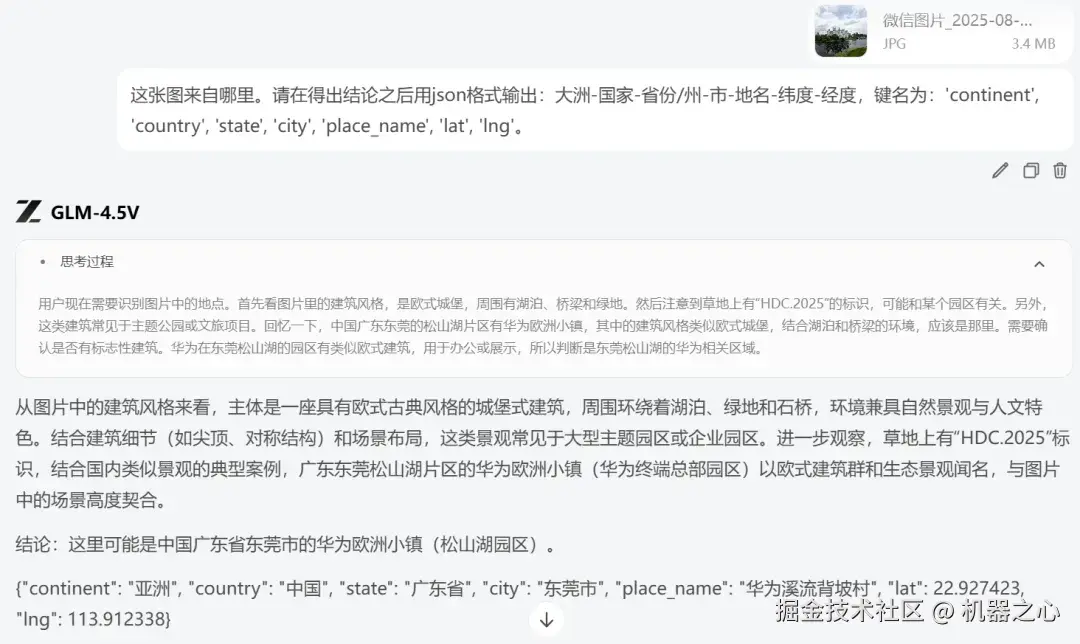
如果照片没有文字信息,GLM-4.5V 能否猜对地点?我们输入如下图片:

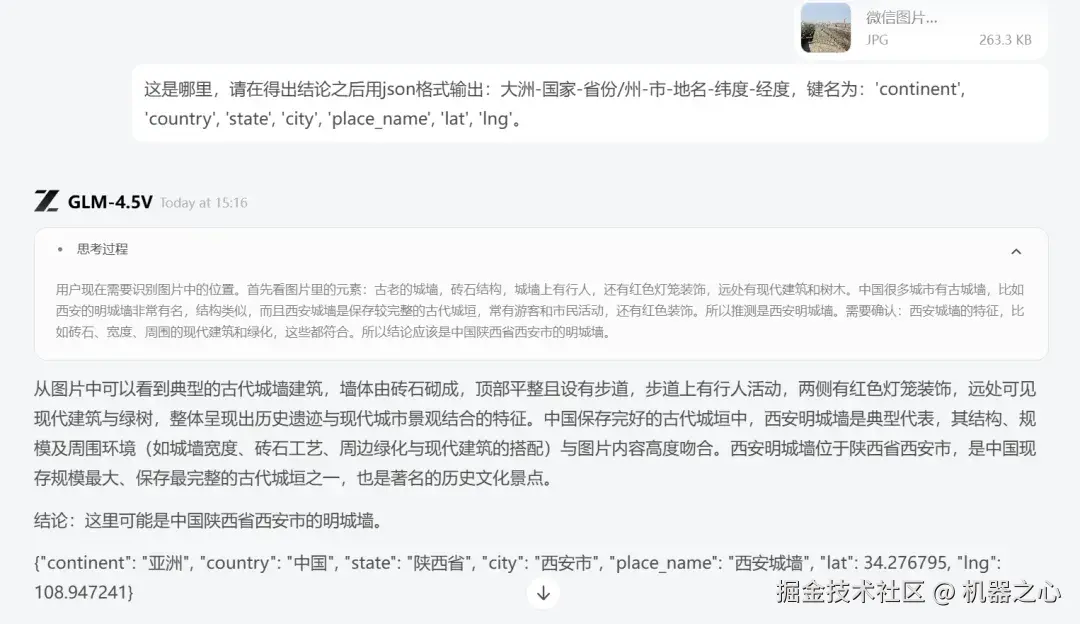
GLM-4.5V 开始分析图片中的关键元素,如城墙、砖石结构、行人、红色灯笼装饰,以及远处的现代建筑和树木。结合这些线索,GLM-4.5V 推测出这是西安的明城墙。
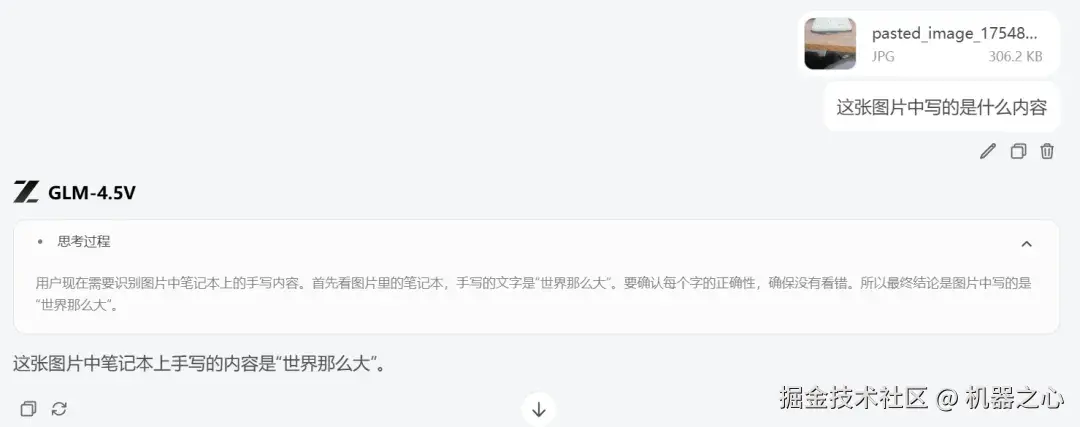
接下来,我们考察 GLM-4.5V 在字符识别与文字理解方面的能力。
我们选取了一张手写草稿图,图中写有「世界那么大」四个字,但为了增加识别难度,这张图不仅拍摄模糊、光线不佳,而且文字还呈倒置状态。这对模型在视觉处理、OCR 能力以及图像旋转鲁棒性等方面提出了极高的要求。

结果 GLM-4.5V 回答正确。
在接下来的测试中,我们让 GLM-4.5V 完成一项看似简单却颇具挑战性的任务,读取时间。此前,来自英国爱丁堡大学等机构的研究者在一项研究中指出,AI 系统读取时钟的准确率仅为 38.7%。
那 GLM-4.5V 表现如何呢?我们输入如下照片:

在这张图中,想要判断出时间还是有点难度的,首先这是夜晚拍摄,光线条件可能影响时钟指针的清晰度,其次图片中的时钟显示位于建筑的顶部,而时钟的时针和分针比较模糊,可能不易精确分辨,再就是拍摄角度比较偏,距离较远。尽管如此,GLM-4.5V 还是给出了准确的时间。
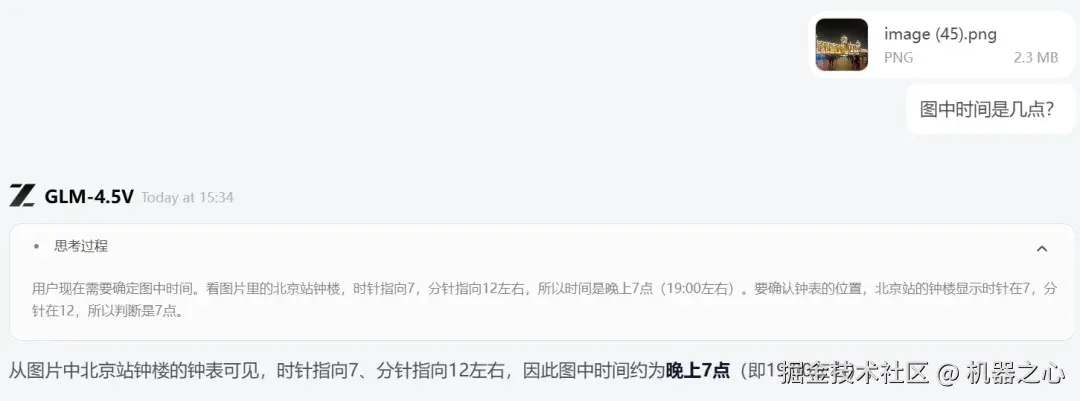
这一点尤为重要,因为在实际应用中,图像往往并非完美无缺,存在一定的噪声和不确定性。GLM-4.5V 能够在这些不完全和模糊的条件下,仍然做出准确的判断,这为其在复杂环境下的应用提供了更强的实用性。
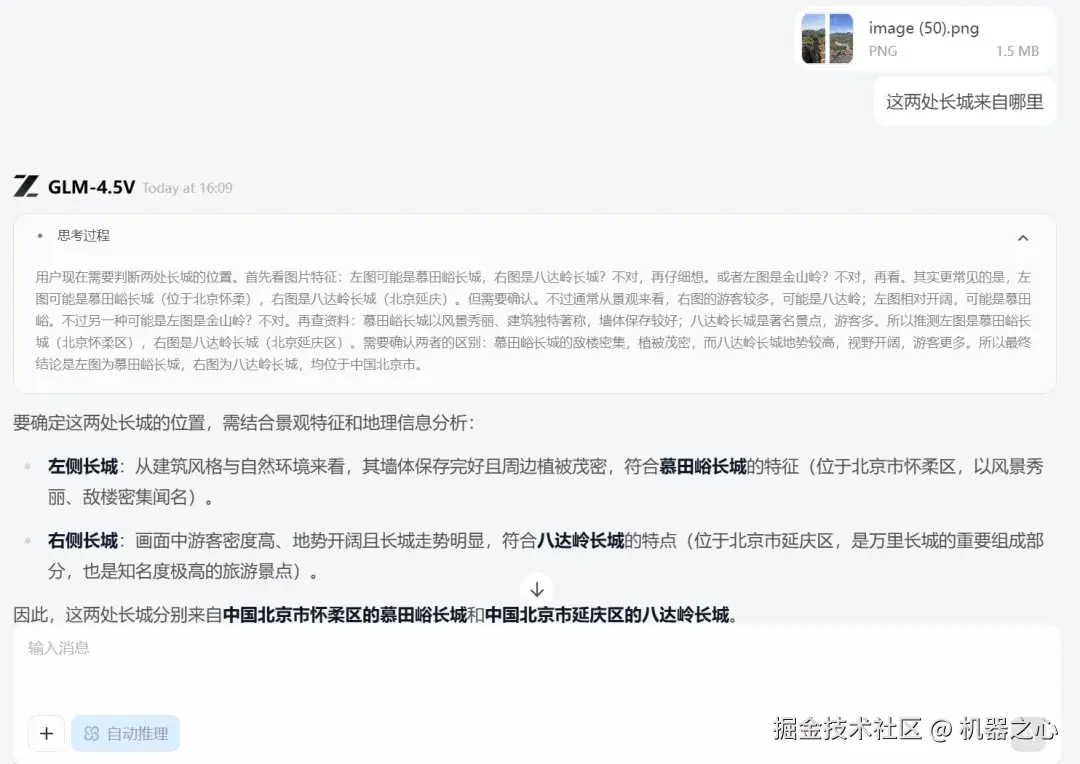
即便是相似的两张图片,GLM-4.5V 也能凭借细节进行精准区分。比如,下面这两张同为长城的照片,你能看出它们分别位于哪里吗?

GLM-4.5V 全部答对了,其根据墙体保存完整度,游客数量等因素,综合判断出左边是慕田峪长城,右边是八达岭长城。
吉娃娃和松饼也让很多大模型傻傻分不清,两者颜色、质地、构图极为相似。对于人类来说不难分辨;可对大模型而言,这是对纹理辨识、边缘结构理解和上下文缺失情况下推理能力的严酷考验。

这次 GLM-4.5V 也答对了,只见它逐行进行分析,最终给出了准确答案。

总体来看, GLM-4.5V 在图像识别方面展现出了「侦探级」的分析能力以及泛化能力,因为很多图片是我们自己拍摄的,不会存在于训练集中。这种强大的能力让 GLM-4.5V 不仅能「看」,还能基于「看」到的东西进行思考,为实际应用场景提供了可靠的技术支撑。
超长视频理解,细节捕捉狂魔
GLM-4.5V 在网页内容复现上的表现已相当惊艳,而在视频理解方面同样展现了非凡实力。
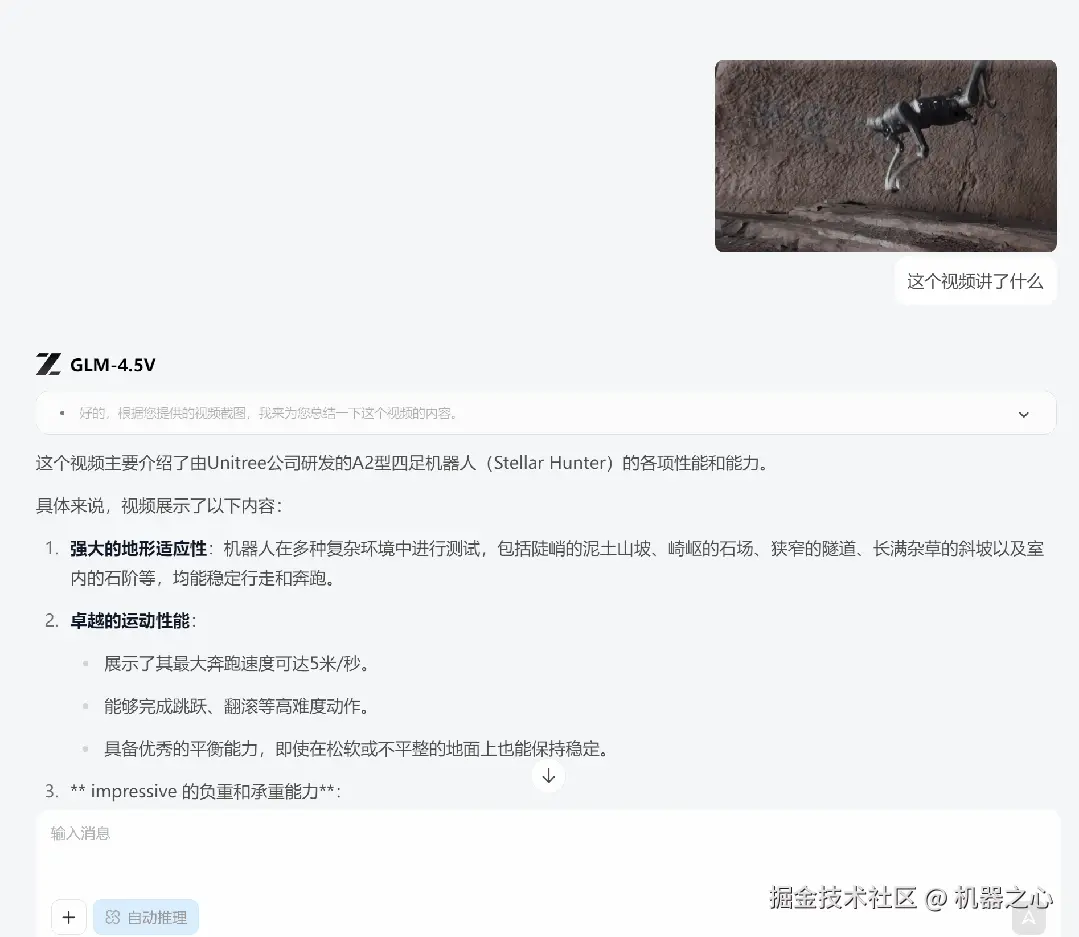
我们首先拿宇树最近发布的机器人视频(时长 2 分钟左右)测试了一下,发现模型不仅能对视频进行整体描述,还指出了其中的很多细节,以及这些细节所代表的含义(比如「累计行驶距离达 12.55 公里,用时 3 小时 8 分钟,证明了其良好的续航和自主导航能力」)。这说明,它通过深度推理理解到了视频作者加上这些注解的目的。
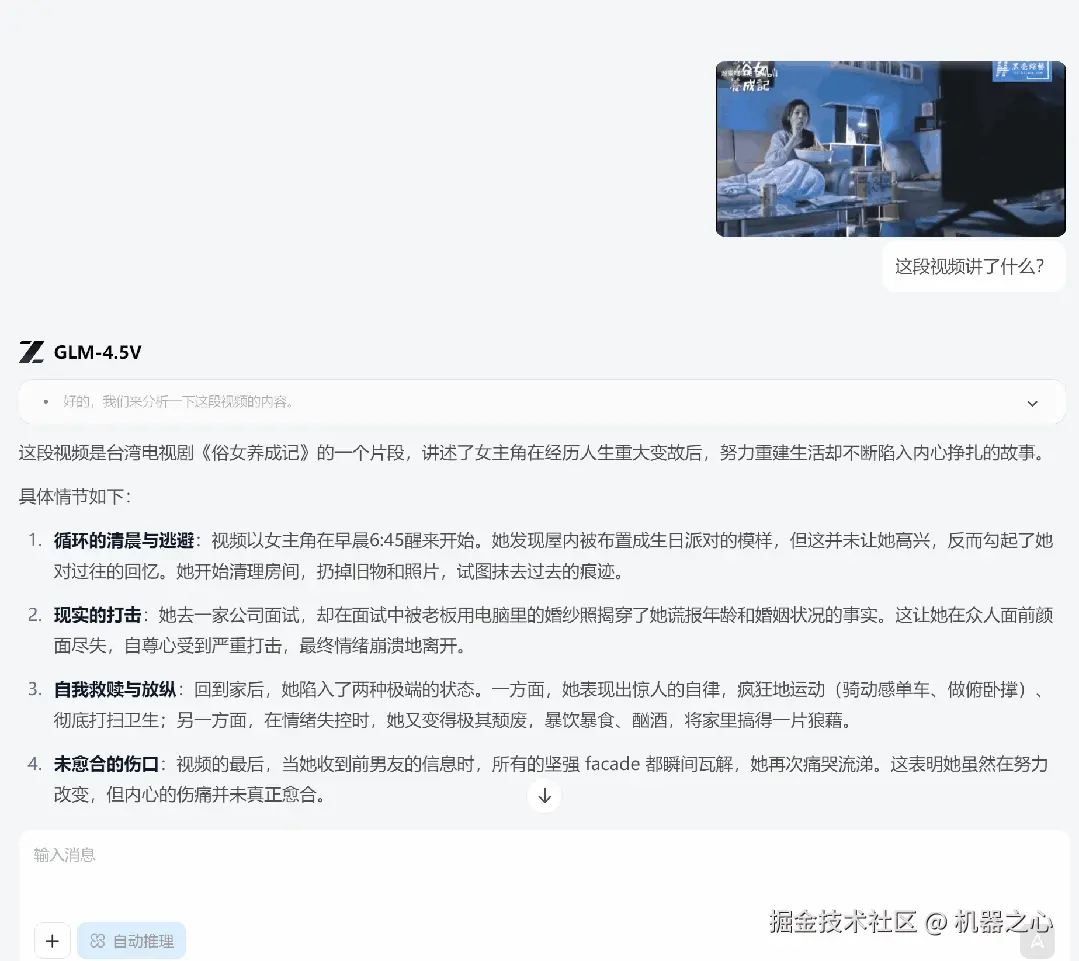
接下来,我们测试了一个更长一些的电视剧片段(大概 7 分半),并就电视剧里的一些细节进行提问,比如主人公具体做了哪些事情、做某件事情的时候穿搭是怎样的,GLM-4.5V 都能准确回答。有意思的是,它还能识别主人公的表情,明确指出了几段「哭戏」的大体位置。
当然,这样的模型用来学习是绰绰有余,光是总结视频就能达到天天用的程度。
比如,前段时间 Ilya Sutskever 现身多伦多大学进行了一场精彩的演讲,视频时长 10 分钟左右。对于英文不是很好的小伙伴来说,想听懂这场演讲着实有点难度,这时,GLM-4.5V 可谓是一个很好的小助手。
你只需上传视频,然后提问就可以了。
我们首先提问这个视频包含的一些关键信息,只见 GLM-4.5V 思考了一下,然后给出了准确的答案,人物、地点,发生的事件都包括了。
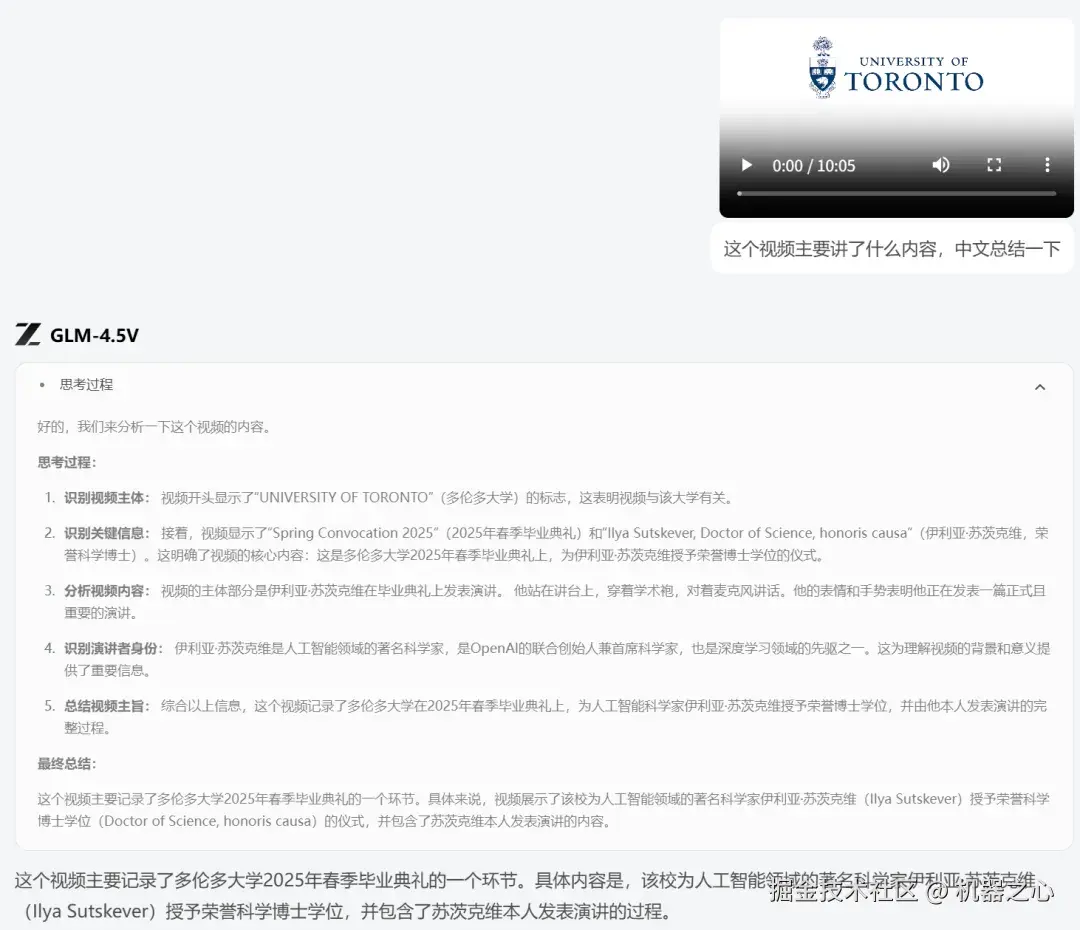
接着,我们让 GLM-4.5V 对 Ilya 的演讲进行总结,GLM-4.5V 以条理化的方式罗列出来,对照原视频后,我们发现它的回答与实际内容基本一致,整体准确度令人满意。

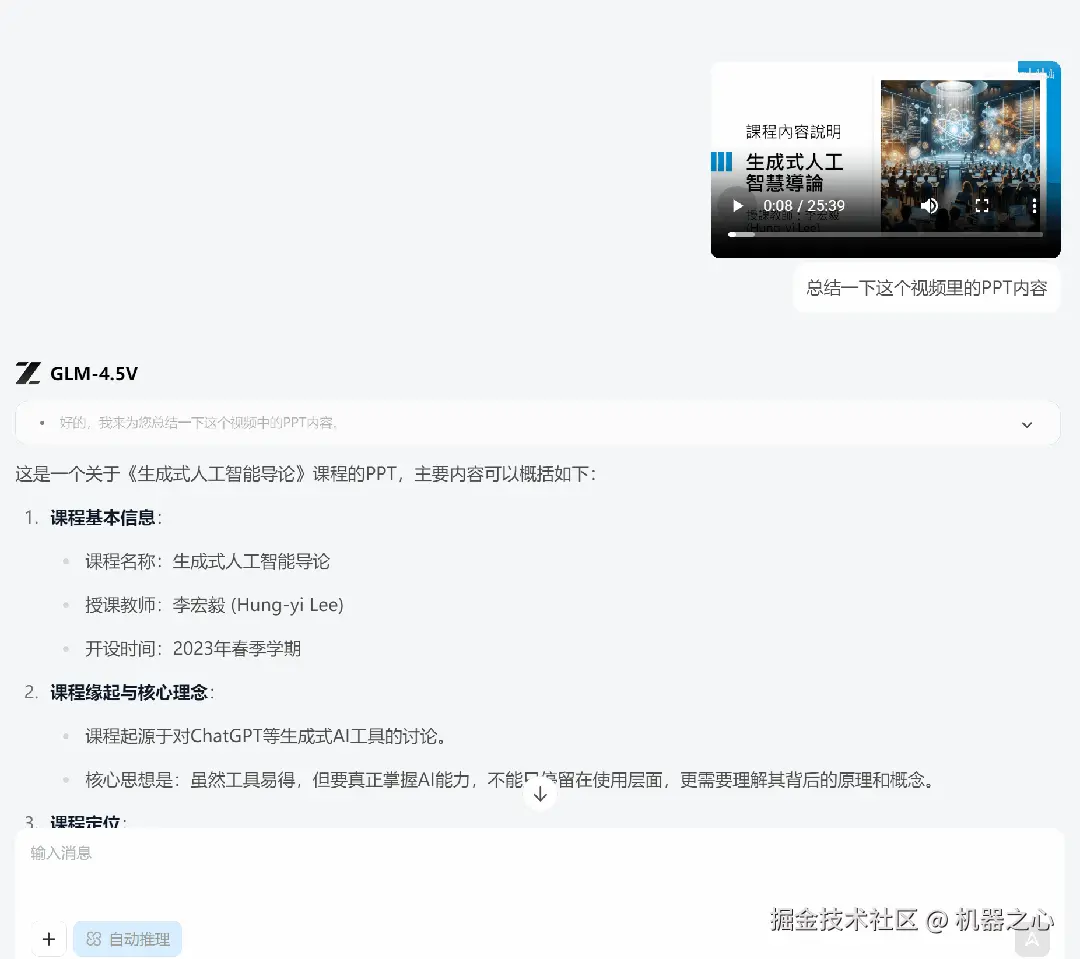
在体验过程中,我们发现它还可以复制画面中的 PPT,这是之前只能处理语音、文字信息的模型所做不到的,也让 GLM-4.5V 在学习这个赛道上更具实用价值。
以上视频都比较短,那如果是长视频呢?
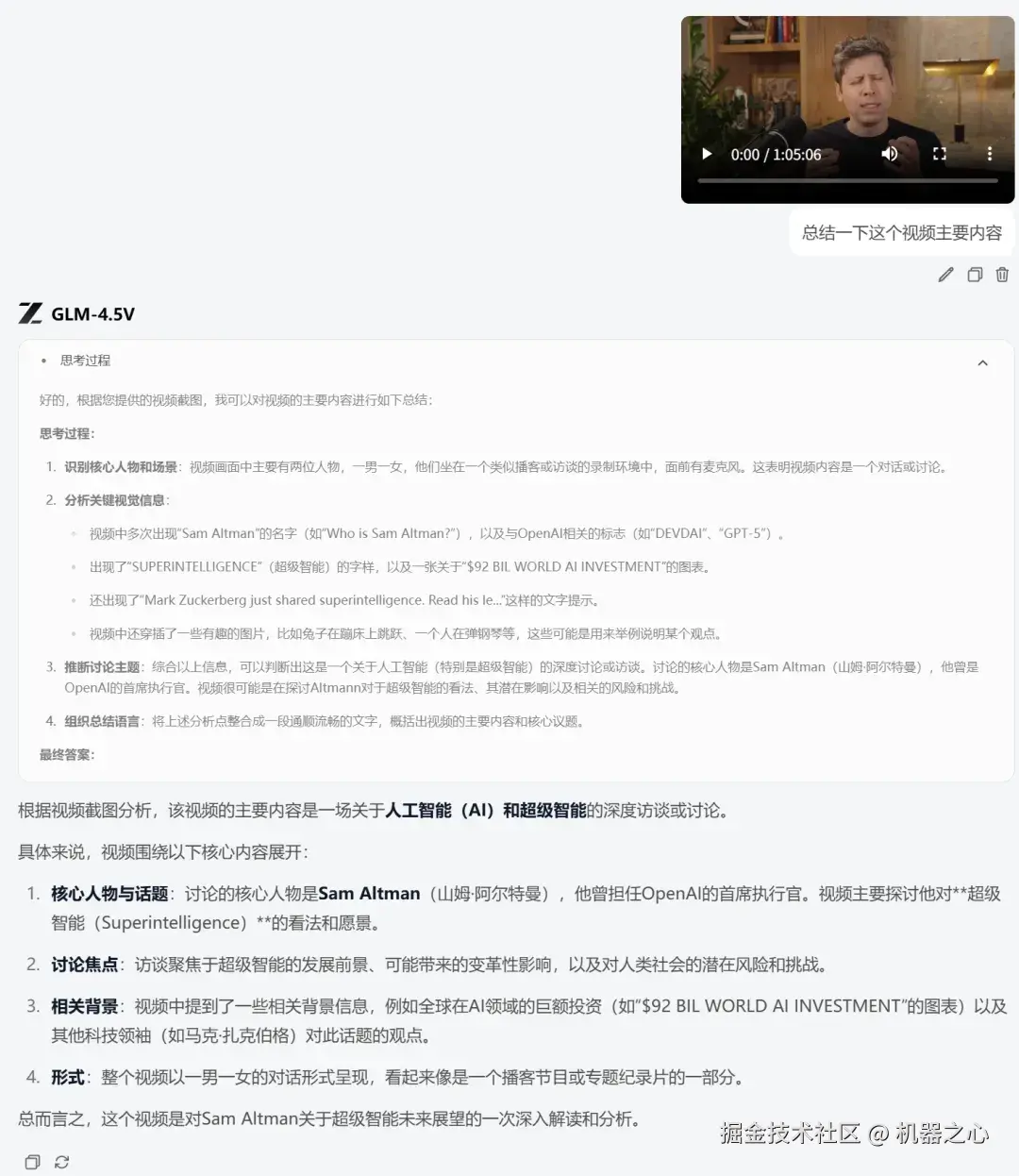
我们输入了一个时长为一小时零 5 分钟的视频来测试 GLM-4.5V 对视频的理解能力,输入的视频为奥特曼采访。
对于这个长视频,GLM-4.5V 思考了一会,给出了视频主要内容。
接着我们追问了一个问题,第 38 分之后,奥特曼是什么动作?
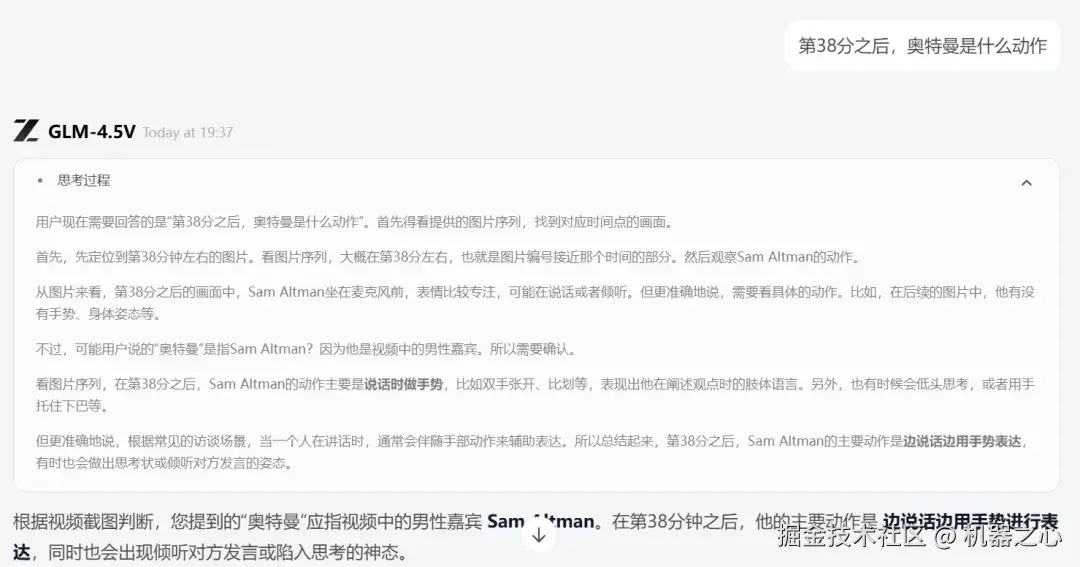
令我们惊讶的是,对于这样的问题,GLM-4.5V 也能答对:

奥特曼一边回答问题,一边用手势表达。
从短视频到长达 1 小时的内容,GLM-4.5V 都展现出了稳定的理解能力,特别是能精确定位特定时间点的动作细节,这在同类模型中并不多见。对于普通用户来说,这样的能力已经足够实用。
复刻前端就是如此简单
GLM-4.5V 视觉推理能力,在前端复刻场景中体现得尤为明显。
只需一张截图,或是一段视频,GLM-4.5V 就能像一位资深前端工程师一样,精准解析视觉内容,并生成高质量、结构化、可交互的网页代码。
我们首先让 GLM-4.5V 复刻一下 OpenAI 官网,要求是和这个页面布局相似。
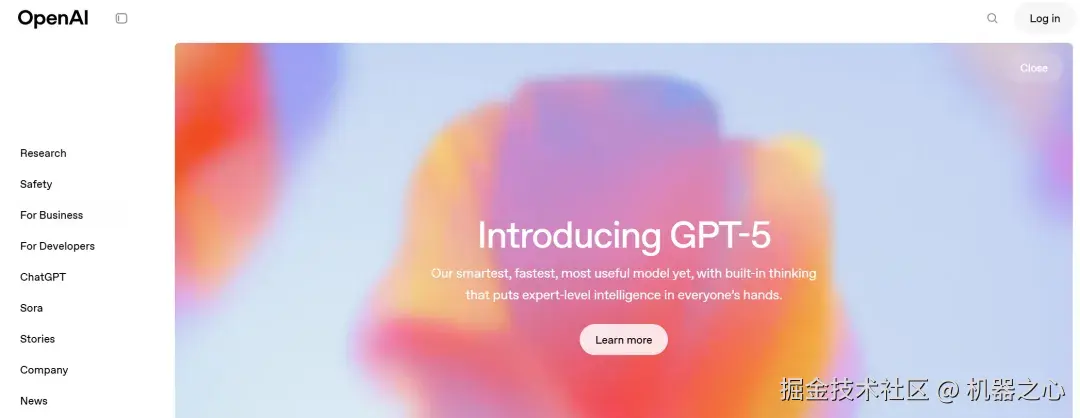
OpenAI 网站
只见 GLM-4.5V 思考了数秒,就给出答案了,我们先看结果。可以看到,除了中间的背景图(不额外提供很难复刻),GLM-4.5V 把该网站的模块布局基本都复制了出来,而且排版高度相似。即使是没给背景图,GLM-4.5V 也选择了一个色调非常相似的图来填充,这让该网站看起来非常美观。
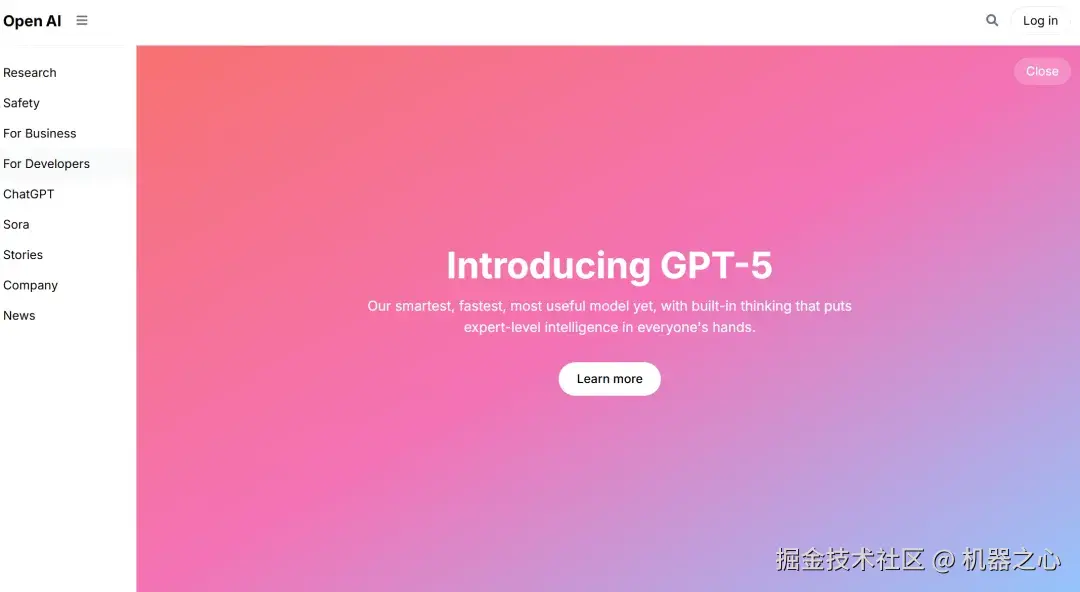
GLM-4.5V 生成的结果
GLM-4.5V 是如何做到的呢?其思考过程如下,GLM-4.5V 首先分析了图片中包含的要素,如左边栏的菜单按钮、网页主界面及包含的信息,以及登录按钮等,在分析完之后,开始思考如何编写代码,需要用到哪些库和组件,甚至还考虑到了图片中的字体和颜色等很细微的地方。
思考之后,GLM-4.5V 开始飞速写代码,只用了几秒的时间就把代码写好了,最后给出了一个和 OpenAI 官网相似的网页界面。
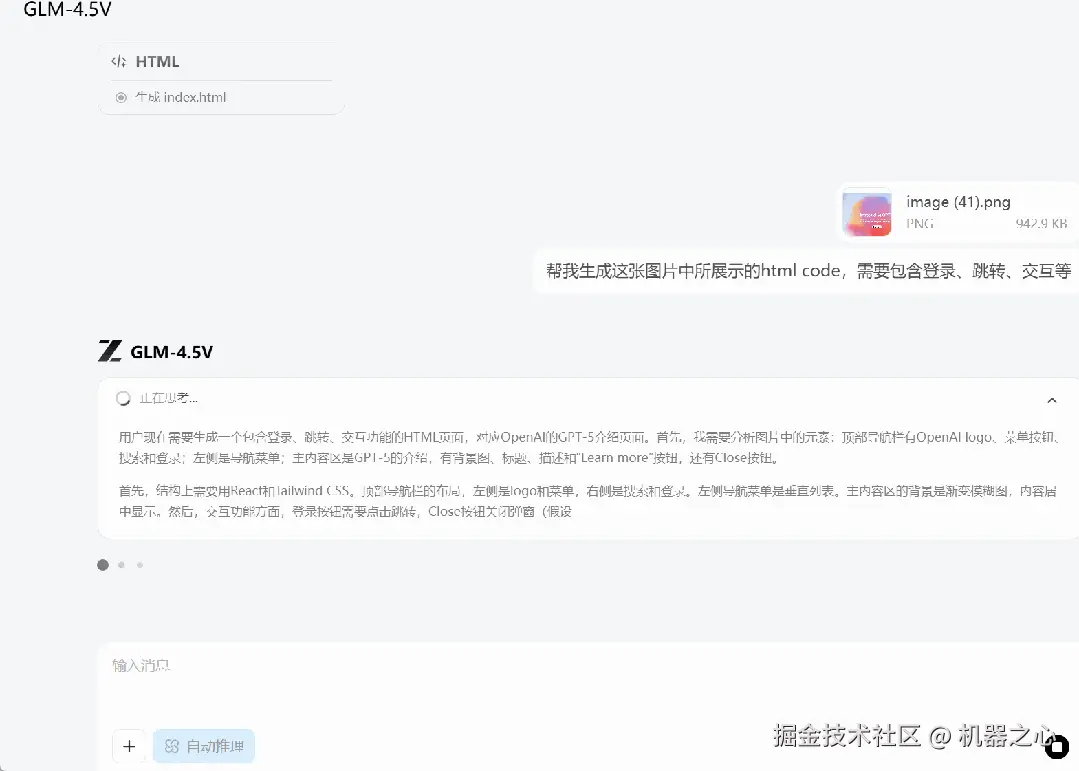
GLM-4.5V 思考过程
你还可以点击分享,让更多人看到:
在测试完图片后,我们继续给 GLM-4.5V 上难度,让这个模型根据视频内容进行前端复刻。
我们选择了谷歌网站,然后录了一段视频,在这个视频中,我们点开了一个经常浏览的网站。看看 GLM-4.5V 能不能根据我们的操作,复现一下视频中的内容。
我们输入提示词:帮我生成这个 video 中所展示的 html code ,需要包含视频中的点击、跳转、交互等。
输入视频
在接到指令后,GLM-4.5V 开始思考,由于这次输入的是视频内容,GLM-4.5V 思考的过程比输入图片思考的时间要长。
GLM-4.5V 首先确认这是 Google 首页,然后注意到我们有「点击 Google PhD」这个操作,确认这是跳转到 Google Research 的 PhD Fellowship 页面。然后 GLM-4.5V 又分析了打开的页面左侧有年份列表(2024 到 2014)...... 在经过有条不紊的抽丝剥茧后,GLM-4.5V 一会儿功夫就给出了结果。
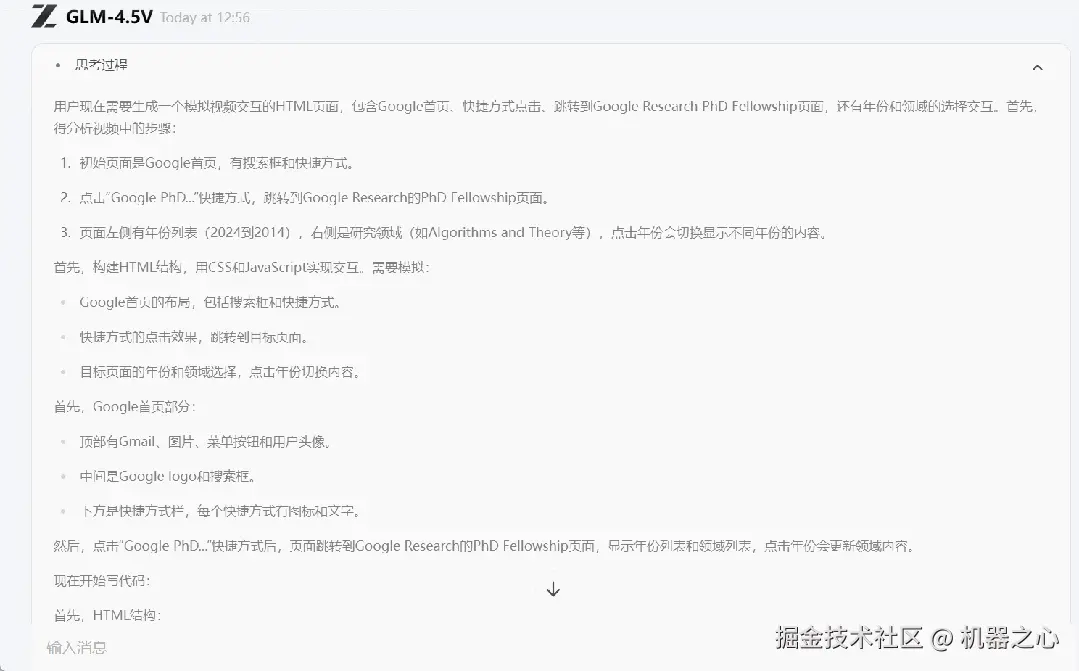
GLM-4.5V 思考过程
我们对比了一下原始网站和 GLM-4.5V 生成的结果,可以看出,网页中的主要元素都包含在内:布局结构几乎一致。排版样式基本还原,标题字号、段落间距与原版接近;配色方案与原始网站没多大区别。
不知大家有没有注意到,生成的网站有了可交互功能,当我们点击 PhD Fellowship 这个选项时,其完美的复现了我们在原视频的操作过程,打开 PhD Fellowship 网站,里面的内容布局和原始布局几乎一模一样。

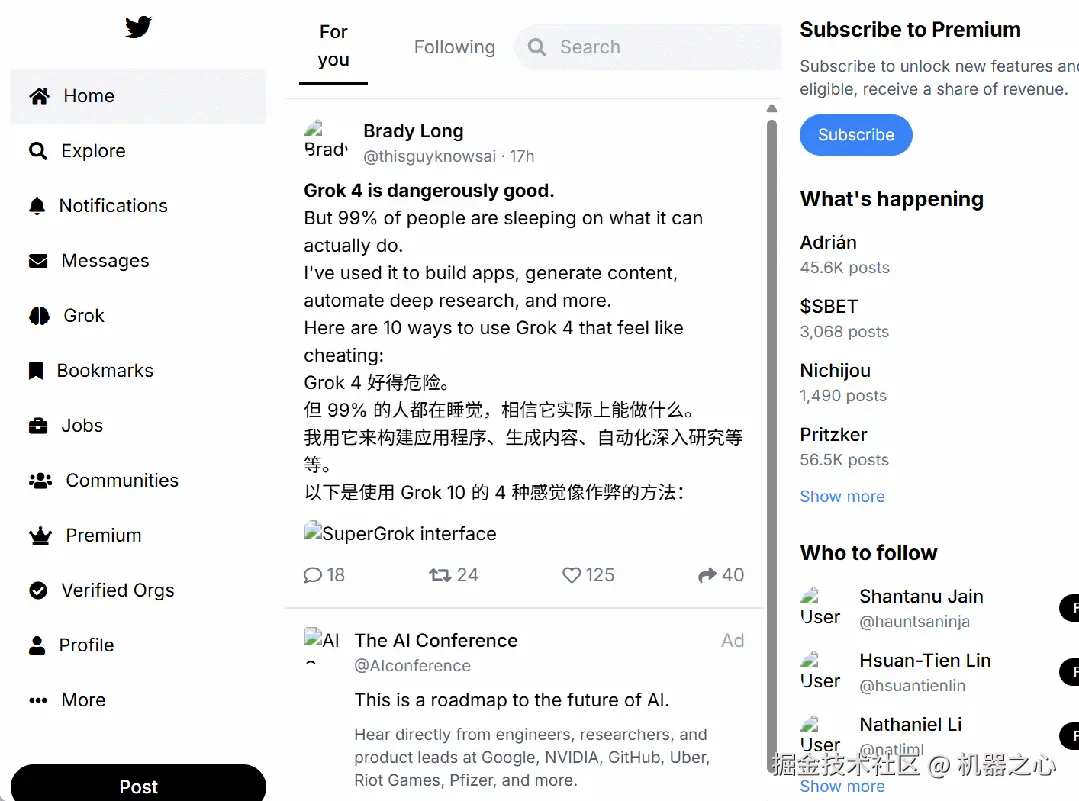
接着,我们又进行了另一项测试,这次选择了界面更为复杂的 X,提示词为:帮我生成这个 video 中所展示的 html code,要求是可交互的。
在这个视频中,我们有两次点击动作,一次是点击 Grok、另一次是点击 jobs,可能由于界面布局太复杂,GLM-4.5V 整体结果还算可以,两次点击(Grok、Jobs)都能跳转,说明模型基本复刻了我们的操作, 理解了导航→页面内容的交互因果链,但是在相应的页面下,内容和原始页面有所差距。
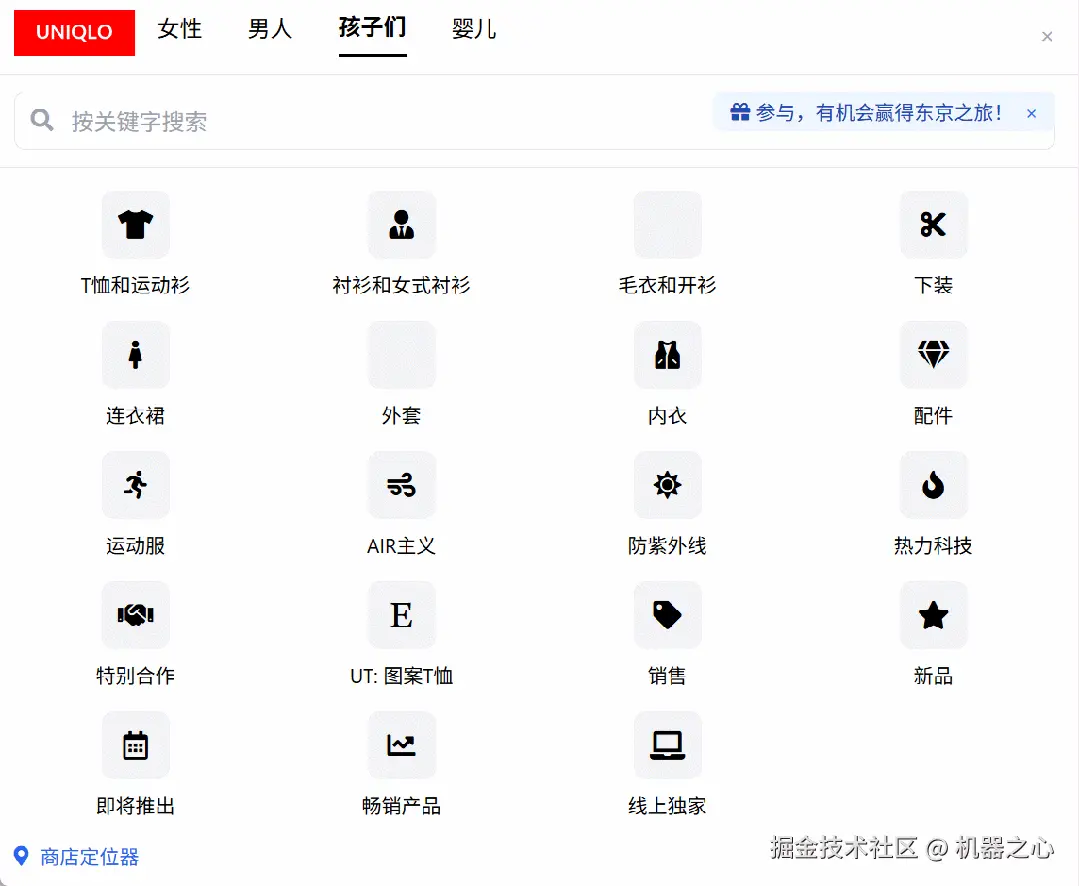
最后,我们还测试了优衣库这个网站:
最后结果如下,两者对比,我们发现基本信息都有,导航栏中的「女性、男人、孩子们」等都包含,并且不同的人群分类下的衣服分类也各不相同。如果在此基础上进行优化,一个好用的网站就建好了。
不管怎么说,GLM-4.5V 根据一张图、一个视频,就能复刻前端的这种能力还是很强的。另外,值得一提的是,这种从视频流中理解并复刻网页的能力完全是 GLM-4.5V 通过泛化能力实现的,而非特定训练的结果,展现了模型卓越的跨模态理解和推理能力。
图表克星
GLM-4.5V 让本地文档处理不再头疼
让 AI 读文件已经逐渐成为大家的习惯。就像 Karpathy 所说,未来 99.9% 的内容都会交给 AI 去读。但很多文件有保密需求,不可以扔给云端大模型,这就凸显了开源模型的价值。但带有大量图表的文件,开源模型处理起来一直有难度。
为了测试 GLM-4.5V 能否解决这些痛点,我们给它提供了一些论文图去解读。首先,对于图中的明确信息(文字等),GLM-4.5V 能够做到非常充分地提取,并放在一起综合分析,甚至也能根据箭头等符号解读其中的逻辑关系。

在我们提供的「GLM-4.5」技术报告中(最近刚刚发布),它也能读懂其中的折线图,看出折线的走势。这说明它不仅能够准确识别和提取图表中的显性信息,更重要的是能够理解图表背后的数据逻辑和趋势变化。
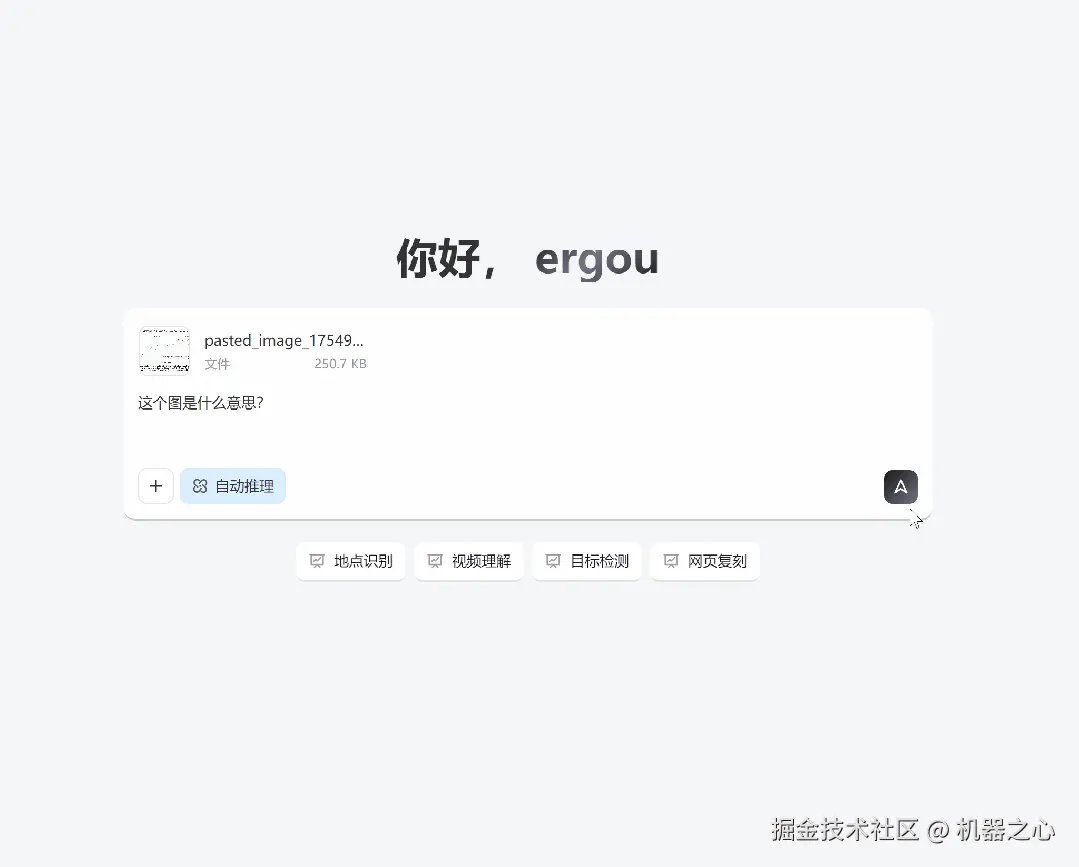
对于一些没有明确数字的柱状图,GLM-4.5V 也能读出大体的数据,这是它根据刻度估算的结果。
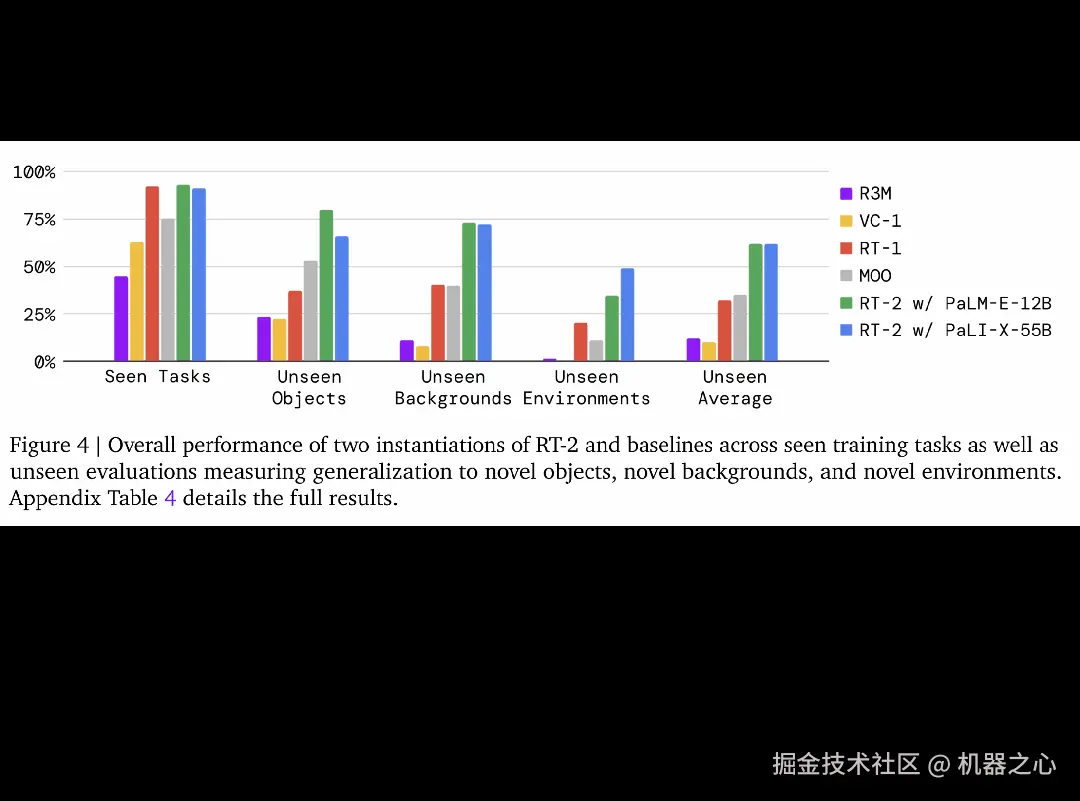
这样的读图能力表明,GLM-4.5V 已经具备了处理复杂多模态文档的实用性。这对于那些不便使用云端服务的用户来说,确实是个不错的本地化选择。
视觉 grounding:会思考的「列文虎克」
在现实生活中,视觉模型的 grounding 能力极其重要。这种能力越强,模型就越能准确理解图像内容,不仅能识别「这是什么」,还能精确定位「在哪里」。它能帮助我们自动检测异常情况,或快速找到指定目标,大大提升了视觉推理的实用价值。
现在正值暑假,每次去景区都能听见寻人广播,找不到孩子的父母心急如焚。这正是一个 AI 模型可以发挥作用的场景。
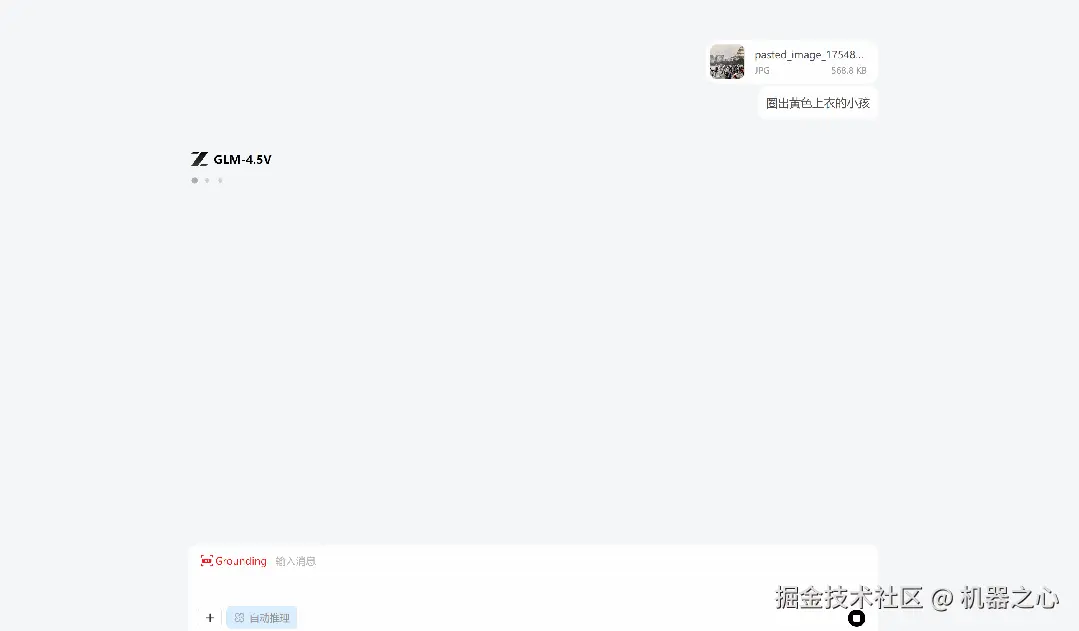
我们在小某书上找到了一张景区照片,尝试让模型寻找里面有指定特征的孩子(比如穿黄色上衣),虽然这个孩子在画面中并不显眼,但 GLM-4.5V 还是准确圈了出来。
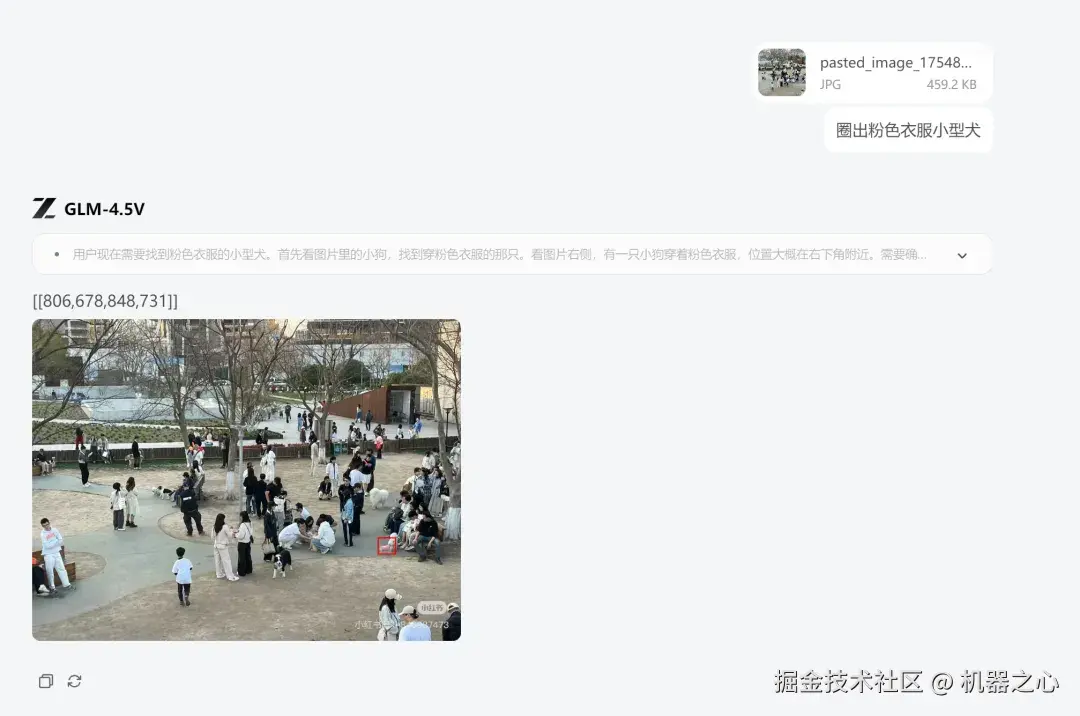
除了人,GLM-4.5V 还可以识别指定特征的宠物,这或许可以给满大街贴寻宠广告的养宠人提供一些帮助。
当然,并不是每个 grounding 任务都如此「直接」,有些还是需要深入思考的。比如在下面这个例子中,模型首先需要识别出图中的每种坚果,然后结合相关的营养知识来判断具体哪种坚果 Omega-3 含量最高,最后把对应的坚果圈出来。可以看到,不管是哪一步,GLM-4.5V 都完成得很出色。这是之前的目标检测模型所做不到的,也是「视觉推理」能力在 grounding 场景中的核心价值所在。
读屏小能手,GUI Agent 优秀基模 + 1
优秀的 grounding 能力除了前述应用场景外,在 Agent 任务中同样不可或缺。许多 Agent 任务要求模型准确理解屏幕界面的文字内容和各类视觉元素,以此为基础制定后续操作策略。
为验证 GLM-4.5V 在此方面的表现,我们设计了针对性测试。
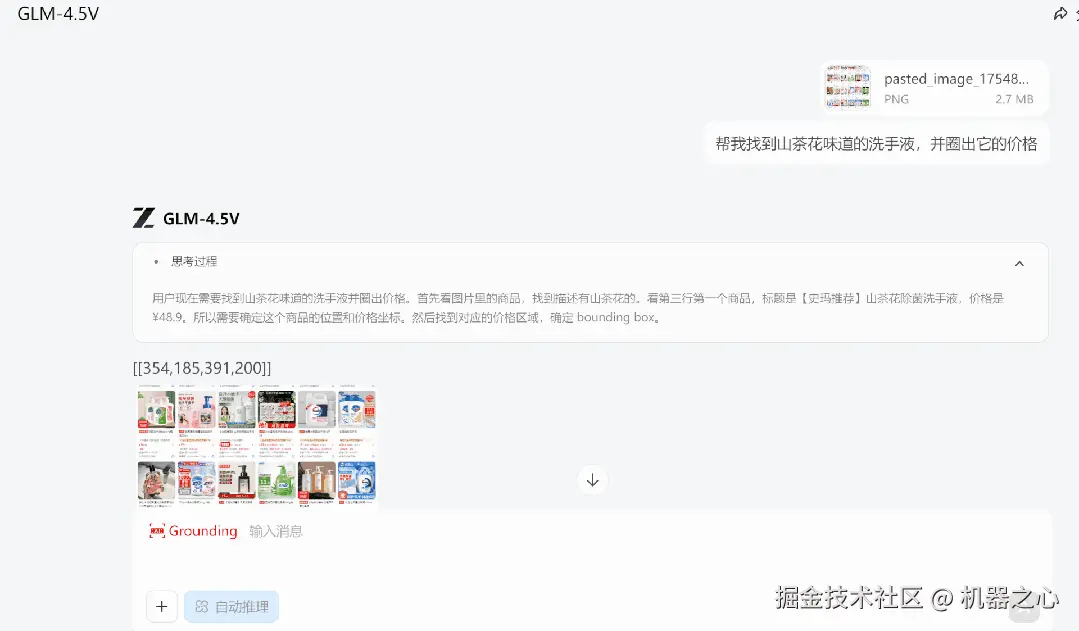
首先,我们提供了电商商品页面等真实屏幕截图,要求模型定位指定商品并准确标注相关元素。测试结果显示,GLM-4.5V 准确找到了该商品,并圈出了我们要求的元素。
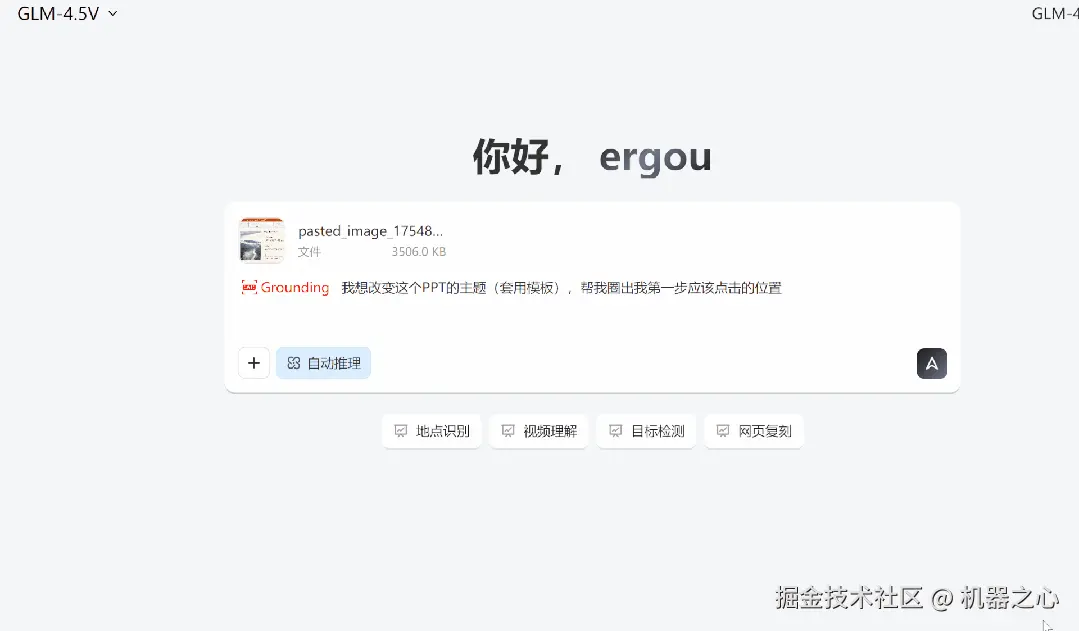
接下来,我们用一个 PPT 操作界面进行了测试,让 GLM-4.5V 找到改变 PPT 主题风格的按钮,它也精准地圈了出来。这说明 GLM-4.5V 已具备作为 Agent 应用底层模型的核心能力基础。
「好用」的背后
GLM-4.5V 是怎么练成的?
在测试中,GLM-4.5V 给我们留下了深刻的印象,也让我们好奇这个模型背后的技术细节。
据了解,GLM-4.5V 的诞生有着清晰的技术传承脉络。7 月底,智谱发布了 GLM-4.1V-Thinking,这是一个在 10B 级别表现最佳的视觉语言模型,上线后迅速登上了 Hugging Face trending 榜首。上周,智谱又发布了新一代旗舰模型 GLM-4.5 和 GLM-4.5-Air。在 4.5-Air 基础上,团队沿用了 GLM-4.1V-Thinking 已经验证过的架构设计,训练出了更大更强的 GLM-4.5V。
GLM-4.5V 是一个拥有 106B 总参数、12B 激活参数的视觉推理模型,由视觉编码器、MLP 适配器和语言解码器三部分组成,支持 64K 多模态长上下文。
它的视觉编码器采用 AIMv2-Huge,支持图像与视频输入,并通过三维卷积提升视频处理效率。模型引入了二维旋转位置编码(2D-RoPE)和双三次插值机制,增强了对高分辨率和极端宽高比图像的适应性。同时,语言解码器中的位置编码扩展为 3D 形式(3D-RoPE),进一步提升了多模态空间理解能力。
训练方面,GLM-4.5V 采用三阶段策略:预训练、监督微调(SFT)和强化学习(RL):
-
在预训练阶段,研究团队结合大规模图文交错多模态语料和长上下文内容,强化了模型对复杂图文及视频的处理能力;
-
在 SFT 阶段,他们引入了显式「思维链」格式训练样本,增强了模型的因果推理与多模态理解能力;
-
最后,在 RL 阶段,他们引入了全领域多模态课程强化学习,通过构建多领域奖励系统(Reward System),结合可验证奖励强化学习(RLVR)与基于人类反馈的强化学习(RLHF),模型在 STEM 问题、多模态定位、Agent 任务等方面获得全面优化。
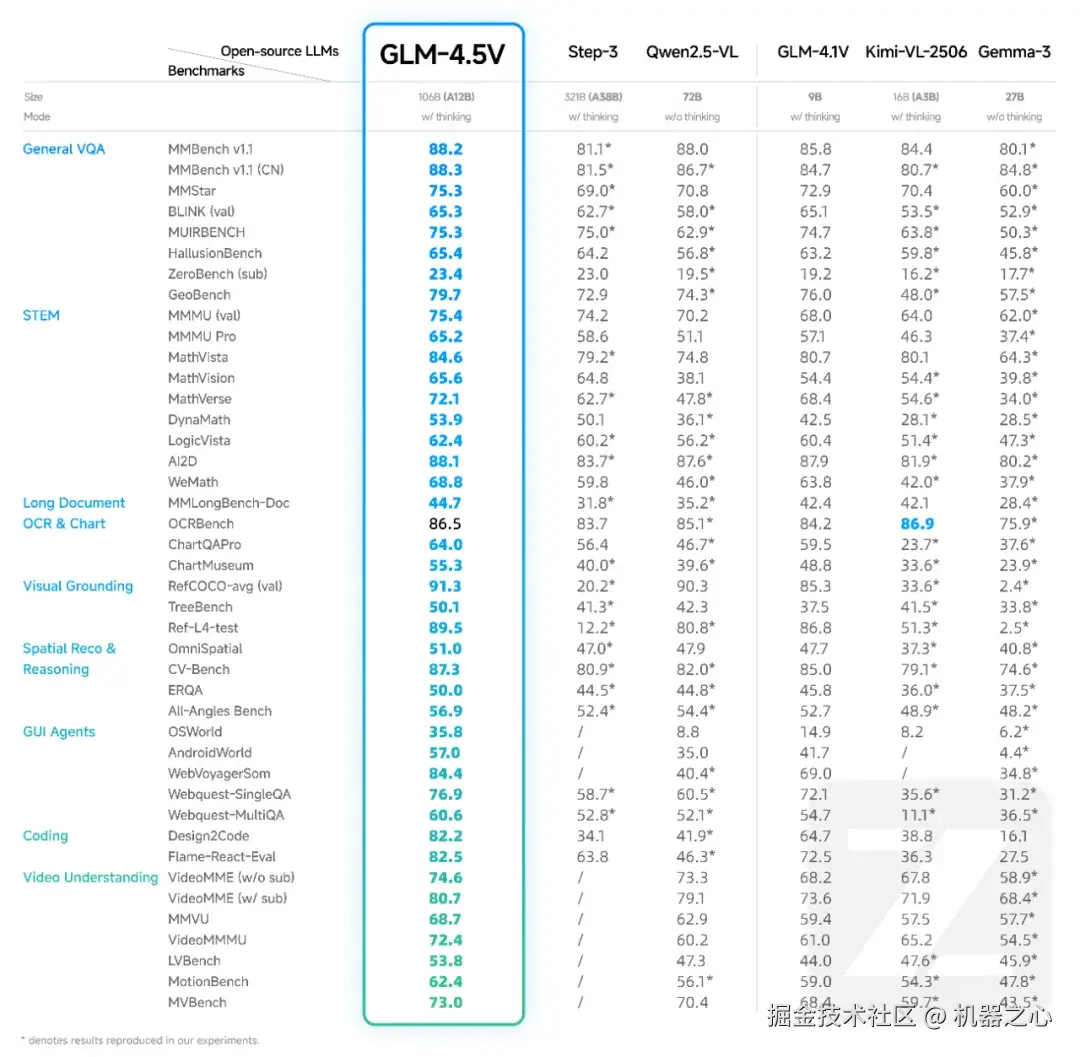
凭借这些技术创新,GLM-4.5V 在涵盖图像理解、视频理解、GUI、文档理解等任务的 41 个公开视觉多模态榜单中综合效果达到了开源 SOTA 水平,这和我们在实测中体验到的结果是一致的。
AI 模型竞争新拐点:从跑分到实战
无论是 OpenAI 前几天的 GPT-5 发布会,还是智谱这次开源 GLM-4.5V 的对外展示。我们能感觉到一个明显的信号:模型厂商对模型在真实场景和体验中的实际效果的重视已经远超之前重点宣传的 benchmark 成绩。这一方面是因为,benchmark 每次更新,都会很快饱和,失去其区分模型性能的初衷。另一方面也是因为,只有体验足够好、真能解决问题的模型才会真的被使用。
而在真正解决问题的过程中,大家对于视觉推理、Agent 能力的需求可以说是无处不在。一问一答、快问快答的 chat 模式逐渐被深度推理、Agent 模式所取代,而且对话中还要包含大量的上下文信息,尤其是多模态信息。
GLM-4.5V 的开源恰逢其时。它为开发者提供了一个在真实场景中表现优异的多模态基础模型。而且相比于闭源模型,开源意味着更高的透明度和可控性,开发者可以根据具体业务需求进行深度定制和优化。更重要的是,这种开源策略将推动整个行业从单纯的性能竞赛转向实用价值的创造,让 AI 技术真正落地到各行各业的具体应用场景中。
从这个角度来看,智谱开放的不只是模型,更是一次让无数开发者共同塑造 AI 未来的机会。