上海合合信息科技股份有限公司(以下简称为合合信息)是一家深耕人工智能、OCR(光学字符识别)及商业大数据技术领域的科技企业。该公司拥有领先的智能文字识别技术,其名片全能王(CamCard)、扫描全能王(CamScanner)和启信宝等核心产品的用户覆盖全球200多个国家和地区,服务用户超过10亿。
在OCR领域,合合信息实力雄厚,可以提供高精度的文档识别与处理解决方案,满足合同比对、财报管理、证照识别等多种场景需求。其OCR技术具备跨格式(Word、PDF和图片)比对、智能纠错、篡改检测等能力,能够精准识别复杂表格、跨页内容以及多语言文本。针对企业级文字识别场景,合合信息旗下的TextIn智能文档处理云平台及其他OCR私有化部署产品,可以灵活适配不同用户的复杂需求。
当前,众多企业正在积极构建文档审核智能体。MaxKB开源企业级智能体平台的文档提取组件主要针对纯文本内容提取,并将结果传递给大模型节点,对于PDF扫描件文档难以实现有效提取。本文将为您介绍MaxKB与TextIn智能文档处理云平台相结合,实现PDF扫描件文档提取与审核功能的具体方案。
一、实现方案
"MaxKB+TextIn"的PDF文档提取基于MaxKB V2版本实现。这主要是考虑到V2版本会存储原文,实现起来更简单。整体流程遵循"用户/文档信息录入→工具提取文档关键信息→大模型融合信息执行审核并输出结果"的实现路径。
1.开启文件MaxKB的文件上传功能,获取文件元数据信息;
-
通过编写函数工具,把文件ID拼接到原文的链接上(通过此链接可以点击直接下载原文);
-
通过函数库实现创建临时文件保存PDF文件,然后调用TextIn智能文档处理云平台的API接口实现上传PDF文件并转换为Markdown格式,然后返回转换结果;
-
调用大模型,结合前面提取的文档信息和用户需求,让AI执行"文档审核"逻辑,生成审核结果或回答。
 ▲图1 通过API实现PDF扫描件文档审核流程
▲图1 通过API实现PDF扫描件文档审核流程二、关键步骤解析
1. 生成PDF下载链接
在MaxKB高级编排中启用文件上传功能后,MaxKB系统将在 {{开始.document}} 参数中存储用户上传文档的URL信息。通过编写函数工具解析该参数获取URL,并按*http://:<端口号>/admin/application/ *的格式输出,即可生成对应的PDF文件下载链接。
输入参数配置为:

函数代码如下:
python
import json
def build_file_url_from_json(data):
"""
从数据中解析出 file_id 并拼接 URL
支持输入:JSON字符串 或 已解析的Python列表对象
参数:
data (str or list): 包含文件信息的JSON字符串或Python列表
返回:
str: 拼接后的完整URL
"""
try:
# 如果输入是字符串,尝试解析为JSON
if isinstance(data, str):
# 替换单引号为双引号(处理不标准的JSON)
data_str= data.replace("'", '"')
data = json.loads(data_str)
# 验证数据格式:必须是列表且第一个元素有file_id
if not isinstance(data, list) or len(data) == 0:
raise ValueError("数据必须是非空列表")
if 'file_id' not in data[0]:
raise ValueError("列表中的元素缺少'file_id'字段")
return "http://10.1.12.36:8080/admin/oss/file/" + data[0]['file_id']
except json.JSONDecodeError:
raise ValueError("无效的JSON字符串")
except Exception as e:
raise ValueError(f"解析失败: {str(e)}")
def process_data(input_data):
try:
file_url = build_file_url_from_json(input_data)
print("转换成功")
return file_url
except ValueError as e:
print(f"转换失败: {str(e)}")
return None 流程编排效果如下:

2. 创建TextIn接口调用函数
函数通过调用TextIn的OCR服务,将指定PDF扫描件下载链接的文档转换为Markdown格式文本。使用前,请注册TextIn智能文档处理云平台(*www.textin.com*)获取认证凭证(x-ti-app-id和x-ti-secret-code),替换代码中的相应参数值。
输入参数配置为:
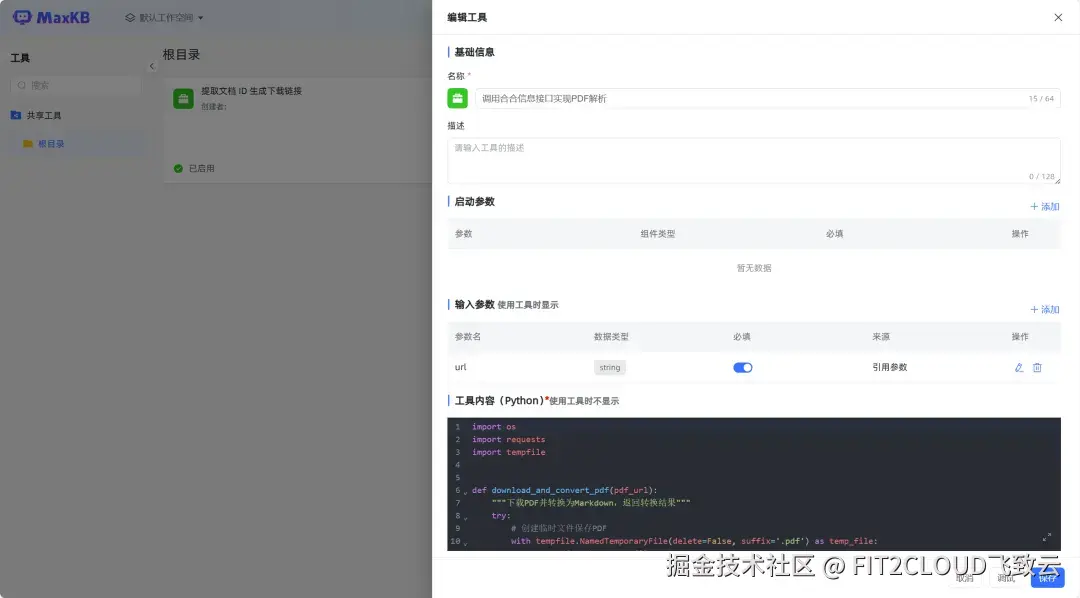
函数代码如下:
python
import os
import requests
import tempfile
def download_and_convert_pdf(pdf_url):
"""下载PDF并转换为Markdown,返回转换结果"""
try:
# 创建临时文件保存PDF
with tempfile.NamedTemporaryFile(delete=False, suffix='.pdf') as temp_file:
temp_pdf_path = temp_file.name
# 下载PDF
response = requests.get(pdf_url)
response.raise_for_status()
temp_file.write(response.content)
# API端点
url = "https://api.textin.com/ai/service/v1/pdf_to_markdown"
headers = {
"x-ti-app-id": "eb4b7ff649d97b0c9***********",
"x-ti-secret-code": "9c635bae8961f55eed************",
"Content-Type": "application/octet-stream"
}
# 读取PDF文件内容并发送请求
with open(temp_pdf_path, 'rb') as f:
response = requests.post(url, headers=headers, data=f.read())
response.raise_for_status()
result = response.json()
# 清理临时文件
os.unlink(temp_pdf_path)
# 处理API响应
if result.get("code") == 200:
return result.get("result", {}).get("markdown", "")
else:
print(f"API请求失败: {result.get('message', '未知错误')}")
return None
except requests.exceptions.RequestException as e:
print(f"网络请求错误: {e}")
return None
except Exception as e:
print(f"处理PDF时出错: {e}")
return None
# 从外部传入URL参数
def process_pdf(url):
markdown_content = download_and_convert_pdf(url)
if markdown_content:
print("转换成功")
return markdown_content
else:
print("转换失败")
return None3. 调用函数实现OCR识别并转为Markdown格式输出
函数执行成功后,其返回值将包含经OCR识别并转换为Markdown格式的文本内容。

4. 调用大模型基于输出的Markdown内容进行审核
在MaxKB的AI对话节点中,大模型能够深度解析OCR转换后的Markdown文本。用户可以针对业务重点灵活配置提示词,通过定制化的审核直接生成带修正建议的审核结果,从而降低排查的时间成本。
三、效果展示
首先,准备好一份PDF文档扫描件。

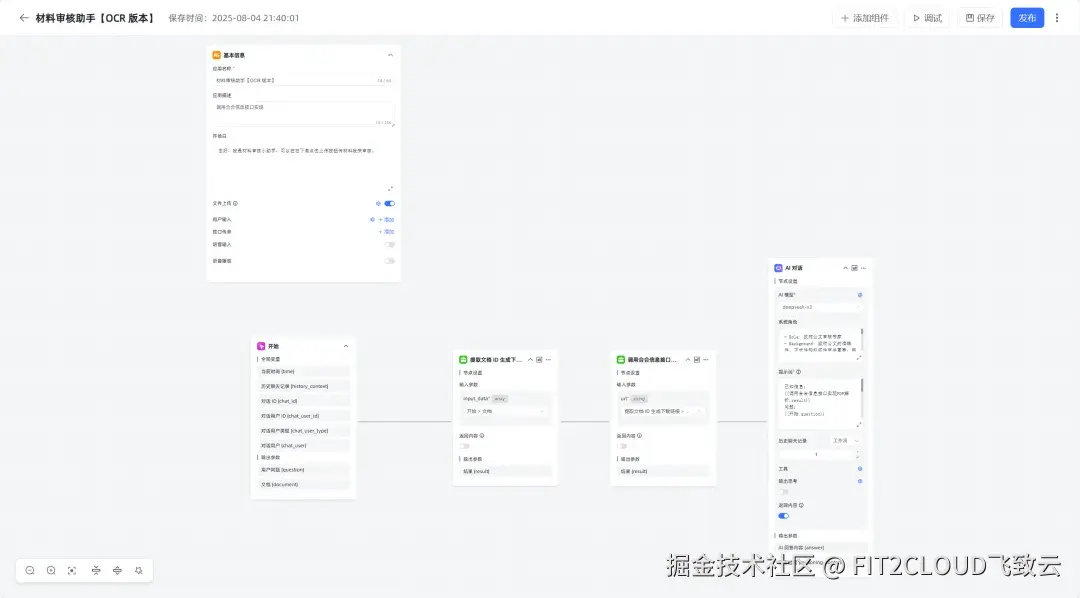
在MaxKB中构建好工作流,具体如下。
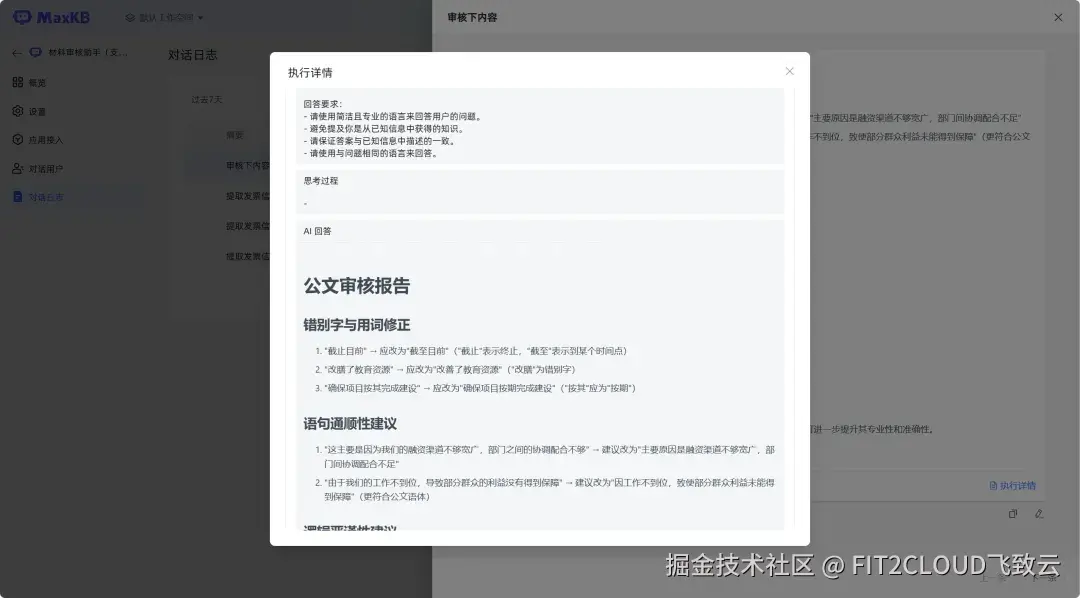
文档审核的对话结果如下,系统对错别字进行了标注,给出了语句修改建议、格式调整意见等审核反馈。

四、延伸思考
本文所介绍的PDF扫描件文档审核方案适用于所有可以通过函数库接入的OCR工具,无论是合合信息TextIn这样的专业云服务,还是企业自建的私有化OCR平台,均可实现灵活接入。MaxKB与OCR技术与服务的结合,能够帮助用户有效突破扫描件文档处理的瓶颈,构建全格式智能审核的闭环。
通过MaxKB与OCR服务的结合,企业不需要投入高成本进行OCR模块的自研,就能直接复用高精度的文本识别能力,在实际业务场景中实现扫描件的秒级解析与审核,大幅提升文档处理效率。