大纲
1.Consumer端代理生成源码流程
2.Consumer动态代理创建源码
3.RegistryProtocol构建Consumer Invoker源码
4.FailoverCluster构建后的处理源码
5.RefreshInvoker源码逻辑
6.Directory的Router链构建过程
7.AppStateRouter路由策略源码
8.ConditionRouter路由策略源码
9.RouterChain源码细节
10.TagStateRouter源码细节
11.Router组件的Invokers变动notify机制
12.ExecutorRepository线程池存储组件源码
13.ExecutorRepository线程池存储组件的操作
14.Directory服务发现和订阅机制
15.Dubbo网络客户端构建流程
Dubbo的Consumer端主要包括如下几大块:
makefile
一.生成动态代理:
1.服务注册(ZooKeeperRegistry + DynamicDirectory) + 与Provider实例建立网络连接
2.组装Invoker链条(MigrationInvoker + MockClusterInvoker + FailoverClusterInvoker)
二.调用动态代理:
1.Filter链条
2.路由+集群容错
3.负载均衡1.Consumer端代理生成源码流程
scss
-> ReferenceConfig.get()
-> getScopeModel().getDeployer().start()
-> AbstractMethodConfig.getScopeModel()
-> ReferenceConfig.init()
-> AbstractConfig.refresh()
-> ReferenceConfigBase.preProcessRefresh()
-> AbstractConfig.assignProperties()
-> AbstractConfig.processExtraRefresh()
-> AbstractInterfaceConfig.processExtraRefresh()
-> ReferenceConfig.postProcessRefresh()
-> ReferenceConfig.checkAndUpdateSubConfigs()
-> AbstractInterfaceConfig.initServiceMetadata()
-> repository.registerService()
-> repository.registerConsumer()
-> ReferenceConfig.createProxy()
public class Application {
public static void main(String[] args) {
//下面一行代码通过泛型传递了调用的服务实例对外暴露的接口
ReferenceConfig<DemoService> reference = new ReferenceConfig<>();
//应用名称
reference.setApplication(new ApplicationConfig("dubbo-demo-api-consumer"));
//设置注册中心的地址,默认是zookeeper
reference.setRegistry(new RegistryConfig("zookeeper://127.0.0.1:2181"));
//设置元数据上报地址
reference.setMetadataReportConfig(new MetadataReportConfig("zookeeper://127.0.0.1:2181"));
//设置要调用的服务的接口
reference.setInterface(DemoService.class);
//直接通过ReferenceConfig的get方法来拿到一个DemoService接口
//它是一个动态代理接口,只要被调用,便会通过底层调用provider服务实例的对应接口
DemoService service = reference.get();
//下面的动态代理接口一旦被调用,首先就会跑到InvokerInvocationHandler.invoke()方法中
String message = service.sayHello("dubbo");
System.out.println(message);
}
}
public class ReferenceConfig<T> extends ReferenceConfigBase<T> {
...
public T get() {
//检测当前ReferenceConfig状态
if (destroyed) {
throw new IllegalStateException("The invoker of ReferenceConfig(" + url + ") has already destroyed!");
}
//ref指向了服务的代理对象
if (ref == null) {
//ensure start module, compatible with old api usage
getScopeModel().getDeployer().start();
synchronized (this) {
if (ref == null) {
//初始化ref字段
init();
}
}
}
return ref;
}
protected synchronized void init() {
//检测ReferenceConfig的初始化状态
if (initialized && ref !=null ) {
return;
}
//执行服务实例的刷新操作,也就是刷新ProviderConfig->MethodConfig->ArgumentConfig
if (!this.isRefreshed()) {
this.refresh();
}
//init serviceMetadata
//对metadata元数据进行初始化以及存储注册等一系列的操作
//封装consumerModel,即把consumer的数据封装起来放到对应的repository里面去
initServiceMetadata(consumer);
serviceMetadata.setServiceType(getServiceInterfaceClass());
//TODO, uncomment this line once service key is unified
serviceMetadata.generateServiceKey();
Map<String, String> referenceParameters = appendConfig();
//init service-application mapping
initServiceAppsMapping(referenceParameters);
//下面这行代码会通过AbstractMethodConfig.getScopeModel()进行ScopeModel获取
//接着会通过ModuleModel.getServiceRepository()再去获取serviceRepository
//ServiceRepository本质是Dubbo服务数据存储组件
ModuleServiceRepository repository = getScopeModel().getServiceRepository();
//接下来会把当前要发布的服务注册到Dubbo服务数据存储组件里去,也就是注册到Repository
ServiceDescriptor serviceDescriptor;
if (CommonConstants.NATIVE_STUB.equals(getProxy())) {
serviceDescriptor = StubSuppliers.getServiceDescriptor(interfaceName);
repository.registerService(serviceDescriptor);
} else {
serviceDescriptor = repository.registerService(interfaceClass);
}
//把所有相关的信息封装成一个ConsumerModel
consumerModel = new ConsumerModel(
serviceMetadata.getServiceKey(),
proxy,
serviceDescriptor,
getScopeModel(),
serviceMetadata,
createAsyncMethodInfo(),
interfaceClassLoader
);
//Compatible with dependencies on ServiceModel#getReferenceConfig() , and will be removed in a future version.
consumerModel.setConfig(this);
//基于Repository组件把consumer数据注册进去
repository.registerConsumer(consumerModel);
serviceMetadata.getAttachments().putAll(referenceParameters);
//调用createProxy()方法创建代理,这是构建整个代理的入口
ref = createProxy(referenceParameters);
//创建完动态代理后,会把这个代理设置给serviceMetadata以及consumerModel
serviceMetadata.setTarget(ref);
serviceMetadata.addAttribute(PROXY_CLASS_REF, ref);
consumerModel.setDestroyRunner(getDestroyRunner());
consumerModel.setProxyObject(ref);
consumerModel.initMethodModels();
//在这里做一下目标服务实例集群是否可用的检查
checkInvokerAvailable();
initialized = true;
}
}
public abstract class AbstractMethodConfig extends AbstractConfig {
...
public ModuleModel getScopeModel() {
return (ModuleModel) scopeModel;
}
...
}
public abstract class AbstractConfig implements Serializable {
...
//Dubbo里有一个model组件体系,其中ScopeModel是基础,ScopeModel类型可以转换为ModuleModel、ApplicationModel
protected ScopeModel scopeModel;
...
}Consumer启动过程中scopeModel的初始化:
java
-> new ReferenceConfig()
-> new ReferenceConfigBase()
-> new AbstractReferenceConfig()
-> new AbstractInterfaceConfig()
-> new AbstractMethodConfig()
-> ApplicationModel.defaultModel()
-> new AbstractConfig(scopeModel)
public class Application {
public static void main(String[] args) throws Exception {
ReferenceConfig<DemoService> reference = new ReferenceConfig<>();
...
}
}
public class ReferenceConfig<T> extends ReferenceConfigBase<T> {
public ReferenceConfig() {
//接着会执行new ReferenceConfigBase()
super();
}
...
}
public abstract class ReferenceConfigBase<T> extends AbstractReferenceConfig {
public ReferenceConfigBase() {
serviceMetadata = new ServiceMetadata();
serviceMetadata.addAttribute(ORIGIN_CONFIG, this);
//接着会执行new AbstractReferenceConfig()
}
...
}
public abstract class AbstractReferenceConfig extends AbstractInterfaceConfig {
public AbstractReferenceConfig() {
//接着会执行new AbstractInterfaceConfig()
}
...
}
public abstract class AbstractInterfaceConfig extends AbstractMethodConfig {
public AbstractInterfaceConfig() {
//接着会执行new AbstractMethodConfig()
}
...
}
public abstract class AbstractMethodConfig extends AbstractConfig {
...
public AbstractMethodConfig() {
//接着会执行new AbstractConfig(scopeModel)
super(ApplicationModel.defaultModel().getDefaultModule());
}
public ModuleModel getScopeModel() {
return (ModuleModel) scopeModel;
}
...
}
public class ApplicationModel extends ScopeModel {
...
public static ApplicationModel defaultModel() {
return FrameworkModel.defaultModel().defaultApplication();
}
...
}
public abstract class AbstractConfig implements Serializable {
//Dubbo里有一个model组件体系,其中ScopeModel是基础,ScopeModel类型可以转换为ModuleModel、ApplicationModel
protected ScopeModel scopeModel;
...
public AbstractConfig(ScopeModel scopeModel) {
this.setScopeModel(scopeModel);
}
}2.Consumer动态代理创建源码
同Provider,Consumer动态代理也分本地和远程。
scss
-> ReferenceConfig.createProxy()
-> ReferenceConfig.shouldJvmRefer()
-> InjvmProtocol.isInjvmRefer()
-> ReferenceConfig.createInvokerForLocal()
-> ReferenceConfig.createInvokerForRemote()
public class ReferenceConfig<T> extends ReferenceConfigBase<T> {
...
private T createProxy(Map<String, String> referenceParameters) {
//provider端有一个本地发布的动作;
//本地发布即把目标实现类封装成一个ProxyInvoker,然后再通过InjvmProtocol发布出去,也就是把ProxyInvoker封装成InjvmExporter;
//所以在同一个JVM里进行本地服务调用时,调用的便是本地发布出去的provider服务实例
//根据url的协议、scope以及injvm等参数检测是否需要本地引用
if (shouldJvmRefer(referenceParameters)) {
createInvokerForLocal(referenceParameters);
} else {
urls.clear();
if (StringUtils.isNotEmpty(url)) {
//user specified URL, could be peer-to-peer address, or register center's address.
//解析用户指定的URL,可能是一个点对点的调用地址,或者是一个注册中心的地址
parseUrl(referenceParameters);
} else {
//if protocols not in jvm checkRegistry
if (!LOCAL_PROTOCOL.equalsIgnoreCase(getProtocol())) {
//加载注册中心的地址RegistryURL
aggregateUrlFromRegistry(referenceParameters);
}
}
//接下来是核心源码的第一步,通过RegistryProtocol创建Invoker
createInvokerForRemote();
}
//这些都是url的处理
URL consumerUrl = new ServiceConfigURL(CONSUMER_PROTOCOL, referenceParameters.get(REGISTER_IP_KEY), 0,
referenceParameters.get(INTERFACE_KEY), referenceParameters);
consumerUrl = consumerUrl.setScopeModel(getScopeModel());
consumerUrl = consumerUrl.setServiceModel(consumerModel);
//对于consumer的元数据,会通过如下代码在这里进行发布
MetadataUtils.publishServiceDefinition(consumerUrl, consumerModel.getServiceModel(), getApplicationModel());
//create service proxy
//通过ProxyFactory适配器选择合适的ProxyFactory扩展实现,基于Invoker创建动态代理对象
return (T) proxyFactory.getProxy(invoker, ProtocolUtils.isGeneric(generic));
}
protected boolean shouldJvmRefer(Map<String, String> map) {
boolean isJvmRefer;
if (isInjvm() == null) {
//if an url is specified, don't do local reference
if (StringUtils.isNotEmpty(url)) {
isJvmRefer = false;
} else {
//by default, reference local service if there is
URL tmpUrl = new ServiceConfigURL("temp", "localhost", 0, map);
isJvmRefer = InjvmProtocol.getInjvmProtocol(getScopeModel()).isInjvmRefer(tmpUrl);
}
} else {
isJvmRefer = isInjvm();
}
return isJvmRefer;
}
private void createInvokerForLocal(Map<String, String> referenceParameters) {
//创建injvm协议的URL
URL url = new ServiceConfigURL(LOCAL_PROTOCOL, LOCALHOST_VALUE, 0, interfaceClass.getName(), referenceParameters);
url = url.setScopeModel(getScopeModel());
url = url.setServiceModel(consumerModel);
//通过Protocol的适配器选择对应的Protocol实现创建Invoker对象
invoker = protocolSPI.refer(interfaceClass, url);
}
private void createInvokerForRemote() {
//createInvokerForRemote核心就两个步骤:
//第一是执行RegistryProtocol.refer()构建出一个invoker;
//第二是执行Cluster.getCluster().join() + new StaticDirectory()对invokers进行加工处理,最后覆盖到invoker上;
//protocolSPI.refer -> invokers -> new StaticDirectory() -> cluster.join -> invoker
if (urls.size() == 1) {
//在单注册中心或是直连单个服务提供方的时候,通过Protocol的适配器选择对应的Protocol实现创建Invoker对象
//也就是会基于RegistryProtocol.refer构建出一个Invoker
//(比如dubbo-demo-api下的示例会构建出一个MigrationInvoker,且curUrl不是注册中心的)
//而且该MigrationInvoker构成:registry属性为装饰ZookeeperRegistry的ListenerRegistryWrapper + cluster属性为装饰FailoverCluster的MockCLusterWrapper
URL curUrl = urls.get(0);
invoker = protocolSPI.refer(interfaceClass, curUrl);
if (!UrlUtils.isRegistry(curUrl)) {
List<Invoker<?>> invokers = new ArrayList<>();
invokers.add(invoker);
//对Invoker进行了一个深加工和处理,又拿到了一个Invoker,覆盖赋值处理
invoker = Cluster.getCluster(scopeModel, Cluster.DEFAULT).join(new StaticDirectory(curUrl, invokers), true);
}
} else {
//多注册中心或是直连多个服务提供方的时候,会根据每个URL创建Invoker对象
List<Invoker<?>> invokers = new ArrayList<>();
URL registryUrl = null;
for (URL url : urls) {
invokers.add(protocolSPI.refer(interfaceClass, url));
if (UrlUtils.isRegistry(url)) {
//确定是多注册中心,还是直连多个Provider
registryUrl = url;
}
}
if (registryUrl != null) {
//多注册中心的场景中,会使用ZoneAwareCluster作为Cluster默认实现,多注册中心之间的选择
String cluster = registryUrl.getParameter(CLUSTER_KEY, ZoneAwareCluster.NAME);
invoker = Cluster.getCluster(registryUrl.getScopeModel(), cluster, false).join(new StaticDirectory(registryUrl, invokers), false);
} else {
//直连多个Provider直连的场景中,使用Cluster适配器选择合适的扩展实现
if (CollectionUtils.isEmpty(invokers)) {
throw new IllegalArgumentException("invokers == null");
}
URL curUrl = invokers.get(0).getUrl();
String cluster = curUrl.getParameter(CLUSTER_KEY, Cluster.DEFAULT);
invoker = Cluster.getCluster(scopeModel, cluster).join(new StaticDirectory(curUrl, invokers), true);
}
}
}
...
}createInvokerForRemote()方法的核心就两点:第一是执行protocolSPI.refer()即主要是RegistryProtocol的refer()方法构建出一个invoker。第二是执行Cluster.getCluster().join()对invokers进行加工处理,最后覆盖到invoker上。
3.RegistryProtocol构建Consumer Invoker源码
RegistryProtocol.refer()的核心逻辑是:首先拿到一个ZooKeeperRegistry即zk注册中心,接着拿到一个MockClusterWrapper(里面会封装一个故障转移集群FailoverCluster)。
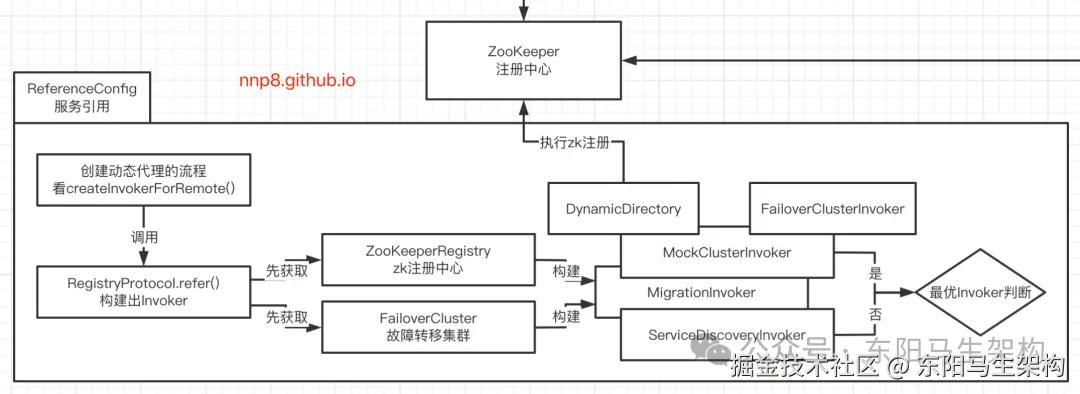
也就是说RegistryProtocol.refer()的方法会返回一个MigrationInvoker,其构成是:
ini
一.registry属性为装饰ZookeeperRegistry的ListenerRegistryWrapper.
二.cluster属性为装饰FailoverCluster的MockCLusterWrapper.
三.invoker属性为MockClusterInvoker.
(directory=RegistryDirectory,invoker=AbstractCluster$ClusterFilterInvoker).
四.serviceDiscoveryInvoker属性为MockClusterInvoker.
(directory=ServiceDiscoveryRegistryDirectory,invoker=AbstractCluster$ClusterFilterInvoker).
scss
-> ReferenceConfig.createInvokerForRemote()
-> protocolSPI.refer(interfaceClass, curUrl)
-> Protocol$Adaptive.refer()
-> ProtocolSerializationWrapper.refer()
-> ProtocolFilterWrapper.refer()
-> ProtocolListenerWrapper.refer()
-> RegistryProtocol.refer()
public class RegistryProtocol implements Protocol, ScopeModelAware {
...
//下面会返回一个MigrationInvoker,其构成是:
//registry属性为装饰ZookeeperRegistry的ListenerRegistryWrapper + cluster属性为装饰FailoverCluster的MockCLusterWrapper;
//invoker和serviceDiscoveryInvoker属性都为MockClusterInvoker,其中前者的directory属性=RegistryDirectory,
//后者的directory属性=ServiceDiscoveryRegistryDirectory,但两者的invoker属性都是AbstractCluster的内部类ClusterFilterInvoker
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
//从URL中获取注册中心的URL
url = getRegistryUrl(url);
//获取Registry实例,这里的RegistryFactory对象是通过Dubbo SPI的自动装载机制注入的
//1.先拿到一个ZooKeeperRegistry即zk注册中心
Registry registry = getRegistry(url);
if (RegistryService.class.equals(type)) {
return proxyFactory.getInvoker((T) registry, type, url);
}
//group="a,b" or group="*"
//从注册中心URL的refer参数中获取此次服务引用的一些参数,其中就包括group
Map<String, String> qs = (Map<String, String>) url.getAttribute(REFER_KEY);
String group = qs.get(GROUP_KEY);
if (StringUtils.isNotEmpty(group)) {
if ((COMMA_SPLIT_PATTERN.split(group)).length > 1 || "*".equals(group)) {
//如果此次可以引用多个group的服务,则Cluser实现使用MergeableCluster实现
//这里的getMergeableCluster()方法就会通过Dubbo SPI方式找到MergeableCluster实例
return doRefer(Cluster.getCluster(url.getScopeModel(), MergeableCluster.NAME), registry, type, url, qs);
}
}
//2.接着会拿到一个MockClusterWrapper,里面会封装一个故障转移集群FailoverCluster
//Cluster是和集群容错强相关的,不同的Cluster会对应不同的Cluster Invoker,不同的Cluster Invoker就有调用失败时不同的集群容错策略和算法
Cluster cluster = Cluster.getCluster(url.getScopeModel(), qs.get(CLUSTER_KEY));
//doRefer()这种代码的编写技巧在很多框架系统都会使用
//refer()方法会先做一些提前的准备工作,而正式的工作可以在方法名称的前面加一个do变成doRefer()方法来执行真正的工作
//下面的doRefer()方法,执行时发现如果没有group参数或是group参数,则通过Cluster适配器选择Cluster实现
return doRefer(cluster, registry, type, url, qs);
}
...
}4.FailoverCluster构建后的处理源码
RegistryProtocol的refer()方法会调用Cluster的getCluster()方法构建FailoverCluster然后装饰到MockClusterWrapper中。
当FailoverCluster构建完成后,就会调用RegistryProtocol的doRefer()方法构建MigrationInvoker。
typescript
-> RegistryProtocol.refer()
-> Cluster.getCluster()
-> RegistryProtocol.doRefer()
-> RegistryProtocol.getMigrationInvoker()
-> new ServiceDiscoveryMigrationInvoker<T>()
-> new MigrationInvoker()
-> RegistryProtocol.interceptInvoker()
-> RegistryProtocol.findRegistryProtocolListeners()
-> MigrationRuleListener.onRefer()
public class RegistryProtocol implements Protocol, ScopeModelAware {
...
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
...
//2.接着会拿到一个MockClusterWrapper,里面会封装一个故障转移集群FailoverCluster
//Cluster是和集群容错强相关的,不同的Cluster会对应不同的Cluster Invoker,不同的Cluster Invoker就有调用失败时不同的集群容错策略和算法
Cluster cluster = Cluster.getCluster(url.getScopeModel(), qs.get(CLUSTER_KEY));
//refer()方法会先做一些提前的准备工作,而正式的工作可以在方法名称的前面加一个do变成doRefer()方法来执行真正的工作
//下面的doRefer()方法,执行时发现如果没有group参数或是group参数,则通过Cluster适配器选择Cluster实现
return doRefer(cluster, registry, type, url, qs);
}
...
}
@SPI(Cluster.DEFAULT)
public interface Cluster {
...
static Cluster getCluster(ScopeModel scopeModel, String name, boolean wrap) {
if (StringUtils.isEmpty(name)) {
//name默认值是failover
name = Cluster.DEFAULT;
}
//比如在RegistryProtocol.refer()中的"Cluster.getCluster(url.getScopeModel(), qs.get(CLUSTER_KEY))"代码
//就会获取到一个装饰着FailoverCluster的MockClusterWrapper
return ScopeModelUtil.getApplicationModel(scopeModel).getExtensionLoader(Cluster.class).getExtension(name, wrap);
}
...
}
public class RegistryProtocol implements Protocol, ScopeModelAware {
...
//doRefer()方法传入的参数cluster就是装饰着FailoverCluster的MockClusterWrapper,registry为装饰ZookeeperRegistry的ListenerRegistryWrapper
//这里会把组装好的Invoker体系里的最源头的一个Invoker返回回去,下一步就会去创建接口的动态代理并把该Invoker放进去
//这样动态代理的方法被调用时,就可以通过该Invoker及其关联的Invoker来完成一个完整的RPC调用过程
protected <T> Invoker<T> doRefer(Cluster cluster, Registry registry, Class<T> type, URL url, Map<String, String> parameters) {
Map<String, Object> consumerAttribute = new HashMap<>(url.getAttributes());
consumerAttribute.remove(REFER_KEY);
String p = isEmpty(parameters.get(PROTOCOL_KEY)) ? CONSUMER : parameters.get(PROTOCOL_KEY);
URL consumerUrl = new ServiceConfigURL (
p,
null,
null,
parameters.get(REGISTER_IP_KEY),
0, getPath(parameters, type),
parameters,
consumerAttribute
);
url = url.putAttribute(CONSUMER_URL_KEY, consumerUrl);
//下面这行代码会以MigrationInvoker作为一个起点去构建一个Invoker链条
//下面这行代码可以理解为初步开始构建Invoker体系链条,也就是把源头Invoker给先准备好,传入的参数cluster就是装饰着FailoverCluster的MockClusterWrapper
//getMigrationInvoker()所返回的MigrationInvoker中,它的invoker和serviceDiscoveryInvoker属性此时还是null
ClusterInvoker<T> migrationInvoker = getMigrationInvoker(this, cluster, registry, type, url, consumerUrl);
//接着下一步,要去继续组装后续的Invoker,然后把后续的Invoker构建好时,便设置给其上层Invoker
//在interceptInvoker()方法中,RegistryProtocol有责任在此把Invoker链条组装好
return interceptInvoker(migrationInvoker, url, consumerUrl);
}
protected <T> ClusterInvoker<T> getMigrationInvoker(RegistryProtocol registryProtocol, Cluster cluster, Registry registry, Class<T> type, URL url, URL consumerUrl) {
//构建基于服务发现机制迁移的Invoker,传入的cluster就是装饰着FailoverCluster的MockClusterWrapper
//传入的registry为装饰ZookeeperRegistry的ListenerRegistryWrapper
return new ServiceDiscoveryMigrationInvoker<T>(registryProtocol, cluster, registry, type, url, consumerUrl);
}
...
}
public class MigrationInvoker<T> implements MigrationClusterInvoker<T> {
...
public MigrationInvoker(...) {
//这个一开始是null
this.invoker = invoker;
//这个一开始也是null
this.serviceDiscoveryInvoker = serviceDiscoveryInvoker;
//cluster就是装饰着FailoverCluster的MockClusterWrapper
this.cluster = cluster;
this.registry = registry;
}
...
}
public class RegistryProtocol implements Protocol, ScopeModelAware {
...
//这里首先会取出RegistryProtocol里的监听回调器,然后遍历监听回调器进行回调处理;
//这种在主业务逻辑里做一些监听回调的处理,让代码读起来感觉逻辑不太清晰;
//比如传入的invoker是MigrationInvoker,对MigrationInvoker进行监听回调的语义就不太好理解了;
protected <T> Invoker<T> interceptInvoker(ClusterInvoker<T> invoker, URL url, URL consumerUrl) {
//根据URL中的registry.protocol.listener参数加载相应的监听器实现,也就是RegistryProtocol里的监听回调器
List<RegistryProtocolListener> listeners = findRegistryProtocolListeners(url);
if (CollectionUtils.isEmpty(listeners)) {
return invoker;
}
//此时传入的invoker也就是MigrationInvoker中,它的invoker和serviceDiscoveryInvoker属性此时还是null
for (RegistryProtocolListener listener : listeners) {
//传递给监听器给invoker,比如下面会调用MigrationRuleListener.onRefer()方法,事实上默认下listeners只有MigrationRuleListener一个元素
listener.onRefer(this, invoker, consumerUrl, url);
}
//此时传入的invoker也就是MigrationInvoker中,它的invoker和serviceDiscoveryInvoker属性就都为MockClusterInvoker
//其中前者的directory属性=RegistryDirectory,后者的directory属性=ServiceDiscoveryRegistryDirectory
//但两者的invoker属性都是AbstractCluster的内部类ClusterFilterInvoker
return invoker;
}
protected List<RegistryProtocolListener> findRegistryProtocolListeners(URL url) {
//通过SPI的Activate自动激活机制,针对指定的接口去获取符合的所有实现类
return ScopeModelUtil.getExtensionLoader(RegistryProtocolListener.class, url.getScopeModel())
.getActivateExtension(url, REGISTRY_PROTOCOL_LISTENER_KEY);
}
...
}5.RefreshInvoker源码逻辑
scss
-> RegistryProtocol.refer()
-> RegistryProtocol.doRefer()
-> RegistryProtocol.getMigrationInvoker()
-> RegistryProtocol.interceptInvoker()
-> listener.onRefer()
-> MigrationRuleListener.onRefer()
-> MigrationRuleHandler.doMigrate()
-> MigrationRuleHandler.refreshInvoker()
-> MigrationInvoker.migrateToApplicationFirstInvoker()
-> MigrationInvoker.refreshInterfaceInvoker()
-> InterfaceCompatibleRegistryProtocol.getInvoker()
-> RegistryProtocol.doCreateInvoker()
-> RegistryProtocol#cluster.join()
-> MockClusterWrapper.join()
-> AbstractCluster.join()
-> FailoverCluster.doJoin()
-> new FailoverClusterInvoker<>(directory)
-> MigrationInvoker.refreshServiceDiscoveryInvoker()
-> InterfaceCompatibleRegistryProtocol.getServiceDiscoveryInvoker()
-> RegistryProtocol.doCreateInvoker()
-> RegistryProtocol#cluster.join()
-> MockClusterWrapper.join()
-> AbstractCluster.join()
-> FailoverCluster.doJoin()
-> new FailoverClusterInvoker<>(directory)
public class MigrationRuleListener implements RegistryProtocolListener, ConfigurationListener {
...
public void onRefer(RegistryProtocol registryProtocol, ClusterInvoker<?> invoker, URL consumerUrl, URL registryURL) {
...
//其实就是拿默认构建好的一个迁移规则处理器,来执行一下对应的迁移逻辑:INIT规则
//比如下面会调用MigrationRuleHandler.doMigrate()
migrationRuleHandler.doMigrate(rule);
}
...
}
public class MigrationRuleHandler<T> {
...
//一旦有新的迁移规则,就把该迁移规则传递进来做对应的迁移
public synchronized void doMigrate(MigrationRule rule) {
//创建出来的源头Invoker是ServiceDiscoveryMigrationInvoker
if (migrationInvoker instanceof ServiceDiscoveryMigrationInvoker) {
refreshInvoker(MigrationStep.FORCE_APPLICATION, 1.0f, rule);
return;
}
...
if (refreshInvoker(step, threshold, rule)) {
// refresh success, update rule
setMigrationRule(rule);
}
}
private boolean refreshInvoker(MigrationStep step, Float threshold, MigrationRule newRule) {
...
//比如会调用MigrationInvoker.migrateToApplicationFirstInvoker()
migrationInvoker.migrateToApplicationFirstInvoker(newRule);
...
}
...
}
public class MigrationInvoker<T> implements MigrationClusterInvoker<T> {
//服务引用时,它是一个MockClusterInvoker,参考RegistryProtocol.refer()的调用栈
private volatile ClusterInvoker<T> invoker;
//这是一个名为serviceDiscoveryInvoker的ClusterInvoker实现类的实例
private volatile ClusterInvoker<T> serviceDiscoveryInvoker;
...
public void migrateToApplicationFirstInvoker(MigrationRule newRule) {
CountDownLatch latch = new CountDownLatch(0);
//这里是比较关键的
//migration迁移有两个核心的Invoker: InterfaceInvoker,ServiceDiscoveryInvoker
//下面会进行Invoker的刷新处理,就是在给我们的MigrationInvoker去注入下一环节的Invoker
refreshInterfaceInvoker(latch);//第一个InterfaceInvoker
refreshServiceDiscoveryInvoker(latch);//第二个ServiceDiscoveryInvoker
//directly calculate preferred invoker, will not wait until address notify
//calculation will re-occurred when address notify later
//下面会把MigrationRule传递进去
//也就是当两个Invoker刷新好后,会根据最新的迁移规则来决定当前应该用哪个Invoker来作为MigrationInvoker的下一级Invoker
calcPreferredInvoker(newRule);
}
protected void refreshInterfaceInvoker(CountDownLatch latch) {
...
//这里是核心逻辑,入参cluster是装饰着FailoverCluster的MockClusterWrapper,入参registry是装饰着ZookeeperRegistry的ListenerRegistryWrapper
//下面会调用InterfaceCompatibleRegistryProtocol的getInvoker()
//这个invoker其实最后发现就是FailoverClusterInvoker
invoker = registryProtocol.getInvoker(cluster, registry, type, url);
...
}
...
}
public class InterfaceCompatibleRegistryProtocol extends RegistryProtocol {
...
public <T> ClusterInvoker<T> getInvoker(Cluster cluster, Registry registry, Class<T> type, URL url) {
//这里传入的registry是ZookeeperRegistry
DynamicDirectory<T> directory = new RegistryDirectory<>(type, url);
//下面会调用RegistryProtocol的doCreateInvoker()方法
return doCreateInvoker(directory, cluster, registry, type);
}
...
}
public class RegistryProtocol implements Protocol, ScopeModelAware {
...
//入参directory是继承了DynamicDirectory的RegistryDirectory或者是继承了DynamicDirectory的ServiceDiscoveryRegistryDirectory
//入参cluster是装饰着FailoverCluster的MockClusterWrapper
protected <T> ClusterInvoker<T> doCreateInvoker(DynamicDirectory<T> directory, Cluster cluster, Registry registry, Class<T> type) {
//设置注册中心
directory.setRegistry(registry);
//设置protocol协议
directory.setProtocol(protocol);
//生成urlToRegistry,协议为consumer,具体的参数是RegistryURL中refer参数指定的参数
Map<String, String> parameters = new HashMap<>(directory.getConsumerUrl().getParameters());
URL urlToRegistry = new ServiceConfigURL(
parameters.get(PROTOCOL_KEY) == null ? CONSUMER : parameters.get(PROTOCOL_KEY),
parameters.remove(REGISTER_IP_KEY),
0,
getPath(parameters, type),
parameters
);
urlToRegistry = urlToRegistry.setScopeModel(directory.getConsumerUrl().getScopeModel());
urlToRegistry = urlToRegistry.setServiceModel(directory.getConsumerUrl().getServiceModel());
if (directory.isShouldRegister()) {
//在urlToRegistry中添加category=consumers和check=false参数
directory.setRegisteredConsumerUrl(urlToRegistry);
//服务注册,在Zookeeper的consumers节点下,添加该Consumer对应的节点
//此时的registry是一个封装了ZookeeperRegistry的ListenerRegistryWrapper或者是一个封装了ServiceDiscoveryRegistry的ListenerRegistryWrapper
registry.register(directory.getRegisteredConsumerUrl());
}
//根据urlToRegistry创建服务路由
directory.buildRouterChain(urlToRegistry);
//订阅服务,toSubscribeUrl()方法会将urlToRegistry中category参数修改为"providers,configurators,routers"
//下面会调用DynamicDirectory子类RegistryDirectory的subscribe()会进行服务发现,同时还会添加相应的监听器
//进行服务发现时,会把从注册中心拿到的服务实例集群invokers都初始化和缓存完毕,并对每个服务实例都新建NettyClient来和provider建立好网络连接
//后面通过directory.list()获取服务实例集群invokers就会从缓存中获取了
directory.subscribe(toSubscribeUrl(urlToRegistry));
//注册中心中可能包含多个Provider,相应的也就有多个Invoker
//这里通过前面选择的cluster(即装饰着FailoverCluster的MockClusterWrapper)将多个Invoker对象封装成一个Invoker对象
//所以下面首先会调用MockClusterWrapper的join()方法,最后返回的MockClusterInvoker会封装好DynamicDirectory和FailoverClusterInvoker
return (ClusterInvoker<T>) cluster.join(directory, true);
}
...
}
public class MockClusterWrapper implements Cluster {
...
public <T> Invoker<T> join(Directory<T> directory, boolean buildFilterChain) throws RpcException {
//先调用AbstractCluster.join()方法处理传入的RegistryDirectory
//然后用MockClusterInvoker进行包装,将DynamicDirectory和FailoverClusterInvoker包装在里面
return new MockClusterInvoker<T>(directory, this.cluster.join(directory, buildFilterChain));
}
...
}
public abstract class AbstractCluster implements Cluster {
...
public <T> Invoker<T> join(Directory<T> directory, boolean buildFilterChain) throws RpcException {
//比如下面会执行FailoverCluster的doJoin()方法
if (buildFilterChain) {
return buildClusterInterceptors(doJoin(directory));
} else {
return doJoin(directory);
}
}
...
}
public class FailoverCluster extends AbstractCluster {
public <T> AbstractClusterInvoker<T> doJoin(Directory<T> directory) throws RpcException {
//使用directory进行join,就是创建出一个ClusterInvoker,同时把directory封装给ClusterInvoker
return new FailoverClusterInvoker<>(directory);
}
}
public class MigrationInvoker<T> implements MigrationClusterInvoker<T> {
//服务引用时,它是一个MockClusterInvoker,参考RegistryProtocol.refer()的调用栈
private volatile ClusterInvoker<T> invoker;
//这是一个名为serviceDiscoveryInvoker的ClusterInvoker实现类的实例
private volatile ClusterInvoker<T> serviceDiscoveryInvoker;
...
protected void refreshServiceDiscoveryInvoker(CountDownLatch latch) {
...
//比如下面会调用RegistryProtocol子类InterfaceCompatibleRegistryProtocol的getServiceDiscoveryInvoker()方法
serviceDiscoveryInvoker = registryProtocol.getServiceDiscoveryInvoker(cluster, registry, type, url);
...
}
...
}
public class InterfaceCompatibleRegistryProtocol extends RegistryProtocol {
...
public <T> ClusterInvoker<T> getServiceDiscoveryInvoker(Cluster cluster, Registry registry, Class<T> type, URL url) {
//这个getRegistry()会获取到装饰着ServiceDiscoveryRegistry的ListenerRegistryWrapper,对传入的registry进行覆盖
registry = getRegistry(super.getRegistryUrl(url));
DynamicDirectory<T> directory = new ServiceDiscoveryRegistryDirectory<>(type, url);
//下面会调用RegistryProtocol的doCreateInvoker()方法
return doCreateInvoker(directory, cluster, registry, type);
}
...
}最后总结Invoker的构建过程:(也就是RegistryProtocol的refer()方法的核心逻辑)
首先通过getRegistry()方法获取zk注册中心:装饰了ZookeeperRegistry的ListenerRegistryWrapper。
然后通过Cluster.getCluster()方法获取封装了故障转移集群FailoverCluster的MockClusterWrapper。
接着通过在doRefer()中调用getMigrationInvoker()创建MigrationInvoker,此时MigrationInvoker里的invoker和serviceDiscoveryInvoker为空。
然后refreshInterfaceInvoker()和refreshServiceDiscoveryInvoker()会刷新invoker和serviceDiscoveryInvoker值。
其中invoker是MockClusterInvoker:其directory属性是注入了ZookeeperRegistry的RegistryDirectory,而invoker属性是FailoverClusterInvoker。
其中serviceDiscoveryInvoker也是MockClusterInvoker:其directory属性是注入了ServiceDiscoveryRegistry的ServiceDiscoveryRegistryDirectory,而invoker属性是FailoverClusterInvoker。
最后在invoker和serviceDiscoveryInvoker之间做一个最优判断,最后确定是MockClusterInvoker。
6.Directory的Router链构建过程
首先通过SPI自动激活机制从RouterFactory(实现类上加了@Activate注解)获取Router的list。
然后通过SPI自动激活机制从StateRouterFactory(实现类上加了@Activate注解)获取有状态的StateRouter的list。
最后对Router和StateRouter分别进行初始化。
scss
-> RegistryProtocol.doCreateInvoker()
-> directory.buildRouterChain()
-> DynamicDirectory.buildRouterChain()
-> RouterChain.buildChain()
-> new RouterChain<>()
-> RouterChain.initWithRouters()
-> RouterChain.initWithStateRouters()
public class RegistryProtocol implements Protocol, ScopeModelAware {
...
//入参directory是继承了DynamicDirectory的RegistryDirectory或者是继承了DynamicDirectory的ServiceDiscoveryRegistryDirectory
//入参cluster是装饰着FailoverCluster的MockClusterWrapper
protected <T> ClusterInvoker<T> doCreateInvoker(DynamicDirectory<T> directory, Cluster cluster, Registry registry, Class<T> type) {
...
//1.根据urlToRegistry创建服务路由
directory.buildRouterChain(urlToRegistry);
//2.订阅服务,toSubscribeUrl()方法会将urlToRegistry中category参数修改为"providers,configurators,routers"
//下面会调用DynamicDirectory子类RegistryDirectory的subscribe()会进行服务发现,同时还会添加相应的监听器
//进行服务发现时,会把从注册中心拿到的服务实例集群invokers都初始化和缓存完毕,并对每个服务实例都新建NettyClient来和provider建立好网络连接
//后面通过directory.list()获取服务实例集群invokers就会从缓存中获取了
directory.subscribe(toSubscribeUrl(urlToRegistry));
//注册中心中可能包含多个Provider,相应的也就有多个Invoker
//这里通过前面选择的cluster(即装饰着FailoverCluster的MockClusterWrapper)将多个Invoker对象封装成一个Invoker对象
//所以下面首先会调用MockClusterWrapper的join()方法,最后返回的MockClusterInvoker会封装好DynamicDirectory和FailoverClusterInvoker
return (ClusterInvoker<T>) cluster.join(directory, true);
}
...
}
public abstract class DynamicDirectory<T> extends AbstractDirectory<T> implements NotifyListener {
...
public void buildRouterChain(URL url) {
this.setRouterChain(RouterChain.buildChain(getInterface(), url));
}
...
}
public class RouterChain<T> {
...
public static <T> RouterChain<T> buildChain(Class<T> interfaceClass, URL url) {
ModuleModel moduleModel = url.getOrDefaultModuleModel();
//针对使用了SPI自动激活机制的Router工厂(实现类上加了@Activate注解),下面会拿到一个Router工厂的list
List<RouterFactory> extensionFactories = moduleModel.getExtensionLoader(RouterFactory.class)
.getActivateExtension(url, ROUTER_KEY);
//遍历所有的Router工厂,每个Router工厂都获取到一个Router,从而构建出一个Router的list
List<Router> routers = extensionFactories.stream()
.map(factory -> factory.getRouter(url))
.sorted(Router::compareTo)
.collect(Collectors.toList());
//通过SPI自动激活机制从StateRouterFactory(实现类上加了@Activate注解)获取有状态的Router
List<StateRouter<T>> stateRouters = moduleModel
.getExtensionLoader(StateRouterFactory.class)
.getActivateExtension(url, ROUTER_KEY)
.stream()
.map(factory -> factory.getRouter(interfaceClass, url))
.collect(Collectors.toList());
boolean shouldFailFast = Boolean.parseBoolean(ConfigurationUtils.getProperty(moduleModel, Constants.SHOULD_FAIL_FAST_KEY, "true"));
RouterSnapshotSwitcher routerSnapshotSwitcher = ScopeModelUtil.getFrameworkModel(moduleModel).getBeanFactory().getBean(RouterSnapshotSwitcher.class);
return new RouterChain<>(routers, stateRouters, shouldFailFast, routerSnapshotSwitcher);
}
//Router就是一个路由规则,可以让当前的consumer服务实例路由到某些provider服务实例上,然后进行后续的访问
//RouterChain则是一套路由规则,可以对consumer服务实例进行约定:到底哪些provider服务实例是可以路由过去进行访问的
public RouterChain(List<Router> routers, List<StateRouter<T>> stateRouters, boolean shouldFailFast, RouterSnapshotSwitcher routerSnapshotSwitcher) {
//所谓Router链条就是一个List,通过对有序List的封装构建了一个有顺序的Router链条
//后续要进行Route路由的时候,就可以按照顺序进行路由处理
initWithRouters(routers);
//init state routers
initWithStateRouters(stateRouters);
this.shouldFailFast = shouldFailFast;
this.routerSnapshotSwitcher = routerSnapshotSwitcher;
}
...
}7.AppStateRouter路由策略源码
(1)Router的主要功能
(2)AppStateRouter
(3)ListenableStateRouter作用和监听方法
(4)ConditionRouterRule
(1)Router的主要功能
Router的主要功能就是根据用户配置的路由规则以及请求携带的信息,过滤出符合条件的Invoker集合,供后续负载均衡逻辑使用。
(2)AppStateRouter
AppStateRouter是由AppStateRouterFactory生成的,AppStateRouter继承了ListenableStateRouter抽象类。虽然ListenableStateRouter是个抽象类,但是没有抽象方法留给子类实现。
(3)ListenableStateRouter作用和监听方法
ListenableStateRouter在ConditionStateRouter基础上添加了动态配置的能力,这体现在ListenableStateRouter的process()方法上,具体的处理逻辑如下:
一.对于ConfigChangedEvent.DELETE事件:直接清空ListenableStateRouter中维护的ConditionRouterRule和ConditionStateRouter集合的引用。
二.对于ConfigChangedEvent.ADDED、ConfigChangedEvent.UPDATED事件,则通过ConditionRuleParser解析事件内容,得到相应的ConditionRouterRule对象和ConditionStateRouter集合。
(4)ConditionRouterRule
ConditionRouterRule中维护了一个List类型的conditions集合,这个conditions集合记录了多个Condition路由条件的规则,对应生成多个ConditionStateRouter对象。
java
@Activate(order = 150)
public class AppStateRouterFactory implements StateRouterFactory {
public static final String NAME = "app";
private volatile StateRouter router;
@Override
public <T> StateRouter<T> getRouter(Class<T> interfaceClass, URL url) {
if (router != null) {
return router;
}
synchronized (this) {
if (router == null) {
router = createRouter(url);
}
}
return router;
}
private <T> StateRouter<T> createRouter(URL url) {
return new AppStateRouter<>(url);
}
}
public class AppStateRouter<T> extends ListenableStateRouter<T> {
public static final String NAME = "APP_ROUTER";
public AppStateRouter(URL url) {
super(url, url.getApplication());
}
}
public class ConditionRouterRule extends AbstractRouterRule {
//每个String就是一个condition条件规则
private List<String> conditions;
...
}
public abstract class ListenableStateRouter<T> extends AbstractStateRouter<T> implements ConfigurationListener {
//里面包含了一系列的condition条件
private volatile ConditionRouterRule routerRule;
private volatile List<ConditionStateRouter<T>> conditionRouters = Collections.emptyList();
...
//如果StateRouter路由规则的配置发生变化,那么就会产生变化的事件推送到process()方法中进行处理
@Override
public synchronized void process(ConfigChangedEvent event) {
...
//如果是删除事件,则把所有的ConditionStateRouter进行清空
if (event.getChangeType().equals(ConfigChangeType.DELETED)) {
routerRule = null;
conditionRouters = Collections.emptyList();
} else {
//如果是变更事件,则先对变更内容进行解析,获取到ConditionRouterRule,然后再生成ConditionStateRouter
routerRule = ConditionRuleParser.parse(event.getContent());
generateConditions(routerRule);
}
}
private void generateConditions(ConditionRouterRule rule) {
if (rule != null && rule.isValid()) {
//对每一条condition条件规则进行处理转化成ConditionStateRouter对象
this.conditionRouters = rule.getConditions()
.stream()
.map(condition -> new ConditionStateRouter<T>(getUrl(), condition, rule.isForce(), rule.isEnabled()))
.collect(Collectors.toList());
for (ConditionStateRouter<T> conditionRouter : this.conditionRouters) {
conditionRouter.setNextRouter(TailStateRouter.getInstance());
}
}
}
@Override
public BitList<Invoker<T>> doRoute(BitList<Invoker<T>> invokers, URL url, Invocation invocation, boolean needToPrintMessage, Holder<RouterSnapshotNode<T>> nodeHolder, Holder<String> messageHolder) throws RpcException {
//检查边界条件,直接返回invokers集合
if (CollectionUtils.isEmpty(invokers) || conditionRouters.size() == 0) {
if (needToPrintMessage) {
messageHolder.set("Directly return. Reason: Invokers from previous router is empty or conditionRouters is empty.");
}
return invokers;
}
// We will check enabled status inside each router.
StringBuilder resultMessage = null;
if (needToPrintMessage) {
resultMessage = new StringBuilder();
}
//遍历路由规则进行过滤
for (AbstractStateRouter<T> router : conditionRouters) {
invokers = router.route(invokers, url, invocation, needToPrintMessage, nodeHolder);
if (needToPrintMessage) {
resultMessage.append(messageHolder.get());
}
}
if (needToPrintMessage) {
messageHolder.set(resultMessage.toString());
}
return invokers;
}
...
}
//基于一些自定义的条件,去进行Router路由,如果一个Invoker是符合条件,那么就可以返回出来去进行调用
public class ConditionStateRouter<T> extends AbstractStateRouter<T> {
public static final String NAME = "condition";
private static final Logger logger = LoggerFactory.getLogger(ConditionStateRouter.class);
//用于切分路由规则的正则表达式
protected static final Pattern ROUTE_PATTERN = Pattern.compile("([&!=,]*)\s*([^&!=,\s]+)");
protected static Pattern ARGUMENTS_PATTERN = Pattern.compile("arguments\[([0-9]+)\]");
//Consumer匹配的条件集合,通过解析条件表达式rule的=>之前半部分,可以得到该集合中的内容
protected Map<String, MatchPair> whenCondition;
//Provider匹配的条件集合,通过解析条件表达式rule的=>之后半部分,可以得到该集合中的内容
protected Map<String, MatchPair> thenCondition;
...
}8.ConditionStateRouter路由策略源码
(1)ConditionStateRouterFactory
(2)关于ConditionStateRouter的路由规则示例
(3)ConditionStateRouter解析规则的流程
(4)ConditionStateRouter.doRoute()方法说明
(1)ConditionStateRouterFactory
首先ConditionStateRouter是由ConditionStateRouterFactory的createRouter()方法创建的。
java
public class ConditionStateRouterFactory extends CacheableStateRouterFactory {
public static final String NAME = "condition";
@Override
protected <T> StateRouter<T> createRouter(Class<T> interfaceClass, URL url) {
return new ConditionStateRouter<T>(url);
}
}(2)关于ConditionStateRouter的路由规则示例
然后ConditionStateRouter是基于条件表达式的路由实现类,比如下面就是一条基于条件表达式的路由规则:
ini
host = 192.168.0.100 => host = 192.168.0.150在上述规则中:"=>"之前的为Consumer匹配的条件(matchWhen),该条件中的所有参数会与Consumer的URL进行对比,当Consumer满足匹配条件时,会对该Consumer的此次调用执行"=>"后面的过滤规则。"=>"之后为Provider地址列表的过滤条件(matchThen),该条件中的所有参数会和Provider的URL进行对比,Consumer最终只拿到过滤后的地址列表。
如果Consumer匹配条件为空,表示"=>"之后的过滤条件对所有Consumer生效。例如:=> host != 192.168.0.150,含义是所有Consumer都不能请求192.168.0.150这个Provider节点。
如果Provider过滤条件为空,表示禁止访问所有Provider。例如:host = 192.168.0.100 =>,含义是192.168.0.100这个Consumer不能访问任何Provider节点。
(3)ConditionStateRouter解析规则的流程
csharp
//基于一些自定义的条件,去进行Router路由,如果一个Invoker是符合条件,那么就可以返回出来去进行调用
public class ConditionStateRouter<T> extends AbstractStateRouter<T> {
...
//Consumer匹配的条件集合,通过解析条件表达式rule的=>之前半部分,可以得到该集合中的内容
protected Map<String, MatchPair> whenCondition;
//Provider匹配的条件集合,通过解析条件表达式rule的=>之后半部分,可以得到该集合中的内容
protected Map<String, MatchPair> thenCondition;
...
//在ConditionStateRouter的构造方法中,会根据URL中携带的相应参数初始化force、enable等字段
//然后从URL的rule参数中获取路由规则进行解析,具体的解析逻辑是在init()方法中实现的
public ConditionStateRouter(URL url) {
super(url);
this.setUrl(url);
this.setForce(url.getParameter(FORCE_KEY, false));
this.enabled = url.getParameter(ENABLED_KEY, true);
if (enabled) {
//下面会从URL的rule参数中获取路由规则进行解析
init(url.getParameterAndDecoded(RULE_KEY));
}
}
public void init(String rule) {
...
//将路由规则中的"consumer."和"provider."字符串清理掉
rule = rule.replace("consumer.", "").replace("provider.", "");
//按照"=>"字符串进行分割,得到whenRule和thenRule两部分
int i = rule.indexOf("=>");
String whenRule = i < 0 ? null : rule.substring(0, i).trim();
String thenRule = i < 0 ? rule.trim() : rule.substring(i + 2).trim();
//解析whenRule和thenRule,得到whenCondition和thenCondition两个条件集合
Map<String, MatchPair> when = StringUtils.isBlank(whenRule) || "true".equals(whenRule) ? new HashMap<String, MatchPair>() : parseRule(whenRule);
Map<String, MatchPair> then = StringUtils.isBlank(thenRule) || "false".equals(thenRule) ? null : parseRule(thenRule);
this.whenCondition = when;
this.thenCondition = then;
...
}
//parseRule()方法会解析表达式生成MatchPair
private static Map<String, MatchPair> parseRule(String rule) throws ParseException {
Map<String, MatchPair> condition = new HashMap<String, MatchPair>();
if (StringUtils.isBlank(rule)) {
return condition;
}
//Key-Value pair, stores both match and mismatch conditions
MatchPair pair = null;
//Multiple values
Set<String> values = null;
//首先按照ROUTE_PATTERN指定的正则表达式匹配整个条件表达式
final Matcher matcher = ROUTE_PATTERN.matcher(rule);
//遍历匹配的结果
while (matcher.find()) {//Try to match one by one
//每个匹配结果有两部分(分组),第一部分是分隔符,第二部分是内容
String separator = matcher.group(1);
String content = matcher.group(2);
//Start part of the condition expression.
if (StringUtils.isEmpty(separator)) {//---(1)没有分隔符,content即为参数名称
pair = new MatchPair();
//初始化MatchPair对象,并将其与对应的Key(即content)记录到condition集合中
condition.put(content, pair);
}
//The KV part of the condition expression
else if ("&".equals(separator)) {//---(4)
//&分隔符表示多个表达式,会创建多个MatchPair对象
if (condition.get(content) == null) {
pair = new MatchPair();
condition.put(content, pair);
} else {
pair = condition.get(content);
}
}
//The Value in the KV part.
else if ("=".equals(separator)) {// ---(2)
//等号分隔符表示KV的分界线
...
values = pair.matches;
values.add(content);
}
//The Value in the KV part.
else if ("!=".equals(separator)) {// ---(5)
//不等号分隔符表示KV的分界线
...
values = pair.mismatches;
values.add(content);
}
//The Value in the KV part, if Value have more than one items.
else if (",".equals(separator)) {// ---(3)
//逗号分隔符表示有多个Value值
...
values.add(content);
} else {
throw new ParseException("Illegal route rule");
}
}
return condition;
}
...
}parseRule()方法解析条件表达式的例子:
ini
host = 2.2.2.2,1.1.1.1,3.3.3.3 & method !=get => host = 1.2.3.4经过ROUTE_PATTERN正则表达式的分组之后,我们得到如下Rule分组示意图:
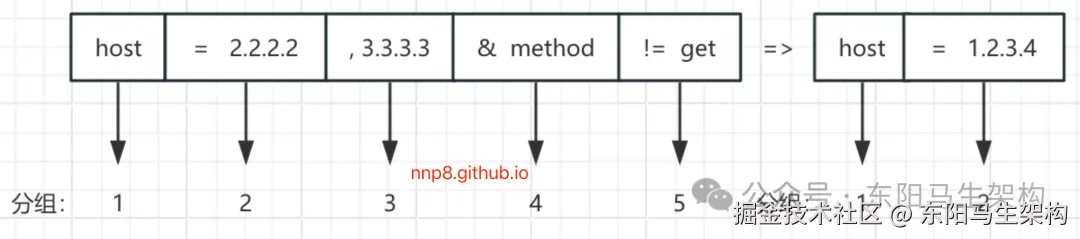
首先,看=>之前的Consumer匹配规则的处理:
步骤一:分组1中,separator为空字符串,content为host字符串。此时会进入parseRule()方法中情况一的分支,创建MatchPair对象,并以host为Key记录到condition集合中。
步骤二:分组2中,separator为"="空字符串,content为"2.2.2.2"字符串。处理该分组时,会进入parseRule()方法中情况二的分支,在MatchPair的matches集合中添加"2.2.2.2"字符串。
步骤三:分组3中,separator为","字符串,content为"3.3.3.3"字符串。处理该分组时,会进入parseRule()方法中的情况三分支,继续向MatchPair的matches集合添加"3.3.3.3"字符串。
步骤四:分组4中,separator为"&"字符串,content为"method"字符串。处理该分组时,会进入parseRule()方法中情况四的分支,创建新的MatchPair对象,并以method为Key记录到condition集合中。
步骤五:分组5中,separator为"!="字符串,content为"get"字符串。处理该分组时,会进入parseRule()方法中情况五的分支,向步骤四新建的MatchPair对象中的mismatches集合添加"get"字符串。
于是,得到的whenCondition集合如下:
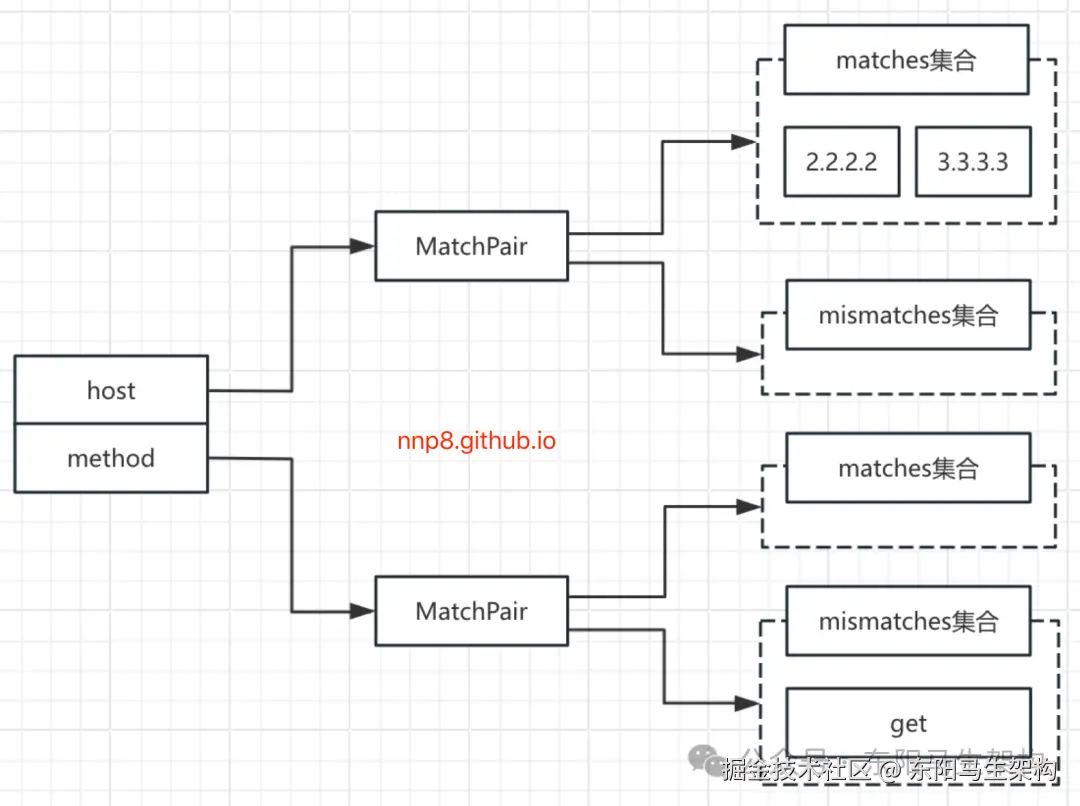
然后,对=>之后的Provider匹配规则的处理,得到的thenCondition集合如下:
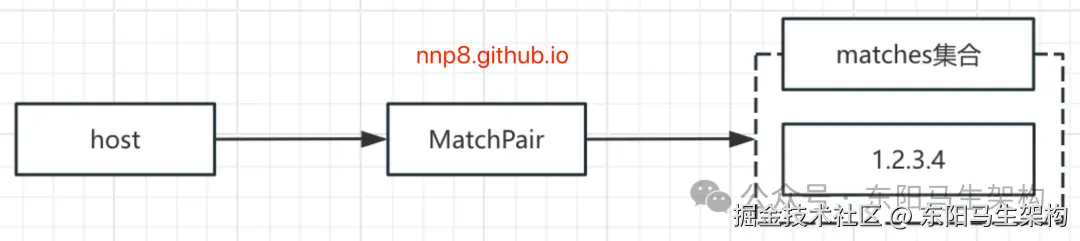
(4)ConditionStateRouter.doRoute()方法说明
ConditionRouter的route()方法会首先尝试匹配whenCondition集合,判断此次发起调用的Consumer是否符合条件表达式中=>之前的Consumer过滤条件。若不符合,则直接返回整个invokers集合。若符合,则通过thenCondition对invokers进行过滤,得到符合Provider过滤条件的Invoker,然后返回给上层调用方。
kotlin
//基于一些自定义的条件,去进行Router路由,如果一个Invoker是符合条件,那么就可以返回出来去进行调用
public class ConditionStateRouter<T> extends AbstractStateRouter<T> {
...
@Override
protected BitList<Invoker<T>> doRoute(BitList<Invoker<T>> invokers, URL url, Invocation invocation, boolean needToPrintMessage, Holder<RouterSnapshotNode<T>> nodeHolder, Holder<String> messageHolder) throws RpcException {
//通过enable字段判断当前ConditionRouter对象是否可用
if (!enabled) {
if (needToPrintMessage) {
messageHolder.set("Directly return. Reason: ConditionRouter disabled.");
}
return invokers;
}
//当前invokers集合为空,则直接返回
if (CollectionUtils.isEmpty(invokers)) {
if (needToPrintMessage) {
messageHolder.set("Directly return. Reason: Invokers from previous router is empty.");
}
return invokers;
}
try {
//匹配发起请求的Consumer是否符合表达式中=>之前的过滤条件,如果没有达到matchWhen的条件,就直接返回
if (!matchWhen(url, invocation)) {
if (needToPrintMessage) {
messageHolder.set("Directly return. Reason: WhenCondition not match.");
}
return invokers;
}
if (thenCondition == null) {
//判断=>之后是否存在Provider过滤条件,若不存在则直接返回空集合,表示无Provider可用
logger.warn("The current consumer in the service blacklist. consumer: " + NetUtils.getLocalHost() + ", service: " + url.getServiceKey());
if (needToPrintMessage) {
messageHolder.set("Empty return. Reason: ThenCondition is empty.");
}
return BitList.emptyList();
}
BitList<Invoker<T>> result = invokers.clone();
//逐个判断Invoker是否符合表达式中=>之后的过滤条件
result.removeIf(invoker -> !matchThen(invoker.getUrl(), url));
if (!result.isEmpty()) {
if (needToPrintMessage) {
messageHolder.set("Match return.");
}
return result;
} else if (this.isForce()) {
//在无Invoker符合条件时,根据force决定是返回空集合还是返回全部Invoker
logger.warn("The route result is empty and force execute. consumer: " + NetUtils.getLocalHost() + ", service: " + url.getServiceKey() + ", router: " + url.getParameterAndDecoded(RULE_KEY));
if (needToPrintMessage) {
messageHolder.set("Empty return. Reason: Empty result from condition and condition is force.");
}
return result;
}
} catch (Throwable t) {
logger.error("Failed to execute condition router rule: " + getUrl() + ", invokers: " + invokers + ", cause: " + t.getMessage(), t);
}
if (needToPrintMessage) {
messageHolder.set("Directly return. Reason: Error occurred ( or result is empty ).");
}
return invokers;
}
...
}9.RouterChain源码细节
scss
public class RouterChain<T> {
...
public static <T> RouterChain<T> buildChain(Class<T> interfaceClass, URL url) {
ModuleModel moduleModel = url.getOrDefaultModuleModel();
//针对使用了SPI自动激活机制的Router工厂(实现类上加了@Activate注解),下面会拿到一个Router工厂的list
List<RouterFactory> extensionFactories = moduleModel.getExtensionLoader(RouterFactory.class)
.getActivateExtension(url, ROUTER_KEY);
//遍历所有的Router工厂,每个Router工厂都获取到一个Router,从而构建出一个Router的list
List<Router> routers = extensionFactories.stream()
.map(factory -> factory.getRouter(url))
.sorted(Router::compareTo)
.collect(Collectors.toList());
//通过SPI自动激活机制从StateRouterFactory(实现类上加了@Activate注解)获取有状态的Router
List<StateRouter<T>> stateRouters = moduleModel
.getExtensionLoader(StateRouterFactory.class)
.getActivateExtension(url, ROUTER_KEY)
.stream()
.map(factory -> factory.getRouter(interfaceClass, url))
.collect(Collectors.toList());
boolean shouldFailFast = Boolean.parseBoolean(ConfigurationUtils.getProperty(moduleModel, Constants.SHOULD_FAIL_FAST_KEY, "true"));
RouterSnapshotSwitcher routerSnapshotSwitcher = ScopeModelUtil.getFrameworkModel(moduleModel).getBeanFactory().getBean(RouterSnapshotSwitcher.class);
return new RouterChain<>(routers, stateRouters, shouldFailFast, routerSnapshotSwitcher);
}
//Router就是一个路由规则,可以让当前的consumer服务实例路由到某些provider服务实例上,然后进行后续的访问
//RouterChain则是一套路由规则,可以对consumer服务实例进行约定:到底哪些provider服务实例是可以路由过去进行访问的
public RouterChain(List<Router> routers, List<StateRouter<T>> stateRouters, boolean shouldFailFast, RouterSnapshotSwitcher routerSnapshotSwitcher) {
//所谓Router链条就是一个List,通过对有序List的封装构建了一个有顺序的Router链条
//后续要进行Route路由的时候,就可以按照顺序进行路由处理
initWithRouters(routers);
//init state routers
initWithStateRouters(stateRouters);
this.shouldFailFast = shouldFailFast;
this.routerSnapshotSwitcher = routerSnapshotSwitcher;
}
public void initWithRouters(List<Router> builtinRouters) {
this.builtinRouters = builtinRouters;
this.routers = new LinkedList<>(builtinRouters);
}
private void initWithStateRouters(List<StateRouter<T>> stateRouters) {
StateRouter<T> stateRouter = TailStateRouter.getInstance();
for (int i = stateRouters.size() - 1; i >= 0; i--) {
StateRouter<T> nextStateRouter = stateRouters.get(i);
nextStateRouter.setNextRouter(stateRouter);
stateRouter = nextStateRouter;
}
this.headStateRouter = stateRouter;
this.stateRouters = Collections.unmodifiableList(stateRouters);
}
public List<Invoker<T>> route(URL url, BitList<Invoker<T>> availableInvokers, Invocation invocation) {
if (RpcContext.getServiceContext().isNeedPrintRouterSnapshot()) {
return routeAndPrint(url, availableInvokers, invocation);
} else {
return simpleRoute(url, availableInvokers, invocation);
}
}
public List<Invoker<T>> routeAndPrint(URL url, BitList<Invoker<T>> availableInvokers, Invocation invocation) {
RouterSnapshotNode<T> snapshot = buildRouterSnapshot(url, availableInvokers, invocation);
logRouterSnapshot(url, invocation, snapshot);
return snapshot.getChainOutputInvokers();
}
public List<Invoker<T>> simpleRoute(URL url, BitList<Invoker<T>> availableInvokers, Invocation invocation) {
BitList<Invoker<T>> resultInvokers = availableInvokers.clone();
//1.route state router
//从头开始执行StateRouter链里的每个StateRouter的route()方法
resultInvokers = headStateRouter.route(resultInvokers, url, invocation, false, null);
if (resultInvokers.isEmpty() && (shouldFailFast || routers.isEmpty())) {
printRouterSnapshot(url, availableInvokers, invocation);
return BitList.emptyList();
}
if (routers.isEmpty()) {
return resultInvokers;
}
List<Invoker<T>> commonRouterResult = resultInvokers.cloneToArrayList();
//2.route common router
//遍历routers字段,逐个调用Router对象的route()方法,对invokers集合进行过滤
for (Router router : routers) {
//Copy resultInvokers to a arrayList. BitList not support
RouterResult<Invoker<T>> routeResult = router.route(commonRouterResult, url, invocation, false);
commonRouterResult = routeResult.getResult();
if (CollectionUtils.isEmpty(commonRouterResult) && shouldFailFast) {
printRouterSnapshot(url, availableInvokers, invocation);
return BitList.emptyList();
}
// stop continue routing
if (!routeResult.isNeedContinueRoute()) {
return commonRouterResult;
}
}
if (commonRouterResult.isEmpty()) {
printRouterSnapshot(url, availableInvokers, invocation);
return BitList.emptyList();
}
return commonRouterResult;
}
...
}10.TagStateRouter源码细节
(1)基于Tag的测试环境隔离方案
(2)TagStateRouterFactory
(3)TagStateRouter
(1)基于Tag的测试环境隔离方案
TagRouter可以将某一个或多个Provider划分到同一分组,约束流量只在指定分组中流转。这样就可以轻松达到流量隔离的目的,从而支持灰度发布等场景。
Dubbo提供了动态和静态两种方式给Provider打标签。其中动态方式就是通过服务治理平台动态下发标签,静态方式就是在XML等静态配置中打标签。
Consumer端可以在RpcContext的attachment中添加request.tag附加属性,注意保存在attachment中的值将会在一次完整的远程调用中持续传递。我们只需要在起始调用时进行设置,就可以达到标签的持续传递。
在实际的开发测试中,一个完整的请求会涉及非常多的Provider,分属不同团队进行维护。这些团队每天都会处理不同的需求,并在其负责的Provider服务中进行修改。如果所有团队都使用一套测试环境,那么测试环境就会变得很不稳定。
如下Provider节点图示:4个Provider分属不同的团队管理,并且都部署在测试环境上。其中,Provider 1和Provider 2部署了稳定的版本,Provider 2和Provider 4部署了不稳定的版本。这样可能会导致整个测试环境无法正常处理请求,因为在这样一个不稳定的测试环境中排查Bug是非常困难的,比如排查Provider2到最后发现是Provider4的Bug。
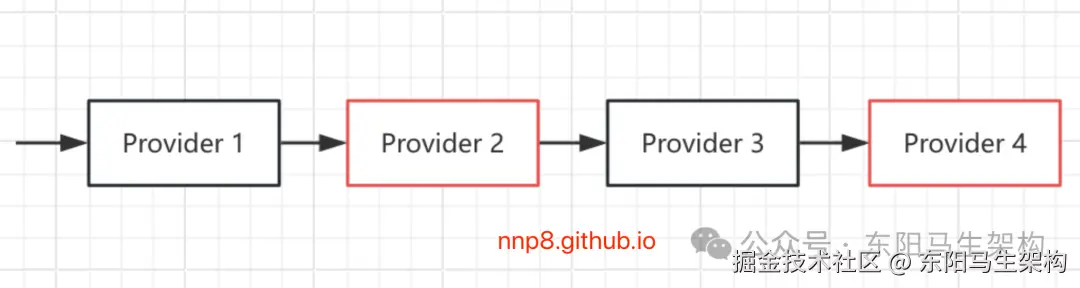
为了解决上述问题,可以针对每个需求分别独立出一套测试环境,但是这个方案会占用大量的机器,前期的搭建成本以及后续的维护成本也都非常高。
下面是一个通过Tag方式实现环境隔离的架构图(依赖Tag实现的测试环境隔离方案)。其中需求1对Provider 2的请求会全部落到有需求1标签的不稳定的Provider 2上,其他Provider使用测试环境中稳定的Provider。需求2对Provider 4的请求会全部落到有需求2标签的不稳定的Provider 4上,其他Provider使用测试环境中稳定的Provider。
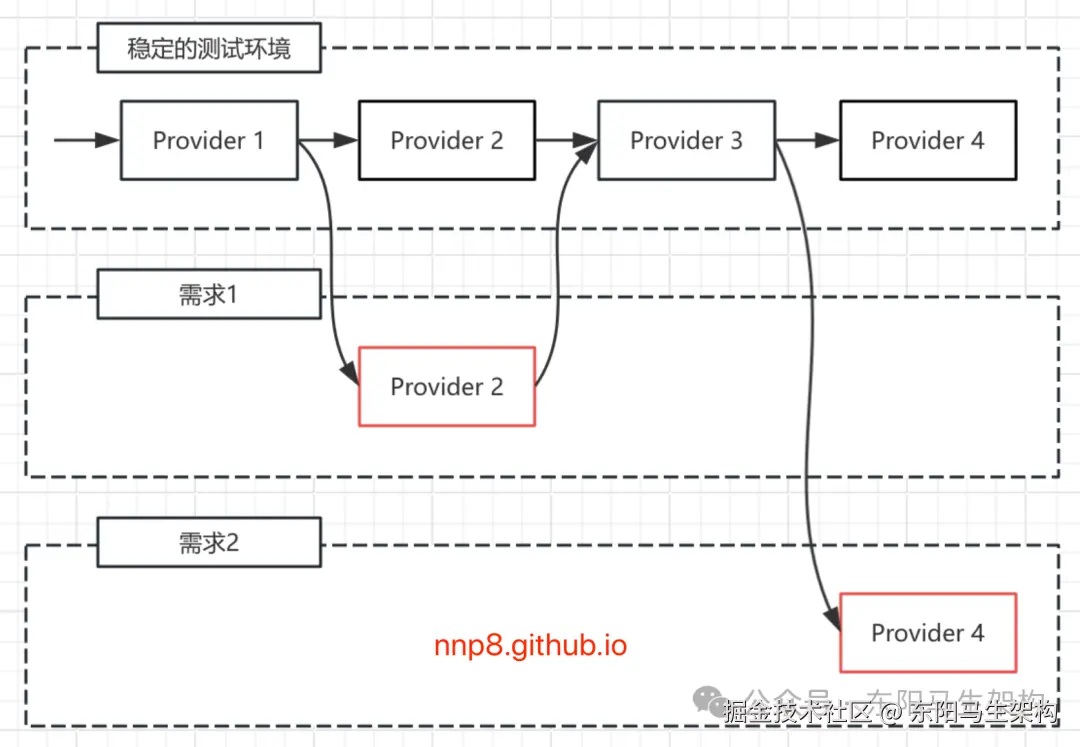
在一些特殊场景中,会有Tag降级的场景,比如当找不到Tag对应的Provider时,就会按照一定的规则进行降级。
如果在Provider集群中不存在与请求Tag对应的Provider节点,默认会将请求降级为Tag是空的Provider。
如果希望在找不到匹配Tag的Provider节点时抛出异常,需要设置request.tag.force = true。如果请求中的request.tag未设置,则只会匹配Tag为空的Provider。
总之,携带Tag的请求可以降级访问到无Tag的Provider,但是不携带Tag的请求永远无法访问到带有Tag的Provider。
(2)TagStateRouterFactory
TagStateRouterFactory作为StateRouterFactory接口的扩展实现,其扩展名为tag。
TagStateRouterFactory与ConditionStateRouterFactory不同如下:
TagStateRouterFactory继承了CacheableStateRouterFactory来间接实现StateRouterFactory接口。
CacheableStateRouterFactory抽象类维护一个routerMap集合来缓存StateRouter,其中Key是ServiceKey。CacheableStateRouterFactory的getRouter()方法,会优先根据URL的ServiceKey查询routerMap集合,查询失败之后会调用createRouter()抽象方法来创建相应的Router对象。
java
@Activate(order = 100)
public class TagStateRouterFactory extends CacheableStateRouterFactory {
public static final String NAME = "tag";
@Override
protected <T> StateRouter<T> createRouter(Class<T> interfaceClass, URL url) {
return new TagStateRouter<T>(url);
}
}
public abstract class CacheableStateRouterFactory implements StateRouterFactory {
//缓存StateRouter,其中Key是ServiceKey
private final ConcurrentMap<String, StateRouter> routerMap = new ConcurrentHashMap<>();
@Override
public <T> StateRouter<T> getRouter(Class<T> interfaceClass, URL url) {
//优先根据URL的ServiceKey查询routerMap集合,查询失败之后会调用createRouter()抽象方法来创建相应的Router对象
return routerMap.computeIfAbsent(url.getServiceKey(), k -> createRouter(interfaceClass, url));
}
protected abstract <T> StateRouter<T> createRouter(Class<T> interfaceClass, URL url);
}(3)TagStateRouter
一个TagRouter对象会持有一个TagRouterRule对象的引用,一个TagRouterRule对象会维护一个Tag对象的集合,一个Tag对象会维护一个Tag的名称以及其绑定的网络地址集合。
另外,TagRouterRule还维护了addressToTagnames、tagnameToAddresses两个Map。这两个Map分别是address到Tag名称的映射以及Tag名称到address的映射。在TagRouterRule的init()方法中,会根据tags集合初始化这两个Map。
typescript
public class TagStateRouter<T> extends AbstractStateRouter<T> implements ConfigurationListener {
private TagRouterRule tagRouterRule;
...
}
public class TagRouterRule extends AbstractRouterRule {
//每个Tag对象会维护一个Tag的名称以及Tag绑定的网络地址集合
private List<Tag> tags;
//记录了Tag名称到各个address的映射
private final Map<String, List<String>> addressToTagnames = new HashMap<>();
//记录了address到Tag名称的映射
private final Map<String, List<String>> tagnameToAddresses = new HashMap<>();
...
}TagStateRouter除了实现了StateRouter接口之外,还实现了ConfigurationListener接口。
ConfigurationListener用于监听配置的变化,其中就包括TagRouterRule配置的变更。当我们动态更新TagRouterRule配置时,就会触发执行ConfigurationListener接口的process()方法。
在TagRouter的process()方法中:如果发现是删除配置的操作,则直接将tagRouterRule设置为null。如果是修改或新增配置的操作,则通过TagRuleParser解析传入的配置得到对应的TagRouterRule对象。
csharp
public class TagStateRouter<T> extends AbstractStateRouter<T> implements ConfigurationListener {
private TagRouterRule tagRouterRule;
...
@Override
public synchronized void process(ConfigChangedEvent event) {
...
try {
//DELETED事件会直接清空tagRouterRule
if (event.getChangeType().equals(ConfigChangeType.DELETED)) {
this.tagRouterRule = null;
} else {
//其他事件会解析最新的路由规则,并记录到tagRouterRule字段中
this.tagRouterRule = TagRuleParser.parse(event.getContent());
}
} catch (Exception e) {
logger.error("...", e);
}
}
}TagStateRouter使用TagRouterRule路由逻辑进行Invoker过滤的步骤如下:
步骤一:如果invokers为空,直接返回空集合。
步骤二:检查关联的tagRouterRule对象是否可用。如果不可用,则直接调用filterUsingStaticTag()方法进行过滤,并返回过滤结果。在filterUsingStaticTag()方法中,会比较请求携带的tag值与Provider URL中的tag参数值。
步骤三:尝试从Invocation以及URL的参数中获取此次调用的tag信息。
步骤四:如果此次请求指定了tag信息,则首先获取tag关联的address集合。
如果address集合不为空,则根据该address集合中的地址,匹配出符合条件的Invoker集合。如果存在符合条件的Invoker,则直接将过滤得到的Invoker集合返回。如果不存在符合条件的Invoker,则会根据force配置决定是否返回空Invoker集合。
如果address集合为空,则会将请求携带的tag值与Provider URL中的tag参数值进行比较,匹配出符合条件的Invoker集合。如果存在符合条件的Invoker或者force配置为true,则直接将过滤得到的Invoker集合返回。如果不存在符合条件的Invoker且force配置为false,则返回所有不包含任何tag的Provider。
步骤五:如果此次请求未携带tag信息,则会先获取TagRouterRule规则中全部tag关联的address集合。如果address集合不为空,则过滤出不在address集合中的Invoker并添加到结果集合中。最后将Provider URL中的tag值与TagRouterRule中的tag名称进行比较,得到最终的Invoker集合。
scss
public class TagStateRouter<T> extends AbstractStateRouter<T> implements ConfigurationListener {
private TagRouterRule tagRouterRule;
...
@Override
public BitList<Invoker<T>> doRoute(BitList<Invoker<T>> invokers, URL url, Invocation invocation, boolean needToPrintMessage, Holder<RouterSnapshotNode<T>> nodeHolder, Holder<String> messageHolder) throws RpcException {
//1.如果invokers为空,直接返回空集合
if (CollectionUtils.isEmpty(invokers)) {
if (needToPrintMessage) {
messageHolder.set("Directly Return. Reason: Invokers from previous router is empty.");
}
return invokers;
}
//since the rule can be changed by config center, we should copy one to use.
final TagRouterRule tagRouterRuleCopy = tagRouterRule;
//2.检查关联的tagRouterRule对象是否可用
//2.1.如果不可用,则会直接调用filterUsingStaticTag()方法进行过滤
if (tagRouterRuleCopy == null || !tagRouterRuleCopy.isValid() || !tagRouterRuleCopy.isEnabled()) {
if (needToPrintMessage) {
messageHolder.set("Disable Tag Router. Reason: tagRouterRule is invalid or disabled");
}
//2.2.在filterUsingStaticTag()方法中,会比较请求携带的tag值与Provider URL中的tag参数值
return filterUsingStaticTag(invokers, url, invocation);
}
BitList<Invoker<T>> result = invokers;
//3.获取此次调用的tag信息,这里会尝试从Invocation以及URL的参数中获取
String tag = StringUtils.isEmpty(invocation.getAttachment(TAG_KEY)) ? url.getParameter(TAG_KEY) :
invocation.getAttachment(TAG_KEY);
//4.如果此次请求指定了tag信息,则首先会获取tag关联的address集合
//此次请求一个特殊的tag
if (StringUtils.isNotEmpty(tag)) {
//获取tag关联的address集合
List<String> addresses = tagRouterRuleCopy.getTagnameToAddresses().get(tag);
//4.1.如果address集合不为空,则根据该address集合中的地址,匹配出符合条件的Invoker集合
if (CollectionUtils.isNotEmpty(addresses)) {
//根据上面的address集合匹配符合条件的Invoker
result = filterInvoker(invokers, invoker -> addressMatches(invoker.getUrl(), addresses));
//如果存在符合条件的Invoker,则直接将过滤得到的Invoker集合返回
//如果不存在符合条件的Invoker,根据force配置决定是否返回空Invoker集合
if (CollectionUtils.isNotEmpty(result) || tagRouterRuleCopy.isForce()) {
if (needToPrintMessage) {
messageHolder.set("Use tag " + tag + " to route. Reason: result is not null OR it's null but force=true");
}
return result;
}
} else {
//dynamic tag group doesn't have any item about the requested app OR it's null after filtered by
//dynamic tag group but force=false. check static tag
//4.2.如果address集合为空,则会将请求携带的tag与Provider URL中的tag参数值进行比较,匹配出符合条件的Invoker集合
result = filterInvoker(invokers, invoker -> tag.equals(invoker.getUrl().getParameter(TAG_KEY)));
}
//If there's no tagged providers that can match the current tagged request. force.tag is set by default
//to false, which means it will invoke any providers without a tag unless it's explicitly disallowed.
//存在符合条件的Invoker或是force配置为true
if (CollectionUtils.isNotEmpty(result) || isForceUseTag(invocation)) {
if (needToPrintMessage) {
messageHolder.set("Use tag " + tag + " to route. Reason: result is not empty or ForceUseTag key is true in invocation");
}
return result;
}
//FAILOVER: return all Providers without any tags.
else {
//4.3.如果force配置为false,且符合条件的Invoker集合为空,则返回所有不包含任何tag的Provider列表
BitList<Invoker<T>> tmp = filterInvoker(invokers, invoker -> addressNotMatches(invoker.getUrl(), tagRouterRuleCopy.getAddresses()));
if (needToPrintMessage) {
messageHolder.set("FAILOVER: return all Providers without any tags");
}
return filterInvoker(tmp, invoker -> StringUtils.isEmpty(invoker.getUrl().getParameter(TAG_KEY)));
}
} else {
//List<String> addresses = tagRouterRule.filter(providerApp);
//return all addresses in dynamic tag group.
//5.如果此次请求未携带tag信息,则会先获取TagRouterRule规则中全部tag关联的address集合
List<String> addresses = tagRouterRuleCopy.getAddresses();
if (CollectionUtils.isNotEmpty(addresses)) {
//如果address集合不为空,则过滤出不在address集合中的Invoker并添加到结果集合中
result = filterInvoker(invokers, invoker -> addressNotMatches(invoker.getUrl(), addresses));
//1. all addresses are in dynamic tag group, return empty list.
if (CollectionUtils.isEmpty(result)) {
if (needToPrintMessage) {
messageHolder.set("all addresses are in dynamic tag group, return empty list");
}
return result;
}
//2. if there are some addresses that are not in any dynamic tag group, continue to filter using the static tag group.
}
if (needToPrintMessage) {
messageHolder.set("filter using the static tag group");
}
//如果不存在符合条件的Invoker或是address集合为空,则会将请求携带的tag与Provider URL中的tag参数值进行比较,得到最终的Invoker集合
return filterInvoker(result, invoker -> {
String localTag = invoker.getUrl().getParameter(TAG_KEY);
return StringUtils.isEmpty(localTag) || !tagRouterRuleCopy.getTagNames().contains(localTag);
});
}
}
...
}11.Router组件的Invokers变动notify机制
kotlin
public class RouterChain<T> {
...
/**
* Notify router chain of the initial addresses from registry at the first time.
* Notify whenever addresses in registry change.
*/
//当注册中心里的地址发生改变时,也就是invokers发生改变或初始化时,要对Router和StateRouter进行notify通知
public void setInvokers(BitList<Invoker<T>> invokers) {
this.invokers = (invokers == null ? BitList.emptyList() : invokers);
routers.forEach(router -> router.notify(this.invokers));
stateRouters.forEach(router -> router.notify(this.invokers));
}
...
}
public abstract class AbstractStateRouter<T> implements StateRouter<T> {
...
@Override
public void notify(BitList<Invoker<T>> invokers) {
// default empty implement
}
}
public class TagStateRouter<T> extends AbstractStateRouter<T> implements ConfigurationListener {
...
@Override
public void notify(BitList<Invoker<T>> invokers) {
if (CollectionUtils.isEmpty(invokers)) {
return;
}
...
Invoker<T> invoker = invokers.get(0);
URL url = invoker.getUrl();
String providerApplication = url.getRemoteApplication();
...
synchronized (this) {
if (!providerApplication.equals(application)) {
if (StringUtils.isNotEmpty(application)) {
this.getRuleRepository().removeListener(application + RULE_SUFFIX, this);
}
String key = providerApplication + RULE_SUFFIX;
//把自己作为监听器进行添加
this.getRuleRepository().addListener(key, this);
//如果规则发生变化,便会通过process()方法进行回调
application = providerApplication;
String rawRule = this.getRuleRepository().getRule(key, DynamicConfiguration.DEFAULT_GROUP);
if (StringUtils.isNotEmpty(rawRule)) {
this.process(new ConfigChangedEvent(key, DynamicConfiguration.DEFAULT_GROUP, rawRule));
}
}
}
}
}12.ExecutorRepository线程池存储组件源码
FrameworkExecutorRepository的构造函数会根据CPU核数进行循环遍历,构建CPU核数个线程池,利用Ring数据结构实现环形获取线程池。
java
public class DefaultExecutorRepository implements ExecutorRepository, ExtensionAccessorAware {
private final ApplicationModel applicationModel;
private final FrameworkExecutorRepository frameworkExecutorRepository;
...
public DefaultExecutorRepository(ApplicationModel applicationModel) {
this.applicationModel = applicationModel;
this.frameworkExecutorRepository = applicationModel.getFrameworkModel().getBeanFactory().getBean(FrameworkExecutorRepository.class);
}
...
}
public class FrameworkExecutorRepository implements Disposable {
private final ExecutorService sharedExecutor;
private final ScheduledExecutorService sharedScheduledExecutor;
private final Ring<ScheduledExecutorService> scheduledExecutors = new Ring<>();
private final Ring<ExecutorService> executorServiceRing = new Ring<>();
...
public FrameworkExecutorRepository() {
//首先构建一个用于共享使用的线程池sharedExecutor,NamedThreadFactory是用来设定线程池里的线程名称的前缀的
//Executors.newCachedThreadPool()会创建一个线程数量无限且线程空闲时间大于60秒则被回收的线程池
sharedExecutor = Executors.newCachedThreadPool(new NamedThreadFactory("Dubbo-framework-shared-handler", true));
//然后构建一个共享的支持定时调度的线程池sharedScheduledExecutor,核心线程数是8,没有线程空闲的处理,线程数量无限
sharedScheduledExecutor = Executors.newScheduledThreadPool(8, new NamedThreadFactory("Dubbo-framework-shared-scheduler", true));
//根据CPU核数进行循环遍历,构建CPU核数个线程池,利用Ring数据结构实现环形获取线程池
int availableProcessors = Runtime.getRuntime().availableProcessors();
for (int i = 0; i < availableProcessors; i++) {
//构建一个单线程调度的线程池,然后添加进Ring里
ScheduledExecutorService scheduler = Executors.newSingleThreadScheduledExecutor(new NamedThreadFactory("Dubbo-framework-scheduler-" + i, true));
scheduledExecutors.addItem(scheduler);
//下面构建的线程池只有一个线程,且不会过期,但是队列是1024大小,对任务会不断进行排队由那唯一的一个线程来执行处理
executorServiceRing.addItem(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(1024), new NamedInternalThreadFactory("Dubbo-framework-state-router-loop-" + i, true),
new ThreadPoolExecutor.AbortPolicy())
);
}
connectivityScheduledExecutor = Executors.newScheduledThreadPool(availableProcessors, new NamedThreadFactory("Dubbo-framework-connectivity-scheduler", true));
cacheRefreshingScheduledExecutor = Executors.newSingleThreadScheduledExecutor(new NamedThreadFactory("Dubbo-framework-cache-refreshing-scheduler", true));
mappingRefreshingExecutor = Executors.newFixedThreadPool(availableProcessors, new NamedThreadFactory("Dubbo-framework-mapping-refreshing-scheduler", true));
//poolRouterExecutor最多10个线程、线程空闲不会进行回收,业务来不及被这10个线程处理时需要进行排队,队列大小是1024
poolRouterExecutor = new ThreadPoolExecutor(1, 10, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(1024),
new NamedInternalThreadFactory("Dubbo-framework-state-router-pool-router", true),
new ThreadPoolExecutor.AbortPolicy()
);
//根据CPU核数进行循环遍历
for (int i = 0; i < availableProcessors; i++) {
//构建一个单线程调度的线程池,然后添加进Ring里
ScheduledExecutorService serviceDiscoveryAddressNotificationExecutor =
Executors.newSingleThreadScheduledExecutor(new NamedThreadFactory("Dubbo-framework-SD-address-refresh-" + i));
ScheduledExecutorService registryNotificationExecutor =
Executors.newSingleThreadScheduledExecutor(new NamedThreadFactory("Dubbo-framework-registry-notification-" + i));
serviceDiscoveryAddressNotificationExecutorRing.addItem(serviceDiscoveryAddressNotificationExecutor);
registryNotificationExecutorRing.addItem(registryNotificationExecutor);
}
metadataRetryExecutor = Executors.newSingleThreadScheduledExecutor(new NamedThreadFactory("Dubbo-framework-metadata-retry"));
}
//初始化时将线程池放在Ring取用环中,就是为了能循环不断的取用不同的线程池进行处理
public ScheduledExecutorService nextScheduledExecutor() {
return scheduledExecutors.pollItem();
}
//初始化时将线程池放在Ring取用环中,就是为了能循环不断的取用不同的线程池进行处理
public ExecutorService nextExecutorExecutor() {
return executorServiceRing.pollItem();
}
...
}
//Ring是Dubbo实现的一个环数据结构------属于取用环
//这个环数据结构,底层是基于CopyOnWriteArrayList来实现的
//可以不停地重复循环地获取数据
public class Ring<T> {
AtomicInteger count = new AtomicInteger();
private List<T> itemList = new CopyOnWriteArrayList<T>();
public void addItem(T t) {
if (t != null) {
itemList.add(t);
}
}
public T pollItem() {
if (itemList.isEmpty()) {
return null;
}
if (itemList.size() == 1) {
return itemList.get(0);
}
//如果count值太大,也就是还差1w条就可以达到Integer.MAX_VALUE值了
//那么此时要对count值进行重置,避免count过大,影响后序取模
if (count.intValue() > Integer.MAX_VALUE - 10000) {
count.set(count.get() % itemList.size());
}
//count指的是poll次数
//每次进行poll的时候count都会进行累加,但是每次累加后都会对itemList进行取模
//比如itemList里有8个元素,每次poll都进行count累加,于是第1次poll获取到第1个元素,第2次poll获取到第2个元素,一直到第8个元素
//所以经过取模,第9次获取又会回来获取到第1个元素,依次类推实现对数据循环获取的效果
int index = Math.abs(count.getAndIncrement()) % itemList.size();
}
...
}13.ExecutorRepository线程池存储组件的操作
typescript
public class DefaultExecutorRepository implements ExecutorRepository, ExtensionAccessorAware {
@Override
public synchronized ExecutorService createExecutorIfAbsent(URL url) {
Map<Integer, ExecutorService> executors = data.computeIfAbsent(getExecutorKey(url), k -> new ConcurrentHashMap<>());
//Consumer's executor is sharing globally, key=Integer.MAX_VALUE. Provider's executor is sharing by protocol.
//根据URL中的side参数值决定第一层key,根据URL中的port值确定第二层key
Integer portKey = CONSUMER_SIDE.equalsIgnoreCase(url.getParameter(SIDE_KEY)) ? Integer.MAX_VALUE : url.getPort();
if (url.getParameter(THREAD_NAME_KEY) == null) {
url = url.putAttribute(THREAD_NAME_KEY, "Dubbo-protocol-" + portKey);
}
URL finalUrl = url;
ExecutorService executor = executors.computeIfAbsent(portKey, k -> createExecutor(finalUrl));
//If executor has been shut down, create a new one
//如果缓存中相应的线程池已关闭,则同样需要调用createExecutor()方法
//创建新的线程池,并替换掉缓存中已关闭的线程持
if (executor.isShutdown() || executor.isTerminated()) {
executors.remove(portKey);
executor = createExecutor(url);
executors.put(portKey, executor);
}
return executor;
}
@Override
public ScheduledExecutorService nextScheduledExecutor() {
return frameworkExecutorRepository.nextScheduledExecutor();
}
@Override
public ExecutorService nextExecutorExecutor() {
return frameworkExecutorRepository.nextExecutorExecutor();
}
@Override
public ExecutorService getSharedExecutor() {
return frameworkExecutorRepository.getSharedExecutor();
}
@Override
public ScheduledExecutorService getSharedScheduledExecutor() {
return frameworkExecutorRepository.getSharedScheduledExecutor();
}
@Override
public ExecutorService getPoolRouterExecutor() {
return frameworkExecutorRepository.getPoolRouterExecutor();
}
...
}14.Directory服务发现和订阅机制
接着回到RegistryProtocol的doCreateInvoker()方法里的服务发现和订阅:
scss
public class RegistryProtocol implements Protocol, ScopeModelAware {
...
//执行MigrationInvoker.refreshInterfaceInvoker()时,这里的入参directory是继承了DynamicDirectory的RegistryDirectory
//执行MigrationInvoker.refreshServiceDiscoveryInvoker()时,这里的入参directory是继承了DynamicDirectory的ServiceDiscoveryRegistryDirectory
//入参cluster是装饰着FailoverCluster的MockClusterWrapper
protected <T> ClusterInvoker<T> doCreateInvoker(DynamicDirectory<T> directory, Cluster cluster, Registry registry, Class<T> type) {
//设置注册中心
directory.setRegistry(registry);
//设置protocol协议
directory.setProtocol(protocol);
//all attributes of REFER_KEY
//生成urlToRegistry,协议为consumer,具体的参数是RegistryURL中refer参数指定的参数
Map<String, String> parameters = new HashMap<>(directory.getConsumerUrl().getParameters());
URL urlToRegistry = new ServiceConfigURL(
parameters.get(PROTOCOL_KEY) == null ? CONSUMER : parameters.get(PROTOCOL_KEY),
parameters.remove(REGISTER_IP_KEY),
0,
getPath(parameters, type),
parameters
);
urlToRegistry = urlToRegistry.setScopeModel(directory.getConsumerUrl().getScopeModel());
urlToRegistry = urlToRegistry.setServiceModel(directory.getConsumerUrl().getServiceModel());
if (directory.isShouldRegister()) {
//在urlToRegistry中添加category=consumers和check=false参数
directory.setRegisteredConsumerUrl(urlToRegistry);
//服务注册,在Zookeeper的consumers节点下,添加该Consumer对应的节点
//此时的registry是一个封装了ZookeeperRegistry的ListenerRegistryWrapper或者是一个封装了ServiceDiscoveryRegistry的ListenerRegistryWrapper
registry.register(directory.getRegisteredConsumerUrl());
}
//1.根据urlToRegistry创建服务路由
directory.buildRouterChain(urlToRegistry);
//2.订阅服务,toSubscribeUrl()方法会将urlToRegistry中category参数修改为"providers,configurators,routers"
//下面会调用DynamicDirectory子类RegistryDirectory的subscribe()会进行服务发现,同时还会添加相应的监听器
//进行服务发现时,会把从注册中心拿到的服务实例集群invokers都初始化和缓存完毕,并对每个服务实例都新建NettyClient来和provider建立好网络连接
//后面通过directory.list()获取服务实例集群invokers就会从缓存中获取了
directory.subscribe(toSubscribeUrl(urlToRegistry));
//注册中心中可能包含多个Provider,相应的也就有多个Invoker
//这里通过前面选择的cluster(即装饰着FailoverCluster的MockClusterWrapper)将多个Invoker对象封装成一个Invoker对象
//所以下面首先会调用MockClusterWrapper的join()方法,最后返回的MockClusterInvoker会封装好DynamicDirectory和FailoverClusterInvoker
return (ClusterInvoker<T>) cluster.join(directory, true);
}
...
}Directory服务发现和订阅机制的核心流程如下:
scss
先调用的是RegistryDirectory.subscribe()方法.
然后会调用DynamicDirectory.subscribe()方法.
接着会调用ListenerRegistryWrapper.subscribe()方法.
接着会调用FailbackRegistry.subscribe()方法.
然后调用AbstractRegistry.subscribe()方法和FailbackRegistry的抽象方法doSubscribe().
也就是会调用到ZookeeperRegistry.doSubscribe()方法,然后会通过zkClient对服务进行订阅和监听.
接着会调用FailbackRegistry.notify()方法通知NotifyListener处理当前已有的URL等注册数据.
接着会调用父类AbstractRegistry.notify()方法.
接着会调用RegistryDirectory.notify()方法,期间会通过NettyClient和provider建立网络连接.
在RegistryDirectory.notify()方法调用链中,最后会通过toInvokers()方法调用到DubboProtocol.refer()方法.
DubboProtocol.refer()方法会通过protocolBindingRefer()把Invoker构建出来,也就是封装一个DubboInvoker.
这个DubboInvoker的构建过程便会通过NettyClient对服务提供实例建立网络连接.
scss
-> RegistryProtocol.doCreateInvoker() : directory.subscribe(toSubscribeUrl(urlToRegistry))
-> RegistryDirectory.subscribe()
-> DynamicDirectory.subscribe()
-> ListenerRegistryWrapper.subscribe()
-> FailbackRegistry.subscribe()
-> AbstractRegistry.subscribe() + FailbackRegistry.doSubscribe()
-> ZookeeperRegistry.doSubscribe() + create()/notify()
-> FailbackRegistry.notify()
-> AbstractRegistry.notify()
-> RegistryDirectory.notify()
-> RegistryDirectory.toInvokers()
-> DubboProtocol.refer()
-> DubboProtocol.protocolBindingRefer()
-> DubboProtocol.getClients()
-> DubboProtocol.initClient()
-> Exchangers.connect()
-> new DubboInvoker()
public class RegistryDirectory<T> extends DynamicDirectory<T> {
...
@Override
public void subscribe(URL url) {
//调用DynamicDirectory.subscribe()方法
super.subscribe(url);
if (moduleModel.getModelEnvironment().getConfiguration().convert(Boolean.class, org.apache.dubbo.registry.Constants.ENABLE_CONFIGURATION_LISTEN, true)) {
//将当前RegistryDirectory对象作为ConfigurationListener记录到consumerConfigurationListener中
consumerConfigurationListener.addNotifyListener(this);
referenceConfigurationListener = new ReferenceConfigurationListener(moduleModel, this, url);
}
}
...
}
public abstract class DynamicDirectory<T> extends AbstractDirectory<T> implements NotifyListener {
...
public void subscribe(URL url) {
setSubscribeUrl(url);
//实现服务发现靠的就是下面这个方法,会调用ListenerRegistryWrapper.subscribe()方法
registry.subscribe(url, this);
}
...
}
public class ListenerRegistryWrapper implements Registry {
...
public void subscribe(URL url, NotifyListener listener) {
...
//服务引用时下面会调用FailbackRegistry.subscribe()方法
//服务发布时下面会调用ServiceDiscoveryRegistry.subscribe()方法
registry.subscribe(url, listener);
...
}
...
}
public abstract class FailbackRegistry extends AbstractRegistry {
...
public void subscribe(URL url, NotifyListener listener) {
...
super.subscribe(url, listener);
//下面会调用到ZookeeperRegistry.doSubscribe()方法
doSubscribe(url, listener);
...
}
public abstract void doSubscribe(URL url, NotifyListener listener);
...
}
public class ZookeeperRegistry extends CacheableFailbackRegistry {
...
public void doSubscribe(final URL url, final NotifyListener listener) {
...
//尝试创建持久节点,主要是为了确保当前path在Zookeeper上存在
//比如会对"/dubbo/服务接口/providers"做一个检查,如果存在就不做什么,如果不存在就会去创建出来
zkClient.create(root, false);
//针对要订阅和发现的那个服务节点,去加一个监听器,而且第一次加监听器,就会直接把子节点列表返回
//这个子节点列表,就是指定的provider服务实例集群地址列表
List<String> children = zkClient.addChildListener(path, zkListener);
...
//初次订阅的时候,会主动调用一次notify()方法,通知NotifyListener处理当前已有的URL等注册数据
//这里会调用FailbackRegistry.notify()方法
notify(url, listener, urls);
...
}
...
}
//这是一个支持故障和重试的抽象类
public abstract class FailbackRegistry extends AbstractRegistry {
...
protected void notify(URL url, NotifyListener listener, List<URL> urls) {
//在订阅和发现时,必然需要直接定位到对应的providers集群地址
//所以这些地址需要存储在本地,这样才能方便后续通过directory获取,保证随时可以拿到对应的集群地址
...
//FailbackRegistry.doNotify()方法实际上就是调用父类AbstractRegistry.notify()方法,没有其他逻辑
doNotify(url, listener, urls);
...
}
protected void doNotify(URL url, NotifyListener listener, List<URL> urls) {
//FailbackRegistry.doNotify()方法实际上就是调用父类AbstractRegistry.notify()方法,没有其他逻辑
super.notify(url, listener, urls);
}
...
}
public abstract class AbstractRegistry implements Registry {
...
protected void notify(URL url, NotifyListener listener, List<URL> urls) {
...
for (Map.Entry<String, List<URL>> entry : result.entrySet()) {
String category = entry.getKey();
List<URL> categoryList = entry.getValue();
categoryNotified.put(category, categoryList);
//下面会调用RegistryDirectory.notify(),通过NettyClient建立网络连接
listener.notify(categoryList);
...
}
}
...
}
public class RegistryDirectory<T> extends DynamicDirectory<T> {
...
public synchronized void notify(List<URL> urls) {
...
refreshOverrideAndInvoker(providerURLs);
}
private synchronized void refreshOverrideAndInvoker(List<URL> urls) {
refreshInvoker(urls);
}
private void refreshInvoker(List<URL> invokerUrls) {
...
//将invokerUrls转换为对应的Invoker映射关系
Map<URL, Invoker<T>> newUrlInvokerMap = toInvokers(oldUrlInvokerMap, invokerUrls);
...
}
private Map<URL, Invoker<T>> toInvokers(Map<URL, Invoker<T>> oldUrlInvokerMap, List<URL> urls) {
...
//这里通过Protocol.refer()方法创建对应的Invoker对象,比如会调用DubboProtocol.refer()方法
invoker = protocol.refer(serviceType, url);
...
}
...
}
public class DubboProtocol extends AbstractProtocol {
...
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
checkDestroyed();
return protocolBindingRefer(type, url);
}
public <T> Invoker<T> protocolBindingRefer(Class<T> serviceType, URL url) throws RpcException {
checkDestroyed();
//进行序列化优化,注册需要优化的类
optimizeSerialization(url);
//create rpc invoker,创建DubboInvoker对象
//下面会针对目标服务实例的url,构建一个DubboInvoker
//针对这个url,会有getClients这个过程,getClients这个过程就是针对目标服务实例进行网络连接
DubboInvoker<T> invoker = new DubboInvoker<T>(serviceType, url, getClients(url), invokers);
//将上面创建DubboInvoker对象添加到invoker集合之中
invokers.add(invoker);
return invoker;
}
private ExchangeClient[] getClients(URL url) {
//CONNECTIONS_KEY参数值决定了后续建立连接的数量
int connections = url.getParameter(CONNECTIONS_KEY, 0);
//如果没有连接数的相关配置,默认使用共享连接的方式
if (connections == 0) {
//确定建立共享连接的条数,默认只建立一条共享连接
String shareConnectionsStr = StringUtils.isBlank(url.getParameter(SHARE_CONNECTIONS_KEY, (String) null))
? ConfigurationUtils.getProperty(url.getOrDefaultApplicationModel(), SHARE_CONNECTIONS_KEY, DEFAULT_SHARE_CONNECTIONS)
: url.getParameter(SHARE_CONNECTIONS_KEY, (String) null);
connections = Integer.parseInt(shareConnectionsStr);
//创建公共ExchangeClient集合
List<ReferenceCountExchangeClient> shareClients = getSharedClient(url, connections);
//整理要返回的ExchangeClient集合
ExchangeClient[] clients = new ExchangeClient[connections];
Arrays.setAll(clients, shareClients::get);
return clients;
}
//整理要返回的ExchangeClient集合
ExchangeClient[] clients = new ExchangeClient[connections];
for (int i = 0; i < clients.length; i++) {
//不使用公共连接的情况下,会创建单独的ExchangeClient实例
clients[i] = initClient(url);
}
return clients;
}
private ExchangeClient initClient(URL url) {
//获取客户端类型,并检查
String str = url.getParameter(CLIENT_KEY, url.getParameter(SERVER_KEY, DEFAULT_REMOTING_CLIENT));
if (StringUtils.isNotEmpty(str) && !url.getOrDefaultFrameworkModel().getExtensionLoader(Transporter.class).hasExtension(str)) {
throw new RpcException("Unsupported client type: ...");
}
try {
url = new ServiceConfigURL(DubboCodec.NAME, url.getUsername(), url.getPassword(), url.getHost(), url.getPort(), url.getPath(), url.getAllParameters());
//设置Codec2的扩展名
url = url.addParameter(CODEC_KEY, DubboCodec.NAME);
//设置默认的心跳间隔
url = url.addParameterIfAbsent(HEARTBEAT_KEY, String.valueOf(DEFAULT_HEARTBEAT));
//如果配置了延迟创建连接的特性,则创建LazyConnectExchangeClient
return url.getParameter(LAZY_CONNECT_KEY, false)
? new LazyConnectExchangeClient(url, requestHandler)
: Exchangers.connect(url, requestHandler);
} catch (RemotingException e) {
throw new RpcException("Fail to create remoting client for service(" + url + "): " + e.getMessage(), e);
}
}
...
}15.Dubbo网络客户端构建流程
Dubbo网络客户端构建入口就是DubboProtocol的initClient()方法里的Exchangers.connect(url, requestHandler)。注意:最后会构建出一个如下层层wrap的handler,这个handler会成为NettyClient的handler属性。
diff
-> MultiMessageHandler
-> HeartbeatHandler
-> AllChannelHandler
-> DecodeHandler
-> HeaderExchangeHandler
-> DubboProtocol.requestHandler同时HeaderExchangeClient装饰了NettyClient,即HeaderExchangeClient的client属性是一个NettyClient。并且HeaderExchangeClient的channel属性也是一个装饰了NettyClient的HeaderExchangeChannel。