嗨,我是小华同学,专注解锁高效工作与前沿AI工具!每日精选开源技术、实战技巧,助你省时50%、领先他人一步。👉免费订阅,与10万+技术人共享升级秘籍!
System Prompts Leaks 是一个开源仓库,专门收集整理各大主流聊天机器人(如 ChatGPT、Claude、Gemini 等)的系统提示词(System Prompts / System Messages / Developer Messages)。仓库按照厂商分目录维护了大量已被提取出的系统提示内容,是学习大模型底层提示工程和安全问题时非常高价值的资料集。
为什么系统提示词值得你花时间?
对绝大多数人来说,和大模型的交互只停留在一行行用户指令(user prompt): "帮我写段代码"、"解释这段 SQL"、"润色一下邮件"。
但在这些对话背后,还有一层不会展示给终端用户看的"底层设定" ------系统提示词(System Prompt):
- 它决定了模型说话的口吻和角色(严肃?幽默?像专家还是像老师?)
- 它规定了必须遵守的规则(哪些问题不能答、遇到敏感话题如何回避)
- 它告诉模型要如何使用工具(搜索、代码执行、文件读取等)
- 它定义了回答格式(是否要用 Markdown、是否强制加引用、是否输出代码块)
对做 AI 产品、做 Prompt Engineering 或研究 AI 安全的人来说,这些系统提示词几乎就是 "模型产品说明书 + 行为规范" 。
学界甚至已经把"系统提示词泄露(Prompt Leakage)"当成一个重要的安全课题:攻击者通过精心构造的提示,诱导模型把自己的 system prompt 说出来,从而窃取内部策略与商业机密。
你正在遇到的这些痛点,这个仓库都对得上号
站在一个日常玩大模型、做技术分享的视角,很容易有这些困惑:
- "为什么 ChatGPT 这么爱加 disclaimer?这些话是哪来的?"
- "Claude 老强调要加引用、要用 artifacts,它是被谁这样要求的?"
- "我也想给自己内部的 Agent 写一套专业的 system prompt,但不知道从哪学起。"
- "安全团队让我评估'Prompt Leakage 风险',可我连别人的 system prompt 长什么样都没见过。"
而 asgeirtj/system_prompts_leaks 做的事情,就是把这些原本藏在云端服务里的"隐身设定",以文本文件的形式整理出来,变成你可以直接学习、对比、借鉴的素材。
核心内容和结构拆解
打开仓库主页,你会看到非常简洁但信息量很大的结构:
-
顶层目录包含:
Anthropic/Google/OpenAI/Perplexity/Proton/xAI/Misc/- 以及根目录下的
claude.txt、WARP.md等文件
这已经暗示了项目的核心定位:按厂商拆分,按产品/模型整理,对应的都是已被提取出来的系统提示词。
1. 多厂商、多模型的系统提示词集中收录
- README 的 About 写得很直接: "Collection of extracted System Prompts from popular chatbots like ChatGPT, Claude & Gemini"。
- 对你来说,这意味着: 不用再到处搜 Reddit、X、博客文章,一个仓库就能看到多家厂商被公开的 system prompt 版本。
2. 按厂商分类的目录结构
顶层目录名直接对应厂商(Anthropic、OpenAI、Google、Perplexity、xAI 等),加上一个 Misc/ 放杂项,结构非常直观。
这带来几个直接好处:
- 想看某一家的设定,直接进对应目录
- 方便你自己脚本批量处理,比如只分析
OpenAI/目录下的文件 - 为后续的自动化对比、可视化打下基础(比如统计不同厂商在"安全条款"上的差异)
3. 具有代表性的 Claude 系统提示词示例
仓库根目录下的 claude.txt 是整个项目里非常典型的一个例子。这个文件被外部分析认为是 Anthropic Claude 模型的系统提示词,长度超过 1000 行,体积约 110KB,并且与实际 Claude Sonnet 3.7 的行为在文案级别高度一致。
文件开头的内容就已经体现出它的"产品级"严谨:
如果回答依赖于
web_search、drive_search等工具的结果,就必须加上正确格式的引用标记......(意译)
在这类长系统提示里,你可以看到:
- 如何设计工具调用策略
- 如何规定引用、格式、代码块等细节
- 如何在安全合规 与用户体验之间做权衡
4. Git 仓库天然具备版本管理能力
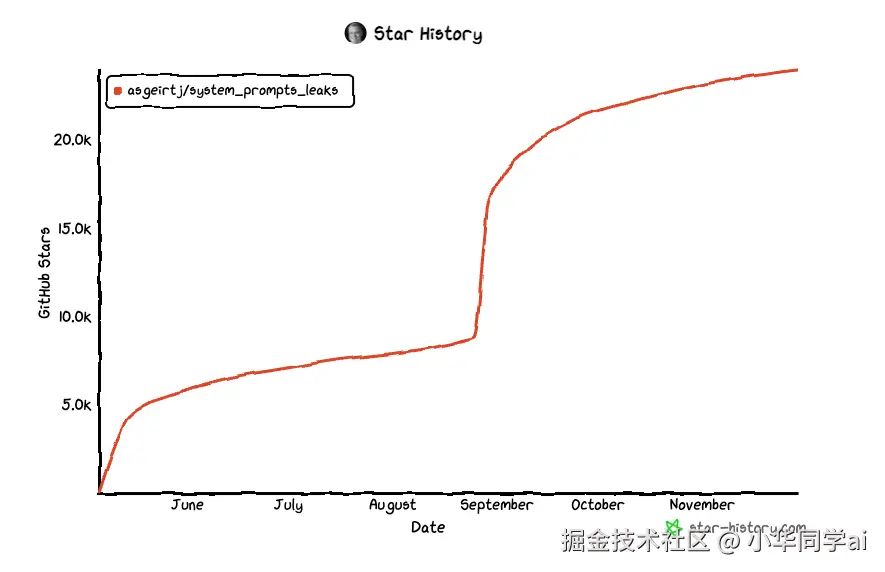
虽然 README 没有大篇幅介绍,但从仓库可以看到至少 200+ 次提交记录,这意味着它并非"一次性上传"后就不管了,而是一个持续更新、跟随模型演进的动态档案库。
对研究者和工程师来说,这给你带来一个额外 bonus:
- 你可以对比不同时间点的系统提示变化
- 用
git diff查看某一段安全条款是如何被加强或放宽的 - 甚至可以据此猜测厂商在不同阶段对产品的策略调整
5. Star History
技术架构
这个项目本身没有复杂的代码逻辑,本质上就是一个文本数据仓库。 但如果我们从"怎么用它"来倒推,可以把它看成下面这样的一个"小型架构":
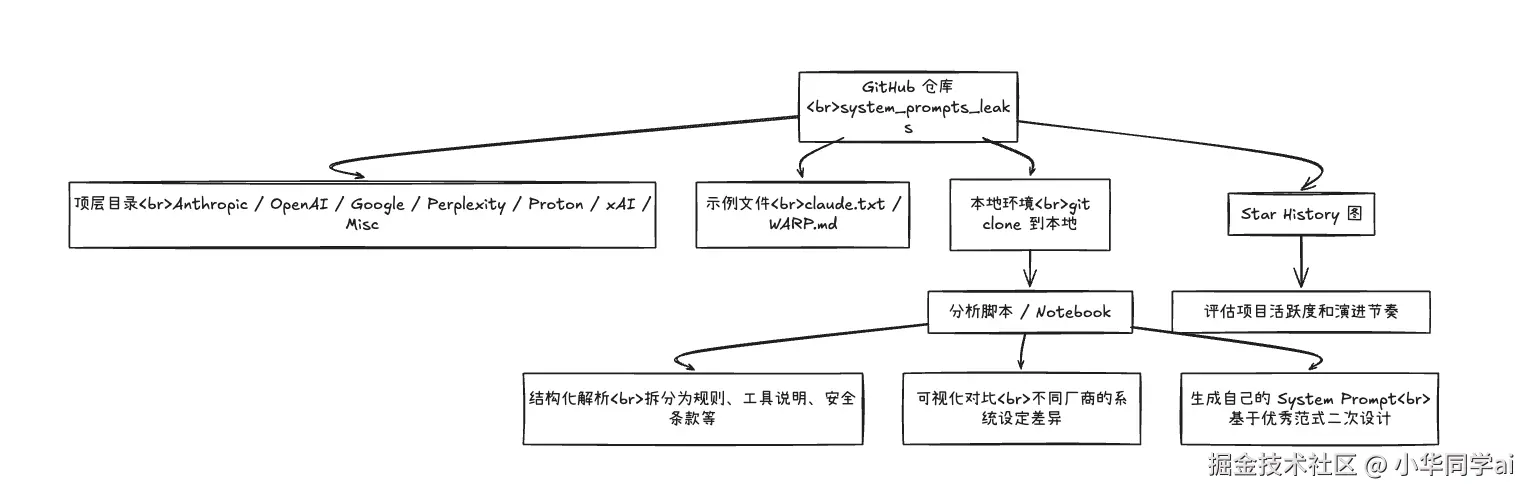
你可以把它理解成:
-
数据层:GitHub 仓库中的各个文本文件
-
处理层:你自己的 Python / Notebook / 脚本
-
应用层:
- 设计自己产品的 System Prompt
- 做安全审计、Prompt Leakage 风险评估
- 教学/内部分享,给非技术同事解释"大模型背后的那份说明书"
如何快速上手这些系统提示词?
下面给出三种非常实用、又容易上手的使用方式,你可以直接在自己的学习/工作流里照抄过去。
方式一:直接在线浏览,快速获取直觉
最简单的方式就是在线点开文本文件,比如:
- 仓库主页选择
claude.txt - 直接在浏览器里滚动阅读
- 用浏览器搜索(
Ctrl + F)关键词,如tool,citation,safety等,观察它在系统提示里是如何被描述和约束的
这一步可以帮你快速形成几个直觉:
- Claude 被要求如何使用工具与引用
- 系统提示会把哪些事情讲得特别细(比如输出格式)
- 哪些内容是在用户对话中永远看不到的"隐形规则"
方式二:本地克隆 + Python 分析
如果你更偏工程实践,推荐直接把仓库拉到本地,用 Python 做一点轻量分析。
bash
# 克隆仓库
git clone https://github.com/asgeirtj/system_prompts_leaks.git
cd system_prompts_leaks
# 查看顶层结构(示例输出)
ls
# Anthropic Google Misc OpenAI Perplexity Proton xAI WARP.md claude.txt readme.md然后用 Python 打开 claude.txt:
ini
from pathlib import Path
root = Path("system_prompts_leaks")
# 读取 Claude 的系统提示
claude_prompt = (root / "claude.txt").read_text(encoding="utf-8")
# 粗略看看前 40 行
for i, line in enumerate(claude_prompt.splitlines()[:40], start=1):
print(f"{i:02d}: {line}")再做一点简单的"词频"统计,看看系统提示里最常提到什么:
ini
keywords = ["tool", "citation", "safety", "assistant", "user", "system"]
lower_text = claude_prompt.lower()
for kw in keywords:
count = lower_text.count(kw)
print(f"{kw:10s}: {count}")你可以把这些统计结果做成表格或图表,用来:
- 对比不同模型在安全相关词汇上的密度
- 找出系统提示里最高频出现的行为要求
- 总结出一套可复用的"系统提示设计 checklist"
方式三:对照自己产品的 System Prompt 做"体检"
如果你所在团队已经有了自己的 AI 助手或 Agent,可以用一个非常简单的思路:
- 把你们自己的 system prompt 复制到一个文本文件,比如
my_product_prompt.txt。 - 从
system_prompts_leaks里选一份你最想参考的(例如某个 ChatGPT 或 Claude 的提示)。 - 用 diff 工具(
git diff、meld、VSCode 的对比功能等)进行并排对比。
你会很直观地看到:
- 大厂会用大量篇幅描述 "不该做什么" ,你的提示里是否缺失?
- 大厂会仔细规定工具调用策略(什么时候检索、什么时候用代码执行),你是否只是简单一句"你可以用搜索"?
- 在格式、引用、错误处理等细节上,你的提示是否"写得太随意"?
这种对比方式,非常适合拿来做团队内部分享或 code review 级别的"prompt review"。
应用场景
结合仓库内容和结构,它特别适合以下几类人群:
- Prompt 工程师 / AI 产品经理 想打造一个"像大厂一样专业"的 system prompt,而不是凭感觉堆几句话。
- AI 安全 / 红队 需要了解系统提示被泄露之后,攻击面长什么样,方便设计更有针对性的测试用例。
- 大模型课程讲师 / 技术博主 需要有真实案例,给学员或读者展示"系统提示到底有多长、多细致"。
- 正在自建 Agent 框架 / AI 平台的团队 需要一套"行业标杆"作为参考,避免完全从零发明轮子。
- 好奇心强的 AI 爱好者 想知道 ChatGPT、Claude、Gemini 到底是被如何"养成"现在这个性格的。
什么时候优先用 system_prompts_leaks?
目前围绕"系统提示词收集"的开源项目已经形成了一个小生态。和其中几款对比一下,更有利于你选型。
代表性同类项目
-
asgeirtj/system_prompts_leaks(本文主角)
- 定位:收集 ChatGPT、Claude、Gemini 等主流聊天机器人的系统提示词。
- 规模:23.9k⭐ Star、3.7k Fork。
-
jujumilk3/leaked-system-prompts
- 定位:收集各类 LLM 服务的泄露系统提示词。
- 规模:约 13.6k⭐ Star、1.9k Fork。
- 仓库内有大量按服务命名的 Markdown 文件,例如 Claude 3.x/4 系列、Cursor IDE、GitHub Copilot Chat、DeepSeek 等等。
-
x1xhlol/system-prompts-and-models-of-ai-tools
- 定位:更大规模的"系统提示 + 内部工具配置 + 模型信息"合集,覆盖 Cursor、Devin、Manus、Same.dev、Lovable、Replit Agent、Windsurf Agent、VSCode Agent、v0 等大量 AI 工具。
- 规模:约 98.5k⭐ Star、26.5k Fork。
- README 提到"Over 30,000+ lines of insights into their structure and functionality."
对比表:三大系统提示词仓库怎么选?
| 仓库 | Star 数(约) | 主要内容范围 | 结构特点 | 适合人群 |
|---|---|---|---|---|
asgeirtj/system_prompts_leaks |
23.9k⭐ | ChatGPT、Claude、Gemini 等主流聊天机器人系统提示词 | 按厂商分目录(Anthropic / OpenAI / Google / Perplexity / Proton / xAI / Misc),包含代表性示例如 claude.txt |
想专注研究对话式助手的整体行为与安全策略 |
jujumilk3/leaked-system-prompts |
13.6k⭐ | 各类 LLM 服务的泄露系统提示词,如 Claude、Cursor、GitHub Copilot、DeepSeek 等 | 文件以服务+版本命名,粒度更细,方便针对具体产品做分析 | 需要分析单一产品/工具(例如某个 IDE 插件或某个在线服务)的行为 |
x1xhlol/system-prompts-and-models-of-ai-tools |
98.5k⭐ | 大量 AI 工具的系统提示、内部工具配置和模型信息,行数超过 30,000 行 | 目录按工具划分(Cursor、Devin、Manus、Perplexity、v0 等),并附加了部分工程环境和模型信息 | 想系统性研究AI 工具生态、对 Agent 框架/Dev 工具有深入兴趣的开发者 |
如果你:
- 主要关注的是聊天机器人本身的行为和安全策略 → 首选
system_prompts_leaks - 想研究特定产品 (比如 Cursor、GitHub Copilot)的系统提示 → 可以配合
leaked-system-prompts使用 - 想从整体上理解各种 AI 工具/Agent 的 Prompt 设计模式 → 可再搭配
system-prompts-and-models-of-ai-tools,形成一个更大的"Prompt 知识图谱"
总结
回到我们最初的问题: "如何写出一份够专业的 system prompt,让自己的 AI 助手看起来不像玩具?"
asgeirtj/system_prompts_leaks 这个仓库,给了你一个非常务实的答案:
- 你可以亲眼看到大厂在真实产品中是怎么写 System Prompt 的;
- 你可以对比不同厂商在安全合规、工具调用、输出格式、用户体验上的取舍;
- 你可以用脚本把这些长文本拆成结构化信息,演化成自己团队的一套"System Prompt 设计规范";
- 你甚至可以把它当成一个"教材",在内部分享或公开课程中展示给更多人看。
它不是那种"点一下就能跑"的工具项目,而是一份实实在在的知识型资产------ 把原本藏在黑盒里的"底层设定",变成你可以阅读、研究、复用的文本。