
「机器学习」天池比赛:金融风控贷款违约预测

于 2021-03-29 20:46:23 发布
阅读量3.2w
收藏 610
点赞数 101
CC 4.0 BY-SA版权
分类专栏: 数据挖掘案例
【AI入门系列】金融守护者:金融风险预测学习赛_学习赛_天池大赛-阿里云天池的赛制
CSDN学习社区文章已被社区收录
加入社区
编辑数据挖掘案例专栏收录该内容
6 篇文章
订阅专栏
一、前言
1.1 赛题背景
赛题以金融风控中的个人信贷为背景,要求选手根据贷款申请人的数据信息预测其是否有违约的可能 ,以此判断是否通过此项贷款,这是一个典型的分类问题。
任务:预测用户贷款是否违约
比赛地址:【AI入门系列】金融守护者:金融风险预测学习赛_学习赛_天池大赛-阿里云天池的赛制
1.2 赛题数据
数据来自某信贷平台的贷款记录,总数据量超过120w,包含47列变量信息,其中15列为匿名变量。
为了保证比赛的公平性,将会从中抽取80万条作为训练集,20万条作为测试集A,20万条作为测试集B,同时会对employmentTitle、purpose、postCode和title等信息进行脱敏。
数据集包含三个下载文件
- train.csv:训练集
- test.csv:测试集
- sample_submit.csv:提交文件样式
字段表
| Field | Description |
|---|---|
| id | 为贷款清单分配的唯一信用证标识 |
| loanAmnt | 贷款金额 |
| term | 贷款期限(year) |
| interestRate | 贷款利率 |
| installment | 分期付款金额 |
| grade | 贷款等级 |
| subGrade | 贷款等级之子级 |
| employmentTitle | 就业职称 |
| employmentLength | 就业年限(年) |
| homeOwnership | 借款人在登记时提供的房屋所有权状况 |
| annualIncome | 年收入 |
| verificationStatus | 验证状态 |
| issueDate | 贷款发放的月份 |
| purpose | 借款人在贷款申请时的贷款用途类别 |
| postCode | 借款人在贷款申请中提供的邮政编码的前3位数字 |
| regionCode | 地区编码 |
| dti | 债务收入比 |
| delinquency_2years | 借款人过去2年信用档案中逾期30天以上的违约事件数 |
| ficoRangeLow | 借款人在贷款发放时的fico所属的下限范围 |
| ficoRangeHigh | 借款人在贷款发放时的fico所属的上限范围 |
| openAcc | 借款人信用档案中未结信用额度的数量 |
| pubRec | 贬损公共记录的数量 |
| pubRecBankruptcies | 公开记录清除的数量 |
| revolBal | 信贷周转余额合计 |
| revolUtil | 循环额度利用率,或借款人使用的相对于所有可用循环信贷的信贷金额 |
| totalAcc | 借款人信用档案中当前的信用额度总数 |
| initialListStatus | 贷款的初始列表状态 |
| applicationType | 表明贷款是个人申请还是与两个共同借款人的联合申请 |
| earliesCreditLine | 借款人最早报告的信用额度开立的月份 |
| title | 借款人提供的贷款名称 |
| policyCode | 公开可用的策略_代码=1新产品不公开可用的策略_代码=2 |
| n系列匿名特征 | 匿名特征n0-n14,为一些贷款人行为计数特征的处理 |
1.3 评价指标
提交结果为每个测试样本是1的概率,也就是y为1的概率。
评价方法为AUC评估模型效果(越大越好)。
注:AUC(Area Under Curve)被定义为 ROC曲线下与坐标轴围成的面积。
详细参见:
「机器学习」分类算法常见的评估指标
机器学习:评估指标
其次,除了要求的评价指标外,对于二分类问题其评价指标还有精确率、召回率、ROC、F值等
1.4 赛题整体流程
分析主要步骤如下
二、探索性的数据分析EDA
数据探索性分析是对数据进行初步分析,了解数据特征,观察数据类型,分析数据分布等等,为后续特征工程,以及建模分析都特别重要
例如
- 分析数据中每个字段的含义、分布、缺失情况;
字段表示什么含义、字段的类型是什么、字段的取值空间是什么、字段每个取值表示什么意义。
字段整体的分布,分析字段在训练集/测试集中的分布情况。
字段缺失值的分布比例,字段在训练集/测试集的缺失情况。 - 分析数据中每个字段的与赛题标签的关系;
- 分析数据字段两两之间,或者主者之间的关系;
引用图片:https://zhuanlan.zhihu.com/p/259788410
首先导入必要模块
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#0077aa">import</span> warnings
warnings<span style="color:#999999">.</span>filterwarnings<span style="color:#999999">(</span><span style="color:#50a14f">"ignore"</span><span style="color:#999999">)</span>
<span style="color:#0077aa">import</span> numpy <span style="color:#0077aa">as</span> np
<span style="color:#0077aa">import</span> pandas <span style="color:#0077aa">as</span> pd
<span style="color:#0077aa">import</span> seaborn <span style="color:#0077aa">as</span> sns
<span style="color:#0077aa">import</span> matplotlib<span style="color:#999999">.</span>pyplot <span style="color:#0077aa">as</span> plt
<span style="color:#0077aa">import</span> statsmodels<span style="color:#999999">.</span>formula<span style="color:#999999">.</span>api <span style="color:#0077aa">as</span> smf
<span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>preprocessing <span style="color:#0077aa">import</span> LabelEncoder
<span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>feature_selection <span style="color:#0077aa">import</span> SelectKBest
<span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>model_selection <span style="color:#0077aa">import</span> train_test_split
<span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>model_selection <span style="color:#0077aa">import</span> StratifiedKFold<span style="color:#999999">,</span> KFold
<span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>feature_selection <span style="color:#0077aa">import</span> SelectKBest
<span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>feature_selection <span style="color:#0077aa">import</span> chi2
<span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>preprocessing <span style="color:#0077aa">import</span> MinMaxScaler
<span style="color:#0077aa">import</span> xgboost <span style="color:#0077aa">as</span> xgb
<span style="color:#0077aa">import</span> lightgbm <span style="color:#0077aa">as</span> lgb
<span style="color:#0077aa">from</span> catboost <span style="color:#0077aa">import</span> CatBoostRegressor
<span style="color:#708090"># 评价指标</span>
<span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>metrics <span style="color:#0077aa">import</span> accuracy_score<span style="color:#999999">,</span> f1_score<span style="color:#999999">,</span> roc_auc_score<span style="color:#999999">,</span> log_loss
plt<span style="color:#999999">.</span>rcParams<span style="color:#999999">[</span><span style="color:#50a14f">"font.sans-serif"</span><span style="color:#999999">]</span><span style="color:#a67f59">=</span><span style="color:#999999">[</span><span style="color:#50a14f">"SimHei"</span><span style="color:#999999">]</span>
plt<span style="color:#999999">.</span>rcParams<span style="color:#999999">[</span><span style="color:#50a14f">"axes.unicode_minus"</span><span style="color:#999999">]</span><span style="color:#a67f59">=</span><span style="color:#0184bb">False</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
使用pandas读入数据,包括训练集与测试集
导入数据集(数据集过大可以进行瘦身处理)
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-py">train <span style="color:#a67f59">=</span> pd<span style="color:#999999">.</span>read_csv<span style="color:#999999">(</span><span style="color:#50a14f">'train.csv'</span><span style="color:#999999">)</span>
test <span style="color:#a67f59">=</span> pd<span style="color:#999999">.</span>read_csv<span style="color:#999999">(</span><span style="color:#50a14f">'testA.csv'</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码py
- 1
- 2
查看部分数据
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">.</span>head<span style="color:#999999">(</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
| id | loanAmnt | term | interestRate | installment | grade | subGrade | employmentTitle | employmentLength | homeOwnership | ... | n5 | n6 | n7 | n8 | n9 | n10 | n11 | n12 | n13 | n14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 35000.0 | 5 | 19.52 | 917.97 | E | E2 | 320.0 | 2 years | 2 | ... | 9.0 | 8.0 | 4.0 | 12.0 | 2.0 | 7.0 | 0.0 | 0.0 | 0.0 | 2.0 |
| 1 | 1 | 18000.0 | 5 | 18.49 | 461.90 | D | D2 | 219843.0 | 5 years | 0 | ... | NaN | NaN | NaN | NaN | NaN | 13.0 | NaN | NaN | NaN | NaN |
| 2 | 2 | 12000.0 | 5 | 16.99 | 298.17 | D | D3 | 31698.0 | 8 years | 0 | ... | 0.0 | 21.0 | 4.0 | 5.0 | 3.0 | 11.0 | 0.0 | 0.0 | 0.0 | 4.0 |
| 3 | 3 | 11000.0 | 3 | 7.26 | 340.96 | A | A4 | 46854.0 | 10+ years | 1 | ... | 16.0 | 4.0 | 7.0 | 21.0 | 6.0 | 9.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 4 | 4 | 3000.0 | 3 | 12.99 | 101.07 | C | C2 | 54.0 | NaN | 1 | ... | 4.0 | 9.0 | 10.0 | 15.0 | 7.0 | 12.0 | 0.0 | 0.0 | 0.0 | 4.0 |
5 rows × 47 columns
2.1 总体分布
前面提到,整个数据包括80万条训练集,20万条测试集A,20万条测试集B
另外
训练集中有47列,其中包括46个特征列,1个标签列
测试集中只有46个特征列
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-py"><span style="color:#708090"># 样本个数和特征维度</span>
train<span style="color:#999999">.</span>shape
<span style="color:#708090"># (800000, 47)</span>
test<span style="color:#999999">.</span>shape
<span style="color:#708090"># (200000, 46)</span>
</code></span></span></span></span>AI写代码py
- 1
- 2
- 3
- 4
- 5
查看特征名
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">.</span>columns
<span style="color:#50a14f">'''
Index(['id', 'loanAmnt', 'term', 'interestRate', 'installment', 'grade',
'subGrade', 'employmentTitle', 'employmentLength', 'homeOwnership',
'annualIncome', 'verificationStatus', 'issueDate', 'isDefault',
'purpose', 'postCode', 'regionCode', 'dti', 'delinquency_2years',
'ficoRangeLow', 'ficoRangeHigh', 'openAcc', 'pubRec',
'pubRecBankruptcies', 'revolBal', 'revolUtil', 'totalAcc',
'initialListStatus', 'applicationType', 'earliesCreditLine', 'title',
'policyCode', 'n0', 'n1', 'n2', 'n3', 'n4', 'n5', 'n6', 'n7', 'n8',
'n9', 'n10', 'n11', 'n12', 'n13', 'n14'],
dtype='object')
'''</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
接下来查看数据集的一些基本信息(缺失情况、类型...)
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">.</span>info<span style="color:#999999">(</span><span style="color:#999999">)</span>
<span style="color:#50a14f">'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 800000 entries, 0 to 799999
Data columns (total 47 columns):
id 800000 non-null int64
loanAmnt 800000 non-null float64
term 800000 non-null int64
interestRate 800000 non-null float64
installment 800000 non-null float64
grade 800000 non-null object
subGrade 800000 non-null object
employmentTitle 799999 non-null float64
employmentLength 753201 non-null object
homeOwnership 800000 non-null int64
annualIncome 800000 non-null float64
verificationStatus 800000 non-null int64
issueDate 800000 non-null object
isDefault 800000 non-null int64
purpose 800000 non-null int64
postCode 799999 non-null float64
regionCode 800000 non-null int64
dti 799761 non-null float64
delinquency_2years 800000 non-null float64
ficoRangeLow 800000 non-null float64
ficoRangeHigh 800000 non-null float64
openAcc 800000 non-null float64
pubRec 800000 non-null float64
pubRecBankruptcies 799595 non-null float64
revolBal 800000 non-null float64
revolUtil 799469 non-null float64
totalAcc 800000 non-null float64
initialListStatus 800000 non-null int64
applicationType 800000 non-null int64
earliesCreditLine 800000 non-null object
title 799999 non-null float64
policyCode 800000 non-null float64
n0 759730 non-null float64
n1 759730 non-null float64
n2 759730 non-null float64
n3 759730 non-null float64
n4 766761 non-null float64
n5 759730 non-null float64
n6 759730 non-null float64
n7 759730 non-null float64
n8 759729 non-null float64
n9 759730 non-null float64
n10 766761 non-null float64
n11 730248 non-null float64
n12 759730 non-null float64
n13 759730 non-null float64
n14 759730 non-null float64
dtypes: float64(33), int64(9), object(5)
memory usage: 286.9+ MB
'''</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
可以看到,许多特征存在缺失,特征的类型有dtypes: float64(33), int64(9), object(5)
对于缺失值的处理以及类型转换将在特征工程中说明
接下来查看一下数据的描述性分析
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">描述性统计
加深对数据分布、数据结构等的理解
看一下数据特征之间的两两关联关系
数据中空值的个数、<span style="color:#986801">0</span>的个数、正值或负值的个数,
以及均值、方差、最小值、最大值、偏度、峰度等。
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">.</span>describe<span style="color:#999999">(</span><span style="color:#999999">)</span>
<span style="color:#708090"># train.describe().T</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
大致了解一下数据的分布、结构,简单的看一下特征值有没有什么异常
| id | loanAmnt | term | interestRate | installment | employmentTitle | homeOwnership | annualIncome | verificationStatus | isDefault | ... | n5 | n6 | n7 | n8 | n9 | n10 | n11 | n12 | n13 | n14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 800000.000000 | 800000.000000 | 800000.000000 | 800000.000000 | 800000.000000 | 799999.000000 | 800000.000000 | 8.000000e+05 | 800000.000000 | 800000.000000 | ... | 759730.000000 | 759730.000000 | 759730.000000 | 759729.000000 | 759730.000000 | 766761.000000 | 730248.000000 | 759730.000000 | 759730.000000 | 759730.000000 |
| mean | 399999.500000 | 14416.818875 | 3.482745 | 13.238391 | 437.947723 | 72005.351714 | 0.614213 | 7.613391e+04 | 1.009683 | 0.199513 | ... | 8.107937 | 8.575994 | 8.282953 | 14.622488 | 5.592345 | 11.643896 | 0.000815 | 0.003384 | 0.089366 | 2.178606 |
| std | 230940.252015 | 8716.086178 | 0.855832 | 4.765757 | 261.460393 | 106585.640204 | 0.675749 | 6.894751e+04 | 0.782716 | 0.399634 | ... | 4.799210 | 7.400536 | 4.561689 | 8.124610 | 3.216184 | 5.484104 | 0.030075 | 0.062041 | 0.509069 | 1.844377 |
| min | 0.000000 | 500.000000 | 3.000000 | 5.310000 | 15.690000 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 199999.750000 | 8000.000000 | 3.000000 | 9.750000 | 248.450000 | 427.000000 | 0.000000 | 4.560000e+04 | 0.000000 | 0.000000 | ... | 5.000000 | 4.000000 | 5.000000 | 9.000000 | 3.000000 | 8.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 |
| 50% | 399999.500000 | 12000.000000 | 3.000000 | 12.740000 | 375.135000 | 7755.000000 | 1.000000 | 6.500000e+04 | 1.000000 | 0.000000 | ... | 7.000000 | 7.000000 | 7.000000 | 13.000000 | 5.000000 | 11.000000 | 0.000000 | 0.000000 | 0.000000 | 2.000000 |
| 75% | 599999.250000 | 20000.000000 | 3.000000 | 15.990000 | 580.710000 | 117663.500000 | 1.000000 | 9.000000e+04 | 2.000000 | 0.000000 | ... | 11.000000 | 11.000000 | 10.000000 | 19.000000 | 7.000000 | 14.000000 | 0.000000 | 0.000000 | 0.000000 | 3.000000 |
| max | 799999.000000 | 40000.000000 | 5.000000 | 30.990000 | 1715.420000 | 378351.000000 | 5.000000 | 1.099920e+07 | 2.000000 | 1.000000 | ... | 70.000000 | 132.000000 | 79.000000 | 128.000000 | 45.000000 | 82.000000 | 4.000000 | 4.000000 | 39.000000 | 30.000000 |
2.2 数据类型分析
2.2.1 数值类型(连续变量、离散型变量和单值变量)
这里引用文章观点:https://blog.csdn.net/qq_43401035/article/details/108648912

数值类型
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#708090"># 数值类型</span>
numerical_feature <span style="color:#a67f59">=</span> <span style="color:#50a14f">list</span><span style="color:#999999">(</span>train<span style="color:#999999">.</span>select_dtypes<span style="color:#999999">(</span>exclude<span style="color:#a67f59">=</span><span style="color:#999999">[</span><span style="color:#50a14f">'object'</span><span style="color:#999999">]</span><span style="color:#999999">)</span><span style="color:#999999">.</span>columns<span style="color:#999999">)</span>
numerical_feature
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#999999">[</span><span style="color:#50a14f">'id'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'loanAmnt'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'term'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'interestRate'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'installment'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'employmentTitle'</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'homeOwnership'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'annualIncome'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'verificationStatus'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'isDefault'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'purpose'</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'postCode'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'regionCode'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'dti'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'delinquency_2years'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'ficoRangeLow'</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'ficoRangeHigh'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'openAcc'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'pubRec'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'pubRecBankruptcies'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'revolBal'</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'revolUtil'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'totalAcc'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'initialListStatus'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'applicationType'</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'title'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'policyCode'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'n0'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'n1'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'n2'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'n3'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'n4'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'n5'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'n6'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'n7'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'n8'</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'n9'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'n10'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'n11'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'n12'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'n13'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'n14'</span><span style="color:#999999">]</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
一共有42个数值型变量(dtypes: float64(33), int64(9), object(5))
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#50a14f">len</span><span style="color:#999999">(</span>numerical_feature<span style="color:#999999">)</span> <span style="color:#708090">## 42</span>
</code></span></span></span></span>AI写代码python
运行
- 1
由于数值类型又可以分为连续变量、离散型变量和单值变量
因此接下来把数值型中的连续型变量和离散型变量区分开来:
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#708090"># 连续型变量</span>
serial_feature <span style="color:#a67f59">=</span> <span style="color:#999999">[</span><span style="color:#999999">]</span>
<span style="color:#708090"># 离散型变量</span>
discrete_feature <span style="color:#a67f59">=</span> <span style="color:#999999">[</span><span style="color:#999999">]</span>
<span style="color:#708090"># 单值变量</span>
unique_feature <span style="color:#a67f59">=</span> <span style="color:#999999">[</span><span style="color:#999999">]</span>
<span style="color:#0077aa">for</span> fea <span style="color:#0077aa">in</span> numerical_feature<span style="color:#999999">:</span>
temp <span style="color:#a67f59">=</span> train<span style="color:#999999">[</span>fea<span style="color:#999999">]</span><span style="color:#999999">.</span>nunique<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#708090"># 返回的是唯一值的个数</span>
<span style="color:#0077aa">if</span> temp <span style="color:#a67f59">==</span> <span style="color:#986801">1</span><span style="color:#999999">:</span>
unique_feature<span style="color:#999999">.</span>append<span style="color:#999999">(</span>fea<span style="color:#999999">)</span>
<span style="color:#708090"># 自定义变量的值的取值个数小于10就为离散型变量 </span>
<span style="color:#0077aa">elif</span> temp <span style="color:#a67f59"><=</span> <span style="color:#986801">10</span><span style="color:#999999">:</span>
discrete_feature<span style="color:#999999">.</span>append<span style="color:#999999">(</span>fea<span style="color:#999999">)</span>
<span style="color:#0077aa">else</span><span style="color:#999999">:</span>
serial_feature<span style="color:#999999">.</span>append<span style="color:#999999">(</span>fea<span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
(1)连续型变量
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-py">serial_feature
<span style="color:#50a14f">'''
['id', 'loanAmnt', 'interestRate', 'installment', 'employmentTitle',
'annualIncome', 'purpose', 'postCode', 'regionCode', 'dti',
'delinquency_2years', 'ficoRangeLow', 'ficoRangeHigh', 'openAcc',
'pubRec', 'pubRecBankruptcies', 'revolBal', 'revolUtil', 'totalAcc',
'title', 'n0', 'n1', 'n2', 'n3', 'n4', 'n5', 'n6', 'n7', 'n8',
'n9', 'n10', 'n13', 'n14']
'''</span>
</code></span></span></span></span>AI写代码py
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
对于连续型变量
-
查看某一个数值型变量的分布,查看变量是否符合正态分布,如果不符合正太分布的变量可以log化后再观察下是否符合正态分布。
-
正态化的原因:一些情况下正态非正态可以让模型更快的收敛,一些模型要求数据正态(eg. GMM、KNN),保证数据不要过偏态即可,过于偏态可能会影响模型预测结果。
可视化呈现
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#708090">#每个数字特征得分布可视化</span>
f <span style="color:#a67f59">=</span> pd<span style="color:#999999">.</span>melt<span style="color:#999999">(</span>train<span style="color:#999999">,</span> value_vars<span style="color:#a67f59">=</span>serial_feature<span style="color:#999999">)</span>
g <span style="color:#a67f59">=</span> sns<span style="color:#999999">.</span>FacetGrid<span style="color:#999999">(</span>f<span style="color:#999999">,</span> col<span style="color:#a67f59">=</span><span style="color:#50a14f">"variable"</span><span style="color:#999999">,</span> col_wrap<span style="color:#a67f59">=</span><span style="color:#986801">3</span><span style="color:#999999">,</span> sharex<span style="color:#a67f59">=</span><span style="color:#0184bb">False</span><span style="color:#999999">,</span> sharey<span style="color:#a67f59">=</span><span style="color:#0184bb">False</span><span style="color:#999999">)</span>
g <span style="color:#a67f59">=</span> g<span style="color:#999999">.</span><span style="color:#50a14f">map</span><span style="color:#999999">(</span>sns<span style="color:#999999">.</span>distplot<span style="color:#999999">,</span> <span style="color:#50a14f">"value"</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
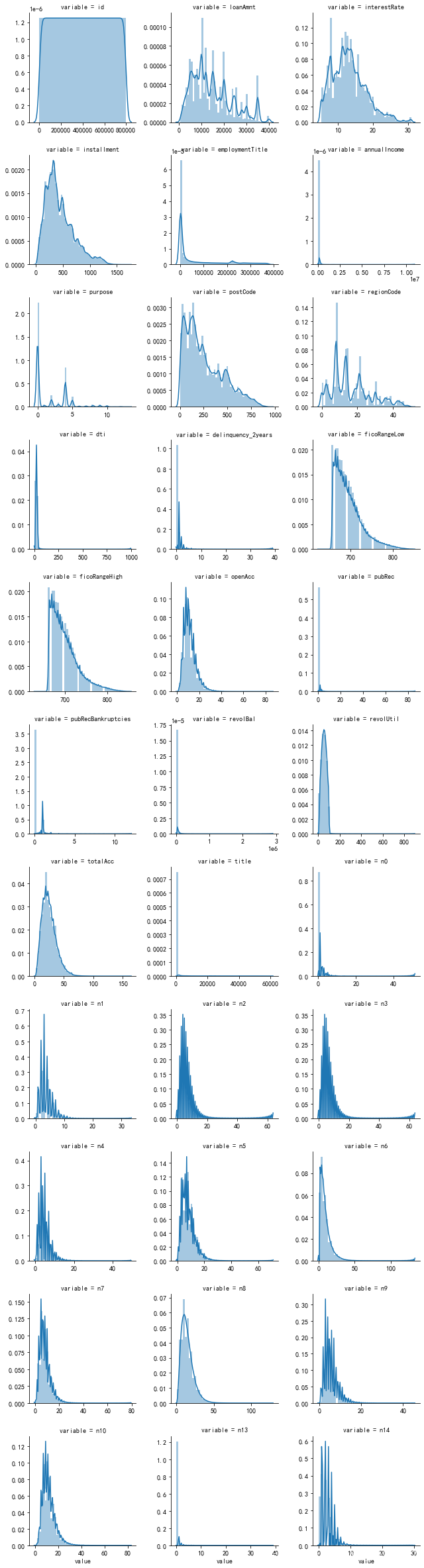
可以单独查看一下贷款金额 loanAmnt 的分布情况
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-sql">plt<span style="color:#999999">.</span>figure<span style="color:#999999">(</span><span style="color:#986801">1</span> <span style="color:#999999">,</span> figsize <span style="color:#a67f59">=</span> <span style="color:#999999">(</span><span style="color:#986801">8</span> <span style="color:#999999">,</span> <span style="color:#986801">5</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
sns<span style="color:#999999">.</span>distplot<span style="color:#999999">(</span>train<span style="color:#999999">.</span>loanAmnt<span style="color:#999999">,</span>bins<span style="color:#a67f59">=</span><span style="color:#986801">40</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>xlabel<span style="color:#999999">(</span><span style="color:#50a14f">'loanAmnt'</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码sql
- 1
- 2
- 3
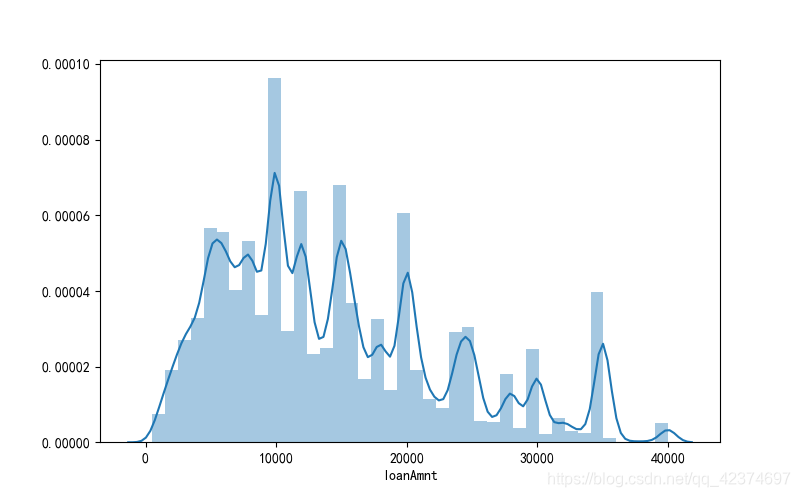
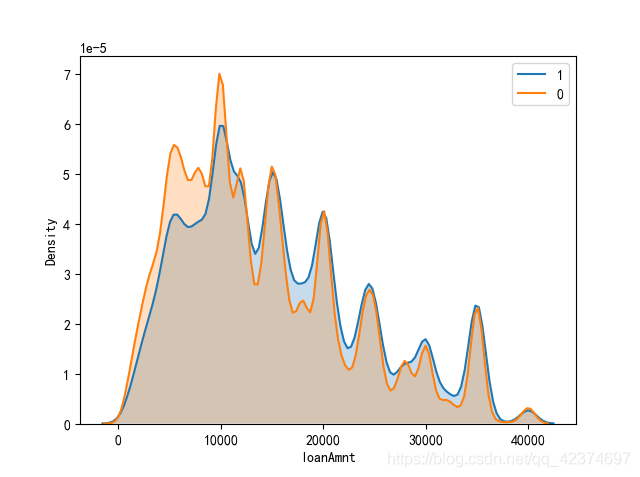
对于违约与不违约两类样本的贷款金额分布情况
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">sns<span style="color:#999999">.</span>kdeplot<span style="color:#999999">(</span>train<span style="color:#999999">.</span>loanAmnt<span style="color:#999999">[</span>label<span style="color:#999999">[</span>label<span style="color:#a67f59">==</span><span style="color:#986801">1</span><span style="color:#999999">]</span><span style="color:#999999">.</span>index<span style="color:#999999">]</span><span style="color:#999999">,</span> label<span style="color:#a67f59">=</span><span style="color:#50a14f">'1'</span><span style="color:#999999">,</span> shade<span style="color:#a67f59">=</span><span style="color:#0184bb">True</span><span style="color:#999999">)</span><span style="color:#708090">#违约</span>
sns<span style="color:#999999">.</span>kdeplot<span style="color:#999999">(</span>train<span style="color:#999999">.</span>loanAmnt<span style="color:#999999">[</span>label<span style="color:#999999">[</span>label<span style="color:#a67f59">==</span><span style="color:#986801">0</span><span style="color:#999999">]</span><span style="color:#999999">.</span>index<span style="color:#999999">]</span><span style="color:#999999">,</span> label<span style="color:#a67f59">=</span><span style="color:#50a14f">'0'</span><span style="color:#999999">,</span> shade<span style="color:#a67f59">=</span><span style="color:#0184bb">True</span><span style="color:#999999">)</span><span style="color:#708090">#没有违约</span>
plt<span style="color:#999999">.</span>xlabel<span style="color:#999999">(</span><span style="color:#50a14f">'loanAmnt'</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>ylabel<span style="color:#999999">(</span><span style="color:#50a14f">'Density'</span><span style="color:#999999">)</span><span style="color:#999999">;</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
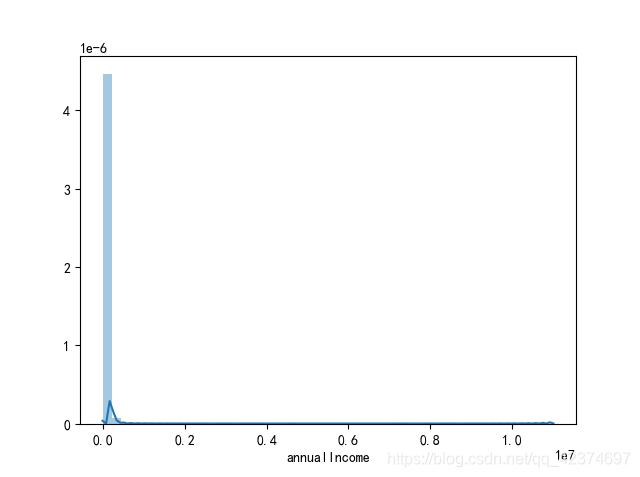
单独查看一下年收入的分布情况
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">plt<span style="color:#999999">.</span>figure<span style="color:#999999">(</span><span style="color:#986801">1</span> <span style="color:#999999">,</span> figsize <span style="color:#a67f59">=</span> <span style="color:#999999">(</span><span style="color:#986801">8</span> <span style="color:#999999">,</span> <span style="color:#986801">5</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
sns<span style="color:#999999">.</span>distplot<span style="color:#999999">(</span>train<span style="color:#999999">[</span><span style="color:#50a14f">'annualIncome'</span><span style="color:#999999">]</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>xlabel<span style="color:#999999">(</span><span style="color:#50a14f">'annualIncome'</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
(2)离散型变量
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-py">discrete_feature
<span style="color:#50a14f">'''
['term', 'homeOwnership', 'verificationStatus', 'isDefault',
'initialListStatus', 'applicationType', 'n11', 'n12']
'''</span>
</code></span></span></span></span>AI写代码py
- 1
- 2
- 3
- 4
- 5
离散型变量的类型数情况
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-sql"><span style="color:#0077aa">for</span> f <span style="color:#a67f59">in</span> discrete_feature:
<span style="color:#0077aa">print</span><span style="color:#999999">(</span>f<span style="color:#999999">,</span> <span style="color:#50a14f">'类型数:'</span><span style="color:#999999">,</span> train<span style="color:#999999">[</span>f<span style="color:#999999">]</span><span style="color:#999999">.</span>nunique<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
<span style="color:#50a14f">''</span><span style="color:#50a14f">'
term 类型数: 2
homeOwnership 类型数: 6
verificationStatus 类型数: 3
isDefault 类型数: 2
initialListStatus 类型数: 2
applicationType 类型数: 2
n11 类型数: 5
n12 类型数: 5
'</span><span style="color:#50a14f">''</span>
</code></span></span></span></span>AI写代码sql
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
离散型特征可视化呈现
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">df_ <span style="color:#a67f59">=</span> train<span style="color:#999999">[</span>discrete_feature<span style="color:#999999">]</span>
sns<span style="color:#999999">.</span>set_style<span style="color:#999999">(</span><span style="color:#50a14f">"whitegrid"</span><span style="color:#999999">)</span> <span style="color:#708090"># 使用whitegrid主题</span>
fig<span style="color:#999999">,</span>axes<span style="color:#a67f59">=</span>plt<span style="color:#999999">.</span>subplots<span style="color:#999999">(</span>nrows<span style="color:#a67f59">=</span><span style="color:#986801">4</span><span style="color:#999999">,</span>ncols<span style="color:#a67f59">=</span><span style="color:#986801">2</span><span style="color:#999999">,</span>figsize<span style="color:#a67f59">=</span><span style="color:#999999">(</span><span style="color:#986801">8</span><span style="color:#999999">,</span><span style="color:#986801">10</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
<span style="color:#0077aa">for</span> i<span style="color:#999999">,</span> item <span style="color:#0077aa">in</span> <span style="color:#50a14f">enumerate</span><span style="color:#999999">(</span>df_<span style="color:#999999">)</span><span style="color:#999999">:</span>
plt<span style="color:#999999">.</span>subplot<span style="color:#999999">(</span><span style="color:#986801">4</span><span style="color:#999999">,</span><span style="color:#986801">2</span><span style="color:#999999">,</span><span style="color:#999999">(</span>i<span style="color:#a67f59">+</span><span style="color:#986801">1</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
<span style="color:#708090">#ax=df[item].value_counts().plot(kind = 'bar')</span>
ax<span style="color:#a67f59">=</span>sns<span style="color:#999999">.</span>countplot<span style="color:#999999">(</span>item<span style="color:#999999">,</span>data <span style="color:#a67f59">=</span> df_<span style="color:#999999">,</span>palette<span style="color:#a67f59">=</span><span style="color:#50a14f">"Pastel1"</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>xlabel<span style="color:#999999">(</span><span style="color:#50a14f">str</span><span style="color:#999999">(</span>item<span style="color:#999999">)</span><span style="color:#999999">,</span>fontsize<span style="color:#a67f59">=</span><span style="color:#986801">14</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>ylabel<span style="color:#999999">(</span><span style="color:#50a14f">'Count'</span><span style="color:#999999">,</span>fontsize<span style="color:#a67f59">=</span><span style="color:#986801">14</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>xticks<span style="color:#999999">(</span>fontsize<span style="color:#a67f59">=</span><span style="color:#986801">13</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>yticks<span style="color:#999999">(</span>fontsize<span style="color:#a67f59">=</span><span style="color:#986801">13</span><span style="color:#999999">)</span>
<span style="color:#708090">#plt.title("Churn by "+ str(item))</span>
i<span style="color:#a67f59">=</span>i<span style="color:#a67f59">+</span><span style="color:#986801">1</span>
plt<span style="color:#999999">.</span>tight_layout<span style="color:#999999">(</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>show<span style="color:#999999">(</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
查看一下每个特征的分布情况
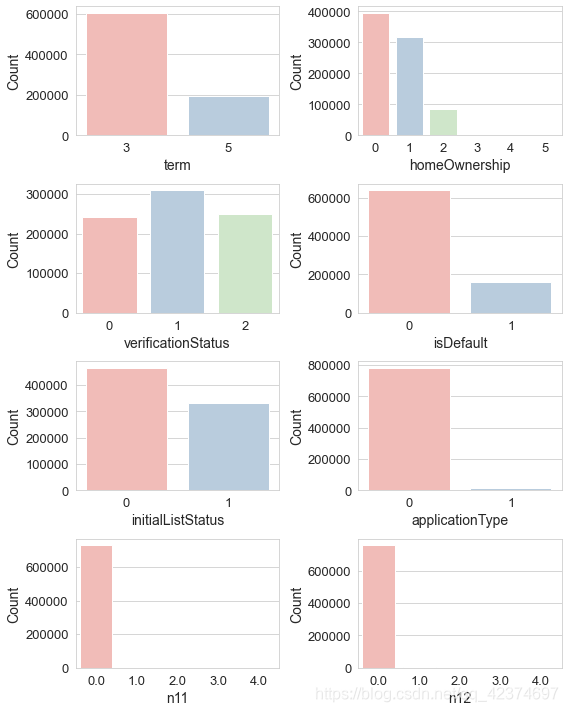
(3)单值变量
单值变量表示该特征只有一种类别,对于数值全部都一样的特征,可以考虑直接删除
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-py">unique_feature
<span style="color:#50a14f">'''
['policyCode']
'''</span>
</code></span></span></span></span>AI写代码py
- 1
- 2
- 3
- 4
2.2.2 分类型特征
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#708090"># 分类型特征</span>
category_feature <span style="color:#a67f59">=</span> <span style="color:#50a14f">list</span><span style="color:#999999">(</span><span style="color:#50a14f">filter</span><span style="color:#999999">(</span><span style="color:#0077aa">lambda</span> x<span style="color:#999999">:</span> x <span style="color:#a67f59">not</span> <span style="color:#0077aa">in</span> numerical_feature<span style="color:#999999">,</span><span style="color:#50a14f">list</span><span style="color:#999999">(</span>train<span style="color:#999999">.</span>columns<span style="color:#999999">)</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
category_feature
<span style="color:#999999">[</span><span style="color:#50a14f">'grade'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'subGrade'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'employmentLength'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'issueDate'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'earliesCreditLine'</span><span style="color:#999999">]</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
对应info结果中的 (dtypes: float64(33), int64(9), object(5))
这里 "grade"为贷款等级,"subGrade"为贷款等级之子级,"employmentLength"为就业年限,"issueDate"为贷款发放的月份,"earliesCreditLine"为借款人最早报告的信用额度开立的月份,共有5个分类型特征。
查看一下这些分类型特征的结构,后面需要对其进行特征编码
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">[</span>category_feature<span style="color:#999999">]</span>
<span style="color:#50a14f">'''
grade subGrade employmentLength issueDate earliesCreditLine
0 E E2 2 years 2014-07-01 Aug-2001
1 D D2 5 years 2012-08-01 May-2002
2 D D3 8 years 2015-10-01 May-2006
3 A A4 10+ years 2015-08-01 May-1999
4 C C2 NaN 2016-03-01 Aug-1977
... ... ... ... ...
799995 C C4 7 years 2016-07-01 Aug-2011
799996 A A4 10+ years 2013-04-01 May-1989
799997 C C3 10+ years 2015-10-01 Jul-2002
799998 A A4 10+ years 2015-02-01 Jan-1994
799999 B B3 5 years 2018-08-01 Feb-2002
[800000 rows x 5 columns]
'''</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
分类型特征可视化呈现
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">df_category <span style="color:#a67f59">=</span> train<span style="color:#999999">[</span><span style="color:#999999">[</span><span style="color:#50a14f">'grade'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'subGrade'</span><span style="color:#999999">]</span><span style="color:#999999">]</span>
sns<span style="color:#999999">.</span>set_style<span style="color:#999999">(</span><span style="color:#50a14f">"whitegrid"</span><span style="color:#999999">)</span> <span style="color:#708090"># 使用whitegrid主题</span>
color <span style="color:#a67f59">=</span> sns<span style="color:#999999">.</span>color_palette<span style="color:#999999">(</span><span style="color:#999999">)</span>
fig<span style="color:#999999">,</span>axes<span style="color:#a67f59">=</span>plt<span style="color:#999999">.</span>subplots<span style="color:#999999">(</span>nrows<span style="color:#a67f59">=</span><span style="color:#986801">2</span><span style="color:#999999">,</span>ncols<span style="color:#a67f59">=</span><span style="color:#986801">1</span><span style="color:#999999">,</span>figsize<span style="color:#a67f59">=</span><span style="color:#999999">(</span><span style="color:#986801">10</span><span style="color:#999999">,</span><span style="color:#986801">10</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
<span style="color:#0077aa">for</span> i<span style="color:#999999">,</span> item <span style="color:#0077aa">in</span> <span style="color:#50a14f">enumerate</span><span style="color:#999999">(</span>df_category<span style="color:#999999">)</span><span style="color:#999999">:</span>
plt<span style="color:#999999">.</span>subplot<span style="color:#999999">(</span><span style="color:#986801">2</span><span style="color:#999999">,</span><span style="color:#986801">1</span><span style="color:#999999">,</span><span style="color:#999999">(</span>i<span style="color:#a67f59">+</span><span style="color:#986801">1</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
<span style="color:#708090">#ax=df[item].value_counts().plot(kind = 'bar')</span>
ax<span style="color:#a67f59">=</span>sns<span style="color:#999999">.</span>countplot<span style="color:#999999">(</span>item<span style="color:#999999">,</span>data <span style="color:#a67f59">=</span> df_category<span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>xlabel<span style="color:#999999">(</span><span style="color:#50a14f">str</span><span style="color:#999999">(</span>item<span style="color:#999999">)</span><span style="color:#999999">,</span>fontsize<span style="color:#a67f59">=</span><span style="color:#986801">14</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>ylabel<span style="color:#999999">(</span><span style="color:#50a14f">'Count'</span><span style="color:#999999">,</span>fontsize<span style="color:#a67f59">=</span><span style="color:#986801">14</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>xticks<span style="color:#999999">(</span>fontsize<span style="color:#a67f59">=</span><span style="color:#986801">13</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>yticks<span style="color:#999999">(</span>fontsize<span style="color:#a67f59">=</span><span style="color:#986801">13</span><span style="color:#999999">)</span>
<span style="color:#708090">#plt.title("Churn by "+ str(item))</span>
i<span style="color:#a67f59">=</span>i<span style="color:#a67f59">+</span><span style="color:#986801">1</span>
plt<span style="color:#999999">.</span>tight_layout<span style="color:#999999">(</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>show<span style="color:#999999">(</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
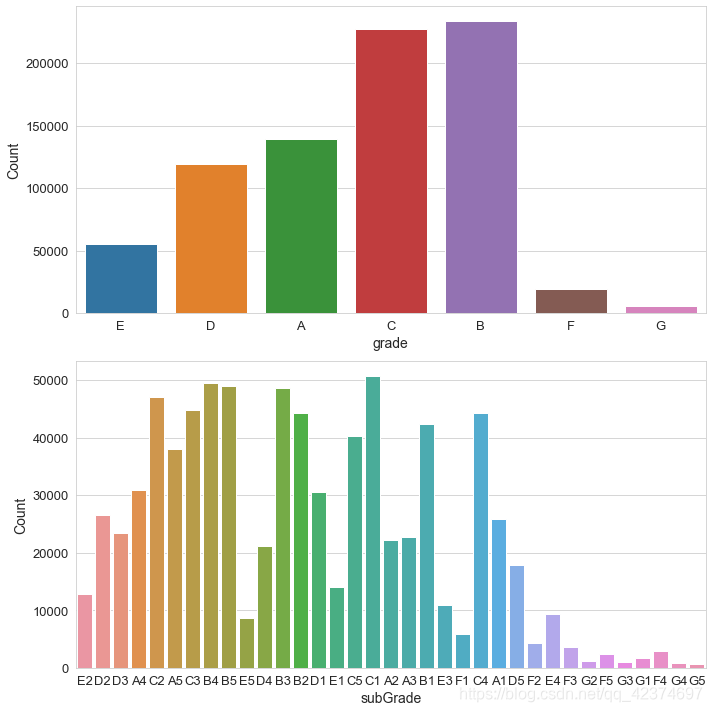
可以看出对于grade特征中A\B\C等级的贷款占比比较大
employmentLength就业年限可视化呈现
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">plt<span style="color:#999999">.</span>figure<span style="color:#999999">(</span><span style="color:#986801">1</span> <span style="color:#999999">,</span> figsize <span style="color:#a67f59">=</span> <span style="color:#999999">(</span><span style="color:#986801">10</span> <span style="color:#999999">,</span> <span style="color:#986801">8</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
sns<span style="color:#999999">.</span>barplot<span style="color:#999999">(</span>train<span style="color:#999999">[</span><span style="color:#50a14f">"employmentLength"</span><span style="color:#999999">]</span><span style="color:#999999">.</span>value_counts<span style="color:#999999">(</span>dropna<span style="color:#a67f59">=</span><span style="color:#0184bb">False</span><span style="color:#999999">)</span><span style="color:#999999">,</span>
train<span style="color:#999999">[</span><span style="color:#50a14f">"employmentLength"</span><span style="color:#999999">]</span><span style="color:#999999">.</span>value_counts<span style="color:#999999">(</span>dropna<span style="color:#a67f59">=</span><span style="color:#0184bb">False</span><span style="color:#999999">)</span><span style="color:#999999">.</span>keys<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>xticks<span style="color:#999999">(</span>fontsize<span style="color:#a67f59">=</span><span style="color:#986801">13</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>yticks<span style="color:#999999">(</span>fontsize<span style="color:#a67f59">=</span><span style="color:#986801">13</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>xlabel<span style="color:#999999">(</span><span style="color:#50a14f">'employmentLength'</span><span style="color:#999999">,</span>fontsize<span style="color:#a67f59">=</span><span style="color:#986801">14</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>show<span style="color:#999999">(</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
可以看到,就业年限最多是 10+year
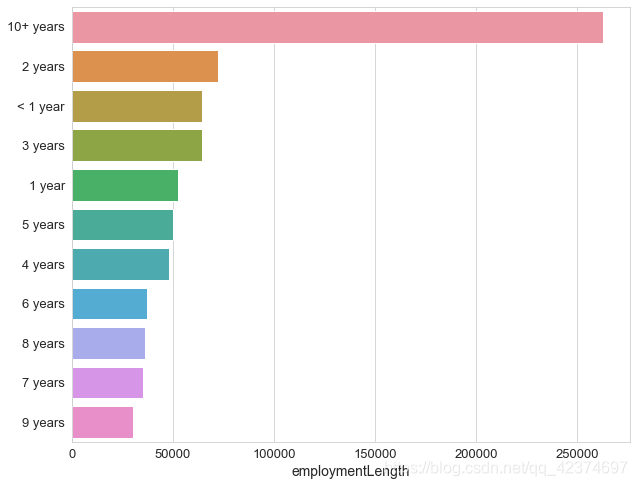
对于 issueDate 与 earliesCreditLine,统计一下每个类别的数量
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#0077aa">for</span> i <span style="color:#0077aa">in</span> train<span style="color:#999999">[</span><span style="color:#999999">[</span><span style="color:#50a14f">'issueDate'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'earliesCreditLine'</span><span style="color:#999999">]</span><span style="color:#999999">]</span><span style="color:#999999">:</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span>train<span style="color:#999999">[</span>i<span style="color:#999999">]</span><span style="color:#999999">.</span>value_counts<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span><span style="color:#999999">)</span>
<span style="color:#50a14f">'''
2016-03-01 29066
2015-10-01 25525
2015-07-01 24496
2015-12-01 23245
2014-10-01 21461
...
2007-08-01 23
2007-07-01 21
2008-09-01 19
2007-09-01 7
2007-06-01 1
Name: issueDate, Length: 139, dtype: int64
Aug-2001 5567
Aug-2002 5403
Sep-2003 5403
Oct-2001 5258
Aug-2000 5246
...
Jan-1946 1
Nov-1953 1
Aug-1958 1
Jun-1958 1
Oct-1957 1
Name: earliesCreditLine, Length: 720, dtype: int64
'''</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
2.3 目标变量(标签y)的分布
查看目标变量(标签)是否平衡
若分类问题中各类别样本数量差距太大,则会造成样本不均衡的问题。样本不均衡不利于建立与训练出正确的模型,且不能做出合理的评估。
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-sql">label<span style="color:#a67f59">=</span>train<span style="color:#999999">.</span>isDefault
label<span style="color:#999999">.</span>value_counts<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#a67f59">/</span><span style="color:#dd4a68">len</span><span style="color:#999999">(</span>label<span style="color:#999999">)</span>
<span style="color:#50a14f">''</span><span style="color:#50a14f">'
0 0.800488
1 0.199513
Name: isDefault, dtype: float64
'</span><span style="color:#50a14f">''</span>
</code></span></span></span></span>AI写代码sql
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-sql">sns<span style="color:#999999">.</span>countplot<span style="color:#999999">(</span>label<span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码sql
- 1
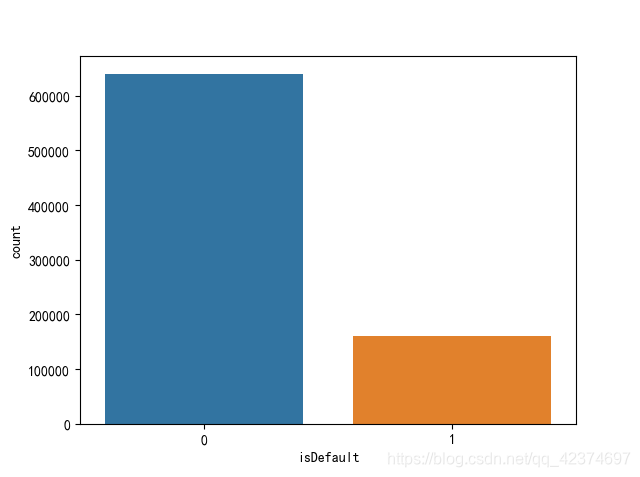
可以看到,贷款违约与不违约的比例大约为1:4,样本较不平衡,这是金融风控模型评估的中常见的现象,大多数的人都是不会拖欠贷款的。
对于这种情况,考虑后续将进行采样等操作。
接下来,看一下目标变量和分类类别之间的分布关系
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-py">train_loan_fr <span style="color:#a67f59">=</span> train<span style="color:#999999">.</span>loc<span style="color:#999999">[</span>train<span style="color:#999999">[</span><span style="color:#50a14f">'isDefault'</span><span style="color:#999999">]</span> <span style="color:#a67f59">==</span> <span style="color:#986801">1</span><span style="color:#999999">]</span>
train_loan_nofr <span style="color:#a67f59">=</span> train<span style="color:#999999">.</span>loc<span style="color:#999999">[</span>train<span style="color:#999999">[</span><span style="color:#50a14f">'isDefault'</span><span style="color:#999999">]</span> <span style="color:#a67f59">==</span> <span style="color:#986801">0</span><span style="color:#999999">]</span>
fig<span style="color:#999999">,</span> <span style="color:#999999">(</span><span style="color:#999999">(</span>ax1<span style="color:#999999">,</span> ax2<span style="color:#999999">)</span><span style="color:#999999">,</span> <span style="color:#999999">(</span>ax3<span style="color:#999999">,</span> ax4<span style="color:#999999">)</span><span style="color:#999999">)</span> <span style="color:#a67f59">=</span> plt<span style="color:#999999">.</span>subplots<span style="color:#999999">(</span><span style="color:#986801">2</span><span style="color:#999999">,</span> <span style="color:#986801">2</span><span style="color:#999999">,</span> figsize<span style="color:#a67f59">=</span><span style="color:#999999">(</span><span style="color:#986801">15</span><span style="color:#999999">,</span> <span style="color:#986801">8</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
<span style="color:#708090"># 目标变量为1时候grade的分布</span>
train_loan_fr<span style="color:#999999">.</span>groupby<span style="color:#999999">(</span><span style="color:#50a14f">"grade"</span><span style="color:#999999">)</span><span style="color:#999999">.</span>size<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">.</span>plot<span style="color:#999999">.</span>bar<span style="color:#999999">(</span>ax<span style="color:#a67f59">=</span>ax1<span style="color:#999999">)</span>
<span style="color:#708090"># 目标变量为0时候grade的分布</span>
train_loan_nofr<span style="color:#999999">.</span>groupby<span style="color:#999999">(</span><span style="color:#50a14f">"grade"</span><span style="color:#999999">)</span><span style="color:#999999">[</span><span style="color:#50a14f">"grade"</span><span style="color:#999999">]</span><span style="color:#999999">.</span>count<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">.</span>plot<span style="color:#999999">.</span>bar<span style="color:#999999">(</span>ax<span style="color:#a67f59">=</span>ax2<span style="color:#999999">)</span>
<span style="color:#708090"># 目标变量为1时候employmentLength的分布</span>
train_loan_fr<span style="color:#999999">.</span>groupby<span style="color:#999999">(</span><span style="color:#50a14f">"employmentLength"</span><span style="color:#999999">)</span><span style="color:#999999">.</span>size<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">.</span>plot<span style="color:#999999">.</span>bar<span style="color:#999999">(</span>ax<span style="color:#a67f59">=</span>ax3<span style="color:#999999">)</span>
<span style="color:#708090"># 目标变量为0时候employmentLength的分布</span>
train_loan_nofr<span style="color:#999999">.</span>groupby<span style="color:#999999">(</span><span style="color:#50a14f">"employmentLength"</span><span style="color:#999999">)</span><span style="color:#999999">[</span><span style="color:#50a14f">"employmentLength"</span><span style="color:#999999">]</span><span style="color:#999999">.</span>count<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">.</span>plot<span style="color:#999999">.</span>bar<span style="color:#999999">(</span>ax<span style="color:#a67f59">=</span>ax4<span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>xticks<span style="color:#999999">(</span>rotation<span style="color:#a67f59">=</span><span style="color:#986801">90</span><span style="color:#999999">)</span><span style="color:#999999">;</span>
</code></span></span></span></span>AI写代码py
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
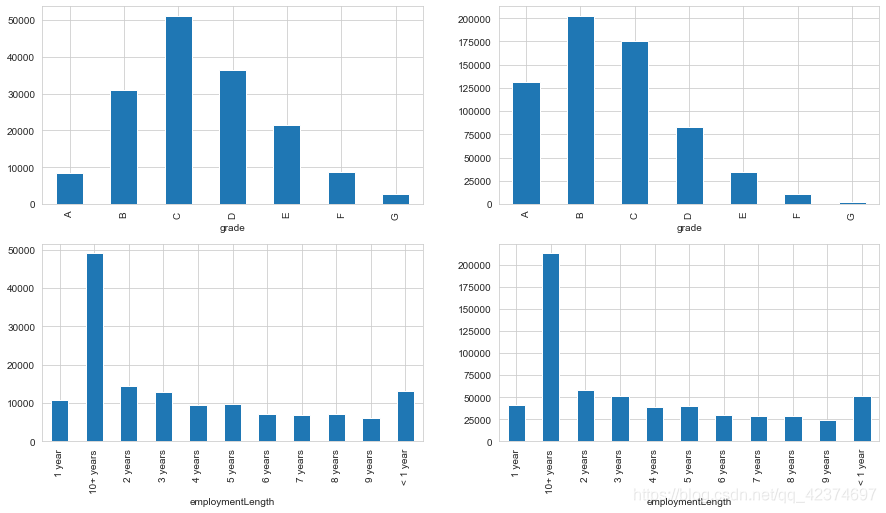
查看一下正负样本的数据差异
把数据集按正负样本分成两份,查看变量的分布差异
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train_positve <span style="color:#a67f59">=</span> train<span style="color:#999999">[</span>train<span style="color:#999999">[</span><span style="color:#50a14f">'isDefault'</span><span style="color:#999999">]</span> <span style="color:#a67f59">==</span> <span style="color:#986801">1</span><span style="color:#999999">]</span>
train_negative <span style="color:#a67f59">=</span> train<span style="color:#999999">[</span>train<span style="color:#999999">[</span><span style="color:#50a14f">'isDefault'</span><span style="color:#999999">]</span> <span style="color:#a67f59">!=</span> <span style="color:#986801">1</span><span style="color:#999999">]</span>
f<span style="color:#999999">,</span> ax <span style="color:#a67f59">=</span> plt<span style="color:#999999">.</span>subplots<span style="color:#999999">(</span><span style="color:#50a14f">len</span><span style="color:#999999">(</span>numerical_feature<span style="color:#999999">)</span><span style="color:#999999">,</span><span style="color:#986801">2</span><span style="color:#999999">,</span>figsize <span style="color:#a67f59">=</span> <span style="color:#999999">(</span><span style="color:#986801">10</span><span style="color:#999999">,</span><span style="color:#986801">80</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
<span style="color:#0077aa">for</span> i<span style="color:#999999">,</span>col <span style="color:#0077aa">in</span> <span style="color:#50a14f">enumerate</span><span style="color:#999999">(</span>numerical_feature<span style="color:#999999">)</span><span style="color:#999999">:</span>
sns<span style="color:#999999">.</span>distplot<span style="color:#999999">(</span>train_positve<span style="color:#999999">[</span>col<span style="color:#999999">]</span><span style="color:#999999">,</span>ax <span style="color:#a67f59">=</span> ax<span style="color:#999999">[</span>i<span style="color:#999999">,</span><span style="color:#986801">0</span><span style="color:#999999">]</span><span style="color:#999999">,</span>color <span style="color:#a67f59">=</span> <span style="color:#50a14f">"blue"</span><span style="color:#999999">)</span>
ax<span style="color:#999999">[</span>i<span style="color:#999999">,</span><span style="color:#986801">0</span><span style="color:#999999">]</span><span style="color:#999999">.</span>set_title<span style="color:#999999">(</span><span style="color:#50a14f">"positive"</span><span style="color:#999999">)</span>
sns<span style="color:#999999">.</span>distplot<span style="color:#999999">(</span>train_negative<span style="color:#999999">[</span>col<span style="color:#999999">]</span><span style="color:#999999">,</span>ax <span style="color:#a67f59">=</span> ax<span style="color:#999999">[</span>i<span style="color:#999999">,</span><span style="color:#986801">1</span><span style="color:#999999">]</span><span style="color:#999999">,</span>color <span style="color:#a67f59">=</span> <span style="color:#50a14f">'red'</span><span style="color:#999999">)</span>
ax<span style="color:#999999">[</span>i<span style="color:#999999">,</span><span style="color:#986801">1</span><span style="color:#999999">]</span><span style="color:#999999">.</span>set_title<span style="color:#999999">(</span><span style="color:#50a14f">"negative"</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>subplots_adjust<span style="color:#999999">(</span>hspace <span style="color:#a67f59">=</span> <span style="color:#986801">1</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

2.4 缺失值查看
如果缺失值过多会对整体的模型结果产生一定的影响,因此每次在建模之前都需要对数据的缺失值情况就行查看,若有缺失情况,需要在后续特征工程中进行填补
缺省值查看
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#708090"># 去掉标签</span>
X_missing <span style="color:#a67f59">=</span> train<span style="color:#999999">.</span>drop<span style="color:#999999">(</span><span style="color:#999999">[</span><span style="color:#50a14f">'isDefault'</span><span style="color:#999999">]</span><span style="color:#999999">,</span>axis<span style="color:#a67f59">=</span><span style="color:#986801">1</span><span style="color:#999999">)</span>
<span style="color:#708090"># 查看缺失情况</span>
missing <span style="color:#a67f59">=</span> X_missing<span style="color:#999999">.</span>isna<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">.</span><span style="color:#50a14f">sum</span><span style="color:#999999">(</span><span style="color:#999999">)</span>
missing <span style="color:#a67f59">=</span> pd<span style="color:#999999">.</span>DataFrame<span style="color:#999999">(</span>data<span style="color:#a67f59">=</span><span style="color:#999999">{</span><span style="color:#50a14f">'特征'</span><span style="color:#999999">:</span> missing<span style="color:#999999">.</span>index<span style="color:#999999">,</span><span style="color:#50a14f">'缺失值个数'</span><span style="color:#999999">:</span>missing<span style="color:#999999">.</span>values<span style="color:#999999">}</span><span style="color:#999999">)</span>
<span style="color:#708090">#通过~取反,选取不包含数字0的行</span>
missing <span style="color:#a67f59">=</span> missing<span style="color:#999999">[</span><span style="color:#a67f59">~</span>missing<span style="color:#999999">[</span><span style="color:#50a14f">'缺失值个数'</span><span style="color:#999999">]</span><span style="color:#999999">.</span>isin<span style="color:#999999">(</span><span style="color:#999999">[</span><span style="color:#986801">0</span><span style="color:#999999">]</span><span style="color:#999999">)</span><span style="color:#999999">]</span>
<span style="color:#708090"># 缺失比例</span>
missing<span style="color:#999999">[</span><span style="color:#50a14f">'缺失比例'</span><span style="color:#999999">]</span> <span style="color:#a67f59">=</span> missing<span style="color:#999999">[</span><span style="color:#50a14f">'缺失值个数'</span><span style="color:#999999">]</span><span style="color:#a67f59">/</span>X_missing<span style="color:#999999">.</span>shape<span style="color:#999999">[</span><span style="color:#986801">0</span><span style="color:#999999">]</span>
missing
<span style="color:#50a14f">'''
特征 缺失值个数 缺失比例
7 employmentTitle 1 0.000001
8 employmentLength 46799 0.058499
14 postCode 1 0.000001
16 dti 239 0.000299
22 pubRecBankruptcies 405 0.000506
24 revolUtil 531 0.000664
29 title 1 0.000001
31 n0 40270 0.050338
32 n1 40270 0.050338
33 n2 40270 0.050338
34 n3 40270 0.050338
35 n4 33239 0.041549
36 n5 40270 0.050338
37 n6 40270 0.050338
38 n7 40270 0.050338
39 n8 40271 0.050339
40 n9 40270 0.050338
41 n10 33239 0.041549
42 n11 69752 0.087190
43 n12 40270 0.050338
44 n13 40270 0.050338
45 n14 40270 0.050338
'''</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
可以看到employmentTitle、employmentLength、dti 以及匿名特征等字段存在缺省值,
从上面的结果可以看出train数据集中的47个字段有22个存在缺省值的情况。下面可视化一下缺省值数量占比。
一般对于缺失值,需要进行横纵对比
-
纵向(从列方向):如果nan存在的过多,说明这一列对label的影响几乎不起作用了,可以考虑删掉。如果缺失值很小一般可以选择填充。比如占到总数的50%,理论上对分析作用不大,这样就可以省略该字段。
-
横向(从行方向):如果在数据集中,某些样本数据的大部分列都是缺失的且样本足够的情况下可以考虑删除。
注意:对于一些模型,可以自动处理缺失值,例如 lightgbm 模型
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#708090"># 可视化</span>
<span style="color:#999999">(</span>train<span style="color:#999999">.</span>isnull<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">.</span><span style="color:#50a14f">sum</span><span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#a67f59">/</span><span style="color:#50a14f">len</span><span style="color:#999999">(</span>train<span style="color:#999999">)</span><span style="color:#999999">)</span><span style="color:#999999">.</span>plot<span style="color:#999999">.</span>bar<span style="color:#999999">(</span>figsize <span style="color:#a67f59">=</span> <span style="color:#999999">(</span><span style="color:#986801">20</span><span style="color:#999999">,</span><span style="color:#986801">6</span><span style="color:#999999">)</span><span style="color:#999999">,</span>color<span style="color:#a67f59">=</span><span style="color:#999999">[</span><span style="color:#50a14f">'#d6ecf0'</span><span style="color:#999999">,</span><span style="color:#50a14f">'#a3d900'</span><span style="color:#999999">,</span><span style="color:#50a14f">'#88ada6'</span><span style="color:#999999">,</span><span style="color:#50a14f">'#ffb3a7'</span><span style="color:#999999">,</span><span style="color:#50a14f">'#cca4e3'</span><span style="color:#999999">,</span><span style="color:#50a14f">'#a1afc9'</span><span style="color:#999999">]</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
缺失特征可视化呈现
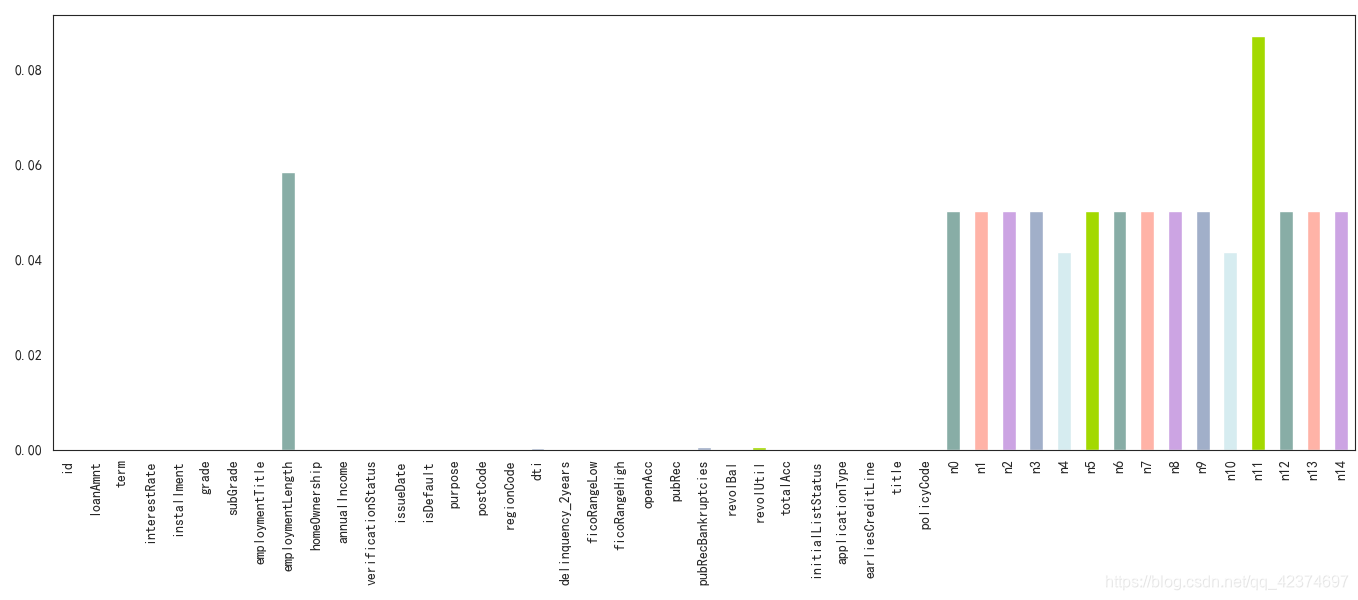
可以看到,所有的特征缺失值都在10%以内,这里考虑全部保留。
总结
47列数据中有22列都缺少少量数据,存在一个唯一值特征 'policyCode'
2.5 数据相关关系
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">f<span style="color:#999999">,</span> ax <span style="color:#a67f59">=</span> plt<span style="color:#999999">.</span>subplots<span style="color:#999999">(</span><span style="color:#986801">1</span><span style="color:#999999">,</span><span style="color:#986801">1</span><span style="color:#999999">,</span> figsize <span style="color:#a67f59">=</span> <span style="color:#999999">(</span><span style="color:#986801">20</span><span style="color:#999999">,</span><span style="color:#986801">20</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
cor <span style="color:#a67f59">=</span> train<span style="color:#999999">[</span>numerical_feature<span style="color:#999999">]</span><span style="color:#999999">.</span>corr<span style="color:#999999">(</span><span style="color:#999999">)</span>
sns<span style="color:#999999">.</span>heatmap<span style="color:#999999">(</span>cor<span style="color:#999999">,</span> annot <span style="color:#a67f59">=</span> <span style="color:#0184bb">True</span><span style="color:#999999">,</span> linewidth <span style="color:#a67f59">=</span> <span style="color:#986801">0.2</span><span style="color:#999999">,</span> linecolor <span style="color:#a67f59">=</span> <span style="color:#50a14f">"white"</span><span style="color:#999999">,</span> ax <span style="color:#a67f59">=</span> ax<span style="color:#999999">,</span> fmt <span style="color:#a67f59">=</span><span style="color:#50a14f">".1g"</span> <span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
可以看到,有些变量之间的相关性还是很强的,比如贷款总额loanAmnt 和分期付款金额installment 相关性为1,ficoRangeLow he ficoRangeHigh 相关性为1...,这种情况后面再特征选择时考虑删除。

三、特征工程
基本的EDA探索完成后(还有一些可以继续探索),就可以进行特征工程啦,在数据挖掘中,大部分时间都是在做特征工程
特征工程包括数据预处理、缺失值以及异常值的处理、数据分桶处理以及特征交互、编码、选择
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-sql">a<span style="color:#999999">)</span> 数据清洗
数据清洗主要的目的是提取原始数据中的噪音部分。(重复数据、异常数据、缺失数据等)
b<span style="color:#999999">)</span>特征预处理(Feature Prepossess)
特征预处理的目的是将数据的原始字段进行相应的编码(定性:独热编码、哈希编码等;
定量:取整、截断、二值化、分箱、放缩)、
变换(归一化、标准化、正态化),并进行缺失值的处理(插值、均值、中位数、众数、删除);
c<span style="color:#999999">)</span>特征提取(Feature Extraction)
特征提取的目的是从原始数据中提取出心的特征字段,并将特征转换成特定的格式;
d<span style="color:#999999">)</span>特征筛选(Feature Selection)
特征筛选的目的是筛选出较优的特征子集,以取得较好的泛化性能;
</code></span></span></span></span>AI写代码sql
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
引用 贷款违约预测3-特征工程 观点:


3.1 重复值处理
重复值
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-sql">train<span style="color:#999999">.</span>duplicated<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">.</span><span style="color:#dd4a68">sum</span><span style="color:#999999">(</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码sql
- 1
0
3.2 缺失值填补
在比赛中数据预处理是必不可少的一部分,对于缺失值的填充往往会影响比赛的结果。
缺失值的处理,请参见
【缺失值处理】拉格朗日插值法---随机森林算法填充---sklearn填充(均值/众数/中位数)

传统地,
- 如果是分类型特征 ,采用众数进行填补。
- 如果是连续型特征 ,采用均值进行填补。
还要考虑
- 均值一般适用于近似正态分布数据,观测值较为均匀散布均值周围;
- 中位数一般适用于偏态分布或者有离群点数据,中位数是更好地代表数据中心趋势;
- 众数一般用于类别变量,无大小、先后顺序之分。
所以对于连续变量
- 对于数据近似符合正态分布,用该变量的均值填补缺失。
- 对于数据存在偏态分布的情况,采用中位数进行填补。
首先剔除标签列
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">label <span style="color:#a67f59">=</span> <span style="color:#50a14f">'isDefault'</span>
Y_label <span style="color:#a67f59">=</span> train<span style="color:#999999">[</span><span style="color:#50a14f">'isDefault'</span><span style="color:#999999">]</span>
numerical_feature<span style="color:#999999">.</span>remove<span style="color:#999999">(</span>label<span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
数值型特征(连续型和离散型)用中位数填补(这里为了方便,都用中位数填补)
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#708090"># 训练集</span>
train<span style="color:#999999">[</span>numerical_feature<span style="color:#999999">]</span> <span style="color:#a67f59">=</span> train<span style="color:#999999">[</span>numerical_feature<span style="color:#999999">]</span><span style="color:#999999">.</span>fillna<span style="color:#999999">(</span>train<span style="color:#999999">[</span>numerical_feature<span style="color:#999999">]</span><span style="color:#999999">.</span>median<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
<span style="color:#708090"># 测试集</span>
test<span style="color:#999999">[</span>numerical_feature<span style="color:#999999">]</span> <span style="color:#a67f59">=</span> test<span style="color:#999999">[</span>numerical_feature<span style="color:#999999">]</span><span style="color:#999999">.</span>fillna<span style="color:#999999">(</span>train<span style="color:#999999">[</span>numerical_feature<span style="color:#999999">]</span><span style="color:#999999">.</span>median<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
分类型特征用众数填补
分类型特征查看
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">[</span>category_feature<span style="color:#999999">]</span>
<span style="color:#50a14f">'''
grade subGrade employmentLength issueDate earliesCreditLine
0 E E2 2 years 2014-07-01 Aug-2001
1 D D2 5 years 2012-08-01 May-2002
2 D D3 8 years 2015-10-01 May-2006
3 A A4 10+ years 2015-08-01 May-1999
4 C C2 NaN 2016-03-01 Aug-1977
... ... ... ... ...
799995 C C4 7 years 2016-07-01 Aug-2011
799996 A A4 10+ years 2013-04-01 May-1989
799997 C C3 10+ years 2015-10-01 Jul-2002
799998 A A4 10+ years 2015-02-01 Jan-1994
799999 B B3 5 years 2018-08-01 Feb-2002
[800000 rows x 5 columns]
'''</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
填补
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#708090"># 训练集</span>
train<span style="color:#999999">[</span>category_feature<span style="color:#999999">]</span> <span style="color:#a67f59">=</span> train<span style="color:#999999">[</span>category_feature<span style="color:#999999">]</span><span style="color:#999999">.</span>fillna<span style="color:#999999">(</span>train<span style="color:#999999">[</span>category_feature<span style="color:#999999">]</span><span style="color:#999999">.</span>mode<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
<span style="color:#708090"># 测试集</span>
test<span style="color:#999999">[</span>category_feature<span style="color:#999999">]</span> <span style="color:#a67f59">=</span> test<span style="color:#999999">[</span>category_feature<span style="color:#999999">]</span><span style="color:#999999">.</span>fillna<span style="color:#999999">(</span>train<span style="color:#999999">[</span>category_feature<span style="color:#999999">]</span><span style="color:#999999">.</span>mode<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
填补之后,再次查看缺失值情况
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">.</span>isnull<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">.</span><span style="color:#50a14f">sum</span><span style="color:#999999">(</span><span style="color:#999999">)</span>
<span style="color:#50a14f">'''
id 0
loanAmnt 0
term 0
interestRate 0
installment 0
grade 0
subGrade 0
employmentTitle 0
employmentLength 46799
homeOwnership 0
annualIncome 0
verificationStatus 0
issueDate 0
isDefault 0
purpose 0
postCode 0
regionCode 0
dti 0
delinquency_2years 0
ficoRangeLow 0
ficoRangeHigh 0
openAcc 0
pubRec 0
pubRecBankruptcies 0
revolBal 0
revolUtil 0
totalAcc 0
initialListStatus 0
applicationType 0
earliesCreditLine 0
title 0
policyCode 0
n0 0
n1 0
n2 0
n3 0
n4 0
n5 0
n6 0
n7 0
n8 0
n9 0
n10 0
n11 0
n12 0
n13 0
n14 0
issueDateDT 0
dtype: int64
'''</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
可以看到,employmentLength 列还存在缺失值
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"> 特征 缺失值个数 缺失比例
<span style="color:#986801">8</span> employmentLength <span style="color:#986801">46799</span> <span style="color:#986801">0.058499</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">.</span>employmentLength
<span style="color:#50a14f">'''
0 2 years
1 5 years
2 8 years
3 10+ years
4 NaN
799995 7 years
799996 10+ years
799997 10+ years
799998 10+ years
799999 5 years
Name: employmentLength, Length: 800000, dtype: object
'''</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
采用决策树来填补就业年限(employmentLength)
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-sql"><span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>tree <span style="color:#0077aa">import</span> DecisionTreeClassifier
empLenNotNullInd <span style="color:#a67f59">=</span> train<span style="color:#999999">.</span>employmentLength<span style="color:#999999">.</span>notnull<span style="color:#999999">(</span><span style="color:#999999">)</span> <span style="color:#708090"># 不是空的行,返回True</span>
<span style="color:#0077aa">columns</span> <span style="color:#a67f59">=</span> <span style="color:#999999">[</span><span style="color:#50a14f">'postCode'</span><span style="color:#999999">,</span><span style="color:#50a14f">'regionCode'</span><span style="color:#999999">,</span><span style="color:#50a14f">'employmentTitle'</span><span style="color:#999999">,</span><span style="color:#50a14f">'annualIncome'</span><span style="color:#999999">]</span> <span style="color:#708090"># 用四个特征来预测employmentLength</span>
train_empLen_X <span style="color:#a67f59">=</span> train<span style="color:#999999">.</span>loc<span style="color:#999999">[</span>empLenNotNullInd<span style="color:#999999">,</span><span style="color:#0077aa">columns</span><span style="color:#999999">]</span>
train_empLen_y <span style="color:#a67f59">=</span> train<span style="color:#999999">.</span>employmentLength<span style="color:#999999">[</span>empLenNotNullInd<span style="color:#999999">]</span>
DTC <span style="color:#a67f59">=</span> DecisionTreeClassifier<span style="color:#999999">(</span><span style="color:#999999">)</span> <span style="color:#708090"># 实例化</span>
DTC<span style="color:#999999">.</span>fit<span style="color:#999999">(</span>train_empLen_X <span style="color:#999999">,</span>train_empLen_y<span style="color:#999999">)</span> <span style="color:#708090"># 训练</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span>DTC<span style="color:#999999">.</span>score<span style="color:#999999">(</span>train_empLen_X <span style="color:#999999">,</span>train_empLen_y<span style="color:#999999">)</span><span style="color:#999999">)</span><span style="color:#708090"># 0.9809320486828881</span>
</code></span></span></span></span>AI写代码sql
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#708090"># 预测</span>
<span style="color:#0077aa">for</span> data <span style="color:#0077aa">in</span> <span style="color:#999999">[</span>train<span style="color:#999999">,</span>test<span style="color:#999999">]</span><span style="color:#999999">:</span>
empLenIsNullInd <span style="color:#a67f59">=</span> data<span style="color:#999999">.</span>employmentLength<span style="color:#999999">.</span>isnull<span style="color:#999999">(</span><span style="color:#999999">)</span>
test_empLen_X <span style="color:#a67f59">=</span> data<span style="color:#999999">.</span>loc<span style="color:#999999">[</span>empLenIsNullInd<span style="color:#999999">,</span>columns<span style="color:#999999">]</span>
empLen_pred <span style="color:#a67f59">=</span> DTC<span style="color:#999999">.</span>predict<span style="color:#999999">(</span>test_empLen_X<span style="color:#999999">)</span>
data<span style="color:#999999">.</span>employmentLength<span style="color:#999999">[</span>empLenIsNullInd<span style="color:#999999">]</span> <span style="color:#a67f59">=</span> empLen_pred
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
填补完毕
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-sql">train<span style="color:#999999">.</span>isnull<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">.</span><span style="color:#0077aa">any</span><span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">.</span><span style="color:#dd4a68">sum</span><span style="color:#999999">(</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码sql
- 1
0
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">[</span><span style="color:#50a14f">'employmentLength'</span><span style="color:#999999">]</span><span style="color:#999999">[</span><span style="color:#999999">:</span><span style="color:#986801">20</span><span style="color:#999999">]</span>
<span style="color:#50a14f">'''
0 2 years
1 5 years
2 8 years
3 10+ years
4 5 years
5 7 years
6 9 years
7 1 year
8 5 years
9 6 years
10 10+ years
11 3 years
12 2 years
13 10+ years
14 2 years
15 2 years
16 9 years
17 < 1 year
18 10+ years
19 9 years
Name: employmentLength, dtype: object
'''</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-py">train<span style="color:#999999">[</span><span style="color:#50a14f">'employmentLength'</span><span style="color:#999999">]</span><span style="color:#999999">.</span>value_counts<span style="color:#999999">(</span>dropna<span style="color:#a67f59">=</span><span style="color:#0184bb">False</span><span style="color:#999999">)</span><span style="color:#999999">.</span>sort_index<span style="color:#999999">(</span><span style="color:#999999">)</span>
<span style="color:#50a14f">'''
1 year 55034
10+ years 276853
2 years 76435
3 years 68888
4 years 50893
5 years 54038
6 years 39517
7 years 37175
8 years 37903
9 years 31463
< 1 year 71801
Name: employmentLength, dtype: int64
'''</span>
</code></span></span></span></span>AI写代码py
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
总结
- 如果采用 XGBoost(LightGBM) 模型,能够自动处理缺失值的模型,这样就无需处理缺失值;
- 如果缺失值较多,可以直接删除
- 如果发现某列特征信息可能是因为某种特定原因导致的,而不是随机缺失,可以考虑在特征工程时利用该假设来构架新特征。
3.3 异常值处理
异常值的存在很可能会影响模型的最终结果,但是当我们发现异常值的时候也不能马上就删除,应该先看看这个异常值是不是有特殊原因造成的,特别是在金融风控问题中,异常值的出现往往是存在意义的。
如果不是因为特殊原因造成的,可以先观察这个异常值出现的频率
-
若异常值只出现了一次,多半是输入错误,直接把异常值删除即可
-
若异常值出现了多次,可以和业务人员沟通,可能这是某种特殊表示,如果是人为造成的错误,留着是没有用,只要数据量不是太大,都可以删除
-
若异常值占到总数据量的10%以上,不能轻易删除。可以考虑把异常值替换成非异常但是非干扰的项,比如说用0来进行替换,或者把异常当缺失值,用均值或者众数来进行替换
通常,在进行EDA的时候会利用描述统计的方法,查看特征的均值、极大值、极小值等信息,结合常识来判断是否存在异常值。
比如,年龄值出现负数,人的身高出现非常大的值等等
除此之外,还有其他判断异常值的方法,例如
3.3.1 方法一:均方差 3σ
在统计学中,如果一个数据分布近似正态,那么大约 68% 的数据值会在均值的一个标准差范围内,大约 95% 会在两个标准差范围内,大约 99.7% 会在三个标准差范围内。
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#0077aa">def</span> <span style="color:#dd4a68">find_outliers_by_3segama</span><span style="color:#999999">(</span>data<span style="color:#999999">,</span>fea<span style="color:#999999">)</span><span style="color:#999999">:</span>
data_std <span style="color:#a67f59">=</span> np<span style="color:#999999">.</span>std<span style="color:#999999">(</span>data<span style="color:#999999">[</span>fea<span style="color:#999999">]</span><span style="color:#999999">)</span>
data_mean <span style="color:#a67f59">=</span> np<span style="color:#999999">.</span>mean<span style="color:#999999">(</span>data<span style="color:#999999">[</span>fea<span style="color:#999999">]</span><span style="color:#999999">)</span>
outliers_cut_off <span style="color:#a67f59">=</span> data_std <span style="color:#a67f59">*</span> <span style="color:#986801">3</span>
lower_rule <span style="color:#a67f59">=</span> data_mean <span style="color:#a67f59">-</span> outliers_cut_off
upper_rule <span style="color:#a67f59">=</span> data_mean <span style="color:#a67f59">+</span> outliers_cut_off
data<span style="color:#999999">[</span>fea<span style="color:#a67f59">+</span><span style="color:#50a14f">'_outliers'</span><span style="color:#999999">]</span> <span style="color:#a67f59">=</span> data<span style="color:#999999">[</span>fea<span style="color:#999999">]</span><span style="color:#999999">.</span><span style="color:#50a14f">apply</span><span style="color:#999999">(</span><span style="color:#0077aa">lambda</span> x<span style="color:#999999">:</span><span style="color:#50a14f">str</span><span style="color:#999999">(</span><span style="color:#50a14f">'异常值'</span><span style="color:#999999">)</span> <span style="color:#0077aa">if</span> x <span style="color:#a67f59">></span> upper_rule <span style="color:#a67f59">or</span> x <span style="color:#a67f59"><</span> lower_rule <span style="color:#0077aa">else</span> <span style="color:#50a14f">'正常值'</span><span style="color:#999999">)</span>
<span style="color:#0077aa">return</span> data
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
得到特征的异常值后可以进一步分析变量异常值和目标变量的关系
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">data_train <span style="color:#a67f59">=</span> train<span style="color:#999999">.</span>copy<span style="color:#999999">(</span><span style="color:#999999">)</span>
<span style="color:#0077aa">for</span> fea <span style="color:#0077aa">in</span> numerical_feature<span style="color:#999999">:</span>
data_train <span style="color:#a67f59">=</span> find_outliers_by_3segama<span style="color:#999999">(</span>data_train<span style="color:#999999">,</span>fea<span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span>data_train<span style="color:#999999">[</span>fea<span style="color:#a67f59">+</span><span style="color:#50a14f">'_outliers'</span><span style="color:#999999">]</span><span style="color:#999999">.</span>value_counts<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span>data_train<span style="color:#999999">.</span>groupby<span style="color:#999999">(</span>fea<span style="color:#a67f59">+</span><span style="color:#50a14f">'_outliers'</span><span style="color:#999999">)</span><span style="color:#999999">[</span><span style="color:#50a14f">'isDefault'</span><span style="color:#999999">]</span><span style="color:#999999">.</span><span style="color:#50a14f">sum</span><span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span><span style="color:#50a14f">'*'</span><span style="color:#a67f59">*</span><span style="color:#986801">10</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
3.3.2 方法二:箱型图
箱型图包括上四
这里,没有对异常值进行处理...
3.4 时间数据处理
对于时间数据

对于本赛题,时间数据有 issueDate ,可以将其转化成时间格式(issueDateDT特征表示数据日期离数据集中日期最早的日期(2007-06-01)的天数)
首先看一下这个issueDate
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">[</span><span style="color:#50a14f">'issueDate'</span><span style="color:#999999">]</span>
<span style="color:#50a14f">'''
0 2014-07-01
1 2012-08-01
2 2015-10-01
3 2015-08-01
4 2016-03-01
...
799995 2016-07-01
799996 2013-04-01
799997 2015-10-01
799998 2015-02-01
799999 2018-08-01
Name: issueDate, Length: 800000, dtype: object
'''</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">.</span>shape <span style="color:#708090"># (800000, 47)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
训练集时间数据处理
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#0077aa">import</span> datetime
<span style="color:#708090"># 转化成时间格式 issueDateDT特征表示数据日期离数据集中日期最早的日期(2007-06-01)的天数</span>
train<span style="color:#999999">[</span><span style="color:#50a14f">'issueDate'</span><span style="color:#999999">]</span> <span style="color:#a67f59">=</span> pd<span style="color:#999999">.</span>to_datetime<span style="color:#999999">(</span>train<span style="color:#999999">[</span><span style="color:#50a14f">'issueDate'</span><span style="color:#999999">]</span><span style="color:#999999">,</span><span style="color:#50a14f">format</span><span style="color:#a67f59">=</span><span style="color:#50a14f">'%Y-%m-%d'</span><span style="color:#999999">)</span>
startdate <span style="color:#a67f59">=</span> datetime<span style="color:#999999">.</span>datetime<span style="color:#999999">.</span>strptime<span style="color:#999999">(</span><span style="color:#50a14f">'2007-06-01'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'%Y-%m-%d'</span><span style="color:#999999">)</span>
train<span style="color:#999999">[</span><span style="color:#50a14f">'issueDateDT'</span><span style="color:#999999">]</span> <span style="color:#a67f59">=</span> train<span style="color:#999999">[</span><span style="color:#50a14f">'issueDate'</span><span style="color:#999999">]</span><span style="color:#999999">.</span><span style="color:#50a14f">apply</span><span style="color:#999999">(</span><span style="color:#0077aa">lambda</span> x<span style="color:#999999">:</span> x<span style="color:#a67f59">-</span>startdate<span style="color:#999999">)</span><span style="color:#999999">.</span>dt<span style="color:#999999">.</span>days
train<span style="color:#999999">.</span>shape <span style="color:#708090"># (800000, 48)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
查看一下处理效果
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">[</span><span style="color:#999999">[</span><span style="color:#50a14f">'issueDate'</span><span style="color:#999999">,</span><span style="color:#50a14f">'issueDateDT'</span><span style="color:#999999">]</span><span style="color:#999999">]</span>
</code></span></span></span></span>AI写代码python
运行
- 1
测试集时间数据处理
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#708090">#转化成时间格式</span>
test<span style="color:#999999">[</span><span style="color:#50a14f">'issueDate'</span><span style="color:#999999">]</span> <span style="color:#a67f59">=</span> pd<span style="color:#999999">.</span>to_datetime<span style="color:#999999">(</span>train<span style="color:#999999">[</span><span style="color:#50a14f">'issueDate'</span><span style="color:#999999">]</span><span style="color:#999999">,</span><span style="color:#50a14f">format</span><span style="color:#a67f59">=</span><span style="color:#50a14f">'%Y-%m-%d'</span><span style="color:#999999">)</span>
startdate <span style="color:#a67f59">=</span> datetime<span style="color:#999999">.</span>datetime<span style="color:#999999">.</span>strptime<span style="color:#999999">(</span><span style="color:#50a14f">'2007-06-01'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'%Y-%m-%d'</span><span style="color:#999999">)</span>
test<span style="color:#999999">[</span><span style="color:#50a14f">'issueDateDT'</span><span style="color:#999999">]</span> <span style="color:#a67f59">=</span> test<span style="color:#999999">[</span><span style="color:#50a14f">'issueDate'</span><span style="color:#999999">]</span><span style="color:#999999">.</span><span style="color:#50a14f">apply</span><span style="color:#999999">(</span><span style="color:#0077aa">lambda</span> x<span style="color:#999999">:</span> x<span style="color:#a67f59">-</span>startdate<span style="color:#999999">)</span><span style="color:#999999">.</span>dt<span style="color:#999999">.</span>days
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
可视化
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">plt<span style="color:#999999">.</span>figure<span style="color:#999999">(</span><span style="color:#986801">1</span> <span style="color:#999999">,</span> figsize <span style="color:#a67f59">=</span> <span style="color:#999999">(</span><span style="color:#986801">10</span> <span style="color:#999999">,</span> <span style="color:#986801">8</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>hist<span style="color:#999999">(</span>train<span style="color:#999999">[</span><span style="color:#50a14f">'issueDateDT'</span><span style="color:#999999">]</span><span style="color:#999999">,</span> label<span style="color:#a67f59">=</span><span style="color:#50a14f">'train'</span><span style="color:#999999">)</span><span style="color:#999999">;</span>
plt<span style="color:#999999">.</span>hist<span style="color:#999999">(</span>test<span style="color:#999999">[</span><span style="color:#50a14f">'issueDateDT'</span><span style="color:#999999">]</span><span style="color:#999999">,</span> label<span style="color:#a67f59">=</span><span style="color:#50a14f">'test'</span><span style="color:#999999">)</span><span style="color:#999999">;</span>
plt<span style="color:#999999">.</span>legend<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">;</span>
plt<span style="color:#999999">.</span>title<span style="color:#999999">(</span><span style="color:#50a14f">'Distribution of issueDateDT dates'</span><span style="color:#999999">)</span><span style="color:#999999">;</span>
<span style="color:#708090">#train 和 test issueDateDT 日期有重叠 所以使用基于时间的分割进行验证是不明智的</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
注:这里issueDate特征先暂时不删除
3.5 特征交叉

这里处理 earliesCreditLine,将利用到 issueDate
这两个特征含义如下
| Field | Description |
|---|---|
| issueDate | 贷款发放的月份 |
| earliesCreditLine | 借款人最早报告的信用额度开立的月份 |
将issueDate贷款发放时的年份减去借款人最早报告的信用额度开立的年份,得到新的特征,即开卡年限CreditLine
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">[</span><span style="color:#999999">[</span><span style="color:#50a14f">'issueDate'</span><span style="color:#999999">,</span><span style="color:#50a14f">'earliesCreditLine'</span><span style="color:#999999">]</span><span style="color:#999999">]</span>
<span style="color:#50a14f">'''
issueDate earliesCreditLine
0 2014-07-01 Aug-2001
1 2012-08-01 May-2002
2 2015-10-01 May-2006
3 2015-08-01 May-1999
4 2016-03-01 Aug-1977
... ...
799995 2016-07-01 Aug-2011
799996 2013-04-01 May-1989
799997 2015-10-01 Jul-2002
799998 2015-02-01 Jan-1994
799999 2018-08-01 Feb-2002
[800000 rows x 2 columns]
'''</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
参考:https://zhuanlan.zhihu.com/p/255105477
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train_earliesCreditLine_year <span style="color:#a67f59">=</span> train<span style="color:#999999">[</span><span style="color:#50a14f">'earliesCreditLine'</span><span style="color:#999999">]</span><span style="color:#999999">.</span><span style="color:#50a14f">apply</span><span style="color:#999999">(</span><span style="color:#0077aa">lambda</span> x<span style="color:#999999">:</span>x<span style="color:#999999">[</span><span style="color:#a67f59">-</span><span style="color:#986801">4</span><span style="color:#999999">:</span><span style="color:#999999">]</span><span style="color:#999999">)</span><span style="color:#999999">.</span>astype<span style="color:#999999">(</span><span style="color:#50a14f">'int64'</span><span style="color:#999999">)</span>
test_earliesCreditLine_year <span style="color:#a67f59">=</span> test<span style="color:#999999">[</span><span style="color:#50a14f">'earliesCreditLine'</span><span style="color:#999999">]</span><span style="color:#999999">.</span><span style="color:#50a14f">apply</span><span style="color:#999999">(</span><span style="color:#0077aa">lambda</span> x<span style="color:#999999">:</span>x<span style="color:#999999">[</span><span style="color:#a67f59">-</span><span style="color:#986801">4</span><span style="color:#999999">:</span><span style="color:#999999">]</span><span style="color:#999999">)</span><span style="color:#999999">.</span>astype<span style="color:#999999">(</span><span style="color:#50a14f">'int64'</span><span style="color:#999999">)</span>
train_issueDate_year <span style="color:#a67f59">=</span> train<span style="color:#999999">[</span><span style="color:#50a14f">'issueDate'</span><span style="color:#999999">]</span><span style="color:#999999">.</span>astype<span style="color:#999999">(</span><span style="color:#50a14f">'str'</span><span style="color:#999999">)</span><span style="color:#999999">.</span><span style="color:#50a14f">apply</span><span style="color:#999999">(</span><span style="color:#0077aa">lambda</span> x<span style="color:#999999">:</span>x<span style="color:#999999">[</span><span style="color:#999999">:</span><span style="color:#986801">4</span><span style="color:#999999">]</span><span style="color:#999999">)</span><span style="color:#999999">.</span>astype<span style="color:#999999">(</span><span style="color:#50a14f">'int64'</span><span style="color:#999999">)</span>
test_issueDate_year <span style="color:#a67f59">=</span> test<span style="color:#999999">[</span><span style="color:#50a14f">'issueDate'</span><span style="color:#999999">]</span><span style="color:#999999">.</span>astype<span style="color:#999999">(</span><span style="color:#50a14f">'str'</span><span style="color:#999999">)</span><span style="color:#999999">.</span><span style="color:#50a14f">apply</span><span style="color:#999999">(</span><span style="color:#0077aa">lambda</span> x<span style="color:#999999">:</span>x<span style="color:#999999">[</span><span style="color:#999999">:</span><span style="color:#986801">4</span><span style="color:#999999">]</span><span style="color:#999999">)</span><span style="color:#999999">.</span>astype<span style="color:#999999">(</span><span style="color:#50a14f">'int64'</span><span style="color:#999999">)</span>
train<span style="color:#999999">[</span><span style="color:#50a14f">'CreditLine'</span><span style="color:#999999">]</span> <span style="color:#a67f59">=</span> train_issueDate_year <span style="color:#a67f59">-</span> train_earliesCreditLine_year
test<span style="color:#999999">[</span><span style="color:#50a14f">'CreditLine'</span><span style="color:#999999">]</span> <span style="color:#a67f59">=</span> test_issueDate_year <span style="color:#a67f59">-</span> test_earliesCreditLine_year
train <span style="color:#a67f59">=</span> train<span style="color:#999999">.</span>drop<span style="color:#999999">(</span><span style="color:#999999">[</span><span style="color:#50a14f">'earliesCreditLine'</span><span style="color:#999999">,</span><span style="color:#50a14f">'issueDate'</span><span style="color:#999999">]</span><span style="color:#999999">,</span>axis<span style="color:#a67f59">=</span><span style="color:#986801">1</span><span style="color:#999999">)</span>
test <span style="color:#a67f59">=</span> test<span style="color:#999999">.</span>drop<span style="color:#999999">(</span><span style="color:#999999">[</span><span style="color:#50a14f">'earliesCreditLine'</span><span style="color:#999999">,</span><span style="color:#50a14f">'issueDate'</span><span style="color:#999999">]</span><span style="color:#999999">,</span>axis<span style="color:#a67f59">=</span><span style="color:#986801">1</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
查看处理结果
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">[</span><span style="color:#50a14f">'CreditLine'</span><span style="color:#999999">]</span>
<span style="color:#50a14f">'''
0 13
1 10
2 9
3 16
4 39
..
799995 5
799996 24
799997 13
799998 21
799999 16
Name: CreditLine, Length: 800000, dtype: int64
'''</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">.</span>shape <span style="color:#708090">## (800000, 47)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
目前新增两个特征 issueDateDT、CreditLine
earliesCreditLine和issueDate 已经删除
3.6 特征编码
对类别型特征进行转换,使其变为数值特征。具体有以下几种方法:
- 序号编码:适用于类别间存在大小关系的特征。比如级别高中低,可以对应 321。
- oneHot 编码:适用于不具有大小关系的特征。比如地名。
- 二进制编码:先给每个类别赋予一个序号 ID,然后对 ID 进行二进制编码,最终得到和 OneHot 类似的 0-1 向量,但是维度更小。
首先将 employmentLength 进行简单的处理,再进行编码
这里将就业年限特征转换为数值(把数字后面的years去掉并且把10+改成10,<1改成0)
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#0077aa">def</span> <span style="color:#dd4a68">employmentLength_to_int</span><span style="color:#999999">(</span>s<span style="color:#999999">)</span><span style="color:#999999">:</span>
<span style="color:#0077aa">if</span> pd<span style="color:#999999">.</span>isnull<span style="color:#999999">(</span>s<span style="color:#999999">)</span><span style="color:#999999">:</span>
<span style="color:#0077aa">return</span> s
<span style="color:#0077aa">else</span><span style="color:#999999">:</span>
<span style="color:#0077aa">return</span> np<span style="color:#999999">.</span>int8<span style="color:#999999">(</span>s<span style="color:#999999">.</span>split<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">[</span><span style="color:#986801">0</span><span style="color:#999999">]</span><span style="color:#999999">)</span>
<span style="color:#0077aa">for</span> data <span style="color:#0077aa">in</span> <span style="color:#999999">[</span>train<span style="color:#999999">,</span> test<span style="color:#999999">]</span><span style="color:#999999">:</span>
data<span style="color:#999999">[</span><span style="color:#50a14f">'employmentLength'</span><span style="color:#999999">]</span><span style="color:#999999">.</span>replace<span style="color:#999999">(</span>to_replace<span style="color:#a67f59">=</span><span style="color:#50a14f">'10+ years'</span><span style="color:#999999">,</span> value<span style="color:#a67f59">=</span><span style="color:#50a14f">'10 years'</span><span style="color:#999999">,</span> inplace<span style="color:#a67f59">=</span><span style="color:#0184bb">True</span><span style="color:#999999">)</span>
data<span style="color:#999999">[</span><span style="color:#50a14f">'employmentLength'</span><span style="color:#999999">]</span><span style="color:#999999">.</span>replace<span style="color:#999999">(</span><span style="color:#50a14f">'< 1 year'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'0 years'</span><span style="color:#999999">,</span> inplace<span style="color:#a67f59">=</span><span style="color:#0184bb">True</span><span style="color:#999999">)</span>
data<span style="color:#999999">[</span><span style="color:#50a14f">'employmentLength'</span><span style="color:#999999">]</span> <span style="color:#a67f59">=</span> data<span style="color:#999999">[</span><span style="color:#50a14f">'employmentLength'</span><span style="color:#999999">]</span><span style="color:#999999">.</span><span style="color:#50a14f">apply</span><span style="color:#999999">(</span>employmentLength_to_int<span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
处理前效果
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">[</span><span style="color:#50a14f">'employmentLength'</span><span style="color:#999999">]</span><span style="color:#999999">[</span><span style="color:#999999">:</span><span style="color:#986801">20</span><span style="color:#999999">]</span>
<span style="color:#50a14f">'''
0 2 years
1 5 years
2 8 years
3 10+ years
4 5 years
5 7 years
6 9 years
7 1 year
8 5 years
9 6 years
10 10+ years
11 3 years
12 2 years
13 10+ years
14 2 years
15 2 years
16 9 years
17 < 1 year
18 10+ years
19 9 years
Name: employmentLength, dtype: object
'''</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
处理后效果
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">[</span><span style="color:#50a14f">'employmentLength'</span><span style="color:#999999">]</span>
<span style="color:#50a14f">'''
0 2
1 5
2 8
3 10
4 5
..
799995 7
799996 10
799997 10
799998 10
799999 5
Name: employmentLength, Length: 800000, dtype: int64
'''</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
接下来,对其余分类型特征进行编码
像等级grade、subGrade这种类别特征,虽然是表示类别的数据,但是信用评级是有高低大小之分的,是有优先级的,所以可以直接自映射,转化为数值类型。(也可以使用labelencode编码)
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">a2z <span style="color:#a67f59">=</span> <span style="color:#50a14f">'ABCDEFGHIJKLMNOPQRSTUVWXYZ'</span>
a2z_code <span style="color:#a67f59">=</span> np<span style="color:#999999">.</span>arange<span style="color:#999999">(</span><span style="color:#986801">1</span><span style="color:#999999">,</span><span style="color:#986801">27</span><span style="color:#999999">)</span>
a2z_mapping <span style="color:#a67f59">=</span> <span style="color:#50a14f">dict</span><span style="color:#999999">(</span><span style="color:#50a14f">zip</span><span style="color:#999999">(</span>a2z<span style="color:#999999">,</span> a2z_code<span style="color:#999999">)</span><span style="color:#999999">)</span>
<span style="color:#0077aa">for</span> data <span style="color:#0077aa">in</span> <span style="color:#999999">[</span>train<span style="color:#999999">,</span>test<span style="color:#999999">]</span><span style="color:#999999">:</span>
data<span style="color:#999999">.</span>loc<span style="color:#999999">[</span><span style="color:#999999">:</span><span style="color:#999999">,</span><span style="color:#999999">[</span><span style="color:#50a14f">'grade'</span><span style="color:#999999">,</span><span style="color:#50a14f">'subGrade'</span><span style="color:#999999">]</span><span style="color:#999999">]</span> <span style="color:#a67f59">=</span> data<span style="color:#999999">.</span>loc<span style="color:#999999">[</span><span style="color:#999999">:</span><span style="color:#999999">,</span><span style="color:#999999">[</span><span style="color:#50a14f">'grade'</span><span style="color:#999999">,</span><span style="color:#50a14f">'subGrade'</span><span style="color:#999999">]</span><span style="color:#999999">]</span><span style="color:#999999">.</span>applymap<span style="color:#999999">(</span><span style="color:#0077aa">lambda</span> g<span style="color:#999999">:</span>g<span style="color:#999999">.</span>replace<span style="color:#999999">(</span>g<span style="color:#999999">[</span><span style="color:#986801">0</span><span style="color:#999999">]</span><span style="color:#999999">,</span> <span style="color:#50a14f">str</span><span style="color:#999999">(</span>a2z<span style="color:#999999">.</span>index<span style="color:#999999">(</span>g<span style="color:#999999">[</span><span style="color:#986801">0</span><span style="color:#999999">]</span><span style="color:#999999">)</span><span style="color:#a67f59">+</span><span style="color:#986801">1</span><span style="color:#999999">)</span><span style="color:#999999">)</span><span style="color:#999999">)</span><span style="color:#999999">.</span>astype<span style="color:#999999">(</span><span style="color:#50a14f">'int'</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
编码前结果
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">[</span><span style="color:#999999">[</span><span style="color:#50a14f">'grade'</span><span style="color:#999999">,</span><span style="color:#50a14f">'subGrade'</span><span style="color:#999999">]</span><span style="color:#999999">]</span>
</code></span></span></span></span>AI写代码python
运行
- 1
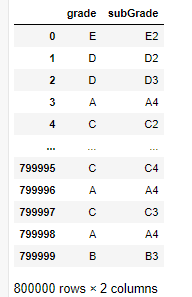
编码后结果
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">[</span><span style="color:#999999">[</span><span style="color:#50a14f">'grade'</span><span style="color:#999999">,</span><span style="color:#50a14f">'subGrade'</span><span style="color:#999999">]</span><span style="color:#999999">]</span>
</code></span></span></span></span>AI写代码python
运行
- 1
对于离散型特征,可以使用OneHotEncoder独热编码
要处理的特征有
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">[</span><span style="color:#999999">[</span><span style="color:#50a14f">'homeOwnership'</span><span style="color:#999999">,</span><span style="color:#50a14f">'verificationStatus'</span><span style="color:#999999">,</span><span style="color:#50a14f">'purpose'</span><span style="color:#999999">]</span><span style="color:#999999">]</span>
<span style="color:#50a14f">'''
homeOwnership verificationStatus purpose
0 2 2 1
1 0 2 0
2 0 2 0
3 1 1 4
4 1 2 10
... ... ...
799995 1 0 0
799996 0 2 4
799997 1 2 0
799998 0 2 4
799999 0 0 4
[800000 rows x 3 columns]
'''</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
编码之前确定一下特征数
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">.</span>shape<span style="color:#708090"># (800000, 47)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
独热编码
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>preprocessing <span style="color:#0077aa">import</span> OneHotEncoder
oh <span style="color:#a67f59">=</span> OneHotEncoder<span style="color:#999999">(</span>sparse<span style="color:#a67f59">=</span><span style="color:#0184bb">False</span><span style="color:#999999">)</span>
oh<span style="color:#999999">.</span>fit<span style="color:#999999">(</span>train<span style="color:#999999">[</span><span style="color:#999999">[</span><span style="color:#50a14f">'homeOwnership'</span><span style="color:#999999">,</span><span style="color:#50a14f">'verificationStatus'</span><span style="color:#999999">,</span><span style="color:#50a14f">'purpose'</span><span style="color:#999999">]</span><span style="color:#999999">]</span><span style="color:#999999">)</span>
OneHot1 <span style="color:#a67f59">=</span> oh<span style="color:#999999">.</span>transform<span style="color:#999999">(</span>train<span style="color:#999999">[</span><span style="color:#999999">[</span><span style="color:#50a14f">'homeOwnership'</span><span style="color:#999999">,</span><span style="color:#50a14f">'verificationStatus'</span><span style="color:#999999">,</span><span style="color:#50a14f">'purpose'</span><span style="color:#999999">]</span><span style="color:#999999">]</span><span style="color:#999999">)</span>
OneHot2 <span style="color:#a67f59">=</span> oh<span style="color:#999999">.</span>transform<span style="color:#999999">(</span>test<span style="color:#999999">[</span><span style="color:#999999">[</span><span style="color:#50a14f">'homeOwnership'</span><span style="color:#999999">,</span><span style="color:#50a14f">'verificationStatus'</span><span style="color:#999999">,</span><span style="color:#50a14f">'purpose'</span><span style="color:#999999">]</span><span style="color:#999999">]</span><span style="color:#999999">)</span>
OneHot1<span style="color:#999999">.</span>shape<span style="color:#708090"># (800000, 23)</span>
<span style="color:#50a14f">'''
array([[0., 0., 1., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
...,
[0., 1., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.]])
'''</span>
train <span style="color:#a67f59">=</span> pd<span style="color:#999999">.</span>concat<span style="color:#999999">(</span><span style="color:#999999">[</span>train<span style="color:#999999">,</span> pd<span style="color:#999999">.</span>DataFrame<span style="color:#999999">(</span>OneHot1<span style="color:#999999">)</span><span style="color:#999999">]</span><span style="color:#999999">,</span> axis<span style="color:#a67f59">=</span><span style="color:#986801">1</span><span style="color:#999999">)</span>
test <span style="color:#a67f59">=</span> pd<span style="color:#999999">.</span>concat<span style="color:#999999">(</span><span style="color:#999999">[</span>test<span style="color:#999999">,</span> pd<span style="color:#999999">.</span>DataFrame<span style="color:#999999">(</span>OneHot2<span style="color:#999999">)</span><span style="color:#999999">]</span><span style="color:#999999">,</span> axis<span style="color:#a67f59">=</span><span style="color:#986801">1</span><span style="color:#999999">)</span>
train <span style="color:#a67f59">=</span> train<span style="color:#999999">.</span>drop<span style="color:#999999">(</span><span style="color:#999999">[</span><span style="color:#50a14f">'homeOwnership'</span><span style="color:#999999">,</span><span style="color:#50a14f">'verificationStatus'</span><span style="color:#999999">,</span><span style="color:#50a14f">'purpose'</span><span style="color:#999999">]</span><span style="color:#999999">,</span>axis<span style="color:#a67f59">=</span><span style="color:#986801">1</span><span style="color:#999999">)</span>
test <span style="color:#a67f59">=</span> test<span style="color:#999999">.</span>drop<span style="color:#999999">(</span><span style="color:#999999">[</span><span style="color:#50a14f">'homeOwnership'</span><span style="color:#999999">,</span><span style="color:#50a14f">'verificationStatus'</span><span style="color:#999999">,</span><span style="color:#50a14f">'purpose'</span><span style="color:#999999">]</span><span style="color:#999999">,</span>axis<span style="color:#a67f59">=</span><span style="color:#986801">1</span><span style="color:#999999">)</span>
train<span style="color:#999999">.</span>shape<span style="color:#708090"># (800000, 67)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
3.7 数据分桶
引用 Datawhale零基础入门金融风控 Task3 特征工程 观点

常见的分箱方法有:

- 固定宽度分箱
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#708090"># 通过除法映射到间隔均匀的分箱中,每个分箱的取值范围都是loanAmnt/1000</span>
train<span style="color:#999999">[</span><span style="color:#50a14f">'loanAmnt_bin1'</span><span style="color:#999999">]</span> <span style="color:#a67f59">=</span> np<span style="color:#999999">.</span>floor_divide<span style="color:#999999">(</span>train<span style="color:#999999">[</span><span style="color:#50a14f">'loanAmnt'</span><span style="color:#999999">]</span><span style="color:#999999">,</span> <span style="color:#986801">1000</span><span style="color:#999999">)</span>
<span style="color:#708090">## 通过对数函数映射到指数宽度分箱</span>
train<span style="color:#999999">[</span><span style="color:#50a14f">'loanAmnt_bin2'</span><span style="color:#999999">]</span> <span style="color:#a67f59">=</span> np<span style="color:#999999">.</span>floor<span style="color:#999999">(</span>np<span style="color:#999999">.</span>log10<span style="color:#999999">(</span>train<span style="color:#999999">[</span><span style="color:#50a14f">'loanAmnt'</span><span style="color:#999999">]</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 分位数分箱
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">[</span><span style="color:#50a14f">'loanAmnt_bin3'</span><span style="color:#999999">]</span> <span style="color:#a67f59">=</span> pd<span style="color:#999999">.</span>qcut<span style="color:#999999">(</span>train<span style="color:#999999">[</span><span style="color:#50a14f">'loanAmnt'</span><span style="color:#999999">]</span><span style="color:#999999">,</span> <span style="color:#986801">10</span><span style="color:#999999">,</span> labels<span style="color:#a67f59">=</span><span style="color:#0184bb">False</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 方分箱及其他分箱方法的尝试
注:这里没有进行分箱
3.8 特征交互
参见引用文章
引用 Datawhale零基础入门金融风控 Task3 特征工程 观点
额,这里也懒得弄
3.9 特征选择
引用图片:https://blog.csdn.net/qq_38366112/article/details/114996847
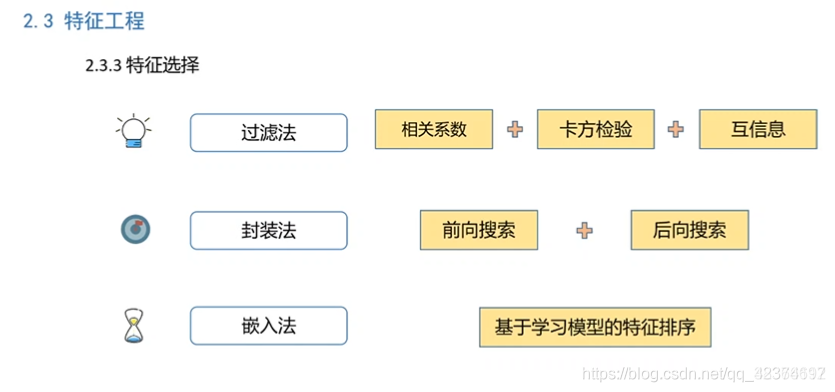
1.人工判断与目标无关联特征为"id",需删除
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#a67f59">=</span>train<span style="color:#999999">.</span>drop<span style="color:#999999">(</span><span style="color:#999999">[</span><span style="color:#50a14f">"id"</span><span style="color:#999999">]</span><span style="color:#999999">,</span>axis<span style="color:#a67f59">=</span><span style="color:#986801">1</span><span style="color:#999999">)</span>
train<span style="color:#999999">.</span>shape <span style="color:#708090"># (800000, 66)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">test<span style="color:#a67f59">=</span>test<span style="color:#999999">.</span>drop<span style="color:#999999">(</span><span style="color:#999999">[</span><span style="color:#50a14f">"id"</span><span style="color:#999999">]</span><span style="color:#999999">,</span>axis<span style="color:#a67f59">=</span><span style="color:#986801">1</span><span style="color:#999999">)</span>
test<span style="color:#999999">.</span>shape <span style="color:#708090"># (200000, 65)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
2.求出各个特征与目标的相关系数,综合考虑排除corr小于0.01的特征
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-sql">train<span style="color:#999999">.</span>corr<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">[</span><span style="color:#50a14f">"isDefault"</span><span style="color:#999999">]</span><span style="color:#999999">.</span>sort_values<span style="color:#999999">(</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码sql
- 1
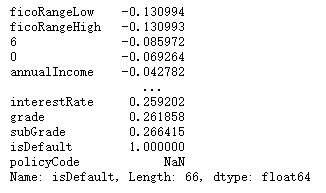
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#a67f59">=</span>train<span style="color:#999999">.</span>drop<span style="color:#999999">(</span><span style="color:#999999">[</span><span style="color:#50a14f">"initialListStatus"</span><span style="color:#999999">,</span><span style="color:#50a14f">"n5"</span><span style="color:#999999">,</span><span style="color:#50a14f">"n11"</span><span style="color:#999999">,</span><span style="color:#50a14f">"n12"</span><span style="color:#999999">,</span><span style="color:#50a14f">"n8"</span><span style="color:#999999">,</span><span style="color:#50a14f">"postCode"</span><span style="color:#999999">,</span><span style="color:#50a14f">"policyCode"</span><span style="color:#999999">]</span><span style="color:#999999">,</span>axis<span style="color:#a67f59">=</span><span style="color:#986801">1</span><span style="color:#999999">)</span>
test<span style="color:#a67f59">=</span>test<span style="color:#999999">.</span>drop<span style="color:#999999">(</span><span style="color:#999999">[</span><span style="color:#50a14f">"initialListStatus"</span><span style="color:#999999">,</span><span style="color:#50a14f">"n5"</span><span style="color:#999999">,</span><span style="color:#50a14f">"n11"</span><span style="color:#999999">,</span><span style="color:#50a14f">"n12"</span><span style="color:#999999">,</span><span style="color:#50a14f">"n8"</span><span style="color:#999999">,</span><span style="color:#50a14f">"postCode"</span><span style="color:#999999">,</span><span style="color:#50a14f">"policyCode"</span><span style="color:#999999">]</span><span style="color:#999999">,</span>axis<span style="color:#a67f59">=</span><span style="color:#986801">1</span><span style="color:#999999">)</span>
train<span style="color:#999999">.</span>shape<span style="color:#708090"># (800000, 59)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
删除特征"initialListStatus","n5","n11","n12","n8","postCode","policyCode",剩余59个特征
3.特征间高相关过滤
两两特征之间高于0.6的
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#708090"># 显示相关性高于0.6的变量</span>
<span style="color:#0077aa">def</span> <span style="color:#dd4a68">getHighRelatedFeatureDf</span><span style="color:#999999">(</span>corr_matrix<span style="color:#999999">,</span> corr_threshold<span style="color:#999999">)</span><span style="color:#999999">:</span>
highRelatedFeatureDf <span style="color:#a67f59">=</span> pd<span style="color:#999999">.</span>DataFrame<span style="color:#999999">(</span>corr_matrix<span style="color:#999999">[</span>corr_matrix<span style="color:#a67f59">></span>corr_threshold<span style="color:#999999">]</span><span style="color:#999999">.</span>stack<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">.</span>reset_index<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
highRelatedFeatureDf<span style="color:#999999">.</span>rename<span style="color:#999999">(</span><span style="color:#999999">{</span><span style="color:#50a14f">'level_0'</span><span style="color:#999999">:</span><span style="color:#50a14f">'feature_x'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'level_1'</span><span style="color:#999999">:</span><span style="color:#50a14f">'feature_y'</span><span style="color:#999999">,</span> <span style="color:#986801">0</span><span style="color:#999999">:</span><span style="color:#50a14f">'corr'</span><span style="color:#999999">}</span><span style="color:#999999">,</span> axis<span style="color:#a67f59">=</span><span style="color:#986801">1</span><span style="color:#999999">,</span> inplace<span style="color:#a67f59">=</span><span style="color:#0184bb">True</span><span style="color:#999999">)</span>
highRelatedFeatureDf <span style="color:#a67f59">=</span> highRelatedFeatureDf<span style="color:#999999">[</span>highRelatedFeatureDf<span style="color:#999999">.</span>feature_x <span style="color:#a67f59">!=</span> highRelatedFeatureDf<span style="color:#999999">.</span>feature_y<span style="color:#999999">]</span>
highRelatedFeatureDf<span style="color:#999999">[</span><span style="color:#50a14f">'feature_pair_key'</span><span style="color:#999999">]</span> <span style="color:#a67f59">=</span> highRelatedFeatureDf<span style="color:#999999">.</span>loc<span style="color:#999999">[</span><span style="color:#999999">:</span><span style="color:#999999">,</span><span style="color:#999999">[</span><span style="color:#50a14f">'feature_x'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'feature_y'</span><span style="color:#999999">]</span><span style="color:#999999">]</span><span style="color:#999999">.</span><span style="color:#50a14f">apply</span><span style="color:#999999">(</span><span style="color:#0077aa">lambda</span> r<span style="color:#999999">:</span><span style="color:#50a14f">'#'</span><span style="color:#999999">.</span>join<span style="color:#999999">(</span>np<span style="color:#999999">.</span>sort<span style="color:#999999">(</span>r<span style="color:#999999">.</span>values<span style="color:#999999">)</span><span style="color:#999999">)</span><span style="color:#999999">,</span> axis<span style="color:#a67f59">=</span><span style="color:#986801">1</span><span style="color:#999999">)</span>
highRelatedFeatureDf<span style="color:#999999">.</span>drop_duplicates<span style="color:#999999">(</span>subset<span style="color:#a67f59">=</span><span style="color:#999999">[</span><span style="color:#50a14f">'feature_pair_key'</span><span style="color:#999999">]</span><span style="color:#999999">,</span>inplace<span style="color:#a67f59">=</span><span style="color:#0184bb">True</span><span style="color:#999999">)</span>
highRelatedFeatureDf<span style="color:#999999">.</span>drop<span style="color:#999999">(</span><span style="color:#999999">[</span><span style="color:#50a14f">'feature_pair_key'</span><span style="color:#999999">]</span><span style="color:#999999">,</span> axis<span style="color:#a67f59">=</span><span style="color:#986801">1</span><span style="color:#999999">,</span> inplace<span style="color:#a67f59">=</span><span style="color:#0184bb">True</span><span style="color:#999999">)</span>
<span style="color:#0077aa">return</span> highRelatedFeatureDf
getHighRelatedFeatureDf<span style="color:#999999">(</span>train<span style="color:#999999">.</span>corr<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">,</span><span style="color:#986801">0.6</span><span style="color:#999999">)</span>
<span style="color:#50a14f">'''
feature_x feature_y corr
2 loanAmnt installment 0.953369
5 interestRate grade 0.953269
6 interestRate subGrade 0.970847
11 grade subGrade 0.993907
22 delinquency_2years n13 0.658946
24 ficoRangeLow ficoRangeHigh 1.000000
28 openAcc totalAcc 0.700796
29 openAcc n2 0.658807
30 openAcc n3 0.658807
31 openAcc n4 0.618207
32 openAcc n7 0.830624
33 openAcc n8 0.646342
34 openAcc n9 0.660917
35 openAcc n10 0.998717
37 pubRec pubRecBankruptcies 0.644402
44 totalAcc n5 0.623639
45 totalAcc n6 0.678482
46 totalAcc n8 0.761854
47 totalAcc n10 0.697192
53 n1 n2 0.807789
54 n1 n3 0.807789
55 n1 n4 0.829016
56 n1 n7 0.651852
57 n1 n9 0.800925
61 n2 n3 1.000000
62 n2 n4 0.663186
63 n2 n7 0.790337
64 n2 n9 0.982015
65 n2 n10 0.655296
70 n3 n4 0.663186
71 n3 n7 0.790337
72 n3 n9 0.982015
73 n3 n10 0.655296
79 n4 n5 0.717936
80 n4 n7 0.742157
81 n4 n9 0.639867
82 n4 n10 0.614658
86 n5 n7 0.618970
87 n5 n8 0.838066
97 n7 n8 0.774955
98 n7 n9 0.794465
99 n7 n10 0.829799
105 n8 n10 0.640729
113 n9 n10 0.660395
'''</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
结果分析:
1) "loanAmnt"贷款金额,"installment"分期付款金额两个特征间相关系数为0.95
2)"ficoRangeLow"fico所属的下限范围,"ficoRangeHigh"fico所属的上限范围两个特征间相关系数为1
3)"openAcc"未结信用额度的数量,"n10" 两个特征间相关系数为0.93
4)"n3","n2"两个特征间相关系数为1;"n3","n9" 两个特征间相关系数为0.98
根据高相关特征,综合考虑他们与目标的相关性,删除特征"installment","ficoRangeHigh","openAcc","n3","n9"
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">col <span style="color:#a67f59">=</span> <span style="color:#999999">[</span><span style="color:#50a14f">'installment'</span><span style="color:#999999">,</span><span style="color:#50a14f">'ficoRangeHigh'</span><span style="color:#999999">,</span><span style="color:#50a14f">'openAcc'</span><span style="color:#999999">,</span><span style="color:#50a14f">'n3'</span><span style="color:#999999">,</span><span style="color:#50a14f">'n9'</span><span style="color:#999999">]</span>
<span style="color:#0077aa">for</span> data <span style="color:#0077aa">in</span> <span style="color:#999999">[</span>train<span style="color:#999999">,</span>test<span style="color:#999999">]</span><span style="color:#999999">:</span>
data<span style="color:#999999">.</span>drop<span style="color:#999999">(</span>col<span style="color:#999999">,</span>axis<span style="color:#a67f59">=</span><span style="color:#986801">1</span><span style="color:#999999">,</span>inplace<span style="color:#a67f59">=</span><span style="color:#0184bb">True</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">.</span>shape <span style="color:#708090"># (800000, 54)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
其余高相关的特征可以使用PCA进行降维处理
(参考:https://zhuanlan.zhihu.com/p/255105477?utm_source=wechat_session)
注:这里不处理了
4.低方差过滤
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">.</span>var<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">.</span>sort_values<span style="color:#999999">(</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
结合相关性过滤方差小于0.1的特征"applicationType"
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">col <span style="color:#a67f59">=</span> <span style="color:#999999">[</span><span style="color:#50a14f">'applicationType'</span><span style="color:#999999">]</span>
<span style="color:#0077aa">for</span> data <span style="color:#0077aa">in</span> <span style="color:#999999">[</span>train<span style="color:#999999">,</span>test<span style="color:#999999">]</span><span style="color:#999999">:</span>
data<span style="color:#999999">.</span>drop<span style="color:#999999">(</span>col<span style="color:#999999">,</span>axis<span style="color:#a67f59">=</span><span style="color:#986801">1</span><span style="color:#999999">,</span>inplace<span style="color:#a67f59">=</span><span style="color:#0184bb">True</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">train<span style="color:#999999">.</span>shape <span style="color:#708090"># (800000, 53)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
总结
特征选择中对高相关性的特征进行删除、PCA降维,处理的可能不太合适,可尝试使用过滤法、包装法、嵌入法等特征选择方法进行特征的筛选
3.10 样本不平衡处理
若分类问题中各类别样本数量差距太大,则会造成样本不均衡的问题。样本不均衡不利于建立与训练出正确的模型,且不能做出合理的评估。
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">label<span style="color:#999999">.</span>value_counts<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#a67f59">/</span><span style="color:#50a14f">len</span><span style="color:#999999">(</span>label<span style="color:#999999">)</span>
<span style="color:#50a14f">'''
0 0.800488
1 0.199513
Name: isDefault, dtype: float64
'''</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
1.上采样
过抽样(也叫上采样、over-sampling)方法通过增加分类中少数类样本的数量来实现样本均衡,最直接的方法是简单复制少数类样本形成多条记录
参考:https://zhuanlan.zhihu.com/p/255105477?utm_source=wechat_session
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#0077aa">import</span> imblearn
<span style="color:#0077aa">from</span> imblearn<span style="color:#999999">.</span>over_sampling <span style="color:#0077aa">import</span> SMOTE
over_samples <span style="color:#a67f59">=</span> SMOTE<span style="color:#999999">(</span>random_state<span style="color:#a67f59">=</span><span style="color:#986801">1234</span><span style="color:#999999">)</span>
train_over<span style="color:#999999">,</span>label_over <span style="color:#a67f59">=</span> over_samples<span style="color:#999999">.</span>fit_sample<span style="color:#999999">(</span>train<span style="color:#999999">,</span> label<span style="color:#999999">)</span>
train_over<span style="color:#999999">.</span>to_csv<span style="color:#999999">(</span><span style="color:#50a14f">'train_over.csv'</span><span style="color:#999999">,</span>index<span style="color:#a67f59">=</span><span style="color:#0184bb">False</span><span style="color:#999999">)</span>
label_over<span style="color:#999999">.</span>to_csv<span style="color:#999999">(</span><span style="color:#50a14f">'label_over.csv'</span><span style="color:#999999">,</span>index<span style="color:#a67f59">=</span><span style="color:#0184bb">False</span><span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span>label_over<span style="color:#999999">.</span>value_counts<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#a67f59">/</span><span style="color:#50a14f">len</span><span style="color:#999999">(</span>label_over<span style="color:#999999">)</span><span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span>train_over<span style="color:#999999">.</span>shape<span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.下采样
欠抽样(也叫下采样、under-sampling)方法通过减少分类中多数类样本的样本数量来实现样本均衡,最直接的方法是随机地去掉一些多数类样本来减小多数类的规模
参考:https://zhuanlan.zhihu.com/p/255105477?utm_source=wechat_session
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#0077aa">from</span> imblearn<span style="color:#999999">.</span>under_sampling <span style="color:#0077aa">import</span> RandomUnderSampler
under_samples <span style="color:#a67f59">=</span> RandomUnderSampler<span style="color:#999999">(</span>random_state<span style="color:#a67f59">=</span><span style="color:#986801">1234</span><span style="color:#999999">)</span>
train_under<span style="color:#999999">,</span> label_under <span style="color:#a67f59">=</span> under_samples<span style="color:#999999">.</span>fit_sample<span style="color:#999999">(</span>train<span style="color:#999999">,</span>label<span style="color:#999999">)</span>
train_under<span style="color:#999999">.</span>to_csv<span style="color:#999999">(</span><span style="color:#50a14f">'train_under.csv'</span><span style="color:#999999">,</span>index<span style="color:#a67f59">=</span><span style="color:#0184bb">False</span><span style="color:#999999">)</span>
label_under<span style="color:#999999">.</span>to_csv<span style="color:#999999">(</span><span style="color:#50a14f">'label_under.csv'</span><span style="color:#999999">,</span>index<span style="color:#a67f59">=</span><span style="color:#0184bb">False</span><span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span>label_under<span style="color:#999999">.</span>value_counts<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#a67f59">/</span><span style="color:#50a14f">len</span><span style="color:#999999">(</span>label_under<span style="color:#999999">)</span><span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span>train_under<span style="color:#999999">.</span>shape<span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
注:这里没有进行采样,如果做了可以分别利用上采样后的数据跑模型和下采样后的数据跑模型
四、建模分析
在完成相关的特征处理后,接下来进行建模分析,通过调节参数得到性能更强的模型
4.1 LightGBM
参考:https://zhuanlan.zhihu.com/p/256310383
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">X <span style="color:#a67f59">=</span> train<span style="color:#999999">.</span>drop<span style="color:#999999">(</span><span style="color:#999999">[</span><span style="color:#50a14f">'isDefault'</span><span style="color:#999999">]</span><span style="color:#999999">,</span> axis<span style="color:#a67f59">=</span><span style="color:#986801">1</span><span style="color:#999999">)</span>
y <span style="color:#a67f59">=</span> train<span style="color:#999999">.</span>loc<span style="color:#999999">[</span><span style="color:#999999">:</span><span style="color:#999999">,</span><span style="color:#50a14f">'isDefault'</span><span style="color:#999999">]</span>
kf <span style="color:#a67f59">=</span> KFold<span style="color:#999999">(</span>n_splits<span style="color:#a67f59">=</span><span style="color:#986801">5</span><span style="color:#999999">,</span> shuffle<span style="color:#a67f59">=</span><span style="color:#0184bb">True</span><span style="color:#999999">,</span> random_state<span style="color:#a67f59">=</span><span style="color:#986801">525</span><span style="color:#999999">)</span>
X_train_split<span style="color:#999999">,</span> X_val<span style="color:#999999">,</span> y_train_split<span style="color:#999999">,</span> y_val <span style="color:#a67f59">=</span> train_test_split<span style="color:#999999">(</span>X<span style="color:#999999">,</span> y<span style="color:#999999">,</span> test_size<span style="color:#a67f59">=</span><span style="color:#986801">0.2</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
使用5折交叉验证法对数据进行验证和训练
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#0077aa">import</span> lightgbm <span style="color:#0077aa">as</span> lgb
cv_scores <span style="color:#a67f59">=</span> <span style="color:#999999">[</span><span style="color:#999999">]</span>
<span style="color:#0077aa">for</span> i<span style="color:#999999">,</span> <span style="color:#999999">(</span>train_index<span style="color:#999999">,</span> val_index<span style="color:#999999">)</span> <span style="color:#0077aa">in</span> <span style="color:#50a14f">enumerate</span><span style="color:#999999">(</span>kf<span style="color:#999999">.</span>split<span style="color:#999999">(</span>X<span style="color:#999999">,</span> y<span style="color:#999999">)</span><span style="color:#999999">)</span><span style="color:#999999">:</span>
X_train<span style="color:#999999">,</span> y_train<span style="color:#999999">,</span> X_val<span style="color:#999999">,</span> y_val <span style="color:#a67f59">=</span> X<span style="color:#999999">.</span>iloc<span style="color:#999999">[</span>train_index<span style="color:#999999">]</span><span style="color:#999999">,</span> y<span style="color:#999999">.</span>iloc<span style="color:#999999">[</span>train_index<span style="color:#999999">]</span><span style="color:#999999">,</span> X<span style="color:#999999">.</span>iloc<span style="color:#999999">[</span>val_index<span style="color:#999999">]</span><span style="color:#999999">,</span> y<span style="color:#999999">.</span>iloc<span style="color:#999999">[</span>val_index<span style="color:#999999">]</span>
train_matrix <span style="color:#a67f59">=</span> lgb<span style="color:#999999">.</span>Dataset<span style="color:#999999">(</span>X_train<span style="color:#999999">,</span> label<span style="color:#a67f59">=</span>y_train<span style="color:#999999">)</span>
valid_matrix <span style="color:#a67f59">=</span> lgb<span style="color:#999999">.</span>Dataset<span style="color:#999999">(</span>X_val<span style="color:#999999">,</span> label<span style="color:#a67f59">=</span>y_val<span style="color:#999999">)</span>
params <span style="color:#a67f59">=</span> <span style="color:#999999">{</span>
<span style="color:#50a14f">'boosting_type'</span><span style="color:#999999">:</span> <span style="color:#50a14f">'gbdt'</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'objective'</span><span style="color:#999999">:</span> <span style="color:#50a14f">'binary'</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'learning_rate'</span><span style="color:#999999">:</span> <span style="color:#986801">0.1</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'metric'</span><span style="color:#999999">:</span> <span style="color:#50a14f">'auc'</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'min_child_weight'</span><span style="color:#999999">:</span> <span style="color:#986801">1e</span><span style="color:#a67f59">-</span><span style="color:#986801">3</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'num_leaves'</span><span style="color:#999999">:</span> <span style="color:#986801">31</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'max_depth'</span><span style="color:#999999">:</span> <span style="color:#a67f59">-</span><span style="color:#986801">1</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'seed'</span><span style="color:#999999">:</span> <span style="color:#986801">525</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'nthread'</span><span style="color:#999999">:</span> <span style="color:#986801">8</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'silent'</span><span style="color:#999999">:</span> <span style="color:#0184bb">True</span><span style="color:#999999">,</span>
<span style="color:#999999">}</span>
model <span style="color:#a67f59">=</span> lgb<span style="color:#999999">.</span>train<span style="color:#999999">(</span>params<span style="color:#999999">,</span> train_set<span style="color:#a67f59">=</span>train_matrix<span style="color:#999999">,</span> num_boost_round<span style="color:#a67f59">=</span><span style="color:#986801">20000</span><span style="color:#999999">,</span> valid_sets<span style="color:#a67f59">=</span>valid_matrix<span style="color:#999999">,</span> verbose_eval<span style="color:#a67f59">=</span><span style="color:#986801">1000</span><span style="color:#999999">,</span> early_stopping_rounds<span style="color:#a67f59">=</span><span style="color:#986801">200</span><span style="color:#999999">)</span>
val_pred <span style="color:#a67f59">=</span> model<span style="color:#999999">.</span>predict<span style="color:#999999">(</span>X_val<span style="color:#999999">,</span> num_iteration<span style="color:#a67f59">=</span>model<span style="color:#999999">.</span>best_iteration<span style="color:#999999">)</span>
cv_scores<span style="color:#999999">.</span>append<span style="color:#999999">(</span>roc_auc_score<span style="color:#999999">(</span>y_val<span style="color:#999999">,</span> val_pred<span style="color:#999999">)</span><span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span>cv_scores<span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span><span style="color:#50a14f">"lgb_scotrainre_list:{}"</span><span style="color:#999999">.</span><span style="color:#50a14f">format</span><span style="color:#999999">(</span>cv_scores<span style="color:#999999">)</span><span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span><span style="color:#50a14f">"lgb_score_mean:{}"</span><span style="color:#999999">.</span><span style="color:#50a14f">format</span><span style="color:#999999">(</span>np<span style="color:#999999">.</span>mean<span style="color:#999999">(</span>cv_scores<span style="color:#999999">)</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span><span style="color:#50a14f">"lgb_score_std:{}"</span><span style="color:#999999">.</span><span style="color:#50a14f">format</span><span style="color:#999999">(</span>np<span style="color:#999999">.</span>std<span style="color:#999999">(</span>cv_scores<span style="color:#999999">)</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
lgb_scotrainre_list:0.7303837315833632, 0.7258692125145638, 0.7305149209921737, 0.7296117869375041, 0.7294438695369077
lgb_score_mean:0.7291647043129024
lgb_score_std:0.0016998349834934656
ROC曲线
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#0077aa">from</span> sklearn <span style="color:#0077aa">import</span> metrics
<span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>metrics <span style="color:#0077aa">import</span> roc_auc_score
al_pre_lgb <span style="color:#a67f59">=</span> model<span style="color:#999999">.</span>predict<span style="color:#999999">(</span>X_val<span style="color:#999999">,</span> num_iteration<span style="color:#a67f59">=</span>model<span style="color:#999999">.</span>best_iteration<span style="color:#999999">)</span>
fpr<span style="color:#999999">,</span> tpr<span style="color:#999999">,</span> threshold <span style="color:#a67f59">=</span> metrics<span style="color:#999999">.</span>roc_curve<span style="color:#999999">(</span>y_val<span style="color:#999999">,</span> val_pred<span style="color:#999999">)</span>
roc_auc <span style="color:#a67f59">=</span> metrics<span style="color:#999999">.</span>auc<span style="color:#999999">(</span>fpr<span style="color:#999999">,</span> tpr<span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span><span style="color:#50a14f">'AUC:{}'</span><span style="color:#999999">.</span><span style="color:#50a14f">format</span><span style="color:#999999">(</span>roc_auc<span style="color:#999999">)</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>figure<span style="color:#999999">(</span>figsize<span style="color:#a67f59">=</span><span style="color:#999999">(</span><span style="color:#986801">8</span><span style="color:#999999">,</span> <span style="color:#986801">8</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>title<span style="color:#999999">(</span><span style="color:#50a14f">'Validation ROC'</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>plot<span style="color:#999999">(</span>fpr<span style="color:#999999">,</span> tpr<span style="color:#999999">,</span> <span style="color:#50a14f">'b'</span><span style="color:#999999">,</span> label <span style="color:#a67f59">=</span> <span style="color:#50a14f">'Val AUC = %0.4f'</span> <span style="color:#a67f59">%</span> roc_auc<span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>ylim<span style="color:#999999">(</span><span style="color:#986801">0</span><span style="color:#999999">,</span><span style="color:#986801">1</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>xlim<span style="color:#999999">(</span><span style="color:#986801">0</span><span style="color:#999999">,</span><span style="color:#986801">1</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>legend<span style="color:#999999">(</span>loc<span style="color:#a67f59">=</span><span style="color:#50a14f">'best'</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>title<span style="color:#999999">(</span><span style="color:#50a14f">'ROC'</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>ylabel<span style="color:#999999">(</span><span style="color:#50a14f">'True Positive Rate'</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>xlabel<span style="color:#999999">(</span><span style="color:#50a14f">'False Positive Rate'</span><span style="color:#999999">)</span>
<span style="color:#708090"># 画出对角线</span>
plt<span style="color:#999999">.</span>plot<span style="color:#999999">(</span><span style="color:#999999">[</span><span style="color:#986801">0</span><span style="color:#999999">,</span><span style="color:#986801">1</span><span style="color:#999999">]</span><span style="color:#999999">,</span><span style="color:#999999">[</span><span style="color:#986801">0</span><span style="color:#999999">,</span><span style="color:#986801">1</span><span style="color:#999999">]</span><span style="color:#999999">,</span><span style="color:#50a14f">'r--'</span><span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>show<span style="color:#999999">(</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
AUC得分为0.7338
4.2 XGBoost
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">X <span style="color:#a67f59">=</span> train<span style="color:#999999">.</span>drop<span style="color:#999999">(</span><span style="color:#999999">[</span><span style="color:#50a14f">'isDefault'</span><span style="color:#999999">]</span><span style="color:#999999">,</span> axis<span style="color:#a67f59">=</span><span style="color:#986801">1</span><span style="color:#999999">)</span>
y <span style="color:#a67f59">=</span> train<span style="color:#999999">.</span>loc<span style="color:#999999">[</span><span style="color:#999999">:</span><span style="color:#999999">,</span><span style="color:#50a14f">'isDefault'</span><span style="color:#999999">]</span>
Xtrain<span style="color:#999999">,</span> Xtest<span style="color:#999999">,</span> Ytrain<span style="color:#999999">,</span> Ytest <span style="color:#a67f59">=</span> train_test_split<span style="color:#999999">(</span>X<span style="color:#999999">,</span>y<span style="color:#999999">,</span>test_size<span style="color:#a67f59">=</span><span style="color:#986801">0.3</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
用XGBClassifier模型跑一下(具体的xgboost 参数设置可以参考官网)
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#0077aa">from</span> xgboost<span style="color:#999999">.</span>sklearn <span style="color:#0077aa">import</span> XGBClassifier
clf1 <span style="color:#a67f59">=</span> XGBClassifier<span style="color:#999999">(</span>n_jobs<span style="color:#a67f59">=</span><span style="color:#a67f59">-</span><span style="color:#986801">1</span><span style="color:#999999">)</span>
clf1<span style="color:#999999">.</span>fit<span style="color:#999999">(</span>Xtrain<span style="color:#999999">,</span>Ytrain<span style="color:#999999">)</span>
clf1<span style="color:#999999">.</span>score<span style="color:#999999">(</span>Xtest<span style="color:#999999">,</span>Ytest<span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
0.8068791666666667
计算模型结构的AUC面积
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>metrics <span style="color:#0077aa">import</span> roc_curve<span style="color:#999999">,</span> auc
predict_proba <span style="color:#a67f59">=</span> clf1<span style="color:#999999">.</span>predict_proba<span style="color:#999999">(</span>Xtest<span style="color:#999999">)</span>
false_positive_rate<span style="color:#999999">,</span> true_positive_rate<span style="color:#999999">,</span> thresholds <span style="color:#a67f59">=</span> roc_curve<span style="color:#999999">(</span>Ytest<span style="color:#999999">,</span> predict_proba<span style="color:#999999">[</span><span style="color:#999999">:</span><span style="color:#999999">,</span><span style="color:#986801">1</span><span style="color:#999999">]</span><span style="color:#999999">)</span>
auc<span style="color:#999999">(</span>false_positive_rate<span style="color:#999999">,</span> true_positive_rate<span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
0.7326304866618416
4.3 三个模型比较
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">gra<span style="color:#a67f59">=</span>GradientBoostingClassifier<span style="color:#999999">(</span><span style="color:#999999">)</span>
xgb<span style="color:#a67f59">=</span>XGBClassifier<span style="color:#999999">(</span><span style="color:#999999">)</span>
lgb<span style="color:#a67f59">=</span>LGBMClassifier<span style="color:#999999">(</span><span style="color:#999999">)</span>
models<span style="color:#a67f59">=</span><span style="color:#999999">[</span>gra<span style="color:#999999">,</span>xgb<span style="color:#999999">,</span>lgb<span style="color:#999999">]</span>
model_names<span style="color:#a67f59">=</span><span style="color:#999999">[</span><span style="color:#50a14f">"gra"</span><span style="color:#999999">,</span><span style="color:#50a14f">"xgb"</span><span style="color:#999999">,</span><span style="color:#50a14f">"lgb"</span><span style="color:#999999">]</span>
<span style="color:#708090">#交叉验证看看上述3个算法评分</span>
<span style="color:#0077aa">for</span> i<span style="color:#999999">,</span>model <span style="color:#0077aa">in</span> <span style="color:#50a14f">enumerate</span><span style="color:#999999">(</span>models<span style="color:#999999">)</span><span style="color:#999999">:</span>
score<span style="color:#a67f59">=</span>cross_val_score<span style="color:#999999">(</span>model<span style="color:#999999">,</span>X<span style="color:#999999">,</span>y<span style="color:#999999">,</span>cv<span style="color:#a67f59">=</span><span style="color:#986801">5</span><span style="color:#999999">,</span>scoring<span style="color:#a67f59">=</span><span style="color:#50a14f">"accuracy"</span><span style="color:#999999">,</span>n_jobs<span style="color:#a67f59">=</span><span style="color:#a67f59">-</span><span style="color:#986801">1</span><span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span>model_names<span style="color:#999999">[</span>i<span style="color:#999999">]</span><span style="color:#999999">,</span>np<span style="color:#999999">.</span>array<span style="color:#999999">(</span>score<span style="color:#999999">)</span><span style="color:#999999">.</span><span style="color:#50a14f">round</span><span style="color:#999999">(</span><span style="color:#986801">3</span><span style="color:#999999">)</span><span style="color:#999999">,</span><span style="color:#50a14f">round</span><span style="color:#999999">(</span>score<span style="color:#999999">.</span>mean<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">,</span><span style="color:#986801">3</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
其他建模方法
参见:
金融风控-贷款违约预测
数据竞赛入门-金融风控(贷款违约预测)四、建模与调参
以及
尝试多种模型

五、模型调参
5.1 调参方法
(1)贪心调参
参考:https://www.jianshu.com/p/cdf0a9ffec6f
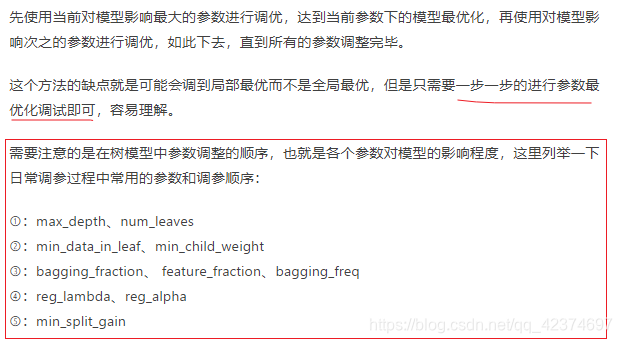
(2)网格搜索
参考:https://www.jianshu.com/p/cdf0a9ffec6f
sklearn 提供GridSearchCV用于进行网格搜索,只需要把模型的参数输进去,就能给出最优化的结果和参数。相比起贪心调参,网格搜索的结果会更优,但是网格搜索只适合于小数据集,一旦数据的量级上去了,很难得出结果。
(3)贝叶斯调参
参考:https://www.jianshu.com/p/cdf0a9ffec6f
贝叶斯调参的主要思想是:给定优化的目标函数(广义的函数,只需指定输入和输出即可,无需知道内部结构以及数学性质),通过不断地添加样本点来更新目标函数的后验分布(高斯过程,直到后验分布基本贴合于真实分布)。简单的说,就是考虑了上一次参数的信息,从而更好的调整当前的参数。
5.2 XGboost调参
参考:https://zhuanlan.zhihu.com/p/255105477?utm_source=wechat_session
1.优化max_depth,min_child_weight
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#0077aa">from</span> xgboost<span style="color:#999999">.</span>sklearn <span style="color:#0077aa">import</span> XGBClassifier
<span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>model_selection <span style="color:#0077aa">import</span> GridSearchCV
<span style="color:#708090"># 其余参数</span>
other_params <span style="color:#a67f59">=</span> <span style="color:#999999">{</span><span style="color:#50a14f">'learning_rate'</span><span style="color:#999999">:</span> <span style="color:#986801">0.1</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'n_estimators'</span><span style="color:#999999">:</span> <span style="color:#986801">100</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'max_depth'</span><span style="color:#999999">:</span> <span style="color:#986801">5</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'min_child_weight'</span><span style="color:#999999">:</span> <span style="color:#986801">1</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'seed'</span><span style="color:#999999">:</span> <span style="color:#986801">0</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'subsample'</span><span style="color:#999999">:</span> <span style="color:#986801">0.8</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'colsample_bytree'</span><span style="color:#999999">:</span> <span style="color:#986801">0.8</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'gamma'</span><span style="color:#999999">:</span> <span style="color:#986801">0</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'reg_alpha'</span><span style="color:#999999">:</span> <span style="color:#986801">0</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'reg_lambda'</span><span style="color:#999999">:</span> <span style="color:#986801">1</span><span style="color:#999999">}</span>
<span style="color:#708090"># 待调参数</span>
param_test1 <span style="color:#a67f59">=</span> <span style="color:#999999">{</span>
<span style="color:#50a14f">'max_depth'</span><span style="color:#999999">:</span><span style="color:#50a14f">list</span><span style="color:#999999">(</span><span style="color:#50a14f">range</span><span style="color:#999999">(</span><span style="color:#986801">4</span><span style="color:#999999">,</span><span style="color:#986801">9</span><span style="color:#999999">,</span><span style="color:#986801">2</span><span style="color:#999999">)</span><span style="color:#999999">)</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'min_child_weight'</span><span style="color:#999999">:</span><span style="color:#50a14f">list</span><span style="color:#999999">(</span><span style="color:#50a14f">range</span><span style="color:#999999">(</span><span style="color:#986801">1</span><span style="color:#999999">,</span><span style="color:#986801">6</span><span style="color:#999999">,</span><span style="color:#986801">2</span><span style="color:#999999">)</span><span style="color:#999999">)</span>
<span style="color:#999999">}</span>
xgb1 <span style="color:#a67f59">=</span> XGBClassifier<span style="color:#999999">(</span><span style="color:#a67f59">**</span>other_params<span style="color:#999999">)</span>
<span style="color:#708090"># 网格搜索</span>
gs1 <span style="color:#a67f59">=</span> GridSearchCV<span style="color:#999999">(</span>xgb1<span style="color:#999999">,</span>param_test1<span style="color:#999999">,</span>cv <span style="color:#a67f59">=</span> <span style="color:#986801">5</span><span style="color:#999999">,</span>scoring <span style="color:#a67f59">=</span> <span style="color:#50a14f">'roc_auc'</span><span style="color:#999999">,</span>n_jobs <span style="color:#a67f59">=</span> <span style="color:#a67f59">-</span><span style="color:#986801">1</span><span style="color:#999999">,</span>verbose<span style="color:#a67f59">=</span><span style="color:#986801">2</span><span style="color:#999999">)</span>
best_model1<span style="color:#a67f59">=</span>gs1<span style="color:#999999">.</span>fit<span style="color:#999999">(</span>Xtrain<span style="color:#999999">,</span>Ytrain<span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span><span style="color:#50a14f">'最优参数:'</span><span style="color:#999999">,</span>best_model1<span style="color:#999999">.</span>best_params_<span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span><span style="color:#50a14f">'最佳模型得分:'</span><span style="color:#999999">,</span>best_model1<span style="color:#999999">.</span>best_score_<span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
最优参数:{'max_depth':4,,'min-childweight':5}
最佳模型得分:0.7185495198261862
2.优化gamma参数
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">other_params <span style="color:#a67f59">=</span> <span style="color:#999999">{</span><span style="color:#50a14f">'learning_rate'</span><span style="color:#999999">:</span> <span style="color:#986801">0.1</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'n_estimators'</span><span style="color:#999999">:</span> <span style="color:#986801">100</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'max_depth'</span><span style="color:#999999">:</span> <span style="color:#986801">4</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'min_child_weight'</span><span style="color:#999999">:</span> <span style="color:#986801">5</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'seed'</span><span style="color:#999999">:</span> <span style="color:#986801">0</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'subsample'</span><span style="color:#999999">:</span> <span style="color:#986801">0.8</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'colsample_bytree'</span><span style="color:#999999">:</span> <span style="color:#986801">0.8</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'gamma'</span><span style="color:#999999">:</span> <span style="color:#986801">0</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'reg_alpha'</span><span style="color:#999999">:</span> <span style="color:#986801">0</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'reg_lambda'</span><span style="color:#999999">:</span> <span style="color:#986801">1</span><span style="color:#999999">}</span>
param_test <span style="color:#a67f59">=</span> <span style="color:#999999">{</span>
<span style="color:#50a14f">'gaama'</span><span style="color:#999999">:</span><span style="color:#999999">[</span><span style="color:#986801">0</span><span style="color:#999999">,</span><span style="color:#986801">0.05</span><span style="color:#999999">,</span><span style="color:#986801">0.1</span><span style="color:#999999">,</span><span style="color:#986801">0.2</span><span style="color:#999999">,</span><span style="color:#986801">0.3</span><span style="color:#999999">]</span>
<span style="color:#999999">}</span>
xgb <span style="color:#a67f59">=</span> XGBClassifier<span style="color:#999999">(</span><span style="color:#a67f59">**</span>other_params<span style="color:#999999">)</span>
gs <span style="color:#a67f59">=</span> GridSearchCV<span style="color:#999999">(</span>xgb<span style="color:#999999">,</span>param_test<span style="color:#999999">,</span>cv <span style="color:#a67f59">=</span> <span style="color:#986801">5</span><span style="color:#999999">,</span>scoring <span style="color:#a67f59">=</span> <span style="color:#50a14f">'roc_auc'</span><span style="color:#999999">,</span>n_jobs <span style="color:#a67f59">=</span> <span style="color:#a67f59">-</span><span style="color:#986801">1</span><span style="color:#999999">,</span>verbose<span style="color:#a67f59">=</span><span style="color:#986801">2</span><span style="color:#999999">)</span>
best_model<span style="color:#a67f59">=</span>gs<span style="color:#999999">.</span>fit<span style="color:#999999">(</span>Xtrain<span style="color:#999999">,</span>Ytrain<span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span><span style="color:#50a14f">'最优参数:'</span><span style="color:#999999">,</span>best_model<span style="color:#999999">.</span>best_params_<span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span><span style="color:#50a14f">'最佳模型得分:'</span><span style="color:#999999">,</span>best_model<span style="color:#999999">.</span>best_score_<span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
最优参数:{'gaama':0}
最模得分:0.7185495198261862
3.subsample和colsample_bytree
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">other_params <span style="color:#a67f59">=</span> <span style="color:#999999">{</span><span style="color:#50a14f">'learning_rate'</span><span style="color:#999999">:</span> <span style="color:#986801">0.1</span><span style="color:#999999">,</span> <span style="color:#50a14f">'n_estimators'</span><span style="color:#999999">:</span> <span style="color:#986801">100</span><span style="color:#999999">,</span> <span style="color:#50a14f">'max_depth'</span><span style="color:#999999">:</span> <span style="color:#986801">4</span><span style="color:#999999">,</span> <span style="color:#50a14f">'min_child_weight'</span><span style="color:#999999">:</span> <span style="color:#986801">5</span><span style="color:#999999">,</span> <span style="color:#50a14f">'seed'</span><span style="color:#999999">:</span> <span style="color:#986801">0</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'subsample'</span><span style="color:#999999">:</span> <span style="color:#986801">0.8</span><span style="color:#999999">,</span> <span style="color:#50a14f">'colsample_bytree'</span><span style="color:#999999">:</span> <span style="color:#986801">0.8</span><span style="color:#999999">,</span> <span style="color:#50a14f">'gamma'</span><span style="color:#999999">:</span> <span style="color:#986801">0</span><span style="color:#999999">,</span> <span style="color:#50a14f">'reg_alpha'</span><span style="color:#999999">:</span> <span style="color:#986801">0</span><span style="color:#999999">,</span> <span style="color:#50a14f">'reg_lambda'</span><span style="color:#999999">:</span> <span style="color:#986801">1</span><span style="color:#999999">}</span>
param_test <span style="color:#a67f59">=</span> <span style="color:#999999">{</span>
<span style="color:#50a14f">'subsample'</span><span style="color:#999999">:</span><span style="color:#999999">[</span><span style="color:#986801">0.6</span><span style="color:#999999">,</span><span style="color:#986801">0.7</span><span style="color:#999999">,</span><span style="color:#986801">0.8</span><span style="color:#999999">,</span><span style="color:#986801">0.9</span><span style="color:#999999">]</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'colsample_bytree'</span><span style="color:#999999">:</span><span style="color:#999999">[</span><span style="color:#986801">0.6</span><span style="color:#999999">,</span><span style="color:#986801">0.7</span><span style="color:#999999">,</span><span style="color:#986801">0.8</span><span style="color:#999999">,</span><span style="color:#986801">0.9</span><span style="color:#999999">]</span>
<span style="color:#999999">}</span>
xgb <span style="color:#a67f59">=</span> XGBClassifier<span style="color:#999999">(</span><span style="color:#a67f59">**</span>other_params<span style="color:#999999">)</span>
gs <span style="color:#a67f59">=</span> GridSearchCV<span style="color:#999999">(</span>xgb<span style="color:#999999">,</span>param_test<span style="color:#999999">,</span>cv <span style="color:#a67f59">=</span> <span style="color:#986801">5</span><span style="color:#999999">,</span>scoring <span style="color:#a67f59">=</span> <span style="color:#50a14f">'roc_auc'</span><span style="color:#999999">,</span>n_jobs <span style="color:#a67f59">=</span> <span style="color:#a67f59">-</span><span style="color:#986801">1</span><span style="color:#999999">,</span>verbose<span style="color:#a67f59">=</span><span style="color:#986801">2</span><span style="color:#999999">)</span>
best_model<span style="color:#a67f59">=</span>gs<span style="color:#999999">.</span>fit<span style="color:#999999">(</span>Xtrain<span style="color:#999999">,</span>Ytrain<span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span><span style="color:#50a14f">'最优参数:'</span><span style="color:#999999">,</span>best_model<span style="color:#999999">.</span>best_params_<span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span><span style="color:#50a14f">'最佳模型得分:'</span><span style="color:#999999">,</span>best_model<span style="color:#999999">.</span>best_score_<span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
最优参数:{'colsample-bytree':0.7,'subsample':0.7}
最佳模得分:0.7187964885978947
4.reg_alpha和reg_lambda
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">other_params <span style="color:#a67f59">=</span> <span style="color:#999999">{</span><span style="color:#50a14f">'learning_rate'</span><span style="color:#999999">:</span> <span style="color:#986801">0.1</span><span style="color:#999999">,</span> <span style="color:#50a14f">'n_estimators'</span><span style="color:#999999">:</span> <span style="color:#986801">100</span><span style="color:#999999">,</span> <span style="color:#50a14f">'max_depth'</span><span style="color:#999999">:</span> <span style="color:#986801">4</span><span style="color:#999999">,</span> <span style="color:#50a14f">'min_child_weight'</span><span style="color:#999999">:</span> <span style="color:#986801">5</span><span style="color:#999999">,</span> <span style="color:#50a14f">'seed'</span><span style="color:#999999">:</span> <span style="color:#986801">0</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'subsample'</span><span style="color:#999999">:</span> <span style="color:#986801">0.7</span><span style="color:#999999">,</span> <span style="color:#50a14f">'colsample_bytree'</span><span style="color:#999999">:</span> <span style="color:#986801">0.7</span><span style="color:#999999">,</span> <span style="color:#50a14f">'gamma'</span><span style="color:#999999">:</span> <span style="color:#986801">0</span><span style="color:#999999">,</span> <span style="color:#50a14f">'reg_alpha'</span><span style="color:#999999">:</span> <span style="color:#986801">0</span><span style="color:#999999">,</span> <span style="color:#50a14f">'reg_lambda'</span><span style="color:#999999">:</span> <span style="color:#986801">1</span><span style="color:#999999">}</span>
param_test <span style="color:#a67f59">=</span> <span style="color:#999999">{</span>
<span style="color:#50a14f">'reg_alpha'</span><span style="color:#999999">:</span> <span style="color:#999999">[</span><span style="color:#986801">4</span><span style="color:#999999">,</span><span style="color:#986801">5</span><span style="color:#999999">,</span><span style="color:#986801">6</span><span style="color:#999999">,</span><span style="color:#986801">7</span><span style="color:#999999">]</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'reg_lambda'</span><span style="color:#999999">:</span> <span style="color:#999999">[</span><span style="color:#986801">0</span><span style="color:#999999">,</span><span style="color:#986801">0.01</span><span style="color:#999999">,</span><span style="color:#986801">0.05</span><span style="color:#999999">,</span> <span style="color:#986801">0.1</span><span style="color:#999999">]</span>
<span style="color:#999999">}</span>
xgb <span style="color:#a67f59">=</span> XGBClassifier<span style="color:#999999">(</span><span style="color:#a67f59">**</span>other_params<span style="color:#999999">)</span>
gs <span style="color:#a67f59">=</span> GridSearchCV<span style="color:#999999">(</span>xgb<span style="color:#999999">,</span>param_test<span style="color:#999999">,</span>cv <span style="color:#a67f59">=</span> <span style="color:#986801">5</span><span style="color:#999999">,</span>scoring <span style="color:#a67f59">=</span> <span style="color:#50a14f">'roc_auc'</span><span style="color:#999999">,</span>n_jobs <span style="color:#a67f59">=</span> <span style="color:#a67f59">-</span><span style="color:#986801">1</span><span style="color:#999999">,</span>verbose<span style="color:#a67f59">=</span><span style="color:#986801">2</span><span style="color:#999999">)</span>
best_model<span style="color:#a67f59">=</span>gs<span style="color:#999999">.</span>fit<span style="color:#999999">(</span>Xtrain<span style="color:#999999">,</span>Ytrain<span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span><span style="color:#50a14f">'最优参数:'</span><span style="color:#999999">,</span>best_model<span style="color:#999999">.</span>best_params_<span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span><span style="color:#50a14f">'最佳模型得分:'</span><span style="color:#999999">,</span>best_model<span style="color:#999999">.</span>best_score_<span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
最优参数:{'reg-alpha':5,'reg-lambda':0.01}
最佳模型得分:0.7194153615536154
5. learning_rate和n_estimators
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python">other_params <span style="color:#a67f59">=</span> <span style="color:#999999">{</span><span style="color:#50a14f">'learning_rate'</span><span style="color:#999999">:</span> <span style="color:#986801">0.1</span><span style="color:#999999">,</span> <span style="color:#50a14f">'n_estimators'</span><span style="color:#999999">:</span> <span style="color:#986801">100</span><span style="color:#999999">,</span> <span style="color:#50a14f">'max_depth'</span><span style="color:#999999">:</span> <span style="color:#986801">4</span><span style="color:#999999">,</span> <span style="color:#50a14f">'min_child_weight'</span><span style="color:#999999">:</span> <span style="color:#986801">5</span><span style="color:#999999">,</span> <span style="color:#50a14f">'seed'</span><span style="color:#999999">:</span> <span style="color:#986801">0</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'subsample'</span><span style="color:#999999">:</span> <span style="color:#986801">0.7</span><span style="color:#999999">,</span> <span style="color:#50a14f">'colsample_bytree'</span><span style="color:#999999">:</span> <span style="color:#986801">0.7</span><span style="color:#999999">,</span> <span style="color:#50a14f">'gamma'</span><span style="color:#999999">:</span> <span style="color:#986801">0</span><span style="color:#999999">,</span> <span style="color:#50a14f">'reg_alpha'</span><span style="color:#999999">:</span> <span style="color:#986801">5</span><span style="color:#999999">,</span> <span style="color:#50a14f">'reg_lambda'</span><span style="color:#999999">:</span> <span style="color:#986801">0.01</span><span style="color:#999999">}</span>
param_test <span style="color:#a67f59">=</span> <span style="color:#999999">{</span>
<span style="color:#50a14f">'learning_rate'</span><span style="color:#999999">:</span> <span style="color:#999999">[</span><span style="color:#986801">0.01</span><span style="color:#999999">,</span> <span style="color:#986801">0.05</span><span style="color:#999999">,</span> <span style="color:#986801">0.07</span><span style="color:#999999">,</span> <span style="color:#986801">0.1</span><span style="color:#999999">,</span> <span style="color:#986801">0.2</span><span style="color:#999999">]</span><span style="color:#999999">,</span>
<span style="color:#50a14f">'n_estimators'</span><span style="color:#999999">:</span> <span style="color:#999999">[</span><span style="color:#986801">100</span><span style="color:#999999">,</span><span style="color:#986801">200</span><span style="color:#999999">,</span><span style="color:#986801">300</span><span style="color:#999999">,</span><span style="color:#986801">400</span><span style="color:#999999">,</span><span style="color:#986801">500</span><span style="color:#999999">]</span>
<span style="color:#999999">}</span>
xgb <span style="color:#a67f59">=</span> XGBClassifier<span style="color:#999999">(</span><span style="color:#a67f59">**</span>other_params<span style="color:#999999">)</span>
gs <span style="color:#a67f59">=</span> GridSearchCV<span style="color:#999999">(</span>xgb<span style="color:#999999">,</span>param_test<span style="color:#999999">,</span>cv <span style="color:#a67f59">=</span> <span style="color:#986801">5</span><span style="color:#999999">,</span>scoring <span style="color:#a67f59">=</span> <span style="color:#50a14f">'roc_auc'</span><span style="color:#999999">,</span>n_jobs <span style="color:#a67f59">=</span> <span style="color:#a67f59">-</span><span style="color:#986801">1</span><span style="color:#999999">,</span>verbose<span style="color:#a67f59">=</span><span style="color:#986801">2</span><span style="color:#999999">)</span>
best_model<span style="color:#a67f59">=</span>gs<span style="color:#999999">.</span>fit<span style="color:#999999">(</span>Xtrain<span style="color:#999999">,</span>Ytrain<span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span><span style="color:#50a14f">'最优参数:'</span><span style="color:#999999">,</span>best_model<span style="color:#999999">.</span>best_params_<span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span><span style="color:#50a14f">'最佳模型得分:'</span><span style="color:#999999">,</span>best_model<span style="color:#999999">.</span>best_score_<span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
最优参数:{'learning-rate':0.05,'n-estimators':400}
最佳模型得分:0.7207082359918353
通过调参后的最终模型
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#0077aa">from</span> xgboost<span style="color:#999999">.</span>sklearn <span style="color:#0077aa">import</span> XGBClassifier
clf <span style="color:#a67f59">=</span> XGBClassifier<span style="color:#999999">(</span>
learning_rate<span style="color:#a67f59">=</span> <span style="color:#986801">0.05</span><span style="color:#999999">,</span>
n_estimators<span style="color:#a67f59">=</span> <span style="color:#986801">400</span><span style="color:#999999">,</span>
max_depth<span style="color:#a67f59">=</span> <span style="color:#986801">4</span><span style="color:#999999">,</span>
min_child_weight<span style="color:#a67f59">=</span> <span style="color:#986801">5</span><span style="color:#999999">,</span>
seed<span style="color:#a67f59">=</span> <span style="color:#986801">0</span><span style="color:#999999">,</span>
subsample<span style="color:#a67f59">=</span> <span style="color:#986801">0.7</span><span style="color:#999999">,</span>
colsample_bytree<span style="color:#a67f59">=</span> <span style="color:#986801">0.7</span><span style="color:#999999">,</span>
gamma<span style="color:#a67f59">=</span> <span style="color:#986801">0</span><span style="color:#999999">,</span>
reg_alpha<span style="color:#a67f59">=</span> <span style="color:#986801">5</span><span style="color:#999999">,</span>
reg_lambda<span style="color:#a67f59">=</span><span style="color:#986801">0.01</span><span style="color:#999999">,</span>
n_jobs <span style="color:#a67f59">=</span> <span style="color:#a67f59">-</span><span style="color:#986801">1</span><span style="color:#999999">)</span>
clf<span style="color:#999999">.</span>fit<span style="color:#999999">(</span>Xtrain<span style="color:#999999">,</span>Ytrain<span style="color:#999999">)</span>
clf<span style="color:#999999">.</span>score<span style="color:#999999">(</span>Xtest<span style="color:#999999">,</span>Ytest<span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
0.80934521
AUC面积
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>metrics <span style="color:#0077aa">import</span> roc_curve<span style="color:#999999">,</span> auc
predict_proba <span style="color:#a67f59">=</span> clf<span style="color:#999999">.</span>predict_proba<span style="color:#999999">(</span>Xtest<span style="color:#999999">)</span>
false_positive_rate<span style="color:#999999">,</span> true_positive_rate<span style="color:#999999">,</span> thresholds <span style="color:#a67f59">=</span> roc_curve<span style="color:#999999">(</span>Ytest<span style="color:#999999">,</span> predict_proba<span style="color:#999999">[</span><span style="color:#999999">:</span><span style="color:#999999">,</span><span style="color:#986801">1</span><span style="color:#999999">]</span><span style="color:#999999">)</span>
auc<span style="color:#999999">(</span>false_positive_rate<span style="color:#999999">,</span> true_positive_rate<span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
0.74512067
这里做完后,还可以得出特征重要性
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#0077aa">from</span> xgboost <span style="color:#0077aa">import</span> plot_importance
plot_importance<span style="color:#999999">(</span>clf<span style="color:#999999">)</span>
plt<span style="color:#999999">.</span>show<span style="color:#999999">(</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
总结
调参过程综合要点:
(1)"n_estimators"基分类器数量越大,偏差越小,但时间有限,这里初步可选30
(2)"max_depth"越大偏差越小,方差越大,需综合考虑时间及拟合性
(3)"learning_rate"学习速率一般越小越好,只是耗时会更长
(4)"subsample"采样比例一般在0.5,0.8之间比较好
六、模型融合
模型融合是比赛后期上分的重要手段,模型融合后结果会有大幅提升,以下是模型融合的方式。
1)平均法(Averaging)-针对回归问题


2)投票法(Voting)- 针对分类问题
-
简单投票法
-
加权投票法
-
硬投票法
模型 1:A - 99%、B - 1%,表示模型 1 认为该样本是 A 类型的概率为 99%,为 B 类型的概率为 1%

python实现
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#0077aa">from</span> xgboost <span style="color:#0077aa">import</span> XGBClassifier
<span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>linear_model <span style="color:#0077aa">import</span> LogisticRegression
<span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>ensemble <span style="color:#0077aa">import</span> RandomForestClassifier
<span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>ensemble <span style="color:#0077aa">import</span> VotingClassifier
<span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>model_selection <span style="color:#0077aa">import</span> train_test_split<span style="color:#999999">,</span>cross_val_score <span style="color:#708090">#划分数据 交叉验证</span>
clf1 <span style="color:#a67f59">=</span> XGBClassifier<span style="color:#999999">(</span>learning_rate<span style="color:#a67f59">=</span><span style="color:#986801">0.1</span><span style="color:#999999">,</span> n_estimators<span style="color:#a67f59">=</span><span style="color:#986801">150</span><span style="color:#999999">,</span> max_depth<span style="color:#a67f59">=</span><span style="color:#986801">3</span><span style="color:#999999">,</span> min_child_weight<span style="color:#a67f59">=</span><span style="color:#986801">2</span><span style="color:#999999">,</span> subsample<span style="color:#a67f59">=</span><span style="color:#986801">0.7</span><span style="color:#999999">,</span>
colsample_bytree<span style="color:#a67f59">=</span><span style="color:#986801">0.6</span><span style="color:#999999">,</span> objective<span style="color:#a67f59">=</span><span style="color:#50a14f">'binary:logistic'</span><span style="color:#999999">)</span>
clf2 <span style="color:#a67f59">=</span> RandomForestClassifier<span style="color:#999999">(</span>n_estimators<span style="color:#a67f59">=</span><span style="color:#986801">50</span><span style="color:#999999">,</span> max_depth<span style="color:#a67f59">=</span><span style="color:#986801">1</span><span style="color:#999999">,</span> min_samples_split<span style="color:#a67f59">=</span><span style="color:#986801">4</span><span style="color:#999999">,</span>
min_samples_leaf<span style="color:#a67f59">=</span><span style="color:#986801">63</span><span style="color:#999999">,</span>oob_score<span style="color:#a67f59">=</span><span style="color:#0184bb">True</span><span style="color:#999999">)</span>
clf3 <span style="color:#a67f59">=</span> SVC<span style="color:#999999">(</span>C<span style="color:#a67f59">=</span><span style="color:#986801">0.1</span><span style="color:#999999">)</span>
<span style="color:#708090"># 硬投票</span>
eclf <span style="color:#a67f59">=</span> VotingClassifier<span style="color:#999999">(</span>estimators<span style="color:#a67f59">=</span><span style="color:#999999">[</span>
<span style="color:#999999">(</span><span style="color:#50a14f">'xgb'</span><span style="color:#999999">,</span> clf1<span style="color:#999999">)</span><span style="color:#999999">,</span>
<span style="color:#999999">(</span><span style="color:#50a14f">'rf'</span><span style="color:#999999">,</span> clf2<span style="color:#999999">)</span><span style="color:#999999">,</span>
<span style="color:#999999">(</span><span style="color:#50a14f">'svc'</span><span style="color:#999999">,</span> clf3<span style="color:#999999">)</span><span style="color:#999999">]</span><span style="color:#999999">,</span> voting<span style="color:#a67f59">=</span><span style="color:#50a14f">'hard'</span><span style="color:#999999">)</span>
<span style="color:#708090"># 比较模型融合效果</span>
<span style="color:#0077aa">for</span> clf<span style="color:#999999">,</span> label <span style="color:#0077aa">in</span> <span style="color:#50a14f">zip</span><span style="color:#999999">(</span><span style="color:#999999">[</span>clf1<span style="color:#999999">,</span> clf2<span style="color:#999999">,</span> clf3<span style="color:#999999">,</span> eclf<span style="color:#999999">]</span><span style="color:#999999">,</span> <span style="color:#999999">[</span><span style="color:#50a14f">'XGBBoosting'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'Random Forest'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'SVM'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'Ensemble'</span><span style="color:#999999">]</span><span style="color:#999999">)</span><span style="color:#999999">:</span>
scores <span style="color:#a67f59">=</span> cross_val_score<span style="color:#999999">(</span>clf<span style="color:#999999">,</span> x<span style="color:#999999">,</span> y<span style="color:#999999">,</span> cv<span style="color:#a67f59">=</span><span style="color:#986801">5</span><span style="color:#999999">,</span> scoring<span style="color:#a67f59">=</span><span style="color:#50a14f">'accuracy'</span><span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span><span style="color:#50a14f">"Accuracy: %0.2f (+/- %0.2f) [%s]"</span> <span style="color:#a67f59">%</span> <span style="color:#999999">(</span>scores<span style="color:#999999">.</span>mean<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">,</span> scores<span style="color:#999999">.</span>std<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">,</span> label<span style="color:#999999">)</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 软投票法
将所有模型预测样本为某一类别的概率的平均值作为标准

new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#0077aa">from</span> xgboost <span style="color:#0077aa">import</span> XGBClassifier
<span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>linear_model <span style="color:#0077aa">import</span> LogisticRegression
<span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>ensemble <span style="color:#0077aa">import</span> RandomForestClassifier
<span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>ensemble <span style="color:#0077aa">import</span> VotingClassifier
<span style="color:#0077aa">from</span> sklearn<span style="color:#999999">.</span>model_selection <span style="color:#0077aa">import</span> train_test_split<span style="color:#999999">,</span>cross_val_score <span style="color:#708090">#划分数据 交叉验证</span>
clf1 <span style="color:#a67f59">=</span> XGBClassifier<span style="color:#999999">(</span>learning_rate<span style="color:#a67f59">=</span><span style="color:#986801">0.1</span><span style="color:#999999">,</span> n_estimators<span style="color:#a67f59">=</span><span style="color:#986801">150</span><span style="color:#999999">,</span> max_depth<span style="color:#a67f59">=</span><span style="color:#986801">3</span><span style="color:#999999">,</span> min_child_weight<span style="color:#a67f59">=</span><span style="color:#986801">2</span><span style="color:#999999">,</span> subsample<span style="color:#a67f59">=</span><span style="color:#986801">0.7</span><span style="color:#999999">,</span>
colsample_bytree<span style="color:#a67f59">=</span><span style="color:#986801">0.6</span><span style="color:#999999">,</span> objective<span style="color:#a67f59">=</span><span style="color:#50a14f">'binary:logistic'</span><span style="color:#999999">)</span>
clf2 <span style="color:#a67f59">=</span> RandomForestClassifier<span style="color:#999999">(</span>n_estimators<span style="color:#a67f59">=</span><span style="color:#986801">50</span><span style="color:#999999">,</span> max_depth<span style="color:#a67f59">=</span><span style="color:#986801">1</span><span style="color:#999999">,</span> min_samples_split<span style="color:#a67f59">=</span><span style="color:#986801">4</span><span style="color:#999999">,</span>
min_samples_leaf<span style="color:#a67f59">=</span><span style="color:#986801">63</span><span style="color:#999999">,</span>oob_score<span style="color:#a67f59">=</span><span style="color:#0184bb">True</span><span style="color:#999999">)</span>
clf3 <span style="color:#a67f59">=</span> SVC<span style="color:#999999">(</span>C<span style="color:#a67f59">=</span><span style="color:#986801">0.1</span><span style="color:#999999">)</span>
<span style="color:#708090"># 软投票</span>
eclf <span style="color:#a67f59">=</span> VotingClassifier<span style="color:#999999">(</span>estimators<span style="color:#a67f59">=</span><span style="color:#999999">[</span>
<span style="color:#999999">(</span><span style="color:#50a14f">'xgb'</span><span style="color:#999999">,</span> clf1<span style="color:#999999">)</span><span style="color:#999999">,</span>
<span style="color:#999999">(</span><span style="color:#50a14f">'rf'</span><span style="color:#999999">,</span> clf2<span style="color:#999999">)</span><span style="color:#999999">,</span>
<span style="color:#999999">(</span><span style="color:#50a14f">'svc'</span><span style="color:#999999">,</span> clf3<span style="color:#999999">)</span><span style="color:#999999">]</span><span style="color:#999999">,</span>
voting<span style="color:#a67f59">=</span><span style="color:#50a14f">'soft'</span><span style="color:#999999">,</span> weights<span style="color:#a67f59">=</span><span style="color:#999999">[</span><span style="color:#986801">2</span><span style="color:#999999">,</span> <span style="color:#986801">1</span><span style="color:#999999">,</span> <span style="color:#986801">1</span><span style="color:#999999">]</span><span style="color:#999999">)</span>
<span style="color:#708090"># 比较模型融合效果</span>
<span style="color:#0077aa">for</span> clf<span style="color:#999999">,</span> label <span style="color:#0077aa">in</span> <span style="color:#50a14f">zip</span><span style="color:#999999">(</span><span style="color:#999999">[</span>clf1<span style="color:#999999">,</span> clf2<span style="color:#999999">,</span> clf3<span style="color:#999999">,</span> eclf<span style="color:#999999">]</span><span style="color:#999999">,</span> <span style="color:#999999">[</span><span style="color:#50a14f">'XGBBoosting'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'Random Forest'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'SVM'</span><span style="color:#999999">,</span> <span style="color:#50a14f">'Ensemble'</span><span style="color:#999999">]</span><span style="color:#999999">)</span><span style="color:#999999">:</span>
scores <span style="color:#a67f59">=</span> cross_val_score<span style="color:#999999">(</span>clf<span style="color:#999999">,</span> x<span style="color:#999999">,</span> y<span style="color:#999999">,</span> cv<span style="color:#a67f59">=</span><span style="color:#986801">5</span><span style="color:#999999">,</span> scoring<span style="color:#a67f59">=</span><span style="color:#50a14f">'accuracy'</span><span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span><span style="color:#50a14f">"Accuracy: %0.2f (+/- %0.2f) [%s]"</span> <span style="color:#a67f59">%</span> <span style="color:#999999">(</span>scores<span style="color:#999999">.</span>mean<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">,</span> scores<span style="color:#999999">.</span>std<span style="color:#999999">(</span><span style="color:#999999">)</span><span style="color:#999999">,</span> label<span style="color:#999999">)</span><span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
3)综合法
- 排序融合
- log融合
4)stacking/blending:
- stacking(构建多层模型,并利用预测结果再拟合预测)
- blending(选取部分数据预测训练得到预测结果作为新特征,带入剩下的数据中预测。Blending只有一层,而Stacking有多层)

5) boosting/bagging
多树的提升方法,在xgboost,Adaboost,GBDT中已经用到
介绍完上述方法之后,回到赛题
这里使用之前的训练的lgb和xgb模型作为基分类器,逻辑回归作为目标分类器做stacking
new-version
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><span style="background-color:#fafafa"><code class="language-python"><span style="color:#0077aa">from</span> mlxtend<span style="color:#999999">.</span>classifier <span style="color:#0077aa">import</span> StackingClassifier
gra<span style="color:#a67f59">=</span>GradientBoostingClassifier<span style="color:#999999">(</span><span style="color:#999999">)</span>
xgb<span style="color:#a67f59">=</span>XGBClassifier<span style="color:#999999">(</span><span style="color:#999999">)</span>
lgb<span style="color:#a67f59">=</span>LGBMClassifier<span style="color:#999999">(</span><span style="color:#999999">)</span>
lr <span style="color:#a67f59">=</span> LogisticRegression<span style="color:#999999">(</span><span style="color:#999999">)</span>
sclf <span style="color:#a67f59">=</span> StackingClassifier<span style="color:#999999">(</span>classifiers<span style="color:#a67f59">=</span><span style="color:#999999">[</span>gra<span style="color:#999999">,</span> xgb<span style="color:#999999">,</span> lgb<span style="color:#999999">]</span><span style="color:#999999">,</span>
use_probas<span style="color:#a67f59">=</span><span style="color:#0184bb">True</span><span style="color:#999999">,</span>
meta_classifier<span style="color:#a67f59">=</span>lr<span style="color:#999999">)</span>
sclf<span style="color:#999999">.</span>fit<span style="color:#999999">(</span>Xtrain<span style="color:#999999">,</span>Ytrain<span style="color:#999999">)</span>
pre <span style="color:#a67f59">=</span>sclf<span style="color:#999999">.</span>predict_proba<span style="color:#999999">(</span>Xtest<span style="color:#999999">)</span><span style="color:#999999">[</span><span style="color:#999999">:</span><span style="color:#999999">,</span><span style="color:#986801">1</span><span style="color:#999999">]</span>
fpr<span style="color:#999999">,</span> tpr<span style="color:#999999">,</span> thresholds <span style="color:#a67f59">=</span> roc_curve<span style="color:#999999">(</span>Ytest<span style="color:#999999">,</span> pre<span style="color:#999999">)</span>
score <span style="color:#a67f59">=</span> auc<span style="color:#999999">(</span>fpr<span style="color:#999999">,</span> tpr<span style="color:#999999">)</span>
<span style="color:#0077aa">print</span><span style="color:#999999">(</span>score<span style="color:#999999">)</span>
</code></span></span></span></span>AI写代码python
运行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
总结
- 简单平均和加权平均是常用的两种比赛中模型融合的方式。其优点是快速、简单。
- stacking融合速度非常慢,同时stacking多层提升幅度并不能抵消其带来的时间和内存消耗,所以实际环境中应用还是有一定的难度。
七 结果部署
a) 预测评估数据集(通过验证数据集来验证被优化过的模型)
b) 利用整个数据集生产模型(通过整个数据集来生成模型)
c) 序列化模型(将模型序列化,以便于预测新数据)
当有新数据产生时,就可以采用这个模型来预测新数据。
至此
2021.3.29
编辑卖山楂啦prss
关注
*
101
-
-
610
23
-
分享
-
专栏目录
金融风控-贷款违约预测
yangjia3369的博客
623
Datawhale组队学习之零基础入门金融风控-贷款违约预测TASK1 赛题理解学习目标了解赛题赛题概况数据概况代码示例 TASK1 赛题理解 项目地址:https://github.com/datawhalechina/team-learning-data-mining/tree/master/FinancialRiskControl 比赛地址:https://tianchi.aliyun.com/competition/entrance/531830/introduction 学习目标 了解赛题 赛题概
金融风控之贷款违约预测挑战赛码源+数据集:数学建模打比赛
05-17
赛题以金融风控中的个人信贷为背景,要求选手根据贷款申请人的数据信息预测其是否有违约的可能,以此判断是否通过此项贷款,这是一个典型的分类问题。通过这道赛题来引导大家了解金融风控中的一些业务背景,解决实际问题,帮助竞赛新人进行自我练习、自我提高。 赛题以预测金融风险为任务,数据集报名后可见并可下载,该数据来自某信贷平台的贷款记录,总数据量超过120w,包含47列变量信息,其中15列为匿名变量。为了保证比赛的公平性,将会从中抽取80万条作为训练集,20万条作为测试集A,20万条作为测试集B,同时会对employmentTitle、purpose、postCode和title等信息进行脱敏。
23 条评论
编辑Egoista_G热评
为什么填充之后employmentLength还有空值
写评论
【数据分析与挖掘实战】金融风控之贷款违约预测详解1(有代码和数据集...
8-8
purpose 借款人在贷款申请时的贷款用途类别 postCode 借款人在贷款申请中提供的邮政编码的前3位数字 regionCode 地区编码 dti 债务收入比 delinquency_2years 借款人过去2年信用档案中逾期30天以上的违约事件数 ficoRangeLow 借款人在贷款发放时的fico所属的下限范围 ficoRangeHigh 借款人在贷款发放
【机器学习】金融风控贷款违约预测--数据分析处理_风控数据处理-CSDN...
8-3
1.数据分析处理 默认拿到了一个数据集,已经划分好了训练集和测试集,这里以金融风控-贷款违约预测为例。该任务取自Datawhale与天池联合发起的金融风控赛事。 零基础入门金融风控-贷款违约预测_学习赛_天池大赛-阿里云天池的赛制 (aliyun.com) 下图所示是整个数据分析处理的框架。 1.1 导入训练集和测试集 importpandasa...
【机器学习】数据挖掘实战:个人信贷违约预测
fengdu78的博客
1913
本次分享风控圈子的一个练手实战项目:个人信贷违约预测,此项目对于想要学习信贷风控模型的同学非常有帮助。项目背景当今社会,个人信贷业务发展迅速,但同时也会暴露较高的信用风险。信息不对称在金融贷款领域突出,表现在过去时期借款一方对自身的财务状况、还款能力及还款意愿有着较为全面的掌握,而金融机构不能全面获知借款方的风险水平,或在相关信息的掌握上具有明显的滞后性。这种信息劣势,使得金融机构在贷款过程中可能...
天池金融比赛数据分析与机器学习实战
最新发布
weixin_42577243的博客
647
在构建机器学习模型的过程中,选择合适的算法是决定最终性能的关键因素之一。目前,机器学习领域中有许多算法可供选择,包括但不限于以下几种:线性回归(Linear Regression)决策树(Decision Trees)随机森林(Random Forests)支持向量机(Support Vector Machines,SVM)神经网络(Neural Networks)K-最近邻(K-Nearest Neighbors,KNN)
【免费】金融风控-贷款违约预测数据_金融风险预测学习赛结果资源...
8-8
赛题以金融风控中的个人信贷为背景,要求选手根据贷款申请人的数据信息预测其是否有违约的可能,以此判断是否通过此项贷款,这是一个典型的分类问题。 金融风控之贷款违约预测挑战赛码源+数据集:数学建模打比赛 5星 · 资源好评率100% 赛题以金融风控中的个人信贷为背景,要求选手根据贷款申请人的数据信息预测其是否有...
Loan default predictor(贷款违约预测)_loan default prediction-CSDN博 ...
7-24
其实,之前kaggle很久之前有过关于贷款相关信用预测的比赛。但是,这次和上次的情况很不同,挑战也更大。传统的金融相关的算法,其实是个典型二分类问题,或者说就是预测用户是否违约,在金融风险领域二分类挑战是正负样本极不平衡。本次的比赛的目标是要求参赛者预测样本是否违约以及如果违约,违约的百分比是多少。所以,本次...
【机器学习】金融风控贷款违约预测--数据分析处理
nghhfgh的博客
2222
以金融风控-贷款违约预测为例,从原始数据到模型输入数据的完整简单处理
天池比赛-金融风控贷款违约预测
爱听许嵩歌的博客
3639
一、赛题背景 以金融风控中的个人信贷为背景,要求根据贷款申请人的数据信息预测其是否有违约的可能,以此判断是否通过此项贷款。这是一个典型的分类问题,但也涉及一些金融的业务背景知识。 二、赛题数据 赛题以预测用户贷款是否违约为任务,该数据集来自某信贷平台的贷款记录,总数据量超过120W,包含47列变量信息,其中15列为匿名变量。比赛中抽取80万条作为训练集,20万条作为测试集A,20万条作为测试集B,同时对employmentTitle、purpose、postCode和title等信息进行脱敏处理。 数据链接
阿里云金融风控入门:贷款违约预测实战指南
7-21
简介:本课程向零基础学员介绍如何使用机器学习技术预测贷款违约,涵盖数据处理、特征工程、模型构建及评估,并侧重于Python在金融风控领域的应用。通过学习,学员将能够理解贷款违约概念,掌握从数据清洗到模型部署的完整流程。 1. 贷款违约概念介绍 贷款违约是指贷款人在偿还贷款本金和利息时未能履行合同约定,导致金融机构面临...
【算法竞赛学习】金融风控之贷款违约预测-数据分析_还款数据分析-CSDN...
8-1
赛题:零基础入门数据挖掘- 零基础入门金融风控之贷款违约 目的: 1.EDA价值主要在于熟悉了解整个数据集的基本情况(缺失值,异常值),对数据集进行验证是否可以进行接下来的机器学习或者深度学习建模. 2.了解变量间的相互关系、变量与预测值之间的存在关系。
零基础入门金融风控预测-01
duyue1的博客
512
赛题理解 数据来源 数据来自某信贷平台的贷款记录,总数据量超过120w,包含47列变量信息,其中15列为匿名变量。为了保证比赛的公平性,将会从中抽取80万条作为训练集,20万条作为测试集A,20万条作为测试集B,同时会对employmentTitle、purpose、postCode和title等信息进行脱敏。 评价指标 竞赛采用AUC作为评价指标。AUC(Area Under Curve)被定义为 ROC曲线 下与坐标轴围成的面积。 赛题流程 数据EDA 特征工程 建模调参 模型融合 ...
阿里云天池大数据长期赛:金融风控-贷款违约预测(含代码)
热门推荐
weixin_46685991的博客
1万+
本次比赛让自己在大数据的处理流程上有了更明确的认知,从数据清洗、特征工程、数据建模,每一个过程都能学到很多经验和知识,值得去历练。
【免费】贷款违约预测_建模调参与模型融合1_车辆贷款违约预测挑战...
8-4
金融风控之贷款违约预测挑战赛码源+数据集:数学建模打比赛 2023-05-17 上传 赛题以金融风控中的个人信贷为背景,要求选手根据贷款申请人的数据信息预测其是否有违约的可能,以此判断是否通过此项贷款,这是一个典型的分类问题。通过这道赛题来引导大家了解金融风控中的一些业务背景,解决实际问题,帮助竞赛新人进行自我练习...
零基础入门金融风控 Task4 建模与调参
Rock_y的博客
1517
文章目录Task4 建模与调参4.1 学习目标4.2 内容介绍4.3 模型相关原理介绍4.3.1 逻辑回归模型4.3.2 决策树模型4.3.3 GBDT模型4.3.4 XGBoost模型4.3.5 LightGBM模型4.3.6 Catboost模型4.3.7 时间序列模型(选学)4.3.8 推荐教材:4.4 模型对比与性能评估4.4.1 逻辑回归4.4.2 决策树模型4.4.3 集成模型集成方法(ensemble method)4.4.4 模型评估方法4.4.5 模型评价标准4.5 代码示例4.5.1 导
实现的金融风控贷款违约预测python源码.zip
05-15
实现的金融风控贷款违约预测python源码.zip实现的金融风控贷款违约预测python源码.zip实现的金融风控贷款违约预测python源码.zip实现的金融风控贷款违约预测python源码.zip实现的金融风控贷款违约预测python源码.zip...
课程大作业基于python实现的金融风控贷款违约预测源码(可参考借鉴).zip
10-16
课程大作业基于python实现的金融风控贷款违约预测源码(可参考借鉴).zip课程大作业基于python实现的金融风控贷款违约预测源码(可参考借鉴).zip课程大作业基于python实现的金融风控贷款违约预测源码(可参考借鉴).zip...
天池比赛_金融风控_贷款违约预测.zip
08-24
【标题】:"天池比赛_金融风控_贷款违约预测.zip"是一个与阿里巴巴天池平台上的金融风控相关比赛相关的资源包,主要目标是预测贷款客户的违约概率。在金融领域,风险管理尤其是信贷风险控制是至关重要的,而贷款...
赛题理解: 阿里天池 零基础入门金融风控-贷款违约预测
123liudong
703
文章目录题意理解提交与指标需要注意的地方 本次赛题链接:https://tianchi.aliyun.com/competition/entrance/531830/information 题意理解 这道题的目的是预测用户是否违约,本质上就是一个二分类问题。 每个样本有 47 个特征,其中 15 个特征做了匿名化处理,不同的特征具有不同的性质!如id是离散的,且没有顺序以及大小的关系;grade表示贷款等级虽然同样是离散的,但他是有大小之分的,因此在建模之前应当尽量考虑这些关系~ 数据的样本数量超过120
阿里天池学习赛-金融风控-贷款违约预测
weixin_40139561的博客
6197
阿里天池学习赛-金融风控-贷款违约预测1 赛题理解1.1 赛题数据1.2 评测标准2 探索性分析(EDA) 1 赛题理解 项目地址: https://github.com/datawhalechina/team-learning-data-mining/tree/master/FinancialRiskControl 比赛地址: https://tianchi.aliyun.com/competition/entrance/531830/introduction 1.1 赛题数据 赛题以预测金融风险为任务,
「机器学习」天池金融风控-贷款违约预测赛题分析
秀球Gang的学习小站
3048
天池金融风控-贷款违约预测赛题分析1. 赛题背景2. 赛题数据3. 评价指标4. 赛题流程5. 代码示例5.1 数据读取pandas5.2 分类指标评价计算示例6. 经验总结7. 拓展知识------评分卡 1. 赛题背景 赛题以金融风控中的个人信贷为背景,要求选手根据贷款申请人的数据信息预测其是否有违约的可能,以此判断是否通过此项贷款,这是一个典型的分类问题。通过这道赛题来引导大家了解金融风控中的一些业务背景,解决实际问题,帮助竞赛新人进行自我练习、自我提高。 比赛地址:https://tianchi.aliyu
天池案例-贷款违约预测(lgb)
weixin_41175904的博客
1857
1 案例描述 赛题以预测用户贷款是否违约为任务,数据集报名后可见并可下载,该数据来自某信贷平台的贷款记录,总数据量超过120w,包含47列变量信息,其中15列为匿名变量。为了保证比赛的公平性,将会从中抽取80万条作为训练集,20万条作为测试集A,20万条作为测试集B,同时会对employmentTitle、purpose、postCode和title等信息进行脱敏。 提交结果为每个测试样本是1的概率,也就是y为1的概率。评价方法为AUC评估模型效果(越大越好)。 2 代码详情 im...
天池金融风控违约预测xgboost
12-29
天池金融风控违约预测是一个基于大数据和人工智能技术的金融风险评估和控制平台。而xgboost是一种梯度提升算法,被广泛应用于数据挖掘和机器学习领域。 在天池金融风控违约预测中,xgboost算法可以用来构建模型,通过对大量客户数据的分析和学习,来预测客户是否存在违约的风险。xgboost算法能够有效地处理大规模数据,并具有较高的预测准确性和稳定性,因此在金融风控中得到了广泛的应用。 通过xgboost算法,天池金融风控平台可以对客户的信用情况、财务状况等多维度数据进行分析和建模,从而实现对违约风险的有效预测和控制。这可以帮助金融机构更好地评估客户的信用风险,及时采取措施降低风险,从而保护金融机构的利益,同时也为客户提供更加精准和个性化的金融服务。 总之,天池金融风控违约预测xgboost的结合,能够有效地提高金融机构风险控制的能力,保障金融市场的稳定和客户的权益。
 400-660-0108
400-660-0108
- 公安备案号11010502030143
- 京ICP备19004658号
- 京网文〔2020〕1039-165号
- 经营性网站备案信息
- 北京互联网违法和不良信息举报中心
- 家长监护
- 网络110报警服务
- 中国互联网举报中心
- Chrome商店下载
- 账号管理规范
- 版权与免责声明
- 版权申诉
- 出版物许可证
- 营业执照
- ©1999-2025北京创新乐知网络技术有限公司
卖山楂啦prss
博客等级
码龄7年
373
3428
点赞
2万+
收藏
8562
粉丝
关注
私信
猜你想问
如何处理信贷数据中的缺失值?编辑特征工程在违约预测中的作用是什么?编辑哪些模型适合用于信用风险评估?编辑
TA的精选
-
1386 阅读
-
1262 阅读
-
207409 阅读
-
147059 阅读
-
109976 阅读
大家在看
- 计算机毕业设计-基于Java web的公司人员考勤管理系统的设计与实现-开题报告 编辑 407
- PHP中有哪些循环结构?如何使用?
- 蚂蚁直播、翡翠TV、小羊直播
- java泛型篇,泛型作用,泛型本质和原理,泛型中E,T,K,V缩写通常代表什么,泛型类,自定义泛型类,泛型接口,自定义泛型接口,泛型接口详解,泛型方法,通配符,上下限,泛型支持的类型,包装类作用,包装 编辑 323
- 超灵秘法社 (Mind over Magic)免安装中文版
分类专栏
- 编辑模型大作战1篇
- 编辑统计学-在金融领域的应用
- 编辑ToC信贷数字能力建设-【开篇】1篇
- 编辑ToC信贷数字能力建设-【策略】
- 编辑ToC信贷数字能力建设-【模型】
- 编辑ToC信贷数字能力建设-【数据】
- 编辑信贷场景之用户营销运营经营分析3篇
- 编辑信贷场景之风控贷前中后7篇
- 编辑银行业务知识3篇
- 编辑Tableau【BI 可视化报表开发】14篇
- 编辑Kylin4篇
- 编辑知识图谱KG2篇
- 编辑大数据1篇
- 编辑大数据基础之hadoop1篇
- 编辑大数据之数据仓库4篇
- 编辑大数据基础之Hbase1篇
- 编辑大数据基础之Hive11篇
- 编辑Spark / Spark SQL3篇
- 编辑数据库4篇
- 编辑文本挖掘分析22篇
- 编辑数据可视化28篇
- 编辑Linux学习9篇
- 编辑统计学45篇
- 编辑深度学习17篇
- 编辑机器学习51篇
- 编辑数据分析1篇
- 编辑数据分析之思维与方法12篇
- 编辑数据分析之实战项目6篇
- 编辑数据分析之面试题整理1篇
- 编辑数据分析之业务理解10篇
- 编辑数据分析之SQL13篇
- 编辑数据分析之数据结构9篇
- 编辑MySQL19篇
- 编辑R语言31篇
- 编辑Python27篇
- 编辑Python效率加速7篇
- 编辑Python爬虫21篇
- 编辑Python自动化办公11篇
- 编辑Seaborn/Plotly/Plotnine2篇
- 编辑Pyecharts23篇
- 编辑数据挖掘案例6篇
- 编辑PyTorch1篇
- 编辑Arcgis5篇
- 编辑MongoDB1篇
- 编辑Java5篇
- 编辑Scala2篇
- 编辑Excel20篇
- 编辑VBA18篇
- 编辑记录9篇
- 编辑Power BI2篇
- 编辑EViews1篇
展开全部
上一篇:
下一篇:

目录
- 一、前言
- 1.1 赛题背景
- 1.2 赛题数据
- 1.3 评价指标
- 1.4 赛题整体流程
- 二、探索性的数据分析EDA
- 2.1 总体分布
- 2.2 数据类型分析
- 2.2.1 数值类型(连续变量、离散型变量和单值变量)
- 2.2.2 分类型特征
- 2.3 目标变量(标签y)的分布
- 2.4 缺失值查看
- 2.5 数据相关关系
- 三、特征工程
- 3.1 重复值处理
- 3.2 缺失值填补
- 3.3 异常值处理
- 3.3.1 方法一:均方差 3σ
- 3.3.2 方法二:箱型图
- 3.4 时间数据处理
- 3.5 特征交叉
- 3.6 特征编码
- 3.7 数据分桶
- 3.8 特征交互
- 3.9 特征选择
- 3.10 样本不平衡处理
- 四、建模分析
- 4.1 LightGBM
- 4.2 XGBoost
- 4.3 三个模型比较
- 五、模型调参
- 5.1 调参方法
- 5.2 XGboost调参
- 六、模型融合
- 七 结果部署
收起
AI助手



AI提问
评论
笔记
数据竞赛入门-金融风控(贷款违约预测)四、建模与调参
搜索
AI 搜索
数据竞赛入门-金融风控(贷款违约预测)四、建模与调参
最新推荐文章于 2024-03-20 16:25:29 发布
阅读量3k
收藏 22
点赞数 1
CC 4.0 BY-SA版权
56 篇文章
订阅专栏
12 篇文章
订阅专栏
前言
本次活动为datawhale与天池联合举办,为金融风控之贷款违约预测挑战赛(入门)
比赛地址:https://tianchi.aliyun.com/competition/entrance/531830/introduction
模型对比与性能评估
首先学习在金融分控领域常用的机器学习模型
逻辑回归
推荐博客:
机器学习笔记I: 基于逻辑回归的分类预测
机器学习系列(1)_逻辑回归初步
-
优点
- 训练速度较快,分类的时候,计算量仅仅只和特征的数目相关;
- 简单易理解,模型的可解释性非常好,从特征的权重可以看到不同的特征对最后结果的影响;
- 适合二分类问题,不需要缩放输入特征;
- 内存资源占用小,只需要存储各个维度的特征值;
-
缺点
-
逻辑回归需要预先处理缺失值和异常值,可以查看此博客;
-
不能用Logistic回归去解决非线性问题,因为Logistic的决策面是线性的;
-
对多重共线性数据较为敏感,且很难处理数据不平衡的问题;
-
准确率并不是很高,因为形式非常简单,很难去拟合数据的真实分布;
-
决策树模型
推荐博客:
机器学习笔记II: 决策树
Python3《机器学习实战》学习笔记(三):决策树实战篇之为自己配个隐形眼镜
- 优点
- 简单直观,生成的决策树可以可视化展示
- 数据不需要预处理,不需要归一化,不需要处理缺失数据
- 既可以处理离散值,也可以处理连续值
- 缺点
- 决策树算法非常容易过拟合,导致泛化能力不强(可进行适当的剪枝)
- 采用的是贪心算法,容易得到局部最优解
集成模型集成方法(ensemble method)
通过组合多个学习器来完成学习任务,通过集成方法,可以将多个弱学习器组合成一个强分类器,因此集成学习的泛化能力一般比单一分类器要好。
集成方法主要包括Bagging和Boosting,Bagging和Boosting都是将已有的分类或回归算法通过一定方式组合起来,形成一个更加强大的分类。两种方法都是把若干个分类器整合为一个分类器的方法,只是整合的方式不一样,最终得到不一样的效果。常见的基于Baggin思想的集成模型有:随机森林、基于Boosting思想的集成模型有:Adaboost、GBDT、XgBoost、LightGBM等。
Baggin和Boosting的区别总结如下:
- 样本选择上: Bagging方法的训练集是从原始集中有放回的选取,所以从原始集中选出的各轮训练集之间是独立的;而Boosting方法需要每一轮的训练集不变,只是训练集中每个样本在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整
- 样例权重上: Bagging方法使用均匀取样,所以每个样本的权重相等;而Boosting方法根据错误率不断调整样本的权值,错误率越大则权重越大
- 预测函数上: Bagging方法中所有预测函数的权重相等;而Boosting方法中每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重
- 并行计算上: Bagging方法中各个预测函数可以并行生成;而Boosting方法各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
模型评估方法
对于模型来说,其在训练集上面的误差我们称之为训练误差或者经验误差,而在测试集上的误差称之为测试误差。
对于我们来说,我们更关心的是模型对于新样本的学习能力,即我们希望通过对已有样本的学习,尽可能的将所有潜在样本的普遍规律学到手,而如果模型对训练样本学的太好,则有可能把训练样本自身所具有的一些特点当做所有潜在样本的普遍特点,这时候我们就会出现过拟合的问题。
因此我们通常将已有的数据集划分为训练集和测试集两部分,其中训练集用来训练模型,而测试集则是用来评估模型对于新样本的判别能力。
对于数据集的划分,我们通常要保证满足以下两个条件:
- 训练集和测试集的分布要与样本真实分布一致,即训练集和测试集都要保证是从样本真实分布中独立同分布采样而得;
- 训练集和测试集要互斥
对于数据集的划分有三种方法:留出法,交叉验证法和自助法,下面挨个介绍:
-
①留出法
留出法是直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T。需要注意的是在划分的时候要尽可能保证数据分布的一致性,即避免因数据划分过程引入额外的偏差而对最终结果产生影响。为了保证数据分布的一致性,通常我们采用分层采样的方式来对数据进行采样。
Tips: 通常,会将数据集D中大约2/3~4/5的样本作为训练集,其余的作为测试集。
-
②交叉验证法
k折交叉验证通常将数据集D分为k份,其中k-1份作为训练集,剩余的一份作为测试集,这样就可以获得k组训练/测试集,可以进行k次训练与测试,最终返回的是k个测试结果的均值。交叉验证中数据集的划分依然是依据分层采样的方式来进行。
对于交叉验证法,其k值的选取往往决定了评估结果的稳定性和保真性,通常k值选取10。
当k=1的时候,我们称之为留一法
-
③自助法
我们每次从数据集D中取一个样本作为训练集中的元素,然后把该样本放回,重复该行为m次,这样我们就可以得到大小为m的训练集,在这里面有的样本重复出现,有的样本则没有出现过,我们把那些没有出现过的样本作为测试集。
进行这样采样的原因是因为在D中约有36.8%的数据没有在训练集中出现过。留出法与交叉验证法都是使用分层采样的方式进行数据采样与划分,而自助法则是使用有放回重复采样的方式进行数据采样
数据集划分总结
- 对于数据量充足的时候,通常采用留出法或者k折交叉验证法来进行训练/测试集的划分;
- 对于数据集小且难以有效划分训练/测试集时使用自助法;
- 对于数据集小且可有效划分的时候最好使用留一法来进行划分,因为这种方法最为准确
模型评价标准
对于本次比赛,我们选用auc作为模型评价标准,类似的评价标准还有ks、f1-score等,具体介绍与实现大家可以参考本篇博客
一起来看一下auc到底是什么?
在逻辑回归里面,对于正负例的界定,通常会设一个阈值,大于阈值的为正类,小于阈值为负类。如果我们减小这个阀值,更多的样本会被识别为正类,提高正类的识别率,但同时也会使得更多的负类被错误识别为正类。为了直观表示这一现象,引入ROC。
根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve,横坐标为False Positive Rate(FPR:假正率),纵坐标为True Positive Rate(TPR:真正率)。 一般情况下,这个曲线都应该处于(0,0)和(1,1)连线的上方,如图:

ROC曲线中的四个点:
- 点(0,1):即FPR=0, TPR=1,意味着FN=0且FP=0,将所有的样本都正确分类;
- 点(1,0):即FPR=1,TPR=0,最差分类器,避开了所有正确答案;
- 点(0,0):即FPR=TPR=0,FP=TP=0,分类器把每个实例都预测为负类;
- 点(1,1):分类器把每个实例都预测为正类
总之:ROC曲线越接近左上角,该分类器的性能越好,其泛化性能就越好。而且一般来说,如果ROC是光滑的,那么基本可以判断没有太大的overfitting。
但是对于两个模型,我们如何判断哪个模型的泛化性能更优呢?这里我们有主要以下两种方法:
如果模型A的ROC曲线完全包住了模型B的ROC曲线,那么我们就认为模型A要优于模型B;
如果两条曲线有交叉的话,我们就通过比较ROC与X,Y轴所围得曲线的面积来判断,面积越大,模型的性能就越优,这个面积我们称之为AUC(area under ROC curve)
代码示例
导入相关关和相关设置
import pandas as pd
import numpy as np
import warnings
import os
import seaborn as sns
import matplotlib.pyplot as plt
"""
sns 相关设置
@return:
"""
# 声明使用 Seaborn 样式
sns.set()
# 有五种seaborn的绘图风格,它们分别是:darkgrid, whitegrid, dark, white, ticks。默认的主题是darkgrid。
sns.set_style("whitegrid")
# 有四个预置的环境,按大小从小到大排列分别为:paper, notebook, talk, poster。其中,notebook是默认的。
sns.set_context('talk')
# 中文字体设置-黑体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决保存图像是负号'-'显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False
# 解决Seaborn中文显示问题并调整字体大小
sns.set(font='SimHei')读取数据
reduce_mem_usage 函数通过调整数据类型,帮助我们减少数据在内存中占用的空间
def reduce_mem_usage(df):
start_mem = df.memory_usage().sum()
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum()
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
# 读取数据
# 读取数据
data_train = pd.read_csv('E:/python-project/deep-learning/datawhale/tianchi/FinancialRiskControl/data/train.csv')
data_test_a = pd.read_csv('E:/python-project/deep-learning/datawhale/tianchi/FinancialRiskControl/data/testA.csv')
data_train = reduce_mem_usage(data_train)
data_test_a = reduce_mem_usage(data_test_a)
'''
Memory usage of dataframe is 300800128.00 MB
Memory usage after optimization is: 72834944.00 MB
Decreased by 75.8%
Memory usage of dataframe is 73600128.00 MB
Memory usage after optimization is: 18034520.00 MB
Decreased by 75.5%
'''简单建模
-
Tips1:金融风控的实际项目多涉及到信用评分,因此需要模型特征具有较好的可解释性,所以目前在实际项目中多还是以逻辑回归作为基础模型。但是在比赛中以得分高低为准,不需要严谨的可解释性,所以大多基于集成算法进行建模。
-
Tips2:因为逻辑回归的算法特性,需要提前对异常值、缺失值数据进行处理【参考task3部分】
-
Tips3:基于树模型的算法特性,异常值、缺失值处理可以跳过,但是对于业务较为了解的同学也可以自己对缺失异常值进行处理,效果可能会更优于模型处理的结果。
注:以下建模的源数据参考baseline进行了相应的特征工程,对于异常缺失值未进行相应的处理操作。
建模之前的预操作
from sklearn.model_selection import KFold
# 分离数据集,方便进行交叉验证
X_train = data_train.drop(['id','issueDate','isDefault'],axis=1)
X_test = data_test_a.drop(['id','issueDate'],axis=1)
y_train = data_train.isDefault
# 5折交叉验证
folds = 5
seed = 2020
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)使用Lightgbm进行建模
"""对训练集数据进行划分,分成训练集和验证集,并进行相应的操作"""
from sklearn.model_selection import train_test_split
import lightgbm as lgb
# 数据集划分
X_train_split, X_val, y_train_split, y_val = train_test_split(X_train, y_train, test_size=0.2)
train_matrix = lgb.Dataset(X_train_split, label=y_train_split)
valid_matrix = lgb.Dataset(X_val, label=y_val)
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'learning_rate': 0.1,
'metric': 'auc',
'min_child_weight': 1e-3,
'num_leaves': 31,
'max_depth': -1,
'reg_lambda': 0,
'reg_alpha': 0,
'feature_fraction': 1,
'bagging_fraction': 1,
'bagging_freq': 0,
'seed': 2020,
'nthread': 8,
'silent': True,
'verbose': -1,
}
"""使用训练集数据进行模型训练"""
model = lgb.train(params, train_set=train_matrix, valid_sets=valid_matrix, num_boost_round=20000, verbose_eval=1000, early_stopping_rounds=200)
'''
Training until validation scores don't improve for 200 rounds
Early stopping, best iteration is:
[118] valid_0's auc: 0.717394
'''对验证集进行预测
from sklearn import metrics
from sklearn.metrics import roc_auc_score
"""预测并计算roc的相关指标"""
val_pre_lgb = model.predict(X_val, num_iteration=model.best_iteration)
fpr, tpr, threshold = metrics.roc_curve(y_val, val_pre_lgb)
roc_auc = metrics.auc(fpr, tpr)
print('未调参前lightgbm单模型在验证集上的AUC:{}'.format(roc_auc))
"""画出roc曲线图"""
plt.figure(figsize=(8, 8))
plt.title('Validation ROC')
plt.plot(fpr, tpr, 'b', label = 'Val AUC = %0.4f' % roc_auc)
plt.ylim(0,1)
plt.xlim(0,1)
plt.legend(loc='best')
plt.title('ROC')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
# 画出对角线
plt.plot([0,1],[0,1],'r--')
plt.show()
#未调参前lightgbm单模型在验证集上的AUC:0.7249469360631181
-
tips:函数roc_curve
接口函数 sklearn.metrics.roc_curve(y_true, y_score, pos_label=None, sample_weight=None, drop_intermediate=True)
参数说明 y_true:数组,存储数据的标签,维度就是样本数,形如[0,1,1,0,1...]这样的,也可以是-1和1,只要有两个值 y_score:数组,存储数据的预测概率值,维度也是样本数,形如[0.38,0.5,0.8]这样的 pos_label:整型或字符串,当y_true中只有一个值时,比如都是1或者都是0,无法判断哪个是正样本,需要用一个数字或字符串指出 sample_weight:采样权重,这个官方没有仔细说,是一个可选参数,有待考察 drop_intermediate:丢掉一些阈值,以便画roc曲线图 返回值:一共三个,分别是fpr,tpr,thresholds fpr:数组,随阈值上涨的假阳性率 tpr:数组,随阈值上涨的真正例率 thresholds:数组,对预测值排序后的score列表,作为阈值,排序从大到小 更进一步的,使用5折交叉验证进行模型性能评估import lightgbm as lgb
"""使用lightgbm 5折交叉验证进行建模预测"""
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(X_train, y_train)):
print('************************************ {} ************************************'.format(str(i+1)))
X_train_split, y_train_split, X_val, y_val = X_train.iloc[train_index], y_train[train_index], X_train.iloc[valid_index], y_train[valid_index]train_matrix = lgb.Dataset(X_train_split, label=y_train_split) valid_matrix = lgb.Dataset(X_val, label=y_val) params = { 'boosting_type': 'gbdt', 'objective': 'binary', 'learning_rate': 0.1, 'metric': 'auc', 'min_child_weight': 1e-3, 'num_leaves': 31, 'max_depth': -1, 'reg_lambda': 0, 'reg_alpha': 0, 'feature_fraction': 1, 'bagging_fraction': 1, 'bagging_freq': 0, 'seed': 2020, 'nthread': 8, 'silent': True, 'verbose': -1, } model = lgb.train(params, train_set=train_matrix, num_boost_round=20000, valid_sets=valid_matrix, verbose_eval=1000, early_stopping_rounds=200) val_pred = model.predict(X_val, num_iteration=model.best_iteration) cv_scores.append(roc_auc_score(y_val, val_pred)) print(cv_scores)print("lgb_scotrainre_list:{}".format(cv_scores))
print("lgb_score_mean:{}".format(np.mean(cv_scores)))
print("lgb_score_std:{}".format(np.std(cv_scores)))'''
Training until validation scores don't improve for 200 rounds
Early stopping, best iteration is:
[126] valid_0's auc: 0.71875
[0.7191601264391831, 0.715544695574905, 0.7192905963725816, 0.7188078144554632, 0.7187502453796062]
lgb_scotrainre_list:[0.7191601264391831, 0.715544695574905, 0.7192905963725816, 0.7188078144554632, 0.7187502453796062]
lgb_score_mean:0.7183106956443478
lgb_score_std:0.0013980576224674034
'''
模型调参
1. 贪心调参
先使用当前对模型影响最大的参数进行调优,达到当前参数下的模型最优化,再使用对模型影响次之的参数进行调优,如此下去,直到所有的参数调整完毕。
这个方法的缺点就是可能会调到局部最优而不是全局最优,但是只需要一步一步的进行参数最优化调试即可,容易理解。
需要注意的是在树模型中参数调整的顺序,也就是各个参数对模型的影响程度,这里列举一下日常调参过程中常用的参数和调参顺序:
-
①:max_depth、num_leaves
-
②:min_data_in_leaf、min_child_weight
-
③:bagging_fraction、 feature_fraction、bagging_freq
-
④:reg_lambda、reg_alpha
-
⑤:min_split_gain
from sklearn.model_selection import cross_val_score
调objective
best_obj = dict()
for obj in objective:
model = LGBMRegressor(objective=obj)
"""预测并计算roc的相关指标"""
score = cross_val_score(model, X_train, y_train, cv=5, scoring='roc_auc').mean()
best_obj[obj] = scorenum_leaves
best_leaves = dict()
for leaves in num_leaves:
model = LGBMRegressor(objective=min(best_obj.items(), key=lambda x:x[1])[0], num_leaves=leaves)
"""预测并计算roc的相关指标"""
score = cross_val_score(model, X_train, y_train, cv=5, scoring='roc_auc').mean()
best_leaves[leaves] = scoremax_depth
best_depth = dict()
for depth in max_depth:
model = LGBMRegressor(objective=min(best_obj.items(), key=lambda x:x[1])[0],
num_leaves=min(best_leaves.items(), key=lambda x:x[1])[0],
max_depth=depth)
"""预测并计算roc的相关指标"""
score = cross_val_score(model, X_train, y_train, cv=5, scoring='roc_auc').mean()
best_depth[depth] = score"""
可依次将模型的参数通过上面的方式进行调整优化,并且通过可视化观察在每一个最优参数下模型的得分情况
"""
可依次将模型的参数通过上面的方式进行调整优化,并且通过可视化观察在每一个最优参数下模型的得分情况
-
tips:cross_val_score()函数
sklearn.cross_validation.cross_val_score(estimator, X, y=None, scoring=None,cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch='2*n_jobs')
其中主要参数含义:
estimator:估计方法对象(分类器)
X:数据特征(Features)
y:数据标签(Labels)
soring:调用方法(包括accuracy和mean_squared_error等等)
cv:几折交叉验证
n_jobs:同时工作的cpu个数(-1代表全部)文档:https://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter
2. 网格搜索
sklearn 提供GridSearchCV用于进行网格搜索,只需要把模型的参数输进去,就能给出最优化的结果和参数。相比起贪心调参,网格搜索的结果会更优,但是网格搜索只适合于小数据集,一旦数据的量级上去了,很难得出结果。
同样以Lightgbm算法为例,进行网格搜索调参:
"""通过网格搜索确定最优参数"""
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import KFold,StratifiedKFold
def get_best_cv_params(learning_rate=0.1, n_estimators=581, num_leaves=31, max_depth=-1, bagging_fraction=1.0,
feature_fraction=1.0, bagging_freq=0, min_data_in_leaf=20, min_child_weight=0.001,
min_split_gain=0, reg_lambda=0, reg_alpha=0, param_grid=None):
# 设置5折交叉验证
cv_fold = StratifiedKFold(n_splits=5, random_state=0, shuffle=True, )
model_lgb = lgb.LGBMClassifier(learning_rate=learning_rate,
n_estimators=n_estimators,
num_leaves=num_leaves,
max_depth=max_depth,
bagging_fraction=bagging_fraction,
feature_fraction=feature_fraction,
bagging_freq=bagging_freq,
min_data_in_leaf=min_data_in_leaf,
min_child_weight=min_child_weight,
min_split_gain=min_split_gain,
reg_lambda=reg_lambda,
reg_alpha=reg_alpha,
n_jobs= 8
)
grid_search = GridSearchCV(estimator=model_lgb,
cv=cv_fold,
param_grid=param_grid,
scoring='roc_auc'
)
grid_search.fit(X_train, y_train)
print('模型当前最优参数为:{}'.format(grid_search.best_params_))
print('模型当前最优得分为:{}'.format(grid_search.best_score_))
"""以下代码未运行,耗时较长,请谨慎运行,且每一步的最优参数需要在下一步进行手动更新,请注意"""
"""
需要注意一下的是,除了获取上面的获取num_boost_round时候用的是原生的lightgbm(因为要用自带的cv)
下面配合GridSearchCV时必须使用sklearn接口的lightgbm。
"""
"""设置n_estimators 为581,调整num_leaves和max_depth,这里选择先粗调再细调"""
lgb_params = {'num_leaves': range(10, 80, 5), 'max_depth': range(3,10,2)}
get_best_cv_params(learning_rate=0.1, n_estimators=581, num_leaves=None, max_depth=None, min_data_in_leaf=20,
min_child_weight=0.001,bagging_fraction=1.0, feature_fraction=1.0, bagging_freq=0,
min_split_gain=0, reg_lambda=0, reg_alpha=0, param_grid=lgb_params)
"""num_leaves为30,max_depth为7,进一步细调num_leaves和max_depth"""
lgb_params = {'num_leaves': range(25, 35, 1), 'max_depth': range(5,9,1)}
get_best_cv_params(learning_rate=0.1, n_estimators=85, num_leaves=None, max_depth=None, min_data_in_leaf=20,
min_child_weight=0.001,bagging_fraction=1.0, feature_fraction=1.0, bagging_freq=0,
min_split_gain=0, reg_lambda=0, reg_alpha=0, param_grid=lgb_params)
"""
确定min_data_in_leaf为45,min_child_weight为0.001 ,下面进行bagging_fraction、feature_fraction和bagging_freq的调参
"""
lgb_params = {'bagging_fraction': [i/10 for i in range(5,10,1)],
'feature_fraction': [i/10 for i in range(5,10,1)],
'bagging_freq': range(0,81,10)
}
get_best_cv_params(learning_rate=0.1, n_estimators=85, num_leaves=29, max_depth=7, min_data_in_leaf=45,
min_child_weight=0.001,bagging_fraction=None, feature_fraction=None, bagging_freq=None,
min_split_gain=0, reg_lambda=0, reg_alpha=0, param_grid=lgb_params)
"""
确定bagging_fraction为0.4、feature_fraction为0.6、bagging_freq为 ,下面进行reg_lambda、reg_alpha的调参
"""
lgb_params = {'reg_lambda': [0,0.001,0.01,0.03,0.08,0.3,0.5], 'reg_alpha': [0,0.001,0.01,0.03,0.08,0.3,0.5]}
get_best_cv_params(learning_rate=0.1, n_estimators=85, num_leaves=29, max_depth=7, min_data_in_leaf=45,
min_child_weight=0.001,bagging_fraction=0.9, feature_fraction=0.9, bagging_freq=40,
min_split_gain=0, reg_lambda=None, reg_alpha=None, param_grid=lgb_params)
"""
确定reg_lambda、reg_alpha都为0,下面进行min_split_gain的调参
"""
lgb_params = {'min_split_gain': [i/10 for i in range(0,11,1)]}
get_best_cv_params(learning_rate=0.1, n_estimators=85, num_leaves=29, max_depth=7, min_data_in_leaf=45,
min_child_weight=0.001,bagging_fraction=0.9, feature_fraction=0.9, bagging_freq=40,
min_split_gain=None, reg_lambda=0, reg_alpha=0, param_grid=lgb_params)
'''
模型当前最优参数为:{'max_depth': 3, 'num_leaves': 10}
模型当前最优得分为:0.7205613577006256
模型当前最优参数为:{'max_depth': 5, 'num_leaves': 32}
模型当前最优得分为:0.7184441089604138
模型当前最优参数为:{'bagging_fraction': 0.5, 'bagging_freq': 0, 'feature_fraction': 0.5}
模型当前最优得分为:0.720551149472765
模型当前最优参数为:{'reg_alpha': 0.5, 'reg_lambda': 0.01}
模型当前最优得分为:0.7183820010400103
模型当前最优参数为:{'min_split_gain': 0.0}
模型当前最优得分为:0.7183197396650165
'''
"""
参数确定好了以后,我们设置一个比较小的learning_rate 0.005,来确定最终的num_boost_round
"""
# 设置5折交叉验证
# cv_fold = StratifiedKFold(n_splits=5, random_state=0, shuffle=True, )
final_params = {
'boosting_type': 'gbdt',
'learning_rate': 0.01,
'num_leaves': 29,
'max_depth': 7,
'min_data_in_leaf':45,
'min_child_weight':0.001,
'bagging_fraction': 0.9,
'feature_fraction': 0.9,
'bagging_freq': 40,
'min_split_gain': 0,
'reg_lambda':0,
'reg_alpha':0,
'nthread': 6
}
cv_result = lgb.cv(train_set=lgb_train,
early_stopping_rounds=20,
num_boost_round=5000,
nfold=5,
stratified=True,
shuffle=True,
params=final_params,
metrics='auc',
seed=0,
)
print('迭代次数{}'.format(len(cv_result['auc-mean'])))
print('交叉验证的AUC为{}'.format(max(cv_result['auc-mean'])))
'''
迭代次数1059
交叉验证的AUC为0.7180641526308893
'''在实际调整过程中,可先设置一个较大的学习率(上面的例子中0.1),通过Lgb原生的cv函数进行树个数的确定,之后再通过上面的实例代码进行参数的调整优化。
最后针对最优的参数设置一个较小的学习率(例如0.05),同样通过cv函数确定树的个数,确定最终的参数。
需要注意的是,针对大数据集,上面每一层参数的调整都需要耗费较长时间,
贝叶斯调参
在使用之前需要先安装包bayesian-optimization,运行如下命令即可:
pip install bayesian-optimization贝叶斯调参的主要思想是:给定优化的目标函数(广义的函数,只需指定输入和输出即可,无需知道内部结构以及数学性质),通过不断地添加样本点来更新目标函数的后验分布(高斯过程,直到后验分布基本贴合于真实分布)。简单的说,就是考虑了上一次参数的信息,从而更好的调整当前的参数。
贝叶斯调参的步骤如下:
-
定义优化函数(rf_cv)
-
建立模型
-
定义待优化的参数
-
得到优化结果,并返回要优化的分数指标
from sklearn.model_selection import cross_val_score
"""定义优化函数"""
def rf_cv_lgb(num_leaves, max_depth, bagging_fraction, feature_fraction, bagging_freq, min_data_in_leaf,
min_child_weight, min_split_gain, reg_lambda, reg_alpha):
# 建立模型
model_lgb = lgb.LGBMClassifier(boosting_type='gbdt', bjective='binary', metric='auc',
learning_rate=0.1, n_estimators=5000,
num_leaves=int(num_leaves), max_depth=int(max_depth),
bagging_fraction=round(bagging_fraction, 2), feature_fraction=round(feature_fraction, 2),
bagging_freq=int(bagging_freq), min_data_in_leaf=int(min_data_in_leaf),
min_child_weight=min_child_weight, min_split_gain=min_split_gain,
reg_lambda=reg_lambda, reg_alpha=reg_alpha,
n_jobs= 8
)val = cross_val_score(model_lgb, X_train_split, y_train_split, cv=5, scoring='roc_auc').mean() return valfrom bayes_opt import BayesianOptimization
"""定义优化参数"""
bayes_lgb = BayesianOptimization(
rf_cv_lgb,
{
'num_leaves':(10, 200),
'max_depth':(3, 20),
'bagging_fraction':(0.5, 1.0),
'feature_fraction':(0.5, 1.0),
'bagging_freq':(0, 100),
'min_data_in_leaf':(10,100),
'min_child_weight':(0, 10),
'min_split_gain':(0.0, 1.0),
'reg_alpha':(0.0, 10),
'reg_lambda':(0.0, 10),
}
)"""开始优化"""
bayes_lgb.maximize(n_iter=10)
'''
| iter | target | baggin... | baggin... | featur... | max_depth | min_ch... | min_da... | min_sp... | num_le... | reg_alpha | reg_la... || 1 | 0.7215 | 0.9392 | 95.45 | 0.6283 | 5.154 | 7.348 | 91.96 | 0.5477 | 120.7 | 7.505 | 9.202 |
| 2 | 0.71 | 0.684 | 94.13 | 0.8277 | 19.45 | 7.331 | 61.9 | 0.9874 | 154.8 | 4.961 | 9.6 |
| 3 | 0.6909 | 0.8767 | 88.37 | 0.9072 | 13.04 | 8.679 | 67.01 | 0.2087 | 60.06 | 4.917 | 7.913 |
| 4 | 0.7039 | 0.9278 | 93.26 | 0.8414 | 13.85 | 9.21 | 58.29 | 0.1119 | 145.3 | 8.758 | 6.015 |
| 5 | 0.7017 | 0.5537 | 81.02 | 0.8678 | 11.87 | 8.096 | 66.72 | 0.3476 | 75.52 | 8.34 | 8.425 |
| 6 | 0.6862 | 0.7061 | 2.857 | 0.6029 | 14.35 | 8.872 | 95.47 | 0.2094 | 189.3 | 4.545 | 0.7469 |
| 7 | 0.7138 | 0.9789 | 90.64 | 0.9698 | 4.522 | 7.877 | 91.99 | 0.5461 | 120.9 | 5.981 | 5.123 |
| 8 | 0.7037 | 0.6634 | 3.512 | 0.9382 | 16.65 | 0.5806 | 99.08 | 0.1003 | 13.15 | 5.831 | 9.107 |
| 9 | 0.7165 | 0.9229 | 5.36 | 0.6364 | 4.753 | 0.2156 | 11.34 | 0.4025 | 142.4 | 0.8094 | 9.965 |
| 10 | 0.7089 | 0.7184 | 88.74 | 0.7707 | 3.606 | 2.881 | 97.5 | 0.449 | 197.4 | 0.2642 | 8.432 |
| 11 | 0.7205 | 0.7023 | 0.8461 | 0.6837 | 4.451 | 0.1962 | 98.99 | 0.5646 | 121.4 | 1.132 | 7.109 |
| 12 | 0.7095 | 0.7484 | 60.44 | 0.8154 | 18.32 | 0.1824 | 92.3 | 0.4826 | 121.7 | 8.076 | 9.022 |
| 13 | 0.7218 | 0.6624 | 0.4073 | 0.6209 | 10.12 | 9.756 | 11.65 | 0.7693 | 66.48 | 2.389 | 8.42 |
| 14 | 0.7121 | 0.8146 | 30.9 | 0.6707 | 4.363 | 9.534 | 99.38 | 0.8295 | 81.61 | 0.8718 | 9.47 |
| 15 | 0.7211 | 0.9868 | 6.277 | 0.5831 | 3.081 | 4.593 | 13.51 | 0.2815 | 19.4 | 1.544 | 8.067 |'''
"""显示优化结果"""
bayes_lgb.max
'''
{'target': 0.7282530196283977,
'params': {'bagging_fraction': 0.9815471914843896,
'bagging_freq': 96.14757648686668,
'feature_fraction': 0.6961281791730929,
'max_depth': 19.45450235568963,
'min_child_weight': 1.6266132496156782,
'min_data_in_leaf': 37.697878831472295,
'min_split_gain': 0.4184947943942168,
'num_leaves': 14.221122487200399,
'reg_alpha': 7.056502173310882,
'reg_lambda': 9.924023764203156}}
'''
参数优化完成后,我们可以根据优化后的参数建立新的模型,降低学习率并寻找最优模型迭代次数
"""调整一个较小的学习率,并通过cv函数确定当前最优的迭代次数"""
base_params_lgb = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'learning_rate': 0.01,
'num_leaves': 14,
'max_depth': 19,
'min_data_in_leaf': 37,
'min_child_weight':1.6,
'bagging_fraction': 0.98,
'feature_fraction': 0.69,
'bagging_freq': 96,
'reg_lambda': 9,
'reg_alpha': 7,
'min_split_gain': 0.4,
'nthread': 8,
'seed': 2020,
'silent': True,
'verbose': -1,
}
cv_result_lgb = lgb.cv(
train_set=train_matrix,
early_stopping_rounds=1000,
num_boost_round=20000,
nfold=5,
stratified=True,
shuffle=True,
params=base_params_lgb,
metrics='auc',
seed=0
)
print('迭代次数{}'.format(len(cv_result_lgb['auc-mean'])))
print('最终模型的AUC为{}'.format(max(cv_result_lgb['auc-mean'])))
'''
迭代次数3215
最终模型的AUC为0.721889151179439
'''模型参数已经确定,建立最终模型并对验证集进行验证
import lightgbm as lgb
"""使用lightgbm 5折交叉验证进行建模预测"""
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(X_train, y_train)):
print('************************************ {} ************************************'.format(str(i+1)))
X_train_split, y_train_split, X_val, y_val = X_train.iloc[train_index], y_train[train_index], X_train.iloc[valid_index], y_train[valid_index]
train_matrix = lgb.Dataset(X_train_split, label=y_train_split)
valid_matrix = lgb.Dataset(X_val, label=y_val)
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'learning_rate': 0.01,
'num_leaves': 14,
'max_depth': 19,
'min_data_in_leaf': 37,
'min_child_weight':1.6,
'bagging_fraction': 0.98,
'feature_fraction': 0.69,
'bagging_freq': 96,
'reg_lambda': 9,
'reg_alpha': 7,
'min_split_gain': 0.4,
'nthread': 8,
'seed': 2020,
'silent': True,
}
model = lgb.train(params, train_set=train_matrix, num_boost_round=14269, valid_sets=valid_matrix, verbose_eval=1000, early_stopping_rounds=200)
val_pred = model.predict(X_val, num_iteration=model.best_iteration)
cv_scores.append(roc_auc_score(y_val, val_pred))
print(cv_scores)
print("lgb_scotrainre_list:{}".format(cv_scores))
print("lgb_score_mean:{}".format(np.mean(cv_scores)))
print("lgb_score_std:{}".format(np.std(cv_scores)))
'''
Training until validation scores don't improve for 200 rounds
[1000] valid_0's auc: 0.720332
[2000] valid_0's auc: 0.722657
[3000] valid_0's auc: 0.723496
[4000] valid_0's auc: 0.723793
Early stopping, best iteration is:
[4269] valid_0's auc: 0.723819
[0.7243424620141432, 0.7204284963319504, 0.7244112277258064, 0.7236275941145316, 0.7238187793702997]
lgb_scotrainre_list:[0.7243424620141432, 0.7204284963319504, 0.7244112277258064, 0.7236275941145316, 0.7238187793702997]
lgb_score_mean:0.7233257119113462
lgb_score_std:0.001479204641160483
'''通过5折交叉验证可以发现,模型迭代次数在13000次的时候会停之,那么我们在建立新模型时直接设置最大迭代次数,并使用验证集进行模型预测
""""""
base_params_lgb = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'learning_rate': 0.01,
'num_leaves': 14,
'max_depth': 19,
'min_data_in_leaf': 37,
'min_child_weight':1.6,
'bagging_fraction': 0.98,
'feature_fraction': 0.69,
'bagging_freq': 96,
'reg_lambda': 9,
'reg_alpha': 7,
'min_split_gain': 0.4,
'nthread': 8,
'seed': 2020,
'silent': True,
}
"""使用训练集数据进行模型训练"""
final_model_lgb = lgb.train(base_params_lgb, train_set=train_matrix, valid_sets=valid_matrix, num_boost_round=13000, verbose_eval=1000, early_stopping_rounds=200)
"""预测并计算roc的相关指标"""
val_pre_lgb = final_model_lgb.predict(X_val)
fpr, tpr, threshold = metrics.roc_curve(y_val, val_pre_lgb)
roc_auc = metrics.auc(fpr, tpr)
print('调参后lightgbm单模型在验证集上的AUC:{}'.format(roc_auc))
"""画出roc曲线图"""
plt.figure(figsize=(8, 8))
plt.title('Validation ROC')
plt.plot(fpr, tpr, 'b', label = 'Val AUC = %0.4f' % roc_auc)
plt.ylim(0,1)
plt.xlim(0,1)
plt.legend(loc='best')
plt.title('ROC')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
# 画出对角线
plt.plot([0,1],[0,1],'r--')
plt.show()
'''
Training until validation scores don't improve for 200 rounds
[1000] valid_0's auc: 0.720332
[2000] valid_0's auc: 0.722657
[3000] valid_0's auc: 0.723496
[4000] valid_0's auc: 0.723793
Early stopping, best iteration is:
[4269] valid_0's auc: 0.723819
调参后lightgbm单模型在验证集上的AUC:0.7238187793702997
'''
可以看到相比最早的原始参数,模型的性能还是有提升的
"""保存模型到本地"""
# 保存模型
import pickle
pickle.dump(final_model_lgb, open('dataset/model_lgb_best.pkl', 'wb'))模型调参小总结
-
集成模型内置的cv函数可以较快的进行单一参数的调节,一般可以用来优先确定树模型的迭代次数
-
数据量较大的时候(例如本次项目的数据),网格搜索调参会特别特别慢,不建议尝试
-
集成模型中原生库和sklearn下的库部分参数不一致,需要注意,具体可以参考xgb和lgb的官方API
经验总结
在博客中,我们主要完成了建模与调参的工作,首先在建模的过程中通过划分数据集、交叉验证等方式对模型的性能进行评估验证,并通过可视化方式绘制模型ROC曲线。
最后我们对模型进行调参,这部分介绍了贪心调参、网格搜索调参、贝叶斯调参共三种调参手段,重点使用贝叶斯调参对本次项目进行简单优化,大家在实际操作的过程中可以参考调参思路进行优化,不必拘泥于以上所写的具体实例。
推荐博客:
- GBDT模型
https://zhuanlan.zhihu.com/p/45145899 - XGBoost模型
https://blog.csdn.net/wuzhongqiang/article/details/104854890 - LightGBM模型
https://blog.csdn.net/wuzhongqiang/article/details/105350579 - Catboost模型
https://mp.weixin.qq.com/s/xloTLr5NJBgBspMQtxPoFA - 时间序列模型
RNN:https://zhuanlan.zhihu.com/p/45289691
LSTM:https://zhuanlan.zhihu.com/p/83496936
推荐教材:
-
《面向机器学习的特征工程》 https://book.douban.com/subject/26826639/
-
《信用评分模型技术与应用》https://book.douban.com/subject/1488075/
关注
-
1
-
-
22
-
0
-
分享
-
打赏
-
专栏目录
4259
数据挖掘实践(金融风控):金融风控之贷款违约预测挑战赛(上篇)xgboots/lightgbm/Catboost等模型--模型融合:stacking、blending
1234
832
415
08-24