
image-93
检索增强生成(RAG)1最初于2020年提出,作为一种结合预训练检索器和预训练生成器的端到端方法。当时,其主要目标是通过模型微调来提升性能。
2022年12月ChatGPT的发布标志着RAG的重要转折点。从那时起,RAG更多地专注于利用大语言模型(LLM)的推理能力,通过整合外部知识来实现更好的生成效果。
RAG技术使开发者无需为每个特定任务重新训练整个大规模模型。相反,他们只需连接相关的知识库,为模型提供额外的输入,从而提高答案的准确性。
本文简要介绍RAG的概念、目的和特点。
什么是检索增强生成(RAG)?
检索增强生成(RAG)1是通过整合外部知识源的额外信息来增强大语言模型(LLM)的过程。这使得LLM能够生成更准确、更具上下文感知能力的答案,同时减少幻觉现象。
在回答问题或生成文本时,首先从现有知识库或大量文档中检索相关信息。然后使用LLM生成答案,通过整合这些检索到的信息来提高响应质量,而不是仅仅依靠LLM来生成。
RAG的典型工作流程如图1所示。
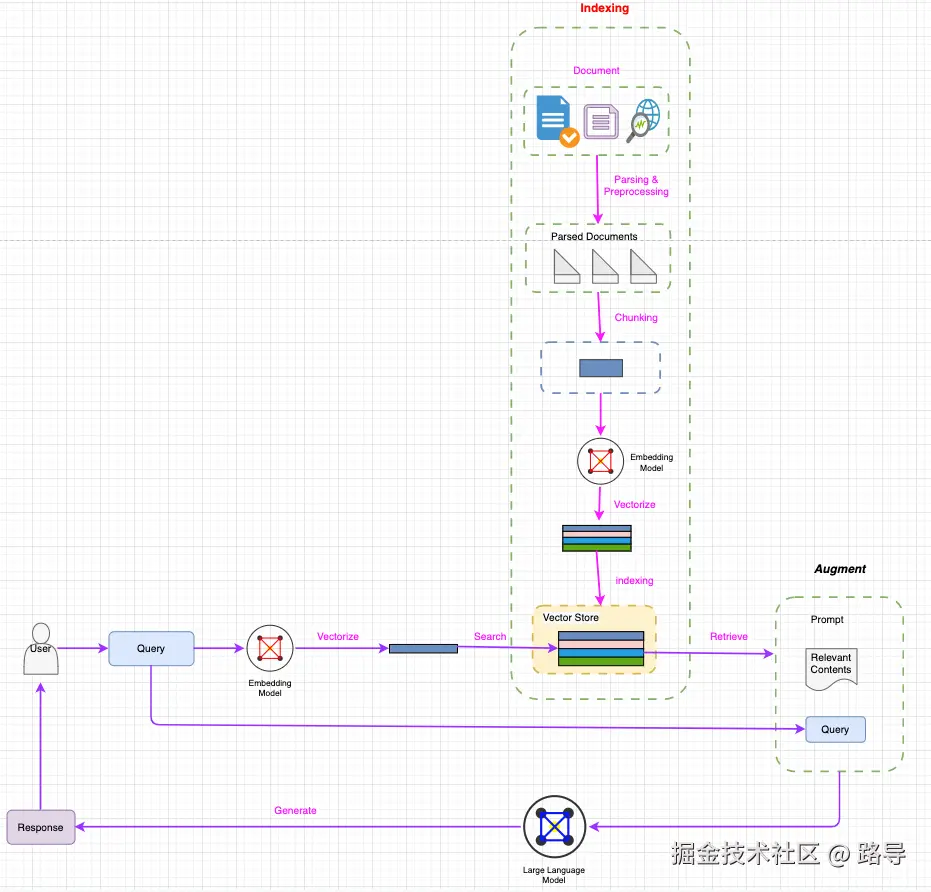
image-92
图1:RAG的典型工作流程
如图1所示,RAG主要包含以下步骤:
索引构建:索引过程是离线执行的关键初始步骤。它首先清洗和提取原始数据,将PDF、HTML和Word等各种文件格式转换为标准化的纯文本。为了适应语言模型的上下文限制,这些文本被分割成更小、更易管理的块,这个过程称为分块。然后,这些文本块通过嵌入模型转换为向量表示。最后,创建一个索引,以键值对的形式存储这些文本块及其向量嵌入,从而实现高效且可扩展的搜索功能。
检索:用户查询用于从外部知识源检索相关上下文。为此,用户查询通过编码模型处理,生成语义相关的嵌入。然后,在向量数据库中进行相似性搜索,检索出最相近的前k个数据对象。
生成:将用户查询和检索到的额外上下文填充到提示模板中。最后,将检索步骤得到的增强提示输入到LLM中。
为什么需要RAG?
既然有了LLM,为什么还需要RAG?原因很简单:LLM无法解决RAG能够解决的问题。这些问题包括:
模型幻觉问题:LLM的文本生成基于概率。在缺乏足够事实支撑的情况下,它可能生成看似严肃但缺乏连贯性的内容。
时效性问题:LLM的参数规模越大,训练成本越高,所需时间越长。因此,时效性数据可能无法及时纳入训练,导致模型无法直接回答时效性问题。
数据安全问题:通用LLM无法访问企业内部或用户私有数据。为了在使用LLM的同时确保数据安全,一个好的解决方案是将数据存储在本地并在本地执行所有数据计算。云端LLM仅用于信息总结。
答案约束问题:RAG对LLM生成提供了更多控制。例如,当一个问题涉及多个知识点时,通过RAG检索到的线索可以用来限制LLM生成的边界。
RAG的特点是什么?
RAG具有以下特点,使其能够有效解决上述问题:
-
- 可扩展性:RAG减少了模型规模和训练成本,便于快速扩展知识。
-
- 准确性:模型基于事实提供答案,最大限度地减少幻觉的发生。
-
- 可控性:RAG允许知识更新和定制。
-
- 可解释性:检索到的相关信息可作为模型预测的参考依据。
-
- 通用性:RAG可以针对问答、摘要、对话等各种任务进行微调和定制。
结论
形象地说,RAG可以比作LLM的开卷考试。就像开卷考试一样,学生可以携带参考资料,查阅相关信息来回答问题。
本文仅介绍了RAG的基础知识。未来将介绍许多高级RAG技术。
1: Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv preprint arXiv:2005.11401, 2023.