摘要
技术背景:Text2SQL 是将自然语言查询转为 SQL 的任务,经历了基于规则、神经网络、预训练语言模型、大语言模型四个阶段。当前面临提示优化、模型训练、推理时增强三大难题,研究基于 BIRD 数据集展开。
方法:提出 J-Schema 呈现数据库结构并合理提供示例值,结合思维链引导模型推理。采用 Iterative DPO 迭代训练,多轮迭代提升性能。用自洽性方法,通过硬 / 软投票从多个候选答案中选最优,软投票更优。
结果:解决 Text2SQL 性能提升的三大难题,将模型在 BIRD 数据集上的执行准确率从 56.6% 提升至 69.2%。
一、Text2SQL挑战
自然语言到 SQL(Text-to-SQL),也称为 NL2SQL,是将自然语言查询转换为可在关系数据库上执行的相应SQL查询的任务。具体来说,给定一个自然语言和一个关系数据库,Text-to-SQL 的目标是生成一个SQL,该SQL能够准确反映用户的意图,并在数据库上执行时返回适当的结果。通过将自然语言查询转换为结构化查询语言的能力,使复杂数据集更易于访问。它极大地促进了非专业用户和高级用户从大量数据存储中提取价值信息。
Text-to-SQL 解决方案的演进,经历了四个不同阶段:
1. 基于规则阶段:早期的Text2SQL方法主要依赖于基于规则的统计语言模型,主要聚焦于单表查询,理解能力仅限于词元阶段;
2. 基于神经网络阶段:神经网络模型(序列模型、图神经模型),提升了同义词处理和意图理解能力,使研究从单表扩展到多表场景。但其泛化能力仍受模型规模和训练数据量限制;
3. 预训练语言模型阶段:预训练语言模型(如BERT和T5)的引入显著提升了性能,极大增强了自然语言理解能力;
4. 大语言模型阶段:LLM凭借强大的涌现能力,成为当前Text2SQL领域的主流方案。研究重心转向优化提示工程和微调LLM。
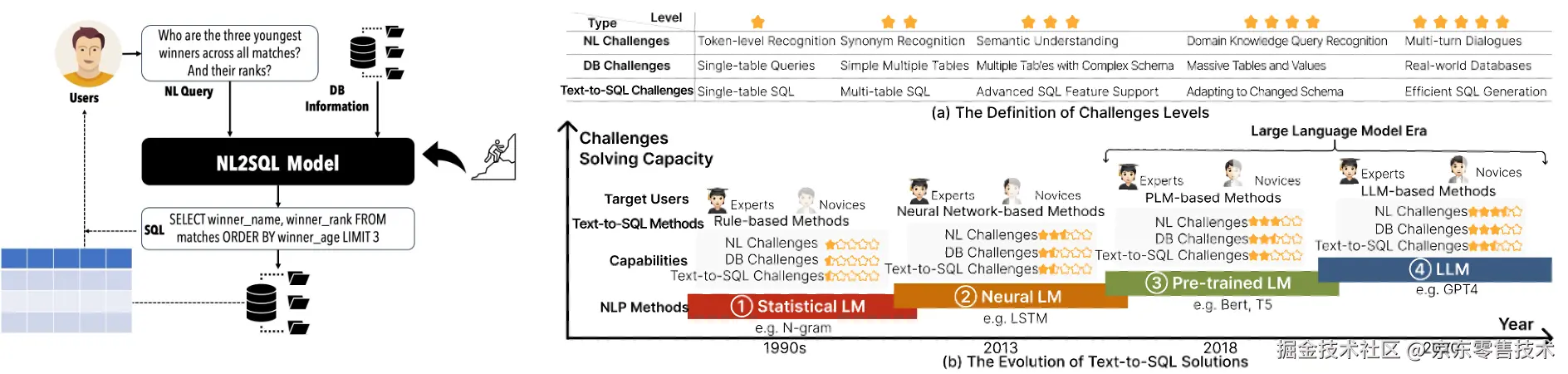
Text2SQL性能的提升,面临着以下三个难题。
提示优化: 怎么引导大模型给出明确的推理过程?数据库的Schema要怎么设计,才能让大模型更容易理解?
模型训练: 如何通过训练方法提升模型的基础能力?
推理时增强: 大模型生成答案时好时坏,有什么办法能让输出更加稳定可靠?
我们从这三个维度,分别给出了我们的答案。在本文中使用的数据集来自BIRD(BIg Bench for LaRge-scale Database Grounded Text-to-SQL Evaluation)。BIRD考察了大规模数据库内容对文本到 SQL 解析的影响。BIRD 包含超过12,751个独特的问题-SQL对,95 个大型数据库,还涵盖了超过 37 个专业领域,例如区块链、冰球、医疗保健和教育等。
二、Prompt & J-Schema
要让 LLM 理解数据库结构,需在提示中提供数据库模式。为此,我们提出一种名为 J-Schema 的新型数据库表达方式 。J-Schema 以完全结构化的格式呈现数据、表与列之间的层次关系,并采用特殊标记进行识别:用 "#DB_ID" 标记数据库,"#Table" 表示表,"#Foreign keys" 表示外键。对于每个表,会给出表名;列信息则通过 "basic_info" 标识,其中包含列名、列描述、主键标识符,且为每个列提供示例值。

对于单一模型而言,在无法执行值检索的情况下,提供尽可能丰富的示例值有助于模型深化对列的理解。然而,示例值过多会受限于上下文长度。为平衡示例值数量与上下文长度之间的关系,我们为值建立了新的显示规则。
1."DATE"、"TIME"、"DATETIME"、"TIMESTAMP"等表示时间的数据类型,只保留一个示例;
2."REAL"浮点数据类型,保留两位小数一个示例;
3.针对"INTEGER"整型,保留一个示例;
4.针对"TEXT"文本类型,根据分词长度保留。小于10 token保留多个示例。
在这套规则背后,包含了我们对大量错误样本的分析 。对于日期、浮点数、整数这些数据类型,大模型往往是根据问题中的日期、时间要求来取值,因此增加这些数据类型的示例对最终的结果影响不大。而针对文本数据类型,往往涉及到用户查询和数据库中值格式不统一问题。例如问题询问的关键字是大写的"North Bohemia",而数据库中的值为小写的"north Bohemia",若给出的示例中包含"north Bohemia",则可以正确检索。实验验证J-Schema在多个模型上均有执行准确率较大提升。
| 问题 | 正确答案 | 错误答案 | 原因分析 |
|---|---|---|---|
| What is the city location of the high school level school with Lunch Provision 2 whose lowest grade is 9 and the highest grade is 12 in the county of Merced? | SELECT T2.City FROM frpm AS T1 INNER JOIN schools AS T2 ON T1.CDSCode = T2.CDSCode WHERE T1.NSLP Provision Status = 'Lunch Provision 2 ' AND T2.County = 'Merced' AND T1.Low Grade = 9 AND T1.High Grade = 12 AND T2.EILCode = 'HS' |
SELECT T2.City FROM main.frpm AS T1 INNER JOIN main.schools AS T2 ON T1.CDSCode = T2.CDSCode WHERE T1."NSLP Provision Status" = 'Breakfast Provision 2' AND T1."Low Grade" = '9' AND T1."High Grade" = '12' AND T1."County Name" = 'Merced'; | 要求检索的是"Lunch Provision 2",因为示例值只给出了"Breakfast Provision 2",导致检索错误。可以通过增加示例解决。 |
| How many accounts who choose issuance after transaction are staying in East Bohemia region? | SELECT COUNT(T2.account_id) FROM district AS T1 INNER JOIN account AS T2 ON T1.district_id = T2.district_id WHERE T1.A3 = 'east Bohemia' AND T2.frequency = 'POPLATEK PO OBRATU' | SELECT COUNT(T1.account_id) FROM main.account AS T1 INNER JOIN main.district AS T2 ON T1.district_id = T2.district_id WHERE T1.frequency = 'POPLATEK PO OBRATU' AND T2.A3 = 'East Bohemia' | 问题的格式"East Bohemia"与示例值"east Bohemia"的格式不统一,增加示例值,让模型学习到标准的值格式。 |
思维链(Chain of Thought, CoT)是一种提升大语言模型复杂推理能力的提示工程技术,核心是引导模型在输出最终答案前,先生成连贯的中间推理步骤,模拟人类逐步思考的过程。在我们的提示中首先给出完整的数据库信息,然后添加用户查询和外部知识,并给出引导大模型分步进行推理的提示,将推理过程输出在和标记内,将最终的SQL答案输出在和标记内。
三、训练方法
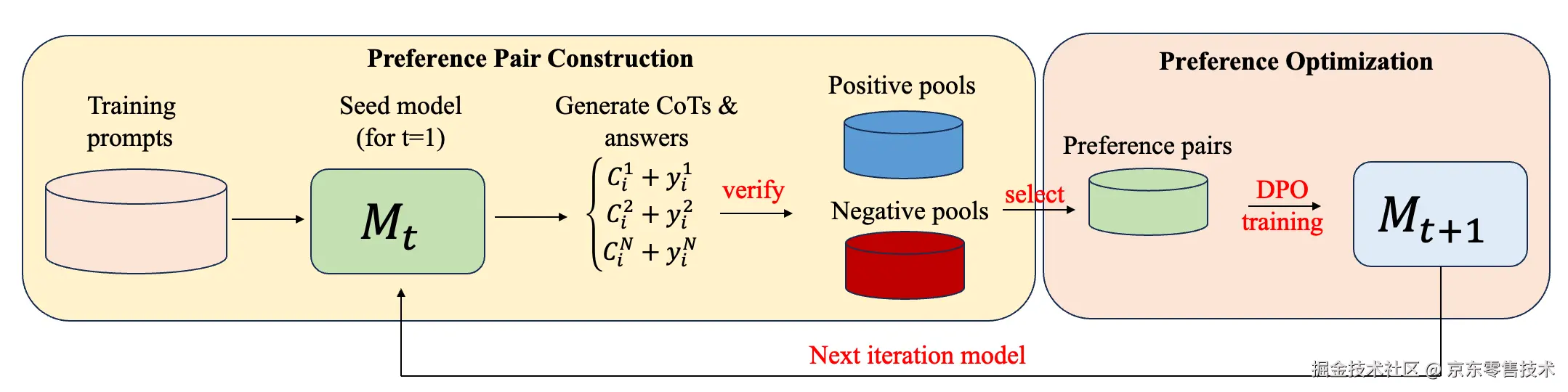
Iterative DPO
偏好优化已被证明,在将预训练语言模型与人类需求对齐时,相较于单独的监督微调能带来巨大的收益。DPO等离线方法因其简单性和效率而越来越受欢迎。最近的研究结果表明,迭代应用这种离线流程是有益的,其中更新后的模型被用来构建更具有信息量的新偏好关系,从而进一步改善结果。为了提高模型的基础能力,我们采用迭代式的DPO训练方法。
具体而言,在每次迭代中,我们从训练提示中采样多个思维链推理步骤和最终答案,通过验证最终答案,构建正例池和负例池,在正、负例池根据距离挑选来构建偏好对,然后进行DPO训练。在训练新模型后,我们通过生成新偏好对并重新训练来迭代该过程。我们发现推理性能在多次迭代后逐渐提高,最终达到饱和。
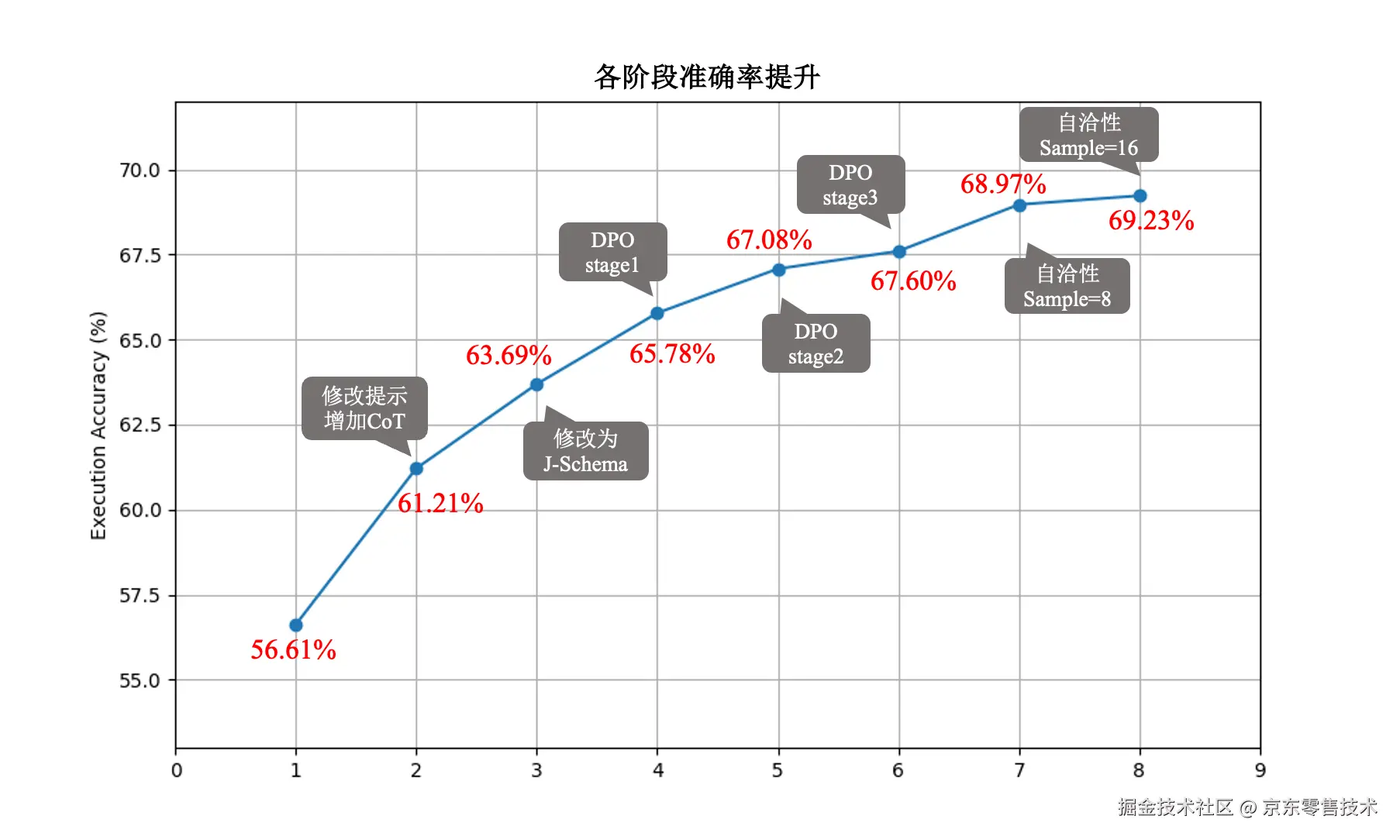
每一轮迭代中Text2SQL准确率提升如下表所示。在第三轮迭代中执行准确率达到最高,并饱和,继续迭代执行准确率下降。并且随着迭代轮次的增加,思维链的长度也在不断增加。
| 模型 | 平均CoT token长度 | 执行准确率EX |
|---|---|---|
| Qwen2.5-Coder-32B | 334 | 63.69% |
| iterative stage1 | 377 | 65.78% |
| iterative stage2 | 377 | 67.08% |
| iterative stage3 | 380 | 67.60% |
| iterative stage4 | 384 | 67.40% |
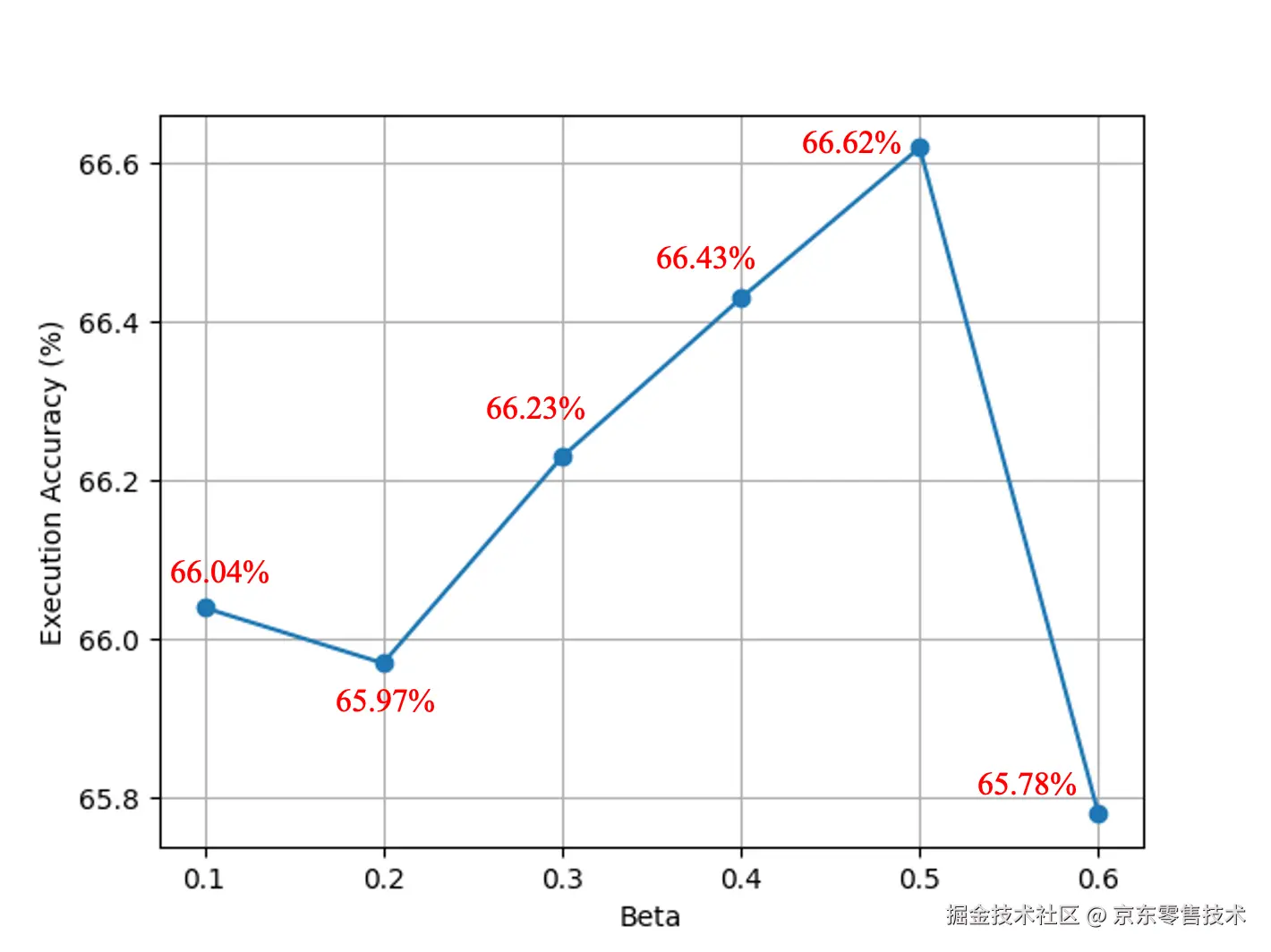
超参数扫描
我们通过DPO方法进行训练, beta是DPO Loss中的权重系数,数值越小越忽略参考模型,通常取0.1~0.5。因为我们观察到DPO对齐算法对这一参数特别敏感。我们设置了beta从0.1、0.2 、...、0.6变化。所有实验均训练两个 epoch。每次运行时,其他超参数保持不变,包括随机种子。不同beta值对应的执行准确率如下图所示。当beta取0.5时,达到最高的执行准确率,后续的DPO迭代中我们都延续使用该beta值。
四、自洽性(Self-consistency)
自一致性的核心思想是:让模型对同一问题生成多个候选答案,然后通过投票机制选择最优解,而不是只依赖单次生成结果。在单训练模型赛道自洽性是被允许的,因为它反映了模型自身的性能。
在实现自洽性的过程中,我们使用了硬投票和软投票两种方式。硬投票直接根据模型生成结果的最终表现(如执行结果是否正确,二元判断)进行投票,不考虑结果之间的相似程度。软投票的决策依据是根据结果之间的相似程度(连续值)。如下图所示。
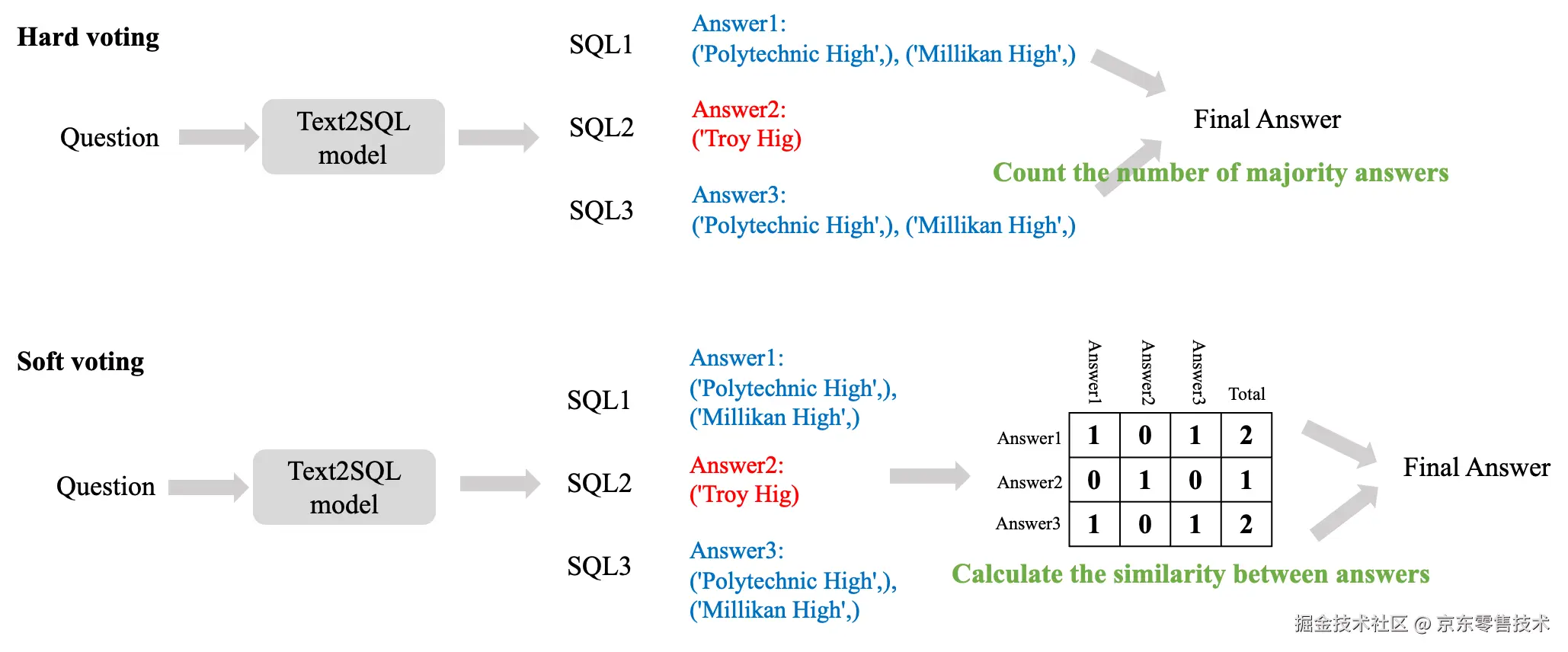
在某些场景下,硬投票可能过于严格:
•语义等价但结果有细微差异:例如 SQL 查询结果的顺序不同,但逻辑上是等价的。
•近似正确的结果:例如模型生成了一个接近正确答案的解,但存在小误差。软投票通过相似度计算,可以将这些 "近似正确" 的结果纳入考虑,从而提高最终答案的可靠性。
不同的checkpoint模型使用自洽性均获得了1%以上的执行准确率提升,其中软投票方法要优于硬投票方法。
| 模型 | 无自洽性 | 硬投票 | 软投票 |
|---|---|---|---|
| iterative stage3 | 67.60% | 67.93% | 68.97% |
| iterative stage4 | 67.40% | 67.40% | 68.45% |
五、未来探索
1. 数据构造
SynSQL-2.5M是百万规模的文本到 SQL 数据集,包含超过250万份多样且高质量的数据样本,涵盖来自不同领域的 16000 多个数据库。如何从250万份样本中筛选出对于BIRD有益的数据将会是未来的重点尝试方向。
2. 其他训练方法
•GRPO通过组内相对奖励来优化策略模型,在Text2SQL任务中,只需要定义奖励函数(例如执行正确奖励为1,执行错误奖励为0),而不需要预先构建偏好数据对。9N LLM的新镜像中提供了提交GRPO的训练任务可作尝试。在目前的尝试中,GRPO的训练时长主要受到reward验证的影响,采样n次时,每一个SQL样本都需要连接数据库执行验证来获取奖励。为了缩短训练时间,可以事先删除执行时长过长的样本。
•在BIRD训练集中,针对多轮DPO后的模型,进行多次采样时,仍然全错的样本,经过检查有很大部分是自身标签错误,使用LLM-as-Judge训练方法,使模型能够具备判断正负样本的能力,并且进一步删除标签错误的样本,保留正确样本。
3. 增加测试该优化方法的数据集和真实场景
用多个测试数据集有助于鲁棒性,能够更加全面的检验模型的性能。其中知名的数据集还有SPIDER、ScienceBenchmark、EHRSQL等。我们将在这些测试集验证我们的优化方案。并且我们会逐步推广到DataAgent的真实应用中。对于企业级的大型数据库来说,还会有哪些新的挑战?我们会持续关注,不断探索和改进!