AI Compass前沿速览:RynnVLA视觉-语言-动作模型、GLM-4.5V 、DreamVVT虚拟换衣、 WeKnora框架、GitMCP、NeuralAgent桌面AI助手
AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供从完整学习路径。
- github地址:AI-Compass👈:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass👈:https://gitee.com/tingaicompass/ai-compass
🌟 如果本项目对您有所帮助,请为我们点亮一颗星!🌟
1.每周大新闻
SkyReels-A3 -- 昆仑万维推出的数字人视频生成模型
昆仑万维推出数字人视频生成模型SkyReels - A3,基于DiT视频扩散架构,结合多项技术,通过音频驱动让照片或视频人物"激活"。
主要功能
具备照片激活、视频创作、视频台词修改、动作交互、运镜控制、长视频生成等功能。
技术原理
采用DiT架构、3D - VAE编码、插帧与延展、强化学习优化、运镜控制模块和多模态输入。
应用场景
涵盖广告营销、电商直播、影视娱乐、教育培训、新闻媒体及个人创作娱乐等领域。
项目信息
已上线SkyReels平台,项目官网为www.skyreels.ai/home
Baichuan-M2 -- 百川开源医疗大模型
百川智能推出开源医疗增强大模型Baichuan - M2。它在HealthBench评测中登顶,可在RTX 4090单卡部署,成本降低,MTP版本token速度提升,核心性能增强,更贴合真实医疗场景与中国临床需求。其技术涉及AI患者模拟器、强化学习等,应用于医疗诊断辅助、多学科会诊等场景。
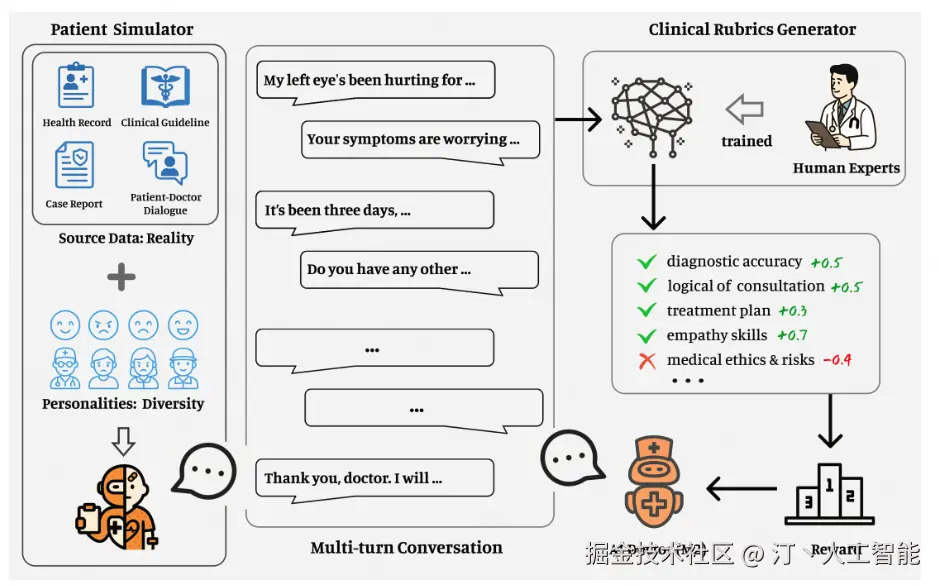
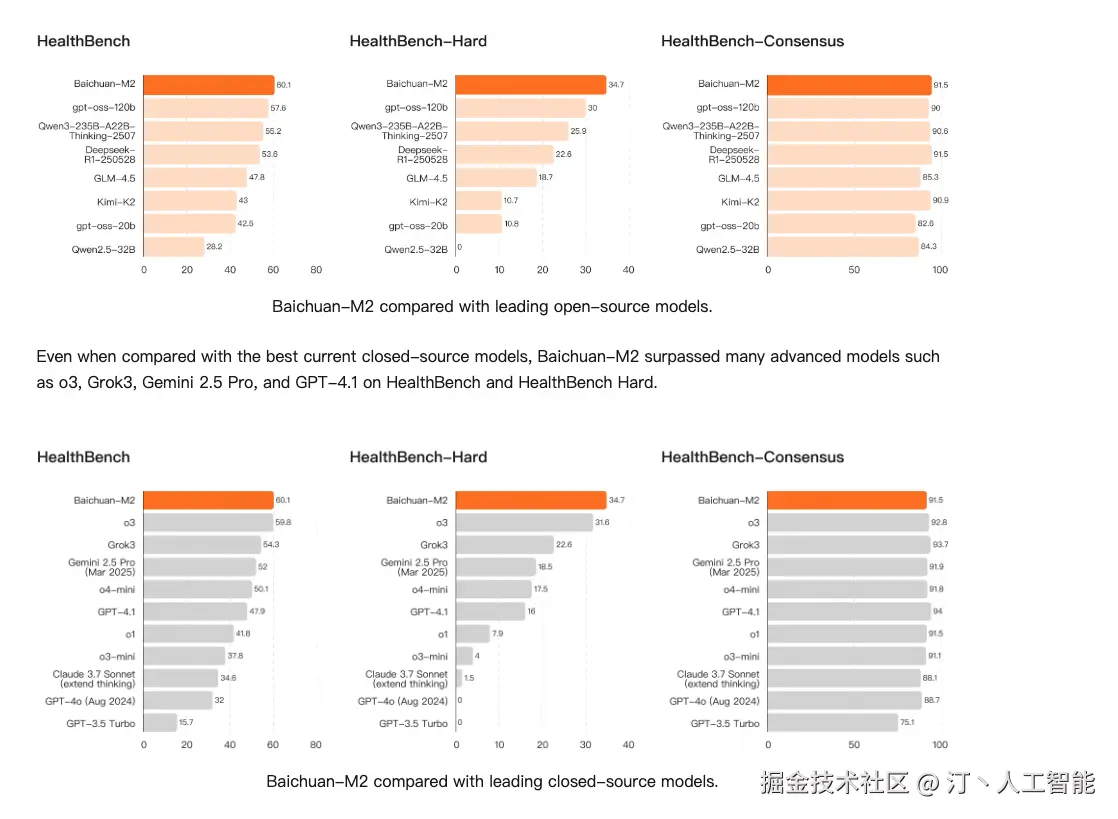
影响意义
在医疗领域表现卓越,为医疗诊断和治疗提供有力支持,降低硬件成本,适合中国医疗机构和医生使用,还可用于临床教学、患者教育等多方面。
- HuggingFace模型库:huggingface.co/baichuan-in...
- 技术论文:www.baichuan-ai.com/blog/baichu...
Sheet0 -- Data Agent,将任意数据源转为结构化数据表格
Sheet0是创新的L4级Data Agent产品,可将任意数据源转为结构化数据表格。通过自然语言交互,将任意数据源(如网页、文件、API)转化为结构化的数据表格,实现"100% 准确,0 幻觉" 的数据交付
主要功能
具备数据收集与结构化、自然语言交互、高准确性与可靠性、实时数据交付、自动化任务执行、动态优化与自我修复等功能。
应用场景
涵盖营销与销售、电商运营、知识工作、市场研究、内容创作等领域。
- 官网地址:www.sheet0.com/
2.每周项目推荐
Voost -- 创新的双向虚拟试穿和试脱AI模型
Voost 是由 Seungyong Lee 和 Jeong-gi Kwak (来自 NXN Labs) 共同开发的一个统一且可扩展的扩散变换器 (Diffusion Transformer) 框架。它旨在解决虚拟试穿中服装与身体对应关系建模的挑战,并首次将虚拟试穿 (Virtual Try-On) 和虚拟脱衣 (Virtual Try-Off) 功能整合到单一模型中,实现了双向处理,显著提高了虚拟服装合成的真实性和泛化能力。
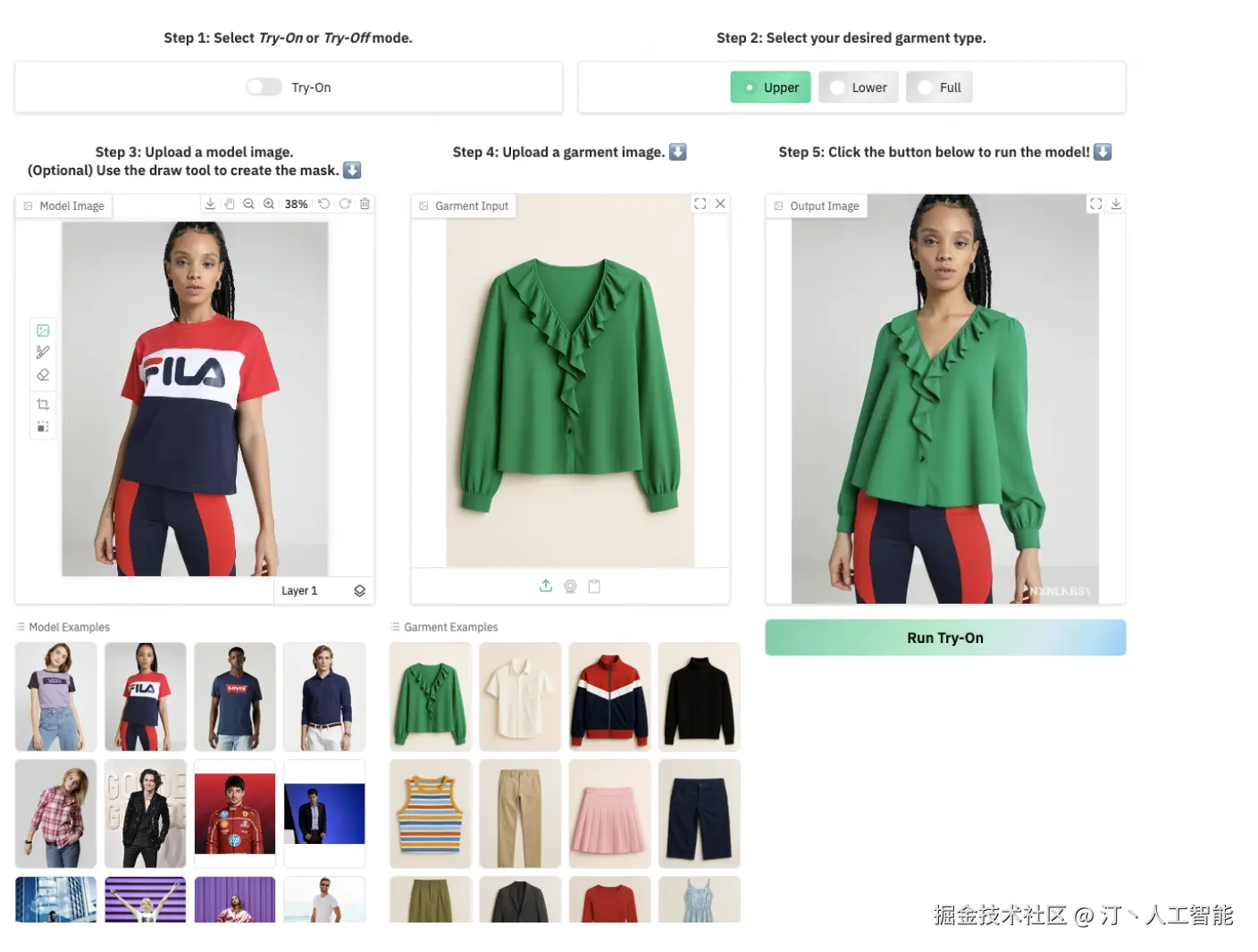

核心功能
- 统一的虚拟试穿与脱衣: 在一个模型中同时支持虚拟试穿(将服装穿到人体上)和虚拟脱衣(将服装从人体上移除)功能。
- 高保真图像合成: 生成高度逼真的人体穿着或脱下目标服装的图像。
- 鲁棒性: 能够适应不同的人体姿态、服装类别、背景、光照条件和图像构图,保持高质量输出。
- 双向监督学习: 通过联合建模试穿和脱衣任务,利用服装-人体对在两个方向上进行监督,提高模型的准确性和灵活性。
- 可扩展性: 作为一个统一且可扩展的框架,具有良好的性能和应用潜力。
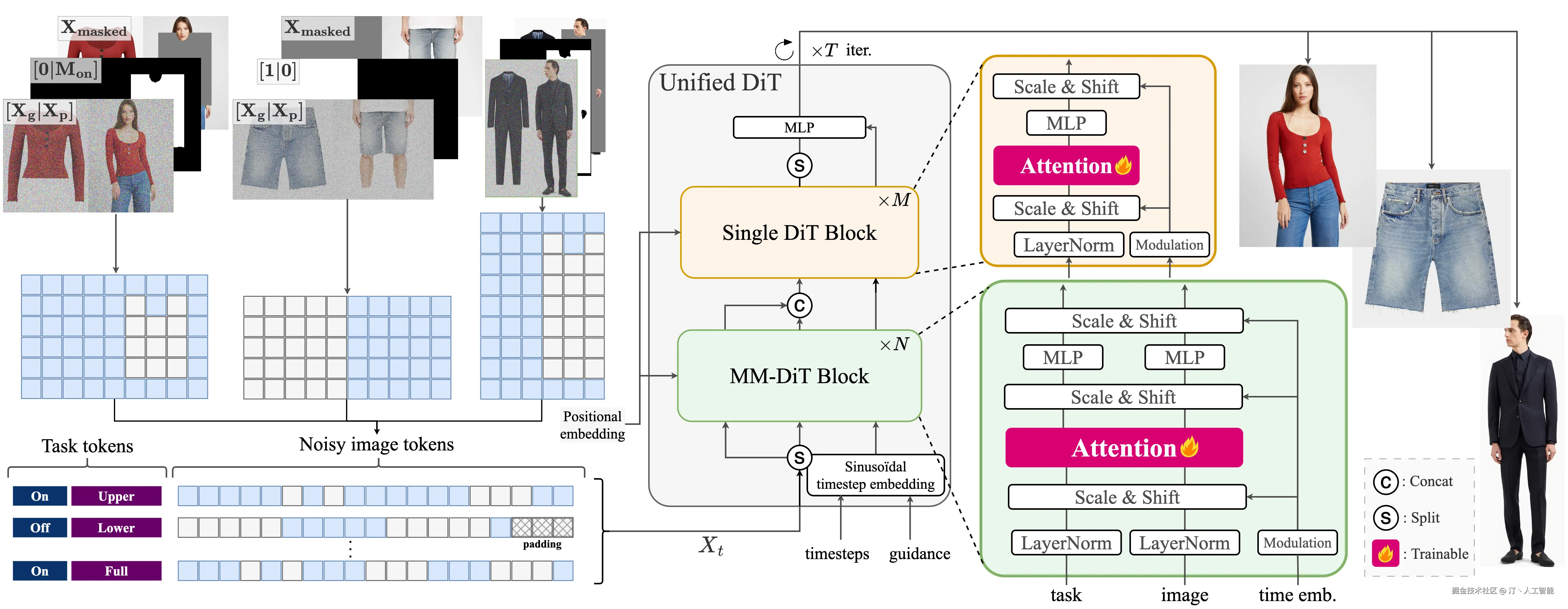
技术原理
Voost 的核心技术是其提出的"统一且可扩展的扩散变换器 (Unified and Scalable Diffusion Transformer)"。该模型利用扩散模型 (Diffusion Model) 在图像生成方面的强大能力,结合变换器架构 (Transformer Architecture) 处理序列和长距离依赖的优势,以端到端的方式学习虚拟试穿和脱衣的复杂映射关系。通过一个单一的扩散变换器,Voost 能够:
- 联合学习: 同时编码和解码人体与服装之间的复杂交互,实现试穿和脱衣任务的协同优化。
- 细节建模: 扩散模型逐步去噪的特性使其能够生成高分辨率且细节丰富的图像,精确模拟服装的褶皱、纹理和与身体的贴合。
- 变换器架构: 使得模型能够捕捉图像中不同区域(如人体姿态、服装形状、背景信息)之间的全局依赖关系,增强了模型处理复杂场景的能力和泛化性。
- 双向流: 实现从服装到人体的合成 (Try-On) 和从人体到服装的逆向合成 (Try-Off),从而在训练中提供更丰富的监督信号,提升模型对服装-身体对应关系的理解。
应用场景
-
在线虚拟试穿平台: 消费者可以在线预览服装穿着效果,提高购物体验和决策效率。
-
服装设计与制造: 设计师快速验证服装设计在不同人体模型上的效果,加速设计迭代周期。
-
时尚内容创作: 快速生成高质量的时尚宣传图片或视频,用于广告、社交媒体等。
-
虚拟现实/增强现实: 为元宇宙、虚拟形象和游戏中的服装更换提供技术支持。
-
个性化推荐系统: 结合用户身体特征和偏好,推荐最适合的服装并展示虚拟试穿效果。
-
Github仓库:github.com/nxnai/Voost
-
arXiv技术论文:arxiv.org/pdf/2508.04...
RynnVLA-001 -- 阿里达摩院开源的视觉-语言-动作模型
RynnVLA-001是阿里巴巴达摩院开发的一种视觉-语言-动作(Vision-Language-Action, VLA)模型。该模型通过大规模第一人称视角的视频进行预训练,旨在从人类示范中学习操作技能,并能够将这些技能隐式地迁移到机器人手臂的控制中,使其能够理解高层语言指令并执行复杂的任务。

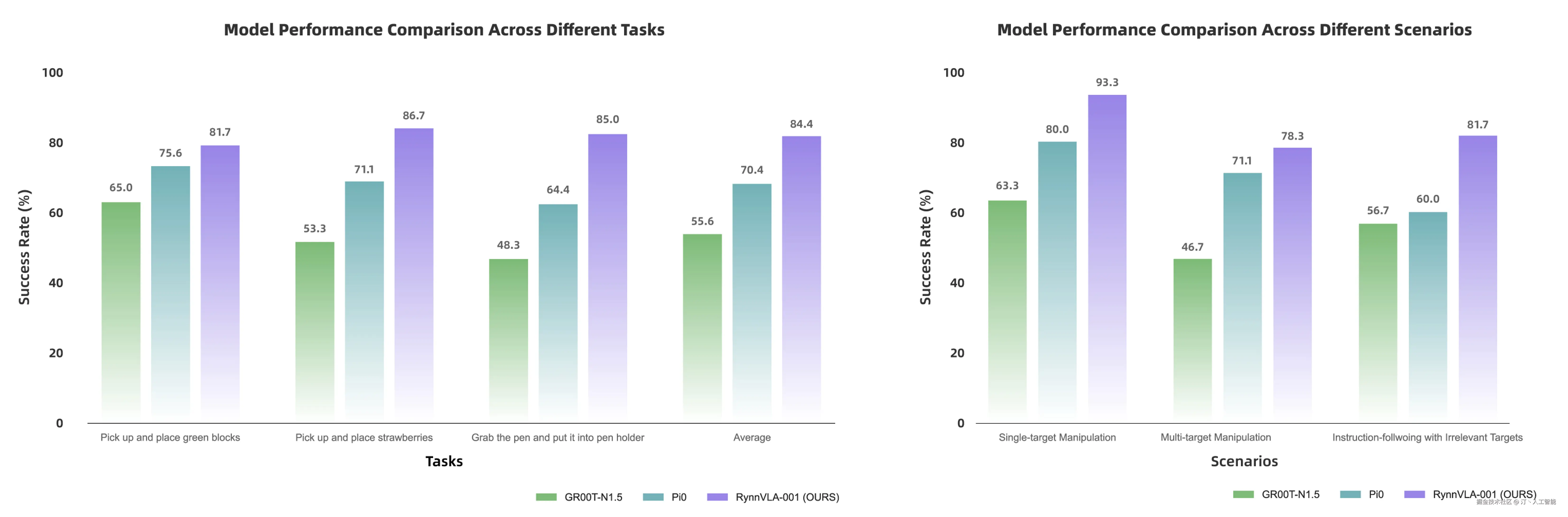
核心功能
- 视觉-语言理解与融合: 能够理解视觉输入和自然语言指令,并将两者关联起来。
- 技能学习与迁移: 从人类第一人称视角的视频示范中学习复杂的操作技能,并将其迁移到机器人平台。
- 机器人操作控制: 使机器人手臂能够精确执行抓取-放置(pick-and-place)等复杂操作任务。
- 长程任务执行: 支持机器人根据高级语言指令完成需要多步操作的长程任务。
技术原理
RynnVLA-001的核心技术原理是基于生成式先验(generative priors)构建的。它是一个简单而有效的VLA模型,其基础是一个预训练的视频生成模型。具体流程包括:
- 第一阶段:自我中心视频生成模型(Ego-centric Video Generation Model): 利用大量第一人称视频数据训练一个视频生成模型,捕捉人类操作的视觉规律。
- 第二阶段:机器人动作块的VAE压缩(VAE for Compressing Robot Action Chunks): 使用变分自编码器(VAE)对机器人动作序列进行高效压缩,提取核心动作特征。
- 第三阶段:视觉-语言-动作模型构建(Vision-Language-Action Model): 将视频生成模型和动作VAE结合,构建一个端到端的VLA模型,使其能够从视觉和语言输入中直接生成机器人动作。
应用场景
-
机器人工业自动化: 用于训练工业机器人执行精细装配、分拣和搬运等任务,提高生产线自动化水平。
-
服务机器人: 赋予服务机器人更强的环境感知和人机交互能力,使其能更好地理解并执行用户指令,例如家庭助手、医疗辅助机器人。
-
人机协作: 促进机器人更自然地与人类协作,通过观察人类操作学习新技能,提高协作效率。
-
智能家居: 应用于智能家电和自动化系统中,实现更智能、更人性化的设备控制和任务执行。
-
教育与研究: 为机器人学习、多模态AI等领域提供一个强大的研究平台和教学工具。
-
GitHub仓库:github.com/alibaba-dam...
-
HuggingFace模型库:huggingface.co/Alibaba-DAM...
RynnEC -- 阿里达摩院世界理解模型
RynnEC是阿里巴巴达摩院推出的一种世界理解模型(MLLM),专为具身认知任务设计。它旨在赋予人工智能系统对物理世界及其环境中物体深入的理解能力。
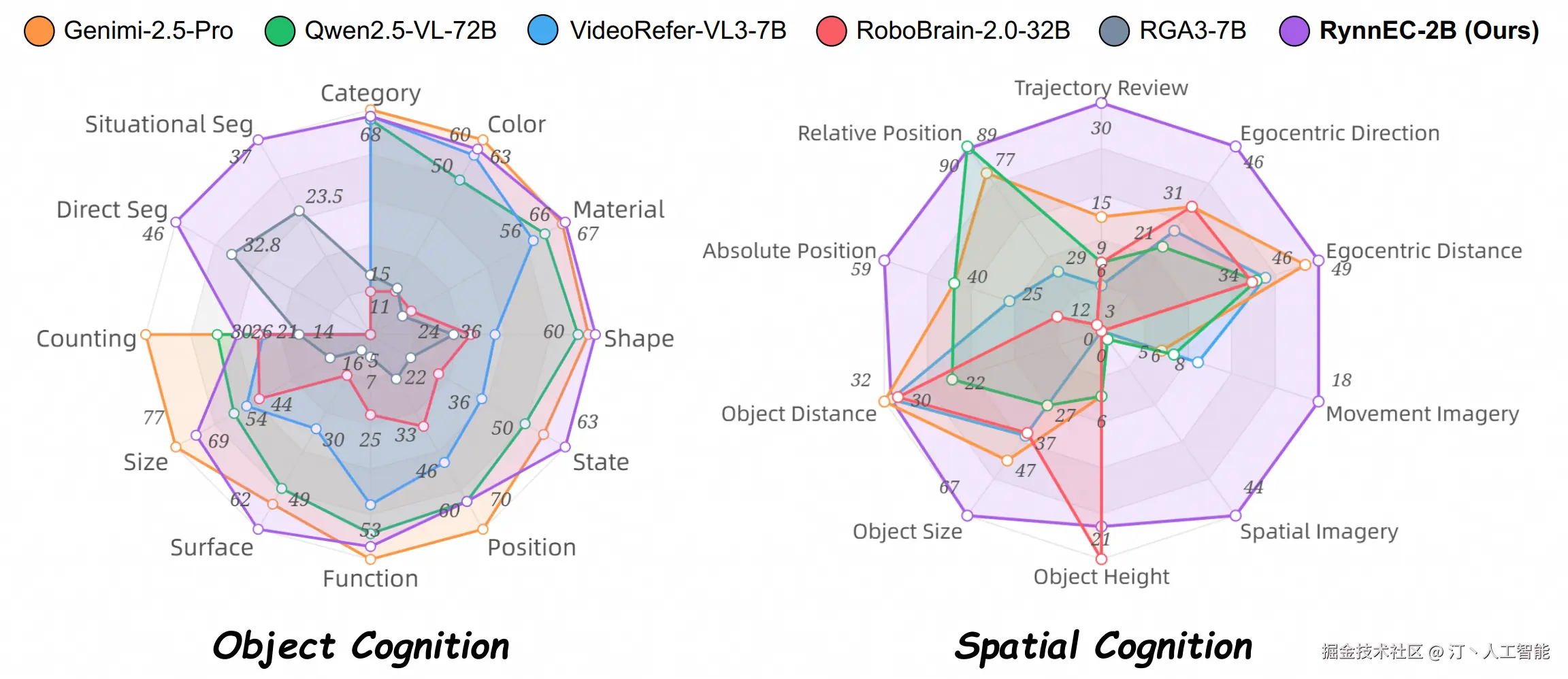
核心功能
RynnEC的核心功能在于能够从多达11个维度全面解析场景中的物体,这些维度包括但不限于物体的位置、功能和数量。模型支持对物体的精确理解以及对空间关系的深入感知。
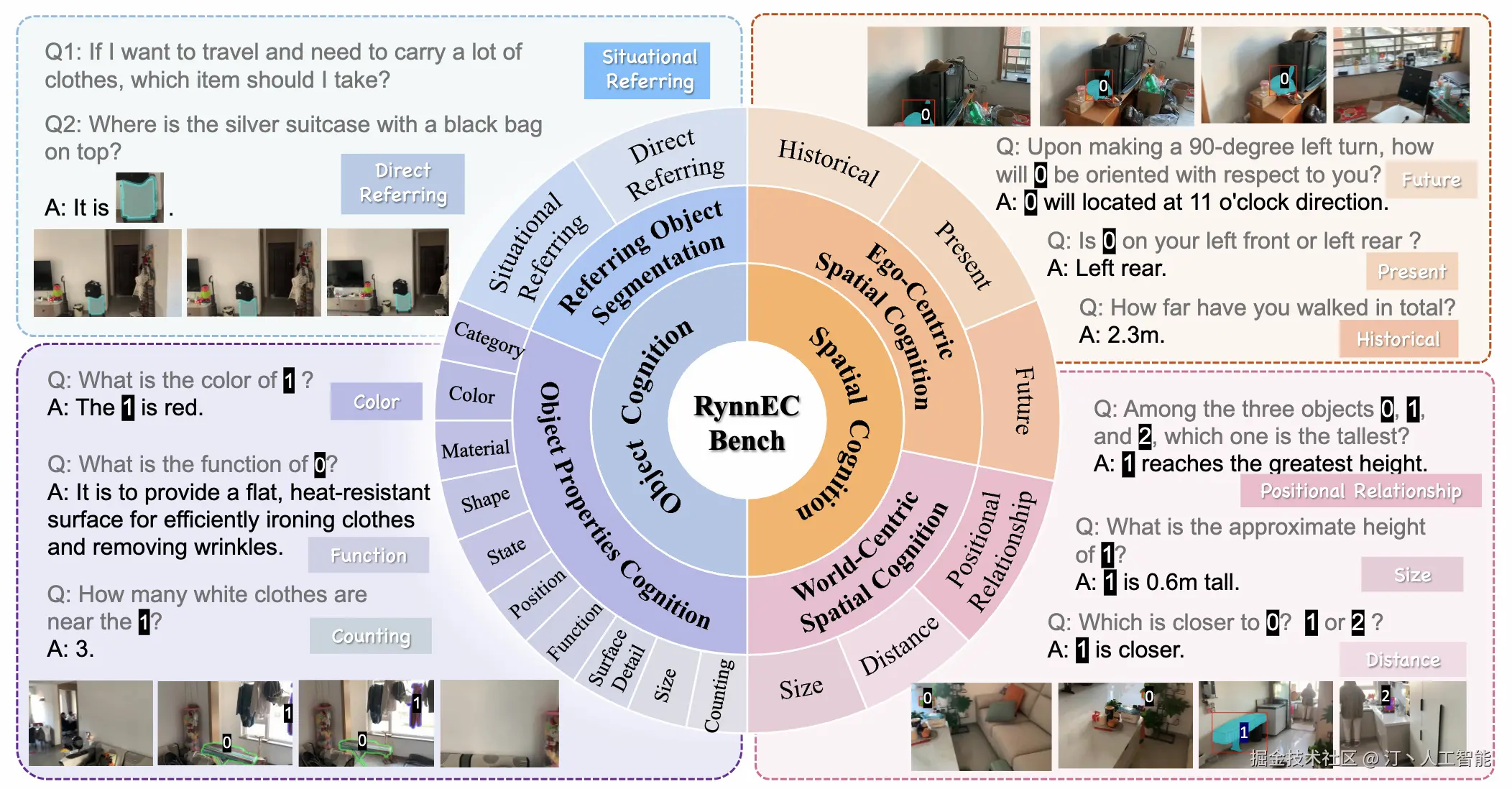
技术原理
RynnEC基于多模态大语言模型(MLLM)架构,其技术原理涉及融合视觉与语言信息,以构建对真实世界的丰富表征。通过对场景中物体在位置、功能、数量等多个维度进行精细化分析,RynnEC能够实现高维度的场景理解和物体属性识别,从而支持复杂的具身智能决策和交互。
应用场景
RynnEC主要应用于需要具身认知能力的领域,包括但不限于:
-
智能机器人与自动化: 帮助机器人在复杂环境中理解并操作物体,执行抓取、导航等任务。
-
虚拟现实(VR)/增强现实(AR): 提升虚拟/增强环境中对现实物体的识别和交互能力,提供更真实的沉浸式体验。
-
智能家居: 赋能智能设备更准确地感知和响应用户指令及环境变化。
-
自动驾驶: 辅助车辆更好地理解道路环境、交通参与者和障碍物,提升决策安全性。
-
GitHub仓库:github.com/alibaba-dam...
RynnRCP -- 阿里达摩院机器人上下文协议
RynnRCP(Robotics Context Protocol)是阿里巴巴达摩院开源的一套机器人上下文协议及框架,旨在打通具身智能(Embodied Intelligence)的开发全流程,提供标准化的机器人服务协议和开发框架。
核心功能
- 标准化协议与框架: 提供一套完整的机器人服务协议和开发框架,促进具身智能开发流程的标准化。
- 模块化组件: 主要由RCP框架和RobotMotion两大核心模块组成,分别负责协议定义与机器人运动控制。
- 全流程打通: 旨在整合具身智能从感知、认知到行动的开发链路,提升开发效率和兼容性。
技术原理
RynnRCP的核心技术原理基于机器人上下文协议(Robotics Context Protocol),该协议定义了机器人系统间进行任务、数据和状态交互的标准化接口和规范。其内部包含:
- RCP 框架: 负责定义具身智能任务的描述、分解、执行状态以及环境上下文信息的传递机制,确保不同模块和设备间的协同工作。
- RobotMotion 模块: 专注于机器人的运动控制,可能涉及高级运动规划、力控、轨迹生成以及与机器人硬件接口的集成,实现精确且鲁棒的物理世界操作。
- 具身智能理论: 结合AI与机器人技术,使机器人能够像人类一样感知环境、理解意图、作出决策并在物理世界中执行任务,强调实体与环境的交互。
应用场景
-
通用具身智能机器人开发: 适用于各类服务机器人、工业机器人、物流机器人等具身智能设备的快速开发与部署。
-
机器人系统集成: 作为统一的通信和控制协议,便于集成不同厂商的机器人硬件、传感器和执行器。
-
智能工厂与自动化: 在工业自动化领域,用于实现机器人协同作业、产线柔性制造和智能巡检。
-
智慧生活与服务: 在家庭、医疗、零售等服务场景中,支撑服务机器人的智能交互和任务执行。
-
GitHub仓库:github.com/alibaba-dam...
Skywork UniPic 2.0 -- 昆仑万维开源的统一多模态模型
简介
Skywork UniPic 2.0 是昆仑万维开源的高效多模态模型,致力于实现统一的图像生成、编辑和理解能力。该模型旨在通过统一的架构处理视觉信息,提升多模态任务的效率和性能。
核心功能
- 图像生成: 能够根据文本描述或其他输入生成高质量图像。
- 图像编辑: 提供对图像内容的编辑和修改能力。
- 图像理解: 具备对图像进行语义理解和分析的能力。
- 统一多模态处理: 将图像生成、编辑和理解等功能集成在一个模型框架内,实现多任务处理。
技术原理
Skywork UniPic 2.0 基于2B参数的SD3.5-Medium架构(部分资料提及UniPic为1.5B参数的自回归模型,但2.0版本主要强调SD3.5-Medium架构)。其核心技术原理包括:
- 自回归模型(Autoregressive Model): 通过预测序列中的下一个元素来逐步生成内容,尤其在图像生成和理解中表现出强大能力。
- 多模态预训练: 模型通过大规模多模态数据进行预训练,学习图像与文本之间的深层关联。
- 渐进式双向特征融合: 采用先进的特征融合技术,有效整合不同模态的信息,增强模型的跨模态理解与生成能力。
- 统一表示学习: 旨在学习一种统一的视觉和文本表示,使得模型能够在一个共享的潜在空间中进行多模态任务处理。
应用场景
-
内容创作: 辅助设计师、艺术家和营销人员快速生成创意图像、广告素材等。
-
图像处理与分析: 在图像编辑软件中集成,实现智能图像修复、风格迁移或内容修改;在安防、医疗等领域进行图像识别和分析。
-
多模态交互系统: 作为智能助手或聊天机器人的一部分,支持用户通过自然语言进行图像查询、生成和编辑。
-
教育与研究: 为多模态AI领域的研究人员提供开源模型和工具,推动技术发展和创新应用。
-
项目官网:unipic-v2.github.io/
-
GitHub仓库:github.com/SkyworkAI/U...
-
HuggingFace模型库:huggingface.co/collections...
Matrix-3D -- 昆仑万维开源的3D世界模型
Matrix-3D是由昆仑万维Skywork AI团队开发的一个先进框架,旨在通过单张图像或文本提示生成可探索的大规模全景3D世界。它结合了全景视频生成与3D重建技术,旨在实现高保真、全向可探索的沉浸式3D场景。
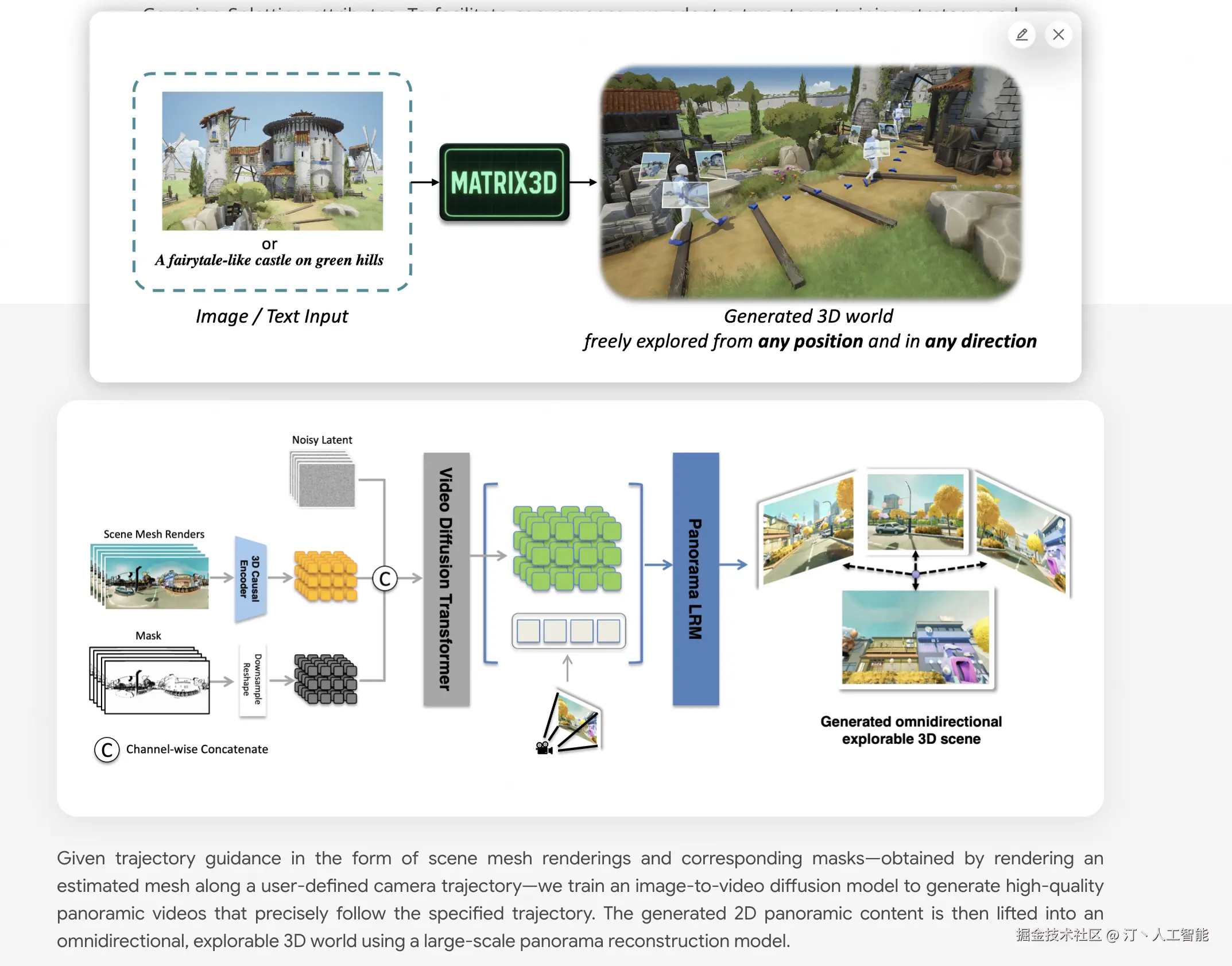
核心功能
- 全景3D世界生成: 能够从单一图像或文本提示生成广阔且可探索的全景3D场景。
- 图像/文本到3D场景转换: 支持将输入的图像或文本描述直接转化为对应的3D世界内容。
- 条件视频生成: 具备基于特定条件生成全景视频的能力。
- 全景3D重建: 实现对全景图像或视频内容的3D重建。
- 强大的泛化能力: 基于自研的3D数据和视频模型先验,能够生成多样化且高质量的3D场景。
技术原理
Matrix-3D的核心技术原理在于其对**全景表示(panoramic representation)**的利用,以实现广覆盖、全向可探索的3D世界生成。它融合了以下关键技术:
- 条件视频生成(conditional video generation): 通过深度学习模型,根据输入条件(如图像或文本)生成符合要求的全景视频序列。
- 全景3D重建(panoramic 3D reconstruction): 运用计算机视觉和图形学技术,从全景图像或视频中恢复场景的几何信息和结构。
- 3D数据和视频模型先验(3D data and video model priors): 模型在大量自研的3D数据和视频数据上进行训练,学习到丰富的场景结构和动态规律,从而增强了生成结果的真实感和多样性。
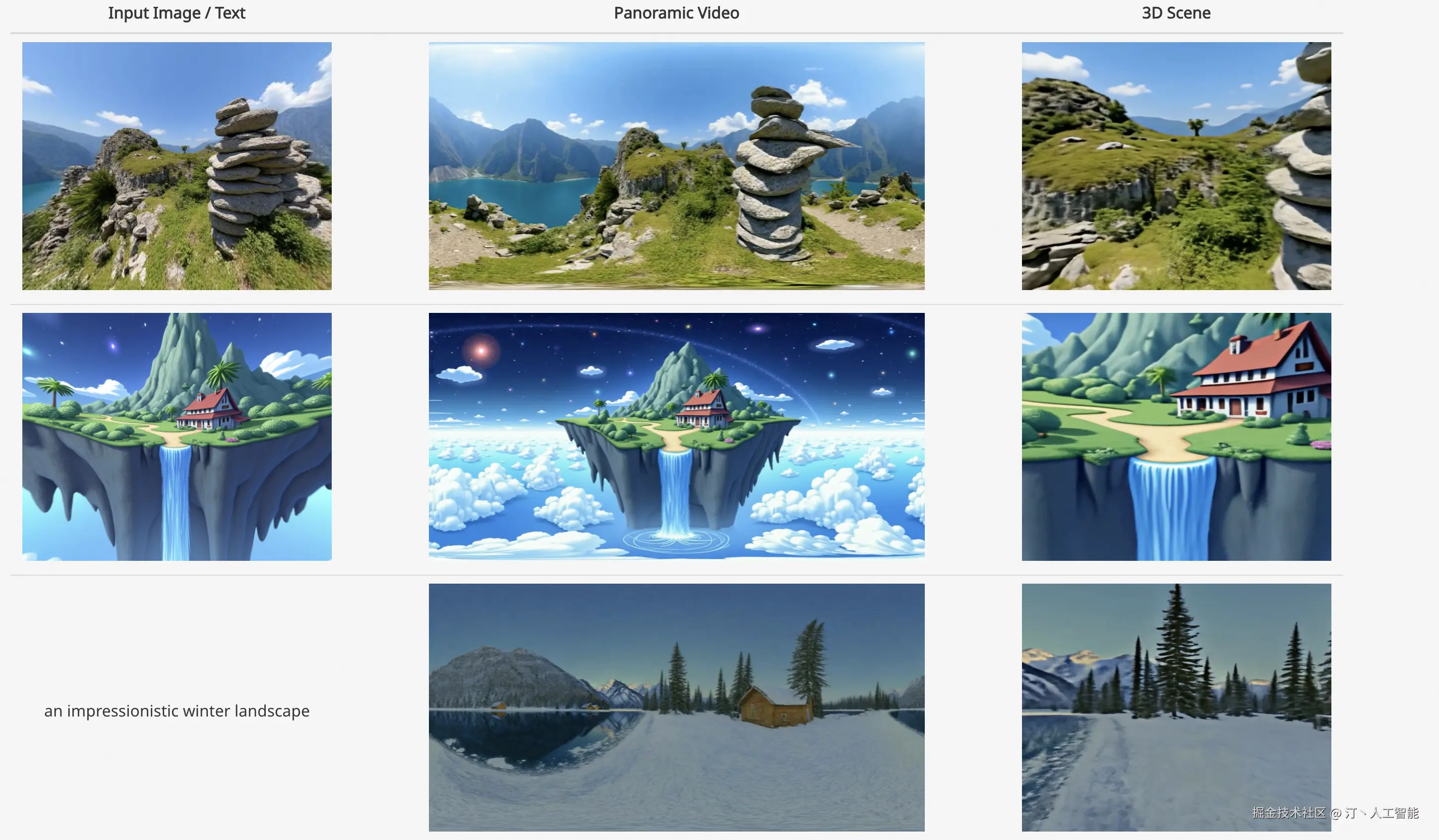
应用场景
- 虚拟现实(VR)/增强现实(AR)内容创作: 快速生成沉浸式的VR/AR环境,用于游戏、教育、旅游等领域。
- 元宇宙(Metaverse)构建: 为元宇宙平台提供大规模、可探索的3D场景内容生成能力。
- 影视动画制作: 辅助制作人员快速生成复杂的3D场景背景或预览。
- 虚拟漫游与规划: 在房地产、城市规划、室内设计等领域,用于生成虚拟漫游体验。
- 数字孪生(Digital Twin): 构建现实世界的虚拟副本,进行模拟和分析。
- 游戏开发: 提升游戏场景的生成效率和多样性,实现更加生动逼真的游戏世界。
Matrix-3D的项目地址
- 项目官网:matrix-3d.github.io/
- GitHub仓库:github.com/SkyworkAI/M...
- HuggingFace模型库:huggingface.co/Skywork/Mat...
- 技术论文:github.com/SkyworkAI/M...
Matrix-Game 2.0 -- 昆仑万维推出的自研世界模型
Matrix-Game 2.0是由昆仑万维SkyWork AI发布的一款自研世界模型,被誉为业内首个开源的通用场景实时长序列交互式生成模型。它旨在推动交互式世界模型领域的发展,能够实现可控的游戏世界生成,并支持高质量、实时、长序列的视频生成。
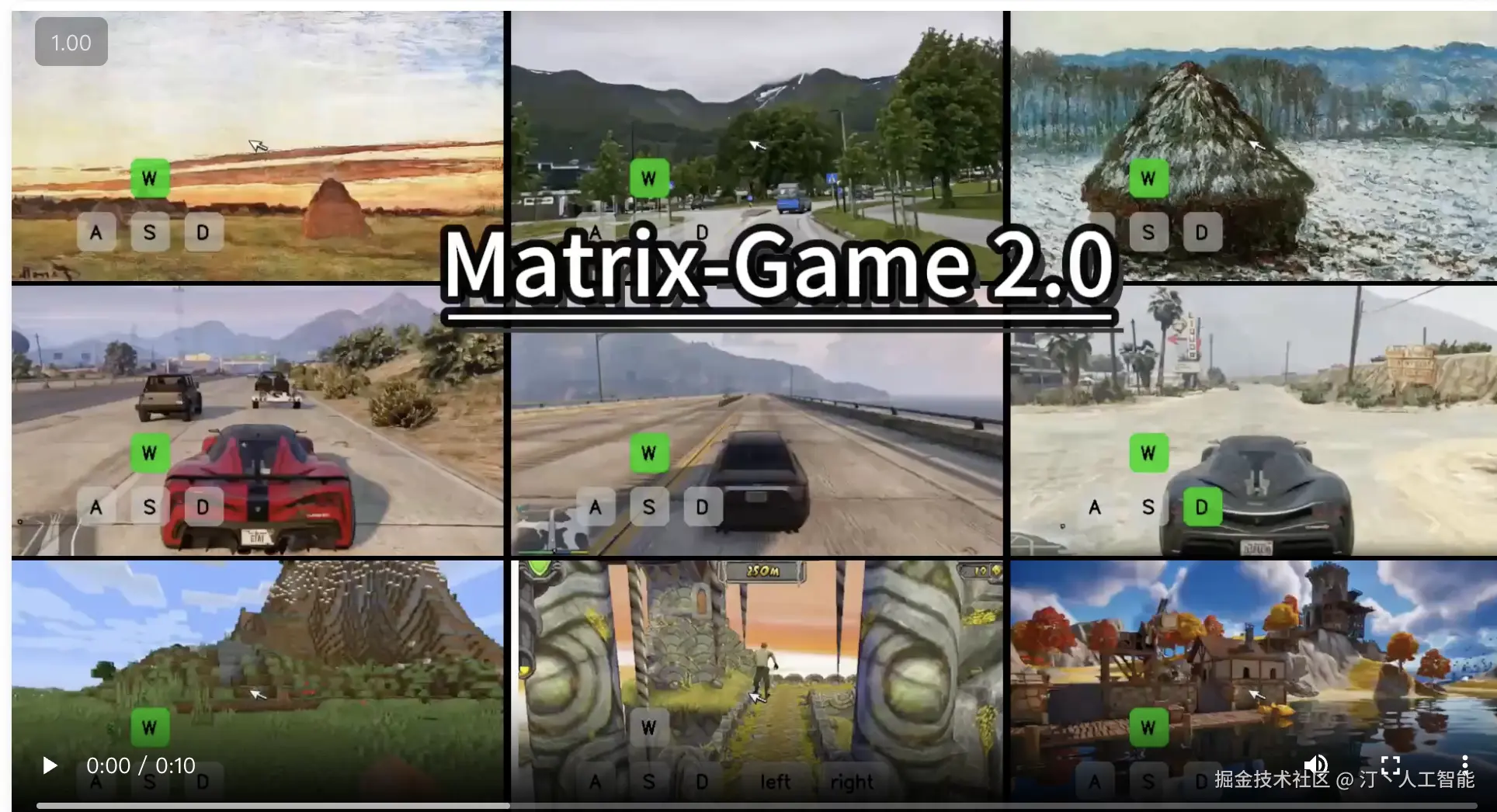
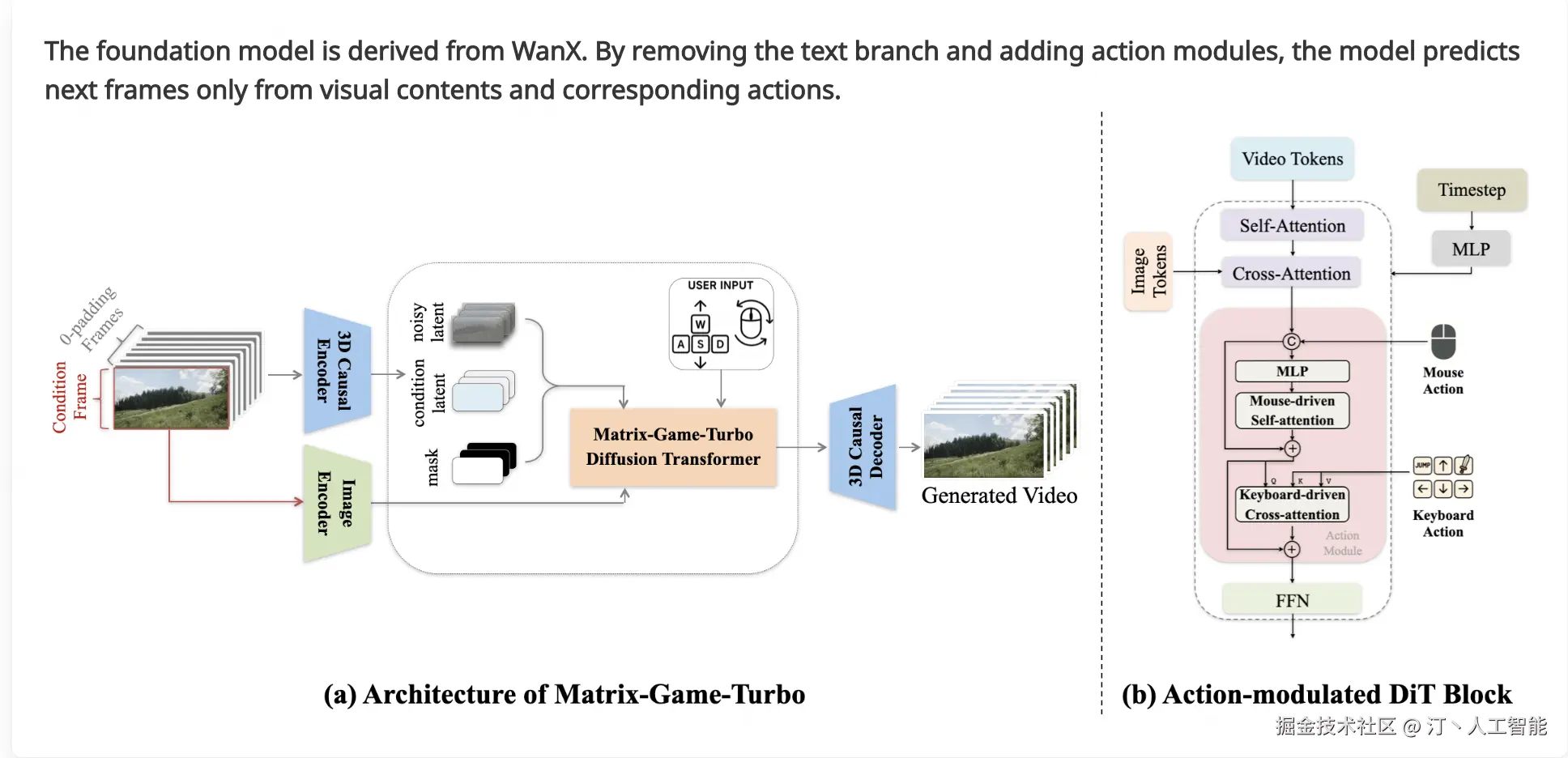
核心功能
- 交互式世界生成: 能够根据指令生成和操控游戏世界,实现高度交互性。
- 实时长序列视频生成: 以25 FPS的超高速率生成分钟级的高质量视频,支持多样的场景。
- 基础世界模型: 作为交互式世界的基础模型,参数量达到17B,可用于构建复杂的虚拟环境。
- 全面开源: 提供模型权重和相关资源,促进社区共同发展和应用。
技术原理
- 生成对抗网络 (GAN) 或扩散模型 (Diffusion Models): 用于高质量的图像和视频内容生成。
- 序列建模: 采用Transformer等架构处理长序列的交互和状态变化,以实现实时且连贯的世界演进。
- 强化学习 (Reinforcement Learning) 或模仿学习 (Imitation Learning): 用于训练模型理解用户意图并生成可控的交互行为。
- 多模态融合: 结合视觉、文本、动作等多种模态信息,以构建更丰富的世界表征。
- 高效推理优化: 实现25 FPS的实时生成速度,可能采用了量化、剪枝或并行计算等优化技术。
应用场景
-
具身AI训练: 为具身智能体提供逼真且可控的训练环境。
-
虚拟现实/元宇宙构建: 快速生成和定制虚拟世界内容,提升用户体验。
-
游戏开发: 自动化游戏场景、角色行为和故事情节的生成,大幅提高开发效率。
-
数字孪生: 创建真实世界的虚拟复刻,用于模拟、预测和优化。
-
内容创作: 辅助艺术家和设计师进行概念设计、动画制作和电影预可视化。
-
GitHub仓库:github.com/SkyworkAI/M...
-
HuggingFace模型库:huggingface.co/Skywork/Mat...
GLM-4.5V -- 智谱开源的最新一代视觉推理模型
GLM-4.5V是由智谱AI开发并开源的领先视觉语言模型(VLM),它基于智谱AI新一代旗舰文本基座模型GLM-4.5-Air(总参数1060亿,活跃参数120亿)。该模型继承并发展了GLM-4.1V-Thinking的技术路线,旨在提升多模态感知之上的高级推理能力,以解决复杂AI任务,并支持长上下文理解和多模态智能体应用。
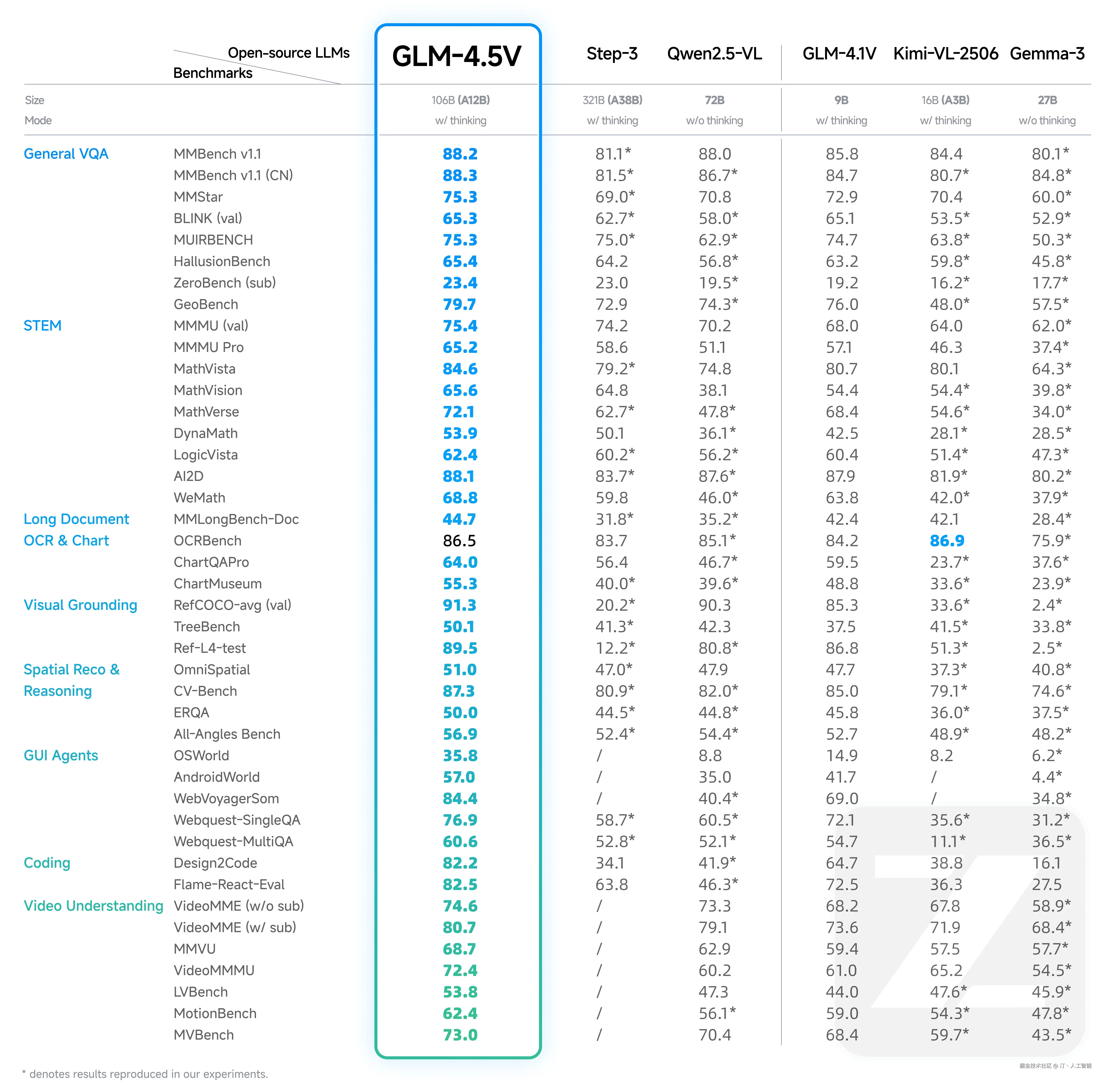
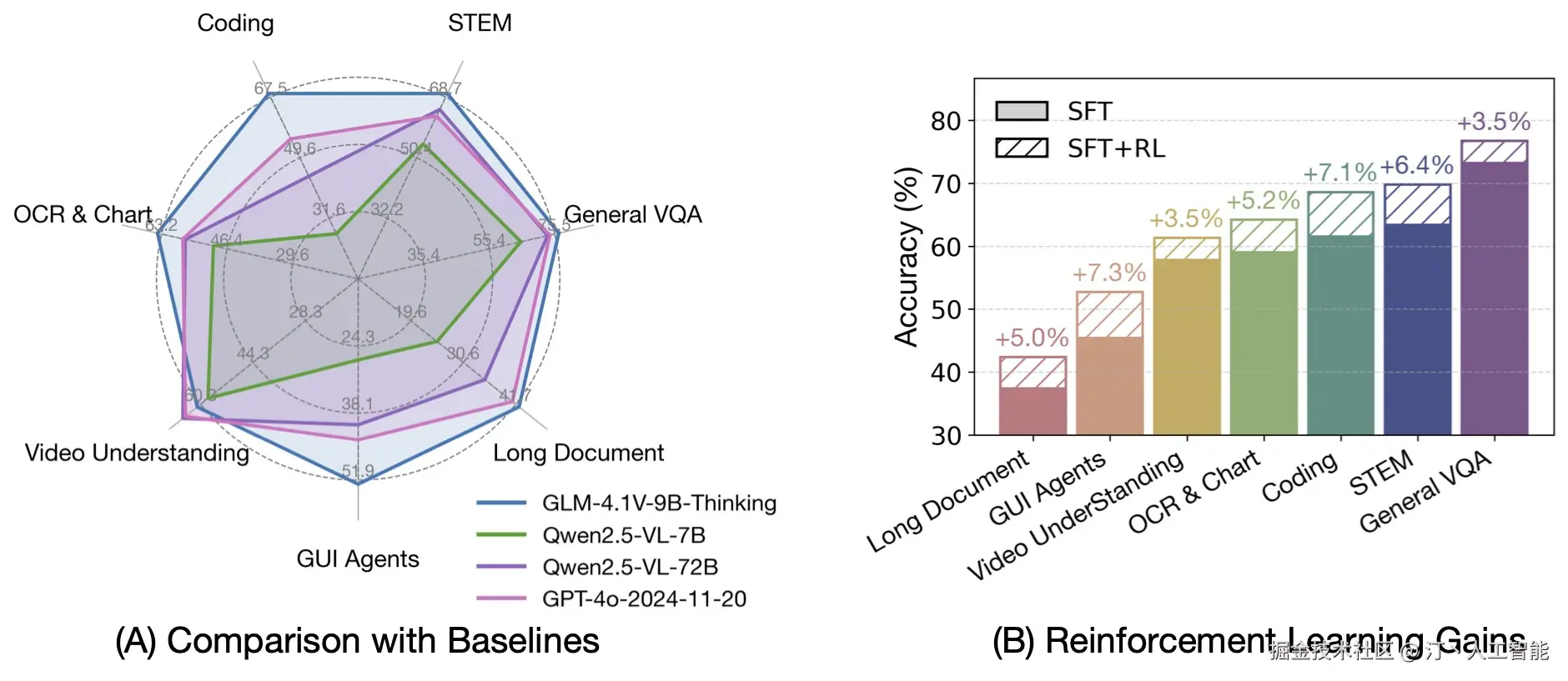
核心功能
- 多模态理解与感知: 能够处理和理解图像、视频、文档等多源异构数据。
- 高级推理能力: 具备强大的长上下文理解、科学问题解决(STEM Reasoning)和代理(Agentic)能力。
- 代码与GUI操作: 支持代码理解、生成以及图形用户界面(GUI)的自动化操作。
- 工具调用: 支持函数调用、知识库检索和网络搜索等工具集成。
- 混合推理模式: 提供"思考模式"用于复杂推理和工具使用,以及"非思考模式"用于即时响应。
技术原理
GLM-4.5V的技术核心在于其 "思考模式"(Thinking Mode) 和 多模态强化学习(Multimodal Reinforcement Learning, RL) 。它基于大规模Transformer架构,以GLM-4.5-Air作为其文本基础模型。通过采用GLM-4.1V-Thinking的先进方法,模型在多模态数据上进行了大规模训练,并结合可扩展的强化学习策略,显著增强了其复杂问题解决、长上下文处理和多模态代理能力。模型响应中的边界框(Bounding Box)坐标通过特殊标记<|begin_of_box|>和<|end_of_box|>表示,坐标值通常在0到1000之间归一化,用于视觉定位。
应用场景
-
智能助理与Agent: 构建能够执行复杂多模态任务的智能代理,如内容创作、信息检索、自动化流程。
-
教育与研究: 辅助科学、技术、工程、数学(STEM)领域的复杂问题求解。
-
文档处理与分析: 进行长文档理解、内容识别与提取。
-
自动化测试与操作: 实现基于GUI的应用程序自动化操作,如UI测试、任务执行。
-
多媒体内容分析: 应用于图像和视频内容理解、分析与生成。
-
编码辅助: 作为代码助手,进行代码理解和生成。
-
GitHub仓库:github.com/zai-org/GLM...
-
HuggingFace模型库:huggingface.co/collections...
DreamVVT -- 字节联合清华推出的视频虚拟试穿技术
DreamVVT是由字节跳动与清华大学(深圳)联合推出的一项视频虚拟试穿(Video Virtual Try-On, VVT)技术。该项目旨在通过先进的AI模型实现高保真、逼真的视频虚拟服装试穿效果,尤其强调在"野外"场景下(即非受控环境)的真实感和鲁棒性。 
核心功能
DreamVVT的核心功能是实现用户在视频中进行虚拟服装试穿。具体包括:
- 高保真试穿效果:生成逼真、细节丰富的虚拟试穿视频。
- 视频流适配:支持在视频内容中进行动态、连续的服装替换和试穿。
- "野外"场景适用性:能够在复杂、非受控的真实视频环境中稳定运行,克服光照、姿态变化等挑战。
- 服装风格转移:将目标服装的样式和纹理精确地应用到视频中的人物身上。
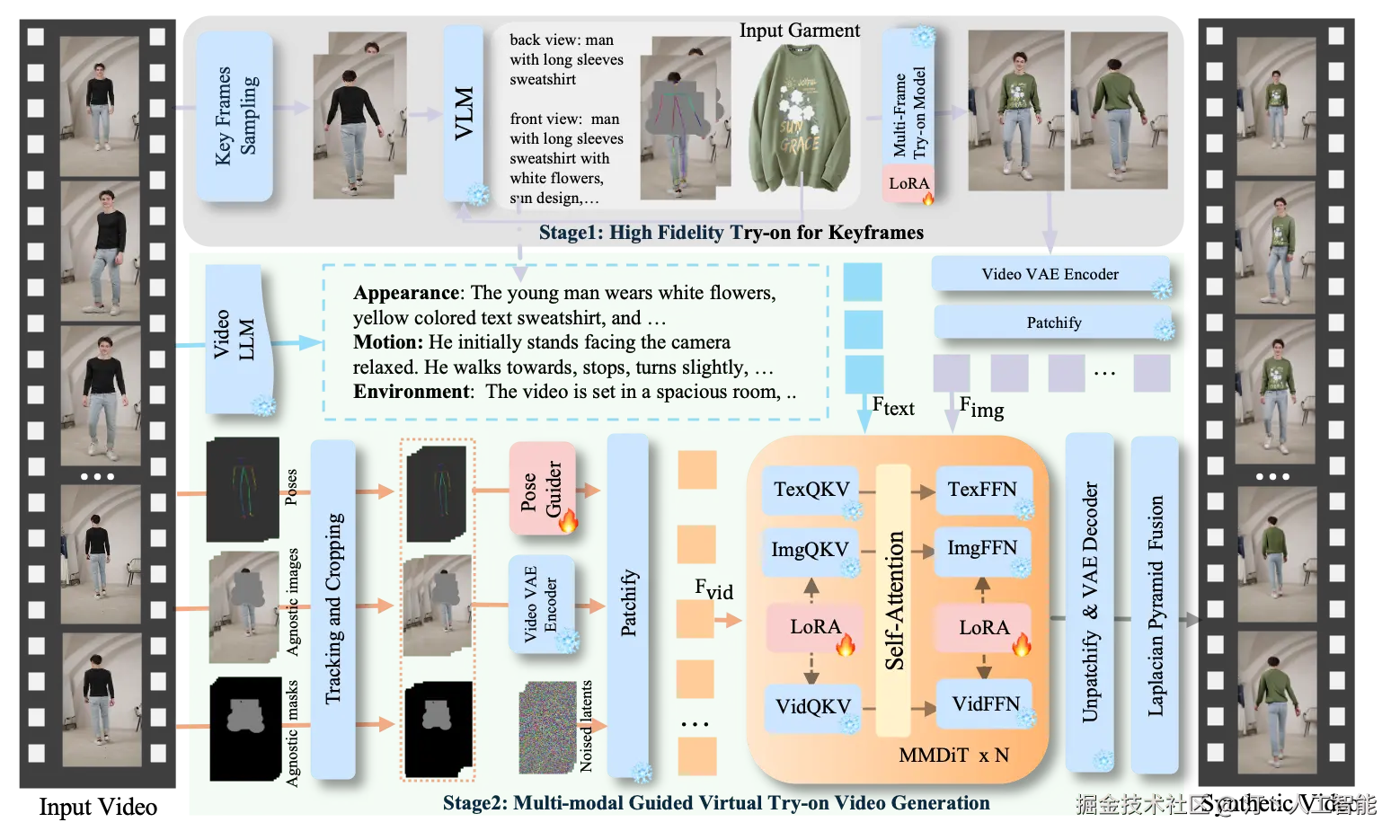
技术原理
DreamVVT技术基于扩散Transformer(DiTs)框架,并采用两阶段(或称为分阶段)方法实现。其主要技术原理包括:
- 扩散Transformer (DiTs):利用Transformer架构的强大建模能力处理扩散过程,以生成高质量的图像和视频内容。扩散模型在生成逼真图像方面表现出色,能够逐步去噪生成目标图像。
- 两阶段框架:通过分解任务为不同阶段来提高生成质量和稳定性。这可能包括初步的姿态对齐/服装变形阶段和随后的高保真渲染阶段。
- LoRA (Low-Rank Adaptation) 适配器:结合LoRA技术,以高效地微调预训练模型,使其适应视频虚拟试穿的特定任务,同时减少计算资源消耗和模型大小。
- 利用无配对数据:该框架能够有效利用无配对的人像和服装数据进行训练,这大大降低了数据采集的难度和成本,使其在实际应用中更具灵活性。
应用场景
DreamVVT技术在多个领域具有广阔的应用前景,主要包括:
- 在线零售与电商:消费者可以在购买前通过视频观看服装在自己身上的虚拟试穿效果,提升购物体验和决策效率,减少退货率。
- 时尚产业:用于服装设计、展示和营销,设计师可以快速预览设计效果,品牌可以制作更具吸引力的虚拟宣传视频。
- 影视制作与内容创作:在电影、电视节目、广告或短视频中快速、高效地更换演员的服装,节省后期制作成本。
- 虚拟形象与元宇宙:为虚拟形象和元宇宙中的用户提供个性化的虚拟服装试穿服务,增强沉浸感和互动性。
DreamVVT的项目地址
- 项目官网:virtu-lab.github.io/
- Github仓库:github.com/Virtu-Lab/D...
- arXiv技术论文:arxiv.org/pdf/2508.02...
AionUi -- 将命令行体验转换为现代、高效的 AI 聊天界面
AionUi 是一个免费、本地、开源的图形用户界面(GUI)应用程序,旨在将强大的AI能力变得人人可及,通过友好的用户界面简化与AI代理的交互。它目前主要为Gemini命令行界面(CLI)提供增强的用户体验,并计划发展成为一个通用的AI代理平台,弥合AI复杂功能与日常易用性之间的鸿沟。
核心功能
- 增强型AI聊天体验: 提供直观的GUI界面,优化与AI的交互过程。
- 多任务处理能力: 集成文件管理、代码差异查看等功能,提升工作效率。
- 开发者工作流优化: 简化开发者与AI工具的交互,如与Gemini CLI的集成。
- 灵活的LLM绑定: 支持与多种大语言模型(LLM)进行绑定和交互。
- API及代理配置: 提供API认证和HTTP代理配置选项,以适应不同的网络环境和认证需求。
技术原理
AionUi 采用Electron和React技术构建其跨平台桌面应用程序,实现了直观的用户界面。其核心原理是通过GUI封装并简化对Gemini命令行界面(CLI)的操作,将复杂的命令转化为图形化交互。它支持多代理生态系统和灵活的LLM绑定机制,允许集成和切换不同的大语言模型。项目采用模块化设计,结构清晰,易于维护和扩展。
应用场景
-
AI辅助开发: 开发者可利用其增强的聊天、代码管理和多任务功能,更高效地进行编程、调试和项目管理。
-
日常AI交互: 降低非技术用户使用复杂AI代理的门槛,使AI功能像聊天一样易于访问和使用。
-
本地AI部署与管理: 为需要本地运行或管理AI模型和代理的用户提供便捷的图形化解决方案。
-
企业内部AI工具: 可作为企业内部集成AI代理、提升团队工作效率的定制化工具。
-
AI学习与普及: 通过友好的界面,帮助更多人轻松探索和学习AI技术及应用。
-
GitHub仓库:github.com/office-sec/...
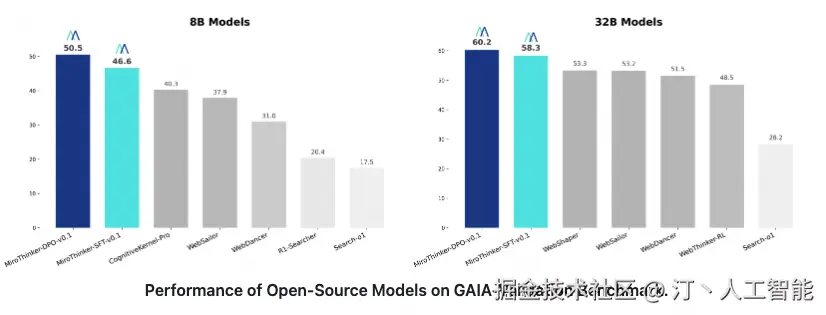
MiroThinker 针对深度研究和复杂工具使用场景进行开源Agent模型
MiroThinker 是一个开源的智能体模型系列,由 MiroMind AI 推出,专为深度研究、复杂问题解决和长期规划设计。该模型致力于通过其先进的智能体能力,弥合人类智能与人工智能之间的鸿沟,旨在推动通用人工智能(AGI)的发展。MiroThinker 在大规模、高质量轨迹和偏好数据集上进行训练,具有高性能表现。
核心功能
- 深度研究与复杂问题解决: 能够处理需要深入分析和多步骤推理的复杂任务。
- 多跳推理能力: 支持链式思维和逐步推理,以解决需要多阶段思考的问题。
- 任务分解: 将复杂任务拆解成可管理的子任务。
- 检索增强生成(RAG): 结合外部知识检索,提高生成内容的准确性和相关性。
- 代码执行: 具备执行代码的能力,支持与外部工具和环境的交互。
- 工具使用与调用: 高效利用各种工具来完成特定任务。
- 自我意识与长期记忆(MiroMind愿景): 作为MiroMind的核心研究方向,旨在通过长期记忆实现AI的自我意识觉醒。
技术原理
MiroThinker 模型系列基于 Qwen3 (通义千问3) 等先进的基础模型进行构建。其核心技术原理包括:
- 大型语言模型(LLM)驱动的智能体架构: 利用强大的LLM作为核心,实现复杂的认知和决策过程。
- 轨迹与偏好数据训练: 模型在 MiroVerse-v0.1 等大规模、高质量的轨迹和偏好数据集上进行训练,通过监督微调(SFT)和直接偏好优化(DPO)等技术,提升模型的决策能力和行为表现。
- 强化学习与反馈机制: 通过从复杂任务执行中获取反馈,不断优化智能体的策略和表现。
- 多智能体系统框架(如MiroFlow): MiroFlow作为一个多智能体系统开发框架,为MiroThinker等模型生成高质量的智能体轨迹数据,并支持高并发处理,提供强大的协同和管理能力。
应用场景
- 科学研究与发现: 辅助科研人员进行深度文献分析、实验设计、数据解释等。
- 复杂项目管理与规划: 在工程、商业等领域进行长期、多阶段的项目规划和执行。
- 智能决策支持系统: 为企业或个人提供基于复杂数据分析的决策建议。
- 自动化问题解决: 在客服、技术支持、教育等领域实现高度自动化的疑难问题解答。
- Agent开发与研究: 为AI研究者和开发者提供一个高性能、开源的Agent模型基础,用于探索更高级的AI智能体应用。
MiroThinker 的项目地址
- GitHub仓库:github.com/MiroMindAI/...
- HuggingFace模型库:huggingface.co/collections...
- 在线体验Demo:dr.miromind.ai/
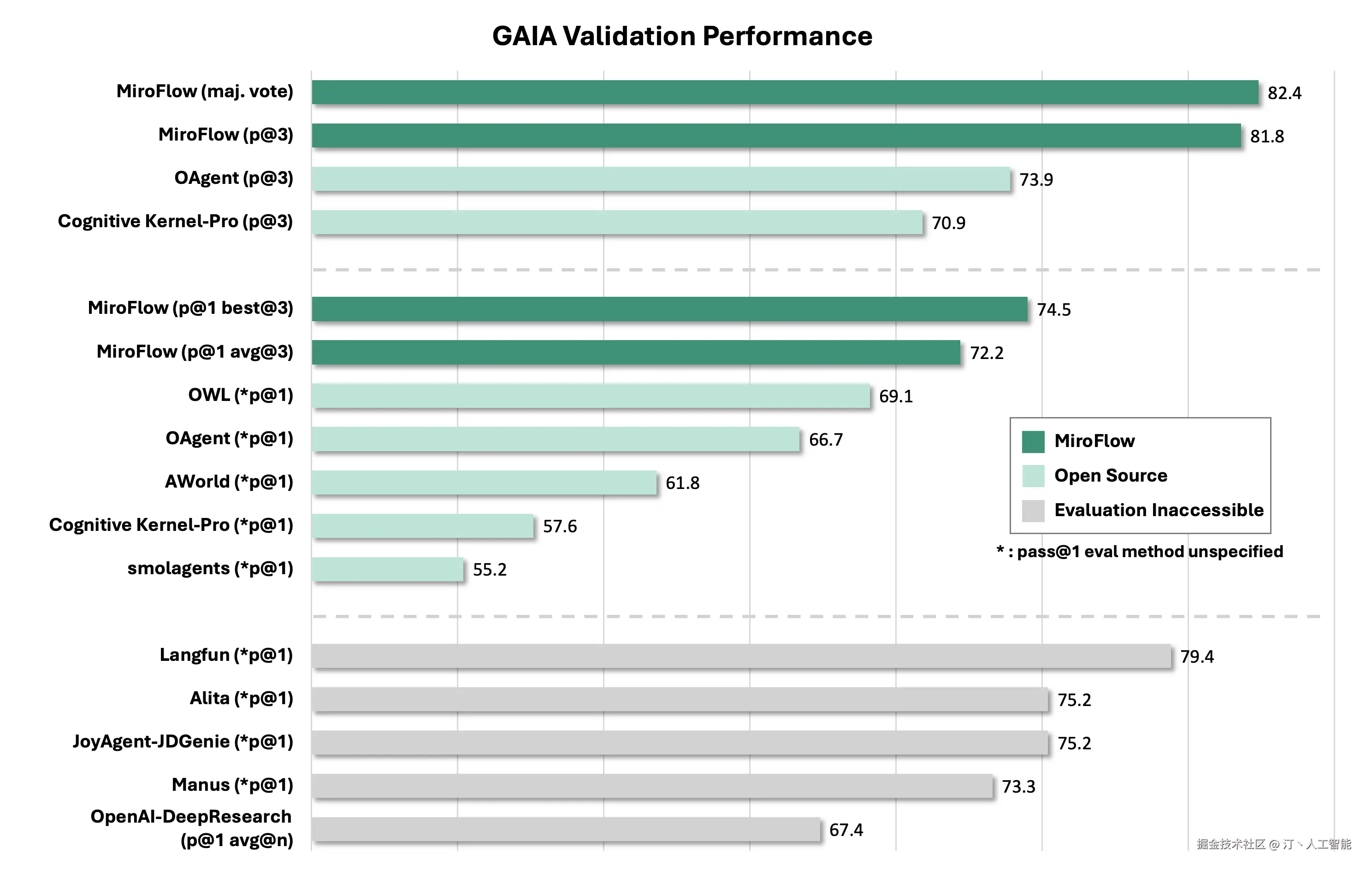
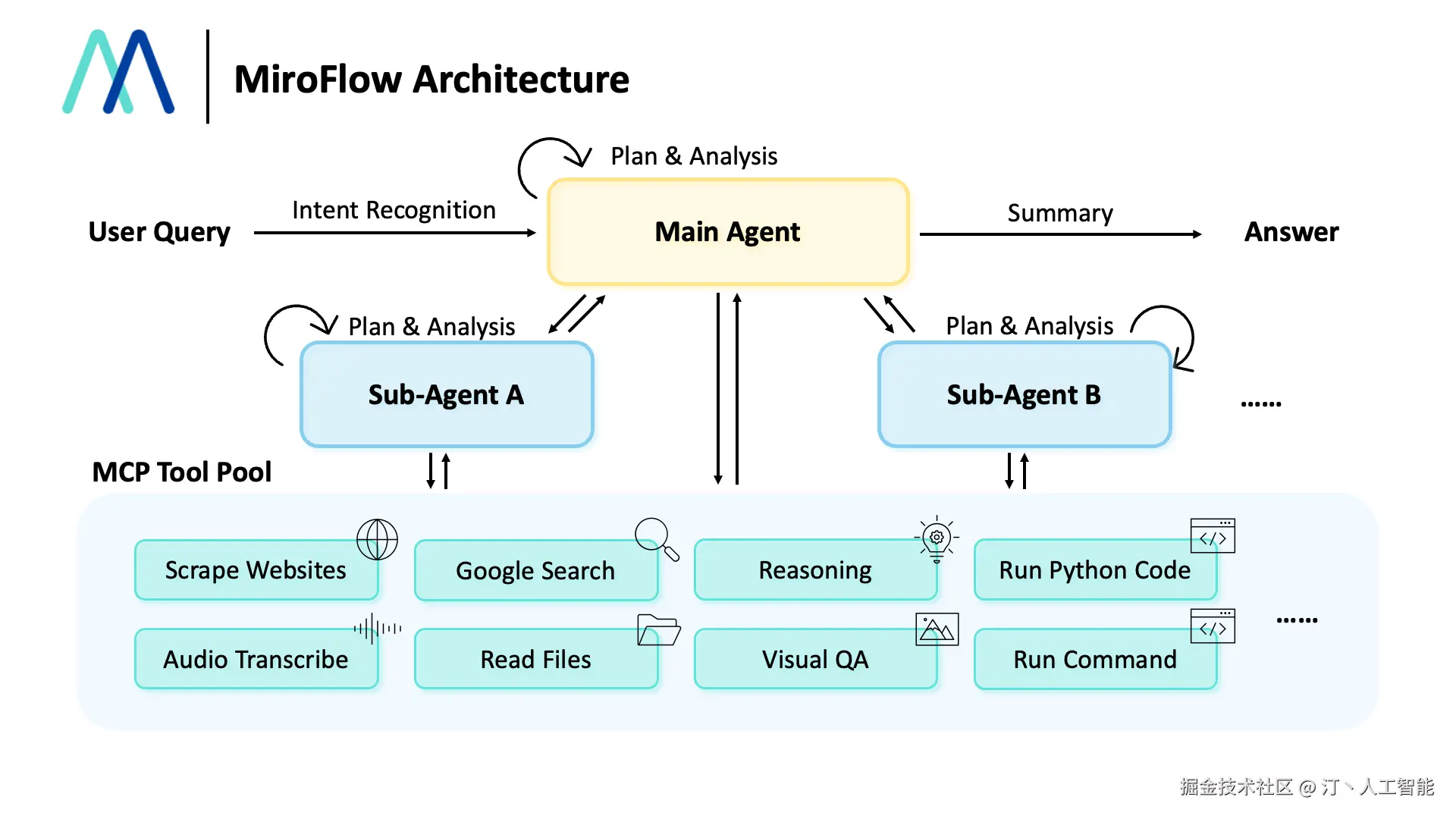
MiroFlow -- 多Agent系统开发框架
MiroFlow是一个强大的多智能体系统开发框架,旨在简化复杂、高性能AI智能体的构建、管理和扩展。它专注于为MiroThinker等模型生成高质量的智能体轨迹数据,并提供对外部工具的无缝集成能力。
核心功能
- 智能体系统开发与管理: 提供构建、管理和扩展复杂多智能体系统的能力。
- 高并发处理: 支持处理高并发任务,确保系统的高效运行。
- 工具集成框架: 提供灵活的框架,支持与外部工具(如搜索引擎、代码执行环境)的无缝集成,以扩展AI模型的功能。
- 数据生成: 能够为AI模型(如MiroThinker)生成高质量的智能体轨迹数据。
技术原理
MiroFlow作为一个多智能体系统开发框架,其核心技术原理在于提供一套结构化的机制来协调和管理多个AI智能体的行为与交互。它通过工具集成框架 实现AI智能体与外部环境的连接与互动,扩展其感知和行动能力。框架设计着重于高并发处理 ,这意味着它内部可能采用异步通信、任务调度或分布式处理等机制,以有效管理大量并行运行的智能体和其交互。同时,通过生成智能体轨迹数据,它可能利用这些数据进行模型训练、行为分析或系统优化,以提升智能体的决策质量和协作效率。
应用场景
-
复杂AI系统构建: 适用于需要多个智能体协同工作以解决复杂问题的场景。
-
大规模智能体部署: 在需要部署和管理大量AI智能体的应用中,如智能客服集群、自动化交易系统。
-
AI模型训练与优化: 为MiroThinker等AI模型提供高质量的智能体交互数据,用于模型训练、微调及性能评估。
-
扩展AI能力: 通过集成外部工具,使AI智能体能够执行更广泛的任务,例如信息检索、代码执行、数据分析等。
-
GitHub仓库:github.com/MiroMindAI/...
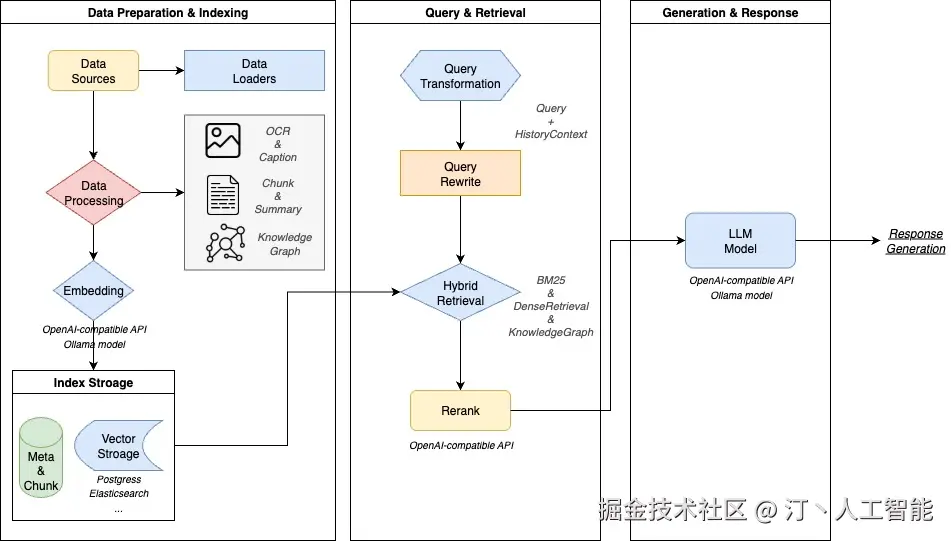
WeKnora -- 腾讯开源的文档理解与语义检索框架
WeKnora是腾讯开源的一款基于大语言模型(LLM)的文档理解与语义检索框架。它专为处理结构复杂、内容异构的文档场景而设计,旨在提供智能问答解决方案,能够快速从文档中提取洞察并提供答案。
核心功能
- 多模态文档解析: 支持对PDF、Word、图片等多种格式文档进行结构化内容提取和解析。
- 文档深度理解: 利用大语言模型对文档内容进行深入理解,捕捉复杂语义。
- 语义检索: 能够进行高效的语义检索,找到与查询最相关的文档片段。
- 智能问答: 基于检索到的信息,提供上下文感知的智能问答。
- 语义视图构建: 统一构建文档的语义视图,便于后续处理和检索。
- 模块化设计: 框架采用模块化架构,方便扩展和集成。
技术原理
WeKnora的核心技术原理是结合了**大语言模型(LLM)和检索增强生成(RAG)**范式。它通过以下步骤实现其功能:
- 多模态预处理与解析: 对不同格式的文档进行预处理,包括文本提取、图像识别(OCR)等,并解析其结构。
- 内容嵌入与向量化: 将解析后的文档内容转换为高维向量表示(嵌入),以便进行语义匹配。
- 知识库构建: 建立基于向量的知识库,存储所有文档的语义信息。
- 检索机制: 当用户提出问题时,利用问题嵌入进行向量相似度搜索,从知识库中检索出最相关的文档片段。
- LLM与RAG: 将检索到的相关文档片段作为上下文信息,结合用户问题一同输入到大语言模型中,通过RAG范式,引导LLM生成准确、相关的答案。
- 模块化架构: 整个框架采用模块化设计,使得各个组件(如解析器、检索器、生成器)可以独立开发、优化和替换,提升了系统的灵活性和可维护性。
应用场景
- 企业知识库管理: 帮助企业高效管理和利用内部大量的非结构化和半结构化文档,实现智能问答和知识检索。
- 智能客服: 应用于客服系统,快速从产品手册、FAQ等文档中获取信息,为用户提供即时准确的回复。
- 法律/金融文档分析: 辅助分析复杂的法律条文、合同、财报等,快速定位关键信息并进行摘要或问答。
- 学术研究: 帮助研究人员快速查阅和理解大量的学术论文和研究报告。
- 教育领域: 用于构建智能学习系统,学生可以通过提问快速获取教材中的知识点。
- 多源异构信息处理: 适用于需要从不同来源、不同格式文档中整合信息并进行智能处理的场景。
WeKnora的项目地址
- 项目官网:weknora.weixin.qq.com/
- GitHub仓库:github.com/Tencent/WeK...
LandPPT -- 开源AI PPT生成工具
LandPPT是一个开源的AI演示文稿生成平台,旨在通过人工智能技术,将文档内容快速、高效地转换为专业且高质量的PPT演示文稿,极大地简化了传统PPT制作流程。
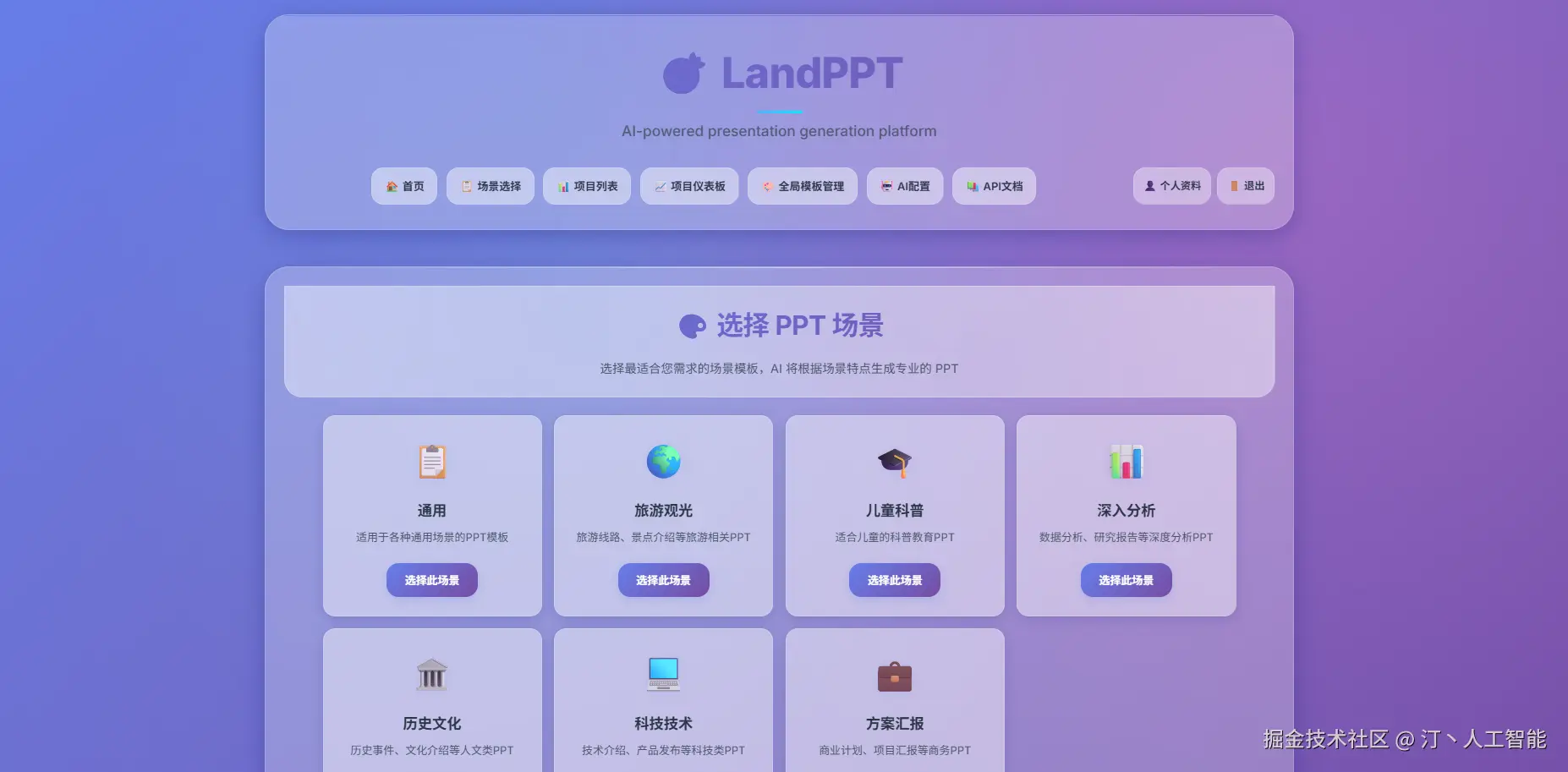
核心功能
- 文档内容快速转换: 能够自动将用户提供的文档内容转化为演示文稿。
- 多AI模型支持: 集成并支持OpenAI、Claude、Gemini等多种主流AI模型,提供更灵活的生成能力。
- 模板与样式选择: 提供丰富的模板和样式选项,帮助用户创建符合需求的演示文稿。
- 智能化图像处理: 具备智能图像处理能力,优化演示文稿的视觉效果。
技术原理
LandPPT的核心技术基于大语言模型(LLM) 。它利用LLM的强大文本理解和生成能力,解析输入的文档内容,并将其结构化、提炼成演示文稿的关键信息。通过集成不同的AI模型(如OpenAI、Claude、Gemini),平台能够根据内容生成相应的演示文稿结构、文本内容、甚至推荐图片和排版,实现自动化和智能化的PPT制作。此外,可能还结合了自然语言处理(NLP)、**计算机视觉(CV)**技术进行文档解析和图像优化。
应用场景
-
商务演示: 快速制作产品介绍、市场分析、项目报告等商务PPT。
-
学术交流: 将研究论文、学术报告等内容快速转换为演示文稿,用于会议或讲座。
-
教育培训: 教师或培训师可利用其将教学大纲、课程内容等转换为PPT课件。
-
个人汇报: 适用于个人工作总结、技能展示等快速生成演示文稿。
-
内容创作: 帮助内容创作者将文章、博客等转换为视觉化的演示材料。
-
GitHub仓库:github.com/sligter/Lan...
GitMCP
GitMCP 是一个免费、开源的远程模型上下文协议(MCP)服务器,旨在将任何 GitHub 项目(包括仓库和 GitHub Pages)转换为文档中心,并为 AI 工具提供即时、准确的项目上下文。它通过消除 AI 模型的"代码幻觉"问题,使得 AI 能够访问最新的文档和代码,即使这些信息未包含在其训练数据中。通过简单地将 GitHub 仓库 URL 中的 github.com 替换为 gitmcp.io,即可为该仓库生成一个可供 AI 助手使用的 MCP 服务器。
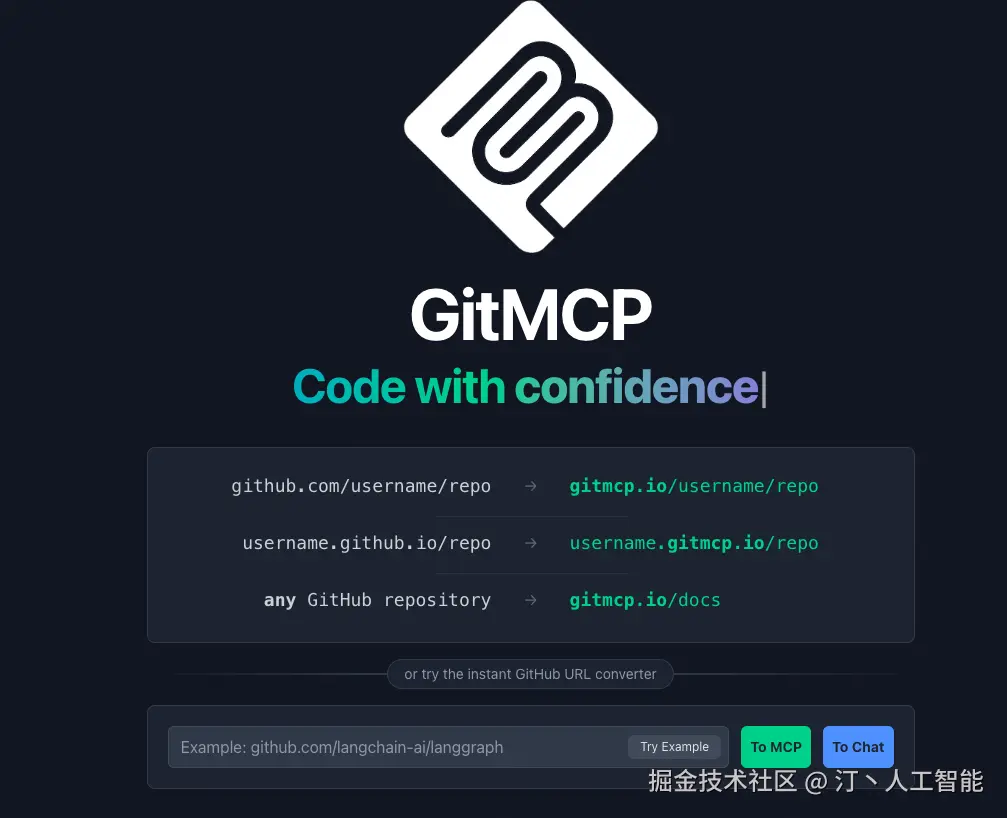
核心功能
- 上下文提供: 为 AI 工具提供 GitHub 仓库的实时、准确的文档和代码上下文。
- 消除幻觉: 解决 AI 模型在处理新项目或训练数据之外的信息时可能出现的"代码幻觉"问题。
- 文档获取:
fetch_documentation:检索项目的主要文档。 - 文档搜索:
search_documentation:根据特定查询在文档中进行搜索。 - 代码搜索:
search_code:在实际仓库代码中进行搜索。 - URL 内容获取:
fetch_url_content:检索引用链接的内容。
技术原理
GitMCP 的核心是实现了模型上下文协议(Model Context Protocol, MCP)。MCP 是一种标准,允许 AI 工具从外部源请求额外的上下文信息。其工作流程如下:
- 用户在 AI 工具中将 GitMCP 配置为一个 MCP 服务器。
- 用户向 AI 提出关于代码或文档的问题。
- AI 工具(在用户批准后)向 GitMCP 发送请求。
- GitMCP 从相应的 GitHub 仓库获取相关信息。
- AI 接收到准确、最新的信息,并提供基于事实的回复。 它通过提供
fetch和search等工具接口,使得 AI 能够按需动态获取并理解 GitHub 仓库的内容。
应用场景
- AI 辅助编程: 允许 AI 编程助手(如 Cursor)深度理解任何 GitHub 仓库的内部结构和文档,从而提供更准确的代码建议、bug 修复和问题解答。
- 知识库查询: AI 模型可以利用 GitMCP 访问和检索非其训练集中的项目文档,为用户提供关于开源项目、库或框架的最新信息。
- 开发效率提升: 开发者可以配置 AI 工具与 GitMCP 集成,快速获取项目上下文,减少手动查阅大量文档和代码的时间。
- 教育与学习: AI 导师可以通过 GitMCP 访问特定 GitHub 项目的详细信息,帮助学生理解和学习新的技术栈。
GitMCP的项目地址
- 项目官网:gitmcp.io/
- GitHub仓库:github.com/idosal/git-...
NeuralAgent -- 开源的桌面AI助手
NeuralAgent是一款开源的桌面AI个人助手,旨在通过自然语言指令自动化执行计算机上的多种复杂任务。它作为一个本地AI智能体,能够直接在用户的操作系统上运行,像人类一样与桌面环境进行交互。
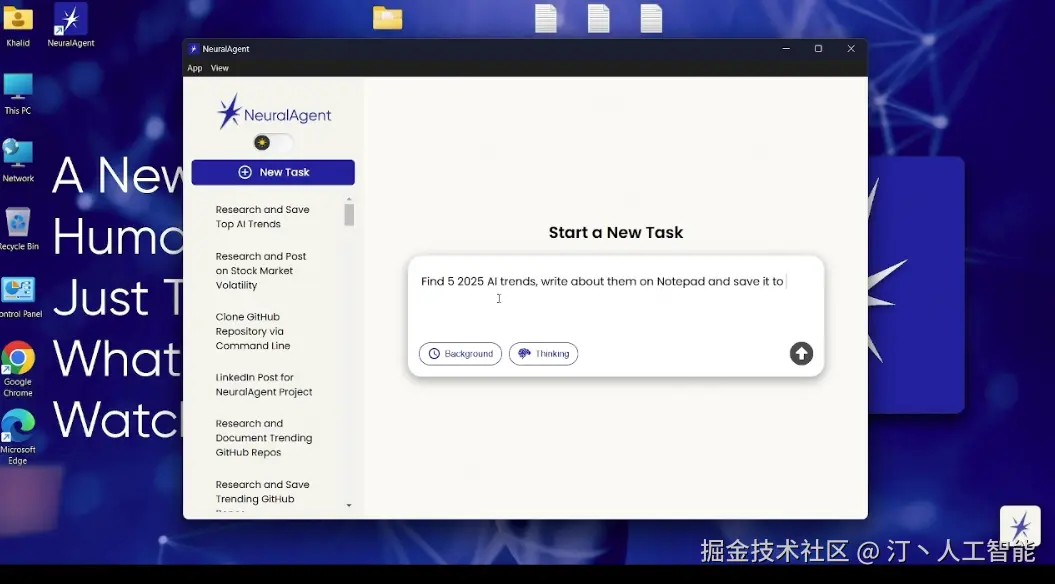
核心功能
- 桌面自动化操作: 模拟键盘输入、鼠标点击等,实现与桌面应用的无缝交互。
- 浏览器任务处理: 自动导航浏览器、填写表单、发送邮件等。
- 跨应用和工作流自动化: 理解并执行跨不同应用程序和工作流程的任务。
- 复杂任务执行: 能够自动化处理需要多步骤和多应用协作的复杂任务。
技术原理
NeuralAgent的核心技术在于其作为"操作系统级智能体"的能力。它利用先进的AI模型来解析用户的自然语言指令,并将其转化为对操作系统和应用程序的底层操作,例如:
- 自然语言处理 (NLP): 理解并解释用户的意图和指令。
- 视觉感知与识别: 识别屏幕上的元素,如同人类用户一般理解界面布局和内容。
- 低级操作模拟: 通过模拟键盘/鼠标事件、调用系统API等方式,实现对操作系统和应用程序的精确控制。
- 任务规划与执行: 根据指令自动规划执行路径,并在实时环境中完成任务。
- 本地化运行: 作为本地AI代理,直接在桌面环境运行,提高了数据安全性和响应速度。
应用场景
-
日常办公自动化: 自动填写表格、整理邮件、数据录入、文档处理等。
-
重复性任务: 自动化执行网页浏览、信息抓取、数据搬运等高重复性工作。
-
客户服务与支持: 辅助处理常见问题、自动回复邮件或消息。
-
个人效率提升: 根据用户指令自动管理文件、启动应用程序、设置提醒等。
-
软件测试与开发: 自动化执行测试用例,模拟用户操作流程。
-
GitHub仓库:github.com/withneural/...
KittenTTS -- KittenML开源的轻量级文本转语音模型
KittenTTS是由KittenML团队开发的一款轻量级开源文本转语音(TTS)模型。该模型以其极小的体积(通常小于25MB,甚至仅1500万参数)和强大的CPU优化能力为主要特点,使其无需图形处理器(GPU)即可在低功耗设备上高效运行,旨在提供高质量、真实的语音合成。
核心功能
- 文本转语音合成: 将输入的文本内容转换为自然流畅的语音输出。
- 轻量级部署: 模型文件体积小,易于集成到资源受限的设备或应用中。
- CPU优化运行: 专为中央处理器(CPU)进行了深度优化,无需依赖高性能GPU,降低了硬件成本和功耗。
- 高质量语音: 能够生成清晰、逼真且具有表现力的语音。
- 多种预设声音: 提供多种高质量的预设语音选择。
技术原理
KittenTTS基于先进的深度学习技术实现文本到语音的转换。其核心技术原理在于采用高效、紧凑的模型架构设计,显著减少了模型的参数量(如15M参数),从而实现了超小的模型体积。同时,通过专门的算法和优化策略,使得模型能够在仅使用CPU的情况下,依然保持高效的推理速度和高质量的语音输出,尤其适用于对计算资源和功耗有严格限制的边缘计算和嵌入式系统。
应用场景
-
低功耗设备: 适用于智能音箱、物联网设备、智能家电等对能耗和体积有严格要求的硬件平台。
-
边缘计算: 在不需要云端算力支持的边缘设备上实现本地语音合成,提升响应速度和数据隐私性。
-
移动应用: 集成到手机应用或嵌入式系统中,为用户提供语音播报、导航等功能。
-
教育领域: 可应用于编程教育平台,为青少年提供交互式语音反馈。
-
个人及商业应用: 凡是需要高质量、低成本语音合成的场景,如内容创作、有声读物、智能客服等。
-
Github仓库:github.com/KittenML/Ki...
3. AI-Compass
AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供从完整学习路径。
- github地址:AI-Compass👈:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass👈:https://gitee.com/tingaicompass/ai-compass
🌟 如果本项目对您有所帮助,请为我们点亮一颗星!🌟
📋 核心模块架构:
- 🧠 基础知识模块:涵盖AI导航工具、Prompt工程、LLM测评、语言模型、多模态模型等核心理论基础
- ⚙️ 技术框架模块:包含Embedding模型、训练框架、推理部署、评估框架、RLHF等技术栈
- 🚀 应用实践模块:聚焦RAG+workflow、Agent、GraphRAG、MCP+A2A等前沿应用架构
- 🛠️ 产品与工具模块:整合AI应用、AI产品、竞赛资源等实战内容
- 🏢 企业开源模块:汇集华为、腾讯、阿里、百度飞桨、Datawhale等企业级开源资源
- 🌐 社区与平台模块:提供学习平台、技术文章、社区论坛等生态资源
📚 适用人群:
- AI初学者:提供系统化的学习路径和基础知识体系,快速建立AI技术认知框架
- 技术开发者:深度技术资源和工程实践指南,提升AI项目开发和部署能力
- 产品经理:AI产品设计方法论和市场案例分析,掌握AI产品化策略
- 研究人员:前沿技术趋势和学术资源,拓展AI应用研究边界
- 企业团队:完整的AI技术选型和落地方案,加速企业AI转型进程
- 求职者:全面的面试准备资源和项目实战经验,提升AI领域竞争力