第四章:大模型(LLM)
第五部分:LLM实战: 实现GPT2
第六节:贪婪编码,temperature及tok原理及实现
1. 贪婪解码(Greedy Decoding)
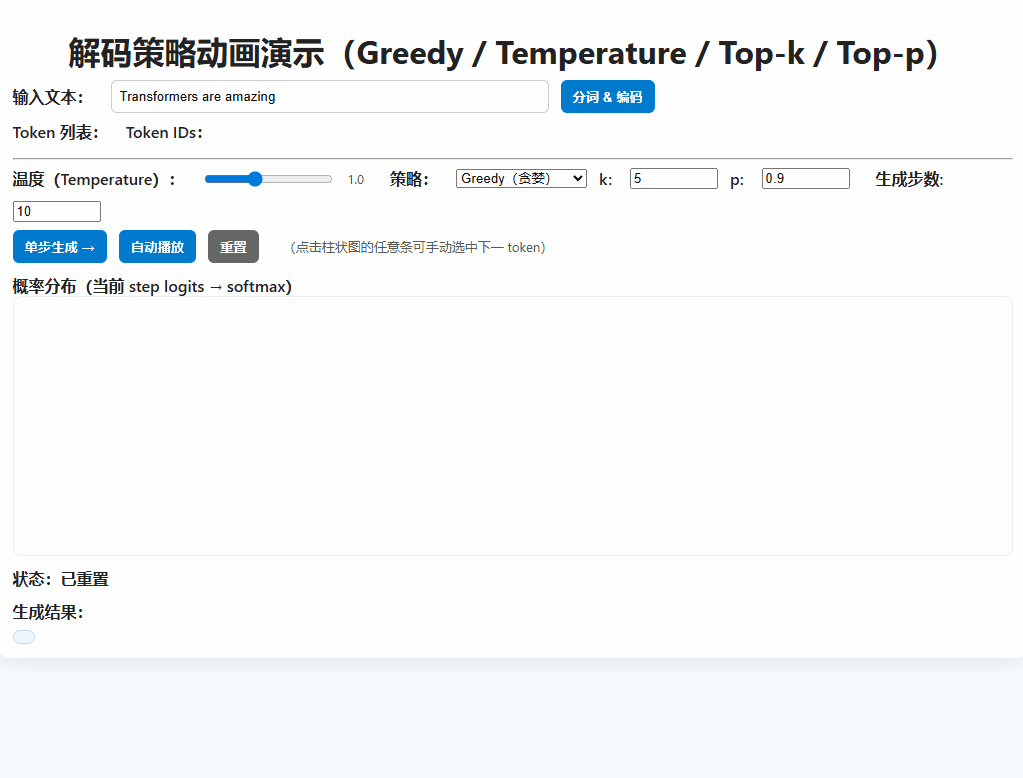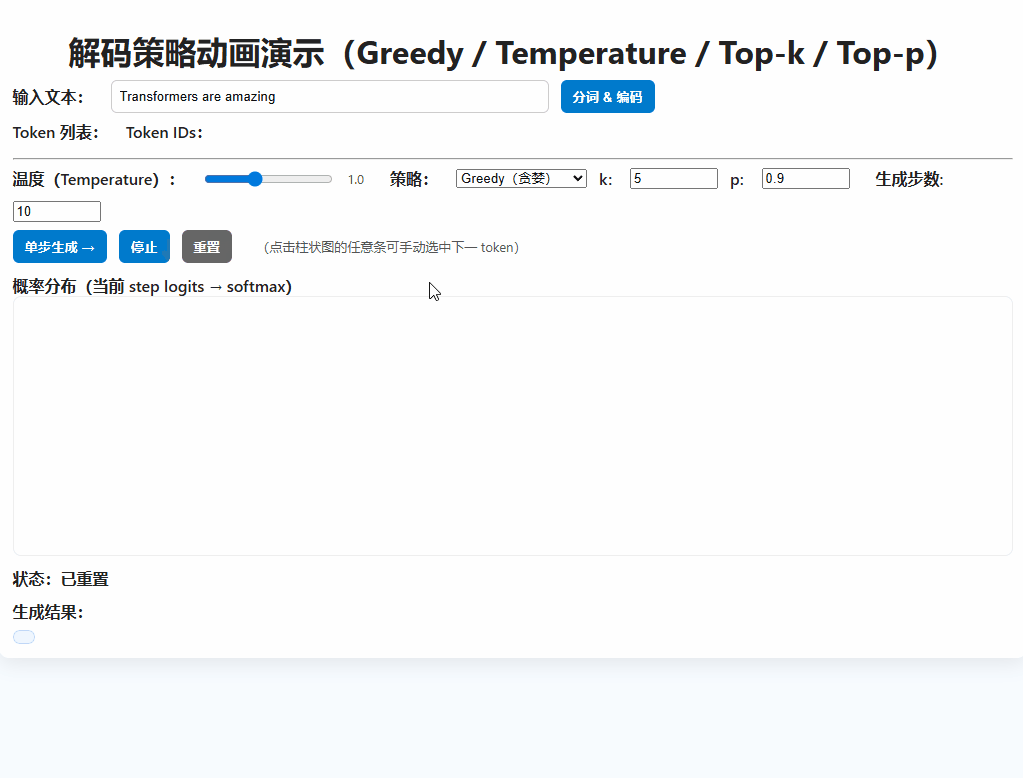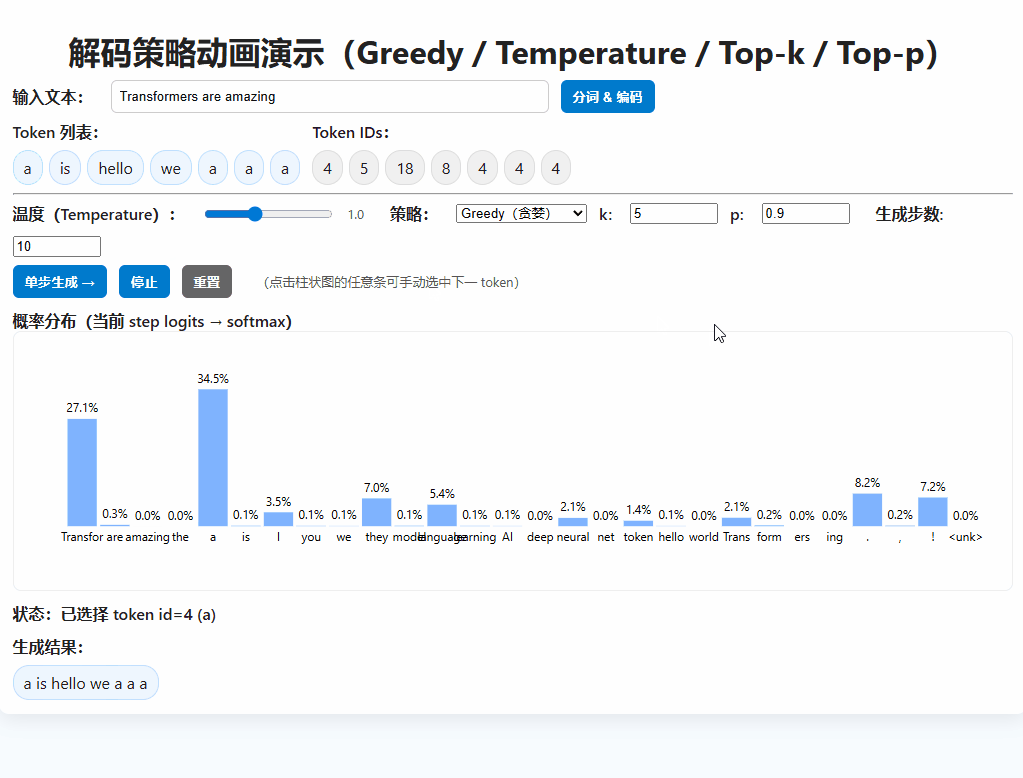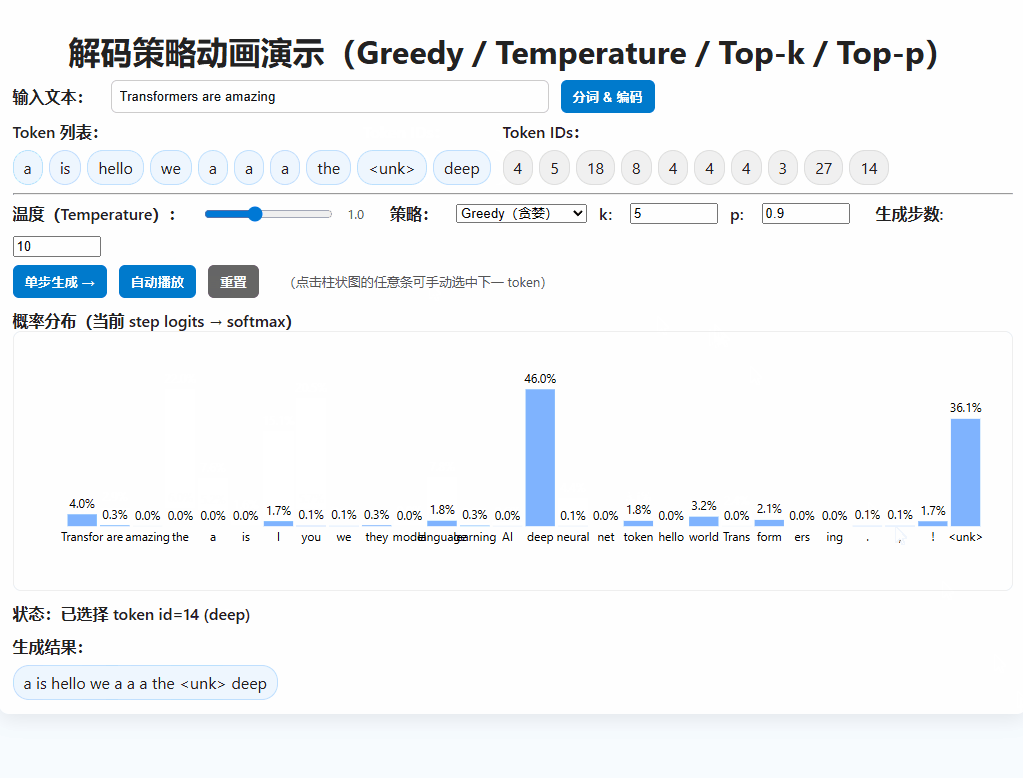
在 GPT-2 等自回归语言模型中,文本生成是一步步预测下一个 token 的过程。
贪婪解码(Greedy Decoding)是最简单的一种生成策略:
-
在每一步预测中,直接选择概率最大的下一个 token。
-
优点:速度快、实现简单。
-
缺点:可能陷入局部最优,导致生成的文本缺乏多样性。
公式:
PyTorch 实现示例:
python
def greedy_decode(model, tokenizer, prompt, max_length=50):
tokens = tokenizer.encode(prompt, return_tensors='pt')
for _ in range(max_length):
logits = model(tokens).logits
next_token = torch.argmax(logits[:, -1, :], dim=-1)
tokens = torch.cat([tokens, next_token.unsqueeze(0)], dim=1)
return tokenizer.decode(tokens[0])2. Temperature 参数
在生成任务中,Temperature 用于控制模型输出分布的"平滑度":
-
Temperature = 1:正常 softmax 概率。
-
Temperature < 1:放大高概率 token 的差距,使模型更保守(确定性更高)。
-
Temperature > 1:平滑概率分布,使低概率 token 更容易被采样(多样性更高)。
修改 logits 的方式:
实现:
python
def apply_temperature(logits, temperature=1.0):
return logits / temperature3. Token 原理
GPT-2 使用 Byte Pair Encoding (BPE) 分词:
-
将文本切分为子词单元(subword),常见词保持完整,生僻词拆分成多个子单元。
-
英文可以按空格分词,但 BPE 能更好地兼顾词汇表大小与覆盖率。
-
中文 BPE 会将常用字、常用词直接作为 token,罕见组合才拆分。
优点:
-
减少词表大小,降低模型参数量。
-
能处理 OOV(未登录词)问题。
简单 BPE 分词示例:
python
from transformers import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokens = tokenizer.encode("机器学习是一门有趣的学科")
print(tokens) # Token ID 列表
print(tokenizer.decode(tokens)) # 再解码回文本4. 结合实现:带 Temperature 的贪婪解码
python
import torch
def generate_with_temperature(model, tokenizer, prompt, max_length=50, temperature=1.0):
tokens = tokenizer.encode(prompt, return_tensors='pt')
for _ in range(max_length):
logits = model(tokens).logits[:, -1, :]
logits = logits / temperature # 调整温度
probs = torch.softmax(logits, dim=-1)
next_token = torch.argmax(probs, dim=-1)
tokens = torch.cat([tokens, next_token.unsqueeze(0)], dim=1)
return tokenizer.decode(tokens[0])
# 使用示例
# result = generate_with_temperature(model, tokenizer, "从前有座山", temperature=0.7)
# print(result)5. 小结表格
| 概念 | 功能 | 优点 | 缺点 |
|---|---|---|---|
| 贪婪解码 | 每步选概率最大 token | 简单、快 | 缺乏多样性 |
| Temperature < 1 | 让模型更确定 | 连贯性高 | 容易重复 |
| Temperature > 1 | 增加多样性 | 生成有创意 | 容易偏离主题 |
| Token(BPE) | 压缩词表,子词编码 | 减少参数 | 分词依赖预训练 |