在日常开发中,我们经常会遇到需要根据不同条件执行不同逻辑的场景,导致代码中出现大量的if/else嵌套。这不仅降低了代码的可读性和可维护性,还会增加后续扩展的难度。
本文将介绍四种优雅的设计模式来优化这种"条件爆炸"问题:
1 策略模式
01 概念
首先我们来看下策略模式的定义。
策略模式(Strategy Pattern)是行为型设计模式之一,它定义了一系列算法,并将每个算法封装起来,使它们可以相互替换。 策略模式使得算法可以独立于使用它们的客户端变化。
怎么理解策略模式 ?
软件开发中常常遇到这种情况,实现某一个功能有多种算法或者策略,我们需要根据环境或者条件的不同选择不同的算法或者策略来完成该功能。
这么一看,不就是 if...else...的逻辑 :

图中的实现逻辑非常简单,当我们是初学者时,这样写没有问题,只要能正常运行即可。但随着经验的增长,这段代码明显违反了 OOP 的两个基本原则:
- 单一职责原则:一个类或模块只负责完成一个职责或功能。
- 开闭原则:软件实体(模块、类、方法等)应该"对扩展开放,对修改关闭"。
由于违反了这两个原则,当 if-else 块中的逻辑日益复杂时,代码会变得越来越难以维护,极容易出现问题。
策略模式的设计思路是:
定义一些独立的类来封装不同的算法,每一个类封装一个具体的算法。
每一个封装算法的类我们都可以称之为策略 (Strategy) ,为了保证这些策略的一致性,一般会用一个抽象的策略类来做算法的定义,而具体每种算法则对应于一个具体策略类。
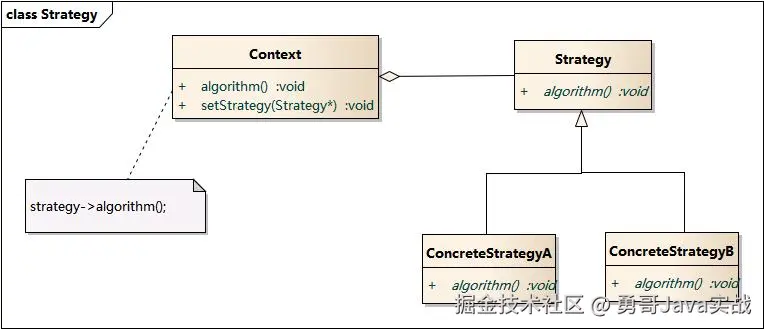
这种设计思想里,包含三个角色:
- Context: 环境类
- Strategy: 抽象策略类
- ConcreteStrategy: 具体策略类
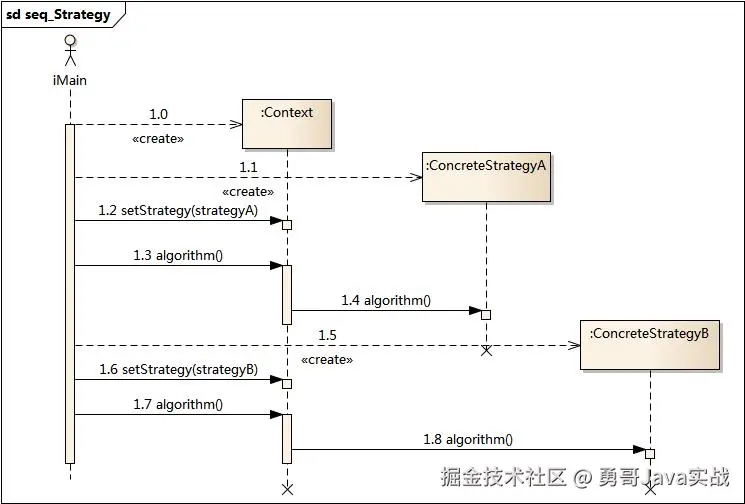
对应的时序图:
接下来,我们用代码简单演示一下。
02 例子
步骤 1:创建接口
csharp
public interface Strategy {
public int doOperation(int num1, int num2);
}Strategy 接口定义了一个 doOperation 方法,所有具体策略类将实现这个接口,以提供具体的操作。
步骤 2:创建实现相同接口的具体类
OperationAdd 是一个具体的策略类,实现了加法操作。
java
public class OperationAdd implements Strategy{
@Override
public int doOperation(int num1, int num2) {
return num1 + num2;
}
}OperationSubtract 是另一个具体的策略类,实现了减法操作。
java
public class OperationMultiply implements Strategy{
@Override
public int doOperation(int num1, int num2) {
return num1 * num2;
}
}OperationMultiply 是第三个具体的策略类,实现了乘法操作。
java
public class OperationMultiply implements Strategy{
@Override
public int doOperation(int num1, int num2) {
return num1 * num2;
}
}步骤 3:创建上下文类
arduino
public class Context {
private Strategy strategy;
public void setStrategy(Strategy strategy) {
this.strategy = strategy;
}
public int executeStrategy(int num1, int num2) {
return strategy.doOperation(num1, num2);
}
}Context 类持有一个策略对象的引用,并允许客户端设置其策略。它提供了一个 executeStrategy 方法,用于执行策略并返回结果。
步骤 4:使用上下文来看到策略改变时的行为变化
csharp
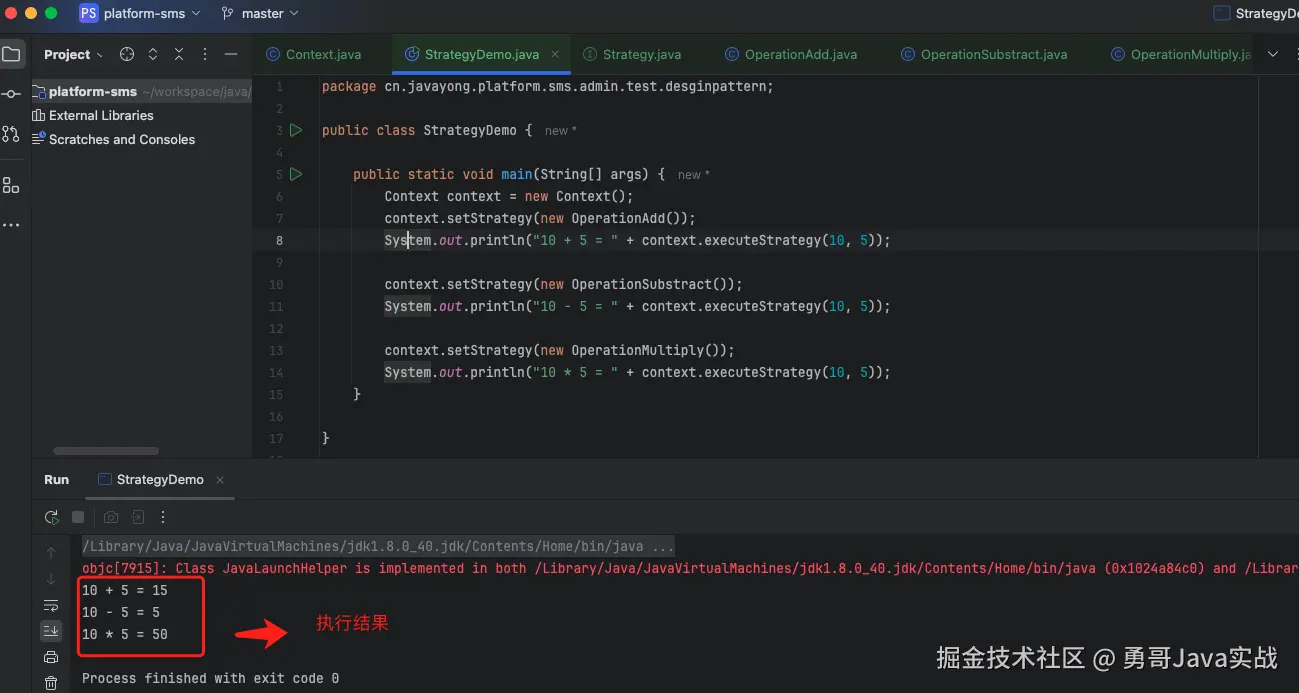
public static void main(String[] args) {
Context context = new Context();
context.setStrategy(new OperationAdd());
System.out.println("10 + 5 = " + context.executeStrategy(10, 5));
context.setStrategy(new OperationSubstract());
System.out.println("10 - 5 = " + context.executeStrategy(10, 5));
context.setStrategy(new OperationMultiply());
System.out.println("10 * 5 = " + context.executeStrategy(10, 5));
}执行结果:
从上面的例子,我们简单总结下策略模式的优缺点:
1、优点
- 策略模式提供了对"开闭原则"的完美支持,用户可以在不修改原有系统的基础上选择算法或行为,也可以灵活地增加新的算法或行为。
- 策略模式提供了管理相关的算法族的办法。
- 使用策略模式可以避免使用多重条件转移语句。
2、缺点
- 客户端必须知道所有的策略类,并自行决定使用哪一个策略类。
- 策略模式将造成产生很多策略类,可以通过使用享元模式在一定程度上减少对象的数量。
2 SPI 机制
01 概念
SPI 全称为 Service Provider Interface,是一种服务发现机制。
SPI 的本质是将接口实现类 的全限定名配置在文件 中,并由服务加载器读取配置文件,加载实现类。这样可以在运行时,动态为接口替换实现类。正因此特性,我们可以很容易的通过 SPI 机制为我们的程序提供拓展功能。
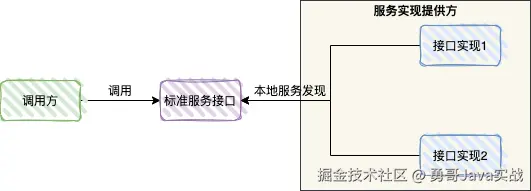
02 Java SPI : JDBC Driver
在JDBC4.0 之前,我们开发有连接数据库的时候,通常先加载数据库相关的驱动,然后再进行获取连接等的操作。
ini
// STEP 1: Register JDBC driver
Class.forName("com.mysql.jdbc.Driver");
// STEP 2: Open a connection
String url = "jdbc:xxxx://xxxx:xxxx/xxxx";
Connection conn = DriverManager.getConnection(url,username,password);JDBC4.0之后使用了 Java 的 SPI 扩展机制,不再需要用 Class.forName("com.mysql.jdbc.Driver") 来加载驱动,直接就可以获取 JDBC 连接。
接下来,我们来看看应用如何加载 MySQL JDBC 8.0.22 驱动:
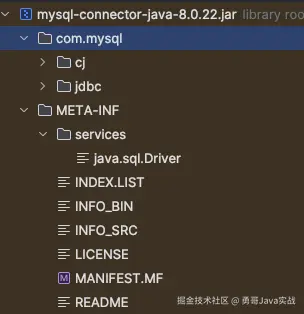
首先 DriverManager类是驱动管理器,也是驱动加载的入口。
scss
/**
* Load the initial JDBC drivers by checking the System property
* jdbc.properties and then use the {@code ServiceLoader} mechanism
*/
static {
loadInitialDrivers();
println("JDBC DriverManager initialized");
}在 Java 中,static 块用于静态初始化,它在类被加载到 Java 虚拟机中时执行。
静态块会加载实例化驱动,接下来我们看看loadInitialDrivers 方法。
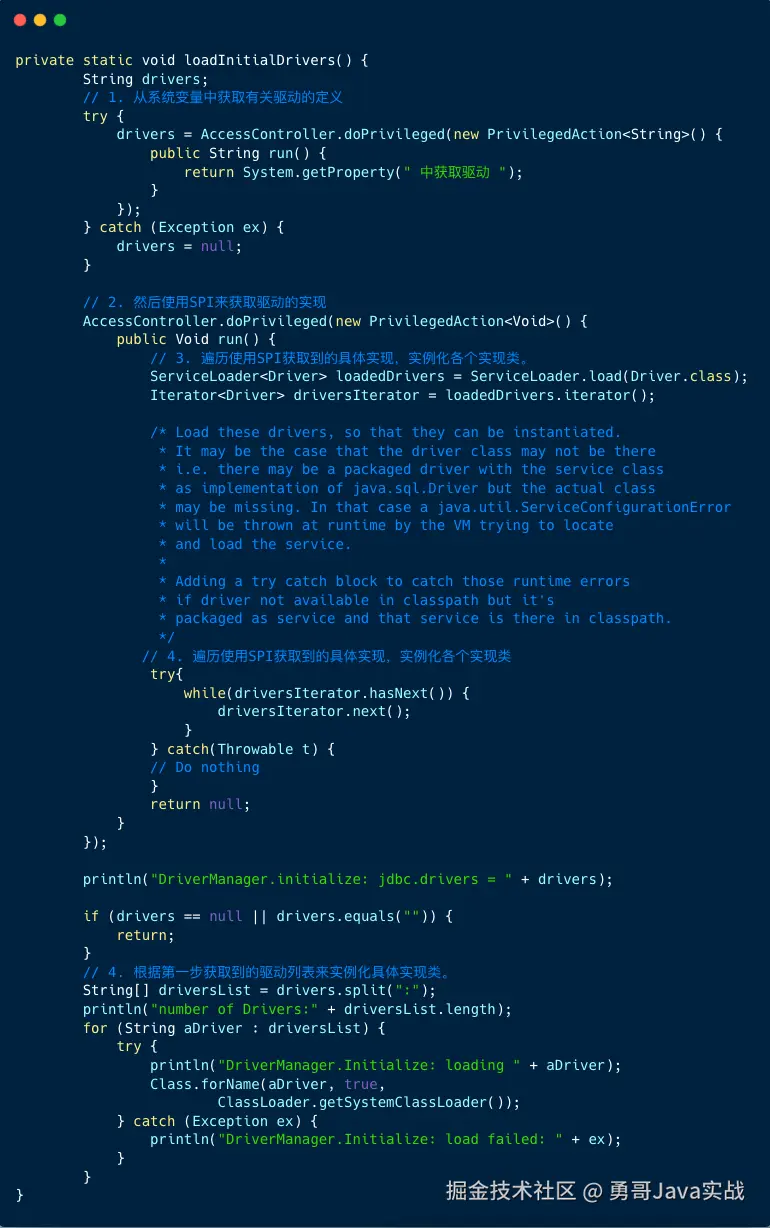
加载驱动代码包含四个步骤:
- 系统变量中获取有关驱动的定义。
- 使用 SPI 来获取驱动的实现类(字符串的形式)。
- 遍历使用 SPI 获取到的具体实现,实例化各个实现类。
- 根据第一步获取到的驱动列表来实例化具体实现类。
我们重点关注 SPI 的用法,首先看第二步,使用 SPI 来获取驱动的实现类 , 对应的代码是:
ini
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);这里没有去 META-INF/services目录下查找配置文件,也没有加载具体实现类,做的事情就是封装了我们的接口类型和类加载器,并初始化了一个迭代器。
接着看第三步,遍历使用SPI获取到的具体实现,实例化各个实现类,对应的代码如下:
scss
Iterator<Driver> driversIterator = loadedDrivers.iterator();
//遍历所有的驱动实现
while(driversIterator.hasNext()) {
driversIterator.next();
}在遍历的时候,首先调用driversIterator.hasNext()方法,这里会搜索 classpath 下以及 jar 包中所有的META-INF/services目录下的java.sql.Driver文件,并找到文件中的实现类的名字,此时并没有实例化具体的实现类。
然后是调用driversIterator.next()方法,此时就会根据驱动名字具体实例化各个实现类了,现在驱动就被找到并实例化了。
这里有一个小小的疑问: 那么如果发现了多个 driver 的话,要选择哪一个具体的实现呢?
那就是 JDBC URL 了,driver 的实现有一个约定,如果 driver 根据 JDBC URL 判断不是自己可以处理的连接就直接返回空,DriverManager 就是基于这个约定直到找到第一个不返回 null 的连接为止。
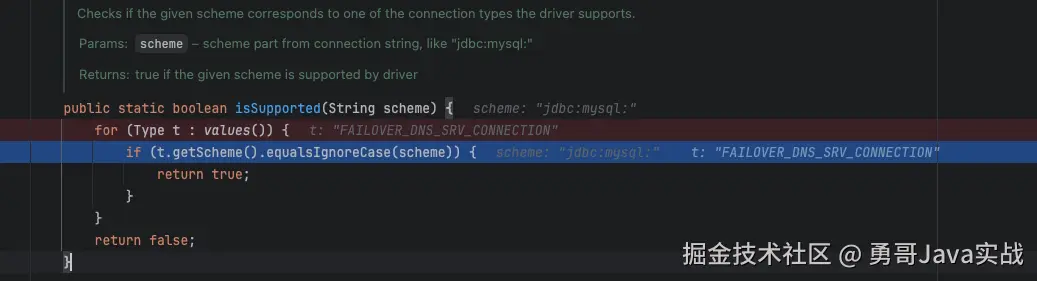
JDBC Driver 是 Java SPI 机制的一个非常经典的应用场景,包含三个核心步骤:
- 定义 SPI 文件 ,指定 Driver class 全限定名 ;
- 通过
DriverManager静态类自动加载驱动 ; - 加载之后,当需要获取连接时,还需要根据 ConnectionUrl 判断使用哪一个加载完成的 Driver 。
因此, JDBC Driver 的 SPI 机制是需要多个步骤配合来完成的 ,同时基于 Java SPI 机制的缺陷,同样也无法按需加载。
03 按需加载:Dubbo SPI 机制
基于 Java SPI 的缺陷无法支持按需加载接口实现类,Dubbo 并未使用 Java SPI,而是重新实现了一套功能更强的 SPI 机制。
Dubbo SPI 的相关逻辑被封装在了 ExtensionLoader 类中,通过 ExtensionLoader,我们可以加载指定的实现类。
Dubbo SPI 所需的配置文件需放置在 META-INF/dubbo 路径下,配置内容如下:
ini
optimusPrime = org.apache.spi.OptimusPrime
bumblebee = org.apache.spi.Bumblebee与 Java SPI 实现类配置不同,Dubbo SPI 是通过键值对的方式进行配置,这样我们可以按需加载指定的实现类。
另外,在测试 Dubbo SPI 时,需要在 Robot 接口上标注 @SPI 注解。
下面来演示 Dubbo SPI 的用法:
ini
public class DubboSPITest {
@Test
public void sayHello() throws Exception {
ExtensionLoader<Robot> extensionLoader =
ExtensionLoader.getExtensionLoader(Robot.class);
Robot optimusPrime = extensionLoader.getExtension("optimusPrime");
optimusPrime.sayHello();
Robot bumblebee = extensionLoader.getExtension("bumblebee");
bumblebee.sayHello();
}
}测试结果如下 :

另外,Dubbo SPI 除了支持按需加载接口实现类,还增加了 IOC 和 AOP 等特性 。
SPI 机制的优势:
- 实现完全解耦
- 新增实现无需修改主代码
- 支持运行时动态发现和加载
3 责任链模式
01 概念
责任链模式是一种行为设计模式, 允许你将请求沿着处理者链进行发送。 收到请求后, 每个处理者均可对请求进行处理, 或将其传递给链上的下个处理者。
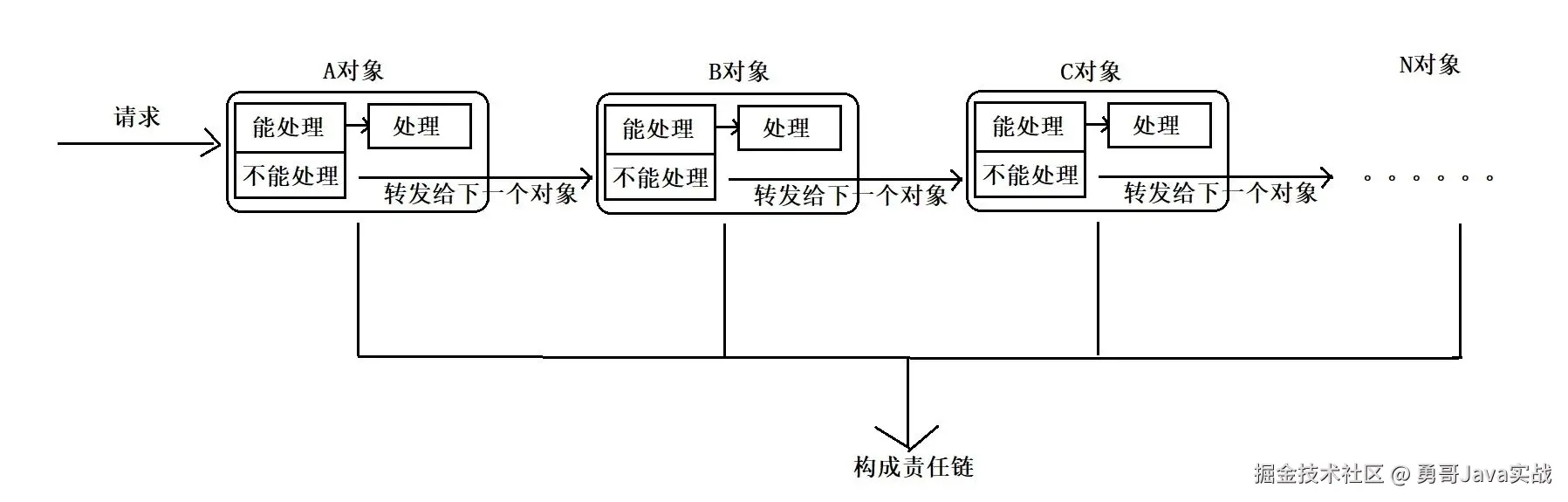
更简单的描述是:责任链是一个链表结构,这条链上有多个节点,它们有相同的接口,各自有各自的责任和实现。当有数据输入时,第一个节点看自己能否处理问题,如果可以就进行处理,如果不能就数据交给下一个节点进行处理,以此类推直到最后一个责任节点。
责任链模式的使用场景是:
-
有多个对象可以处理同一个请求,具体由哪个对象处理是在运行时确定的。
- 例如,有 ABC 三个处理者可以处理一个请求,请求 a 需要 AC 两个处理者处理,请求 b 需要 BC 两个处理者处理,同时两个处理者之间可能有前后依赖关系,这时候就可以使用责任链模式
-
在不确定请求处理者的时候,向同一类型的处理者中的一个发送请求
02 例子
笔者曾经通过责任链模式优化神州专车支付流程 。
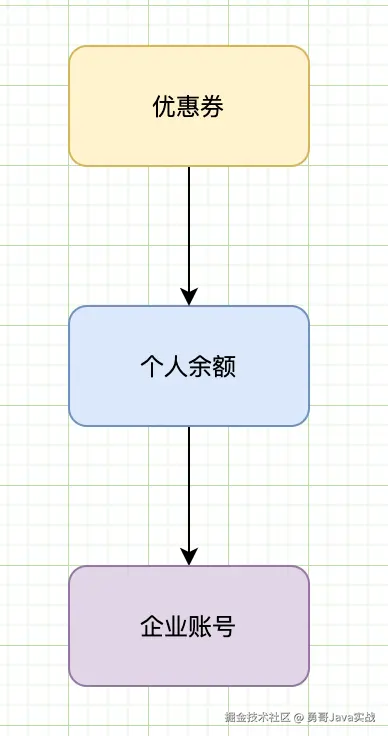
支付流程是通过定时任务执行,每次都需要去判断用户的账号余额、优惠券、企业账号余额是否可以抵扣,假如满足条件,则从对应的账号资产里扣除对应的金额 。
因为原来的代码存在大量的 if/else 逻辑,业务逻辑相互杂糅,维护成本很高,勇哥花了一周时间重构了该逻辑 , 以下是演示伪代码:
1、定义抽象处理者(Handler)
arduino
/**
* 支付处理器接口
* 定义所有支付方式需要实现的方法
*/
public interface PaymentHandler {
/**
* 判断该支付处理器是否适用于当前用户
* @param userId 用户ID
* @return 是否适用
*/
boolean canProcess(String userId);
/**
* 执行支付操作
* @param userId 用户ID
* @param amount 支付金额
* @return 支付结果
*/
PaymentResult processPayment(String userId, double amount);
}
/**
* 支付结果类
* 封装支付操作的结果信息
*/
class PaymentResult {
private boolean success; // 支付是否成功
private double paidAmount; // 实际支付金额
private String message; // 支付结果描述信息
public PaymentResult(boolean success, double paidAmount, String message) {
this.success = success;
this.paidAmount = paidAmount;
this.message = message;
}
// Getter方法
public boolean isSuccess() {
return success;
}
public double getPaidAmount() {
return paidAmount;
}
public String getMessage() {
return message;
}
}2、定义具体处理者(Concrete Handler)
arduino
/**
* 企业账户支付处理器实现
*/
public class CorporatePaymentHandler implements PaymentHandler {
private static final double MAX_CORPORATE_PAYMENT = 5000; // 企业账户最大支付限额
@Override
public boolean canProcess(String userId) {
// 只有以"emp_"开头的用户ID才能使用企业账户支付
return userId.startsWith("emp_");
}
@Override
public PaymentResult processPayment(String userId, double amount) {
System.out.printf("尝试使用企业账户支付: 用户[%s], 金额[%.2f]%n", userId, amount);
if (amount <= MAX_CORPORATE_PAYMENT) {
// 金额在限额内,全额支付
return new PaymentResult(true, amount, "企业账户支付成功");
} else {
// 超过限额,只支付限额部分
return new PaymentResult(true, MAX_CORPORATE_PAYMENT,
String.format("企业账户部分支付成功(%.2f),还需支付: %.2f",
MAX_CORPORATE_PAYMENT, amount - MAX_CORPORATE_PAYMENT));
}
}
}
/**
* 个人账户支付处理器实现
*/
public class PersonalPaymentHandler implements PaymentHandler {
private static final double MAX_PERSONAL_PAYMENT = 1000; // 个人账户最大支付限额
@Override
public boolean canProcess(String userId) {
// 所有用户都可以使用个人账户支付
return true;
}
@Override
public PaymentResult processPayment(String userId, double amount) {
System.out.printf("尝试使用个人账户支付: 用户[%s], 金额[%.2f]%n", userId, amount);
if (amount <= MAX_PERSONAL_PAYMENT) {
// 金额在限额内,全额支付
return new PaymentResult(true, amount, "个人账户支付成功");
} else {
// 超过限额,只支付限额部分
return new PaymentResult(true, MAX_PERSONAL_PAYMENT,
String.format("个人账户部分支付成功(%.2f),还需支付: %.2f",
MAX_PERSONAL_PAYMENT, amount - MAX_PERSONAL_PAYMENT));
}
}
}3、定义组合支付上下文(核心数据结构是链表)
typescript
/**
* 组合支付上下文
* 负责管理支付处理器并执行组合支付
*/
public class CompositePaymentContext {
private final List<PaymentHandler> handlers = new ArrayList<>();
/**
* 添加支付处理器
* @param handler 支付处理器实例
*/
public void addHandler(PaymentHandler handler) {
handlers.add(handler);
}
/**
* 执行组合支付
* @param userId 用户ID
* @param totalAmount 总支付金额
* @return 支付结果映射表,key为处理器类名,value为支付结果
*/
public Map<String, PaymentResult> executePayment(String userId, double totalAmount) {
// 使用LinkedHashMap保持支付尝试的顺序
Map<String, PaymentResult> paymentResults = new LinkedHashMap<>();
double remaining = totalAmount; // 剩余待支付金额
// 按处理器顺序尝试支付
for (PaymentHandler handler : handlers) {
// 检查处理器是否适用且还有金额需要支付
if (handler.canProcess(userId) && remaining > 0) {
// 执行支付
PaymentResult result = handler.processPayment(userId, remaining);
// 记录支付结果
paymentResults.put(handler.getClass().getSimpleName(), result);
if (result.isSuccess()) {
// 支付成功,减少剩余金额
remaining -= result.getPaidAmount();
if (remaining <= 0) {
break; // 金额已支付完成,退出循环
}
}
}
}
// 如果还有剩余金额未支付,记录剩余金额
if (remaining > 0) {
paymentResults.put("Remaining", new PaymentResult(false, remaining,
String.format("支付未完成,剩余金额: %.2f", remaining)));
}
return paymentResults;
}
}4、测试类
arduino
/**
* 组合支付系统演示类
*/
public class CompositePaymentSystem {
public static void main(String[] args) {
// 初始化支付上下文
CompositePaymentContext paymentContext = new CompositePaymentContext();
// 注册支付处理器(顺序决定了支付尝试的优先级)
paymentContext.addHandler(new CorporatePaymentHandler()); // 先尝试企业账户
paymentContext.addHandler(new PersonalPaymentHandler()); // 再尝试个人账户
// 测试用例1:企业用户,只需企业账户支付
System.out.println("\n=== 测试用例1 ===");
System.out.println("用户ID: emp_789, 支付金额: 3000.00");
Map<String, PaymentResult> results1 = paymentContext.executePayment("emp_789", 3000);
results1.forEach((handlerName, result) -> {
System.out.printf("[%s] %s (支付金额: %.2f)%n",
handlerName, result.getMessage(), result.getPaidAmount());
});
// 测试用例2:企业用户,需要组合支付
System.out.println("\n=== 测试用例2 ===");
System.out.println("用户ID: emp_789, 支付金额: 6000.00");
Map<String, PaymentResult> results2 = paymentContext.executePayment("emp_789", 6000);
results2.forEach((handlerName, result) -> {
System.out.printf("[%s] %s (支付金额: %.2f)%n",
handlerName, result.getMessage(), result.getPaidAmount());
});
// 测试用例3:个人用户,只需个人账户支付
System.out.println("\n=== 测试用例3 ===");
System.out.println("用户ID: user123, 支付金额: 1500.00");
Map<String, PaymentResult> results3 = paymentContext.executePayment("user123", 1500);
results3.forEach((handlerName, result) -> {
System.out.printf("[%s] %s (支付金额: %.2f)%n",
handlerName, result.getMessage(), result.getPaidAmount());
});
}
}4 规则引擎
01 概念
电商系统中,经常会有营销活动,比如支付订单时给与用户一定程度的优惠,比如活动规则:满 1000 减200 ,满 500 减 100 。
这种情况一般都是通过 if-else 做分支判断处理,还是非常简单的。
但假如需要频繁的修改活动规则,那么就需要频繁的修改代码,非常不容易维护(开发成本 + 上线成本)。
此时,引入规则引擎有顺其自然了。规则引擎的优势如下:
- 降低开发成本
- 业务人员独立配置业务规则,开发人员无需理解,以往需要业务人员告诉开发人员,开发人员需要理解才能开发,并且还需要大量的测试来确定是否正确,而且开发结果还容易和提出的业务有偏差,种种都导致开发成本上升
- 增加业务的透明度,业务人员配置之后其它人业务人员也能看到
- 提高了规则改动的效率和上线的速度
通过规则引擎,我们只需要将业务人员配置的规则转换成一个规则字符串 ,然后将该规则字符串保存进数据库中,当使用该规则时,只传递该规则所需要的参数,便可以直接计算出结果。
02 例子
回到刚才营销活动 ,使用 AviatorScript 规则引擎的流程如下:
1、创建运营脚本,将脚本存储在数据库 或者 配置中心。
kotlin
if (amount>=1000){
return 200;
}elsif(amount>=500){
return 100;
}else{
return 0;
}2、定义调用方法 。
typescript
public static BigDecimal getDiscount(BigDecimal amount, String rule) {
// 执行规则并计算最终价格
Map<String, Object> env = new HashMap<String, Object>();
env.put("amount", amount);
Expression expression = AviatorEvaluator.compile(
DigestUtils.md5Hex(rule.getBytes()),
rule,
true);
Object result = expression.execute(env);
if (result != null) {
return new BigDecimal(String.valueOf(result));
}
return null;
}3、执行测试例子
swift
// step1 : 此处可以从配置中心 或者数据库中获取
String rule = "if (amount>=1000){\n" +
" return 200;\n" +
"}elsif(amount>=500){\n" +
" return 100;\n" +
"}else{\n" +
" return 0;\n" +
"}\n";
// step 2: 通过 AviatorScript 执行
BigDecimal discount = getDiscount(new BigDecimal("600"), rule);
System.out.println("discount:" + discount);
// 执行结果是: discount:100测试类地址:
5 总结
在实际开发中,我们经常会遇到需要根据不同条件执行不同逻辑的场景。
传统的if-else嵌套方式虽然直观,但随着业务复杂度增加,会导致代码臃肿、可读性差、维护困难等问题。
本文总结了四种优雅的设计模式来解决这类"条件爆炸"问题。
01. 策略模式:灵活切换策略
核心思想:定义一系列算法,将每个算法封装起来,并使它们可以相互替换。
适用场景:
- 系统中有多个相似的类,仅在行为上有差异
- 需要在运行时动态选择算法
- 需要避免暴露复杂的条件判断
优势:
- 符合开闭原则,易于扩展新策略
- 消除大量条件语句
- 算法可以自由切换
示例:支付系统中不同支付方式的处理,如信用卡、支付宝、微信支付等。
02. SPI机制:服务发现的优雅实现
核心思想:通过配置文件动态发现和加载服务实现。
适用场景:
- 需要实现插件化架构
- 服务提供方需要独立于服务调用方
- 需要运行时动态发现服务
优势:
- 实现完全解耦
- 新增实现无需修改主代码
- 支持热插拔
示例:JDBC驱动加载、Dubbo的扩展点实现。
03. 责任链模式:处理流程的链式传递
核心思想:将请求的发送者和接收者解耦,使多个对象都有机会处理请求。
适用场景:
- 有多个对象可以处理同一请求
- 需要动态指定处理流程
- 处理顺序很重要
优势:
- 降低耦合度
- 灵活调整处理顺序
- 新增处理器方便
示例:支付流程中的多账户组合支付、审批流程等。
04. 规则引擎:业务规则的动态管理
核心思想:将业务规则从代码中分离,实现动态配置。
适用场景:
- 业务规则频繁变化
- 需要非技术人员配置规则
- 规则复杂度高
优势:
- 业务人员可自主配置
- 降低开发成本
- 提高规则透明度
示例:营销活动规则、风控规则等。
05 设计原则指导
在实际选择解决方案时,应遵循以下原则:
- 单一职责原则:每个类/模块只负责一个功能
- 开闭原则:对扩展开放,对修改关闭
- 高内聚低耦合:模块内部高度聚合,模块间依赖最小化
- KISS原则:保持简单直接,不过度设计
没有放之四海而皆准的解决方案,需要根据具体业务场景选择最合适的方式,而不是一味追求技术的新颖或复杂。
最终目标是写出可维护、可扩展、高内聚低耦合的代码。