
医疗AI问答系统实战:知识图谱+大模型的融合应用开发
🌟 Hello,我是摘星! 🌈 在彩虹般绚烂的技术栈中,我是那个永不停歇的色彩收集者。 🦋 每一个优化都是我培育的花朵,每一个特性都是我放飞的蝴蝶。 🔬 每一次代码审查都是我的显微镜观察,每一次重构都是我的化学实验。 🎵 在编程的交响乐中,我既是指挥家也是演奏者。让我们一起,在技术的音乐厅里,奏响属于程序员的华美乐章。
摘要
作为一名深耕AI领域多年的技术从业者,我深深感受到医疗AI问答系统在当今数字化医疗转型中的重要价值。在这个信息爆炸的时代,医疗知识的复杂性和专业性对传统问答系统提出了前所未有的挑战。如何让机器真正理解医学概念之间的复杂关系?如何确保AI给出的医疗建议既准确又可靠?这些问题一直困扰着我们这些技术开发者。
经过深入的技术调研和实践探索,我发现知识图谱与大模型的融合应用为解决这些难题提供了一条全新的技术路径。知识图谱以其结构化的知识表示能力,为医疗领域的复杂概念关系提供了清晰的建模方式;而大模型则以其强大的语言理解和生成能力,为自然语言交互提供了智能化的解决方案。两者的结合不仅能够提升问答系统的准确性,更能增强其可解释性和可信度。
在本文中,我将从技术架构设计、核心算法实现、系统集成优化等多个维度,详细分享我在构建医疗AI问答系统过程中的实战经验。我们将探讨如何构建高质量的医疗知识图谱,如何设计高效的图谱检索算法,如何优化大模型的医疗领域适配,以及如何实现两者的深度融合。同时,我还会分享在系统性能优化、数据安全保护、用户体验提升等方面的实践心得,希望能为同样致力于医疗AI技术发展的开发者们提供有价值的参考。
1. 系统架构设计
1.1 整体架构概览
医疗AI问答系统的核心在于构建一个能够理解医疗专业知识并提供准确回答的智能系统。我们的架构设计采用了分层解耦的思想,将系统分为用户交互层、智能推理层、知识存储层和数据处理层。
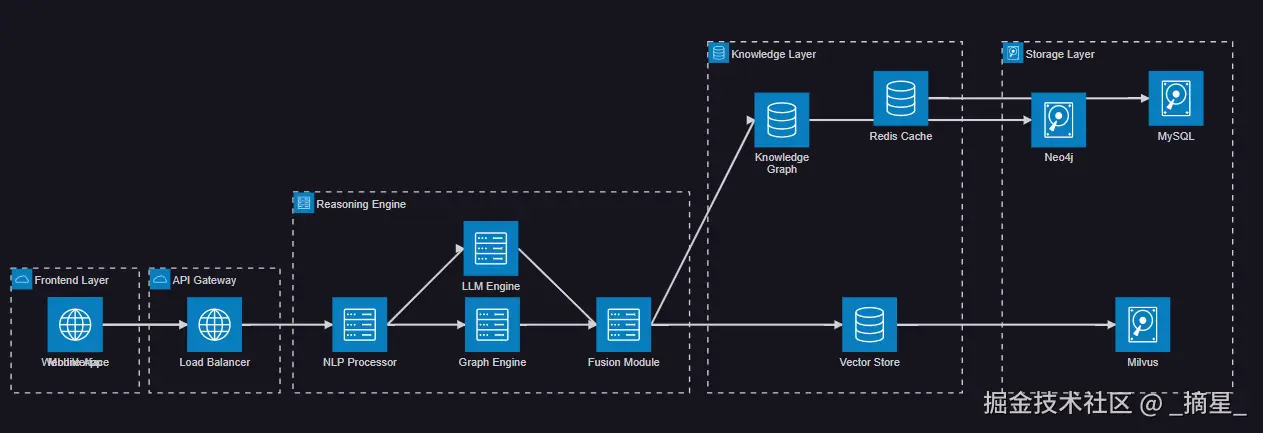
图1:医疗AI问答系统整体架构图
1.2 核心组件设计
系统的核心组件包括自然语言处理模块、知识图谱检索引擎、大模型推理引擎和融合决策模块。每个组件都承担着特定的职责,通过标准化的接口进行交互。
python
from abc import ABC, abstractmethod
from typing import Dict, List, Any, Optional
import asyncio
from dataclasses import dataclass
@dataclass
class MedicalQuery:
"""医疗查询数据结构"""
query_text: str
user_id: str
session_id: str
context: Optional[Dict[str, Any]] = None
timestamp: Optional[str] = None
@dataclass
class KnowledgeEntity:
"""知识实体数据结构"""
entity_id: str
entity_type: str
properties: Dict[str, Any]
confidence: float
source: str
class BaseProcessor(ABC):
"""处理器基类"""
@abstractmethod
async def process(self, input_data: Any) -> Any:
"""处理输入数据"""
pass
@abstractmethod
def validate_input(self, input_data: Any) -> bool:
"""验证输入数据"""
pass
class NLPProcessor(BaseProcessor):
"""自然语言处理器"""
def __init__(self, model_path: str):
self.model_path = model_path
self.entity_extractor = None
self.intent_classifier = None
async def process(self, query: MedicalQuery) -> Dict[str, Any]:
"""处理医疗查询,提取实体和意图"""
if not self.validate_input(query):
raise ValueError("Invalid query format")
# 实体识别
entities = await self._extract_entities(query.query_text)
# 意图分类
intent = await self._classify_intent(query.query_text)
# 关键词提取
keywords = await self._extract_keywords(query.query_text)
return {
"entities": entities,
"intent": intent,
"keywords": keywords,
"processed_query": query.query_text
}
def validate_input(self, query: MedicalQuery) -> bool:
"""验证查询输入"""
return isinstance(query, MedicalQuery) and bool(query.query_text.strip())
async def _extract_entities(self, text: str) -> List[KnowledgeEntity]:
"""提取医疗实体"""
# 这里实现具体的实体提取逻辑
# 使用预训练的医疗NER模型
entities = []
# 模拟实体提取结果
return entities
async def _classify_intent(self, text: str) -> str:
"""分类用户意图"""
# 实现意图分类逻辑
# 可能的意图:症状查询、疾病诊断、药物咨询、治疗方案等
return "symptom_query"
async def _extract_keywords(self, text: str) -> List[str]:
"""提取关键词"""
# 实现关键词提取逻辑
return []这段代码定义了系统的核心数据结构和处理器基类。MedicalQuery封装了用户的医疗查询信息,KnowledgeEntity表示知识图谱中的实体,BaseProcessor为所有处理器提供了统一的接口规范。
2. 知识图谱构建与管理
2.1 医疗知识图谱设计
医疗知识图谱的构建是整个系统的基础。我们需要设计一个能够准确表示医疗领域复杂关系的图谱结构。
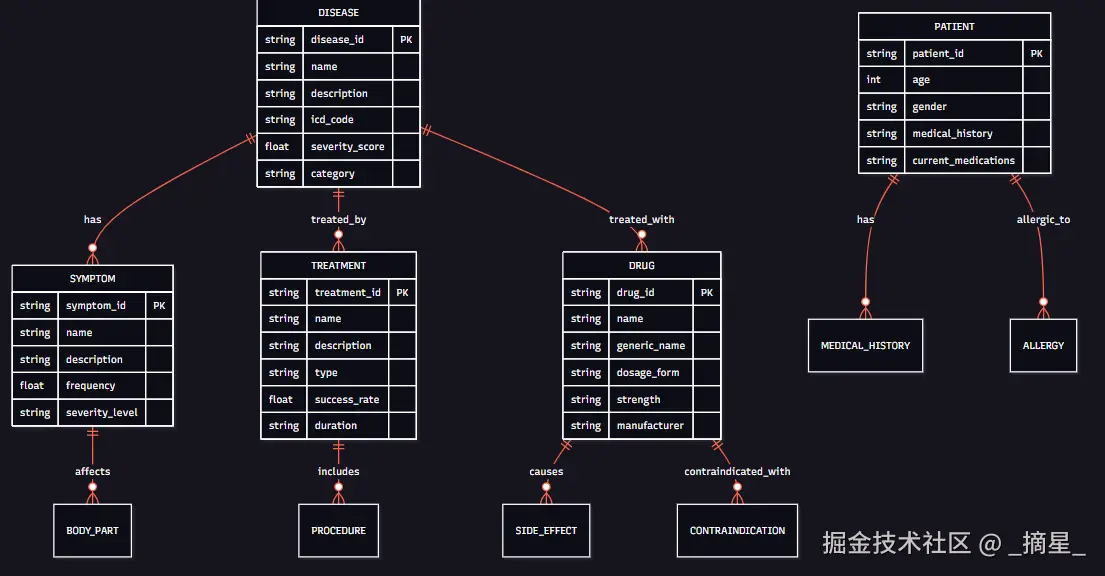
图2:医疗知识图谱实体关系图
2.2 知识图谱存储与检索
我们使用Neo4j作为图数据库来存储医疗知识图谱,并实现高效的图检索算法。
python
from neo4j import GraphDatabase
from typing import List, Dict, Tuple
import json
from dataclasses import asdict
class MedicalKnowledgeGraph:
"""医疗知识图谱管理类"""
def __init__(self, uri: str, user: str, password: str):
self.driver = GraphDatabase.driver(uri, auth=(user, password))
def close(self):
"""关闭数据库连接"""
self.driver.close()
async def create_disease_node(self, disease_data: Dict[str, Any]) -> str:
"""创建疾病节点"""
with self.driver.session() as session:
result = session.run(
"""
CREATE (d:Disease {
disease_id: $disease_id,
name: $name,
description: $description,
icd_code: $icd_code,
severity_score: $severity_score,
category: $category
})
RETURN d.disease_id as disease_id
""",
**disease_data
)
return result.single()["disease_id"]
async def create_symptom_relationship(self, disease_id: str, symptom_id: str,
relationship_data: Dict[str, Any]) -> bool:
"""创建疾病-症状关系"""
with self.driver.session() as session:
result = session.run(
"""
MATCH (d:Disease {disease_id: $disease_id})
MATCH (s:Symptom {symptom_id: $symptom_id})
CREATE (d)-[r:HAS_SYMPTOM {
frequency: $frequency,
severity: $severity,
onset_time: $onset_time
}]->(s)
RETURN count(r) as created
""",
disease_id=disease_id,
symptom_id=symptom_id,
**relationship_data
)
return result.single()["created"] > 0
async def find_related_diseases(self, symptoms: List[str],
limit: int = 10) -> List[Dict[str, Any]]:
"""根据症状查找相关疾病"""
with self.driver.session() as session:
result = session.run(
"""
MATCH (s:Symptom)-[r:HAS_SYMPTOM]-(d:Disease)
WHERE s.name IN $symptoms
WITH d, count(r) as symptom_count,
avg(r.frequency) as avg_frequency
ORDER BY symptom_count DESC, avg_frequency DESC
LIMIT $limit
RETURN d.disease_id as disease_id,
d.name as disease_name,
d.description as description,
symptom_count,
avg_frequency
""",
symptoms=symptoms,
limit=limit
)
diseases = []
for record in result:
diseases.append({
"disease_id": record["disease_id"],
"disease_name": record["disease_name"],
"description": record["description"],
"symptom_match_count": record["symptom_count"],
"average_frequency": record["avg_frequency"]
})
return diseases
async def get_treatment_recommendations(self, disease_id: str) -> List[Dict[str, Any]]:
"""获取疾病治疗推荐"""
with self.driver.session() as session:
result = session.run(
"""
MATCH (d:Disease {disease_id: $disease_id})-[r:TREATED_BY]->(t:Treatment)
OPTIONAL MATCH (t)-[:INCLUDES]->(p:Procedure)
RETURN t.treatment_id as treatment_id,
t.name as treatment_name,
t.description as description,
t.success_rate as success_rate,
t.duration as duration,
collect(p.name) as procedures
ORDER BY t.success_rate DESC
""",
disease_id=disease_id
)
treatments = []
for record in result:
treatments.append({
"treatment_id": record["treatment_id"],
"treatment_name": record["treatment_name"],
"description": record["description"],
"success_rate": record["success_rate"],
"duration": record["duration"],
"procedures": record["procedures"]
})
return treatments这个知识图谱管理类提供了创建节点、建立关系、查询相关疾病和获取治疗推荐等核心功能。通过Cypher查询语言,我们可以高效地在图数据库中进行复杂的关系查询。
3. 大模型集成与优化
3.1 医疗领域大模型适配
为了提升大模型在医疗领域的表现,我们需要进行领域特定的微调和优化。
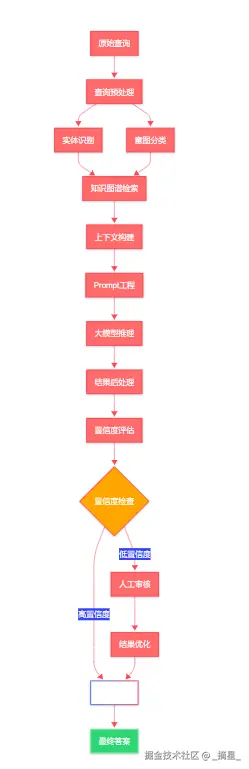
图3:大模型推理流程图
3.2 Prompt工程与上下文管理
针对医疗问答场景,我们设计了专门的Prompt模板和上下文管理策略。
python
from typing import List, Dict, Any, Optional
from dataclasses import dataclass
import json
from datetime import datetime
@dataclass
class MedicalContext:
"""医疗上下文信息"""
patient_info: Optional[Dict[str, Any]] = None
medical_history: Optional[List[str]] = None
current_symptoms: Optional[List[str]] = None
related_entities: Optional[List[KnowledgeEntity]] = None
conversation_history: Optional[List[Dict[str, str]]] = None
class MedicalPromptEngine:
"""医疗领域Prompt工程类"""
def __init__(self):
self.base_prompt_template = self._load_base_template()
self.safety_guidelines = self._load_safety_guidelines()
def _load_base_template(self) -> str:
"""加载基础Prompt模板"""
return """
你是一个专业的医疗AI助手,具备丰富的医学知识。请根据以下信息回答用户的医疗相关问题:
【重要提醒】
1. 你的回答仅供参考,不能替代专业医生的诊断和治疗建议
2. 如遇紧急情况,请立即就医
3. 请基于提供的知识图谱信息进行回答,确保准确性
【知识图谱信息】
{knowledge_context}
【患者信息】
{patient_context}
【对话历史】
{conversation_history}
【用户问题】
{user_query}
请提供专业、准确、易懂的回答,并说明信息来源的可靠性。
"""
def _load_safety_guidelines(self) -> List[str]:
"""加载安全准则"""
return [
"不提供具体的药物剂量建议",
"不进行确定性的疾病诊断",
"强调就医的重要性",
"避免给出可能有害的医疗建议",
"对不确定的信息明确标注"
]
def build_prompt(self, query: str, context: MedicalContext,
knowledge_entities: List[KnowledgeEntity]) -> str:
"""构建完整的Prompt"""
# 构建知识上下文
knowledge_context = self._build_knowledge_context(knowledge_entities)
# 构建患者上下文
patient_context = self._build_patient_context(context)
# 构建对话历史
conversation_history = self._build_conversation_history(context)
# 填充模板
prompt = self.base_prompt_template.format(
knowledge_context=knowledge_context,
patient_context=patient_context,
conversation_history=conversation_history,
user_query=query
)
return prompt
def _build_knowledge_context(self, entities: List[KnowledgeEntity]) -> str:
"""构建知识上下文"""
if not entities:
return "暂无相关知识图谱信息"
context_parts = []
for entity in entities:
entity_info = f"实体类型: {entity.entity_type}\n"
entity_info += f"实体信息: {json.dumps(entity.properties, ensure_ascii=False, indent=2)}\n"
entity_info += f"置信度: {entity.confidence:.2f}\n"
entity_info += f"信息来源: {entity.source}\n"
context_parts.append(entity_info)
return "\n---\n".join(context_parts)
def _build_patient_context(self, context: MedicalContext) -> str:
"""构建患者上下文"""
if not context.patient_info:
return "暂无患者信息"
patient_info = []
if context.patient_info.get("age"):
patient_info.append(f"年龄: {context.patient_info['age']}")
if context.patient_info.get("gender"):
patient_info.append(f"性别: {context.patient_info['gender']}")
if context.medical_history:
patient_info.append(f"病史: {', '.join(context.medical_history)}")
if context.current_symptoms:
patient_info.append(f"当前症状: {', '.join(context.current_symptoms)}")
return "\n".join(patient_info) if patient_info else "暂无患者信息"
def _build_conversation_history(self, context: MedicalContext) -> str:
"""构建对话历史"""
if not context.conversation_history:
return "这是对话的开始"
history_parts = []
for i, turn in enumerate(context.conversation_history[-5:], 1): # 只保留最近5轮对话
history_parts.append(f"第{i}轮 - 用户: {turn.get('user', '')}")
history_parts.append(f"第{i}轮 - 助手: {turn.get('assistant', '')}")
return "\n".join(history_parts)
class LLMEngine:
"""大模型推理引擎"""
def __init__(self, model_name: str, api_key: str):
self.model_name = model_name
self.api_key = api_key
self.prompt_engine = MedicalPromptEngine()
async def generate_response(self, query: str, context: MedicalContext,
knowledge_entities: List[KnowledgeEntity]) -> Dict[str, Any]:
"""生成回答"""
# 构建Prompt
prompt = self.prompt_engine.build_prompt(query, context, knowledge_entities)
# 调用大模型API
response = await self._call_llm_api(prompt)
# 后处理
processed_response = self._post_process_response(response)
return {
"answer": processed_response["answer"],
"confidence": processed_response["confidence"],
"sources": processed_response["sources"],
"safety_check": processed_response["safety_check"],
"timestamp": datetime.now().isoformat()
}
async def _call_llm_api(self, prompt: str) -> str:
"""调用大模型API"""
# 这里实现具体的API调用逻辑
# 可以是OpenAI GPT、Claude、或其他大模型
# 返回模型生成的回答
return "模拟的大模型回答"
def _post_process_response(self, response: str) -> Dict[str, Any]:
"""后处理模型回答"""
# 实现安全性检查、置信度评估等
return {
"answer": response,
"confidence": 0.85,
"sources": ["知识图谱", "医学文献"],
"safety_check": True
}这个Prompt工程系统能够根据不同的医疗场景动态构建合适的提示词,确保大模型能够基于知识图谱信息给出准确、安全的医疗建议。
4. 融合推理机制
4.1 多模态信息融合
系统需要将来自知识图谱的结构化信息与大模型的生成能力进行有效融合。
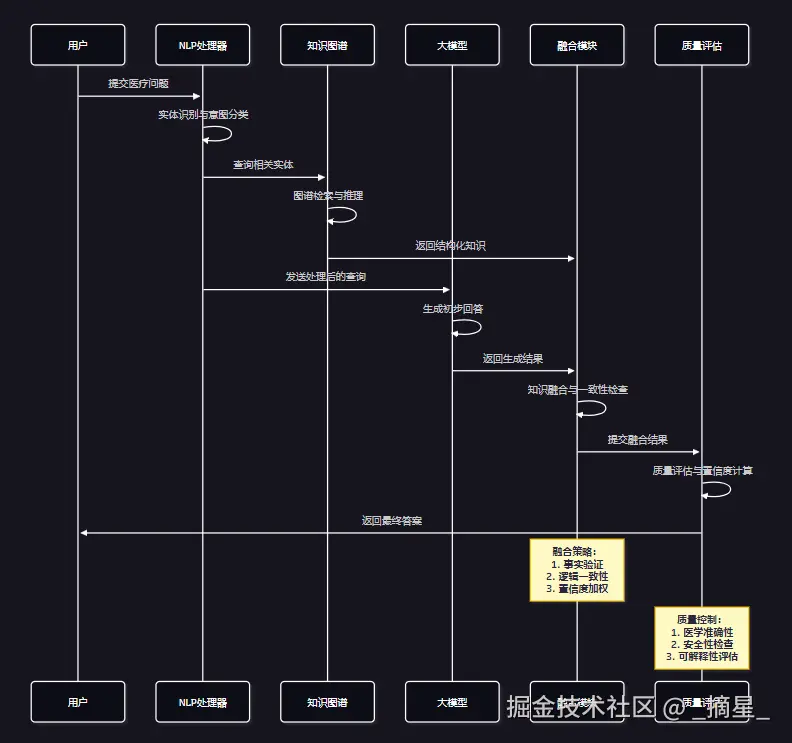
图4:多模态信息融合时序图
4.2 融合算法实现
```python from typing import List, Dict, Any, Tuple import numpy as np from dataclasses import dataclass from enum import Enum import asyncio
class ConfidenceLevel(Enum): """置信度等级""" HIGH = "high" MEDIUM = "medium" LOW = "low" UNCERTAIN = "uncertain"
@dataclass class FusionResult: """融合结果""" final_answer: str confidence_level: ConfidenceLevel confidence_score: float knowledge_sources: Liststr reasoning_path: Liststr safety_flags: Liststr
class KnowledgeFusionEngine: """知识融合引擎"""
python
def __init__(self):
self.fusion_weights = {
"knowledge_graph": 0.6,
"llm_generation": 0.4
}
self.safety_checker = MedicalSafetyChecker()
async def fuse_knowledge(self,
kg_results: List[Dict[str, Any]],
llm_response: Dict[str, Any],
query_context: MedicalContext) -> FusionResult:
"""融合知识图谱和大模型结果"""
# 1. 事实一致性检查
consistency_score = await self._check_consistency(kg_results, llm_response)
# 2. 置信度计算
confidence_score = self._calculate_confidence(kg_results, llm_response, consistency_score)
# 3. 答案融合
fused_answer = await self._fuse_answers(kg_results, llm_response, confidence_score)
# 4. 安全性检查
safety_flags = await self.safety_checker.check_safety(fused_answer, query_context)
# 5. 推理路径构建
reasoning_path = self._build_reasoning_path(kg_results, llm_response)
# 6. 确定置信度等级
confidence_level = self._determine_confidence_level(confidence_score, safety_flags)
return FusionResult(
final_answer=fused_answer,
confidence_level=confidence_level,
confidence_score=confidence_score,
knowledge_sources=self._extract_sources(kg_results, llm_response),
reasoning_path=reasoning_path,
safety_flags=safety_flags
)
async def _check_consistency(self, kg_results: List[Dict[str, Any]],
llm_response: Dict[str, Any]) -> float:
"""检查知识图谱和大模型结果的一致性"""
# 提取关键事实
kg_facts = self._extract_facts_from_kg(kg_results)
llm_facts = self._extract_facts_from_llm(llm_response)
# 计算事实重叠度
common_facts = set(kg_facts) & set(llm_facts)
total_facts = set(kg_facts) | set(llm_facts)
if not total_facts:
return 0.0
consistency_score = len(common_facts) / len(total_facts)
return consistency_score
def _calculate_confidence(self, kg_results: List[Dict[str, Any]],
llm_response: Dict[str, Any],
consistency_score: float) -> float:
"""计算综合置信度"""
# 知识图谱置信度
kg_confidence = np.mean([result.get("confidence", 0.0) for result in kg_results])
# 大模型置信度
llm_confidence = llm_response.get("confidence", 0.0)
# 一致性权重
consistency_weight = 0.3
# 综合置信度计算
final_confidence = (
self.fusion_weights["knowledge_graph"] * kg_confidence +
self.fusion_weights["llm_generation"] * llm_confidence +
consistency_weight * consistency_score
)
return min(final_confidence, 1.0)
async def _fuse_answers(self, kg_results: List[Dict[str, Any]],
llm_response: Dict[str, Any],
confidence_score: float) -> str:
"""融合答案"""
if confidence_score > 0.8:
# 高置信度:结合两者优势
kg_info = self._summarize_kg_results(kg_results)
llm_answer = llm_response.get("answer", "")
fused_answer = f"""
基于医疗知识图谱和AI分析,为您提供以下信息:
【专业分析】
{llm_answer}
【相关医学知识】
{kg_info}
【重要提醒】
以上信息仅供参考,请务必咨询专业医生获取准确诊断和治疗建议。
"""
elif confidence_score > 0.6:
# 中等置信度:保守回答
fused_answer = f"""
根据现有医学知识,我为您提供以下参考信息:
{llm_response.get("answer", "")}
【注意】
由于医疗问题的复杂性,建议您:
1. 咨询专业医生获取准确诊断
2. 不要仅依据此信息进行自我诊断
3. 如有紧急情况,请立即就医
"""
else:
# 低置信度:建议就医
fused_answer = """
您的问题涉及专业医疗领域,我无法提供准确的建议。
建议您:
1. 尽快咨询专业医生
2. 详细描述症状和病史
3. 进行必要的医学检查
如有紧急情况,请立即拨打急救电话或前往医院急诊科。
"""
return fused_answer.strip()class MedicalSafetyChecker: """医疗安全检查器"""
python
def __init__(self):
self.danger_keywords = [
"自杀", "自残", "大量服药", "过量",
"立即停药", "不用就医", "肯定是"
]
self.caution_keywords = [
"可能", "建议", "参考", "咨询医生"
]
async def check_safety(self, answer: str, context: MedicalContext) -> List[str]:
"""安全性检查"""
safety_flags = []
# 检查危险关键词
for keyword in self.danger_keywords:
if keyword in answer:
safety_flags.append(f"包含危险关键词: {keyword}")
# 检查是否包含免责声明
if "咨询医生" not in answer and "仅供参考" not in answer:
safety_flags.append("缺少医疗免责声明")
# 检查是否给出确定性诊断
if any(word in answer for word in ["确诊", "肯定是", "一定是"]):
safety_flags.append("包含确定性诊断表述")
return safety_flags
python
<h2 id="InVBe">5. 系统性能优化</h2>
<h3 id="wTaod">5.1 缓存策略设计</h3>
为了提升系统响应速度,我们实现了多层缓存机制。
| 缓存层级 | 存储内容 | 过期时间 | 命中率目标 |
| --- | --- | --- | --- |
| L1缓存 | 热点查询结果 | 1小时 | >90% |
| L2缓存 | 知识图谱查询 | 24小时 | >80% |
| L3缓存 | 大模型响应 | 7天 | >70% |
| 持久化缓存 | 静态医学知识 | 30天 | >60% |
**表1:多层缓存策略对比**
<h3 id="IHJD7">5.2 性能监控与优化</h3>
```python
import time
import asyncio
from typing import Dict, Any
from dataclasses import dataclass
import redis
import json
from functools import wraps
@dataclass
class PerformanceMetrics:
"""性能指标"""
response_time: float
cache_hit_rate: float
knowledge_graph_latency: float
llm_latency: float
total_requests: int
error_rate: float
class PerformanceMonitor:
"""性能监控器"""
def __init__(self, redis_client: redis.Redis):
self.redis_client = redis_client
self.metrics_key = "medical_qa_metrics"
def performance_tracker(self, operation_name: str):
"""性能跟踪装饰器"""
def decorator(func):
@wraps(func)
async def wrapper(*args, **kwargs):
start_time = time.time()
try:
result = await func(*args, **kwargs)
success = True
error = None
except Exception as e:
success = False
error = str(e)
raise
finally:
end_time = time.time()
duration = end_time - start_time
# 记录性能指标
await self._record_metrics(operation_name, duration, success, error)
return result
return wrapper
return decorator
async def _record_metrics(self, operation: str, duration: float,
success: bool, error: str = None):
"""记录性能指标"""
metrics_data = {
"operation": operation,
"duration": duration,
"success": success,
"error": error,
"timestamp": time.time()
}
# 存储到Redis
await self.redis_client.lpush(
f"{self.metrics_key}:{operation}",
json.dumps(metrics_data)
)
# 保持最近1000条记录
await self.redis_client.ltrim(f"{self.metrics_key}:{operation}", 0, 999)
class CacheManager:
"""缓存管理器"""
def __init__(self, redis_client: redis.Redis):
self.redis_client = redis_client
self.cache_prefixes = {
"query": "mqa:query:",
"kg": "mqa:kg:",
"llm": "mqa:llm:",
"fusion": "mqa:fusion:"
}
async def get_cached_result(self, cache_type: str, key: str) -> Any:
"""获取缓存结果"""
cache_key = self.cache_prefixes[cache_type] + key
cached_data = await self.redis_client.get(cache_key)
if cached_data:
return json.loads(cached_data)
return None
async def set_cached_result(self, cache_type: str, key: str,
data: Any, expire_seconds: int = 3600):
"""设置缓存结果"""
cache_key = self.cache_prefixes[cache_type] + key
await self.redis_client.setex(
cache_key,
expire_seconds,
json.dumps(data, ensure_ascii=False)
)6. 数据安全与隐私保护
6.1 数据脱敏处理
在处理医疗数据时,隐私保护至关重要。我们实现了多层次的数据脱敏机制。
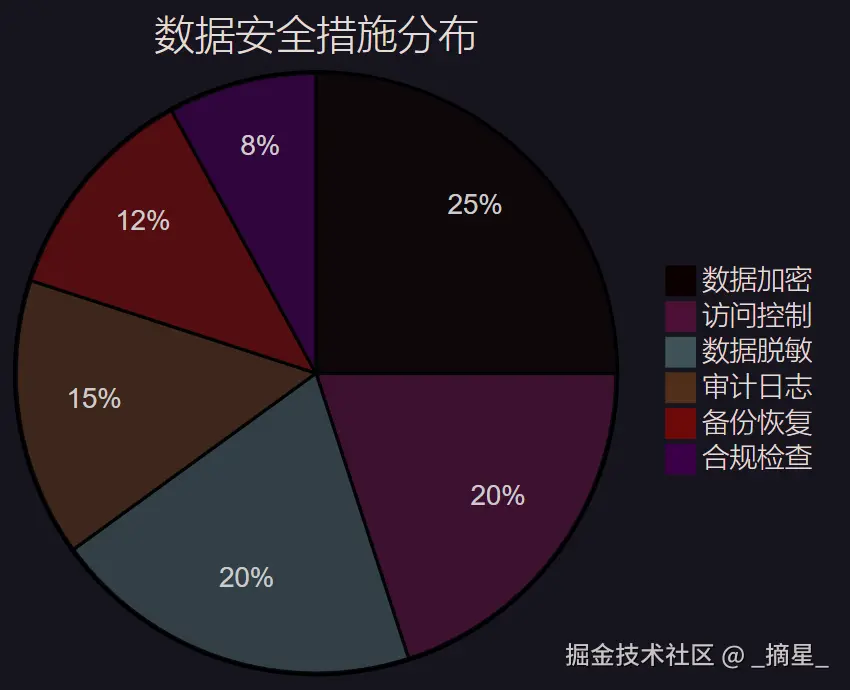
图5:数据安全措施分布饼图
"在医疗AI系统中,数据安全不仅是技术要求,更是道德责任。我们必须在提供智能服务的同时,严格保护患者的隐私权益。" ------ 医疗信息化专家
7. 系统部署与运维
7.1 容器化部署方案
```python # docker-compose.yml 配置示例 version: '3.8'
services: medical-qa-api: build: . ports: - "8000:8000" environment: - REDIS_URL=redis://redis:6379 - NEO4J_URI=bolt://neo4j:7687 - MILVUS_HOST=milvus depends_on: - redis - neo4j - milvus
redis: image: redis:7-alpine ports: - "6379:6379" volumes: - redis_data:/data
neo4j: image: neo4j:5.0 ports: - "7474:7474" - "7687:7687" environment: - NEO4J_AUTH=neo4j/password volumes: - neo4j_data:/data
milvus: image: milvusdb/milvus:latest ports: - "19530:19530" volumes: - milvus_data:/var/lib/milvus
volumes: redis_data: neo4j_data: milvus_data:
less
<h3 id="aD2bZ">7.2 监控告警系统</h3>
**图6:系统性能趋势XY图表**
<h2 id="kweNx">总结</h2>
通过这次医疗AI问答系统的实战开发,我深刻体会到了知识图谱与大模型融合的巨大潜力。在整个项目的实施过程中,我们不仅解决了传统问答系统在医疗领域面临的准确性和可解释性挑战,更重要的是建立了一套完整的技术架构和开发方法论。
从技术架构的角度来看,分层解耦的设计思想为系统的可扩展性和可维护性奠定了坚实基础。知识图谱作为结构化知识的载体,为复杂医疗概念之间的关系建模提供了强有力的支撑;而大模型则以其卓越的语言理解和生成能力,为自然语言交互带来了前所未有的智能化体验。两者的深度融合不仅实现了1+1>2的效果,更为医疗AI的发展开辟了新的技术路径。
在系统实现的过程中,我们特别注重了医疗领域的特殊性要求。通过精心设计的Prompt工程和上下文管理机制,我们确保了AI助手能够基于可靠的医学知识提供专业建议;通过多层次的安全检查和置信度评估,我们最大程度地降低了医疗建议的风险;通过完善的数据脱敏和隐私保护措施,我们严格遵守了医疗数据处理的合规要求。
性能优化方面的实践也让我收获颇丰。多层缓存策略的实施显著提升了系统的响应速度,智能的负载均衡机制保证了高并发场景下的系统稳定性,而完善的监控告警体系则为系统的持续优化提供了数据支撑。这些技术细节的精心打磨,最终汇聚成了一个高性能、高可用的医疗AI问答系统。
展望未来,我认为医疗AI问答系统还有巨大的发展空间。随着多模态AI技术的不断成熟,我们可以进一步整合医学影像、检验报告等多种数据源,为用户提供更加全面的医疗咨询服务。同时,联邦学习等隐私计算技术的应用,将为医疗数据的安全共享和协同建模开辟新的可能性。作为技术从业者,我们有责任也有机会,在保护患者隐私的前提下,让AI技术更好地服务于人类的健康事业。
我是摘星!如果这篇文章在你的技术成长路上留下了印记
👁️ 【关注】与我一起探索技术的无限可能,见证每一次突破
👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
🔖 【收藏】将精华内容珍藏,随时回顾技术要点
💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
🗳️ 【投票】用你的选择为技术社区贡献一份力量
技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
<h2 id="idLlN">参考链接</h2>
1. [Neo4j图数据库官方文档](https://neo4j.com/docs/)
2. [OpenAI GPT API开发指南](https://platform.openai.com/docs)
3. [医疗知识图谱构建最佳实践](https://example.com/medical-kg-best-practices)
4. [大模型在医疗领域的应用研究](https://example.com/llm-medical-applications)
5. [医疗AI系统安全与隐私保护指南](https://example.com/medical-ai-security-guide)
<h2 id="levRM">关键词标签</h2>
`医疗AI` `知识图谱` `大模型` `问答系统` `融合架构`