笔记本5070 8G,python3.10,新建虚拟环境就不说了,pytorch2.9.1是我自己提前装的,因为它给的2.3.1不支持50系显卡。我用的WSL。
requirements.txt中需要做一些修改
bash
--extra-index-url https://download.pytorch.org/whl/cu121
改成
--extra-index-url https://download.pytorch.org/whl/cu128
torch==2.3.1
torchaudio==2.3.1
改成
torch==2.9.1+cu128
torchaudio==2.9.1+cu128
我以前都是把requirements.txt中torch相关的删掉,提前手动用whl安装,以前这样没遇到问题。这次发现即便提前安装了GPU版pytorch,但是安装conformer==0.3.2时会下载cpu版的pytorch,所以这次不删了,改成指定安装GPU版,这样的话如果提前有安装,也会跳过。
上面的改动,根据你的CUDA版本来
openai-whisper==20231117
改成
openai-whisper
否则报错
ERROR: Cannot install -r requirements.txt (line 24) and -r requirements.txt (line 35) because these package versions have conflicting dependencies.
The conflict is caused by:
torch 2.9.1+cu128 depends on triton==3.5.1; platform_system == "Linux"
openai-whisper 20231117 depends on triton<3 and >=2.0.0
Additionally, some packages in these conflicts have no matching distributions available for your environment:
triton
To fix this you could try to:
1. loosen the range of package versions you've specified
2. remove package versions to allow pip to attempt to solve the dependency conflict
ERROR: ResolutionImpossible: for help visit https://pip.pypa.io/en/latest/topics/dependency-resolution/#dealing-with-dependency-conflicts我是用git从魔搭下载模型,下载前需要安装git lfs
bash
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
cd CosyVoice
git lfs installOptionally, you can unzip
ttsfrdresource and installttsfrdpackage for better text normalization performance.Notice that this step is not necessary. If you do not install
ttsfrdpackage, we will use wetext by default.
bash
cd pretrained_models/CosyVoice-ttsfrd/
unzip resource.zip -d .
pip install ttsfrd_dependency-0.1-py3-none-any.whl
pip install ttsfrd-0.4.2-cp310-cp310-linux_x86_64.whl启动webui,CUDA报错
bash
python3 webui.py --port 9999 --model_dir pretrained_models/CosyVoice-300M
[2025-11-27 20:14:23,568] [INFO] [real_accelerator.py:203:get_accelerator] Setting ds_accelerator to cuda (auto detect)
df: /home/abc/.triton/autotune: No such file or directory
Traceback (most recent call last):
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/transformers/utils/import_utils.py", line 1967, in _get_module
return importlib.import_module("." + module_name, self.__name__)
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1050, in _gcd_import
File "<frozen importlib._bootstrap>", line 1027, in _find_and_load
File "<frozen importlib._bootstrap>", line 1006, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 688, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 883, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/transformers/modeling_utils.py", line 158, in <module>
import deepspeed
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/deepspeed/__init__.py", line 25, in <module>
from . import ops
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/deepspeed/ops/__init__.py", line 15, in <module>
from ..git_version_info import compatible_ops as __compatible_ops__
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/deepspeed/git_version_info.py", line 29, in <module>
op_compatible = builder.is_compatible()
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/deepspeed/ops/op_builder/fp_quantizer.py", line 35, in is_compatible
sys_cuda_major, _ = installed_cuda_version()
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/deepspeed/ops/op_builder/builder.py", line 51, in installed_cuda_version
raise MissingCUDAException("CUDA_HOME does not exist, unable to compile CUDA op(s)")
deepspeed.ops.op_builder.builder.MissingCUDAException: CUDA_HOME does not exist, unable to compile CUDA op(s)
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/abc/CosyVoice/webui.py", line 25, in <module>
from cosyvoice.cli.cosyvoice import CosyVoice, CosyVoice2
File "/home/abc/CosyVoice/cosyvoice/cli/cosyvoice.py", line 19, in <module>
from modelscope import snapshot_download
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/modelscope/__init__.py", line 115, in <module>
fix_transformers_upgrade()
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/modelscope/utils/automodel_utils.py", line 45, in fix_transformers_upgrade
from transformers import PreTrainedModel
File "<frozen importlib._bootstrap>", line 1075, in _handle_fromlist
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/transformers/utils/import_utils.py", line 1955, in __getattr__
module = self._get_module(self._class_to_module[name])
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/transformers/utils/import_utils.py", line 1969, in _get_module
raise RuntimeError(
RuntimeError: Failed to import transformers.modeling_utils because of the following error (look up to see its traceback):
CUDA_HOME does not exist, unable to compile CUDA op(s)DeepSpeed需要直接访问CUDA工具包路径来进行自定义CUDA操作的编译,而它找不到CUDA_HOME环境变量。which nvcc或ls -la /usr/local | grep cuda,会没输出。
bash
# 添加NVIDIA仓库
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
rm cuda-keyring_1.1-1_all.deb
# 安装CUDA工具包(选择与PyTorch兼容的版本,这里是12.8)
sudo apt-get update
sudo apt-get install -y cuda-toolkit-12-8
# 安装完成后,将CUDA添加到环境变量
echo 'export PATH=/usr/local/cuda-12.8/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-12.8/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
echo 'export CUDA_HOME=/usr/local/cuda-12.8' >> ~/.bashrc
source ~/.bashrc
# 验证安装
nvcc --version再启动,报错
bash
2025-11-28 17:01:47.570007787 [E:onnxruntime:Default, provider_bridge_ort.cc:1744 TryGetProviderInfo_CUDA] /onnxruntime_src/onnxruntime/core/session/provider_bridge_ort.cc:1426 onnxruntime::Provider& onnxruntime::ProviderLibrary::Get() [ONNXRuntimeError] : 1 : FAIL : Failed to load library libonnxruntime_providers_cuda.so with error: libcudnn.so.8: cannot open shared object file: No such file or directory
2025-11-28 17:01:47.570079156 [W:onnxruntime:Default, onnxruntime_pybind_state.cc:870 CreateExecutionProviderInstance] Failed to create CUDAExecutionProvider. Please reference https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirementsto ensure all dependencies are met.
text.cc: festival_Text_init
open voice lang map failed这是ONNX Runtime尝试使用CUDA执行提供程序,但找不到libcudnn.so.8文件,缺少cuDNN
bash
# 安装cuDNN 8.x(与CUDA 12.x兼容的版本),这里我报错了
sudo apt-get install -y libcudnn8=8.9.7.29 libcudnn8-dev=8.9.7.29
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
Package libcudnn8 is not available, but is referred to by another package.
This may mean that the package is missing, has been obsoleted, or
is only available from another source
Package libcudnn8-dev is not available, but is referred to by another package.
This may mean that the package is missing, has been obsoleted, or
is only available from another source
E: Version '8.9.7.29' for 'libcudnn8' was not found
E: Version '8.9.7.29' for 'libcudnn8-dev' was not found
那就换个写法
sudo apt-get install -y libcudnn8 libcudnn8-dev
# 验证安装
ls -la /usr/lib/x86_64-linux-gnu/libcudnn*
# 添加到~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/lib/x86_64-linux-gnu:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
# 检查是否能加载库,我这没输出,说明系统动态链接器没有缓存cuDNN库,需要更新动态链接器缓存才会有输出(在后面)
ldconfig -p | grep libcudnn
# 检查cuDNN版本
cat /usr/include/x86_64-linux-gnu/cudnn_version.h | grep CUDNN_MAJOR -A 2
如果上一行报错,执行下面的
# 查找正确的头文件位置
sudo find /usr -name "cudnn_version.h" 2>/dev/null
# 假设找到在 /usr/include/cudnn_version.h,创建符号链接
sudo mkdir -p /usr/include/x86_64-linux-gnu
sudo ln -s /usr/include/cudnn_version.h /usr/include/x86_64-linux-gnu/cudnn_version.h
# 下面的内容可选
# 创建符号链接(如果需要),我没执行
sudo ln -s /usr/lib/x86_64-linux-gnu/libcudnn.so.8 /usr/local/cuda/lib64/libcudnn.so.8
# 更新动态链接器缓存
sudo ldconfig前面的text.cc: festival_Text_init,open voice lang map failed报错,可以忽略,在issues中看的。
再次启动,成功
bash
[2025-11-29 11:02:41,133] [INFO] [real_accelerator.py:203:get_accelerator] Setting ds_accelerator to cuda (auto detect)
/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/lightning/fabric/__init__.py:41: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81.
/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/diffusers/models/lora.py:393: FutureWarning: `LoRACompatibleLinear` is deprecated and will be removed in version 1.0.0. Use of `LoRACompatibleLinear` is deprecated. Please switch to PEFT backend by installing PEFT: `pip install peft`.
deprecate("LoRACompatibleLinear", "1.0.0", deprecation_message)
2025-11-29 11:02:46,614 INFO input frame rate=50
2025-11-29 11:02:48.698204212 [W:onnxruntime:, transformer_memcpy.cc:74 ApplyImpl] 12 Memcpy nodes are added to the graph main_graph for CUDAExecutionProvider. It might have negative impact on performance (including unable to run CUDA graph). Set session_options.log_severity_level=1 to see the detail logs before this message.
2025-11-29 11:02:48.699382186 [W:onnxruntime:, session_state.cc:1166 VerifyEachNodeIsAssignedToAnEp] Some nodes were not assigned to the preferred execution providers which may or may not have an negative impact on performance. e.g. ORT explicitly assigns shape related ops to CPU to improve perf.
2025-11-29 11:02:48.699394617 [W:onnxruntime:, session_state.cc:1168 VerifyEachNodeIsAssignedToAnEp] Rerunning with verbose output on a non-minimal build will show node assignments.
text.cc: festival_Text_init
open voice lang map failed
2025-11-29 11:02:53,234 DEBUG Using selector: EpollSelector
2025-11-29 11:02:53,243 DEBUG Starting new HTTPS connection (1): huggingface.co:443
2025-11-29 11:02:53,258 DEBUG connect_tcp.started host='api.gradio.app' port=443 local_address=None timeout=3 socket_options=None
/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/components/base.py:201: UserWarning: 'scale' value should be an integer. Using 0.5 will cause issues.
warnings.warn(
/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/components/base.py:201: UserWarning: 'scale' value should be an integer. Using 0.25 will cause issues.
warnings.warn(
/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/layouts/column.py:55: UserWarning: 'scale' value should be an integer. Using 0.25 will cause issues.
warnings.warn(
2025-11-29 11:02:53,500 DEBUG connect_tcp.complete return_value=<httpcore._backends.sync.SyncStream object at 0x7778391349d0>
2025-11-29 11:02:53,501 DEBUG start_tls.started ssl_context=<ssl.SSLContext object at 0x7778391203c0> server_hostname='api.gradio.app' timeout=3
2025-11-29 11:02:53,532 DEBUG Using selector: EpollSelector
* Running on local URL: http://0.0.0.0:9999
2025-11-29 11:02:53,561 DEBUG connect_tcp.started host='localhost' port=9999 local_address=None timeout=None socket_options=None
2025-11-29 11:02:53,563 DEBUG connect_tcp.complete return_value=<httpcore._backends.sync.SyncStream object at 0x7778198405b0>
2025-11-29 11:02:53,563 DEBUG send_request_headers.started request=<Request [b'GET']>
2025-11-29 11:02:53,563 DEBUG send_request_headers.complete
2025-11-29 11:02:53,563 DEBUG send_request_body.started request=<Request [b'GET']>
2025-11-29 11:02:53,563 DEBUG send_request_body.complete
2025-11-29 11:02:53,563 DEBUG receive_response_headers.started request=<Request [b'GET']>
2025-11-29 11:02:53,565 DEBUG receive_response_headers.complete return_value=(b'HTTP/1.1', 200, b'OK', [(b'date', b'Sat, 29 Nov 2025 03:02:53 GMT'), (b'server', b'uvicorn'), (b'content-length', b'4'), (b'content-type', b'application/json')])
2025-11-29 11:02:53,566 INFO HTTP Request: GET http://localhost:9999/gradio_api/startup-events "HTTP/1.1 200 OK"
2025-11-29 11:02:53,566 DEBUG receive_response_body.started request=<Request [b'GET']>
2025-11-29 11:02:53,566 DEBUG receive_response_body.complete
2025-11-29 11:02:53,566 DEBUG response_closed.started
2025-11-29 11:02:53,566 DEBUG response_closed.complete
2025-11-29 11:02:53,566 DEBUG close.started
2025-11-29 11:02:53,566 DEBUG close.complete
2025-11-29 11:02:53,567 DEBUG connect_tcp.started host='localhost' port=9999 local_address=None timeout=3 socket_options=None
2025-11-29 11:02:53,568 DEBUG connect_tcp.complete return_value=<httpcore._backends.sync.SyncStream object at 0x777819841ab0>
2025-11-29 11:02:53,568 DEBUG send_request_headers.started request=<Request [b'HEAD']>
2025-11-29 11:02:53,568 DEBUG send_request_headers.complete
2025-11-29 11:02:53,568 DEBUG send_request_body.started request=<Request [b'HEAD']>
2025-11-29 11:02:53,568 DEBUG send_request_body.complete
2025-11-29 11:02:53,568 DEBUG receive_response_headers.started request=<Request [b'HEAD']>
2025-11-29 11:02:53,584 DEBUG receive_response_headers.complete return_value=(b'HTTP/1.1', 200, b'OK', [(b'date', b'Sat, 29 Nov 2025 03:02:53 GMT'), (b'server', b'uvicorn'), (b'content-length', b'36958'), (b'content-type', b'text/html; charset=utf-8')])
2025-11-29 11:02:53,584 INFO HTTP Request: HEAD http://localhost:9999/ "HTTP/1.1 200 OK"
2025-11-29 11:02:53,584 DEBUG receive_response_body.started request=<Request [b'HEAD']>
2025-11-29 11:02:53,584 DEBUG receive_response_body.complete
2025-11-29 11:02:53,584 DEBUG response_closed.started
2025-11-29 11:02:53,584 DEBUG response_closed.complete
2025-11-29 11:02:53,584 DEBUG close.started
2025-11-29 11:02:53,584 DEBUG close.complete
To create a public link, set `share=True` in `launch()`.
2025-11-29 11:02:53,586 DEBUG Starting new HTTPS connection (1): huggingface.co:443
2025-11-29 11:02:53,910 DEBUG start_tls.complete return_value=<httpcore._backends.sync.SyncStream object at 0x7778391349a0>
2025-11-29 11:02:53,910 DEBUG send_request_headers.started request=<Request [b'GET']>
2025-11-29 11:02:53,911 DEBUG send_request_headers.complete
2025-11-29 11:02:53,911 DEBUG send_request_body.started request=<Request [b'GET']>
2025-11-29 11:02:53,911 DEBUG send_request_body.complete
2025-11-29 11:02:53,911 DEBUG receive_response_headers.started request=<Request [b'GET']>
2025-11-29 11:02:54,109 DEBUG receive_response_headers.complete return_value=(b'HTTP/1.1', 200, b'OK', [(b'Date', b'Sat, 29 Nov 2025 03:02:53 GMT'), (b'Content-Type', b'application/json'), (b'Content-Length', b'21'), (b'Connection', b'keep-alive'), (b'Server', b'nginx/1.18.0'), (b'Access-Control-Allow-Origin', b'*')])
2025-11-29 11:02:54,109 INFO HTTP Request: GET https://api.gradio.app/pkg-version "HTTP/1.1 200 OK"
2025-11-29 11:02:54,109 DEBUG receive_response_body.started request=<Request [b'GET']>
2025-11-29 11:02:54,110 DEBUG receive_response_body.complete
2025-11-29 11:02:54,110 DEBUG response_closed.started
2025-11-29 11:02:54,110 DEBUG response_closed.complete
2025-11-29 11:02:54,110 DEBUG close.started
2025-11-29 11:02:54,110 DEBUG close.complete浏览器访问127.0.0.1:9999
webui中"3s极速复刻"生成音频时报错
bash
Traceback (most recent call last):
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/queueing.py", line 624, in process_events
response = await route_utils.call_process_api(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/route_utils.py", line 323, in call_process_api
output = await app.get_blocks().process_api(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/blocks.py", line 2018, in process_api
result = await self.call_function(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/blocks.py", line 1579, in call_function
prediction = await utils.async_iteration(iterator)
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/utils.py", line 691, in async_iteration
return await anext(iterator)
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/utils.py", line 685, in __anext__
return await anyio.to_thread.run_sync(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/anyio/to_thread.py", line 56, in run_sync
return await get_async_backend().run_sync_in_worker_thread(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 2485, in run_sync_in_worker_thread
return await future
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 976, in run
result = context.run(func, *args)
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/utils.py", line 668, in run_sync_iterator_async
return next(iterator)
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/utils.py", line 829, in gen_wrapper
response = next(iterator)
File "/home/abc/CosyVoice/webui.py", line 96, in generate_audio
if torchaudio.info(prompt_wav).sample_rate < prompt_sr:
AttributeError: module 'torchaudio' has no attribute 'info'这个错误是因为在较新版本的torchaudio(2.9.1)中,torchaudio.info函数的API已经改变。在torchaudio 2.x版本中,获取音频文件信息的方式需要使用不同的方法。
将webui.py中大约96行的if torchaudio.info(prompt_wav).sample_rate < prompt_sr:改成
python
import soundfile as sf # 需要安装soundfile
# 尝试使用新API
if hasattr(torchaudio, 'info') and callable(torchaudio.info):
audio_info = torchaudio.info(prompt_wav, backend="soundfile")
sample_rate = audio_info.sample_rate
else:
# 回退到soundfile
audio_info = sf.info(prompt_wav)
sample_rate = audio_info.samplerate
if sample_rate < prompt_sr:再次尝试生成,报错
bash
Traceback (most recent call last):
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/torchaudio/_torchcodec.py", line 82, in load_with_torchcodec
from torchcodec.decoders import AudioDecoder
ModuleNotFoundError: No module named 'torchcodec'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/queueing.py", line 624, in process_events
response = await route_utils.call_process_api(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/route_utils.py", line 323, in call_process_api
output = await app.get_blocks().process_api(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/blocks.py", line 2018, in process_api
result = await self.call_function(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/blocks.py", line 1579, in call_function
prediction = await utils.async_iteration(iterator)
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/utils.py", line 691, in async_iteration
return await anext(iterator)
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/utils.py", line 685, in __anext__
return await anyio.to_thread.run_sync(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/anyio/to_thread.py", line 56, in run_sync
return await get_async_backend().run_sync_in_worker_thread(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 2485, in run_sync_in_worker_thread
return await future
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 976, in run
result = context.run(func, *args)
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/utils.py", line 668, in run_sync_iterator_async
return next(iterator)
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/utils.py", line 829, in gen_wrapper
response = next(iterator)
File "/home/abc/CosyVoice/webui.py", line 131, in generate_audio
prompt_speech_16k = postprocess(load_wav(prompt_wav, prompt_sr))
File "/home/abc/CosyVoice/cosyvoice/utils/file_utils.py", line 45, in load_wav
speech, sample_rate = torchaudio.load(wav, backend='soundfile')
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/torchaudio/__init__.py", line 86, in load
return load_with_torchcodec(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/torchaudio/_torchcodec.py", line 84, in load_with_torchcodec
raise ImportError(
ImportError: TorchCodec is required for load_with_torchcodec. Please install torchcodec to use this function.这个错误是因为在torchaudio 2.9.1中,指定backend='soundfile'参数时,内部尝试使用TorchCodec库,但该库未安装。在torchaudio 2.x版本中,音频后端架构发生了重大变化。
编辑文件 cosyvoice/utils/file_utils.py,定位到 load_wav 函数(大约45行),将其修改为以下兼容版本:
python
import soundfile as sf # 需安装soundfile
from typing import Tuple
def load_wav(wav: str, target_sr: int = None) -> Tuple[torch.Tensor, int]:
"""
兼容不同版本torchaudio的音频加载函数
Args:
wav: 音频文件路径
target_sr: 目标采样率,如果指定则重采样
Returns:
(音频张量, 采样率)
"""
try:
# 方法1:尝试使用torchaudio的标准load(不指定backend)
import torchaudio
# 检查torchaudio版本
from torchaudio import __version__ as ta_version
version_parts = [int(x) for x in ta_version.split('+')[0].split('.')]
if version_parts[0] >= 2:
# torchaudio 2.x+ 版本
speech, sample_rate = torchaudio.load(wav)
else:
# 旧版本
speech, sample_rate = torchaudio.load(wav, backend='soundfile')
# 重采样(如果需要)
if target_sr is not None and sample_rate != target_sr:
speech = resample_audio(speech, sample_rate, target_sr)
sample_rate = target_sr
return speech, sample_rate
except Exception as e:
print(f"torchaudio load failed: {e}")
# 方法2:回退到soundfile
return load_wav_with_soundfile(wav, target_sr)
def load_wav_with_soundfile(wav: str, target_sr: int = None) -> Tuple[torch.Tensor, int]:
"""使用soundfile加载音频的回退方法"""
try:
# 读取音频文件
data, sample_rate = sf.read(wav, dtype='float32')
# 转换为torch张量
if data.ndim == 1:
# 单声道:添加通道维度
speech = torch.tensor(data).float().unsqueeze(0)
elif data.ndim == 2:
# 立体声:转置为[通道, 样本]格式
speech = torch.tensor(data.T).float()
else:
raise ValueError(f"Unsupported audio dimension: {data.ndim}")
# 重采样(如果需要)
if target_sr is not None and sample_rate != target_sr:
speech = resample_audio(speech, sample_rate, target_sr)
sample_rate = target_sr
return speech, sample_rate
except Exception as e:
print(f"soundfile load failed: {e}")
raise RuntimeError(f"Failed to load audio file {wav}: {e}")
def resample_audio(waveform: torch.Tensor, orig_sr: int, new_sr: int) -> torch.Tensor:
"""重采样音频"""
try:
import torchaudio
resampler = torchaudio.transforms.Resample(orig_freq=orig_sr, new_freq=new_sr)
return resampler(waveform)
except Exception as e:
print(f"Resampling failed: {e}")
# 简单回退(不推荐用于生产)
ratio = new_sr / orig_sr
new_length = int(waveform.shape[-1] * ratio)
return torch.nn.functional.interpolate(
waveform.unsqueeze(0),
size=new_length,
mode='linear',
align_corners=False
).squeeze(0)如果嫌上面的修改太多,可以试一下简化版,我没用简化版
python
def load_wav(wav: str, target_sr: int = None) -> Tuple[torch.Tensor, int]:
"""使用soundfile加载音频,完全绕过torchaudio的兼容性问题"""
try:
# 读取音频
data, sample_rate = sf.read(wav, dtype='float32')
# 转换为torch张量 [通道, 样本]
if data.ndim == 1:
speech = torch.tensor(data).float().unsqueeze(0)
else:
speech = torch.tensor(data.T).float()
# 重采样(如果需要)
if target_sr is not None and sample_rate != target_sr:
import torchaudio
resampler = torchaudio.transforms.Resample(orig_freq=sample_rate, new_freq=target_sr)
speech = resampler(speech)
sample_rate = target_sr
return speech, sample_rate
except Exception as e:
raise RuntimeError(f"Failed to load audio {wav}: {e}")再次生成,报错
bash
Traceback (most recent call last):
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/queueing.py", line 624, in process_events
response = await route_utils.call_process_api(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/route_utils.py", line 323, in call_process_api
output = await app.get_blocks().process_api(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/blocks.py", line 2018, in process_api
result = await self.call_function(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/blocks.py", line 1579, in call_function
prediction = await utils.async_iteration(iterator)
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/utils.py", line 691, in async_iteration
return await anext(iterator)
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/utils.py", line 685, in __anext__
return await anyio.to_thread.run_sync(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/anyio/to_thread.py", line 56, in run_sync
return await get_async_backend().run_sync_in_worker_thread(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 2485, in run_sync_in_worker_thread
return await future
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 976, in run
result = context.run(func, *args)
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/utils.py", line 668, in run_sync_iterator_async
return next(iterator)
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/utils.py", line 829, in gen_wrapper
response = next(iterator)
File "/home/abc/CosyVoice/webui.py", line 131, in generate_audio
prompt_speech_16k = postprocess(load_wav(prompt_wav, prompt_sr))
File "/home/abc/CosyVoice/webui.py", line 48, in postprocess
speech, _ = librosa.effects.trim(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/librosa/effects.py", line 669, in trim
non_silent = _signal_to_frame_nonsilent(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/librosa/effects.py", line 598, in _signal_to_frame_nonsilent
mse = feature.rms(y=y, frame_length=frame_length, hop_length=hop_length)
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/librosa/feature/spectral.py", line 876, in rms
padding = [(0, 0) for _ in range(y.ndim)]
AttributeError: 'tuple' object has no attribute 'ndim'这个错误是因为 postprocess 函数接收到了元组而不是预期的音频数据。根本原因是 load_wav 函数返回了 (speech, sample_rate) 元组,但 postprocess 期望的是单一的音频张量/数组。此外,librosa 需要 numpy 数组(librosa 通常期望 samples (单声道) 或 channels, samples (多声道)),而我们提供的是 torch.Tensor。
修复 webui.py 中的 postprocess 调用
python
prompt_speech_16k = postprocess(load_wav(prompt_wav, prompt_sr))
改成
# 正确解包 load_wav 的返回值
speech_data, sr = load_wav(prompt_wav, prompt_sr)
prompt_speech_16k = postprocess(speech_data)
有两处postprocess调用需要改修改 postprocess 函数(webui.py 第48行附近),将 postprocess 函数修改为处理 torch.Tensor 并转换为 numpy 格式
python
# pip install librosa numpy
def postprocess(speech, top_db=60, hop_length=220, win_length=440):
"""
后处理音频数据,适配librosa要求
Args:
speech: torch.Tensor 或 numpy array,形状为 [channels, samples]
top_db: librosa trim的阈值
hop_length: librosa的hop长度
win_length: librosa的窗口长度
Returns:
处理后的torch.Tensor
"""
# 确保输入是torch.Tensor
if isinstance(speech, tuple):
speech = speech[0] # 处理意外传入元组的情况
# 转换为numpy数组 (librosa需要)
if torch.is_tensor(speech):
# 确保是CPU张量
if speech.device != torch.device('cpu'):
speech = speech.cpu()
# 转换为numpy
if speech.ndim == 1:
# 单声道
y = speech.numpy()
elif speech.ndim == 2:
# 多声道,取第一个声道
y = speech[0].numpy()
else:
raise ValueError(f"Unsupported speech dimension: {speech.ndim}")
else:
# 假设是numpy array
y = speech[0] if speech.ndim > 1 else speech
# 使用librosa进行trim
try:
from librosa.effects import trim
y_trimmed, _ = trim(
y=y,
top_db=top_db,
frame_length=win_length,
hop_length=hop_length
)
except Exception as e:
print(f"librosa trim failed: {e}")
print(f"Falling back to simple trimming. Input shape: {y.shape}")
# 简单回退:移除开头和结尾接近零的部分
threshold = np.max(np.abs(y)) * 0.01 # 1% of max amplitude
mask = np.abs(y) > threshold
if np.any(mask):
start = np.argmax(mask)
end = len(mask) - np.argmax(mask[::-1])
y_trimmed = y[start:end]
else:
y_trimmed = y
# 转回torch.Tensor
speech_trimmed = torch.tensor(y_trimmed, dtype=torch.float32)
# 确保形状为 [1, samples] (单声道)
if speech_trimmed.ndim == 1:
speech_trimmed = speech_trimmed.unsqueeze(0)
return speech_trimmed如果嫌上面的修改太多,可以试一下简化版,我没用简化版
python
def postprocess(speech, top_db=60, hop_length=220, win_length=440):
# 处理可能的元组输入
if isinstance(speech, tuple):
speech = speech[0]
# 确保是numpy数组
if torch.is_tensor(speech):
speech = speech.cpu().numpy()
# 确保是单声道
if speech.ndim > 1:
speech = speech[0] if speech.shape[0] == 1 else speech.mean(axis=0)
# 应用trim
from librosa.effects import trim
trimmed, _ = trim(
y=speech,
top_db=top_db,
frame_length=win_length,
hop_length=hop_length
)
# 转回tensor
return torch.tensor(trimmed).unsqueeze(0).float()再次生成,ffprobe报错
bash
2025-11-29 09:27:17,652 INFO synthesis text 我是通义实验室语音团队全新推出的生成式语音大模型,提供舒适自然的语音合成能力。
/home/abc/CosyVoice/cosyvoice/cli/model.py:104: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with self.llm_context, torch.cuda.amp.autocast(self.fp16 is True and hasattr(self.llm, 'vllm') is False):
/home/abc/CosyVoice/cosyvoice/cli/model.py:131: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(self.fp16):
2025-11-29 09:27:25,177 INFO yield speech len 6.350657596371882, rtf 1.1850020106732029
/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/processing_utils.py:738: UserWarning: Trying to convert audio automatically from float32 to 16-bit int format.
warnings.warn(warning.format(data.dtype))
/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/pydub/utils.py:198: RuntimeWarning: Couldn't find ffprobe or avprobe - defaulting to ffprobe, but may not work
warn("Couldn't find ffprobe or avprobe - defaulting to ffprobe, but may not work", RuntimeWarning)
Traceback (most recent call last):
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/queueing.py", line 624, in process_events
response = await route_utils.call_process_api(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/route_utils.py", line 323, in call_process_api
output = await app.get_blocks().process_api(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/blocks.py", line 2043, in process_api
data = await self.handle_streaming_outputs(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/blocks.py", line 1870, in handle_streaming_outputs
binary_data, output_data = await block.stream_output(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/components/audio.py", line 361, in stream_output
value, duration = await self.covert_to_adts(binary_data)
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/components/audio.py", line 330, in covert_to_adts
return await anyio.to_thread.run_sync(Audio._convert_to_adts, data)
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/anyio/to_thread.py", line 56, in run_sync
return await get_async_backend().run_sync_in_worker_thread(
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 2485, in run_sync_in_worker_thread
return await future
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 976, in run
result = context.run(func, *args)
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/gradio/components/audio.py", line 321, in _convert_to_adts
segment = AudioSegment.from_file(io.BytesIO(data))
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/pydub/audio_segment.py", line 728, in from_file
info = mediainfo_json(orig_file, read_ahead_limit=read_ahead_limit)
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/site-packages/pydub/utils.py", line 274, in mediainfo_json
res = Popen(command, stdin=stdin_parameter, stdout=PIPE, stderr=PIPE)
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/subprocess.py", line 971, in __init__
self._execute_child(args, executable, preexec_fn, close_fds,
File "/home/abc/miniconda3/envs/cosyvoice/lib/python3.10/subprocess.py", line 1863, in _execute_child
raise child_exception_type(errno_num, err_msg, err_filename)
FileNotFoundError: [Errno 2] No such file or directory: 'ffprobe'这个错误是因为 Gradio 在处理音频输出时需要 ffprobe(ffmpeg 的一部分)来进行音频格式转换,但系统中没有安装。
bash
# 安装 ffmpeg 工具包(包含 ffprobe)
sudo apt-get update
sudo apt-get install -y ffmpeg
# 验证安装
which ffprobe
ffprobe -version我是安装ffmpeg后就可以了,如果还不行,试试下面的
预防性措施:虽然你已经安装了 ffprobe 并验证了它在终端中可用,但 Python/Gradio 进程可能在不同的环境中运行,无法访问到系统 PATH 中的 ffprobe。特别是在 WSL 环境中,环境变量有时会有差异。
更健壮的解决方案 :即使 ffprobe 现在可用,
type="numpy"是一种更直接、更可靠的处理方式,它:
- 避免了额外的格式转换开销
- 减少了对外部依赖的敏感性
- 在跨平台部署时更稳定
python
# webui.py
audio_output = gr.Audio(label="合成音频", autoplay=True, streaming=True)
改成
audio_output = gr.Audio(
label="合成音频",
type="numpy",
format="wav",
autoplay=True,
streaming=True,
interactive=False
)
# 在 generate_audio 函数中,确保返回的数据是正确的 numpy 格式:
# 在 generate_audio 函数末尾,确保返回格式正确
if isinstance(speech, torch.Tensor):
speech = speech.cpu().numpy()
# 确保形状正确 [samples] 或 [channels, samples]
if speech.ndim == 2 and speech.shape[0] == 1:
speech = speech[0] # 转换为单声道 [samples]
# 确保在 [-1, 1] 范围内(如果使用 float32)
if speech.dtype == np.float32:
speech = np.clip(speech, -1.0, 1.0)
# 返回 (采样率, 音频数据) 元组
yield (22050, speech) # 假设采样率为22050处理torch.cuda.amp.autocast警告(可选),我没试
python
# cosyvoice/cli/model.py
# 将
with self.llm_context, torch.cuda.amp.autocast(self.fp16 is True and hasattr(self.llm, 'vllm') is False):
# 修改为
with self.llm_context, torch.amp.autocast('cuda', enabled=(self.fp16 is True and hasattr(self.llm, 'vllm') is False)):
# 同样,将
with torch.cuda.amp.autocast(self.fp16):
# 修改为
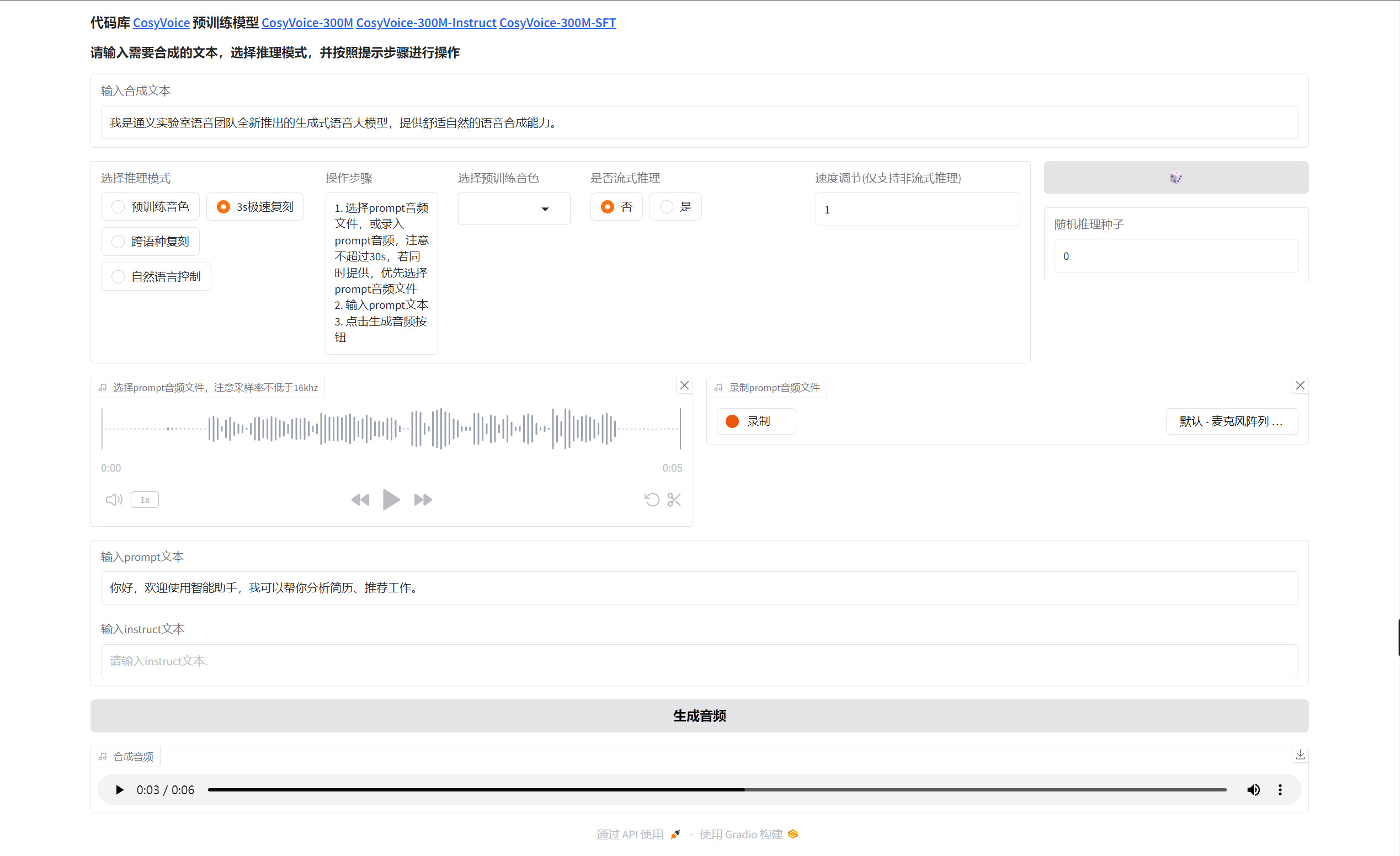
with torch.amp.autocast('cuda', enabled=self.fp16):生成成功
参考链接
使用PAI-EAS部署CosyVoice2.0 WebUI服务-人工智能平台 PAI-阿里云
使用函数计算FunctionAI一键部署CosyVoice2.0语音合成模型-开发者社区-阿里云
在阿里云ECS上部署CosyVoice语音克隆WebUI-开发者社区-阿里云
CosyVoice:开源强大的 AI 语音合成工具-腾讯云开发者社区-腾讯云