摘要:随着现代社会健康问题的日益严重,糖尿病已经成为全球范围内的主要公共卫生问题。糖尿病的早期诊断和有效干预对于控制疾病进展、提高患者生活质量至关重要。近年来,深度学习技术在医学领域的应用逐渐增多,尤其是在疾病预测和诊断方面取得了显著成果。本研究基于深度学习方法,开发了一种糖尿病医疗数据可视化与预测平台,旨在帮助医疗专业人员和患者实现糖尿病的早期筛查与管理。
项目概述
本研究设计并实现了一套基于深度学习的糖尿病预测系统,旨在构建一个兼具数据预处理、模型训练、在线推理与健康记录管理功能的一体化风险评估平台。研究使用 Kaggle Pima Indians Diabetes Dataset 作为数据源,针对原始数据中 SkinThickness、Insulin、Glucose 等特征大量出现的零值问题,采用基于类别(Outcome)的均值与中位数填补策略进行清洗与修正,以提升数据质量与模型泛化能力。在数据处理后,将数据集按 8:2 的比例划分为训练集与测试集,并基于训练集计算八个输入特征的均值与标准差,以确保模型训练与推理阶段的标准化一致性。
模型部分构建了由三层全连接结构(8-64-32-1)组成的深度神经网络,以 ReLU 和 Sigmoid 作为激活函数,并采用二元交叉熵损失函数与 Adam 优化器进行训练。模型训练 1000 轮后,在测试集上取得良好分类性能,并通过混淆矩阵、ROC 曲线与学习曲线对模型的性能与收敛情况进行了分析。训练完成后,模型参数及标准化参数分别以 Ddiabetes_model.pth、feature_mean.npy 与 feature_std.npy 的形式持久化,用于后续部署。
系统部署部分基于 Flask 框架实现 Web 化服务。后端加载训练好的 PyTorch 模型,对用户输入的八项生理指标进行标准化处理后生成预测结果,并结合医学规则(如空腹血糖阈值、BMI 与胰岛素水平组合条件)对模型输出进行风险校正,以增强系统的可解释性与临床适用性。系统采用 SQLite 数据库存储所有用户记录,开发了包括患者数量统计、历史记录查询、特征均值比较、糖尿病分布等多项 API 接口,实现了对历史健康数据的可视化管理与动态查询。
此外,为提升系统在统计分析模块中的数据丰富度,本研究开发了配套脚本 adddata.py,可基于 Kaggle 数据集批量生成带有随机时间戳与随机患者编号的模拟历史记录,从而增强数据库样本的多样性与可用性。
综上所述,本研究完成了一套从数据清洗、深度学习建模、规则融合推理到 Web 部署与数据库管理的完整糖尿病智能预测系统。系统结构轻量、部署简单、可扩展性强,可为基层医疗机构、健康管理平台及相关研究人员提供一种实用、可解释且具有推广潜力的疾病风险预测工具。

图1 系统整体流程图
硬件配置
该系统硬件配置如上,如果您的电脑配置低于下述规格,运行速度可能会与本系统的存在差异,请注意。

表1 惠普(HP)暗影精灵10台式整机配置(系统硬件配置)
软件环境
对本实验所需的各类软件及工具的基本信息进行了清晰汇总。

表2 系统软件配置(真实运行环境)
运行展示
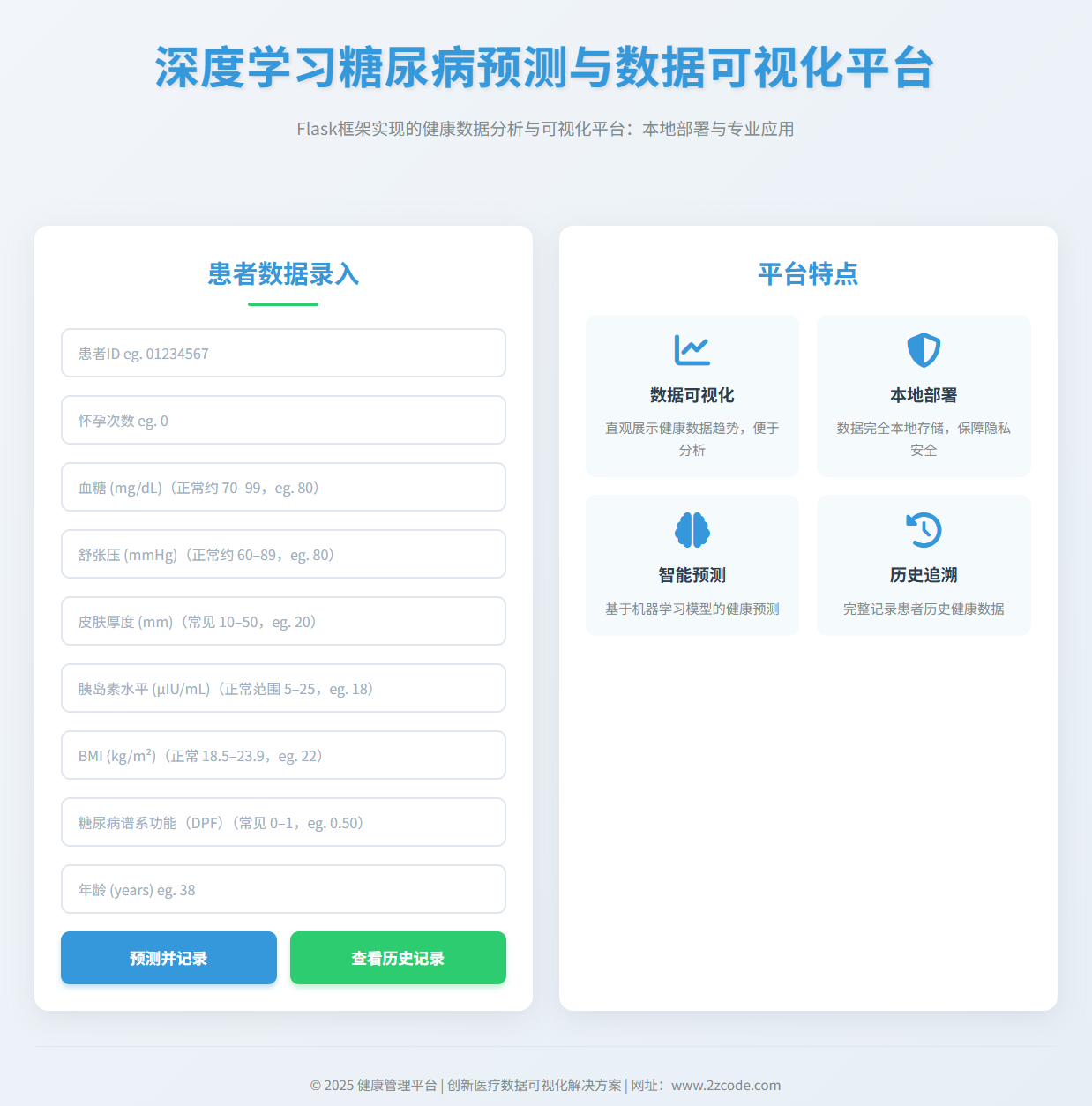
图2 系统主界面

图3 患者数据
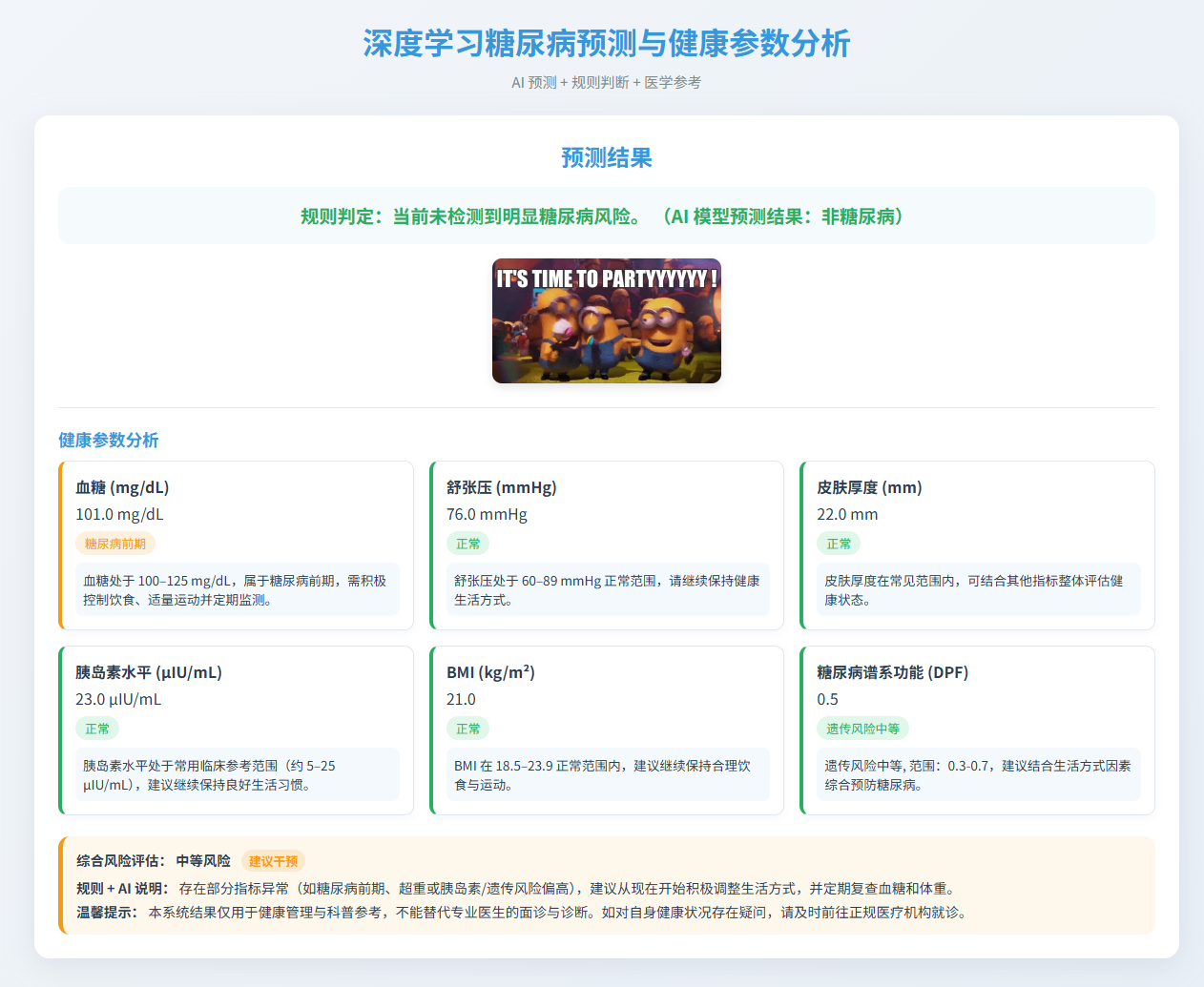
图4 预测结果-未患糖尿病(前期风险)
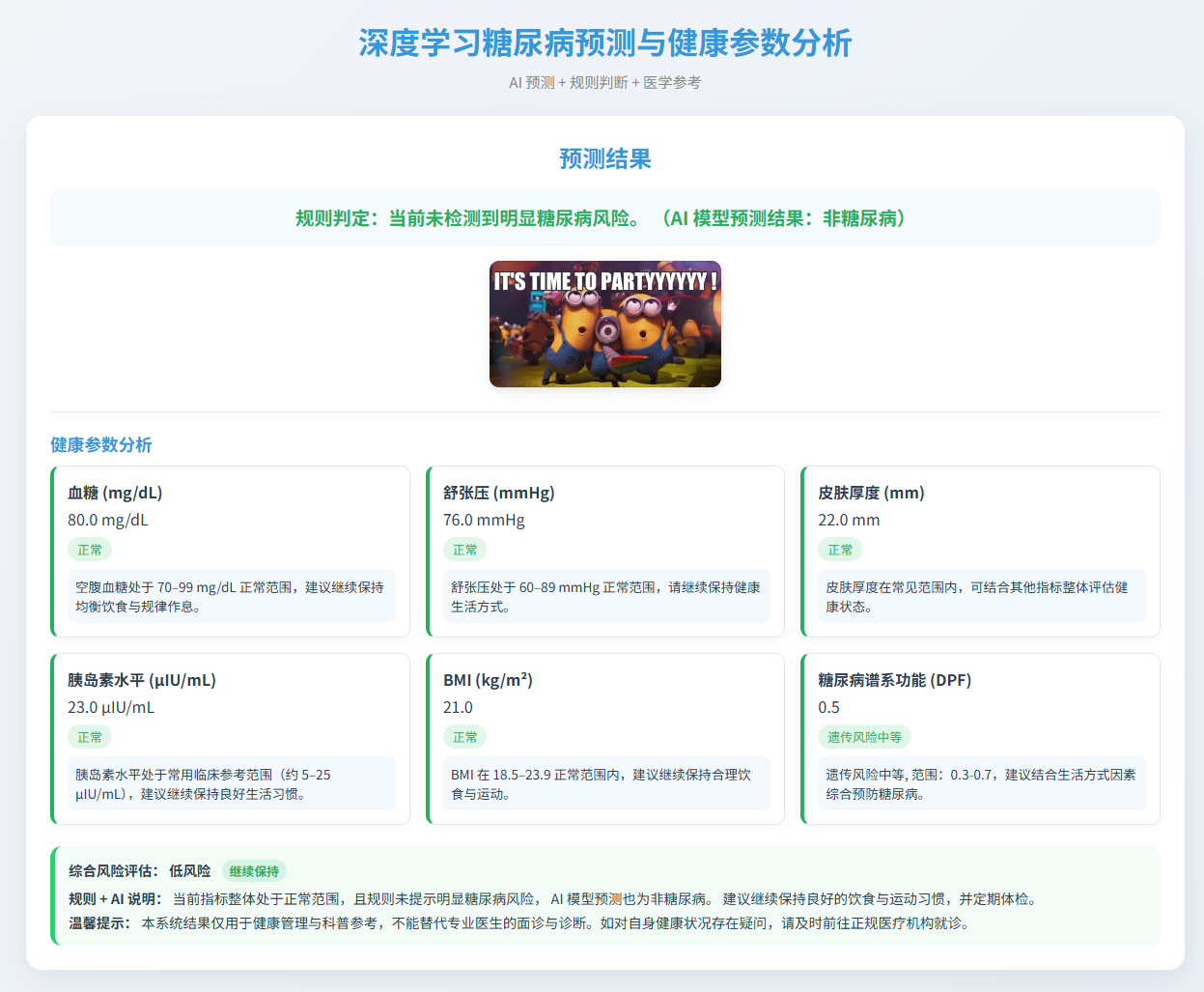
图5 预测结果-未患糖尿病(暂无风险)

图6 预测结果-患糖尿病(高风险)

图7 预测结果-患糖尿病-多项数值异常(高风险)

图8 历史记录概述
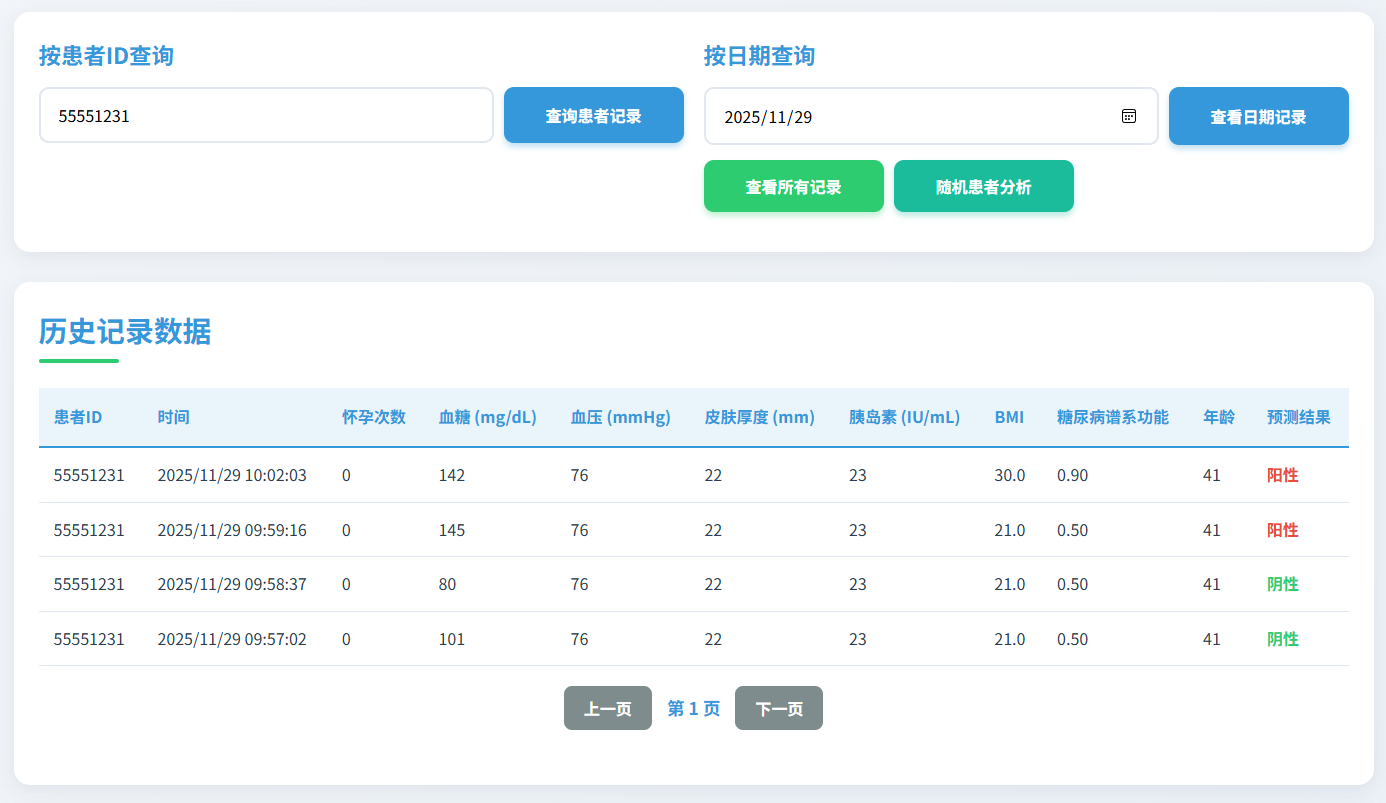
图9 按患者ID查询
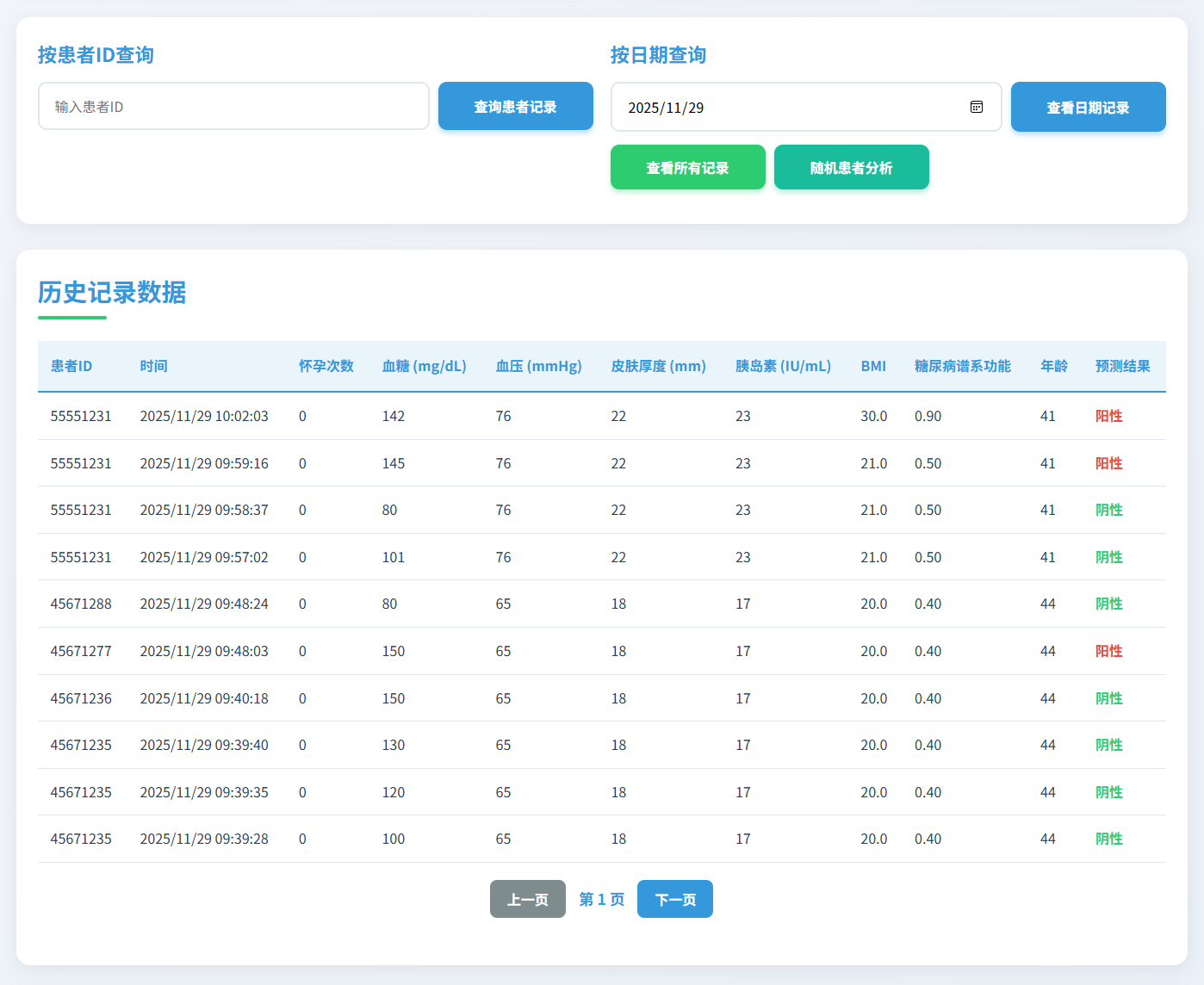
图10 查看日期记录
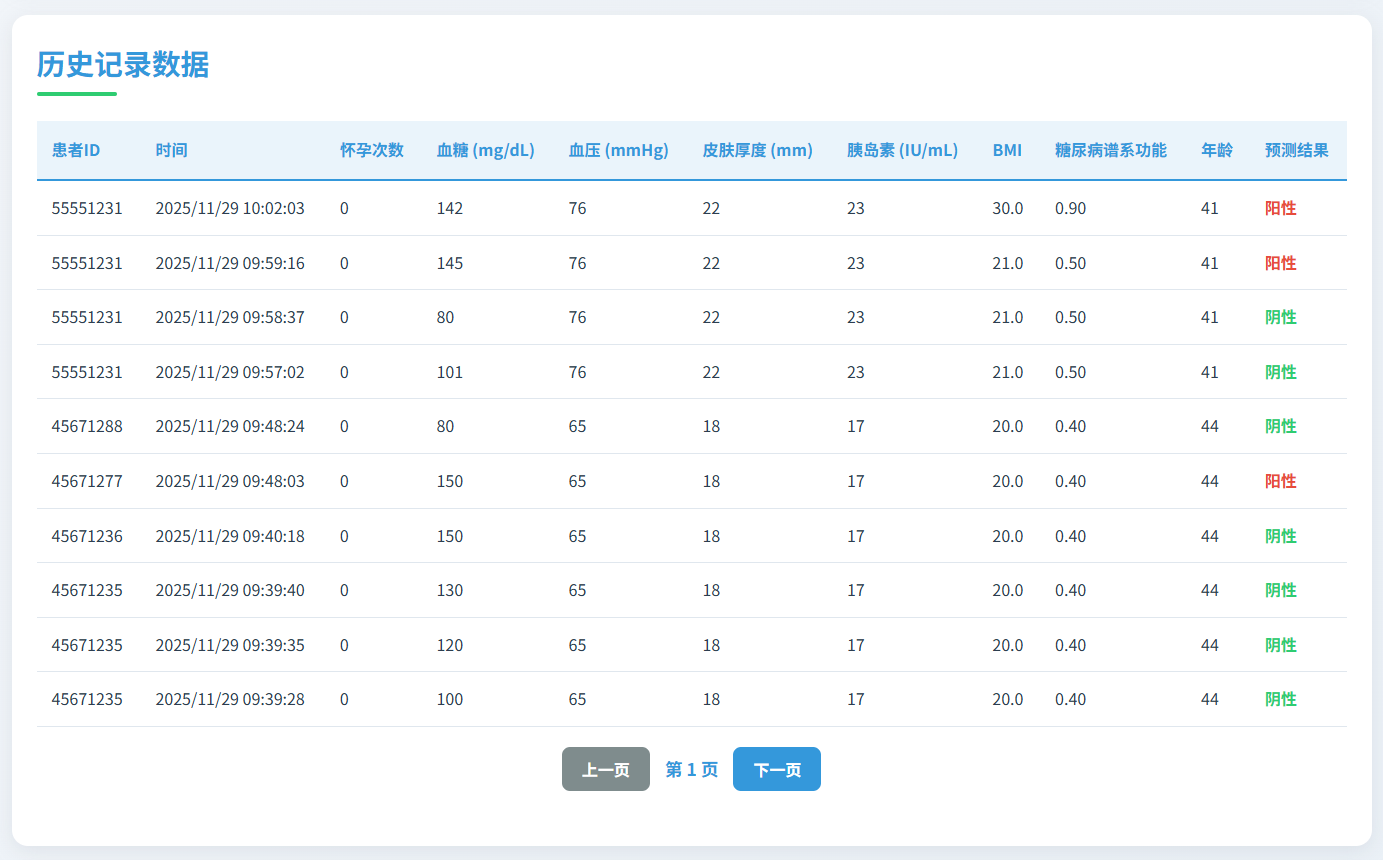
图11 历史记录数据
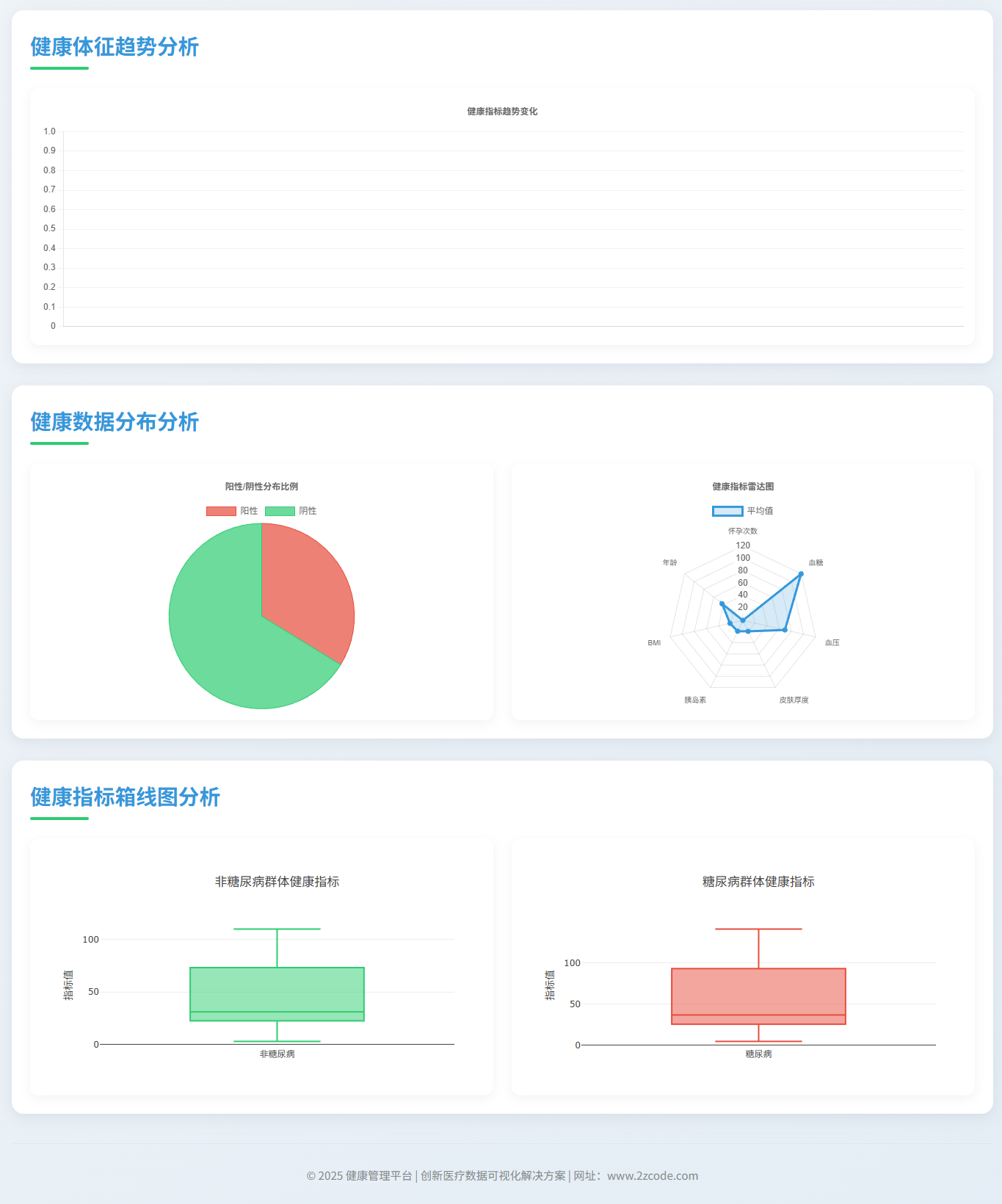
图12 健康指标
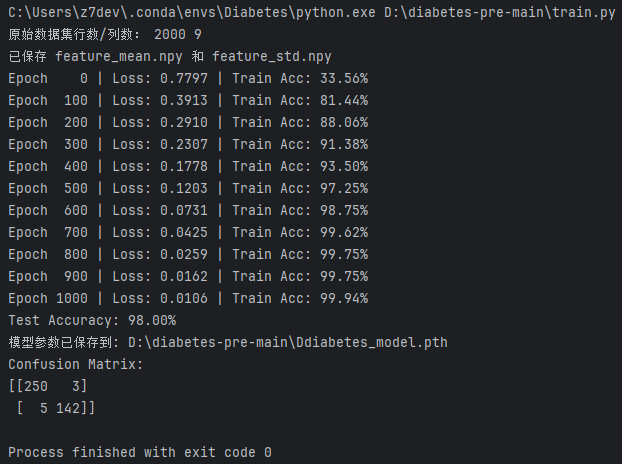
图13 训练日志
模型在 2000 条数据上训练后损失从 0.78 降至 0.01、训练准确率接近 100%、测试集准确率达 98% 且混淆矩阵仅有极少数误判,说明模型拟合良好、泛化能力很强,仅可能存在轻微过拟合但整体性能非常优秀。

图14 混淆矩阵
模型在 400 个样本上仅有极少数误判,整体准确率约 98%,阴阳性都能被很好地区分。
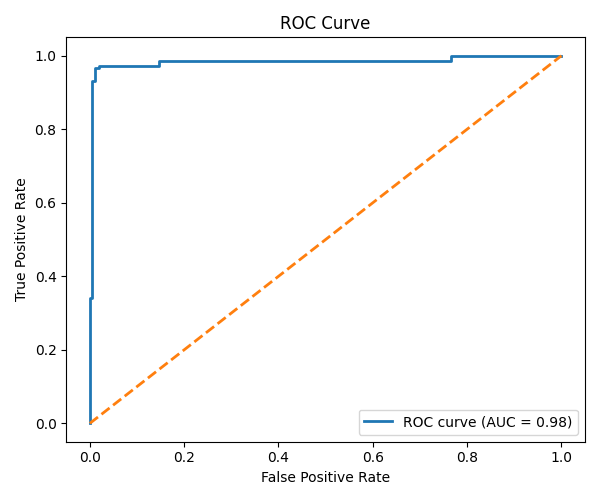
图15 ROC-曲线
AUC≈0.98,说明模型对糖尿病和非糖尿病样本具有极强的区分能力。
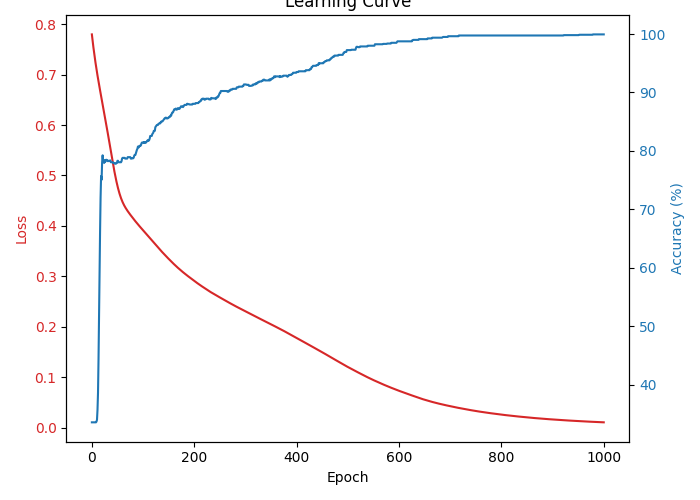
图16 学习曲线
随着训练轮数增加,损失持续下降、准确率持续上升,表明模型训练稳定并成功收敛。