前言
纠错式检索增强生成(CRAG)主要是为了解决RAG系统的一个关键问题:如果检索出来的结果不相关或者不正确怎么办?
CRAG引入纠错机制,用来评估和改进检索到的文档的质量。这在减少LLM的"幻觉"方面特别有用。
CRAG的概念
CRAG的核心想法就是给RAG系统加上一层"质量检查和纠错"的功能,让它在检索阶段就能把关,从而提高系统的可靠性。
因为LLM有时候会"脑补"信息,也就是凭空捏造一些听起来很自信但实际上并不可靠的内容。虽然RAG可以通过检索相关文档来引导生成回答,但如果检索到的内容本身就不准确,那效果也会大打折扣。
CRAG引入了以下几个关键机制:
- 轻量级检索评估器:这个组件会评估检索到的文档和问题的相关性,然后给一个"信心分数",告诉系统这些文档有多靠谱。
- 纠错动作 :根据相关性评估的结果,CRAG可以触发三种动作:正确 、错误 或者模糊。这就让CRAG可以根据情况决定是直接用检索到的文档,还是扔掉这些文档去网上重新搜索,或者如果相关性不确定的话,就把两者结合起来用。
- 补充网络检索:如果检索到的文档完全不相关,CRAG就会从网上搜新的结果来补充知识库。
- 细化文档知识:CRAG可以把文档进一步切成"知识条",这样就能只用检索到的文档里相关部分,把不相关的细节过滤掉。
总之CRAG不仅会检索文档,还会评估这些文档的质量,然后根据需要进行选择性的修正。它会根据手头的信息质量动态调整,有利于生成更靠谱的回答。
纠错式RAG的不同动作
在CRAG里,根据检索结果的相关性评估,会触发不同的动作:
-
正确动作(Correct Action):如果相关性的信心分数很高,CRAG就会假设检索到的文档是有用的,然后在把检索到的知识提炼成精华部分之后,继续生成回答。这在文档里有有用的信息,但这些信息不是特别聚焦,需要进一步提炼的情况下特别有用。
-
错误动作(Incorrect Action):如果所有文档的相关性信心分数都很低,CRAG就会采取纠错动作,扔掉这些检索到的文档,直接去网上搜索,找更相关的内容。
-
模糊动作(Ambiguous Action):如果相关性评估得出来的分数是中间水平,CRAG就会采取折中的办法,把提炼后的检索知识和网上的搜索结果结合起来用。这种平衡在那些模棱两可的情况下特别有用,因为不管是检索到的数据还是纯网上搜索的结果,单独来看都不够充分。
这些动作保证了CRAG在面对不同质量的检索结果时,能够保持灵活和适应性,从而提高系统的可靠性。
实现代码
python
import os
from typing import List, TypedDict
from dotenv import load_dotenv
from langchain.schema import Document # Import the Document class
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
# pip install pypdf
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# pip install beautifulsoup4
from langgraph.graph import StateGraph, START, END
from pydantic import BaseModel, Field
load_dotenv()
embeddings = DashScopeEmbeddings(
dashscope_api_key=os.getenv("OPENAI_API_KEY"),
model="text-embedding-v4",
)
model = ChatOpenAI(model="qwen-plus",
base_url=os.getenv("BASE_URL"),
api_key=os.getenv("OPENAI_API_KEY"),
temperature=0,
streaming=True)
# Step 1: Load and prepare documents
docs_list = TextLoader(os.path.join(os.getcwd(), "crag_data.txt")).load()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=250, chunk_overlap=0)
doc_splits = text_splitter.split_documents(docs_list)
# print("doc_splits=", len(doc_splits))
# 示例取部分doc吧
docs = doc_splits[:3]
vectorstore = Chroma.from_documents(docs, collection_name="crag-chroma", embedding=embeddings)
retriever = vectorstore.as_retriever()
# Step 2: Define Graders and Relevance Model
class GradeDocuments(BaseModel):
binary_score: str = Field(description="Documents are relevant to the question, 'yes' or 'no'")
retrieval_prompt = ChatPromptTemplate.from_template("""
您是一名评分员,负责评估文档是否与用户的问题相关。
Document: {document}
Question: {question}
Is the document relevant? Answer 'yes' or 'no'.
You must respond using JSON format with the following structure:
{{"binary_score": "yes or no"}}
""")
retrieval_grader = retrieval_prompt | model.with_structured_output(GradeDocuments)
# Step 3: Query Re-writer
class ImproveQuestion(BaseModel):
improved_question: str = Field(description="Formulate an improved question.")
re_write_prompt = ChatPromptTemplate.from_template(
"""这是原始问题: \n\n {question} \n 提出一个该问题的改进表达.
You must respond using JSON format with the following structure:
{{"improved_question": "new question"}}
"""
)
query_rewriter = re_write_prompt | model.with_structured_output(ImproveQuestion)
# Define prompt template
prompt = ChatPromptTemplate.from_template("""
使用以下上下文回答问题:
Question: {question}
Context: {context}
Answer:
""")
rag_chain = prompt | model | StrOutputParser()
# Define CRAG State
class GraphState(TypedDict):
question: str
generation: str
web_search: str
documents: List[str]
# Step 4: Define Workflow Nodes
def retrieve(state):
question = state["question"]
documents = retriever.invoke(question)
return {"documents": documents, "question": question}
def grade_documents(state):
question = state["question"]
documents = state["documents"]
filtered_docs = []
web_search_needed = "No"
for doc in documents:
grade = retrieval_grader.invoke({"question": question, "document": doc.page_content}).binary_score
if grade == "yes":
print("---评估: 文档有相关性---")
filtered_docs.append(doc)
else:
print("---评估: 文档没有相关性---")
web_search_needed = "Yes"
return {"documents": filtered_docs, "question": question, "web_search": web_search_needed}
def transform_query(state):
question = state["question"]
rewritten_question = query_rewriter.invoke({"question": question})
return {"question": rewritten_question.improved_question, "documents": state["documents"]}
def web_search(state):
print("---网络搜索---")
question = state["question"]
documents = state["documents"]
print(question)
search_results = TavilySearchResults(k=3).invoke({"query": question})
print("搜索结果=", len(search_results))
web_documents = [Document(page_content=result["content"]) for result in search_results if "content" in result]
documents.extend(web_documents)
return {"documents": documents, "question": question}
def generate(state):
generation = rag_chain.invoke(
{
"context": state["documents"],
"question": state["question"]
}
)
return {"generation": generation}
# Step 5: Define Decision-Making Logic
def decide_to_generate(state):
print("---评估是否改进问题表达---")
web_search = state["web_search"]
if web_search == "Yes":
# All documents have been filtered check_relevance
# We will re-generate a new query
print("--决策:所有文档都与问题无关,转换查询---")
return "transform_query"
print("--决策:直接生成答案---")
return "generate"
# Step 6: Build and Compile the Graph
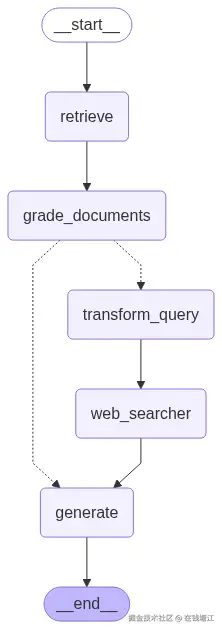
workflow = StateGraph(GraphState)
workflow.add_node("retrieve", retrieve)
workflow.add_node("grade_documents", grade_documents)
workflow.add_node("transform_query", transform_query)
workflow.add_node("web_searcher", web_search)
workflow.add_node("generate", generate)
# Define edges
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate"
}
)
workflow.add_edge("transform_query", "web_searcher")
workflow.add_edge("web_searcher", "generate")
workflow.add_edge("generate", END)
app = workflow.compile()
# Example input
# inputs = {"question": "解释不同类型的代理记忆是如何工作的?"}
inputs = {"question": "地球如何自转?"}
for output in app.stream(inputs):
for key, value in output.items():
print(f"节点 {key}:")
# Optional: print full state at each node
# pprint.pprint(value["keys"], indent=2, width=80, depth=None)
print(value["generation"])问一个有相关性的问题
markdown
节点 retrieve:
---评估: 文档有相关性---
---评估: 文档有相关性---
---评估: 文档有相关性---
---评估是否改进问题表达---
--决策:直接生成答案---
节点 grade_documents:
节点 generate:
在基于大语言模型(LLM)的自主代理系统中,**代理记忆**(Agent Memory)是其关键组成部分之一,用于帮助代理保留和利用信息。根据上下文,代理记忆主要分为两种类型:**短期记忆**和**长期记忆**。它们的工作方式如下:
### 1. **短期记忆**(Short-term Memory)
- **工作原理**:短期记忆通常依赖于模型的**上下文学习**(In-context Learning)能力。当代理处理任务时,它会将当前对话或任务的上下文信息保留在模型的输入提示(Prompt)中,从而让模型在生成回答时能够参考这些信息。
- **特点**:
- 依赖于模型的输入提示长度限制,信息存储有限。
- 适用于当前任务或对话中的即时信息,例如对话历史、临时状态等。
- 无需外部存储,所有信息都直接嵌入到模型的提示中。
- **应用场景**:适用于需要快速响应的小型任务或对话交互。
### 2. **长期记忆**(Long-term Memory)
- **工作原理**:长期记忆通过**外部向量存储**(Vector Store)和**快速检索机制**(如最大内积搜索 MIPS)来实现。代理可以将需要长期保留的信息(如历史交互记录、知识库等)存储到外部数据库中,并在需要时快速检索。
- **特点**:
- 可以存储大量信息,理论上不受模型提示长度限制。
- 支持跨任务和跨时间的信息检索,适用于复杂场景。
- 通常需要结合检索增强生成(RAG)技术,从外部知识库中提取相关信息。
- **应用场景**:适用于需要持久存储和跨任务访问的场景,例如用户历史偏好、企业知识库等。
### 总结
- **短期记忆**更注重当前任务的上下文信息,依赖模型的提示机制,适合即时交互。
- **长期记忆**则通过外部存储和检索机制扩展代理的信息存储能力,适合需要持久化和跨任务访问的场景。
这两种记忆机制相辅相成,使得代理能够在不同场景下灵活应对,提升其智能化水平和任务处理能力。问一个没有相关性的问题
markdown
节点 retrieve:
---评估: 文档没有相关性---
---评估: 文档没有相关性---
---评估: 文档没有相关性---
---评估是否改进问题表达---
--决策:所有文档都与问题无关,转换查询---
节点 grade_documents:
节点 transform_query:
---网络搜索---
地球是如何进行自转的,其自转的方向和周期是怎样的?
搜索结果= 5
节点 web_searcher:
节点 generate:
地球的自转是指地球围绕其自身轴线进行旋转的运动。以下是关于地球自转的方向和周期的详细说明:
### **方向**
1. **自西向东**:地球自转的方向是自西向东。
2. **从北极点上空看**:呈逆时针方向旋转。
3. **从南极点上空看**:呈顺时针方向旋转。
### **周期**
1. **恒星日**:地球自转一周的实际时间是 **23小时56分4秒**(约23小时56分)。这个周期是相对于遥远的恒星而言的,被称为"恒星日"。
2. **太阳日**:由于地球同时绕太阳公转,相对于太阳来说,地球自转一周的时间为 **24小时**,这被称为"太阳日",是日常生活中使用的时间单位。
### **补充信息**
- 地球自转的速度并不完全均匀,会受到一些因素的影响:
- **长期减慢**:由于潮汐摩擦等因素,地球自转速度逐渐减慢,一天的长度每世纪增加约1.7毫秒。
- **周期性变化**:季节性风的变化等因素会导致地球自转速度的周期性变化。
- **不规则变化**:由于地球内部和外部动力学因素,自转速度还会出现时快时慢的不规则变化。
### **总结**
地球自转的方向是自西向东,从北极点上空看呈逆时针方向,从南极点上空看呈顺时针方向;自转周期为 **23小时56分**(恒星日),日常使用的时间周期为 **24小时**(太阳日)。总结
LangGraph的实现CRAG
- 检索评估:LangGraph的工作流程里有个"评分器",它就像一个轻量级的检索评估器,会评估每篇文档的相关性,这和论文里的方法是一样的。
- 纠错动作:根据相关性分数,LangGraph的工作流程会触发相应的动作(正确、错误或模糊),这直接反映了CRAG方法论里的分支条件。
- 基于网络的补充:如果检索到的文档不够用,工作流程就会用Tavily Search从网上补充信息,这体现了CRAG用更广泛的来源来补充有限语料库的原则。
通过实现这些组件,LangGraph的工作流程构建了一个强大的CRAG框架,提升了文档质量评估和上下文提炼的能力,从而解决了原始RAG的局限性,减少了生成回答中的"幻觉"现象。