
引
我在「cursor 实战经验分享,与 AI 编码的深度思考」一文分享了一些 cursor 实战的分享,其中谈到了一些 mcp 和工具 ,但只是简单带过,结合后续的一些开发体验也有一些额外的感受,所以单开一篇文章介绍一些站在前端视角我觉得好用的 mcp 和 rule 定义。
一、Playwright MCP
playwright 是一个能打通 cursor 和 Chrome 的 mcp 服务,能在调试测试阶段自动帮你操作浏览器完成部分测试,以及读取控制台日志或接口信息,这样能省去在调试阶段通过截图给 cursor 和描述问题的时间,更重要的是,一旦使用 playwright 打开网页地址后,后续的调试 cursor 自己会理解使用此 playwright 工具进行调试和查看日志,非常方便。
1.1 关于配置:
我们可以在 cursor mcp 添加如下配置:
perl
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest",
"--browser",
"chrome",
"--image-responses",
"auto"
],
"env": {
"DEBUG": "pw:*"
}
},1.2 关于用法:
假设我们已经在终端运行了项目,我们可以直接复制链接,告知 cursor:
arduino
使用 playwright 打开 http://localhost:4000/当然你也可以直接说使用 playwright 打开网页访问 XX 项目,cursor 也能做到执行脚本后访问,但我觉得对话路线太长,与 AI 交谈还是越简单目的越明确越好。
之后 cursor 会调用工具新开一个 Chrome 页面,后续的开发 cursor 会通过 playwright 完成自动化测试、页面截图以及调试日志读取。
1.3 一点心得
可能会出现 cursor 无限制尝试打开信 tab 的情况,一般 cursor 会尝试 10 来次后放弃,这种一般是因为之前访问过 playwright,历史对话没清除干净,解决办法是直接退出 cursor 后重新打开再走上面的流程就好。
另外,与 Browser MCP 、Chrome mcp 等一系列操作网页 mcp 类似,AI 虽然能理解我们的行为意图并帮我们操作网页完成任务,但由于我们并没有专门去定义 playwright 测试脚本,所以对于复杂的交互如果描述不清晰其实测试效果非常慢(可能会多次摸索尝试) ,所以虽然 AI 能做,但我永远鼓励采用更高效的方式去开发,与 AI 保持合作的关系共同推进一件事,该自己动手的还是动手,而不是全都丢给 AI。
二、Figma MCP
figma mcp 有个人开发和官方两个版本,这里介绍的是官方版本,由于 beta 版本只支持客户端,所以需要大家下载 figma 客户端,网页版无法使用。
2.1 关于配置
我们可以添加如下配置:
json
"Figma": {
"url": "http://127.0.0.1:3845/mcp",
"headers": {}
},之后用客户端打开对应设计稿,按如下点击:
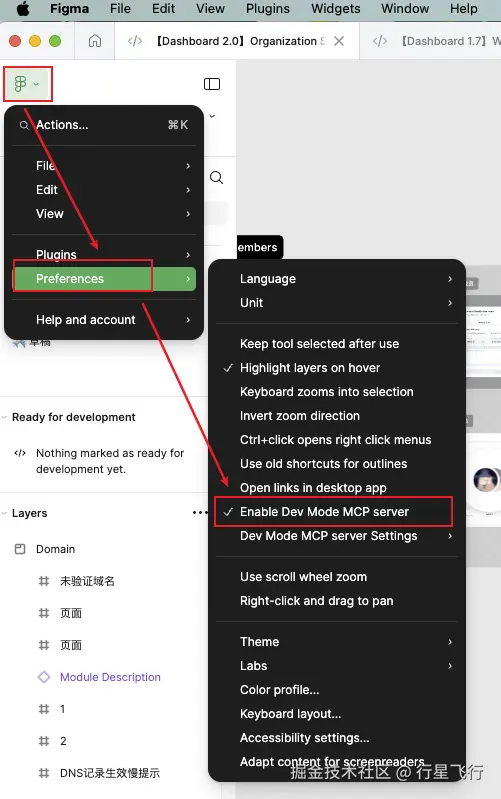
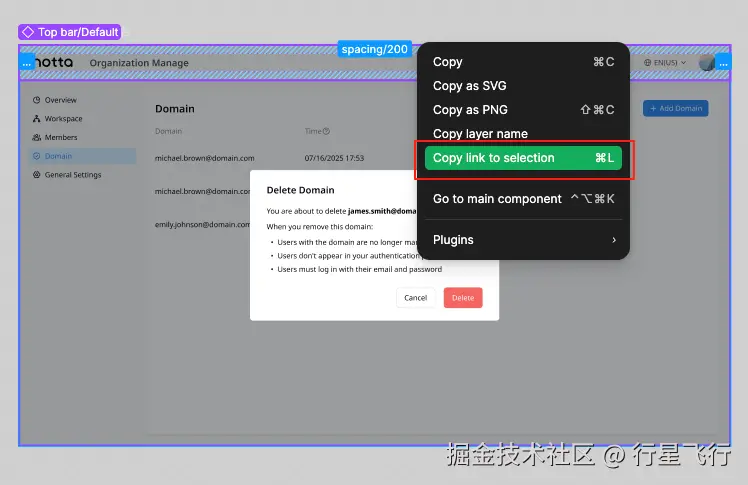
之后我们就可以复制链接到 cursor 通过 AI 来阅读对应链接的设计稿了,比如:
2.2 一点心得
2.2.1 关于 tools
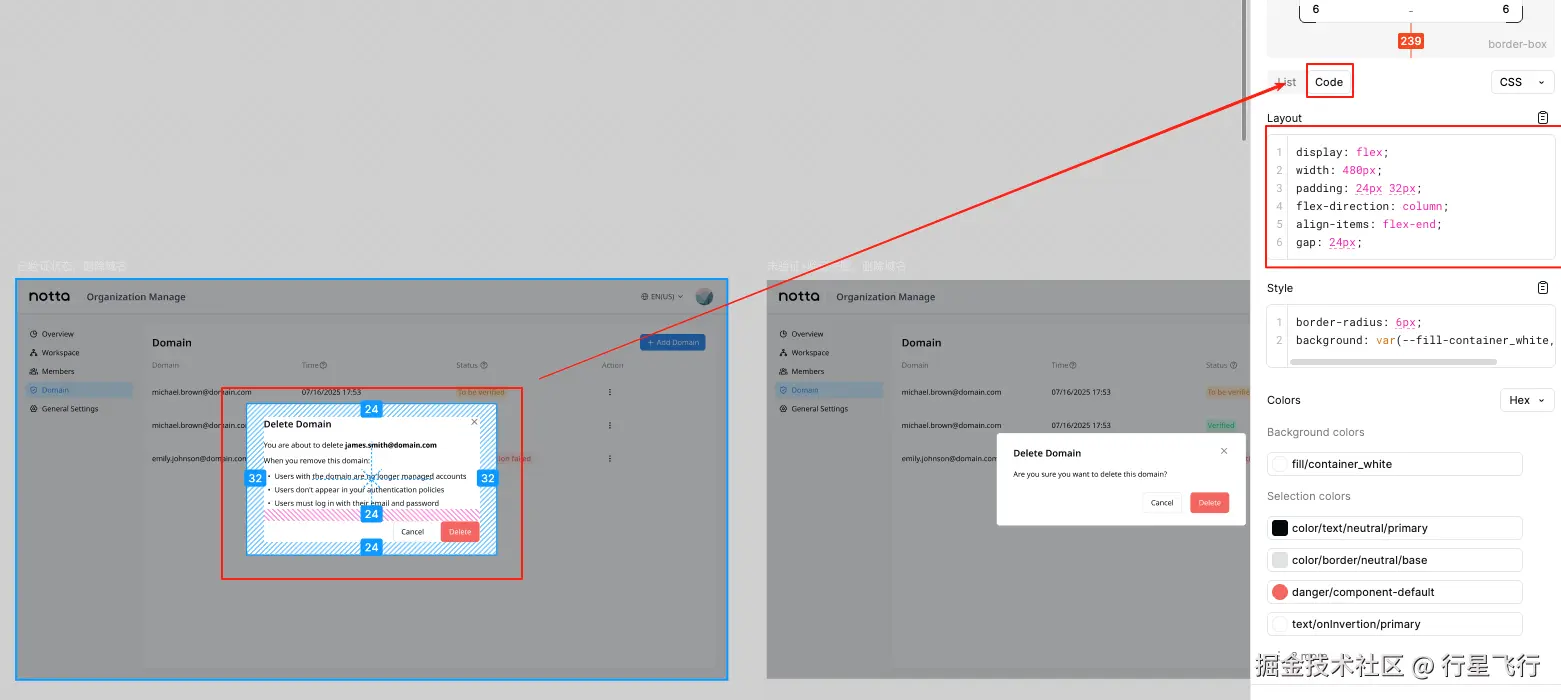
figma mcp 支持多个 tools,比较常用的是 image 和 code,前者类似于让 AI 直接通过截图的方式阅读设计稿,能了解大概但不够精细,后者属于直接阅读设计稿的代码,精准度更好。
所以在 AI 对话时,我们直接说用 image 或者 code 阅读设计稿,figma mcp 自身可以理解这样的语义,而关于设计稿的代码其实就是之前我们经常需要手动复制的部分。
2.2.2 使用 image 提前参与需求规划和 task 拆解
我们现在使用 kiro 工作流的第一个阶段就是讨论需求,正常来说我们会提前准备一个给 AI 阅读的 PRD 文档,包含一些简单的需求 ToDo 方便 AI 理解这个需求要做什么,事实证明在第一阶段加入需求设计稿能利于 AI 更精准的理解需求,但由于需求的设计稿可能包含多张图,因此我们可以直接选择这个区域的 link 然后提供给 AI,并要求是用 image 来粗略理解需求:
当设计稿过大,上下文过大的情况下,figma mcp code 可能会失败,所以一般用 image 来粗略阅读大范围的设计稿。
2.2.3 组件实现阶段使用 image + code 提升还原精准度
在需求实现阶段,建议大家在根据组件范围提供更为精准的设计稿链接,同时可以明确要求使用 image + code 同时理解设计稿,image 作用用于理解设计稿整体布局和文案提取,code 用于逐行阅读代码提供像素级别的 UI 还原。
另外,有时候我们提供设计稿链接,AI 会偷懒默认使用 image 阅读设计稿,这就跟我们直接截图没区别,自然做不到精准还原,所以明确要求这两个工具非常有必要。
2.2.4 使用 playwright + figma 做到 UI 还原与截图自查
由于 playwirght 本身支持截图页面用于 AI 理解界面情况,因此我们可以在 figma 还原设计稿时结合 playwright 做到 UI 还原后的界面自查,对于还原明显缺陷的地方便于 AI 自动结合问题和设计稿进一步优化,我的流程一般是这样:
开发前:get_code + get_image 同时调用
↓
理解设计:精确数据 + 布局结构
↓
实现代码:基于完整理解编写
↓
验证效果:Playwright 检查 + 必要时再次对比设计稿
↓
手动自查:人为识别更细致的问题,主动抛给 AI 进一步修复问题但需要注意的是,playwirght 做不到像素级别的的 UI 缺陷失败,它其实也是通过截图粗略理解,但通过上面的方式能帮我们将 UI 还原到 7-8 成的水平,剩下的问题我们直接提供给 AI 后精准修复,效率也会提高很多。
最后,贴一个我在 figma mcp 执行时明确要求的 rule:
markdown
# Figma mcp UI 实现规范(重要)
1. 设计稿阅读策略:
- 同时调用 get_code 和 get_image 并行阅读
- code 逐行阅读 Figma 生成的 className 和 code,对比 Figma Variables 确保颜色值精确
- Image 理解整体布局结构、文案,确认组件间的相对位置关系,验证实现效果是否符合设计意图
- 避免视觉估算,使用设计稿的确切值
2. 实现要求:
- 先索要设计稿,不能自行开始写 UI
- 仔细逐行阅读设计稿的变量和代码,不允许使用 image 阅读设计稿就写代码
- 确保精确还原,不能"看起来差不多"
3. 组件规范:
- 优先使用 @notta/components(如McButton),如果存在疑问请主动询问用户
- 先查看组件库支持的 props(如 theme="red"、size = large),避免重复定义样式
- 图标使用 notta-web-icon,不用 antd 图标
- 样式文件使用 xx.less 命名
- 样式嵌套不要超过 5 层
- CSS类名使用 snake_case ,不允许使用小驼峰
- 样式文件无需添加注释
4. 开发流程请遵守:
开发前:get_code + get_image 同时调用
↓
理解设计:精确数据 + 布局结构
↓
实现代码:基于完整理解编写
↓
验证效果:Playwright 检查 + 必要时再次对比设计稿
↓
还原完成后告知用户,并等待用户主动提供反馈,进入下一轮 UI 验证三、使用 AI 完成多语言替换与 airtable key 新建
使用 figma mcp 完成组件和页面还有一个好处是,AI 会通过 image 直接理解文案并还原,所以当我们昨晚需求,整个需求的多语言的英文版本已经具备了,此时我们可以 @write-i18n.mdc 完成英语替换成多语言写法,以及 airtable 新建 key 的过程。
目前 rule 具备如下几个特性:
- 检查本次改动文件或者用户提供文件范围的所有
.tsx和.ts文件,并查找文件中的文案硬编码 - 将硬编码替换为
intl.formatMessage({id: "key"})写法或者多语言 key - key 命名遵守
[模块名]_[功能]_[用途],比如organization_domain_status_title - 根据 key 前缀自动上传对应名称表
- 上传前支持主动检索 key 是否重复,若重复上传失败
- 主动与用户确认是否删除之前准备的 json 文件
流程:
vbnet
扫描代码,AI扫描代码提取Key和文案
↓
【第一步检测】本地文案相似性检查 (AI执行)
├─ 发现相似 → 询问用户是否复用现有Key
└─ 无相似 → 继续
↓
生成JSON文件(仅包含需要新建的Key)
↓
用户确认JSON内容
↓
【第二步检测】Airtable Key存在性检查 (脚本执行)
├─ Key已存在 → 跳过写入
└─ Key不存在 → 写入Airtable
↓
显示结果统计
↓
【第三步:必须步骤】询问用户是否删除临时JSON文件!
↓
用户明确说"删除"后才执行删除需要注意的是,ts 文件中可能会存在多语言枚举的 key 配置,有时我们也会直接在 ts 方法里直接调用 domain 的 intl 使用多语言,目前 AI 对于这种复杂场景只能说尽可能去实现,在 AI 做完自查替换后,还是需要大家人为检查是否有多语言是重复可复用的,是否有无用 key 的情况,但可以确定的是,本流程的确能帮助大家节省大量新建 key 或自己替换 key 的时间。
关于用法,可基于所有改动或者指定文件让 AI 扫描:
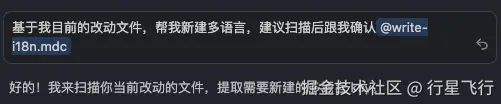
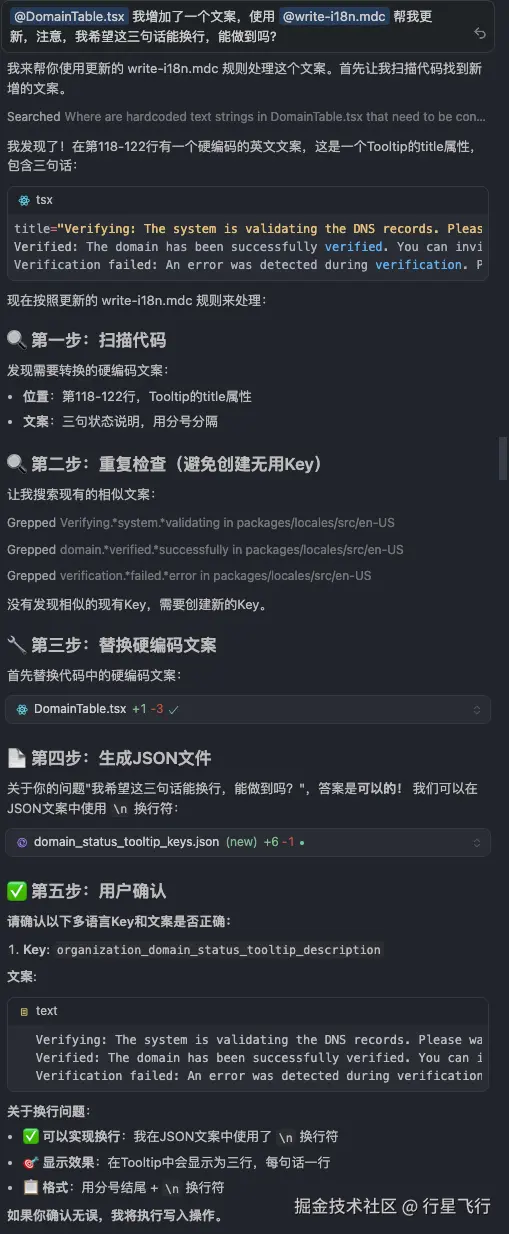
不同公司多语言体系不同,这里我分享下我的多语言 rule,脚本大家可以根据自己的多语言平台看是否要定义:
markdown
---
description:
globs:
alwaysApply: false
---
# 多语言 Key 写入工具使用说明
## 🎯 工具用途
AI 助手专用工具,用于将多语言 Key 扫描与批量写入 Airtable 对应表格。
## 📋 使用方法
### 基本命令
```bash
# 测试API连接
node scripts/write_i18n_keys.js --test
# 从JSON文件批量写入Key
node scripts/write_i18n_keys.js --file keys.json
# 清理所有临时JSON文件
node scripts/write_i18n_keys.js --clean-all
```
## 🚀 AI 助手工作流程
当用户要求替换多语言时,AI 助手应按以下步骤执行:
### 流程大纲
扫描代码,AI 扫描代码提取 Key 和文案
↓
【第一步检测】本地文案相似性检查 (AI 执行)
├─ 发现相似 → 询问用户是否复用现有 Key
└─ 无相似 → 继续
↓
生成 JSON 文件(仅包含需要新建的 Key,换行文案使用\n)
↓
用户确认 JSON 内容
↓
【第二步检测】Airtable Key 存在性检查 (脚本执行)
├─ Key 已存在 → 跳过写入
└─ Key 不存在 → 写入 Airtable
↓
显示结果统计
↓
【第三步:🚨 必须步骤】询问用户是否删除临时 JSON 文件!
↓
用户明确说"删除"后才执行删除
### 1. 替换硬编码文案为 `intl.formatMessage({id: "key"})`或者多语言 key
- 扫描用户当前改动文件或用户主动提供的文件中所有硬编码文案,要求扫描 .tsx 和 .ts 文件,重要强调。
- 将 .tsx 中硬编码文案替换为 `intl.formatMessage({id: "key"})`
- 将 .ts 配置中硬编码文案替换为 key 或者 `intl.formatMessage({id: "key"})`,重要提醒,这里取决具体实现方案,若存疑请主动询问用户。
- key 名遵守 `[模块名]_[功能]_[用途]`,比如 `organization_domain_status_title`,若存在疑问请主动询问用户由我来决策。
### 2. 扫描代码
- 收集所有 `intl.formatMessage({id: "key"})` 调用和 ts 中新增的 key
- 提取 Key 名称和对应的英文文案
### 3. 重复检查(避免创建无用 Key)
- **搜索现有 Key**:用 `grep` 在 `packages/locales/src/en-US/` 搜索相似文案
- **如发现相似**:展示对比,询问用户是复用现有 Key 还是创建新 Key
- **搜索关键词**:提取文案核心词汇进行模糊匹配
### 4. 生成 JSON 文件
```json
// 示例:临时生成keys.json(仅包含真正需要新建的Key)
[
{ "key": "organization_domain_add_button", "text": "Add Domain" },
{ "key": "organization_domain_delete_title", "text": "Delete Domain" },
{
"key": "organization_domain_status_tooltip",
"text": "Line 1: First line text;\nLine 2: Second line text;\nLine 3: Third line text."
}
]
```
**换行文案处理:** JSON 中用 `\n` 换行,前端加 `style={{ whiteSpace: 'pre-line' }}`
### 5. 用户确认
- **必须步骤**:展示生成的 JSON 内容给用户确认
- 明确列出所有 key 名称和对应的英文文案
- **等待用户明确同意**后才能进入下一步
### 6. 执行写入命令
```bash
# 写入Key(不使用--cleanup参数)
node scripts/write_i18n_keys.js --file generated_keys.json
```
### 7. 检查结果
- 查看成功/失败/跳过的统计信息
- 在最终总结中查看具体的失败 Key 名称和错误原因
- 在最终总结中查看具体的跳过 Key 名称
- 确认所有 Key 都已正确写入对应表
### 8. 🚨 清理临时文件(必须执行)
- **⚠️ 重要**:此步骤是流程的必要组成部分,不可省略
- **必须步骤**:询问用户是否删除临时 JSON 文件
- **等待用户明确说"删除"**才执行删除操作
## 🎯 Key 命名规范
### 格式要求
```
表名_功能_用途
```
### 示例
- `organization_domain_title` → organization 表
- `dashboard_analytics_chart` → dashboard 表
- `setting_profile_avatar` → setting 表
### 支持的表前缀
dashboard, record, folder, login, error, new_landingpage, new_languages, new_extension, referearn, setting, subscribe, uploader, common, meeting, live_screen_recording, scheduler, library, onboarding, organization
## 🔧 脚本功能特性
- **自动表识别**:根据 Key 前缀识别目标表,支持 29 张表
- **存在性检查**:自动跳过重复 Key,只写入新 Key
- **分批处理**:每批最多 10 条记录,大量 Key 自动分批
- **多表支持**:单次可写入多张表,按表分组处理
## ⚠️ 注意事项
- **Key 命名**:必须遵循前缀规范,否则无法识别目标表
- **权限配置**:确保 Airtable Token 有写入权限
- **批量限制**:每批最多 10 条记录
- **文件删除**:必须询问用户确认后才能删除临时文件
## 🔗 相关文件
- `scripts/write_i18n_keys.js` - 主脚本文件
- `scripts/generated_*.json` - 临时生成的 Key 文件最后,多语言检测不要用 GPT5 执行,效果比 claude 4 差很多,这点单独提醒下。