🔥🔥 AllData大数据产品是可定义数据中台,以数据平台为底座,以数据中台为桥梁,以机器学习平台为中层框架,以大模型应用为上游产品,提供全链路数字化解决方案。
✨杭州奥零数据科技官网:http://www.aolingdata.com
✨Github项目:https://github.com/alldatacenter/alldata
✨Gitee项目:https://gitee.com/alldatacenter/alldata
✨AllData官方手册:https://www.yuque.com/aolingdata/product
✨AllData正式环境:http://43.138.156.44:5173/ui_moat
摘要:
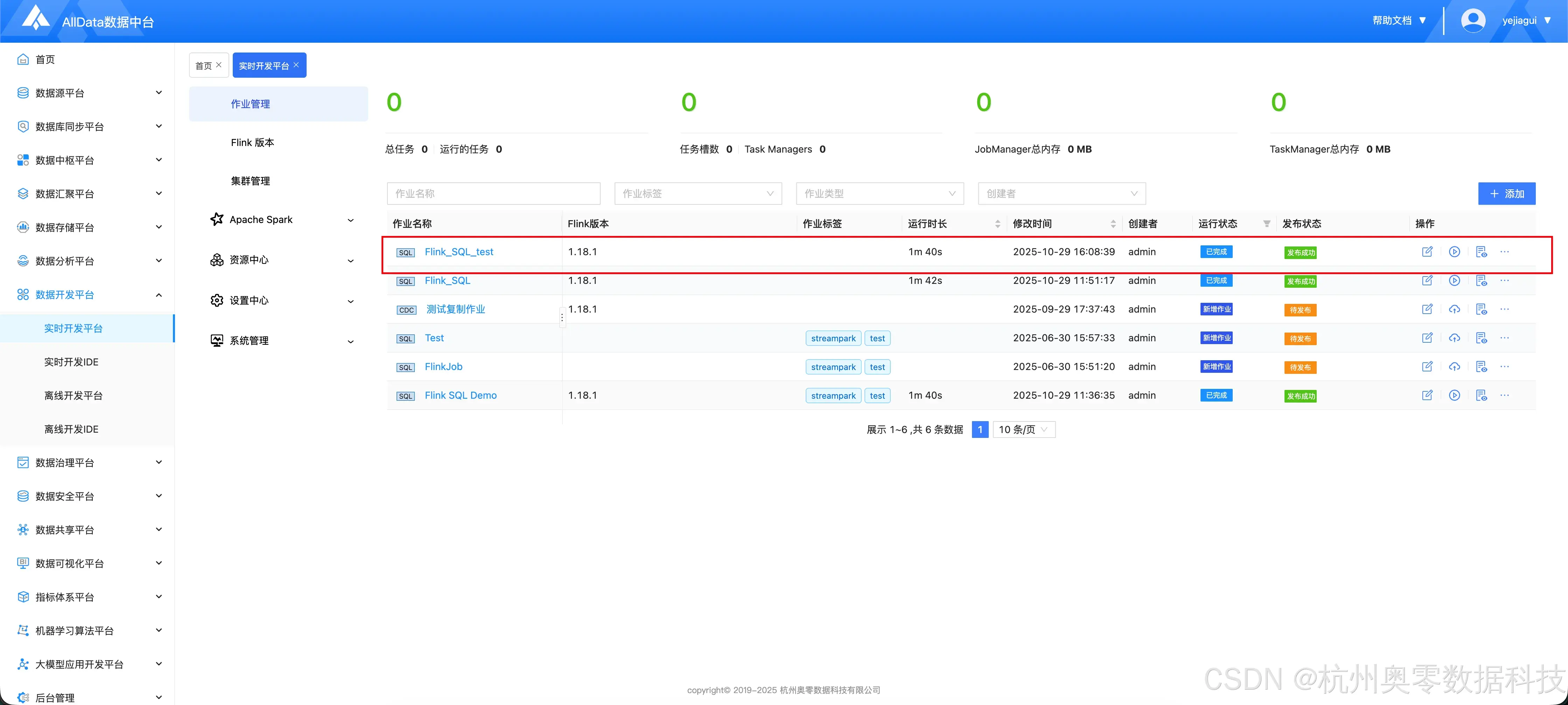
• 使用Flink StandaIone模式运行FIink SQL Demo
• Flink 安装包需要与 StreamPark 服务同在一台服务器

实时开发平台基于开源项目StreamPark建设
实时开发平台 StreamPark 提供了一系列快捷 API 和 Connector,开箱即用,作业状态自动追踪,快速完成作业的开发和管理。同时支持 Flink & Spark,无缝支持流式处理和批处理,连接互通,创造无限可能。
StreamPark 是一个流处理应用程序开发管理框架,旨在轻松构建和管理流处理应用程序,提供使用Flink 和 Spark 编写流处理应用的开发框架和一站式实时计算平台,核心能力包括不限于应用开发、部署、管理、运维、实时数仓等。
StreamPark 为流处理作业提供全生命周期支持,从开发到部署,集众多功能于一身,是一站式流处理平台。
- StreamPark开源项目:https://github.com/apache/streampark
- StreamPark文档:https://streampark.apache.org/docs/get-started/quick-start
1、FIink安装
1.1 下载
- Flink 版本:1.18.1
- 官网下载地址:https://archive.apache.org/dist/flink/flink-1.18.1/
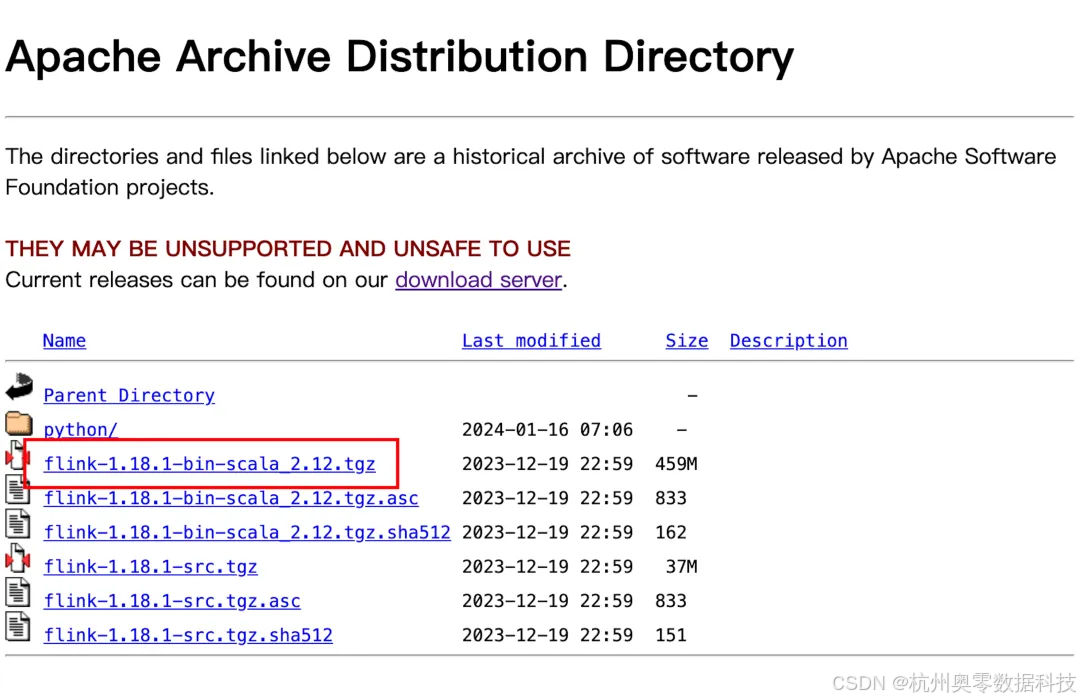
1.2 解压
- 上传服务器并解压
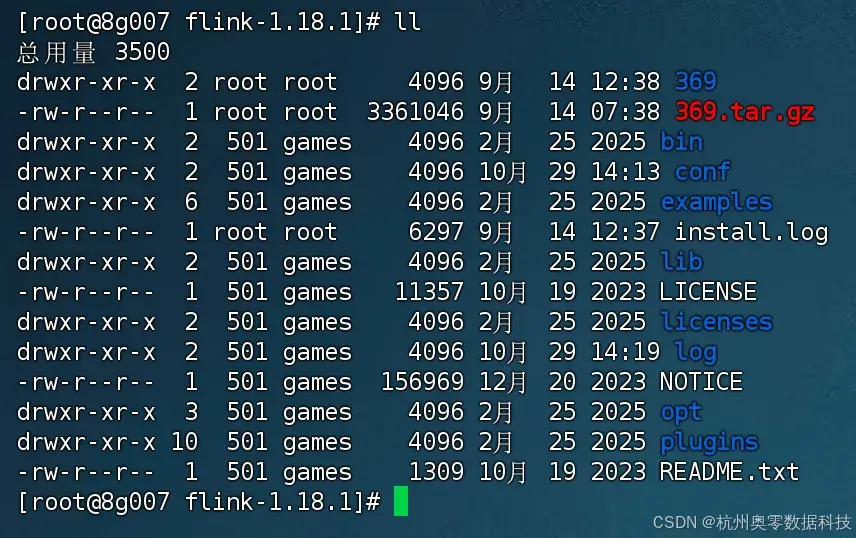
- 配置系统环境变量

- 添加以下内容

- 使配置生效

1.3 配置
- 进入conf目录

- 修改flink-conf.yaml 配置文件

- 修改以下内容

- 保存并提出
1.4 启动
- 进入bin目录

- 执行以下命令启动

2、Streampark
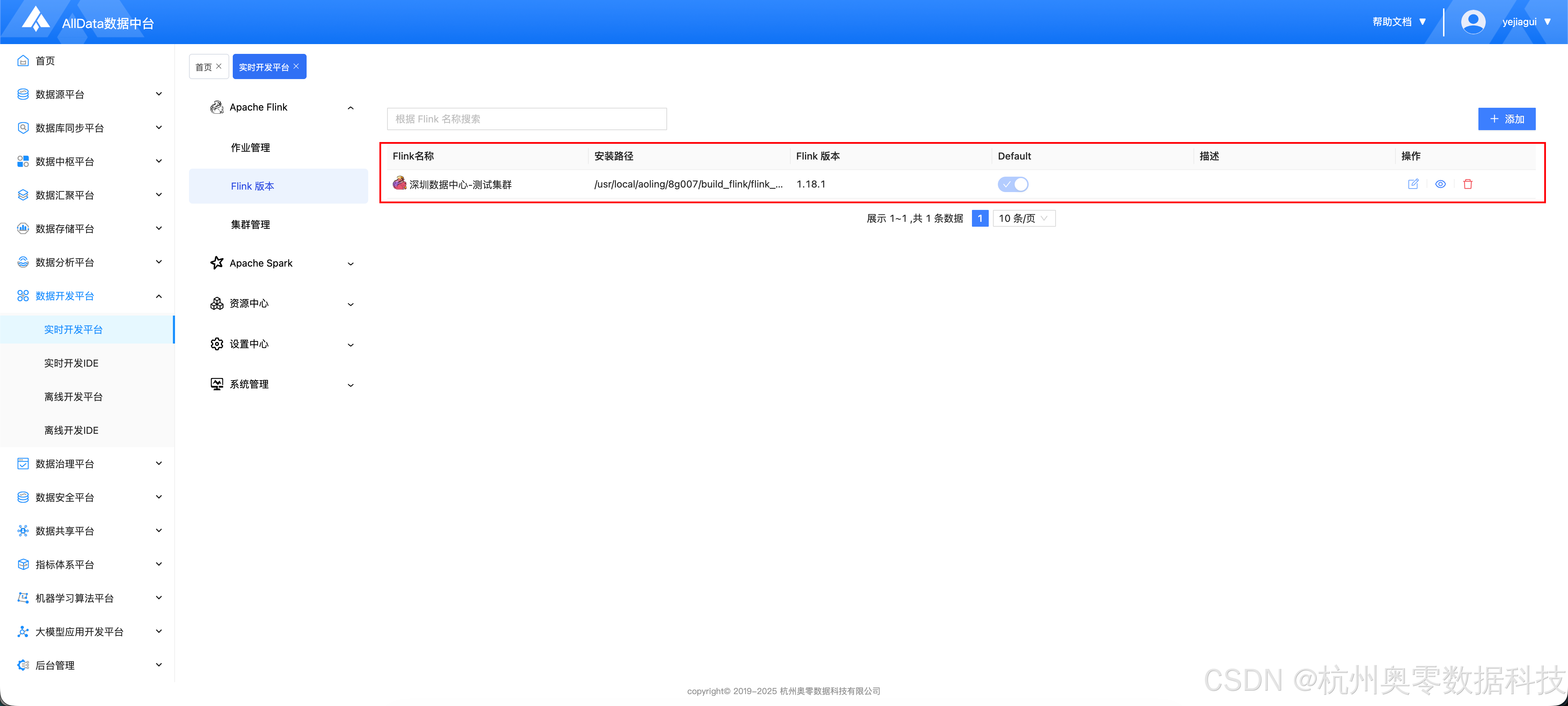
2.1 配置Flink版本
- 安装路径为服务器Flink的绝对路径
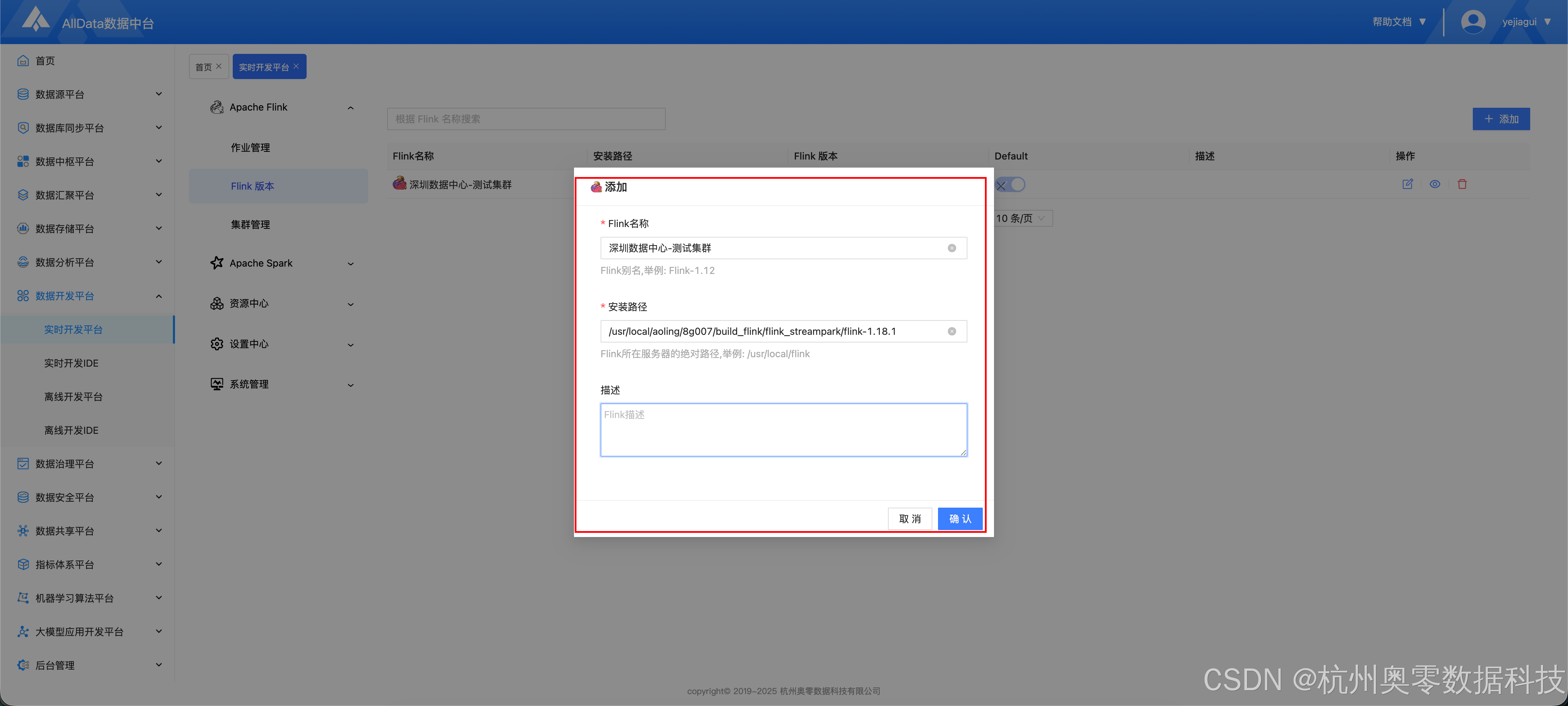
- 添加完成
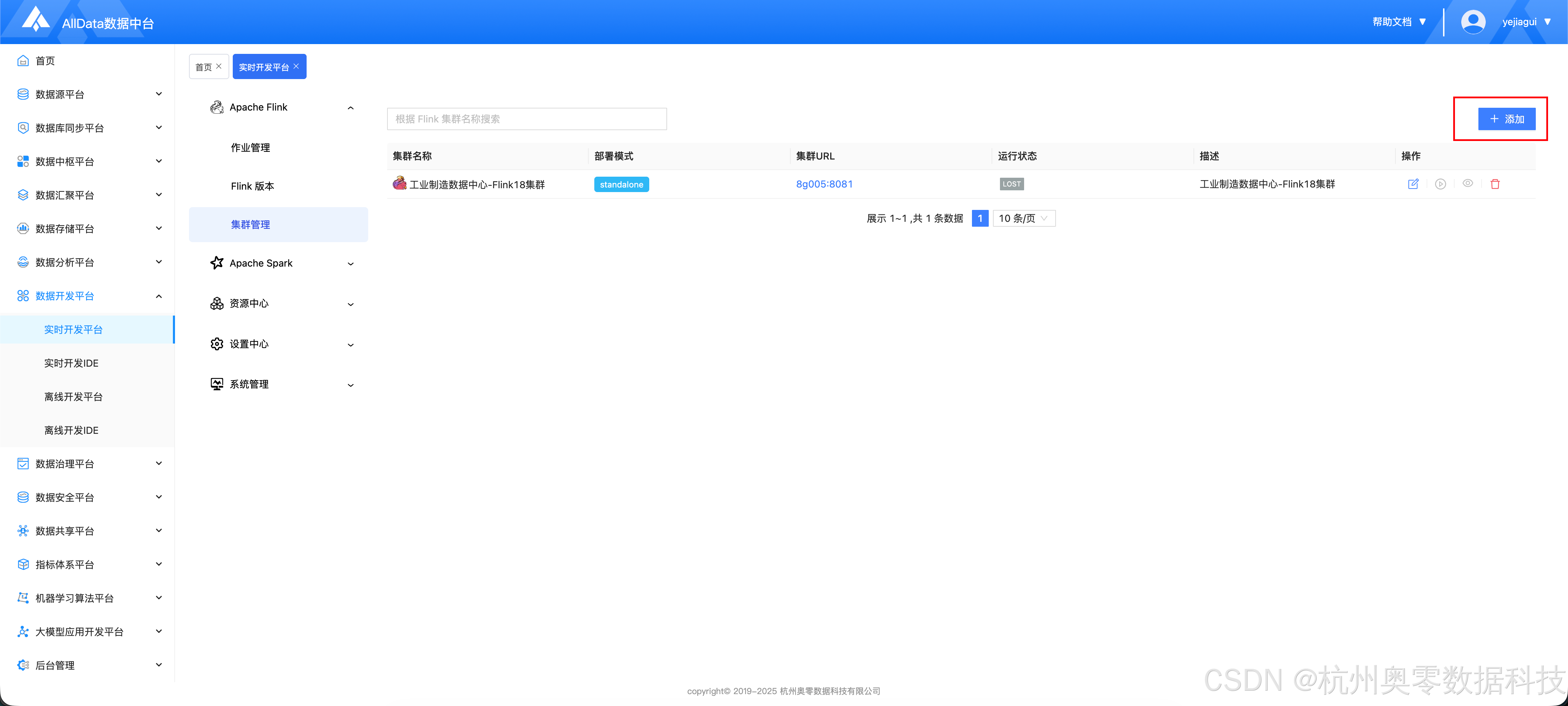
2.2 配置集群
- 进入集群管理页面,点击 "添加"
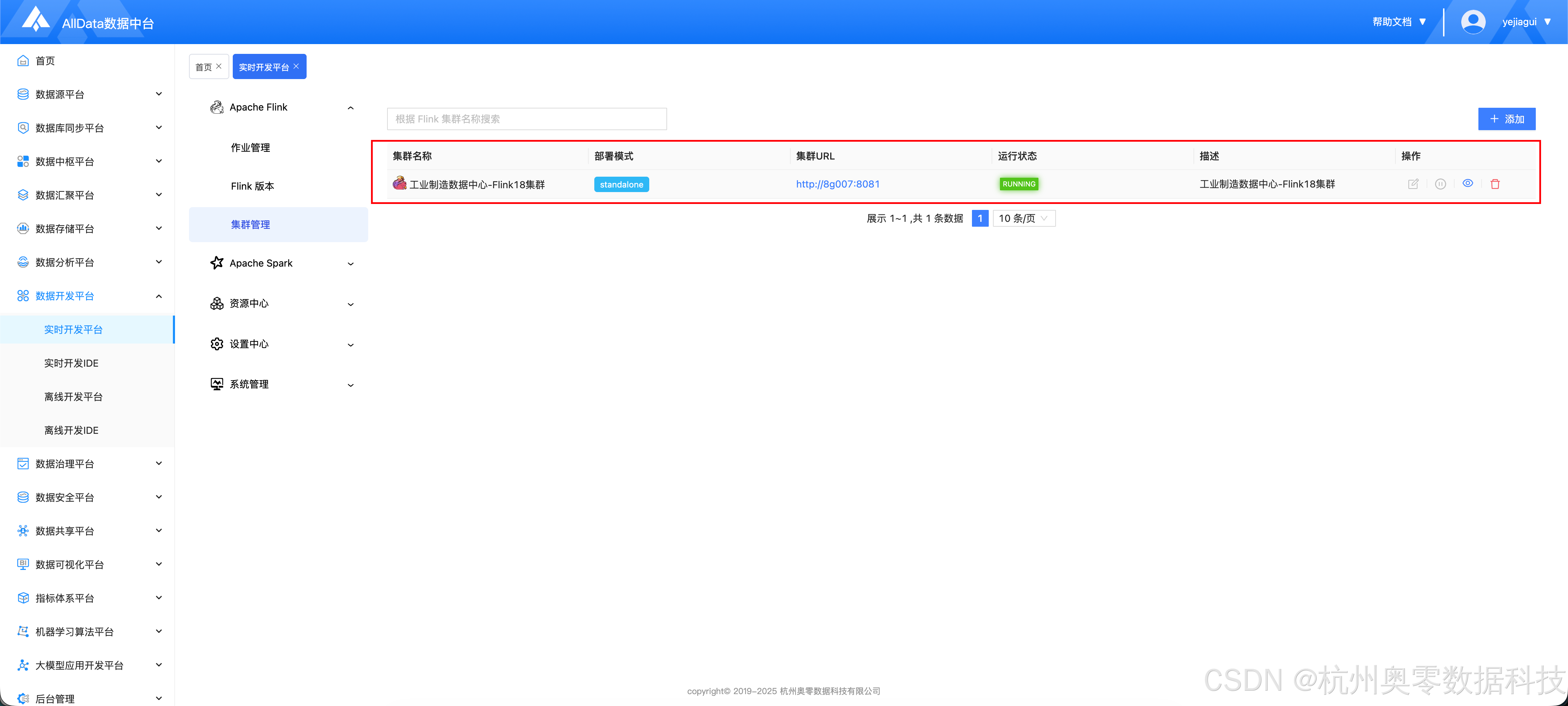
- 配置集群信息,点击 "提交"

- 配置完成
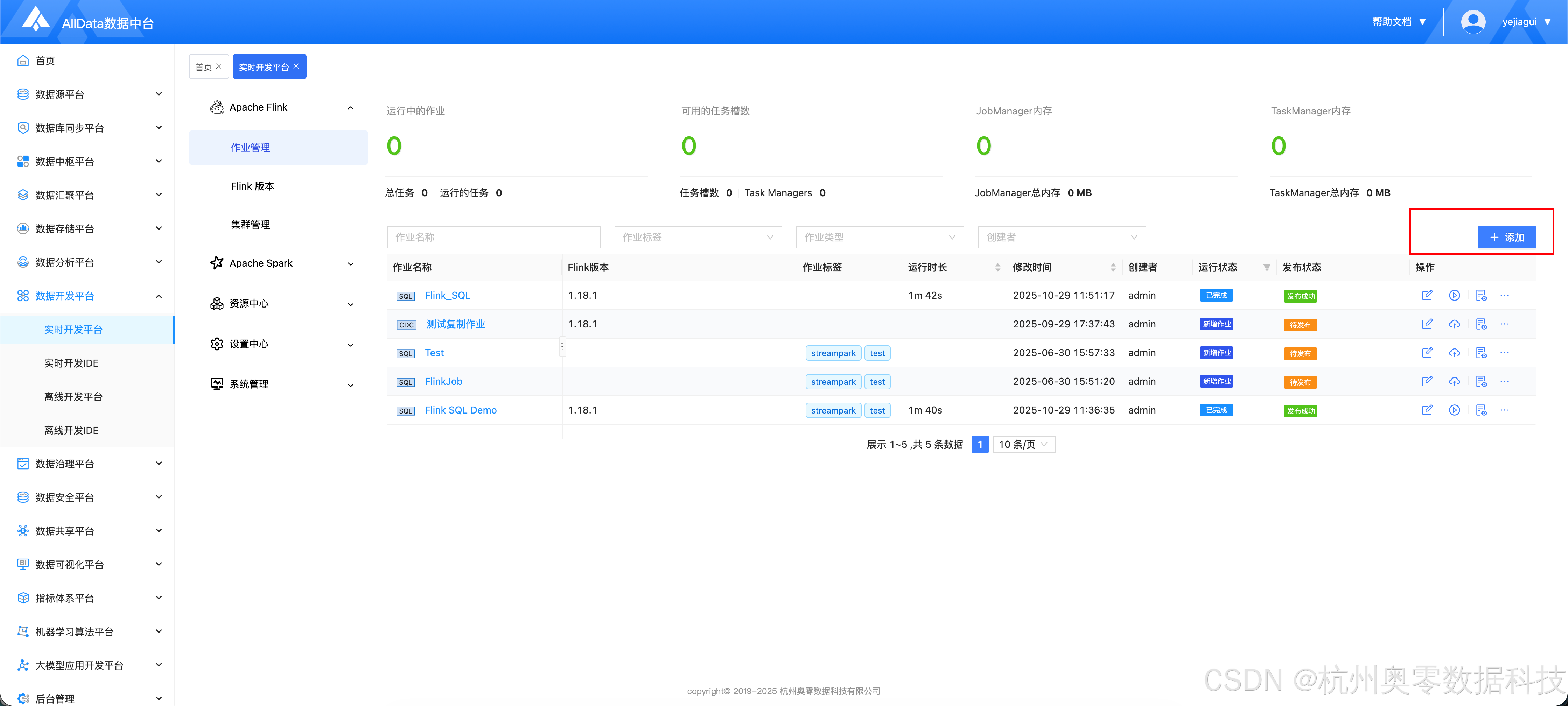
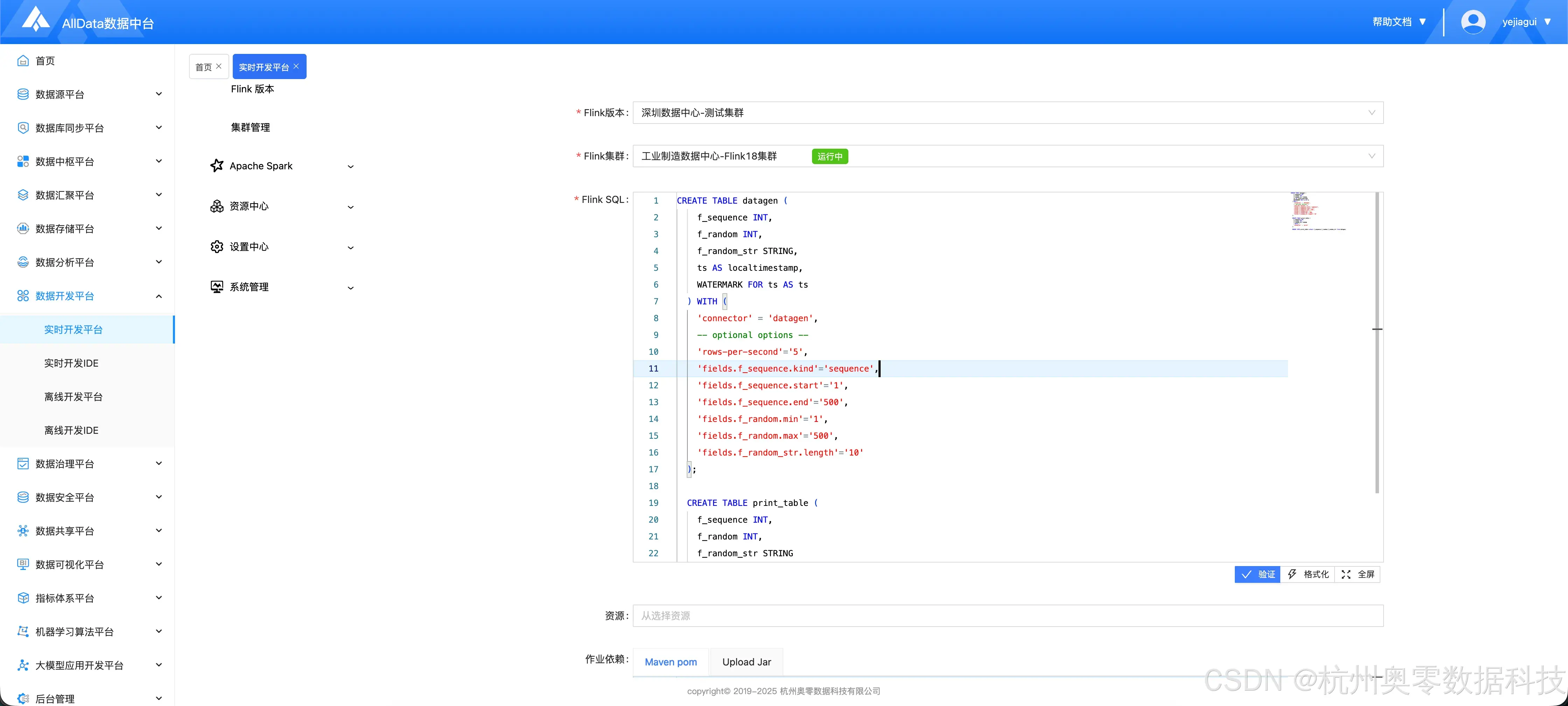
2.3 配置作业
- 进入作业管理,点击 "添加"
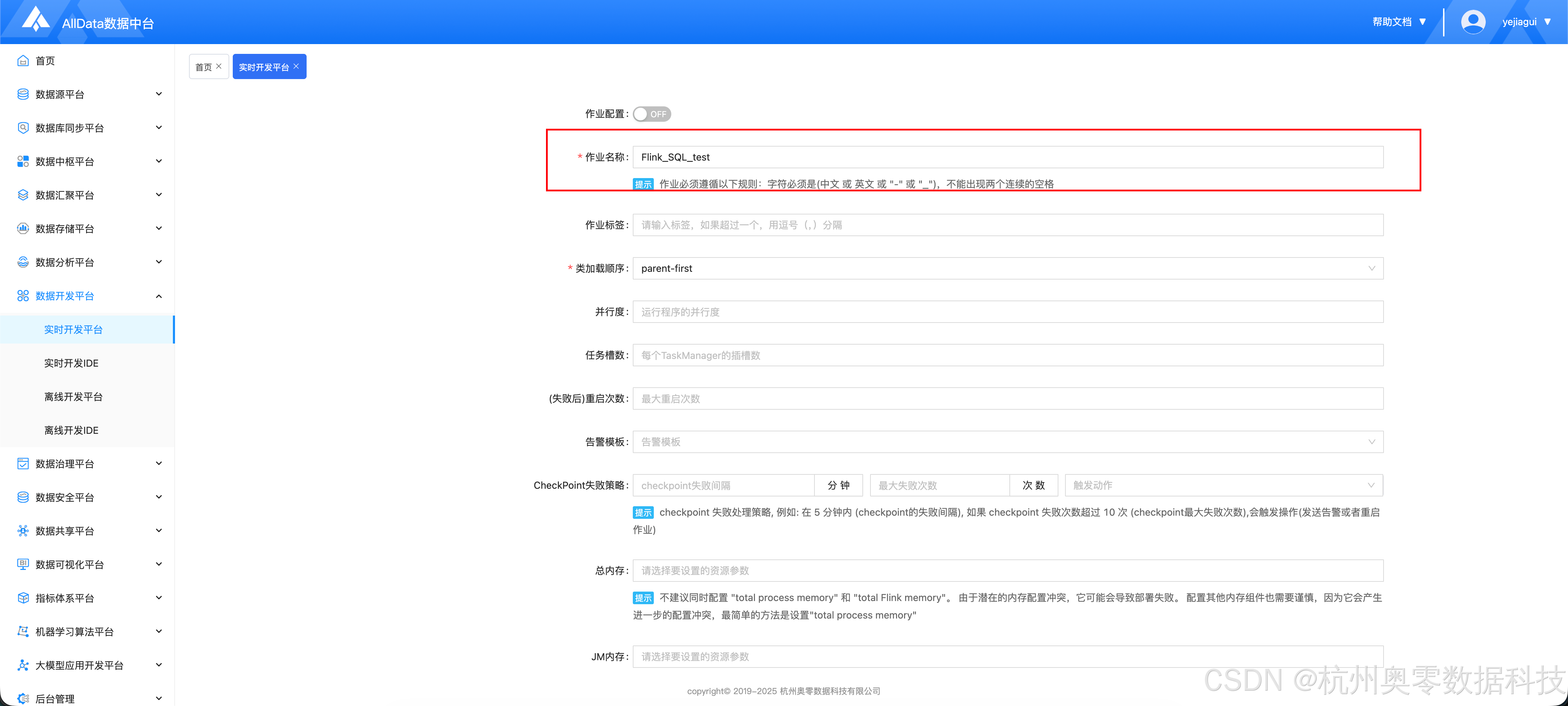
- 配置作业信息
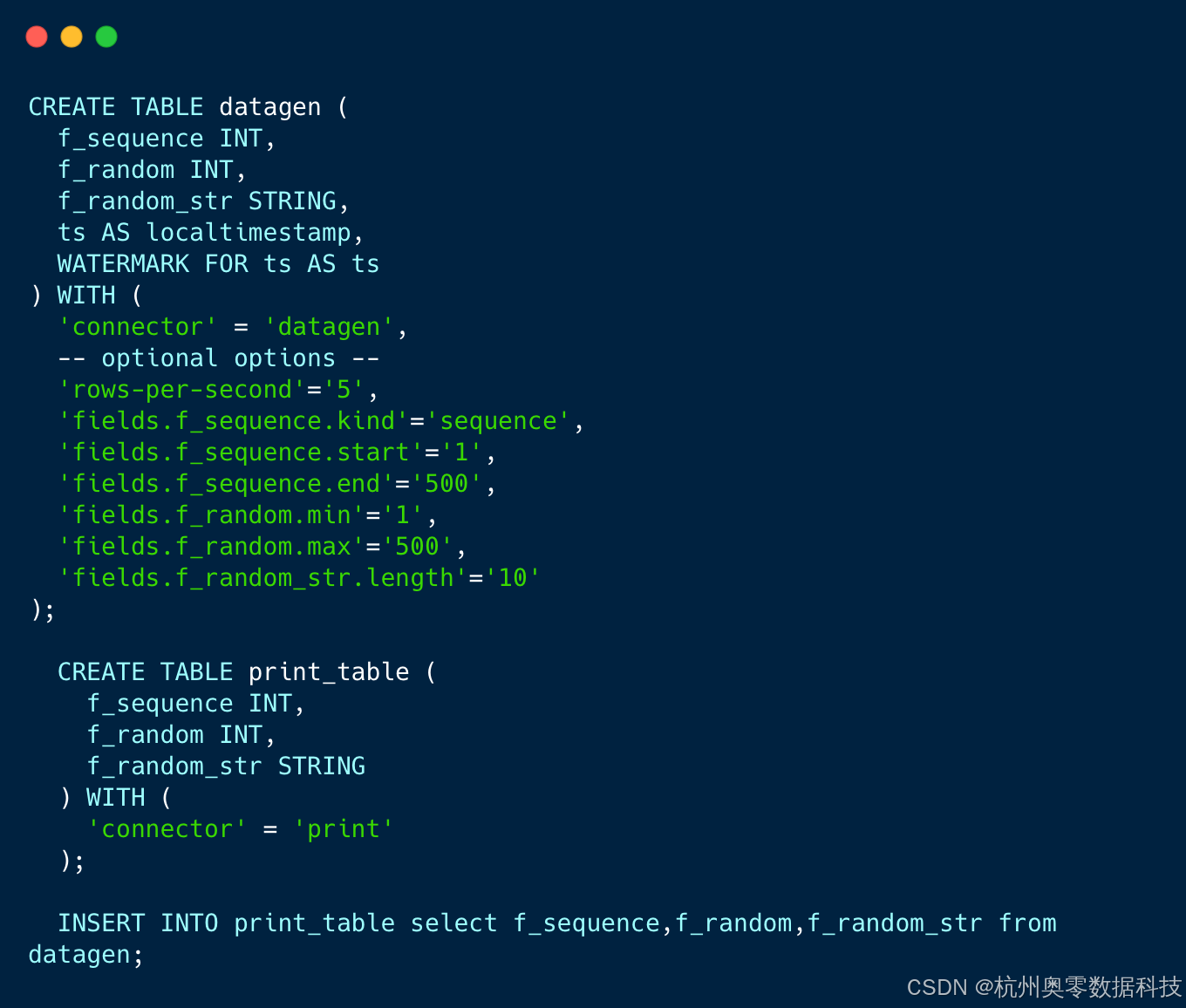
- FIink SQL
- 下滑到最下方,点击提交

2.4 发布作业
- 点击下图所示按钮
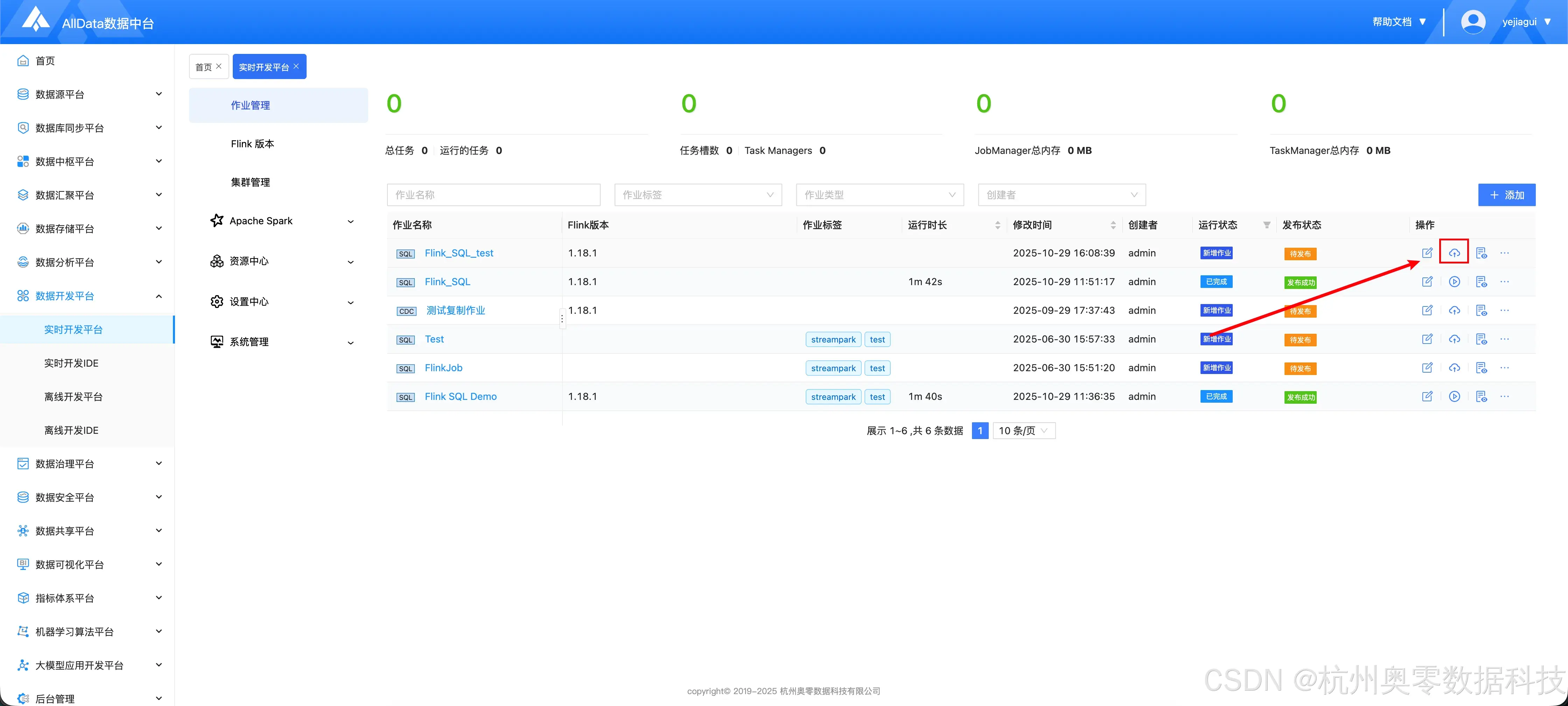
- 发布中
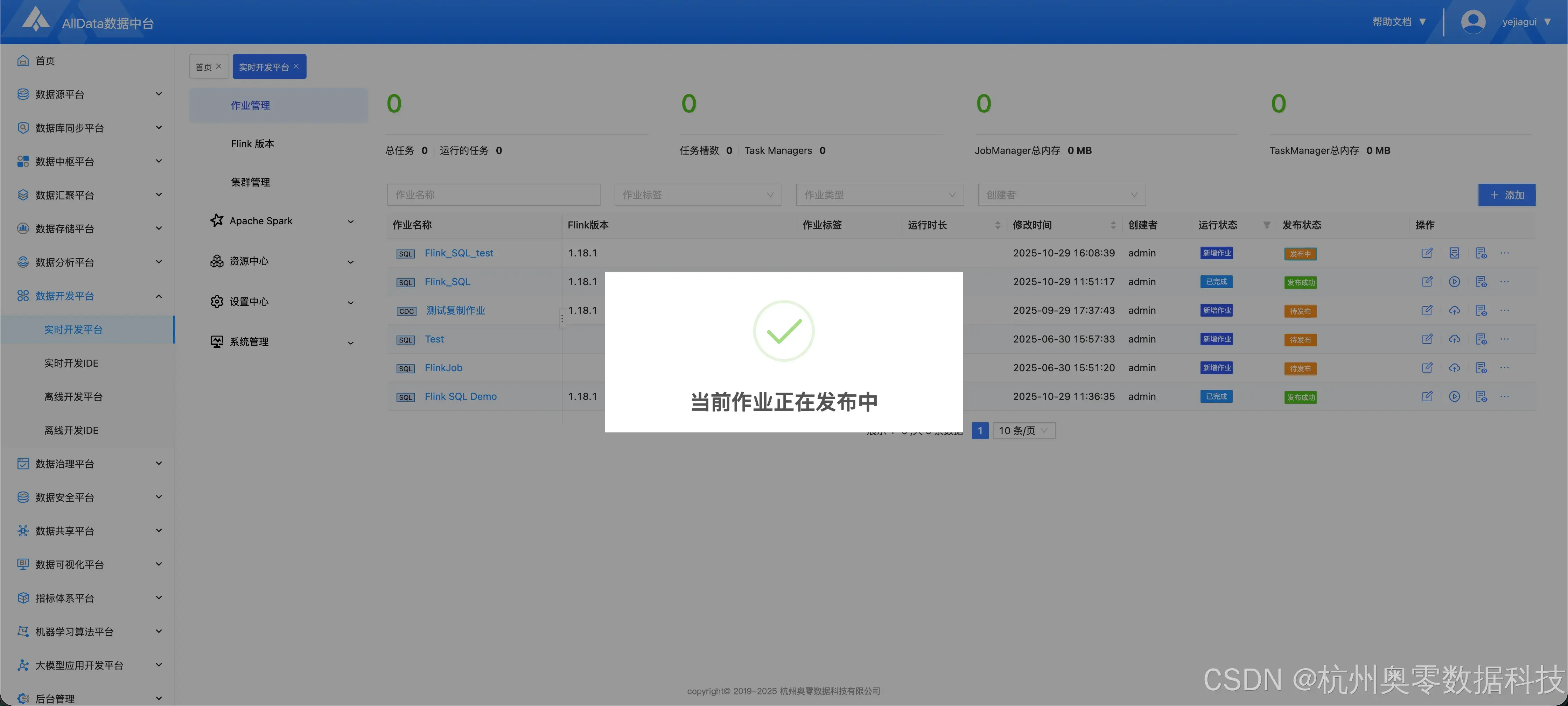
- 发布成功
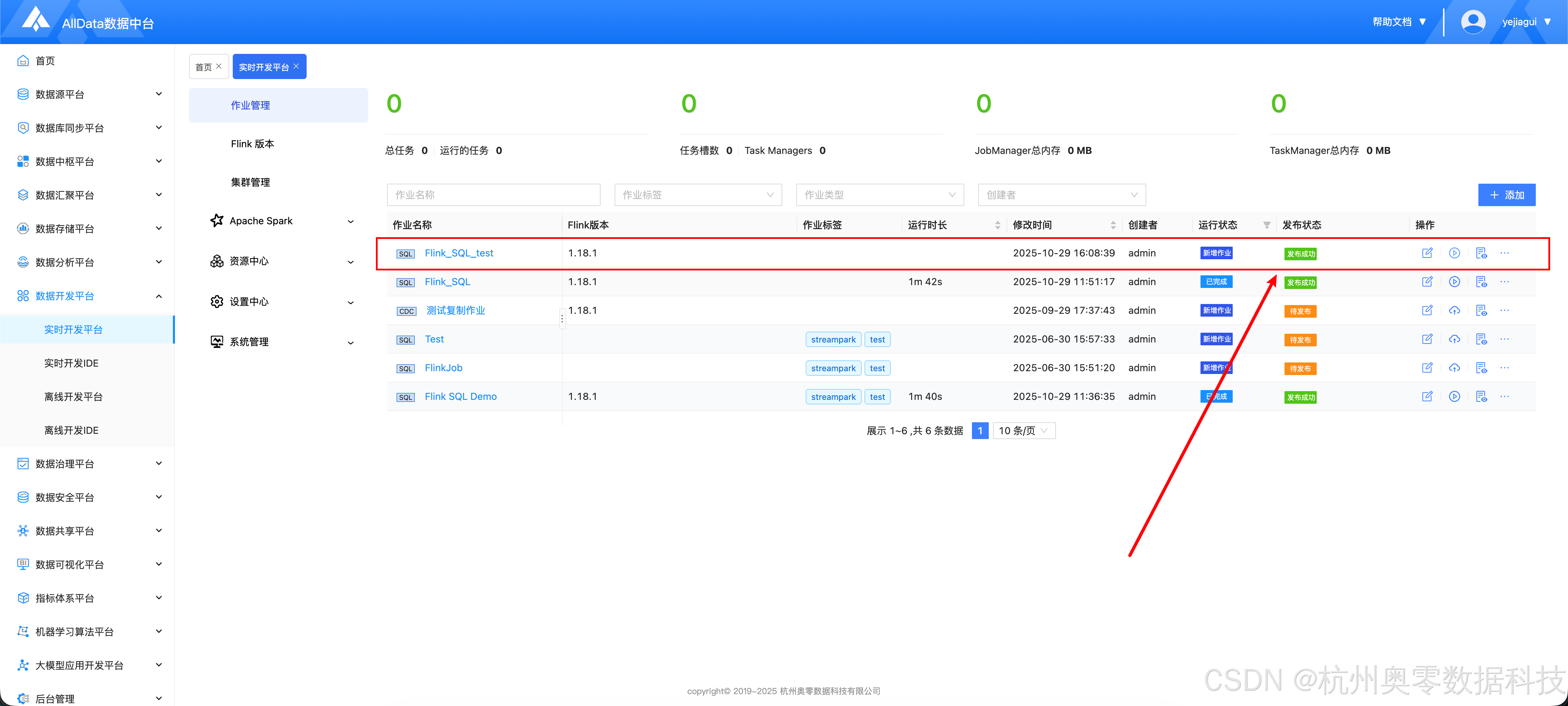
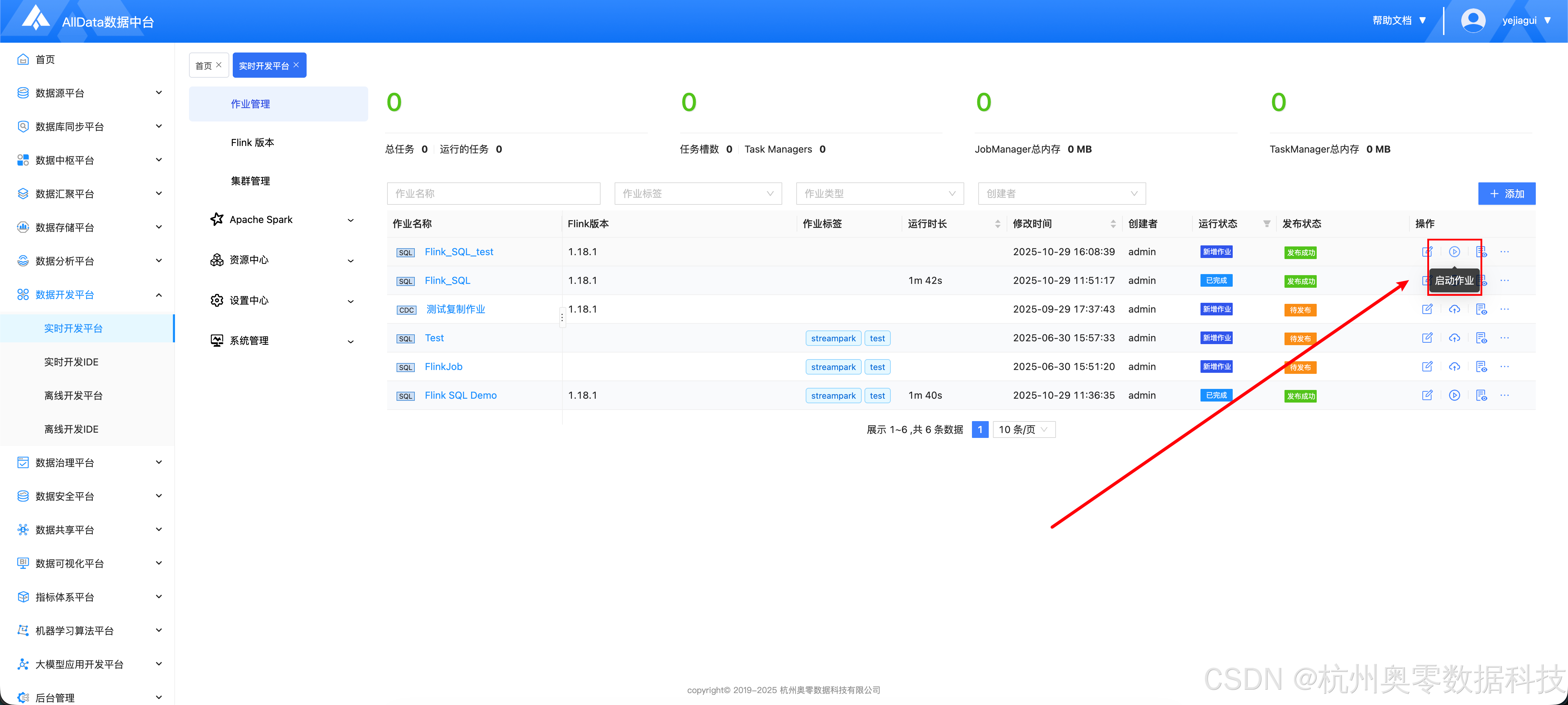
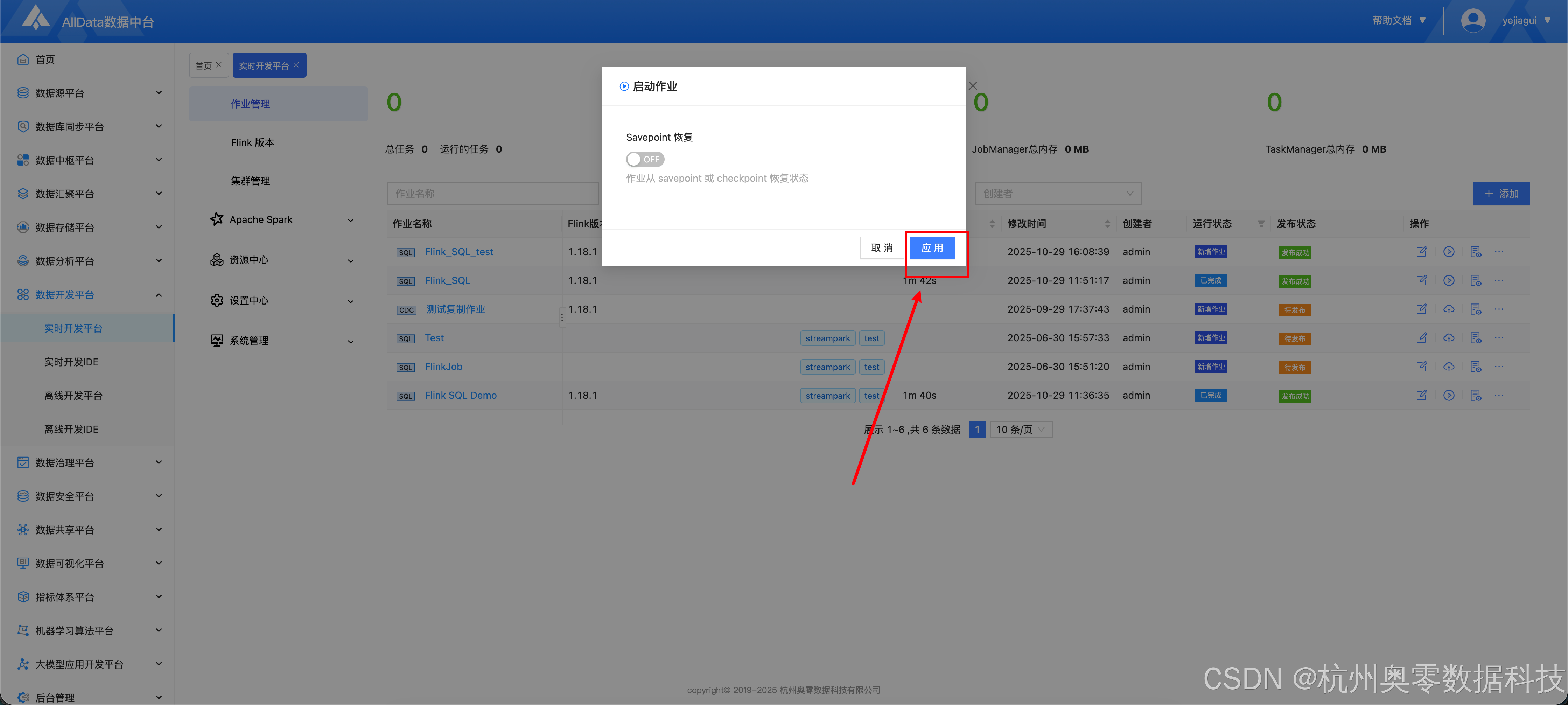
2.5 启动作业
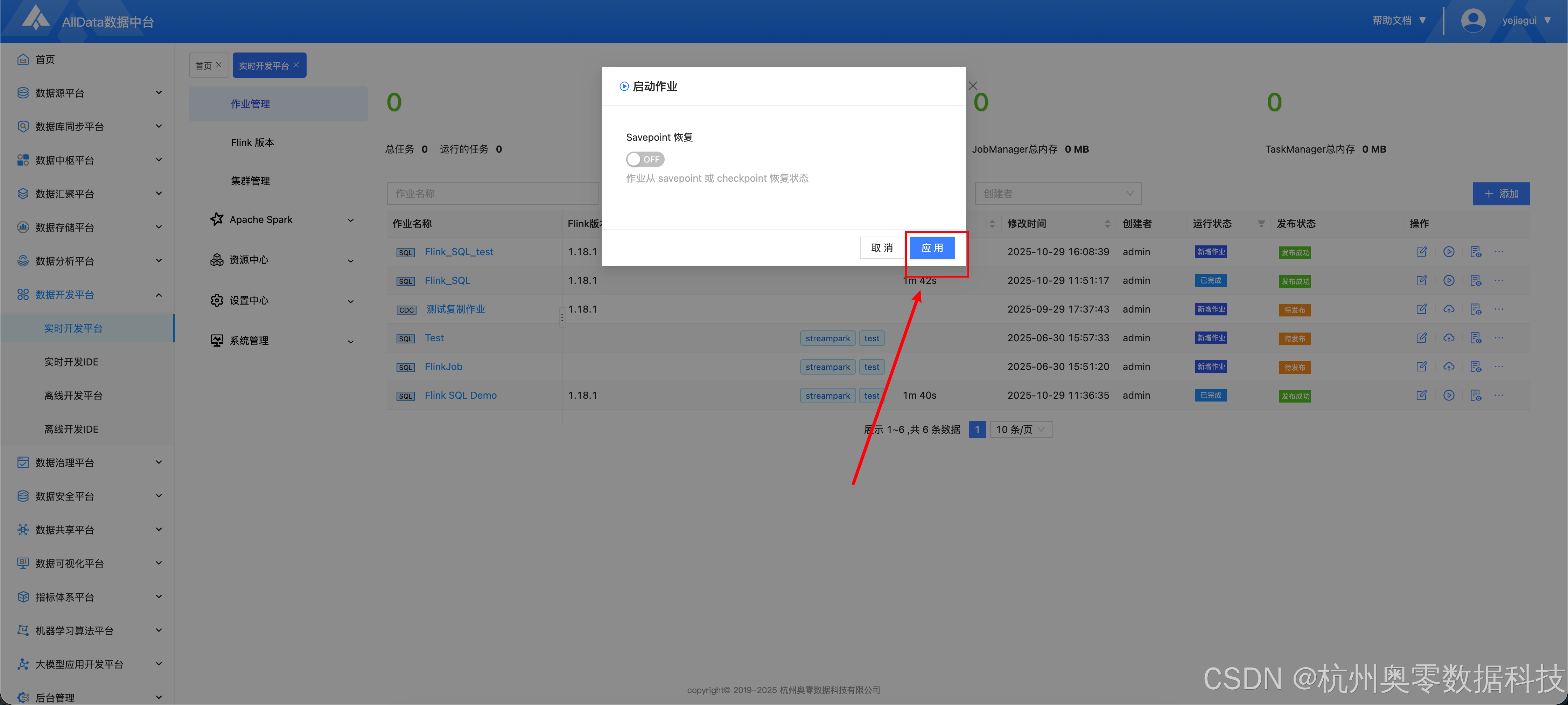
- 点击下图所示按钮,启动作业
- 点击应用
- 启动中
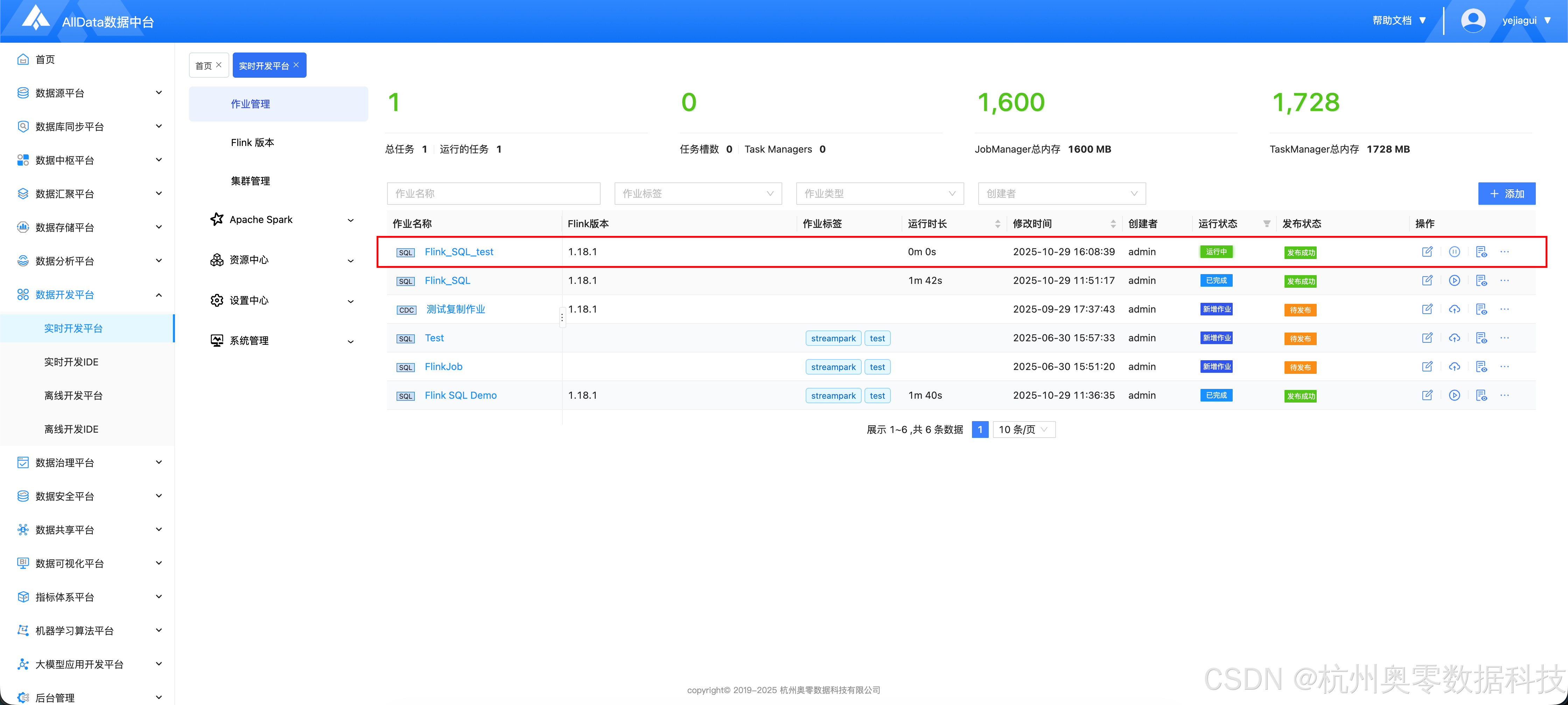
- 启动完成
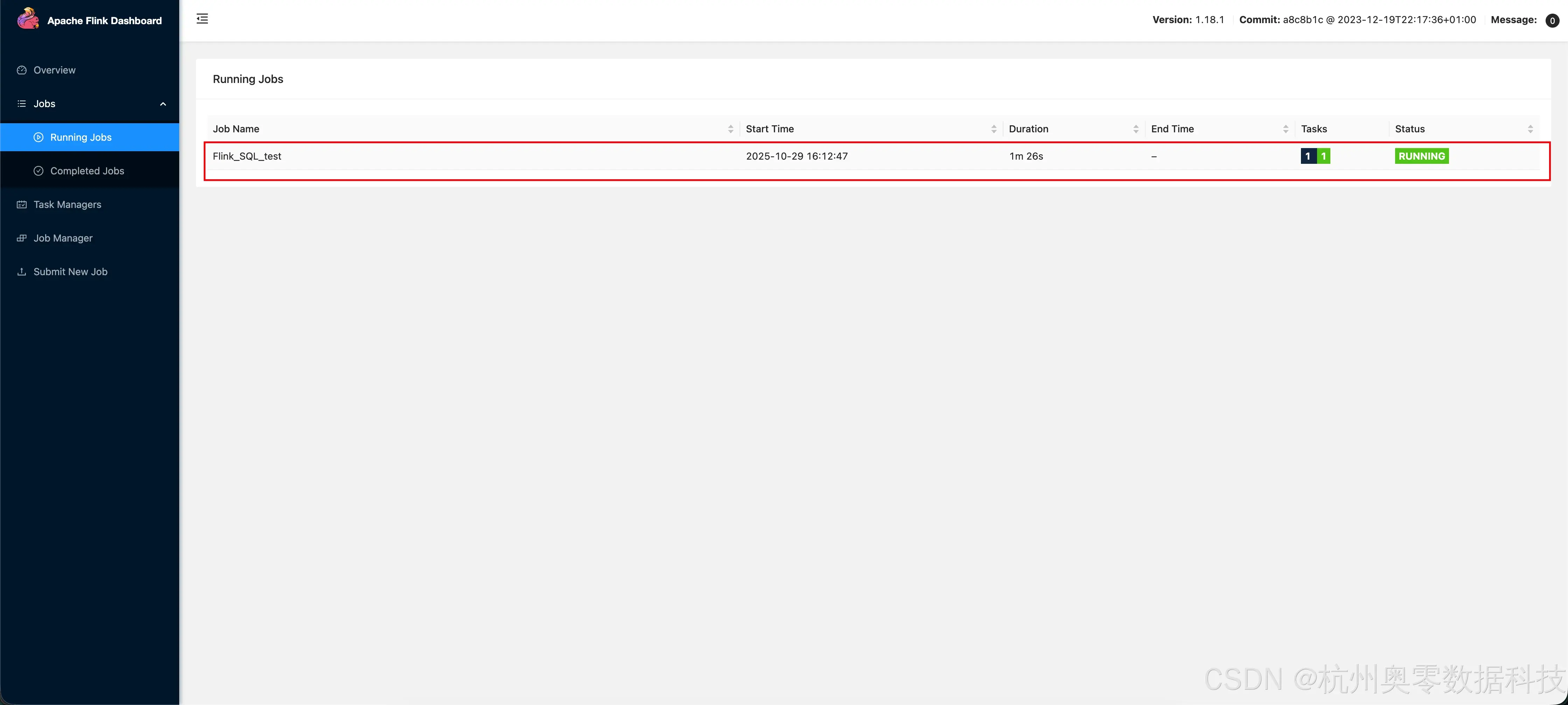
- 等待执行完成,可以访问 flink ui 查看执行情况 http://8g007:8081
- 8g007 为 flink安装所在服务器域名或ip,8081 为flink默认访问端口
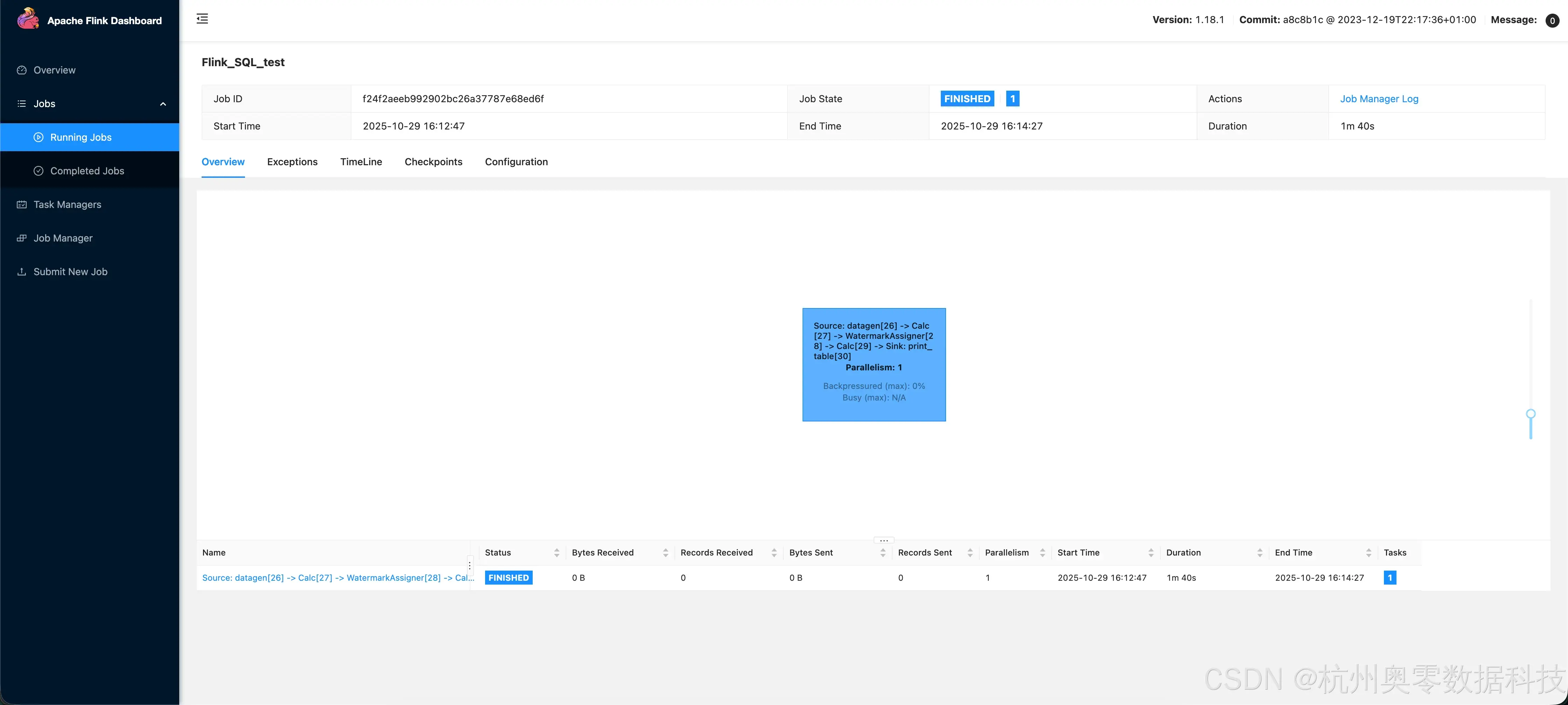
2.6 完成作业