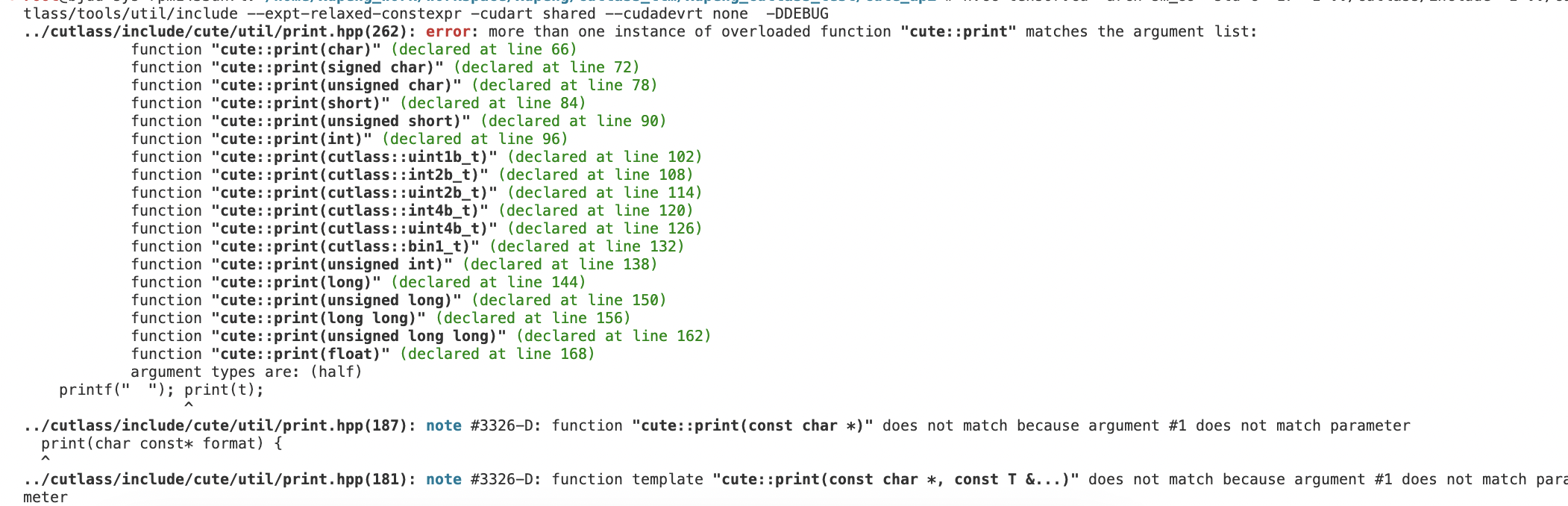
经过实践,cute中使用print_tensor打印一个tensor,如果类型是half是会直接编译不过的:
cpp
#include <cuda.h>
#include <stdlib.h>
#include <cute/tensor.hpp>
/*
cute中的Tensor更多的是对Tensor进行分解和组合等操作,而这些操作多是对Layout的变换(只是逻辑层面的数据组织形式),底层的数据实体一般不变更。
Tensor = Layout + storage
*/
// nvcc tensor.cu -arch=sm_89 -std=c++17 -I ../cutlass/include -I ../cutlass/tools/util/include --expt-relaxed-constexpr -cudart shared --cudadevrt none -DDEBUG
using namespace cute;
using namespace std;
#define PRINT(name, content) \
print(name); \
print(" : "); \
print(content); \
print("\n");
#define PRINTTENSOR(name, content) \
print(name); \
print(" : "); \
print_tensor(content); \
print("\n");
template<typename T>
__global__ void handle_global_tensor(T *pointer)
{
auto gshape = make_shape(Int<4>{}, Int<6>{});
auto gstride = make_stride(Int<6>{}, Int<1>{});
auto gtensor = make_tensor(make_gmem_ptr(pointer), make_layout(gshape, gstride));
PRINTTENSOR("global tensor", gtensor);
}
int main()
{
// register tensor
// handle_regiser_tensor<<<1, 1>>>();
// global memory tensor
using T = half;
T *pointer;
int size = 4 * 6;
cudaMalloc(&pointer, size * sizeof(T));
T *cpointer = (T *)malloc(size * sizeof(T));
for (int i = 0; i < size; i++)
{
cpointer[i] = (T)i;
}
cudaMemcpy(pointer, cpointer, size * sizeof(int), cudaMemcpyHostToDevice);
handle_global_tensor<T><<<1, 1>>>(pointer);
cudaDeviceSynchronize();
return 0;
}
如果类型换成int或者float,是可以成功打印的:
cpp
#include <cuda.h>
#include <stdlib.h>
#include <cute/tensor.hpp>
/*
cute中的Tensor更多的是对Tensor进行分解和组合等操作,而这些操作多是对Layout的变换(只是逻辑层面的数据组织形式),底层的数据实体一般不变更。
Tensor = Layout + storage
*/
// nvcc tensor.cu -arch=sm_89 -std=c++17 -I ../cutlass/include -I ../cutlass/tools/util/include --expt-relaxed-constexpr -cudart shared --cudadevrt none -DDEBUG
using namespace cute;
using namespace std;
#define PRINT(name, content) \
print(name); \
print(" : "); \
print(content); \
print("\n");
#define PRINTTENSOR(name, content) \
print(name); \
print(" : "); \
print_tensor(content); \
print("\n");
template<typename T>
__global__ void handle_global_tensor(T *pointer)
{
auto gshape = make_shape(Int<4>{}, Int<6>{});
auto gstride = make_stride(Int<6>{}, Int<1>{});
auto gtensor = make_tensor(make_gmem_ptr(pointer), make_layout(gshape, gstride));
PRINTTENSOR("global tensor", gtensor);
}
int main()
{
using T = float;
T *pointer;
int size = 4 * 6;
cudaMalloc(&pointer, size * sizeof(T));
T *cpointer = (T *)malloc(size * sizeof(T));
for (int i = 0; i < size; i++)
{
cpointer[i] = (T)i;
}
cudaMemcpy(pointer, cpointer, size * sizeof(int), cudaMemcpyHostToDevice);
handle_global_tensor<T><<<1, 1>>>(pointer);
cudaDeviceSynchronize();
return 0;
}
惊喜发现,不能直接用half,得用cute::half_t,这样的是可以打印的
cpp
#include <cuda.h>
#include <stdlib.h>
#include <cute/tensor.hpp>
/*
cute中的Tensor更多的是对Tensor进行分解和组合等操作,而这些操作多是对Layout的变换(只是逻辑层面的数据组织形式),底层的数据实体一般不变更。
Tensor = Layout + storage
*/
// nvcc tensor.cu -arch=sm_89 -std=c++17 -I ../cutlass/include -I ../cutlass/tools/util/include --expt-relaxed-constexpr -cudart shared --cudadevrt none -DDEBUG
using namespace cute;
using namespace std;
#define PRINT(name, content) \
print(name); \
print(" : "); \
print(content); \
print("\n");
#define PRINTTENSOR(name, content) \
print(name); \
print(" : "); \
print_tensor(content); \
print("\n");
template<typename T>
__global__ void handle_global_tensor(T *pointer)
{
auto gshape = make_shape(Int<4>{}, Int<6>{});
auto gstride = make_stride(Int<6>{}, Int<1>{});
auto gtensor = make_tensor(make_gmem_ptr(pointer), make_layout(gshape, gstride));
PRINTTENSOR("global tensor", gtensor);
}
int main()
{
using T = cute::half_t;
// using T = half;
T *pointer;
int size = 4 * 6;
cudaMalloc(&pointer, size * sizeof(T));
T *cpointer = (T *)malloc(size * sizeof(T));
for (int i = 0; i < size; i++)
{
cpointer[i] = 1;
}
cudaMemcpy(pointer, cpointer, size * sizeof(T), cudaMemcpyHostToDevice);
handle_global_tensor<T><<<1, 1>>>(pointer);
cudaDeviceSynchronize();
return 0;
}