科大讯飞AI大赛(多模态RAG方向) - Datawhale
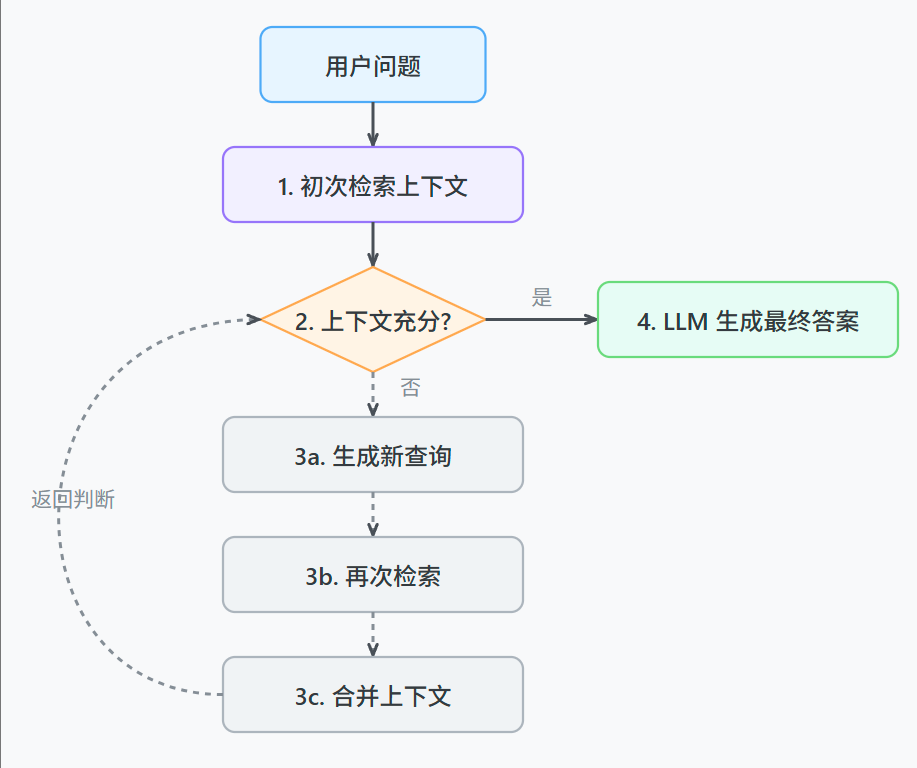
项目流程图
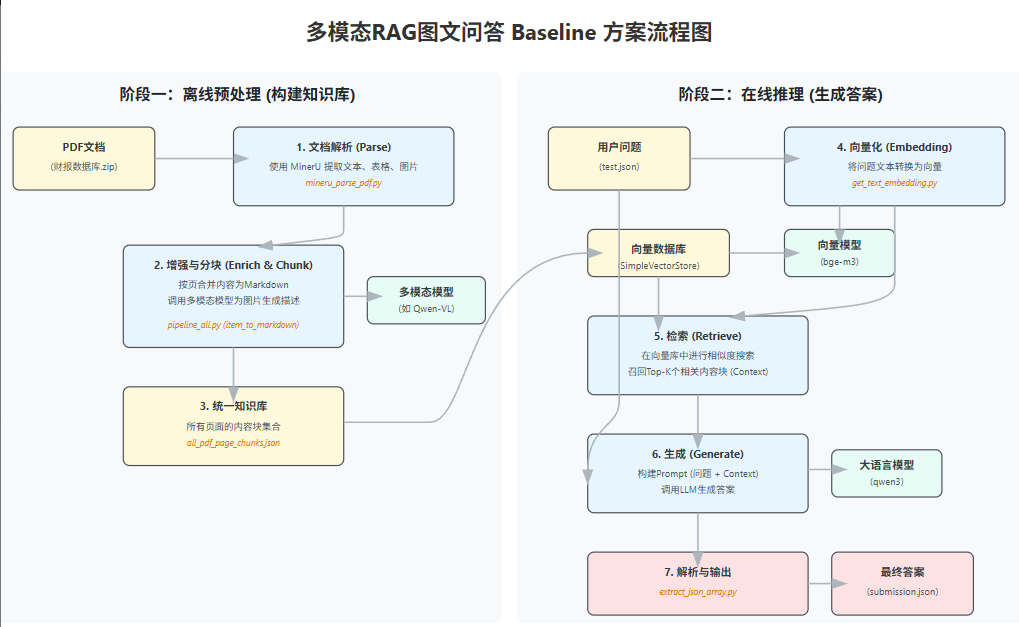
1、升级数据解析方案:从 fitz 到 MinerU
PyMuPDF(fitz)是基于规则的方式提取pdf里面的数据;MinerU是基于深度学习模型通过把PDF内的页面看成是图片进行各种检测,识别的方式提取。
(1)识别表格 :将表格转化为结构化的Markdown或JSON格式。
(2)提取图片 :对文档中的图片进行识别。
(3)图片描述 :(可选)调用多模态模型为提取出的图片生成文字说明。
这会为后续的RAG流程提供包含表格和图片信息的、更丰富且更精确的上下文,是解决多模态问题的关键举措。
-
基础方案所使用的 fitz 工具仅能提取文本,会遗漏表格、图片等关键信息。
-
**MinerU 的优势:**对PDF进行深度的版面分析,除了能更精准地提取文本块外,还具备以下功能:
-
因此转而使用
mineru_pipeline_all.py脚本,具体操作如下:
bash
# 建议在GPU环境下运行,执行完大约需要1.5h
python mineru_pipeline_all.py报错:系统网络无法访问外网 huggingface.co,导致 Mineru 无法下载所需的 PDF 处理模型。
解决方法:在 mineru_pipeline_all.py 文件开头添加环境变量设置:
bash
os.environ['MINERU_MODEL_SOURCE'] = "modelscope"这将使 Mineru 从 ModelScope(阿里云模型库)下载模型,避免因网络问题无法访问 Hugging Face,下载到的是OpenDataLab的MinerU2.0-2505-0.9B模型。
mineru_pipeline_all.py 文件中关键的有两个函数依次执行:
1、parse_all_pdfs 函数------分析 PDF 的版面布局,识别出里面的文本、标题、表格和图片 ,然后把这些识别出的所有内容元素,连同它们的类型、位置、层级等信息,都存进一个名为 _content_list.json 的文件里。
2、process_all_pdfs_to_page_json 函数------读取 _content_list.json ,先按页码把内容分好组,然后逐个处理每一页里的内容项,里面内嵌了一个item_to_markdown 函数,这个函数是一个转换器,它根据内容项的类型( text、table、image)来决定如何转换成MarkDown格式,而且代码会检查图片本身有没有自带的文字描述( caption ),如果没有,并且我们允许进行视觉分析( enable_image_caption=True ),它就会调用一个**多模态大模型(代码里指定的是 Qwen/Qwen2.5-VL-32B-Instruct )**来给这张图片生成一段描述。
MinerU的输出:会是三种类型------text、table、image的集合(相比于fitz则完全是text,对图表也是提取text,完全丢失了图的表意)
bash
{
"type": "text",
"text": "分析师: 彭波 \nE-mail: pengbo@yongxingsec.com \nSAC编号: S1760524100001 \n分析师: 陈灿 \nE-mail: chencan2@yongxingsec.com \nSAC编号: S1760525010002 \n相关报告: \n《伏美替尼持续放量,适应症拓展仍 \n有空间》2025 年 05 月 06 日",
"page_idx": 0
},
{
"type": "table",
"img_path": "images/e615166fd385400608ed9069eb20088bb78ce2c5de7fad66da7072570597386f.jpg",
"table_caption": [],
"table_footnote": [],
"table_body": "<table><tr><td colspan=\"2\">基本数据</td></tr><tr><td>07月04日收盘价(元)</td><td>94.61</td></tr><tr><td>12mthA股价格区间(元)</td><td>39.82-99.99</td></tr><tr><td>总股本(百万股)</td><td>450.00</td></tr><tr><td>无限售A股/总股本</td><td>100.00%</td></tr><tr><td>流通市值 (亿元)</td><td>425.75</td></tr></table>",
"page_idx": 0
},
{
"type": "image",
"img_path": "images/cefb4046fc651be250334d71e02a2c9289c2dc5420d575183f79eb329cdb68d5.jpg",
"image_caption": [
"最近一年股票与沪深 300比较",
"资料来源:Wind,甬兴证券研究所"
],
"image_footnote": [],
"page_idx": 0
},table:

image:原图和提取的图
但是目前mineru只是提取出来了图片,还需要对图片进行进一步的融合,只是简单加入图片的描述信息还有有比较大的局限性的。
2、升级分块策略
目前的分块策略:
按页来分块(每一页都是一个知识块,可以直接用于后续的向量化和索引),每一个pdf文件按页来排序,每一页的内容包含text、table、image,上一个pdf最后一页结束之后,便是下一个pdf的第一页,以此类推直到最后一个pdf的最后一页。
上述分块方式存在缺点:按"页"分块过于粗暴,一个完整的表格或逻辑段落可能被硬生生切开,或者说当本来应检索的信息分布于前后两页之中时,便破坏了信息的上下文完整性。
优化分块策略:
有了 MinerU 精细化的解析结果,我们可以对图片进行进一步的内容解释,添加图片的描述信息。
后续涉及对图像描述信息的融合处理。
3、引入重排模型
在终端下载BAAI的bge-reranker-v2-m3重排模型:
bash
# 先下载 lfs
git lfs install
git clone https://www.modelscope.cn/BAAI/bge-reranker-v2-m3.git加载重排模型:
python
# 初始化 FlagReranker(加载一次就行)
local_model_path = "./bge-reranker-v2-m3" # 替换为你的下载模型路径
self.reranker = FlagReranker(
local_model_path,
use_fp16=True # 没 GPU 用 "cpu"
)召回+重排实现代码:取的是先召回后重排得到的Top-k个chunks,代替原来的直接取的Top-k个chunks。
python
# 1️⃣ 向量粗召回 15 个
q_emb = self.embedding_model.embed_text(question)
retrieved_chunks = self.vector_store.search(q_emb, top_k=15)
if not retrieved_chunks:
return {
"question": question,
"answer": "",
"filename": "",
"page": "",
"retrieval_chunks": []
}
# 2️⃣ 用 FlagReranker 精排
pairs = [[question, chunk['content']] for chunk in retrieved_chunks]
scores = self.reranker.compute_score(pairs) # 返回每个pair的相关性分数
# 绑定分数
for i, sc in enumerate(scores):
retrieved_chunks[i]['score'] = sc
# 按分数排序,取 top_k
reranked_chunks = sorted(retrieved_chunks, key=lambda x: x['score'], reverse=True)[:top_k]
# 3️⃣ 拼接上下文
context = "\n".join([
f"[文件名]{c['metadata']['file_name']} [页码]{c['metadata']['page']}\n{c['content']}"
for c in reranked_chunks
])
# 4️⃣ 构造 Prompt
prompt = (
f"你是一名专业的金融分析助手,请根据以下检索到的内容回答用户问题。\n"
f"请严格按照如下JSON格式输出:\n"
f'{{"answer": "你的简洁回答", "filename": "来源文件名", "page": "来源页码"}}'"\n"
f"检索内容:\n{context}\n\n问题:{question}\n"
f"请确保输出内容为合法JSON字符串,不要输出多余内容。"
)
# 5️⃣ 调用大模型
client = OpenAI(api_key=qwen_api_key, base_url=qwen_base_url)
completion = client.chat.completions.create(
model=qwen_model,
messages=[
{"role": "system", "content": "你是一名专业的金融分析助手。"},
{"role": "user", "content": prompt}
],
temperature=0.2,
max_tokens=1024
)4、升级索引策略
多路召回与融合:
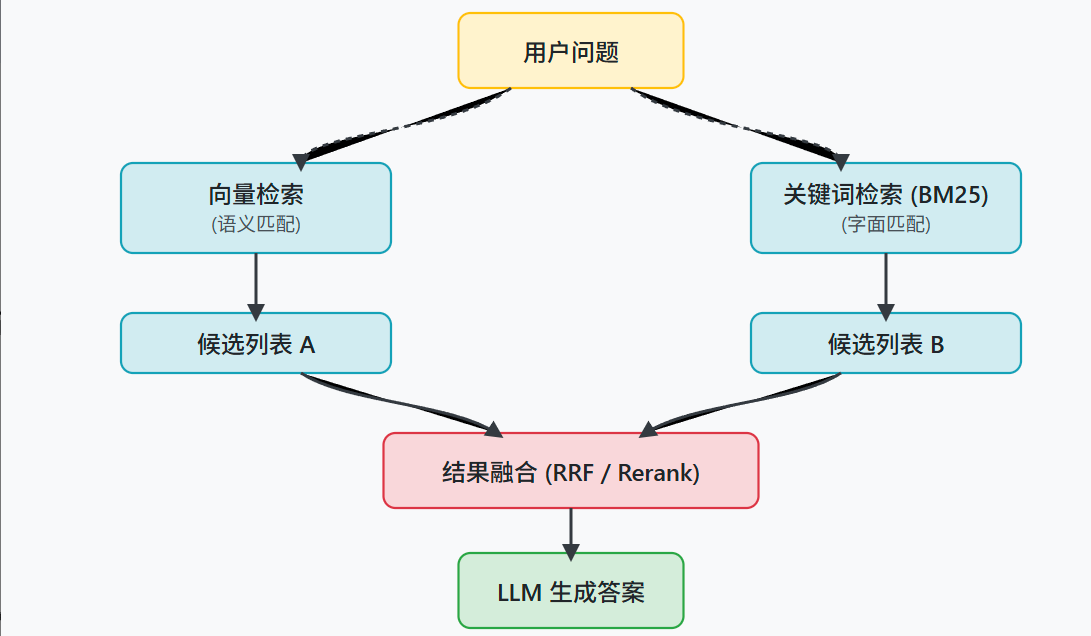
除了原先的基于向量的语义检索------使用 embedding 模型来查找意思相近的chunk之外,另外再引入一种基于关键词的检索方法------BM25 算法,它擅长匹配问题中出现的具体词语,即要将chunk中的content内容的每一个单词/字给分出来,再去做匹配。
step1:下载BM25算法库和中文分词器
bash
uv pip install rank_bm25, jiebastep2:在SimpleVectorStore类中新增 BM25 算法关键词检索函数,利用中文分词器(jieba)去对中文句子进行分词
python
class SimpleVectorStore:
def __init__(self):
self.embeddings = []
self.chunks = []
# --- 新增 ---
self.bm25 = None # BM25 模型
self.tokenized_chunks = [] # 预先分好词的文本
def add_chunks(self, chunks: List[Dict[str, Any]], embeddings: List[List[float]]):
self.chunks.extend(chunks)
self.embeddings.extend(embeddings)
# --- 新增:构建 BM25 ---
# 使用 jieba 精确分词
self.tokenized_chunks = [
list(jieba.cut_for_search(c['content'])) # 搜索引擎模式,速度快
for c in self.chunks
]
self.bm25 = BM25Okapi(self.tokenized_chunks)
def search(self, query_embedding: List[float], top_k: int = 3) -> List[Dict[str, Any]]:
from numpy import dot
from numpy.linalg import norm
import numpy as np
if not self.embeddings:
return []
emb_matrix = np.array(self.embeddings)
query_emb = np.array(query_embedding)
sims = emb_matrix @ query_emb / (norm(emb_matrix, axis=1) * norm(query_emb) + 1e-8)
idxs = sims.argsort()[::-1][:top_k]
return [self.chunks[i] for i in idxs]
# --- 新增:bm25检索 ---
def search_bm25(self, query: str, top_k: int = 3) -> List[Dict[str, Any]]:
if not self.bm25:
return []
# 同样用 jieba 分词
tokens = list(jieba.cut_for_search(query))
scores = self.bm25.get_scores(tokens)
idxs = scores.argsort()[::-1][:top_k]
return [self.chunks[i] for i in idxs]step3:在 SimpleRAG 类中新增混合检索接口
python
class SimpleRAG:
def __init__(self, chunk_json_path: str, model_path: str = None, batch_size: int = 32):
self.loader = PageChunkLoader(chunk_json_path)
self.embedding_model = EmbeddingModel(batch_size=batch_size)
self.vector_store = SimpleVectorStore()
self.memory = ConversationBufferMemory(return_messages=True)
def search_hybrid(self, question: str, top_k_vec: int = 10, top_k_bm25: int = 10) -> List[Dict[str, Any]]:
"""
混合检索:向量 + BM25,各取 top_k,合并去重后返回
"""
# 向量检索
q_emb = self.embedding_model.embed_text(question)
vec_results = self.vector_store.search(q_emb, top_k=top_k_vec)
# BM25 检索
bm25_results = self.vector_store.search_bm25(question, top_k=top_k_bm25)
# 合并去重(保持顺序)
seen = set()
merged = []
for chunk in vec_results + bm25_results:
cid = (chunk['metadata']['file_name'], chunk['metadata']['page'], chunk['content'])
if cid not in seen:
seen.add(cid)
merged.append(chunk)
return mergedstep4:函数应用,修改原来search方法为混合检索
python
# chunks = self.vector_store.search(q_emb, top_k)
# 2. 混合检索
chunks = self.search_hybrid(rewritten_question)5、反思重写:
我们甚至可以考虑让RAG系统拥有自我修正的能力。
具体来说,就是让系统在检索一次之后,能自己判断一下找到的上下文够不够回答问题。
如果不够,它可以自己生成一个新的、更具体的查询语句,再次进行检索,把两次的结果合在一起再生成答案。
这会让整个问答过程更动态一些。