一、虚拟机及CentOS安装配置
1、软件准备
1.1 虚拟机软件
建议使用VMwareWorkstation,本文是基于vmware来讲解的,当然也可以使用VirtualBox,道理都是一样的。
1.2 Linux系统
使用CentOS6.7,虽然CentOS已经停更,但是这个版本的Linux性能稳定,作为服务器操作系统应用广泛。
- 内核与系统架构
CentOS6.7基于Linux2.6.32内核,相比新版本更轻量级,适合资源受限的服务器环境。其默认的ext4文件系统在常规Hadoop数据存储场景中表现稳定,支持单文件系统容量达1EB,满足分布式存储需求。
- 兼容性与稳定性
对老旧硬件和软件的兼容性优异,适合运行依赖旧版库的Hadoop生态工具(如Hive1.x)。
长期运行的稳定性得到验证,尤其适合无需频繁更新的生产环境。实际案例显示,CentOS6.7部署的Hadoop集群可稳定处理高并发任务,如Web日志分析和大规模数据批处理。
- 资源占用优化
最小化安装时内存占用较低(约200MB),适合虚拟机或老旧硬件部署。通过关闭防火墙(service iptables stop)和禁用一些不用的服务,可进一步减少系统开销,提升Hadoop集群资源利用率。
下载地址:vault.centos.org/6.7/isos/x8...
1.3 JavaJDK
Hadoop是基于java的,因此需要java JDK,使用版本java 8 Linux版,形如jdk-8uXXX-linux-x64.tar.gz这样的linux版文件,官网下载地址是www.oracle.com/java/techno...
2、虚拟机网络配置
在虚拟机中安装好CentOS后,首先就要进行网络配置,保证虚拟机网络畅通、和主机通讯无误。
2.1模式分类
桥接模式(BridgedMode)
网络架构:通过虚拟网桥(VMnet0)将虚拟机网卡直接映射到物理网卡,虚拟机与宿主机处于同一局域网,相当于独立物理设备。
IP分配:由物理网络的DHCP服务器分配(或手动配置),与宿主机同网段(如宿主机192.168.1.100,虚拟机192.168.1.101)。
通信特性:
虚拟机可被局域网内其他设备直接访问(如共享文件、远程桌面)。
若物理网络有公网IP,虚拟机可直接暴露于外网。
自定义NAT模式
网络架构:通过VMnet8虚拟交换机和NAT服务,虚拟机共享宿主机IP访问外网。宿主机充当"路由器",对外隐藏虚拟机IP。
IP分配:由VMware虚拟DHCP分配私有IP(如192.168.200.0网段),与宿主机不同子网。
通信特性:
虚拟机可主动访问外网,但除宿主机之外的不能直接访问虚拟机,除非通过端口转发规则(如宿主机8080→虚拟机80)。
默认隔离局域网内其他设备的直接访问。
在生产环境中,虚拟机和真实机不应有任何区别,共处同一网段,因此一般情况下使用桥接模式。
在测试开发环境中,如果需要虚拟机处在隔离的网段中,就使用自定义NAT模式。
2.2配置方法
桥接模式:
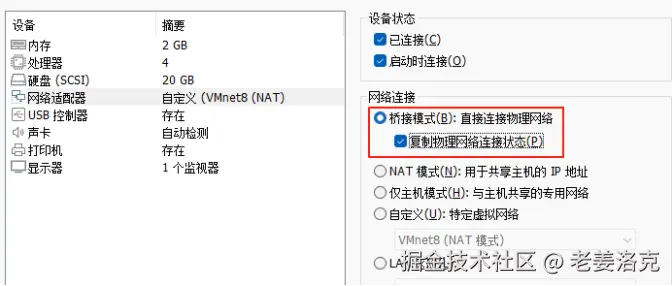 自定义NAT模式
自定义NAT模式
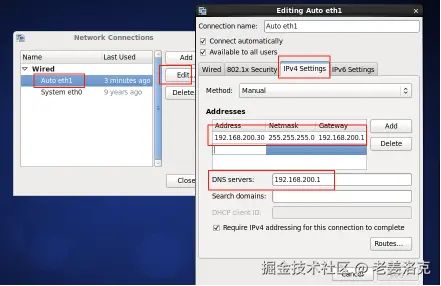
进入VMware菜单,编辑-虚拟网络编辑器,添加VMnet8配置,设定和宿主机不同的网段,如本例:子网IP192.168.200.0,子网掩码255.255.255.0。

然后点击【NAT设置】配置网关,如本例192.168.200.1
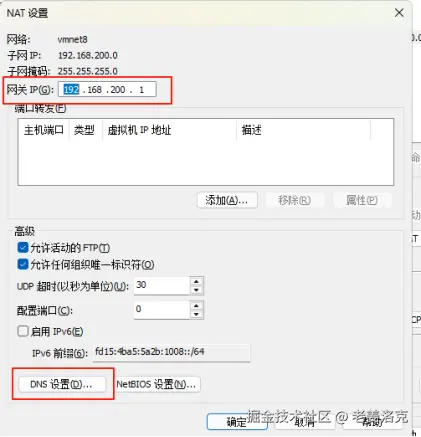
为了保证虚拟机能够通过域名访问外网,还要配置DNS,去掉自动检测,加上两个当地快些的DNS地址
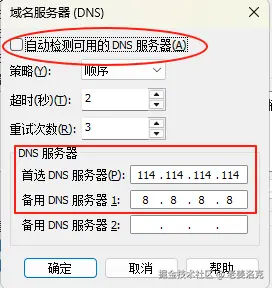 点击确定返回后,再点击【DHCP设置】,注意这个DHCP是虚拟机虚拟出来的,和宿主机使用的DHCP服务毫无关系。由于将来我们的几个节点的Hadoop服务器都采用固定IP,那么这里的动态分配的IP地址域就要避开固定的IP。
点击确定返回后,再点击【DHCP设置】,注意这个DHCP是虚拟机虚拟出来的,和宿主机使用的DHCP服务毫无关系。由于将来我们的几个节点的Hadoop服务器都采用固定IP,那么这里的动态分配的IP地址域就要避开固定的IP。
这里的VMnet8配置好后,就可以在具体的虚拟机的配置里选择它了。

3、Linux基本配置
3.1切换英文
CentOS安装完默认是中文的,需要切换成英文
启动虚拟机,登录进去,启动终端,切换成root,为了不必要的麻烦,本文下面的操作都是root进行的
bash
su用vi编辑配置文件
bash
vi /etc/sysconfig/i18n输入i,进入编辑模式,修改为下面代码
text
LANG="en_US.UTF-8"然后输入:wq保存退出
3.2配置网络
用vi编辑配置文件
bash
vi /etc/sysconfig/network-scripts/ifcfg-eth0输入i,进入编辑模式,修改为下面代码
text
DEVICE=eth0
BOOTPROTO=static #设置为静态IP
ONBOOT=yes #开机自启
IPADDR=192.168.200.2 5#静态IP地址
NETMASK=255.255.255.0 #子网掩码
GATEWAY=192.168.200.1 #网关地址
DNS1=8.8.8.8 #桥接模式下直接指定外网DNS
DNS1=192.168.200.1 #自定义NAT模式下通过网关获取DNS然后输入:wq保存退出
启动网络
bash
service network restart查看IP和子网掩码
bash
Ifconfig查看网关是否生效
bash
route -n测试网络连通性
bash
ping www.baidu.com当然了,CentOS已经有了图形化界面来配置网络,效果是一样的。
鼠标右键
配置好后,点击网络图标重新连接即可
永久关闭防火墙
bash
chkconfig iptables off更改本机名称
bash
vi /etc/sysconfig/network输入i,进入编辑模式,修改为下面代码
text
hadoop-server-00然后输入:wq保存退出
配置主机名称和IP地址的映射
bash
vi /etc/hosts输入i,进入编辑模式,增加下面代码
text
192.168.200.25 hadoop-server-00然后输入:wq保存退出
3.3安装javaJDK
在CentOS里安装软件的方法简单的介绍一下,离线式的可以通过rpm,直接安装rpm格式的预编译的二进制文件,还可以通过软件的源码,自行编译、处理依赖,进行安装。
而在线的,通过软件源,用yum工具来进行安装。
Hadoop是java生态下的,其运行需要java虚拟机,因此安装javaJDK是必须的,java运行环境是编译好的,只要安装包解压到linux的特定路径下,经过配置就可以运行了。
首先根据上文1.3介绍获取jdk的安装包上传到虚拟机内即可,上传工具可以采用支持SFTP的工具例如FileZilla等,个人首推FinalSSH,因为这个SSH工具除了支持SFTP之外,可以方便地进行拷贝粘贴等命令。
检查CentOS现有的java安装情况
bash
rpm -qa|grep java
text
java-1.7.0-openjdk-1.7.0.79-2.5.5.4.el6.x86_64
tzdata-java-2015e-1.el6.noarch
java-1.5.0-gcj-1.5.0.0-29.1.el6.x86_64
java_cup-0.10k-5.el6.x86_64
java-1.6.0-openjdk-1.6.0.35-1.13.7.1.el6_6.x86_64rpm -qa指令输出当前系统已经安装的所有软件包
|管道符,把前一命令的输出输入到下一个命令
grep java 文本查找包含java字样的
根据结果可知,系统目前安装了低版本的java
卸载已安装的jdk
bash
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.79-2.5.5.4.el6.x86_64
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.35-1.13.7.1.el6_6.x86_64
rpm -e --nodeps java-1.5.0-gcj-1.5.0.0-29.1.el6.x86_64创建程序目录
以后我们的软件都安装在这个位置
bash
mkdir -p -m755 /usr/local/apps解压jdktar包
进入到jdk上传到的那个目录内
bash
cd /home/hadoop/Downloads执行下面指令
bash
tar -xvf jdk-8u77-linux-x64.tar.gz -C /usr/local/apps配置环境变量
bash
vi /etc/profile输入i,进入编辑模式,添加下面代码
text
export JAVA_HOME=/usr/local/apps/jdk1.8.0_77
export PATH=$PATH:$JAVA_HOME/bin然后输入:wq保存退出
刷新配置文件
bash
source /etc/profile检查效果,打出java版本,检查是否一致
bash
java -version
text
javaversion"1.8.0_77"
Java(TM)SERuntimeEnvironment(build1.8.0_77-b03)
JavaHotSpot(TM)64-BitServerVM(build25.77-b03,mixedmode)二、单节点Hadoop
1、安装hadoop
我们使用的是原生hadoop,即Apache版本的,还有一个是CDH版的不在本文讲解范围内。
Apache版本的官网地址是hadoop.apache.org/,我们使用2.7.3版本,下载地址为archive.apache.org/dist/hadoop...
解压安装tar包
进入到tar上传到的那个目录内
bash
cd /home/hadoop/Downloads执行下面指令
bash
tar -xvf hadoop-2.7.3.tar.gz -C /usr/local/apps配置环境变量
bash
vi /etc/profile输入i,进入编辑模式,接前,添加修改下面代码
text
export JAVA_HOME=/usr/local/apps/jdk1.8.0_77
export HADOOP_HOME=/usr/local/apps/hadoop-2.7.3
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin然后输入:wq保存退出
刷新配置文件
bash
source /etc/profile检查效果,打出hadoop版本,检查是否一致
bash
hadoop version
text
Hadoop2.7.3
Subversionhttps://git-wip-us.apache.org/repos/asf/hadoop.git-rbaa91f7c6bc9cb92be5982de4719c1c8af91ccff
Compiledbyrooton2016-08-18T01:41Z
Compiledwithprotoc2.5.0
Fromsourcewithchecksum2e4ce5f957ea4db193bce3734ff29ff4
Thiscommandwasrunusing/usr/local/apps/hadoop-2.7.3/share/hadoop/common/hadoop-common-2.7.3.jar创建必要的运行目录并授权
bash
mkdir -p /opt/hadoop/tmp
mkdir -p /opt/hadoop/hdfs/name
mkdir -p /opt/hadoop/hdfs/data
chmod -R 755 /opt/hadoop755权限值:
所有者(Owner):7(读4+写2+执行1)
所属组(Group):5(读4+执行1)
其他用户(Others):5(读4+执行1)
效果:所有者可读写执行,组用户和其他用户仅可读和执行。
2、配置hadoop
2.1检查java关联
检查/usr/local/apps/hadoop-2.7.3/etc/hadoop/hadoop-env.sh文件
bash
vi /usr/local/apps/hadoop-2.7.3/etc/hadoop/hadoop-env.sh确保存在如下配置
text
#The java implementation to use.
export JAVA_HOME=${JAVA_HOME}2.2配置全局核心参数
此配置文件位于/usr/local/apps/hadoop-2.7.3/etc/hadoop/core-site.xml。是Hadoop的核心配置文件,主要用于定义Hadoop集群的全局参数,直接影响HDFS、MapReduce和YARN等组件的运行机制。其核心作用如下:
1.基础文件系统配置
默认文件系统URI:通过fs.defaultFS指定HDFS的访问地址(如hdfs://namenode-host:9000),集群内所有节点和客户端均依赖此配置与NameNode通信。
临时目录:hadoop.tmp.dir定义临时文件存储路径(如/tmp/hadoop-${user.name}),该目录被HDFS、YARN等组件共用。
2.I/O与网络优化
缓冲区大小:io.file.buffer.size控制读写操作的缓冲区容量(默认4KB,建议调整为128KB以上以提升性能)。
压缩编解码器:io.compression.codecs指定支持的压缩算法(如org.apache.hadoop.io.compress.GzipCodec)。
3.安全与权限管理
认证方式:hadoop.security.authentication设置安全认证模式(如kerberos或simple)。
代理用户:通过hadoop.proxyuser.配置允许代理访问的主机和用户组(如hadoop.proxyuser.hadoop.hosts=)。
4.其他关键参数
垃圾回收:fs.trash.interval定义删除文件的保留时间(分钟),避免误删。
本地库支持:io.native.lib.available启用本地库加速压缩/解压操作。
本次单节点,用vi检查只要配置如下关键点即可
xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-server-00:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/apps/hadoop-2.7.3/tmp/</value>
</property>
</configuration>2.3配置分布式文件系统
此配置文件位于/usr/local/apps/hadoop-2.7.3/etc/hadoop/hdfs-site.xml。是Hadoop分布式文件系统(HDFS)的核心配置文件,用于定制HDFS的运行时参数,覆盖默认配置以满足集群需求。其核心作用如下:
1.数据存储与副本管理
副本数量:
通过dfs.replication设置文件块的副本数(默认3),确保数据冗余和容错能力。
块大小:
dfs.blocksize定义文件块大小(如128MB),影响MapReduce任务的分片策略和NameNode内存消耗。
2.NameNode与DataNode配置
元数据存储路径:
dfs.namenode.name.dir指定NameNode元数据(如文件系统镜像)的存储目录。
数据存储路径:
dfs.datanode.data.dir配置DataNode存储实际数据的本地路径(支持多目录以提升I/O性能)。
高可用(HA):
dfs.nameservices定义名称服务标识。dfs.ha.namenodes列出HA集群中的NameNode节点。
dfs.namenode.shared.edits.dir设置共享编辑日志的JournalNode地址。
3.网络与访问控制
RPC/HTTP地址:
dfs.namenode.rpc-address设置NameNode的RPC通信端口(默认9000)。
dfs.namenode.http-address配置WebUI访问地址(如0.0.0.0:9870)。
短路本地读取:
dfs.client.read.shortcircuit启用本地数据块直接读取,减少网络开销。
4.安全与故障处理
故障转移:
dfs.ha.automatic-failover.enabled启用自动故障转移功能。
防脑裂机制:
dfs.ha.fencing.methods配置隔离方法(如sshfence)防止多NameNode同时活跃。
本次单节点,用vi检查只要配置如下关键点即可
xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>2.4配置MapReduce框架
此配置文件位于/usr/local/apps/hadoop-2.7.3/etc/hadoop/mapred-site.xml。可以通过mapred-site.template复制而来,或者vi直接创建。是Hadoop中专门用于配置MapReduce框架的核心文件,主要定义作业调度、资源分配、任务执行等关键参数,直接影响MapReduce任务的性能和稳定性。其核心作用如下:
1.框架运行模式
指定计算框架:
通过mapreduce.framework.name设置MapReduce的运行模式(如yarn或local),决定任务由YARN管理还是本地执行。
类路径配置:
mapreduce.application.classpath定义任务依赖的库路径,确保分布式环境下任务能访问所需资源。
2.任务调度与资源分配
内存管理:
mapreduce.map.memory.mb和mapreduce.reduce.memory.mb分别设置Map/Reduce任务的堆内存上限,需与YARN的容器资源限制匹配。
mapreduce.map.java.opts可细化JVM参数(如-Xmx)优化内存使用。
CPU资源:
mapreduce.map.cpu.vcores控制任务占用的虚拟CPU核数。
3.性能优化参数
排序与溢写:
mapreduce.task.io.sort.mb调整排序缓冲区大小(默认100MB),影响磁盘I/O频率。
mapreduce.map.sort.spill.percent设置溢写阈值(默认80%)。
并行度控制:
mapreduce.job.reduces指定Reduce任务数量,默认基于输入数据分片自动计算。
4.日志与容错
日志聚合:
yarn.log-aggregation-enable启用日志聚合功能,便于调试。
任务重试:
mapreduce.map.maxattempts定义Map任务失败后的最大重试次数。
本次单节点,用vi检查只要配置如下关键点即可
xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>2.5配置YARN框架
此配置文件位于/usr/local/apps/hadoop-2.7.3/etc/hadoop/yarn-site.xml。由于我们在MapReduce框架配置中定义了运算任务由YARN(YetAnotherResourceNegotiator)来管理,因此需要进一步配置yarn-site.xml,主要用于定义YARN集群的资源管理、任务调度、节点通信等关键参数。其核心作用如下:
1.资源管理配置
ResourceManager地址:
通过yarn.resourcemanager.hostname指定ResourceManager的主机名,yarn.resourcemanager.address设置其RPC通信端口(默认8032),客户端通过该地址提交应用程序。
NodeManager资源限制:
yarn.nodemanager.resource.memory-mb定义单个节点可用的物理内存总量(如8192MB)。yarn.nodemanager.resource.cpu-vcores设置虚拟CPU核数(默认8)。
2.任务调度与容器配置
容器资源范围:
yarn.scheduler.minimum-allocation-mb和yarn.scheduler.maximum-allocation-mb分别指定容器可申请的最小/最大内存(如1024MB和8192MB)。yarn.scheduler.minimum-allocation-vcores限制单个容器的虚拟CPU核数。
调度器选择:
yarn.resourcemanager.scheduler.class配置调度器类型(如CapacityScheduler或FairScheduler)。
3.高可用(HA)与容错
HA配置:
yarn.resourcemanager.ha.enabled启用ResourceManager高可用。
yarn.resourcemanager.ha.rm-ids列出多个RM节点标识(如rm1,rm2)。
故障恢复:
yarn.resourcemanager.recovery.enabled启用RM状态恢复功能。
4.辅助服务与日志
Shuffle服务:
yarn.nodemanager.aux-services必须设置为mapreduce_shuffle以支持MapReduce任务。
日志聚合:
yarn.log-aggregation-enable启用日志聚合功能,便于任务调试。
本次单节点,用vi检查只要配置如下关键点即可
xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-server-00</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>3、启动运行hadoop
3.1启动hadoop
1、格式化HDFS
进入/usr/local/apps/hadoop-2.7.3/bin目录下,由于已经配置了环境变量$HADOOP_HOME,下面的命令可以在任意路径下运行
bash
hadoop namenode -format或者
bash
hdfs namenode -format其目的是初始化NameNode元数据存储目录,会生成fsimage(文件系统镜像)和edits(操作日志)文件,存储HDFS的命名空间和块映射信息。生成全局唯一标识符,确保NameNode和DataNode的元数据一致性。
格式化会清空原有元数据,需提前备份关键数据,即备份元数据目录(如dfs.name.dir配置的路径)。
2、启动NameNode守护进程服务
NameNode进程,负责管理文件系统元数据。
我们使用的是hadoop2.X,启动命令需要进入/usr/local/apps/hadoop-2.7.3/sbin目录下去运行相应的SH脚本
bash
./hadoop-daemon.sh start namenode关闭是
bash
./hadoop-daemon.sh stop namenodeHadoop3.X,这个SH脚本方式被废弃了,改用了hdfs命令
bash
hdfs --daemon start namenode运行完成后,用jps检查当前进程中是否已经运行了namenode
bash
jps
text
4483 NameNode
4776 Jps有任何异常,按照提示去查看日志文件的内容,分析出错原因/usr/local/apps/hadoop-2.7.3/logs/hadoop-root-namenode-CentOS.log
权限问题:若以root用户执行,可能导致权限冲突,需切换至Hadoop专用用户(如hadoop)再启动
bash
su hadoop主机名解析失败:/etc/hosts中未正确映射主机名,按上文3.2检查处理
端口冲突:NameNode默认端口9000是否被占用,检查端口
bash
netstat -tulnp|grep 9000修改core-site.xml中的fs.defaultFS的端口配置或终止占用进程
3、 启动datanode 守护 进程 服务
DataNode进程,负责存储和管理数据块。
我们使用的是hadoop2.X,启动命令需要进入/usr/local/apps/hadoop-2.7.3/sbin目录下去运行相应的SH脚本
bash
./hadoop-daemon.sh start dataenode关闭是
bash
./hadoop-daemon.sh stop datanodeHadoop3.X,这个SH脚本方式被废弃了,改用了hdfs命令
bash
hdfs --daemon start datanode运行完成后,用jps检查当前进程中是否已经运行了datanode
bash
jps
text
20887 NameNode
21415 Jps
21231 DataNode有任何异常,按照提示去查看日志文件的内容,分析出错原因/usr/local/apps/hadoop-2.7.3/logs/hadoop-root-datanode-CentOS.log
端口冲突:datanode默认端口50010是否被占用,检查端口
bash
netstat -tulnp|grep 50010需修改hdfs-site.xml中的dfs.datanode.address端口配置或终止占用进程
ClusterID不匹配:若DataNode的VERSION文件与NameNode的ClusterID不一致,需手动同步或重新格式化。
4、启动secondarynamenode守护进程服务
SecondaryNameNode进程,负责定期合并NameNode的编辑日志(EditLog)和文件系统镜像(FsImage),生成新的FsImage并回传给NameNode,以减轻NameNode的负担。
我们使用的是hadoop2.X,启动命令需要进入/usr/local/apps/hadoop-2.7.3/sbin目录下去运行相应的SH脚本
bash
./hadoop-daemon.sh start secondarynamenode关闭是
bash
./hadoop-daemon.sh stop secondarynamenodeHadoop3.X,这个SH脚本方式被废弃了,改用了hdfs命令
bash
hdfs --daemon start secondarynamenode运行完成后,用jps检查当前进程中是否已经运行了secondarynamenode
bash
jps
text
40703 SecondaryNameNode端口冲突:确认hdfs-site.xml中的dfs.namenode.secondary.http-address或dfs.secondary.http.address配置正确(默认端口为50090)。若默认端口被占用,需修改配置或终止占用进程。
ClusterID不匹配:若SecondaryNameNode的VERSION文件与NameNode的ClusterID不一致,需手动同步或重新格式化。
重复格式化问题:多次格式化可能导致元数据不一致,需清理/tmp和Hadoop数据目录后重新初始化。
5、Hadoop的Web管理界面
如果以上进程服务都正常启动了,就可以访问到Hadoop的Web管理界面了,在宿主机里启动浏览器,输入虚拟机的IP地址和端口号即可访问,如果宿主机配置了hosts,亦可以通过机器名来访问。
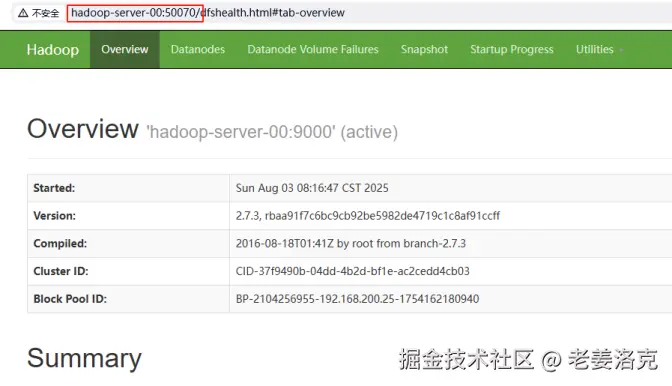 Hadoop的Web管理界面(默认端口50070)是监控和管理HDFS集群的重要工具。以下是对该页面各功能的详细解析:
Hadoop的Web管理界面(默认端口50070)是监控和管理HDFS集群的重要工具。以下是对该页面各功能的详细解析:
(一)核心功能模块
1、Overview(概览)
-
ClusterID:显示集群唯一标识符
-
Version:Hadoop版本信息
-
Compiled:编译时间和开发者信息
-
ClusterStatus:集群存储使用情况(总容量/已用/剩余)
2、Datanodes(数据节点)
-
显示所有活跃/死亡节点列表
-
每个节点的存储容量、使用率、最后心跳时间
-
节点状态可视化(正常/异常)
3、Snapshot(快照)
-
文件系统快照管理界面
-
创建/删除/查看快照功能
(二)高级功能入口
1、Utilities(工具集)
-
Browsethefilesystem:可视化文件浏览器
-
Logs:查看NameNode日志
-
Configuration:查看当前生效的配置参数
-
Threadstacks:查看线程堆栈信息
2、StartupProgress(启动进度)
-
NameNode启动各阶段耗时分析
-
关键初始化步骤状态监控
(三)运维操作指南
1、文件系统检查
-
通过"BrowseDirectory"可查看所有HDFS文件
-
支持文件权限、副本数、块大小等元数据检查
2、节点管理
-
手动下线节点(Decommission)
-
节点维护模式设置
3、日志分析
-
实时查看NameNode运行日志
-
支持日志级别动态调整
(四)安全配置建议
1、访问控制
-
建议启用Kerberos认证
-
配置防火墙规则限制50070端口访问
2、监控集成
-
可通过JMX接口对接监控系统
-
关键指标:FSImage加载时间、EditLog堆积量
注:该页面是Hadoop2.x的经典界面,在Hadoop3.x中端口可能变更为9870,且界面布局有所调整。生产环境建议通过API(http://hadoop-server-00:50070/jmx)获取更详细的监控数据。
3.2启动yarn
1、YARN的作用
前文已经提及YARN(YetAnotherResourceNegotiator)是Hadoop生态系统的核心资源管理系统,主要作用是为分布式计算框架提供统一的资源管理和调度平台。其核心功能与架构可归纳如下:
(一)核心作用
-
集中管理集群的CPU、内存、磁盘等资源,通过全局视图动态分配资源给不同应用程序。
-
支持多租户环境,通过资源池和队列实现租户间的资源隔离与优先级控制。
-
采用主从架构(ResourceManager+NodeManager),根据调度策略(如FIFO、公平调度)分配资源。
-
支持多种计算框架(如MapReduce、Spark、Flink),实现资源复用与任务并行。
-
通过ZooKeeper实现ResourceManager的HA(高可用),避免单点故障。
-
根据集群负载动态调整资源分配,优化利用率。
(二)关键组件
-
ResourceManager(RM):全局资源调度器,负责接收应用请求并分配Container资源。包含调度器(Scheduler)和应用管理器(ApplicationsManager)。
-
NodeManager(NM):节点代理,监控本地资源并执行RM分配的任务。通过心跳机制向RM汇报资源状态。
-
ApplicationMaster(AM):每个应用独立实例,负责向RM申请资源并管理任务生命周期。任务失败时自动重新申请资源。
-
Container:资源抽象单元,封装CPU、内存等资源供任务使用。
2、启动主节点进程
yarn的主节点进程,负责集群资源分配和任务调度。默认监听8032(RPC端口)和8088(WebUI端口)。
我们使用的是hadoop2.X,启动命令需要进入/usr/local/apps/hadoop-2.7.3/sbin目录下去运行相应的SH脚本
bash
./yarn-daemon.sh start resourcemanager关闭是
bash
./yarn-daemon.sh stop resourcemanagerHadoop3.X,这个SH脚本方式被废弃了,改用了yarn命令
bash
yarn --daemon start resourcemanager运行完成后,用jps检查当前进程中是否已经运行了ResourceManager
bash
jps
text
3576 ResourceManager3、启动从节点进程
yarn的从节点进程,负责管理单个节点上的资源容器(Container)。默认向ResourceManager发送心跳(间隔3秒),汇报节点资源状态。
我们使用的是hadoop2.X,启动命令需要进入/usr/local/apps/hadoop-2.7.3/sbin目录下去运行相应的SH脚本
bash
./yarn-daemon.sh start nodemanager关闭是
bash
./yarn-daemon.sh stop nodemanagerHadoop3.X,这个SH脚本方式被废弃了,改用了yarn命令
bash
yarn --daemon start nodemanager运行完成后,用jps检查当前进程中是否已经运行了nodemanager
bash
jps
text
3842 NodeManager4、yarn的web管理界面
如果以上yarn的主从进程都正常启动,就可以访问到yarn的Web管理界面了,在宿主机里启动浏览器,输入虚拟机的IP地址和端口号即可访问http://<主机名>:8088,如果宿主机配置了hosts,亦可以通过机器名来访问。
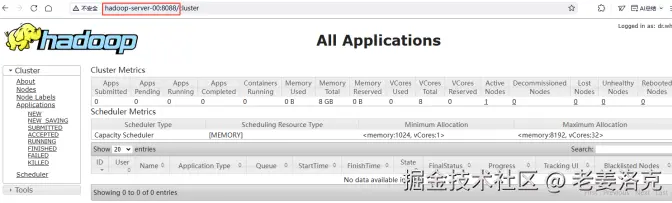
YARN的Web管理界面是监控和管理Hadoop集群资源的核心工具,主要功能模块和特性如下:
(一)核心功能模块
-
实时显示集群资源使用率(内存/CPU),包括已用资源、总资源和保留资源比例
-
节点状态分类统计:活跃节点(ActiveNodes)、退役中节点(Decommissioning)、失联节点(LostNodes)等
-
应用状态追踪:提交(Submitted)、挂起(Pending)、运行中(Running)、已完成(Completed)四类状态统计
-
容器运行监控:显示当前运行的Container数量及资源占用详情
-
调度策略展示:包括FIFO、FairScheduler或CapacityScheduler类型
-
资源分配规则:最小/最大资源分配值(Memory/VCores)
(二)关键数据维度
-
集群资源: MemoryTotal/Used,VCores分配量
-
节点健康状态: UnhealthyNodes,RebootedNodes
-
应用详情: 用户/队列/优先级/运行时长
(三)高级功能
-
日志聚合查看:通过HistoryServer服务查看已完成应用的日志,需配合HDFS日志聚合功能启用
-
节点热力图:可视化展示各节点资源负载情况,支持按内存/CPU维度筛选
-
队列资源配置:可查看和修改队列资源容量、最大资源上限等参数(需管理员权限)
通过该界面,运维人员可以快速定位资源瓶颈、监控应用执行状态,并调整调度策略。具体界面布局和功能可能因Hadoop版本不同存在差异。
3.3运行MapReduce例子
在$HADOOP_HOME/share/hadoop/mapreduce/目录下有个hadoop-mapreduce-examples-2.7.3.jar示例程序,这些示例涵盖了从基本到高级的各种MapReduce应用场景,是学习和测试Hadoop集群功能的绝佳资源。我将在后续课程内做详细讲解。
1、运行一个蒙特卡洛方法估算π值的示例
bash
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar pi 10 100运行后,我们就可以在yarn的web页面上看到此计算任务的运行情况 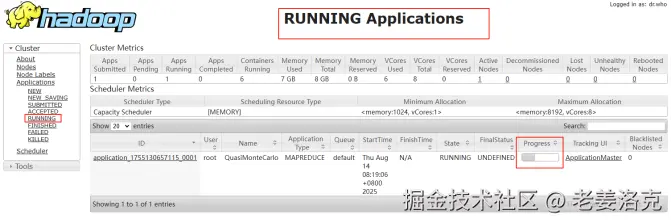
点击ID,进入此任务的详细页面,可以看到Map的进展和Reduce的进展
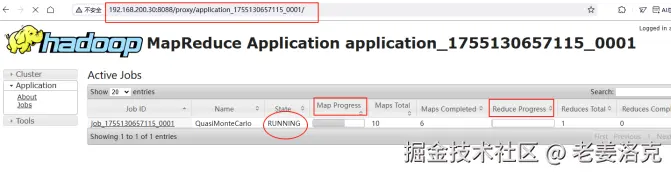
由于蒙特卡洛计算π值的运算量还是很大的,我们现在单节点上运行,是很耗时的,等我们配置好集群后再运行相同的例子,就能看出其优势了。
运行完成后,输出内容节选如下:
text
[root@hadoop-server-00sbin]#hadoopjar$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jarpi10100
NumberofMaps=10
SamplesperMap=100
WroteinputforMap#0
WroteinputforMap#1
WroteinputforMap#2
WroteinputforMap#3
WroteinputforMap#4
WroteinputforMap#5
WroteinputforMap#6
WroteinputforMap#7
WroteinputforMap#8
WroteinputforMap#9
StartingJob
25/08/1408:19:02INFOclient.RMProxy:ConnectingtoResourceManagerathadoop-server-00/192.168.200.30:8032
25/08/1408:19:04INFOinput.FileInputFormat:Totalinputpathstoprocess:10
25/08/1408:19:04INFOmapreduce.JobSubmitter:numberofsplits:10
25/08/1408:19:05INFOmapreduce.JobSubmitter:Submittingtokensforjob:job_1755130657115_0001
25/08/1408:19:06INFOimpl.YarnClientImpl:Submittedapplicationapplication_1755130657115_0001
Totalcommittedheapusage(bytes)=2006450176
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
ShuffleErrors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
FileInputFormatCounters
BytesRead=1180
FileOutputFormatCounters
BytesWritten=97
Job Finished in 278.835seconds
Estimated value of Pi is 3.14800000000000000000本次计算一共分了10个Map,每个Map有100个样本,共计算了278.835秒,计算的结果是3.148
2、计算过程
该程序基于蒙特卡洛模拟方法来估算π值,具体原理如下:
在一个边长为1的正方形内画一个四分之一圆(半径为1)随机向正方形内投掷大量点,统计落在四分之一圆内的点的数量.根据几何概率估算π值.计算公式:π≈4×(落在圆内的点数/总点数)。
MapReduce实现细节
1.Map阶段
每个map任务执行以下操作:
生成指定数量(numSamples)的随机点(x,y),其中x和y都在0,1区间内,对每个点检查是否满足x²+y²≤1(即是否在四分之一圆内),统计满足条件的点数。
每个map任务最终输出两个计数器:inside:在圆内的点数,total:生成的总点数。
2.Reduce阶段
Reduce任务汇总所有map任务的结果:累加所有 inside 计数器,累加所有 tota- 计数器,计算最终的π值:π≈4×(总inside数/总total数)。
示例计算过程以 pi 10 100 为例:
10个map任务,每个生成100个随机点
总点数=10×100=1000
假设汇总后落在圆内的点数为785
计算结果:π≈4×(785/1000)=3.14
数学解释
为什么这个方法有效?正方形面积=1×1=1,四分之一圆面积=(π×1²)/4=π/4,点在圆内的概率=(π/4)/1=π/4,因此π=4×(点在圆内的概率)。
样本点越多,结果越精确,由于随机性,每次运行结果可能略有不同,典型结果范围:当样本足够大时,通常在3.14附近波动。
性能特点
完全并行化:每个map任务独立计算,适合分布式处理
无数据依赖:不需要在map任务间传输数据,只有最终统计
计算密集型:主要开销在于随机数生成和条件判断
线性扩展性:增加计算节点可以线性提高精度
这个示例很好地展示了MapReduce的:分布式计算能力,简单的编程模型,适用于数据并行处理的场景。通过这个例子,可以直观理解Hadoop如何将一个大问题分解为许多可以并行处理的小问题,然后汇总结果。
三、集群Hadoop
hadoop作为典型的分布式计算框架,其优势具体体现在:
并行处理:MapReduce模型允许任务在多个节点上并行执行,大大提高了处理速度和效率。
负载均衡:系统能够自动平衡各个节点的工作负载,确保没有单点过载,提高了整体性能和稳定性。
数据分析能力:适合进行复杂的数据分析任务,如日志分析、用户行为分析等,这些任务通常需要处理大量数据和复杂的计算。
实时数据处理:通过集成如ApacheKafka等技术,Hadoop可以实现实时数据流的处理和分析。
配置多节点集群才能发挥其优势。
1、克隆其他节点
在前文单节点的虚拟机基础上在VMwareWorkstationPro中选中待克隆的虚拟机,点击菜单栏的「虚拟机」→「管理」→「克隆」。
配置克隆类型要选择完整克隆,生成完全独立的副本,占用与原虚拟机相同的存储空间。
输入新虚拟机名称,指定存储路径(建议新建文件夹)需修改网络配置,避免IP冲突。
完成后点击「完成」启动克隆进程。主从节点名称及IP配置如下
主节点 hadoop-server-00 192.168.200.25
从节点 hadoop-server-01 192.168.200.26
从节点 hadoop-server-02 192.168.200.27
2、配置集群
2.1配置全局核心参数
检查并配置每个节点的/usr/local/apps/hadoop-2.7.3/etc/hadoop/core-site.xml
xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-server-00:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/apps/hadoop-2.7.3/tmp/</value>
</property>
</configuration>所有的主从节点上面的配置都是一样的,注意其中fs.defaultFS都是指向主节点的地址和端口。这是HDFS的核心配置,它定义了整个集群的默认文件系统入口。
所有节点(包括从节点)需要通过这个地址与HDFS交互(如读写文件、获取元数据等)。无论节点角色如何,fs.defaultFS必须指向同一个NameNode地址(这里是hadoop-server-00),否则集群无法正常协作。9000是HDFS默认的IPC通信端口(可自定义,需与hdfs-site.xml中配置一致)。
-
高可用集群(HA):如果配置了NameNode高可用(HA),fs.defaultFS应指向逻辑服务名(如hdfs://mycluster),而非单节点地址,由ZooKeeper(后续文章详细讲解)自动故障切换。
-
多命名空间:若集群使用了联邦(Federation),不同命名空间可能有不同的入口地址,此时需要根据业务路径动态配置。
-
主机名解析:确保所有节点的hadoop-server-00能正确解析为IP(通过DNS或/etc/hosts),否则需直接使用IP地址(如hdfs://192.168.200.25:9000)。
配置完成后,在所有节点上执行下面命令,检查返回结果是否一致
bash
hdfs getconf-confKey fs.defaultFS2.2配置分布式文件系统
检查并配置每个节点的/usr/local/apps/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/hadoop/hdfs/data</value>
</property>
<!--只在主节点配置-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-server-00:50090</value>
</property>
</configuration>这里要说明一点,在前文中我们讲过了SecondaryNameNode进程的作用,它的主要职责是定期合并FsImage(文件系统元数据快照)和EditLogs(操作日志),以防止NameNode的EditLog文件过大,从而优化NameNode启动和恢复时间。
SecondaryNameNode和NameNode部署在同一台机器上:
优点:部署简单,适用于小型集群或测试环境。SecondaryNameNode可以直接访问NameNode的本地文件(如fsimage和edits),减少网络开销。
缺点:占用主节点资源(CPU、内存、磁盘IO),可能影响NameNode性能。如果主节点宕机,SecondaryNameNode也无法工作,影响元数据合并。
在真实的hadoop生产环境下,SecondaryNameNode要部署在另外的节点上,和主节点分开,这样可以避免主节点负载过高,提高集群稳定性。
xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-server-01:50090</value>
</property>如果使用了HA集群(hadoop高可用架构,后续文章详解),就不需要SecondaryNameNode了,而是由StandbyNameNode替代。
2.3配置MapReduce框架
检查并配置每一个节点的/usr/local/apps/hadoop-2.7.3/etc/hadoop/mapred-site.xml
xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>2.4配置YARN框架
检查并配置每一个节点的/usr/local/apps/hadoop-2.7.3/etc/hadoop/yarn-site.xml
xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-server-00</value>
</property>
</configuration>在Hadoop集群的YARN(YetAnotherResourceNegotiator)架构中,yarn.resourcemanager.hostname的配置项指向主节点(hadoop-server-00)是标准设计,因为ResourceManager(RM)是YARN的核心调度服务,通常部署在主节点上。
-
ResourceManager(RM):是YARN的主控进程,负责全局资源管理和作业调度。管理所有NodeManager(NM,运行在从节点上)的资源(CPU、内存等)。接收客户端提交的作业(如MapReduce、Spark等),并分配资源给ApplicationMaster(AM)。
-
NodeManager(NM):运行在从节点(如hadoop-server-01、hadoop-server-02),负责本节点的资源监控和任务执行。
在非高可用(非HA)的YARN集群中,ResourceManager是单点服务,通常部署在主节点(hadoop-server-00)。因此,所有节点(包括从节点)的yarn-site.xml需要统一指向该地址,以便:NodeManager向RM注册并汇报资源。客户端(如用户提交作业)知道RM的位置。
所有节点(包括主节点和从节点)的yarn-site.xml中yarn.resourcemanager.hostname必须一致,否则:
NodeManager无法连接到RM,导致资源无法被调度。客户端提交作业时会失败(找不到RM)。
2.5配置从节点定义
在主节点的$HADOOP_HOME/etc/hadoop/slaves文件里添加如下两行
text
hadoop-server-01
hadoop-server-02在Hadoop集群中,slaves(或workers,较新版本使用)文件用于定义所有从节点(DataNode和NodeManager)的主机名或IP地址,主要作用包括:
启动/停止DataNode和NodeManager:当在主节点执行start-dfs.sh或stop-dfs.sh时,脚本会读取slaves文件,自动在这些节点上启动/停止DataNode服务。类似地,start-yarn.sh会读取该文件,在从节点启动NodeManager。
仅在主节点(hadoop-server-00)上配置,start-dfs.sh、stop-dfs.sh、start-yarn.sh等脚本通常在主节点执行。从节点不需要此文件(它们只需运行服务,不负责管理集群其他节点)
2.6配置SSH互访
由于主节点要通过SSH发布指令给到各个从节点,因此要打通之间的SSH通讯
在主节点上生成公钥
bash
ssh -keygen
text
Generatingpublic/privatersakeypair.
Enterfileinwhichtosavethekey(/root/.ssh/id_rsa):**id_rsa**
Enterpassphrase(emptyfornopassphrase):
Entersamepassphraseagain:
Youridentificationhasbeensavedinid_rsa.
Yourpublickeyhasbeensavedinid_rsa.pub.
Thekeyfingerprintis:
c9:83:c0:f3:51:a7:b8:b5:e1:bf:7a:db:8b:e1:f7:caroot@hadoop-server-00
Thekey'srandomartimageis:
+--[RSA 2048 ]----+
|. .|
|.o o |
|+o+ |
| + B + |
| + S |
| o |
| o |
| . .* . |
| .o=oE+. |
+-----------------+把公钥分发给从节点
bash
ssh-copy-id hadoop-server-01
text
Nowtryloggingintothemachine,with"ssh'hadoop-server-01'",andcheckin:
.ssh/authorized_keys
tomakesurewehaven'taddedextrakeysthatyouweren'texpecting.提示用ssh登录一下01节点
bash
ssh hadoop-server-01
text
Lastlogin:SunAug304:28:422025from192.168.200.1
[root@hadoop-server-01~ ]#由提示符可见,已经切换至01节点了。exit命令可以返回原终端提示符。
同样再分发给02
bash
ssh-copy-id hadoop-server-023、启动运行集群
3.1启动集群
在主节点上,进入到$HADOOP_HOME/sbin/路径下,执行如下脚本,启动
bash
./start-dfs.shstart-dfs.sh脚本是一个集成化的集群启动脚本,在主节点上运行。是HadoopHDFS的核心启动脚本,负责启动HDFS相关的守护进程(如NameNode、DataNode等)。以下是对其运行过程的详细解析,包括执行流程、关键代码逻辑和环境依赖:
1.脚本位置与基本功能
路径:$HADOOP_HOME/sbin/start-dfs.sh
功能:按顺序启动HDFS的以下服务:NameNode(主节点)、DataNode(从节点,通过slaves文件定义)、SecondaryNameNode
2.脚本执行流程
(1)环境变量加载
脚本首先加载Hadoop的环境配置:hadoop-env.sh和hdfs-env.sh(设置JVM参数、日志目录等)
(2)检查NameNode启动权限
脚本会检查当前用户是否有权限启动NameNode(依赖HADOOP_SECURE_DN_USER配置,生产环境通常要求用特定用户启动)。
(3)启动NameNode
以守护进程(--daemon)方式启动NameNode。
(4)启动DataNode(遍历slaves文件)
读取slaves文件中的节点列表。通过SSH连接到每个从节点,执行从节点的hadoop-daemon.sh启动DataNode。
(5)启动SecondaryNameNode
仅在hdfs-site.xml中配置了dfs.namenode.secondary.http-address时触发。
3.关键依赖与配置
(1)slaves文件
(2)SSH无密码登录
(3)配置文件一致性
启动后用jps指令检查各节点的进程
主节点应包括:NameNode、SecondaryNameNode
从节点应包括:DataNode
在主节点上,进入到$HADOOP_HOME/sbin/路径下,执行如下脚本,启动
bash
./start-yarn.shstart-yarn.sh是HadoopYARN(资源管理框架)的核心启动脚本,负责启动YARN相关的守护进程(如ResourceManager和NodeManager)。以下是其执行流程的详细解析,包括关键代码逻辑、依赖关系。
1.脚本位置与基本功能
路径:$HADOOP_HOME/sbin/start-yarn.sh
功能:按顺序启动以下YARN服务:ResourceManager(RM):主节点上的全局资源调度器。NodeManager(NM):从节点上的本地资源管理器(通过slaves或workers文件控制)。
依赖配置文件:yarn-site.xml(YARN核心配置)slaves或workers(定义NodeManager节点)
2.脚本执行流程
(1)加载环境变量
脚本首先加载Hadoop和YARN的环境配置:hadoop-env.sh和yarn-env.sh(设置JVM参数、日志目录等)
(2)启动主节点的ResourceManager
(3)启动NodeManager(遍历slaves文件),通过SSH在每个从节点上执行yarn--daemonstartnodemanager。
3.关键依赖与配置
(1)workers/slaves文件
(2)SSH无密码登录
(3)yarn-site.xml关键配置
启动后用jps指令检查各节点的进程
主节点应包括:ResourceManager
从节点应包括:NodeManager
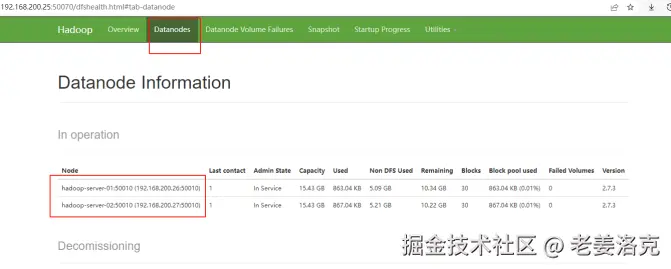
两个启动脚本如果运行无误,就可以访问到yarn的Web管理界面了,在宿主机里启动浏览器
3.2运行MapReduce例子
同前文单节点实例一样,我们来运行那个计算π的任务
bash
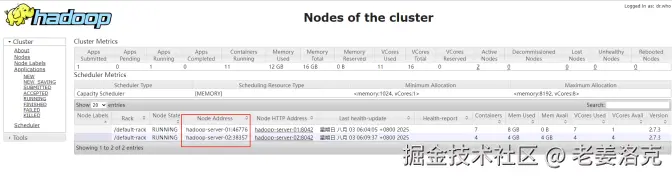
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar pi 10 100计算过程中,可以随时通过yarn来观察
运行完成后,输出内容节选如下:
text
Job Finished in 124.325 seconds
Estimated value of Pi is 3.14800000000000000000前文单节点运行时间是278.835秒,现在是三节点集群运行124.325秒,效果是显著的,在实际的企业应用中,hadoop集群的节点数量往往是成百上千的。