论文地址:https://arxiv.org/pdf/2404.07846
代码地址:https://github.com/nagejacob/TBSN
关注UP CV缝合怪,分享最计算机视觉新即插即用模块,并提供配套的论文资料与代码。
https://space.bilibili.com/473764881
摘要
本研究提出了一种基于Transformer 的盲点网络(TBSN) ,用于自监督图像去噪 。现有的大多数BSN都使用卷积层构建。尽管Transformer 已经展现出克服卷积在许多图像复原任务中局限性的潜力,但注意力机制 可能违反盲点要求,从而限制了它们在BSN中的适用性。为此,本研究重新设计通道注意力和空间注意力 以满足盲点要求。具体来说,由于下采样将空间特征混洗到通道维度中,通道自注意力 可能会在多尺度架构中泄漏盲点信息。为了缓解这个问题,本研究将通道分成几组并分别执行通道注意力。对于空间自注意力 ,本研究将精心设计的掩码应用于注意力矩阵,以限制并模拟空洞卷积的感受野。基于重新设计的通道注意力和窗口注意力,本研究构建了一个基于Transformer的盲点网络 (TBSN) ,它表现出很强的局部拟合和全局感知能力 。此外,本研究引入了一种知识蒸馏策略 ,将TBSN蒸馏成更小的去噪器,以提高计算效率 ,同时保持性能。在真实世界图像去噪数据集 上的大量实验表明,TBSN极大地扩展了感受野 ,并且相对于最先进的SSID方法 表现出良好的性能 。
引言
图像去噪 是低级视觉任务中的基础任务,其目标是从噪声观测中恢复清晰的图像。随着卷积神经网络 的发展,基于学习的图像去噪方法相比传统方法取得了显著的进步。然而,由于加性高斯白噪声(AWGN)与真实相机噪声 之间存在分布差异,监督学习方法在真实场景中的去噪性能下降。尽管可以使用真实噪声-干净图像对进行训练,但这种数据采集成本高昂且费力。
近年来,自监督图像去噪(SSID)被提出以规避对配对数据集的需求。开创性的工作Noise2Void 通过随机掩蔽噪声输入的部分位置,并训练网络从周围像素重建这些位置,从而实现自监督去噪。盲点网络(BSN)通过精心设计的网络架构进一步改进了这种掩蔽策略,使得每个输出位置的感受野都排除相应的输入像素,从而在性能和训练效率方面都表现出优越性。对于真实世界场景中存在的空间相关噪声 ,一些研究建议首先使用**像素重组下采样(PD)**来打破噪声相关性,然后再使用BSN进行去噪。非对称PD策略在训练和推理过程中取得了噪声去除和细节保留之间的良好平衡。
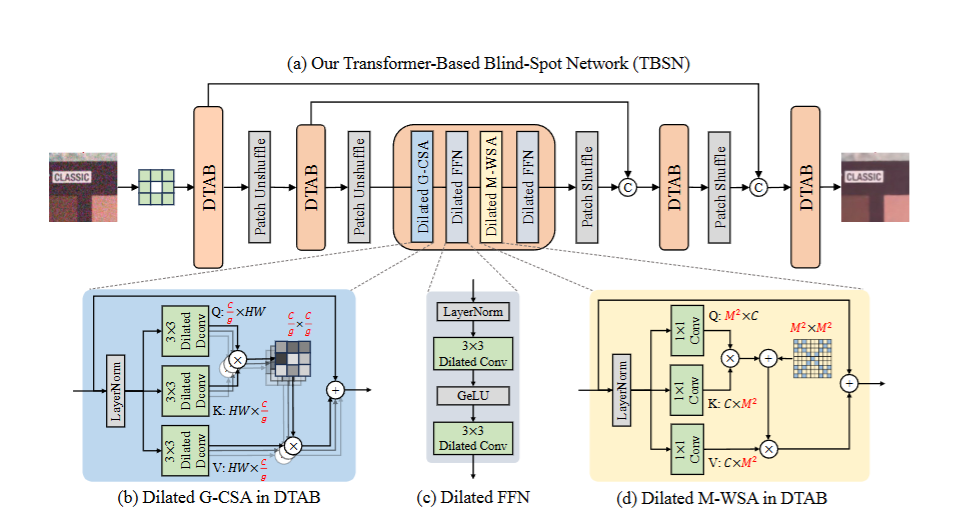
现有的BSN架构大多是卷积神经网络(CNN) 。然而,卷积操作在捕获长距离依赖关系 方面能力有限,并且卷积滤波器的静态权重 无法灵活地适应输入内容。Transformer模型 在许多图像复原任务中已经展现出克服卷积限制的潜力。尽管如此,Transformer算子可能违反盲点要求 ,并导致对噪声输入的过拟合 ,限制了其在BSN中的适用性。目前仅有少数尝试将Transformer应用于BSN。例如,LG-BPN 结合了通道自注意力机制 来增强全局特征,但仍然使用卷积层来整合局部信息。SwinIA 实现了一个基于Swin Transformer 的BSN,并对窗口注意力机制 进行了修改。然而,由于盲点要求的限制,它只能在注意力层中利用噪声输入的浅层特征,从而导致性能较差。由此可见,在BSN中有效发挥Transformer的能力非常具有挑战性。
本研究旨在分析和重新设计空间和通道自注意力机制 ,以满足盲点要求,并构建一个基于Transformer的盲点网络(TBSN) 。本研究发现,通道自注意力 在多尺度架构 中可能会泄露盲点信息,因为下采样操作将空间特征混洗到通道维度。为了缓解这个问题,本研究将通道分成几个组,并分别对每个组执行通道注意力。对于空间自注意力 ,本研究将一个精心设计的掩码应用于注意力矩阵,以限制其感受野并模拟空洞卷积 的感受野。此外,由于满足盲点要求的额外设计,BSN架构的计算效率通常较低。本研究利用知识蒸馏策略,将TBSN蒸馏成更小的去噪器,以提高计算效率,同时保持性能。
论文创新点
本研究提出了一个名为TBSN的基于Transformer的盲点网络,用于自监督图像去噪,它在多个方面进行了创新:
-
🎨 重新设计通道注意力机制: 🎨
- 本研究发现,在多尺度架构中,传统的通道注意力机制可能会泄露盲点信息,尤其当通道维度大于空间分辨率时。
- 这是因为下采样操作将空间信息混淆到了通道维度中,通道间的交互会导致盲点位置的信息泄露,从而导致对噪声输入的过拟合。
- 为了解决这个问题,本研究提出将通道分成若干组,并在每组内分别执行通道注意力。
- 通过控制每组的通道数量小于空间分辨率,有效避免了空间信息的泄露,从而提高了去噪性能。
-
🪟 引入带掩码的窗口注意力机制: 🪟
- 本研究提出了一种带掩码的窗口注意力机制(M-WSA),以满足盲点网络的要求。
- 该机制通过对注意力矩阵应用一个精心设计的固定掩码,来限制每个像素的感受野,使其只能注意到偶数坐标处的像素。
- 这种设计模仿了空洞卷积的感受野,既能保持盲点特性,又能利用Transformer的优势,例如更大的感受野和更强的局部拟合能力,从而在不牺牲盲点要求的前提下,提高了网络的性能。
-
🌐 构建基于Transformer的盲点网络(TBSN): 🌐
- 本研究将重新设计的通道注意力和窗口注意力机制结合起来,构建了一个名为TBSN的Transformer网络。
- 该网络集成了空洞卷积和Transformer的优点,既能有效地捕捉局部信息,又具有全局感知能力,从而在自监督图像去噪任务中取得了优异的性能。
-
👨🏫 提出知识蒸馏策略以提高推理效率: 👨🏫
- 本研究发现,由于复杂的网络设计和额外的盲点限制,盲点网络通常计算效率较低。
- 为了解决这个问题,本研究引入了一种知识蒸馏策略。
- 将预训练的TBSN的结果作为伪ground-truth,并以此来监督训练一个更简单的U-Net网络(TBSN2UNet)。
- 这种方法在保持去噪性能的同时,显著降低了推理时的计算成本,使其更适用于实时应用和资源受限的设备。
-
🔄 非对称像素重组下采样和随机替换策略: 🔄
- 本研究采用非对称的像素重组下采样策略来打破噪声相关性,在训练和推理阶段使用不同的下采样因子,以在噪声去除和细节保留之间取得更好的平衡。
- 此外,本研究还采用了随机替换精细化策略来进一步提升去噪效果。
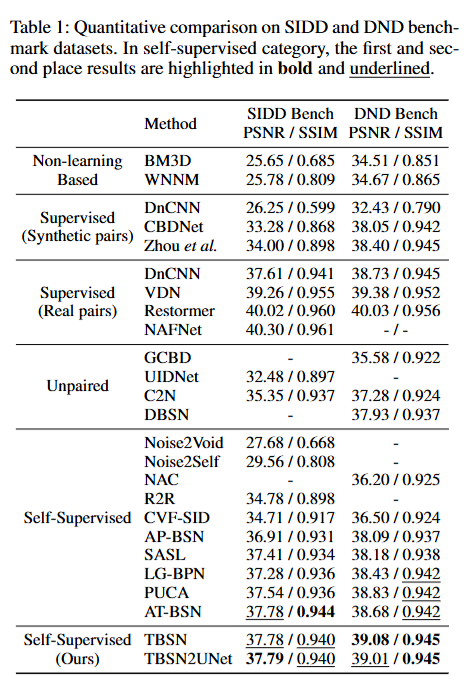
论文实验