深度学习 --- 迁移学习以及onnx推理
文章目录
- [深度学习 --- 迁移学习以及onnx推理](#深度学习 --- 迁移学习以及onnx推理)
- 五,预训练与迁移学习
-
- 5.1(以resnet18网络以及权重示例)
- [5.2 初始化](#5.2 初始化)
- [5.3 保存初始权值重文件](#5.3 保存初始权值重文件)
- [5.4 修改网格结构](#5.4 修改网格结构)
- [5.5 调整权重参数](#5.5 调整权重参数)
- [5.6 新参数+新模型](#5.6 新参数+新模型)
- 六,整体流程
- 七,模型移植
-
- [7.1 onnx](#7.1 onnx)
- [7.2 得到onnx文件](#7.2 得到onnx文件)
-
- [7.2.1 安装依赖包](#7.2.1 安装依赖包)
- [7.2.2 导出onnx文件](#7.2.2 导出onnx文件)
- [7.2.3 onnx结构可视化](#7.2.3 onnx结构可视化)
- [7.3 使用onnx作推理](#7.3 使用onnx作推理)
五,预训练与迁移学习
在原始的已经学习了基本特征的权重参数基础之上,继续进行训练,而不是每次都从0开始。
原始权重参数:
- 官方经典网络模型的预训练参数:别人已经训练好了;
- 也可以是自己训练好的权重文件;
5.1(以resnet18网络以及权重示例)
python
from torchvision.models import resnet18, ResNet18_Weights5.2 初始化
python
weight = ResNet18_Weights.DEFAULT
model = resnet18(weights=weight)
model.to(device)5.3 保存初始权值重文件
python
# 保存模型权重文件到本地
if not os.path.exists(os.path.join(mdelpath, f"model_res18.pth")):
torch.save(model.state_dict(), os.path.join(mdelpath, f"model_res18.pth"))5.4 修改网格结构
重新加载resnet18模型并修改网络结构。
ResNet18默认有1000个类别,和我们的需求不匹配需要修改网络结构
python
# 重新加载网络模型:需要根据分类任务进行模型结构调整
pretrained_model = resnet18(weights=None)
# print(pretrained_model)
in_features_num = pretrained_model.fc.in_features
pretrained_model.fc = nn.Linear(in_features_num, 10)5.5 调整权重参数
python
# 加载刚才下载的权重参数
weight18 = torch.load(os.path.join(mdelpath, f"model_res18.pth"))
print(weight18.keys())
# 全连接层被我们修改了,需要删除历史的全连接层参数
weight18.pop("fc.weight")
weight18.pop("fc.bias")
# 获取自己的模型的参数信息
my_resnet18_dict = pretrained_model.state_dict()
# 去除不必要的权重参数
weight18 = {k:v for k, v in weight18.items() if k in my_resnet18_dict}
#更新
my_resnet18_dict.update(weight18)5.6 新参数+新模型
python
处理完后把最新的参数更新到模型中
pretrained_model.load_state_dict(my_resnet18_dict)
model = pretrained_model.to(device)六,整体流程
6.1导入包
python
import time
import os
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10
from torchvision.models import resnet18, ResNet18_Weights
import wandb
from torch.utils.tensorboard import SummaryWriter
from sklearn.metrics import *
import matplotlib.pyplot as plt6.2 加载构建数据集
python
train_dataset = CIFAR10(
root=datapath,
train=True,
download=True,
transform=transform,
)
train_loader = DataLoader(
#
dataset=train_dataset,
batch_size=batzh_size,
shuffle=True,
num_workers=2,
)6.3模型
python
# 再次获取resnet18原始神经网络并对齐fc层进行调整
model = resnet18(weights=None)
in_features = model.fc.in_features
# 重写FC:我们这里做的是10分类
model.fc = nn.Linear(in_features=in_features, out_features=10)
# 需要对权重信息进行处理:要加载我们训练之后最新的权重文件
weights_default = torch.load(weightpath)
weights_default.pop("fc.weight")
weights_default.pop("fc.bias")
# 把权重参数进行同步
new_state_dict = model.state_dict()
weights_default_process = {
k: v for k, v in weights_default.items() if k in new_state_dict
}
new_state_dict.update(weights_default_process)
model.load_state_dict(new_state_dict)
model.to(device)6.4 训练
6.4.1 数据增强
python
transform = transforms.Compose(
[
transforms.RandomRotation(45), # 随机旋转,-45到45度之间随机选
transforms.RandomCrop(32, padding=4), # 随机裁剪
transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转 选择一个概率概率
transforms.RandomVerticalFlip(p=0.5), # 随机垂直翻转
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2471, 0.2435, 0.2616)),
]
)
transformtest = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2471, 0.2435, 0.2616)),
]
)6.4.2 开始训练
python
# 损失函数和优化器
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
for epoch in range(epochs):
# 开始时间
start = time.time()
# 总的损失值
total_loss = 0.0
# 样本数量:最后一次样本数量不是128
samp_num = 0
# 总的预测正确的分类
correct = 0
model.train()
for i, (x, y) in enumerate(train_loader):
x, y = x.to(device), y.to(device)
# 累加样本数量
samp_num += len(y)
out = model(x)
# 预测正确的样本数量
correct += out.argmax(dim=1).eq(y).sum().item()
loss = loss_fn(out, y)
# 损失率累加
total_loss += loss.item() * len(y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 100 == 0:
img_grid = torchvision.utils.make_grid(x)
write1.add_image(
f"r_m_{epoch}_{i}", img_grid, epoch * len(train_loader) + i
)
print(
"批次:%d 损失率:%.4f 准确率:%.4f 耗时:%.4f"
% (epoch, total_loss / samp_num, correct / samp_num, time.time() - start)
)
# log metrics to wandb
wandb.log({"acc": correct / samp_num, "loss": total_loss / samp_num})6.4.3 保存模型
python
torch.save(model.state_dict(), weightpath)6.4.4 训练过程可视化
python
write1 = SummaryWriter(log_dir=log_dir)
# 保存模型结构到tensorboard
write1.add_graph(model, input_to_model=torch.randn(1, 3, 32, 32).to(device=device))6.5 数据验证
- 数据验证
python
weights_default = torch.load(weightpath)
# 再次获取resnet18原始神经网络并对齐fc层进行调整
model = resnet18(pretrained=False)
in_features = model.fc.in_features
# 重写FC:我们这里做的是10分类
model.fc = nn.Linear(in_features=in_features, out_features=10)
model.load_state_dict(weights_default)
model.to(device)
model.eval()
samp_num = 0
correct = 0
data2csv = np.empty(shape=(0, 13))
for x, y in vaild_loader:
x = x.to(device)
y = y.to(device)
# 累加样本数量
samp_num += len(y)
# 模型运算
out = model(x)
# 数组的合并
data2csv = np.concatenate((data2csv, outdata_softmax), axis=0)
# 预测正确的样本数量
correct += out.argmax(dim=1).eq(y).sum().item()
print("准确率:%.4f" % (correct / samp_num))- 数据结果可视化
python
data2csv = np.empty(shape=(0, 13))
#数据整理
out = model(x)
outdata = out.cpu().detach()
outdata_softmax = torch.softmax(outdata, dim=1)
outdata_softmax = np.concatenate(
(
# 本身预测的值
outdata_softmax.numpy(),
# 真正的目标值
y.cpu().numpy().reshape(-1, 1),
# 预测值
outdata_softmax.argmax(dim=1).reshape(-1, 1),
# 分类名称
np.array([vaild_dataset.classes[i] for i in y.cpu().numpy()]).reshape(
-1, 1
),
),
axis=1,
)
# 数组的合并
data2csv = np.concatenate((data2csv, outdata_softmax), axis=0)
#写入CSV
columns = np.concatenate((vaild_dataset.classes, ["target", "prep", "分类"]))
pddata = pd.DataFrame(data2csv, columns=columns)
pddata.to_csv(csvpath, encoding="GB2312")6.6 指标分析
python
def analy():
# 读取csv数据
data1 = pd.read_csv(csvpath, encoding="GB2312")
print(type(data1))
# 整体数据分析报告
report = classification_report(
y_true=data1["target"].values,
y_pred=data1["prep"].values,
)
print(report)
# 准确度 Acc
print(
"准确度Acc:",
accuracy_score(
y_true=data1["target"].values,
y_pred=data1["prep"].values,
),
)
# 精确度
print(
"精确度Precision:",
precision_score(
y_true=data1["target"].values, y_pred=data1["prep"].values, average="macro"
),
)
# 召回率
print(
"召回率Recall:",
recall_score(
# 100
y_true=data1["target"].values,
y_pred=data1["prep"].values,
average="macro",
),
)
# F1 Score
print(
"F1 Score:",
f1_score(
y_true=data1["target"].values,
y_pred=data1["prep"].values,
average="macro",
),
)
pass
def matrix():
# 读取csv数据
data1 = pd.read_csv(csvpath, encoding="GB2312", index_col=0)
confusion = confusion_matrix(
# 0
y_true=data1["target"].values,
y_pred=data1["prep"].values,
# labels=data1.columns[0:10].values,
)
print(confusion)
# 绘制混淆矩阵
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
plt.matshow(confusion, cmap=plt.cm.Greens)
plt.colorbar()
for i in range(confusion.shape[0]):
for j in range(confusion.shape[1]):
plt.text(j, i, confusion[i, j], ha="center", va="center", color="b")
plt.title("验证数据混淆矩阵")
plt.xlabel("Predicted label")
plt.xticks(range(10), data1.columns[0:10].values, rotation=45)
plt.ylabel("True label")
plt.yticks(range(10), data1.columns[0:10].values)
plt.show()6.7 调用主函数
python
def app():
dir = os.path.dirname(__file__)
imgpath = os.path.join("图片位置目录", "图片名称")
# 读取图像文件
img = cv2.imread(imgpath)
# 将图像转换为灰度图
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 对灰度图进行二值化处理,采用OTSU自适应阈值方法,并反转颜色
ret, img = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)
plt.imshow(img)
plt.show()
# img = cv2.resize(img, (32, 32))
img = torch.Tensor(img).unsqueeze(0)
transform = transforms.Compose(
[
transforms.Resize((32, 32)), # 调整输入图像大小为32x32
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)),
]
)
img = transform(img).unsqueeze(0)
# 加载模型
net = LeNet5()
net.load_state_dict(torch.load(modelpath))
# 预测
outputs = net(img)
print(outputs)
print(outputs.argmax(axis=1))七,模型移植
7.1 onnx
Open Neural Network Exchange(ONNX,开放神经网络交换)格式,是一个用于表示深度学习模型的标准,可使模型在不同框架之间进行转移。
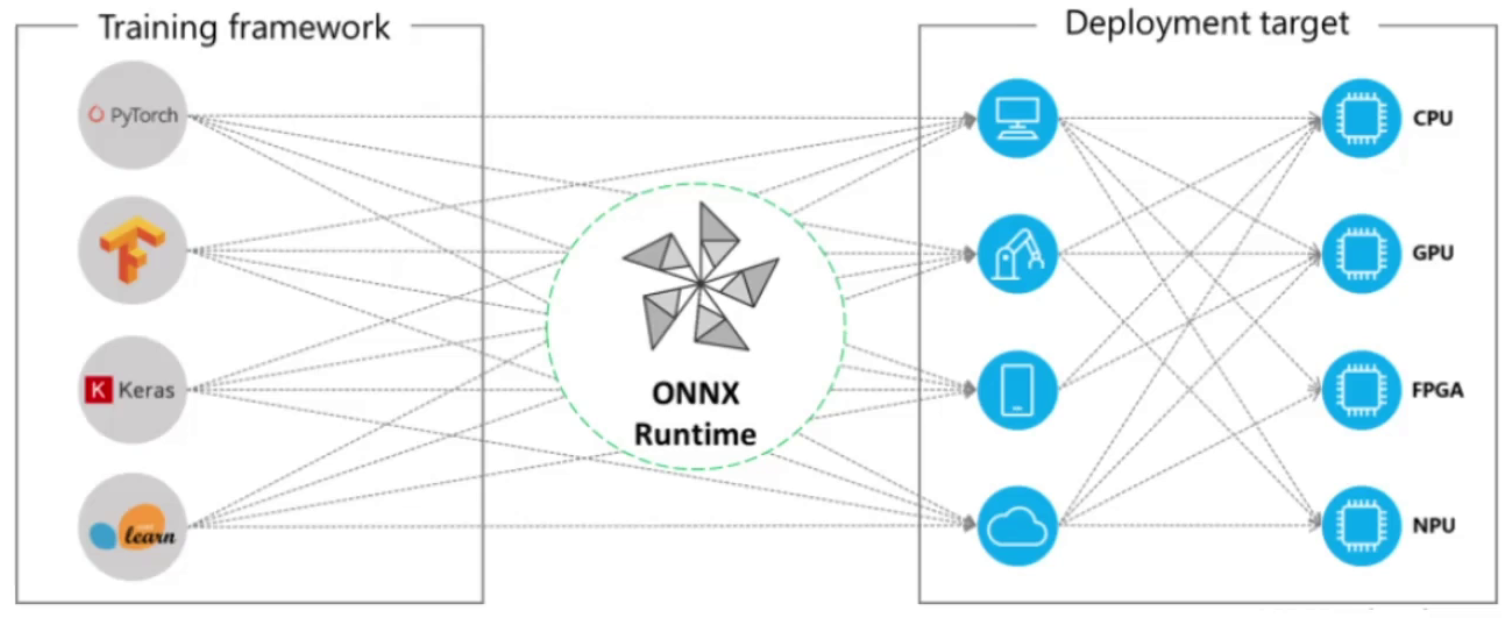
目前官方支持加载ONNX模型并进行推理的深度学习框架有: Caffe2, PyTorch, PaddlePaddle, TensorFlow等。
7.2 得到onnx文件
7.2.1 安装依赖包
python
pip install onnx
pip install onnxruntime7.2.2 导出onnx文件
python
import os
import torch
import torch.nn as nn
from torchvision.models import resnet18
if __name__ == "__main__":
dir = os.path.dirname(__file__)
weightpath = os.path.join(
os.path.dirname(__file__), "pth", "resnet18_default_weight.pth"
)
onnxpath = os.path.join(
os.path.dirname(__file__), "pth", "resnet18_default_weight.onnx"
)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = resnet18(pretrained=False)
model.conv1 = nn.Conv2d(
#
in_channels=3,
out_channels=64,
kernel_size=3,
stride=1,
padding=0,
bias=False,
)
# 删除池化层
model.maxpool = nn.MaxPool2d(kernel_size=1, stride=1, padding=0)
# 修改全连接层
in_feature = model.fc.in_features
model.fc = nn.Linear(in_feature, 10)
model.load_state_dict(torch.load(weightpath, map_location=device))
model.to(device)
# 创建一个实例输入
x = torch.randn(1, 3, 224, 224, device=device)
# 导出onnx
torch.onnx.export(
model,
x,
onnxpath,
#
verbose=True, # 输出转换过程
input_names=["input"],
output_names=["output"],
)
print("onnx导出成功")7.2.3 onnx结构可视化
可以直接在线查看:https://netron.app/
也可以下载桌面版:https://github.com/lutzroeder/netron
7.3 使用onnx作推理
一般使用GPU,安装
pip install onnxruntime-gpu
python
import time
import random
import os
# 推理的模块
import onnxruntime as ort
import torchvision.transforms as transforms
import numpy as np
import PIL.Image as Image
img_size = 32
transformtest = transforms.Compose(
[
transforms.Resize((img_size, img_size)),
transforms.ToTensor(),
transforms.Normalize(
# 均值和标准差
mean=[0.4914, 0.4822, 0.4465],
std=[0.2471, 0.2435, 0.2616],
),
]
)
def softmax(x):
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum(axis=1, keepdims=True)
def imgclass():
# AI推理
# 读取图片
imgpath = os.path.join(os.path.dirname(__file__), "..", "static/ai", filename)
# 加载并预处理图像
image = Image.open(imgpath)
input_tensor = transformtest(image)
input_tensor = input_tensor.unsqueeze(0) # 添加批量维度
# 将图片转换为ONNX运行时所需的格式
img_numpy = input_tensor.numpy()
# 加载模型
onnxPath = os.path.join(
#
os.path.dirname(__file__),
"..",
"onnx",
"resnet18_default_weight_1.onnx",
)
# 设置 ONNX Runtime 使用 GPU
providers = ["CUDAExecutionProvider"]
sess = ort.InferenceSession(onnxPath, providers=providers)
# 使用模型对图片进行推理运算
output = sess.run(None, {"input": img_numpy})
output = softmax(output[0])
print(output)
ind = np.argmax(output, axis=1)
print(ind)
lablename = "飞机、汽车、鸟类、猫、鹿、狗、青蛙、马、船、卡车".split("、")
res = {"code": 200, "msg": "处理成功", "url": img, "class": lablename[ind[0]]}